
Redes neuronales en el trading: Sistema multiagente con validación conceptual (Final)

Introducción
En el artículo anterior, nos familiarizamos con los aspectos teóricos del framework FinCon, desarrollado como herramienta de análisis y automatización en el sector financiero. Su objetivo consiste en ayudar a la toma de decisiones en los mercados financieros utilizando big data, análisis de información textual (NLP) y técnicas de gestión de portafolios. La idea principal del sistema es usar una arquitectura multiagente, en la que cada módulo realiza determinadas tareas, interactuando con otros para alcanzar objetivos comunes.
El elemento clave de la arquitectura es el Agentes-Gestor, que coordina el trabajo de los Agentes-Analistas. El gestor integra los resultados del trabajo de los analistas, controla los riesgos y afina la estrategia de inversión. En el FinCon se emplean analistas especializados, entre los que se distribuyen las funciones de procesamiento y análisis de datos, la previsión de la dinámica del mercado y la evaluación de riesgos. La división de tareas entre agentes reduce la redundancia de información y acelera el procesamiento.
El framework aplica una arquitectura de gestión de riesgos de dos niveles:
- El primer nivel opera en tiempo real, minimizando las pérdidas a corto plazo.
- La segunda capa analiza las acciones del sistema según los episodios completados, lo que ayuda a identificar errores y mejorar las estrategias.
Una de las características clave de FinCon es el uso del refuerzo verbal conceptual (FRCV). Este mecanismo evalúa la actuación de los Analistas y las decisiones comerciales del Gestor. Esto permite al sistema aprender de la experiencia y mejorar la política de comportamiento usada centrándose en los factores más relevantes del mercado.
El framework también incluye un sistema de memoria de tres niveles:
- La memoria de trabajo se encarga de almacenar temporalmente los datos para las operaciones en curso.
- La memoria procedimental almacena métodos y algoritmos probados que pueden reutilizarse.
- La memoria episódica registra acontecimientos clave y sus resultados, lo cual nos permite analizar experiencias pasadas y aplicarlas al futuro.
A continuación le mostramos la visualización del framework FinCon realizada por el autor.

En el artículo anterior empezamos a trabajar en la implementación de nuestra propia visión de los planteamientos propuestos por los autores del framework. Dentro del objeto CNeuronMemoryDistil, construimos los algoritmos de funcionamiento del sistema de memoria de tres niveles. Y hoy continuaremos esa labor.
Objeto de análisis de agentes
Hoy comenzaremos nuestro trabajo construyendo el módulo de Agente-Analista. Los autores del framework FinCon han desarrollado un módulo de agente universal que puede trabajar en una gran variedad de ámbitos, independientemente de la especificidad de las tareas realizadas. Esto es posible gracias a una arquitectura basada en un gran modelo lingüístico (LLM) preentrenado que funciona a modo de «pregunta-respuesta» (QA). La especificidad del trabajo de un agente dependerá de la cuestión o tarea que se le plantee.
Aunque nuestros modelos no utilizan LLM, esto no nos impide crear un objeto genérico que puede adaptarse para realizar las funciones de los Agentes-Analistas con distintas especializaciones. Este planteamiento garantizará la flexibilidad y modularidad del sistema.
Como ya describimos en el artículo del autor, los agentes del framework FinCon incluyen varios módulos clave que se integran para apoyar su funcionalidad.
El módulo de configuración general y perfiles juega un papel importante en la definición de los tipos de tareas que deben resolverse. No solo fija objetivos comerciales, incluyendo detalles sobre sectores económicos e indicadores de resultados, sino que también asigna funciones y responsabilidades a los agentes. Este módulo genera un framework textual básico que se usa para generar consultas relacionadas con la funcionalidad del agente a la base de datos de memoria.
Además, el módulo general de configuración y creación de perfiles ayuda a los agentes a adaptarse a los distintos sectores de la economía identificando las métricas más importantes para la tarea en curso. La información generada por este módulo se convierte en la base para la correcta interacción de todos los demás componentes del sistema.
El módulo de percepción se ocupa de organizar la interacción del agente con el entorno, y regula la percepción de la información del mercado filtrando los datos y destacando además los patrones significativos. De este modo, el agente puede adaptarse a las condiciones cambiantes sin dejar de resultar eficaz y preciso en sus predicciones.
