
Redes neuronales en el trading: Agente con memoria multinivel

Introducción
El creciente volumen de datos financieros exige de los tráders no solo procesarlos con rapidez, sino también analizarlos en profundidad para tomar decisiones precisas y oportunas. Sin embargo, las limitaciones de la memoria humana, la atención y la capacidad de procesar grandes cantidades de información pueden provocar la omisión de eventos críticos o llevar a los tráders a conclusiones erróneas. Y esto conlleva la necesidad de crear agentes de ventas autónomos que puedan integrar eficazmente datos dispares, haciéndolo además rápidamente y con gran precisión. Una de estas soluciones se propone en el artículo "FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design".
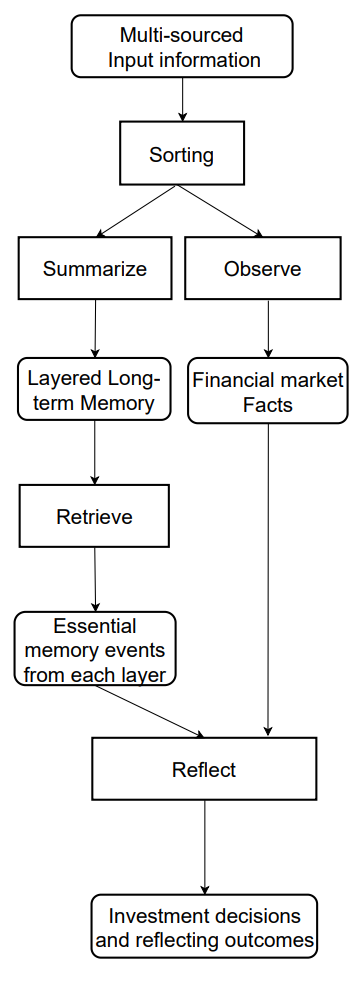
El framework FinMem propuesto es un agente innovador basado en grandes modelos de lenguaje (LLM) que ofrece un sistema de memoria multinivel único. Este enfoque permite gestionar con eficacia datos de distinta naturaleza e importancia temporal. El módulo de memoria de FinMem se divide en memoria de trabajo, diseñada para procesar datos a corto plazo, y memoria estratificada a largo plazo, en la que la información se clasifica según su importancia y relevancia. Por ejemplo, las noticias diarias y las fluctuaciones del mercado a corto plazo se analizan a un nivel superficial, mientras que los informes e investigaciones con repercusiones a largo plazo se canalizan hacia las capas profundas de la memoria. Esta estructura permite al agente priorizar la información centrándose en los datos más relevantes.
El módulo de perfilado FinMem permite adaptar el agente al contexto profesional y a las condiciones del mercado. Considerando las preferencias individuales del usuario y su perfil de riesgo, el agente personaliza su estrategia para garantizar la máxima eficacia. El módulo de toma de decisiones integra los datos actuales del mercado y las memorias almacenadas para generar estrategias bien meditadas. Esto nos permite considerar tanto las tendencias a corto plazo como las pautas a largo plazo. Este enfoque de inspiración cognitiva hace que FinMem sea capaz de recordar y usar los eventos clave del mercado, mejorando la precisión y adaptabilidad de su toma de decisiones.
Los resultados de numerosos experimentos presentados en el trabajo del autor muestran que FinMem supera a otros modelos de comercio autónomo en eficiencia. Incluso entrenando con datos limitados, el agente muestra un rendimiento sobresaliente en el procesamiento de la información y la toma de decisiones de inversión. Con su capacidad única para ajustar la carga cognitiva, FinMem gestiona un gran volumen de eventos sin pérdida de calidad en el análisis. Por ejemplo, puede analizar simultáneamente docenas de señales de mercado independientes, estructurarlas según su importancia y tomar decisiones informadas con limitaciones de tiempo.
Otro aspecto importante de FinMem es su capacidad para aprender y adaptarse a nuevos datos en tiempo real. Esto permite al agente no solo afrontar los retos actuales, sino también mejorar continuamente sus estrategias comerciales respondiendo a los cambios en las condiciones del mercado. Esta combinación de flexibilidad cognitiva y potencia tecnológica hace de FinMem un importante paso adelante en el comercio autónomo. FinMem representa una solución de vanguardia que combina principios cognitivos y tecnología avanzada para navegar con éxito por mercados financieros complejos y volátiles.
La arquitectura FinMem
El framework FinMem incluye tres módulos principales:
- de perfilado;
- de memoria;
- de toma de decisiones.
El módulo de perfilado permite a FinMem desarrollar un carácter de agente dinámico diseñado específicamente para navegar con eficacia por la compleja dinámica de los mercados financieros. La naturaleza dinámica de FinMem implica dos componentes principales: una base de conocimientos profesionales fundamentales similar a la de un experto en trading, y un agente con tres propensiones diferentes al riesgo de inversión.
El primer componente incluye dos tipos de información: una introducción a los principales sectores comerciales pertinentes para la empresa cuyas acciones serán negociadas por FinMem, y un breve resumen de los resultados financieros históricos del ticker especificado, que abarca todo el periodo de estudio. Antes de negociar con las acciones de una nueva empresa, FinMem accede y actualiza estos datos financieros históricos y del sector desde la base de datos del servidor. Esta configuración del conocimiento profesional reduce la información a la memorización de eventos relevantes para tareas de negociación específicas.
El segundo componente del diseño de FinMem incluye tres variantes diferentes de propensión al riesgo:
- búsqueda de riesgo,
- aversión al riesgo,
- naturaleza autoadaptativa del riesgo.
En el modo de búsqueda de riesgo, FinMem se centra en un enfoque agresivo con altos rendimientos, mientras que el modo de aversión al riesgo reorienta el comercio hacia una estrategia conservadora con menos riesgo. Una característica distintiva de FinMem es su capacidad para alternar dinámicamente entre los ajustes de riesgo especificados en respuesta a las condiciones actuales del mercado. En particular, cambia las preferencias de riesgo cuando los rendimientos agregados caen por debajo de cero durante un periodo de tiempo corto. Este diseño flexible funciona como mecanismo de defensa, mitigando las caídas prolongadas en un entorno de mercado turbulento.
En la fase inicial de entrenamiento, FinMem se personaliza con las preferencias de riesgo seleccionadas, cada una de las cuales se complementa con explicaciones textuales detalladas con ayuda de las sugerencias de LLM. Estas directrices definen cómo FinMem procesa los mensajes entrantes y determina sus próximas acciones según la propensión al riesgo asignada. El sistema mantiene un catálogo de todas las propensiones al riesgo y sus explicaciones detalladas, lo cual le permite adaptarse fácilmente a las distintas acciones cambiando entre estos perfiles de riesgo según sea necesario.
La personalización dinámica de símbolos en el módulo de perfiles de FinMem proporciona conocimientos subjetivos y profesionales, así como una selección flexible de la propensión al riesgo. Y esto ofrece un contexto importante para filtrar y extraer la información relacionada con el comercio y los eventos de la memoria, mejorando así la muestra precisa y la adaptabilidad a las condiciones del mercado.
El módulo de memoria FinMem emula el sistema cognitivo de un tráder para procesar eficazmente la información financiera jerarquizada y priorizar los mensajes críticos para tomar decisiones de inversión de alta calidad. También ajusta con flexibilidad la capacidad de memoria, lo cual permite al agente trabajar con una gama más amplia de eventos durante un periodo de recuperación más largo. El módulo de memoria FinMem incluye memoria de trabajo y a largo plazo con capacidad de procesamiento multinivel y se inicia usando una solicitud de inversión específica.
La memoria de trabajo se refiere a las funciones del sistema cognitivo humano para el almacenamiento temporal, así como a una amplia variedad de operaciones. Los autores del framework incorporan este concepto al diseño del módulo de memoria FinMem, creando un espacio de trabajo central para la toma de decisiones informadas. A diferencia de la memoria de trabajo humana, que tiene una capacidad máxima de siete más o menos dos eventos, FinMem puede ampliar su capacidad según las necesidades. La memoria de trabajo de FinMem para traducir los datos financieros a acciones comerciales incluye tres operaciones clave: generalización, observación y reflexión.
FinMem usa datos de mercado externos para ofrecer información crítica sobre inversiones y opiniones adaptadas a solicitudes comerciales específicas de acciones. El sistema comprime el texto de origen en un párrafo compacto pero informativo, aumentando así la eficacia del procesamiento de FinMem. Este extrae y resume eficazmente los datos relevantes y el sentimiento para tomar decisiones de inversión. FinMem dirige posteriormente estas muestras a la capa correspondiente de su arquitectura de memoria a largo plazo, seleccionando la capa según la sensibilidad temporal de la información.