El módulo de memoria es un componente fundamental, pues permite almacenar y procesar los datos necesarios para la toma de decisiones. Consta de tres componentes clave: la memoria de trabajo, la memoria procedimental y la memoria episódica. La memoria de trabajo permite al agente ejecutar las tareas actuales observando los cambios en el mercado y adaptando sus acciones. La memoria procedimental registra todos los pasos dados por el agente durante el proceso, incluidos los resultados y las conclusiones. La memoria episódica, a su vez, almacena datos sobre tareas completadas y ayuda a formar estrategias a largo plazo.
En nuestro artículo anterior ya desarrollamos el módulo de memoria, así que ahora podemos utilizar una solución comercial. Aquí merece la pena decir que los autores del framework solo proporcionan acceso a la memoria episódica al gestor. En nuestra implementación, sin embargo, usaremos una organización de memoria de tres niveles para todos los agentes. Cada agente dispondrá de su propio módulo de memoria, que restringirá de forma natural el acceso solo a los datos relevantes para la tarea en cuestión. Este enfoque permitirá al agente tener en cuenta no solo los cambios recientes, sino también su contexto dentro de una perspectiva temporal más amplia.
La funcionalidad del módulo general de configuración y creación de perfiles implica un objeto especial que resida fuera del agente y genere tareas considerando las particularidades de cada agente y los datos de origen disponibles. En nuestra aplicación, asumiremos el uso de datos de entrada homogéneos. Y esto significa que, dado un rol de agente fijo, se generarán las mismas consultas en cada paso del trabajo del agente. No obstante, durante el entrenamiento del modelo, estas consultas pueden ajustarse para que el agente reciba tareas más precisas de acuerdo con su función y habilidades actuales.
Estas reflexiones nos llevan a la idea de crear un tensor de consultas entrenable dentro del propio módulo del agente. Dicho enfoque eliminará la necesidad de un flujo adicional de información externa al agente. En este caso, los valores iniciales de dicho tensor se establecerán aleatoriamente durante la inicialización del objeto. Estos parámetros forman las capacidades "cognitivas innatas" del agente, ofreciendo una base única para su aprendizaje futuro.
Durante el entrenamiento, el agente adquiere gradualmente el papel que mejor se ajusta a sus capacidades individuales formadas durante la fase de inicialización. Esto permitirá al agente no solo adaptarse orgánicamente a las tareas que tiene entre manos, sino también utilizar eficazmente sus características "innatas", creando una base sólida para su desarrollo posterior. El tensor de consultas entrenado se convierte así en una herramienta clave para identificar y reforzar la dirección más adecuada para el desarrollo de agentes. Este enfoque garantiza la coherencia entre el estado inicial dado aleatoriamente y el papel objetivo del agente, lo cual a su vez ayudará a reducir el coste de entrenamiento del modelo, mejorando su eficiencia global.
El objetivo principal del módulo de percepción consiste en identificar enfoques que ayuden a extraer patrones del flujo general de información que resulten más útiles para realizar las tareas del agente. Para hacer realidad esta característica, podemos usar mecanismos de atención cruzada. Estos permitirán "destacar" los datos más relevantes, garantizando un filtrado y procesamiento de la información eficaces.
Tras considerar las cuestiones relativas a la construcción de los módulos internos del agente, nos convendrá detenernos en el análisis de los resultados de nuestro trabajo. Una de las cuestiones clave es la especificidad de los resultados obtenidos. Por una parte, dicha especificidad se debe a las tareas asignadas al agente, lo cual contradice en cierto modo el concepto de agente universal. Por otra parte, la diversidad de resultados complica su procesamiento, lo que hace muy pertinente la tarea de la normalización.
En esta implementación, a la salida de cada agente, generaremos un tensor de la próxima decisión comercial. Obviamente, deberemos recordar que los autores del framework han otorgado el derecho exclusivo de generar una solución comercial únicamente al gestor. Pero nadie impide que cada agente ofrezca sus sugerencias. Esto nos permitirá crear una estructura de datos unificada que pueda utilizarse para describir la salida de un agente, independientemente de su función específica. Dicha normalización simplificará el procesamiento de los resultados y mejorará la eficacia global del sistema.
Todos los enfoques descritos anteriormente se implementarán dentro del objeto CNeuronFinConAgent, cuya estructura se muestra a continuación.
class CNeuronFinConAgent : public CNeuronRelativeCrossAttention { protected: CNeuronMemoryDistil cStatesMemory; CNeuronMemoryDistil cActionsMemory; CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronFinConAgent(void) {}; ~CNeuronFinConAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
En la estructura presentada, podemos observar el conjunto familiar de métodos redefinidos y varios objetos que utilizaremos para organizar los enfoques descritos anteriormente. Conoceremos más detalles sobre la finalidad de cada uno de ellos durante la implementación de los algoritmos de los métodos de dicho objeto.
Además, deberemos prestar atención a la utilización rigurosa del objeto de atención cruzada como clase padre. También usaremos los métodos y objetos heredados de esta forma para organizar el trabajo del módulo que estamos creando.
Todos los objetos internos se declararán estáticamente, lo que simplificará la estructura de la clase al dejar vacíos el constructor y el destructor. La inicialización de todos los objetos internos y heredados se realizará en el método Init. El método especificado adoptará una serie de constantes que permitirán definir de forma clara e inequívoca la arquitectura del objeto creado.
bool CNeuronFinConAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, 3, window_key, action_space / 3, heads, window, units_count, optimization_type, batch)) return false;
Como siempre, en el cuerpo del método primero llamaremos al método homónimo de la clase padre, en el que ya estará organizado el proceso de inicialización de los objetos heredados y las interfaces de intercambio de datos con los objetos externos.
Como ya hemos mencionado, hemos elegido un objeto de atención cruzada como clase padre. Estos objetos están diseñados para trabajar con dos flujos de datos, lo que puede plantear dudas en el contexto de las operaciones de los agentes FinCon. Al fin y al cabo, inicialmente interactúan con el flujo unitario de información necesario para una tarea concreta. Sin embargo, debemos considerar que los agentes reciben además información del módulo de memoria. Y esto introduce un segundo flujo de datos. Además, un aspecto importante de la actuación de los agentes es su coherencia y capacidad para analizar sus acciones, realizando ajustes en respuesta a las cambiantes condiciones del mercado. Este proceso de reflexión constituye el tercer flujo de información.
En nuestra implementación, la funcionalidad de reflexión se organizará usando mecanismos heredados de la clase padre. Se espera que los enfoques de atención cruzada resulten eficaces para ajustar el tensor de resultados anteriores en el contexto de las cambiantes condiciones del mercado. Así, el flujo de datos principal para el objeto padre estará representado por los parámetros del tensor de resultados, mientras que el segundo flujo estará representado por información sobre el estado actual del entorno.
Recordemos que a la salida del agente esperaremos un tensor de operaciones recomendadas.
A continuación, inicializaremos los dos módulos de atención. En ellos, almacenaremos por separado la dinámica de la situación del mercado y la secuencia de decisiones comerciales propuestas por este agente. Esto nos permitirá evaluar mejor la eficacia de la política de comportamiento usada en el contexto de la dinámica actual del mercado.
int index = 0; if(!cStatesMemory.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, stack_size, optimization, iBatch)) return false; index++; if(!cActionsMemory.Init(0, index, OpenCL, iWindow, iWindowKey, iUnits, iHeads, stack_size, optimization, iBatch)) return false;
Construiremos el módulo de perfiles partiendo de dos capas consecutivas totalmente conectadas. La primera capa contendrá un elemento con un valor fijo de "1", mientras que la segunda capa generará un tensor de un tamaño determinado. En nuestra aplicación, la longitud del vector generado será 10 veces la longitud de la descripción de un elemento de la secuencia original. Esto puede compararse con la descripción del papel de un agente con una secuencia de 10 elementos.
index++; if(!caRole[0].Init(10 * iWindow, index, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = caRole[0].getOutput(); if(!out || !out.Fill(1)) return false; index++; if(!caRole[1].Init(0, index, OpenCL, 10 * iWindow, optimization, iBatch)) return false;
La función del módulo de percepción, como ya hemos comentado, la cumplirá el objeto interno de atención cruzada. Este deberá analizar los datos de origen recibidos en el contexto de la especificidad del agente.
index++; if(!cStateToRole.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, iWindow, 10, optimization, iBatch)) return false; //--- return true; }
Y tras inicializar con éxito todos los objetos internos y heredados, devolveremos el resultado lógico de las operaciones al programa que realiza la llamada y finalizaremos el método.