Iniciando la misma solicitud, FinMem inicia una operación de observación para recopilar datos sobre el mercado. La información de que dispone FinMem varía entre las fases de entrenamiento y de prueba. Durante la fase de entrenamiento, FinMem tiene acceso a datos exhaustivos sobre las cotizaciones de las acciones durante un periodo determinado. Tras recibir solicitudes de operaciones que incluyan el ticker y la fecha de la acción, FinMem se centrará en la diferencia diaria ajustada del precio de cierre, comparando el precio del día siguiente con el precio del día actual. Estas diferencias de precios se usan como referencias de mercado. Específicamente, una disminución en el precio indicará una acción de Venta, mientras que un aumento o ningún cambio en el precio indicará una acción de Compra.
Durante la fase de pruebas, en un momento determinado, FinMem pierde la capacidad de acceder a los datos de precios futuros. Su enfoque se desplaza hacia el análisis de los movimientos históricos de las cotizaciones bursátiles, según una evaluación retrospectiva de los rendimientos totales durante el periodo analizado. Esta fase, caracterizada por la falta de fundamentos previsibles del mercado, sirve para evaluar de forma crítica el desarrollo de FinMem. Este comprueba si el sistema ha establecido adecuadamente vínculos lógicos entre la evolución de las cotizaciones bursátiles y diversas fuentes de información financiera, como noticias, informes e indicadores. Esta etapa resulta clave para evaluar la capacidad de FinMem de desarrollar de forma independiente sus estrategias comerciales para tareas posteriores utilizando su análisis e interpretación de los datos históricos.
Existen dos tipos de reacciones: inmediatas y ampliadas. La respuesta inmediata se activa cuando se recibe una solicitud comercial diaria para un determinado ticker. Usando un LLM y señales específicas, el agente combina los indicadores de mercado y los eventos top-K clasificados de cada capa de la memoria a largo plazo. Los indicadores de mercado se derivan de operaciones de observación y varían entre las fases de entrenamiento y prueba. Durante la prueba, este proceso produce tres tipos de resultados: la dirección de la operación ("Comprar", "Vender" o "Mantener"), el fundamento de esa decisión y los eventos de memoria más influyentes y sus identificadores de cada nivel en los que hemos basado la decisión. Durante la fase de aprendizaje, no es necesario especificar la dirección de la operación, ya que FinMem ya está informado de las futuras direcciones de las acciones. Los eventos top-K clasificados encapsulan las muestras y sentimientos clave derivados de los mensajes entrantes críticos relacionadas con la inversión, todo ello resumido por FinMem utilizando funciones avanzadas.
La respuesta ampliada reevalúa los resultados inmediatos de las acciones del agente para un ticker en un intervalo de rastreo concreto. Incluye datos como la evolución de las cotizaciones bursátiles, la rentabilidad de las transacciones y los fundamentos de actuación basados en algunas reflexiones inmediatas. Mientras que la reacción directa permite operar directamente y registrar las reacciones actuales, la reacción ampliada resume las tendencias del mercado y reevalúa los rendimientos acumulados recientes de las inversiones. La reacción ampliada se almacena finalmente en una capa profunda de la memoria a largo plazo para subrayar su carácter esencial.
La memoria a largo plazo de FinMem organiza los datos financieros analíticos jerárquicos en una estructura estratificada. FinMem usa una estructura de memoria multinivel para adaptarse a la diferente sensibilidad temporal inherente a los distintos tipos de datos financieros. Esta estructura clasifica las muestras generalizadas según su carácter oportuno y su velocidad de decaimiento (olvido). Las muestras se generan usando la operación de generalización de la memoria de trabajo. Los eventos dirigidos a capas de memoria más profundas reciben una tasa de decaimiento más baja, lo cual indica una retención más larga, mientras que los datos de capas menos profundas reciben una tasa de decaimiento más alta para una retención más corta. Cada evento de memoria solo puede pertenecer a una capa de memoria.
Tras recibir una solicitud de inversión, FinMem extrae los eventos de memoria top-K clave de cada capa y los dirige al componente de representación directa de la memoria de trabajo. Estos eventos se seleccionan por orden descendente de puntuación; esta incluye tres medidas: novedad, relevancia e importancia. Las puntuaciones métricas individuales superiores a 1,0 se escalan al intervalo [0,1] antes de ser sumadas.