La siguiente etapa de nuestro trabajo consistirá en construir el algoritmo de pasada directa dentro del método feedForward. Aquí deberemos organizar los flujos de información entre los objetos anteriormente inicializados.
bool CNeuronFinConAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
En los parámetros del método, obtendremos el puntero al objeto de datos de origen que contiene las descripciones del estado del entorno. Y aquí deberemos recordar que cada agente analiza la información recibida teniendo en cuenta sus especificidades. Por ello, primero generaremos una descripción tensorial del problema en cuestión.
Nótese que el tensor de roles del agente solo se generará durante el proceso de aprendizaje. Y es que en el modo de prueba y de explotación del modelo, la especialización del agente permanecerá invariable, y no será necesario volver a generar este tensor en cada iteración.
A continuación, utilizaremos el objeto interno de atención cruzada para extraer patrones relevantes para la tarea del agente.
if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false; if(!cStatesMemory.FeedForward(cStateToRole.AsObject())) return false;
Luego transferiremos los valores obtenidos al módulo de memoria del estado del entorno, para enriquecer el estado actual con información sobre la dinámica anterior. Este enfoque permitirá comprender mejor el contexto.
Del mismo modo, añadiremos los resultados de la pasada anterior al módulo de memoria de acciones del agente.
if(!cActionsMemory.FeedForward(this.AsObject())) return false;
Así, las salidas de los dos módulos de memoria generarán tensores que describirán la última acción del agente y los cambios correspondientes en el estado del entorno. Estos datos se transmitirán al método homónimo de la clase padre, que ajustará el tensor de transacciones comerciales recomendadas considerando la dinámica actual del mercado.
Antes de hacerlo, sin embargo, deberemos reorganizar los punteros a los búferes de datos, lo que preservará el tensor de resultados anterior, asegurando que las operaciones de pasada inversa se realicen correctamente durante el entrenamiento del modelo.
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CNeuronRelativeCrossAttention::feedForward(cActionsMemory.AsObject(), cStatesMemory.getOutput()); }
Después retornaremos el resultado lógico de las operaciones al programa que realiza la llamada y finalizaremos el método.
Una vez finalizada la implementación del algoritmo de pasada directa, organizaremos los flujos de información para la pasada inversa. Como es sabido, el flujo de datos en la propagación del gradiente de error sigue la estructura de los flujos de información de pasada directa, pero se dirigirá en sentido contrario. Como las rutas de pasada directa y inversa son idénticas, el modelo considerará eficazmente la influencia de cada parámetro en el resultado final.
Las operaciones de distribución del gradiente de error se implementarán en el método calcInputGradients. En los parámetros del método, obtendremos el puntero al objeto de datos de origen, solo que ahora tendremos que pasarle los valores de los gradientes de error correspondientes a la influencia de los datos de origen en el resultado final del modelo.
bool CNeuronFinConAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
En el cuerpo del método comprobaremos directamente la relevancia del puntero obtenido, porque de lo contrario todas las operaciones posteriores carecerán de sentido.
Las operaciones de distribución del gradiente de error comenzarán directamente con una llamada al método homónimo de la clase padre. Este pasará los errores a los módulos de atención.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cActionsMemory.AsObject(), cStatesMemory.getOutput(), cStatesMemory.getGradient(), (ENUM_ACTIVATION)cStatesMemory.Activation())) return false;
En la línea troncal del módulo de memoria de las propuestas de transacciones comerciales, tendremos que transmitir el gradiente de error a nuestro objeto actual. Al fin y al cabo, los resultados de su pasada directa anterior se han utilizado como datos de entrada para este módulo de memoria. Solo el búfer de resultados contendrá otros valores obtenidos durante las operaciones de la última pasada directa. Además, queremos conservar los valores actuales del búfer de gradiente de error. Por lo tanto, primero retornaremos al búfer de resultados los resultados que tan prudentemente guardamos de la anterior pasada directa, sustituyendo los punteros al objeto de búfer. Y en lugar del puntero al búfer de gradiente de error, pondremos un búfer de datos libre. Y solo después de completar con éxito el trabajo preparatorio, realizaremos la distribución del gradiente de error.
CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cActionsMemory.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cActionsMemory.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
Aquí, cabe señalar que no propagaremos recurrentemente el gradiente de error a las pasadas anteriores. Y en este caso no utilizaremos el gradiente de error obtenido tras las operaciones anteriores. Sin embargo, la implementación de estas operaciones se verá condicionada por la necesidad de distribuir los gradientes de error entre los objetos internos del módulo de memoria. Y ya después de ejecutar con éxito las acciones especificadas, devolveremos los punteros a los búferes de datos al estado inicial.