Para una solicitud comercial que llega a la capa tecnológica, mediante una consulta al LLM, el agente calcula una puntuación de novedad que está inversamente correlacionada con el intervalo temporal entre la solicitud y la marca temporal del evento en la memoria, lo que refleja una curva de olvido. El término de estabilidad controla parcialmente la tasa de decaimiento en las distintas capas, lo cual indica una mayor persistencia de la memoria en la capa a largo plazo con un valor de estabilidad más alto. En el contexto del trading, los informes anuales de las empresas se consideran más relevantes que las noticias financieras diarias. Como consecuencia, se les asigna un valor de estabilidad más alto y se clasifican dentro de un nivel de procesamiento más profundo. Esta categorización refleja su amplia relevancia e influencia en los escenarios de decisiones financieras.
La puntuación de relevancia cuantifica la similitud coseno entre los vectores de incorporación. Estos vectores se derivan del contenido textual del evento en la memoria. La consulta alLLM incluye los datos de origen asociados a las solicitudes comerciales y la configuración de los símbolos comerciales.
El módulo de toma de decisiones de FinMem integra eficazmente los resultados operativos de los módulos de perfilado y memoria para respaldar decisiones de inversión fundamentadas. En sus soluciones comerciales diarias, a FinMem se le pide que seleccione una de las tres acciones diferentes para una acción específica utilizando la función de selección de texto: "Comprar", "Vender" o "Mantener". Además, los datos de origen y los resultados necesarios para el módulo de decisión FinMem varían entre las fases de entrenamiento y de prueba.
Durante la fase de entrenamiento, FinMem tiene acceso a una amplia gama de información procedente de múltiples fuentes relevantes para todo el periodo de entrenamiento. Cuando FinMem recibe solicitudes de operaciones que contienen un ticker bursátil y una fecha, así como los textos relacionados con las descripciones de las "personalidades" del tráder, inicia simultáneamente operaciones de observación y resumen en su memoria de trabajo. FinMem observa los marcadores de mercado que incluyen diferencias de precios ajustadas diariamente entre días consecutivos que indican acciones de Compra o Venta. Usando estas señales de cambio de precio, FinMem identifica y prioriza los recuerdos top-K, clasificándolos en función de las puntuaciones de recuperación de cada capa de la memoria a largo plazo. Este procedimiento permite a FinMem crear análisis exhaustivos que posibilitan la corroboración y la muestra en profundidad de la correlación entre las etiquetas de los fundamentos del mercado y las memorias recuperadas. Gracias a las operaciones comerciales repetidas, las reacciones y los eventos de la memoria con un impacto significativo pasan a un nivel más profundo del procesamiento de la memoria almacenado para futuras decisiones de inversión durante la fase de prueba.
En la fase de prueba, cuando FinMem no puede acceder a datos de precios futuros, para predecir las tendencias futuras del mercado este se basa en los rendimientos acumulados en comparación con el periodo analizado. Para compensar la falta de información sobre los precios futuros del mercado, FinMem usa reacciones ampliadas derivadas de las reacciones inmediatas como etiquetas adicionales. Cuando se enfrenta a una solicitud de operación específica, FinMem integra la información procedente de diversas fuentes, incluidos los rendimientos acumulados históricos, los resultados de las reflexiones ampliadas y las memorias top-K recuperadas. Este enfoque integral permite a FinMem tomar decisiones comerciales con conocimiento de causa.
Cabe señalar que FinMem genera acciones ejecutables solo en el módulo de respuesta directa durante la fase de prueba. Como la dirección de las operaciones se centra en la tendencia real de los precios, durante la fase de entrenamiento de FinMem no se toman decisiones de inversión. En cambio, esta fase se dedica a crear experiencia comercial comparando las tendencias del mercado con los mensajes financieros entrantes procedentes de múltiples fuentes. Además, en esta fase FinMem rellena el módulo de memoria enriquecido con una amplia base de conocimientos, desarrollando así sus capacidades para la toma de decisiones independientes en futuras actividades comerciales.
A continuación le mostramos la visualización del framework FinMem por parte del autor.
Implementación con MQL5
Tras considerar los aspectos teóricos del framework FinMem, pasaremos a la implementación de los enfoques propuestos mediante MQL5. Y aquí debemos decir de inmediato que en este caso nuestra implementación probablemente diferirá de la solución del autor todo lo imaginable en comparación con todos los artículos anteriores. En especial, esto se debe al uso de un LLM preentrenado en la solución del autor, que constituye la base del framework. Por consiguiente, tomaremos los enfoques de procesamiento de la información propuestos por los autores del framework y estudiaremos su aplicación desde una perspectiva diferente.
Módulo de memoria
Empezaremos nuestro robot con la construcción de un módulo de memoria. En la implementación del autor del framework FinMem, mediante el uso de LLM, la memoria del Agente se rellena con una descripción textual de la generalización de los eventos recibidos de diferentes fuentes y sus incorporaciones. Sin embargo, no utilizaremos un LLM en nuestra aplicación. Y, como consecuencia, trabajaremos únicamente con información numérica obtenida directamente del terminal.
A continuación, deberemos pensar en construir una memoria multinivel con diferentes tasas de decaimiento en los distintos niveles. Y luego está la cuestión de la priorización de los eventos analizados. Si analizamos únicamente el estado actual del entorno, representado por los datos de la evolución de los precios y diversos indicadores técnicos, resulta bastante difícil determinar las prioridades de los dos próximos estados.
Tras considerar varias opciones, hemos decidido utilizar bloques de recurrencia para organizar los niveles de memoria. Y para emular diferentes tasas de olvido, usaremos diferentes arquitecturas de bloques de recurrencia para niveles de memoria individuales, que poseen diferentes tasas de decaimiento debido a sus decisiones arquitectónicas. Al hacerlo, no priorizaremos artificialmente los distintos estados del entorno. En su lugar, procesaremos los datos de origen por igual en todas las capas de memoria, mientras que sugeriremos al modelo que aprenda las prioridades.
Luego compararemos los datos de distintos niveles de memoria con ayuda del bloque de atención cruzada.
El algoritmo anteriormente propuesto lo construiremos dentro del objeto CNeuronMemory, cuya estructura se presenta a continuación.
class CNeuronMemory : public CNeuronRelativeCrossAttention { protected: CNeuronLSTMOCL cLSTM; CNeuronMambaOCL cMamba; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronMemory(void){}; ~CNeuronMemory(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMemory; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
En nuestra biblioteca, implementaremos 2 bloques de recurrencia: LSTM y Mamba. Los utilizaremos para organizar los niveles de memoria. Para comparar sus resultados, usaremos un módulo de atención cruzada relativa. Sin embargo, para reducir el número de objetos internos de nuestro bloque de atención, usaremos el objeto de atención cruzada como clase padre.
Declararemos los objetos de capas de memoria interna de forma estática, lo que nos permitirá dejar el constructor y el destructor de la clase vacíos, mientras que la inicialización de todos los objetos declarados y heredados, como es habitual, se realizará en el método Init.
bool CNeuronMemory::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, units_count, heads, window, units_count, optimization_type, batch)) return false;
En los parámetros del método, veremos las ya conocidas constantes utilizadas en el método homónimo de la clase padre. Sin embargo, en este caso excluiremos los parámetros de la segunda fuente de datos de origen. Al fin y al cabo, nuestro nuevo objeto trabajará con una única fuente de datos. Y al llamar al método homónimo de la clase padre, repetiremos los valores del flujo de información principal en los parámetros de la segunda fuente de datos.
Una vez ejecutadas con éxito las operaciones del método padre, inicializaremos los objetos de capa de memoria recurrente con parámetros de fuente de datos similares.
if(!cLSTM.Init(0, 0, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cMamba.Init(0, 1, OpenCL, iWindow, 2 * iWindow, iUnits, optimization, iBatch)) return false; //--- return true; }
Y al finalizar el método, retornaremos el resultado lógico de las operaciones del método al programa que realiza la llamada.