A continuación, tendremos que distribuir el gradiente de error a lo largo de la línea troncal del módulo de memoria del estado del entorno. Aquí lo haremos descender primero al nivel del módulo de percepción, cuyo papel desempeña la unidad de atención cruzada.
if(!cStateToRole.calcHiddenGradients(cStatesMemory.AsObject())) return false;
Y a continuación distribuiremos los errores obtenidos entre los datos de origen y el MLP de generación del tensor de descripción del rol del agente según su influencia en el resultado del modelo.
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
No distribuimos el gradiente de error por el MLP de generación del tensor de descripción del rol del agente, ya que su primera capa contiene un valor fijo.
Por consiguiente, una vez realizadas todas las operaciones necesarias, el método retornará el resultado lógico de su éxito al programa que realiza la llamada y finalizará.
Aquí concluimos el análisis de los algoritmos de construcción de los métodos del objeto universal Agente-Analista. Podrá leer el código completo de la clase presentada y todos sus métodos por sí mismo en el archivo adjunto.
Objeto de Gestor
La siguiente etapa de nuestro trabajo consistirá en construir el objeto de Agente-Gestor. Y aquí es donde surge un poco de disonancia. Por un lado, hablamos de construir un agente universal que también pueda usarse como gestor. Por otro, el gestor agrega los resultados y coordina el trabajo de todos los agentes. Y esto significa que obtendrá información de múltiples fuentes.
El trabajo descrito a continuación puede tratarse de muchas maneras distintas. incluida la adaptación del agente universal creado anteriormente a las tareas del gestor. Al fin y al cabo, es la clase del agente universal la que utilizaremos como clase padre al construir el nuevo objeto cuya estructura se presenta a continuación.
class CNeuronFinConManager : public CNeuronFinConAgent { protected: CNeuronTransposeOCL cTransposeState; CNeuronFinConAgent caAgents[3]; CNeuronFinConAgent caTrAgents[3]; CNeuronFinConAgent cRiskAgent; CNeuronBaseOCL cConcatenatedAgents; CNeuronBaseOCL cAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinConManager(void) {}; ~CNeuronFinConManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConManager; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; virtual void TrainMode(bool flag); };
Para minimizar los flujos de información externa, hemos trasladado todos los agentes, colocándolos dentro de nuestro gestor. Y en esta forma, puede percibirse como una organización de un framework FinCon coherente. Sin embargo, esto es más una cuestión de percepción subjetiva, nos centraremos en desarrollar la funcionalidad del nuevo objeto.
En la estructura del nuevo objeto presentada anteriormente, podemos ver el conjunto familiar de métodos redefinidos y varios objetos internos cuya funcionalidad consideraremos durante la creación de los algoritmos para estos métodos de la nueva clase.
Todos los objetos internos se declararán estáticamente, lo que nos permitirá dejar vacíos el constructor y el destructor de la clase, La inicialización de todos los objetos declarados y heredados se realizará en el método Init. En los parámetros de este método obtendremos una serie de constantes que nos permitirán identificar unívocamente la arquitectura del objeto creado.
bool CNeuronFinConManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFinConAgent::Init(numOutputs, myIndex, open_cl, action_space, window_key, caAgents.Size() + caTrAgents.Size() + 1, heads, stack_size, action_space, optimization_type, batch)) return false;
En el cuerpo del método, como viene siendo habitual, llamaremos directamente al método homónimo de la clase padre. Pero en este caso hay un matiz a considerar. Los datos de entrada para el gestor serán los resultados del funcionamiento de los agentes. Por consiguiente, especificaremos la dimensionalidad del vector de resultados del agente como ventana de datos de entrada, mientras que las dimensiones de la secuencia serán iguales al número de agentes internos, incluido el agente de evaluación de riesgos.