En el siguiente paso, construiremos el algoritmo feedForward. Aquí todo resultará bastante sencillo. En los parámetros del método obtendremos el puntero al objeto de datos de origen, que pasaremos a los métodos homónimos de las capas de memoria interna.
bool CNeuronMemory::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cLSTM.FeedForward(NeuronOCL)) return false; if(!cMamba.FeedForward(NeuronOCL)) return false;
Y luego compararemos los resultados de la operación de los objetos recurrentes usando la atención cruzada de la clase padre y devolveremos el resultado lógico de la ejecución de las operaciones al programa que realiza la llamada.
return CNeuronRelativeCrossAttention::feedForward(cMamba.AsObject(), cLSTM.getOutput());
}
El algoritmo calcInputGradients para distribuir gradientes de error será un poco más complicado. Aquí tendremos que transferir el error de los dos flujos de información al nivel del objeto de datos de origen, cuyo puntero obtendremos en los parámetros del método.
bool CNeuronMemory::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
En el cuerpo del método, primero comprobaremos la relevancia del puntero obtenido al objeto de datos de origen. De lo contrario, la transmisión del gradiente de error se hará imposible.
Y en caso de pasar con éxito el bloque de control, distribuiremos el gradiente de error entre las capas de memoria interna usando el objeto padre.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cMamba.AsObject(), cLSTM.getOutput(), cLSTM.getGradient(), (ENUM_ACTIVATION)cLSTM.Activation())) return false;
A continuación, haremos descender primero el gradiente de error a los datos de origen de una capa de memoria.
if(!NeuronOCL.calcHiddenGradients(cMamba.AsObject())) return false;
Y luego sustituiremos el puntero al búfer de gradiente del objeto de datos de origen por un búfer libre y pasaremos los datos a través del segundo flujo de información.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cMamba.getPrevOutput(), false)) return false; if(!NeuronOCL.calcHiddenGradients(cLSTM.AsObject())) return false; if(!NeuronOCL.SetGradient(temp, false) || !SumAndNormilize(temp, cMamba.getPrevOutput(), temp, iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
Ahora solo tendremos que sumar los datos de los dos flujos de información y devolver los punteros a los búferes de datos a sus estados iniciales. Y cuando todas las operaciones se hayan completado, informaremos al programa que realiza la llamada sobre el progreso de las operaciones y finalizaremos el método.
El algoritmo del método updateInputWeights de actualización de los parámetros del modelo no destaca por su complejidad. Así que le sugiero que se familiarice con él por su cuenta. Encontrará el código completo del módulo de memoria presentado y todos sus métodos en el archivo adjunto. Bueno, sigamos adelante.
Creación del framework FinMem
La siguiente etapa de nuestro trabajo consistirá en implementar el algoritmo completo del framework FinMem, que construiremos dentro del objeto CNeuronFinMem. A continuación, le mostraremos la estructura de la nueva clase.
class CNeuronFinMem : public CNeuronRelativeCrossAttention { protected: CNeuronTransposeOCL cTransposeState; CNeuronMemory cMemory[2]; CNeuronRelativeCrossAttention cCrossMemory; CNeuronRelativeCrossAttention cMemoryToAccount; CNeuronRelativeCrossAttention cActionToAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinMem(void) {}; ~CNeuronFinMem(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint accoiunt_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinMem; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Como puede ver, la estructura del nuevo objeto declarará los 2 módulos de memoria presentados anteriormente y varios bloques de atención cruzada. Su propósito, creo, se explorará mejor en la implementación de los algoritmos de los métodos de clase.
Todos los objetos internos se han declarado estáticamente, dejando el constructor y el destructor de la clase vacíos, mientras que la inicialización de todos los objetos declarados y heredados se realizará en el método Init.
Cabe destacar que en este caso estaremos creando un objeto de Agente. Este analizará los datos de origen y retornará un vector de acciones que se reflejará en los parámetros de inicialización del objeto. Por lo tanto, añadiremos a las constantes del método de inicialización la dimensionalidad del vector de descripción del estado de la cuenta (account_descr) y del espacio de acciones (nactions), además de la información habitual sobre el tensor de descripción del estado del entorno.
Además, al simular el funcionamiento del módulo de respuesta ampliado propuesto por los autores del framework FinMem, planeamos usar de forma recurrente información sobre las acciones realizadas previamente por el agente frente a la transición a un nuevo estado del entorno. Por lo tanto, hemos elegido el módulo de atención cruzada como clase principal.
bool CNeuronFinMem::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint account_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, nactions / 2, window_key, 2, heads, window, units_count, optimization_type, batch)) return false;
En el cuerpo del método de inicialización del objeto, como viene siendo tradición, primero llamaremos al método homónimo de la clase padre. Como ya hemos dicho, será un objeto de atención cruzada. En el flujo de información principal, obtendremos el vector de las acciones anteriores del agente, que dividiremos en 2 bloques iguales (presumiblemente los datos de las operaciones de compra y venta). Y en el segundo flujo de información tenemos previsto introducir datos procesados sobre el estado actual del entorno.
Una vez ejecutadas con éxito las operaciones de la clase padre, procederemos a inicializar los objetos recién declarados. Y primero inicializaremos el objeto de transposición de datos de descripción del estado del entorno.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false;
Recordemos que recibiremos como entrada al modelo las descripciones del estado del entorno en cuanto a los vectores que describen barras individuales. La transposición de este tensor nos permitirá realizar el análisis en términos de secuencias unitarias individuales.
Aprovechando la propiedad anterior, utilizaremos dos módulos de memoria para analizar los datos de origen en diferentes proyecciones.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false; index++; if(!cMemory[1].Init(0, index, OpenCL, units_count, window_key, window, heads, optimization, iBatch)) return false;
Agregaremos al bloque de atención cruzada los resultados de los análisis realizados por los módulos de memoria.
index++; if(!cCrossMemory.Init(0, index, OpenCL, window, window_key, units_count, heads, units_count, window, optimization, iBatch)) return false;
El siguiente módulo de atención cruzada enriquecerá la información sobre la descripción del estado del entorno con las ganancias y pérdidas acumuladas del vector del estado de la cuenta. También contendrá la fecha y hora del estado analizado.
index++; if(!cMemoryToAccount.Init(0, index, OpenCL, window, window_key, units_count, heads, account_descr, 1, optimization, iBatch)) return false;
Y al final del método, inicializaremos otro bloque de atención cruzada que comparará las acciones recientes del Agente y el resultado obtenido, reflejado en el estado de cuenta actual.
index++; if(!cActionToAccount.Init(0, index, OpenCL, nactions / 2, window_key, 2, heads, account_descr, 1, optimization, iBatch)) return false; //--- if(!Clear()) return false; //--- return true; }
A continuación, borraremos el estado interno de los objetos recurrentes y devolveremos el resultado lógico de las operaciones al programa que realiza la llamada.
Sin apenas darnos cuenta, hemos alcanzado el final del artículo, pero nuestro trabajo aún no ha terminado. Por hoy nos tomaremos un descanso. En el próximo artículo llevaremos nuestra aplicación a su conclusión lógica y evaluaremos la eficacia de las soluciones aplicadas con datos históricos reales.
Conclusión
En este artículo nos hemos familiarizado con el framework FinMem, que supone una nueva etapa en el desarrollo de sistemas comerciales autónomos. Este sistema combina principios cognitivos y algoritmos avanzados basados en grandes modelos lingüísticos. Su memoria multinivel y su adaptabilidad en tiempo real permiten al agente tomar decisiones de inversión precisas e informadas, incluso en mercados volátiles.
En la parte práctica, hemos comenzado a implementar nuestra propia visión de los enfoques propuestos mediante MQL5, excluyendo el uso del modelo lingüístico. En el próximo artículo llevaremos a su conclusión lógica lo que hemos empezado hoy.
Enlaces
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de la descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16804
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola, interesante artículo. Desafortunadamente no puedo compilar el archivo Research.mq5 - la línea if((!CreateDescriptions(actor, critic, critic))) - Número incorrecto de parámetros. No puedo seguir adelante(
Buenas tardes, ¿Desde qué catálogo se carga el archivo Research? Efectivamente, hay muchos parámetros. En este trabajo sólo se utiliza un modelo.
Buenas tardes, ¿De qué catálogo se descarga el archivo Research? Efectivamente hay muchos parámetros. En este documento sólo se utiliza un modelo.
He mirado en los catálogos y ya me he confundido de donde lo he sacado((
¿Puede indicarme por favor que catálogo utilizar para este trabajo?
En catálogos perezosamente y ya confundido donde tomé((
Por favor, me indique qué catálogo de utilizar para este artículo?
Todos los archivos relacionados con este artículo se encuentran en la carpeta FinMem.
He intentado todo tipo de cosas pero no he llegado a tus resultados.
Lo siento, ¿puede dar instrucciones adecuadas sobre qué ejecutar y qué archivos en qué orden.
Gracias.