Cabe señalar que nuestro gestor trabajará con dos tipos de agentes-analistas. Estos analizarán el estado actual del entorno en dos proyecciones. Y para obtener la segunda proyección de los datos de origen, utilizaremos el objeto de transposición de matrices.
int index = 0; if(!cTransposeState.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
A continuación, organizaremos dos ciclos consecutivos de inicialización agente-analista.
for(uint i = 0; i < caAgents.Size(); i++) { index++; if(!caAgents[i].Init(0, index, OpenCL, window, iWindowKey, units_count, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
for(uint i = 0; i < caTrAgents.Size(); i++) { index++; if(!caTrAgents[i].Init(0, index, OpenCL, units_count, iWindowKey, window, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
Y añadiremos un agente de control de riesgos. Para ello, como datos de origen actuará el vector de descripción del estado actual de la cuenta, que se reflejará en los parámetros al llamar al método de inicialización del objeto.
index++; if(!cRiskAgent.Init(0, index, OpenCL, account_descr, iWindowKey, 1, iHeads, stack_size, action_space, optimization, iBatch)) return false;
Además, necesitaremos un objeto de concatenación para los resultados de todos los agentes internos. Precisamente con este objeto trabajará nuestro Agente-Gestor, cuya funcionalidad hemos heredado de la clase padre.
index++; if(!cConcatenatedAgents.Init(0, index, OpenCL, caAgents.Size()*caAgents[0].Neurons() + caTrAgents.Size()*caTrAgents[0].Neurons() + cRiskAgent.Neurons(), optimization, iBatch)) return false;
Aquí cabe señalar que tenemos previsto recibir información sobre el estado de la cuenta a través de un flujo de información auxiliar que está representado por un búfer de datos. Sin embargo, para que el agente de control de riesgos inicializado funcione correctamente, deberá existir un objeto de capa neuronal que contenga los datos de origen. Por consiguiente, crearemos un objeto interno al que transferiremos la información recibida por el segundo flujo de información.
index++; if(!cAccount.Init(0, index, OpenCL, account_descr, optimization, iBatch)) return false; //--- return true; }
Una vez completadas todas las operaciones anteriores, el método retornará un resultado booleano que indicará que estas se han realizado correctamente y finalizará.
A continuación, construiremos el algoritmo de pasada directa dentro del método feedForward. En este caso, trabajaremos con dos flujos de información de datos de origen. En la línea troncal, planeamos obtener la descripción tensorial del estado del entorno analizado, mientras que la segunda línea troncal obtendrá el resultado financiero del modelo como vector del estado de la cuenta.
bool CNeuronFinConManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(cAccount.getOutput() != SecondInput) { if(!cAccount.SetOutput(SecondInput, true)) return false; }
En el cuerpo del método, primero realizaremos un pequeño trabajo preparatorio, durante el cual el puntero al búfer de resultados del objeto interno de datos de origen de la segunda línea troncal (estado de la cuenta) se sustituirá por el búfer obtenido del flujo de información correspondiente. Además, realizaremos la transposición del tensor de datos de origen del flujo básico de información.
if(!cTransposeState.FeedForward(NeuronOCL)) return false;
Una vez realizado el trabajo preparatorio, transmitiremos los datos obtenidos a los agentes-analistas para que los analicen y generen sus propuestas.
//--- Agents for(uint i = 0; i < caAgents.Size(); i++) if(!caAgents[i].FeedForward(NeuronOCL)) return false; for(uint i = 0; i < caTrAgents.Size(); i++) if(!caTrAgents[i].FeedForward(cTransposeState.AsObject())) return false; if(!cRiskAgent.FeedForward(cAccount.AsObject())) return false;
Los resultados de su funcionamiento se concatenarán en un único objeto.
//--- Concatenate if(!Concat(caAgents[0].getOutput(), caAgents[1].getOutput(), caAgents[2].getOutput(), cRiskAgent.getOutput(), cConcatenatedAgents.getPrevOutput(), Neurons(), Neurons(), Neurons(), Neurons(), 1) || !Concat(caTrAgents[0].getOutput(), caTrAgents[1].getOutput(), caTrAgents[2].getOutput(), cConcatenatedAgents.getPrevOutput(), cConcatenatedAgents.getOutput(), Neurons(), Neurons(), Neurons(), 4 * Neurons(), 1)) return false;
Los resultados combinados del trabajo de todos los agentes se transmitirán al gestor para que tome una decisión final sobre las operaciones comerciales a realizar.
//--- Manager return CNeuronFinConAgent::feedForward(cConcatenatedAgents.AsObject()); }
Luego transmitiremos el resultado lógico de la ejecución de las operaciones al programa que realiza la llamada y finalizaremos el método.
Con esto concluirá nuestra revisión de los algoritmos de construcción de los métodos de nuestro Gestor. Le sugiero estudiar los métodos de pasada inversa por su cuenta. Encontrará el código completo de la clase presentada y todos sus métodos en el archivo adjunto.
Arquitectura del modelo
Ahora diremos unas palabras sobre la arquitectura del modelo entrenado. Para elaborar este artículo solo hemos entrenado un modelo de Agente de decisiones comerciales. Le ruego que no lo confunda con los agentes del framework FinCon.
La arquitectura del modelo entrenado se mantendrá casi sin cambios respecto a artículos anteriores sobre el método FinAgent. Solo hemos sustituido una capa neuronal, lo cual nos ha permitido integrar los enfoques aplicados del framework FinCon.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFinConManager; //--- Windows { int temp[] = {BarDescr, 24, AccountDescr, 2 * NActions}; //Window, Stack Size, Account description, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El código completo de la arquitectura del modelo entrenado se encuentra en el archivo adjunto al artículo. También le presentamos los programas utilizados en el entrenamiento y las pruebas del modelo. Todos ellos se han trasladado sin cambios desde artículos anteriores, por lo que no nos detendremos ahora en su análisis.
Simulación
Los dos últimos artículos se han centrado en el framework FinCon. En ellos hemos detallado sus principios básicos de funcionamiento. Nuestra visión de los enfoques propuestos por los autores del framework se ha implementado utilizando herramientas MQL5, y ahora es el momento de evaluar la eficacia de los enfoques implementados con datos históricos reales.
Cabe señalar que la aplicación presentada en este documento difiere significativamente de la aplicación original, lo cual sin duda afectará a los resultados obtenidos. Por consiguiente, solo podremos hablar de la evaluación de la eficacia de los enfoques aplicados.
Para entrenar el modelo, utilizaremos los datos de EURUSD para 2024 en el marco temporal H1. Los parámetros de los indicadores analizados no han sido modificados, lo cual nos ha permitido centrarnos en el análisis de la eficacia de los propios algoritmos.
La muestra de entrenamiento se ha generado a partir de las ejecuciones de varios modelos con parámetros inicializados aleatoriamente. Además, añadiremos pasadas exitosas creadas a partir de los datos de señales de mercado disponibles utilizando la aplicación Real-ORL. Esto ampliará el abanico de posibles situaciones de mercado y llenará la muestra de entrenamiento de ejemplos positivos.
Durante el entrenamiento, se aplicará un algoritmo para generar acciones objetivo "casi perfectas" para entrenar al Agente. Este enfoque permitirá entrenar el modelo sin actualizar constantemente la muestra de entrenamiento. No obstante, le recomendamos actualizar periódicamente los datos, lo que puede mejorar aún más los resultados del aprendizaje al ampliar la cobertura de los estados.
Las pruebas finales se realizarán con los datos disponibles para enero de 2025, manteniendo intactos los demás parámetros. Ahora le presentamos los resultados de las pruebas.
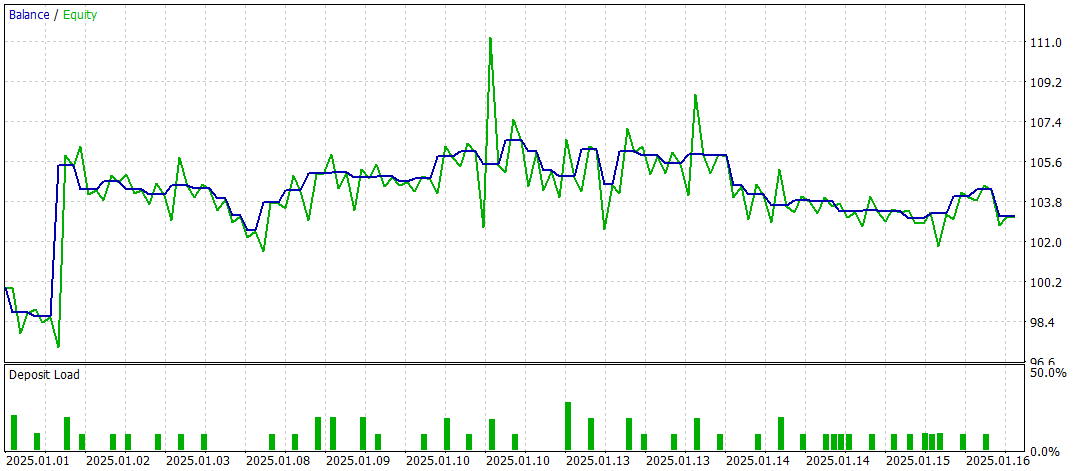
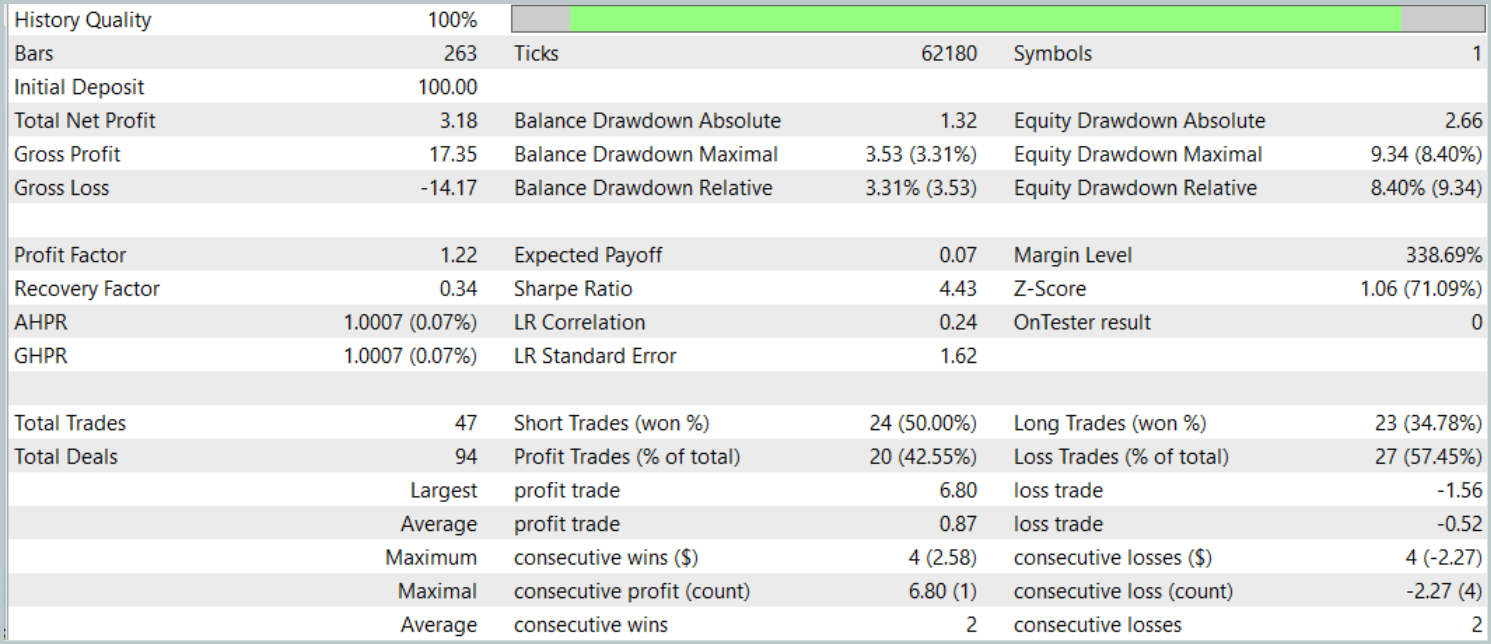
Los resultados de las pruebas ofrecen una imagen desigual de la eficacia del modelo. Durante el periodo de prueba hemos logrado obtener beneficios realizando 47 transacciones comerciales, pero solo el 42% de ellas han tenido éxito. Además, solo se ha logrado un aumento significativo del balance gracias a una operación exitosa, mientras que el resto del tiempo la línea de balance se ha mantenido en un estrecho margen. Esto indica la necesidad de seguir optimizando el modelo.
Conclusión
En este artículo hemos repasado los principales componentes y funcionalidades del framework FinCon, así como sus ventajas para automatizar y optimizar las decisiones comerciales. En la parte práctica, hemos aplicado los enfoques propuestos utilizando herramientas MQL5. Asimismo, hemos construido y entrenado el modelo con datos históricos reales. Sin embargo, los resultados de las pruebas muestran que el modelo requiere una mayor optimización para lograr resultados más estables y mejores.
Enlaces
- FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16937
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso