
Aprendizaje automático y Data Science (Parte 30): La pareja ideal para predecir el mercado bursátil: redes neuronales convolucionales (CNN) y recurrentes (RNN)

Contenido
- Introducción
- Comprensión de las RNN y las CNN
- La sinergia de las CNN y las RNN
- Extracción de características con CNN
- Modelado temporal con RNN
- Entrenamiento y realización de predicciones
- Una combinación de CNN y LSTM
- Una combinación de CNN y GRU
- Conclusión
Introducción
En los artículos anteriores, hemos visto lo potentes que son tanto las Redes Neuronales Convolucionales (Convolutional Neural Networks, CNN) como las Redes Neuronales Recurrentes (Recurrent Neural Networks, RNN) y cómo pueden desplegarse para ayudar a batir al mercado proporcionándonos valiosas señales de trading.
En este vamos a intentar combinar dos de las técnicas más potentes CNN y RNN y observar su impacto predictivo en el mercado de valores. Pero antes de eso entendamos brevemente qué son CNN y RNN.
Comprensión de las redes neuronales recurrentes (RNN) y las redes neuronales convolucionales (CNN)
Redes neuronales convolucionales (CNN), están diseñados para reconocer patrones y características en los datos, a pesar de haber sido desarrollados originalmente para tareas de reconocimiento de imágenes, funcionan bien en datos tabulares que están diseñados específicamente para el pronóstico de series de tiempo.
Como se dijo en los artículos anteriores, funcionan primero aplicando filtros a los datos de entrada y luego extraen características de alto nivel que pueden ser útiles para la predicción. En los datos del mercado de valores, estas características incluyen tendencias, efectos estacionales y anomalías.

Arquitectura CNN
Al aprovechar la naturaleza jerárquica de las CNN, podemos descubrir capas de representaciones de datos, cada una de las cuales proporciona información sobre diferentes aspectos del mercado.
Redes neuronales recurrentes (RNN) Son redes neuronales artificiales diseñadas para reconocer patrones en secuencias de datos, como series de tiempo, idiomas o vídeos.
A diferencia de lo tradicional (redes neuronales), que suponen que las entradas son independientes entre sí, las RNN pueden detectar y comprender patrones a partir de una secuencia de datos (información).
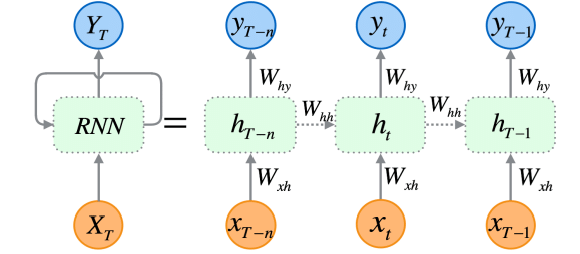
Las RNN están diseñadas explícitamente para datos secuenciales. Su arquitectura les permite mantener una memoria de entradas anteriores, lo que las hace muy adecuadas para el pronóstico de series de tiempo, ya que son capaces de comprender las dependencias temporales dentro de los datos, lo cual es crucial para hacer predicciones precisas en el mercado de valores.
Como expliqué en la Parte 25 de esta serie de artículos, hay tres tipos (de uso común) específicos de RNN que incluyen una red neuronal recurrente (RNN) convencional, una memoria a corto y largo plazo (LSTM) y una unidad recurrente cerrada (GRU).
Dado que las CNN son excelentes para extraer y detectar características de los datos, las RNN son excepcionales para interpretar estas características a lo largo del tiempo. La idea es simple: combinar ambos y ver si podemos construir un modelo poderoso y robusto capaz de hacer mejores predicciones en el mercado de valores.
La sinergia de las CNN y las RNN
Para integrar estos dos, vamos a crear los modelos en tres pasos.
- Extracción de características con CNN
- Modelado temporal con RNN
- Entrenamiento y obtención de predicciones
Vayamos paso a paso y construyamos este modelo robusto compuesto de RNN y LSTM.
01: Extracción de características con CNN
Este primer paso implica introducir los datos de series de tiempo en un modelo CNN, el modelo CNN procesa los datos, identifica patrones significativos y extrae características relevantes.
Utilizando el conjunto de datos de acciones de Tesla que consta de valores de apertura, máximo, mínimo y cierre. Comencemos por preparar los datos en un formato de serie temporal 3D aceptable para CNN y RNN.
Creemos la variable objetivo para un problema de clasificación.
Código Python
target_var = [] open_price = new_df["Open"] close_price = new_df["Close"] for i in range(len(open_price)): if close_price[i] > open_price[i]: # Closing price is greater than opening price target_var.append(1) # buy signal else: target_var.append(0) # sell signal
Normalizamos los datos utilizando el escalador estándar para hacerlos robustos a efectos de ML.
X = new_df.iloc[:, :-1] y = target_var # Scalling the data scaler = StandardScaler() X = scaler.fit_transform(X) # Train-test split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) print(f"x_train = {X_train.shape} - x_test = {X_test.shape}\n\ny_train = {len(y_train)} - y_test = {len(y_test)}")
Salidas
x_train = (799, 3) - x_test = (200, 3) y_train = 799 - y_test = 200
Luego podemos preparar los datos en formato de series de tiempo.
# creating the sequence
X_train, y_train = create_sequences(X_train, y_train, time_step)
X_test, y_test = create_sequences(X_test, y_test, time_step) Como se trata de un problema de clasificación, codificamos la variable objetivo.
from tensorflow.keras.utils import to_categorical
y_train_encoded = to_categorical(y_train)
y_test_encoded = to_categorical(y_test)
print(f"One hot encoded\n\ny_train {y_train_encoded.shape}\ny_test {y_test_encoded.shape}") Salidas
One hot encoded y_train (794, 2) y_test (195, 2)
La extracción de características la realiza el propio modelo CNN. Vamos a darle al modelo los datos sin procesar que acabamos de preparar.
model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2))
02: Modelado temporal con RNN
Las características extraídas en el paso anterior se pasan luego al modelo RNN. El modelo procesa estas características, considerando el orden temporal y las dependencias dentro de los datos.
A diferencia de la arquitectura del modelo CNN que usamos en la parte 27 de esta serie de artículos, donde utilizamos capas de red neuronal totalmente conectadas justo después de la capa Flatten. Esta vez reemplazamos esas capas de red neuronal (NN) tradicionales por capas de red neuronal recurrente (RNN).
Sin olvidar eliminar la "capa Flatten" que aparece en la imagen de la arquitectura CNN.
Eliminamos la capa Flatten en la arquitectura CNN porque esta capa se usa normalmente para convertir una entrada 3D en una salida 2D, mientras que las RNNs (RNN, LSTM y GRU) esperan datos de entrada en 3D con el formato (tamaño del lote, pasos de tiempo, características).
model.add(MaxPooling1D(pool_size=2)) model.add(SimpleRNN(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # Softmax for binary classification (1 buy, 0 sell signal)
03: Entrenamiento y obtención de predicciones
Finalmente, podemos proceder a entrenar el modelo que construimos en los dos pasos anteriores, después de eso, lo validamos, medimos su desempeño y luego obtenemos las predicciones.
Código Python
model.summary()
# Compile the model
optimizer = Adam(learning_rate=0.0001)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
history = model.fit(X_train, y_train_encoded, epochs=1000, batch_size=16, validation_split=0.2, callbacks=[early_stopping])
plt.figure(figsize=(7.5, 6))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.legend()
plt.savefig("training loss curve-rnn-cnn-clf.png")
plt.show()
# Evaluating the Trained Model
y_pred = model.predict(X_test)
classes_in_y = np.unique(y)
y_pred_binary = classes_in_y[np.argmax(y_pred, axis=1)]
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix RNN + CNN.png") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) Salidas
Después de evaluar el modelo después de 14 épocas, el modelo tuvo una precisión del 54% en los datos de prueba.

7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step Classification Report precision recall f1-score support 0 0.70 0.40 0.51 117 1 0.45 0.74 0.56 78 accuracy 0.54 195 macro avg 0.58 0.57 0.54 195 weighted avg 0.60 0.54 0.53 195
Vale la pena mencionar que el entrenamiento del modelo final tomó algo de tiempo cuando se agregaron más capas, esto se debe a la naturaleza compleja de los dos modelos que combinamos.
Después del entrenamiento, tuve que guardar el modelo final en formato ONNX.
Código Python
onnx_file_name = "rnn+cnn.TSLA.D1.onnx" spec = (tf.TensorSpec((None, time_step, X_train.shape[2]), tf.float16, name="input"),) model.output_names = ['outputs'] onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13) # Save the ONNX model to a file with open(onnx_file_name, "wb") as f: f.write(onnx_model.SerializeToString())
Sin olvidar guardar también los parámetros del escalador de estandarización.
# Save the mean and scale parameters to binary files scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin") scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
He abierto el modelo ONNX guardado en Netron, es enorme.

De forma similar a como implementamos anteriormente la Red Neuronal Convolucional (CNN), podemos usar la misma biblioteca para ayudarnos con la tarea de leer este modelo masivo sin esfuerzo en MQL5.
#include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler; //from preprocessing.mqh
Pero, antes de eso, tenemos que agregar el modelo ONNX y los parámetros del escalador de estandarización a nuestro Asesor Experto como recursos.
#resource "\\Files\\rnn+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[]
Lo primero que tenemos que hacer dentro de la función OnInit es inicializar ambos (el escalador de estandarización y el modelo CNN).
int OnInit() { //--- if (!cnn.Init(onnx_model)) //Initialize the Convolutional neural network return INIT_FAILED; scaler = new StandardizationScaler(standardization_mean, standardization_std); //Initialize the saved scaler by populating it with values ... ... return (INIT_SUCCEEDED); }
Para obtener las predicciones, tenemos que normalizar los datos de entrada utilizando este escalador precargado, luego aplicamos los datos normalizados al modelo CNN y obtenemos la señal y las probabilidades previstas.
if (NewBar()) //Trade at the opening of a new candle { CopyRates(Symbol(), PERIOD_D1, 1, time_step, rates); for (ulong i=0; i<x_data.Rows(); i++) { x_data[i][0] = rates[i].open; x_data[i][1] = rates[i].high; x_data[i][2] = rates[i].low; } //--- x_data = scaler.transform(x_data); //Normalize the data int signal = cnn.predict_bin(x_data, classes_in_data_); //getting a trading signal from the RNN model vector probabilities = cnn.predict_proba(x_data); //probability for each class Comment("Probability = ",probabilities,"\nSignal = ",signal);
A continuación se muestra cómo se ve el comentario en el gráfico.

El vector de probabilidad depende de las clases que estaban presentes en la variable objetivo de sus datos de entrenamiento. A partir de los datos de entrenamiento, preparamos la variable objetivo para indicar 0 para una señal de venta y 1 para una señal de compra. Los identificadores o números de clase deben estar en orden ascendente.
input int time_step = 5; input int magic_number = 24092024; input int slippage = 100; MqlRates rates[]; matrix x_data(time_step, 3); //3 columns for open, high and low vector classes_in_data_ = {0, 1}; //unique target variables as they are in the target variable in your training data int OldNumBars = 0; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //---
La matriz llamada x\_data es la encargada del almacenamiento temporal de las variables independientes (características) del mercado. Esta matriz se redimensiona a 3 columnas ya que entrenamos el modelo con 3 características (Apertura, Máximo y Mínimo), y se ajusta en número de filas al valor de los pasos de tiempo.
El valor del paso de tiempo debe ser similar al utilizado para crear datos de entrenamiento secuencial.
Podemos elaborar una estrategia sencilla basándonos en las señales que nos proporciona el modelo que hemos construido.
double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { ClosePos(POSITION_TYPE_SELL); //close sell trades when the signal is buy if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions { if (!m_trade.Buy(min_lot, Symbol(), ticks.ask, 0 , 0)) //Open a buy trade printf("Failed to open a buy position err=%d",GetLastError()); } } else if (signal==0) //Bearish signal { ClosePos(POSITION_TYPE_BUY); //close all buy trades when the signal is sell if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions { if (!m_trade.Sell(min_lot, Symbol(), ticks.bid, 0 , 0)) //open a sell trade printf("Failed to open a sell position err=%d",GetLastError()); } } else //There was an error return;
Ahora que tenemos el modelo cargado y listo para hacer predicciones, ejecuté una prueba desde el 01/01/2020 hasta el 01/09/2024. A continuación se muestra la imagen de configuración completa del probador.
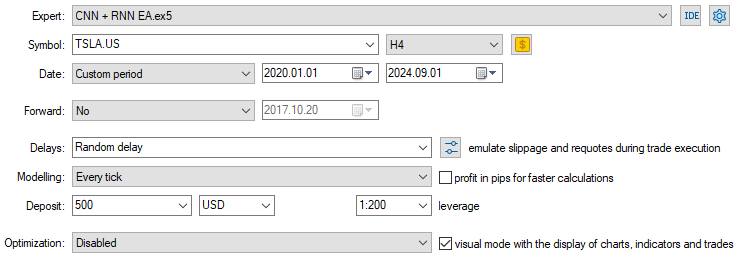
Tenga en cuenta que apliqué el EA en un gráfico de 4 horas, en lugar del marco de tiempo diario del que se recopilaron los datos de las acciones de Tesla. Esto se debe a que programamos la estrategia y los modelos para que entren en acción un instante después de que se abra la nueva vela, pero la vela diaria generalmente se abre cuando el mercado está cerrado, lo que provoca que el EA pierda operaciones hasta el día siguiente.
Al aplicar el EA a un marco de tiempo inferior (marco de tiempo de 4 horas en este caso), nos aseguramos de monitorear continuamente el mercado cada 4 horas y realizar algunas actividades comerciales.
Esto no afecta los datos proporcionados al EA, ya que aplicamos la función CopyRates al marco de tiempo diario (las decisiones comerciales aún dependen del gráfico diario).
A continuación se muestra el resultado del probador.
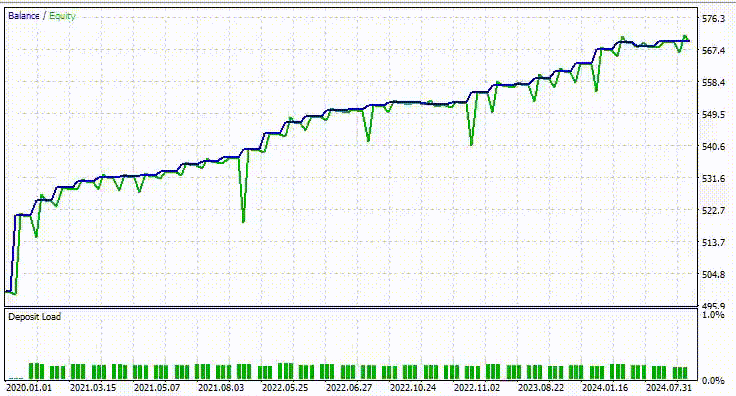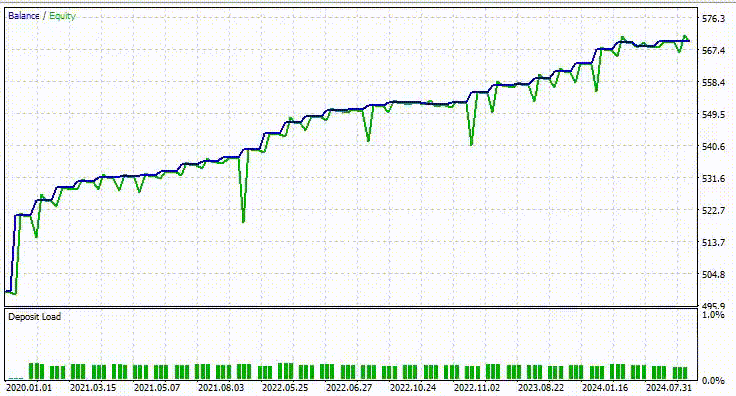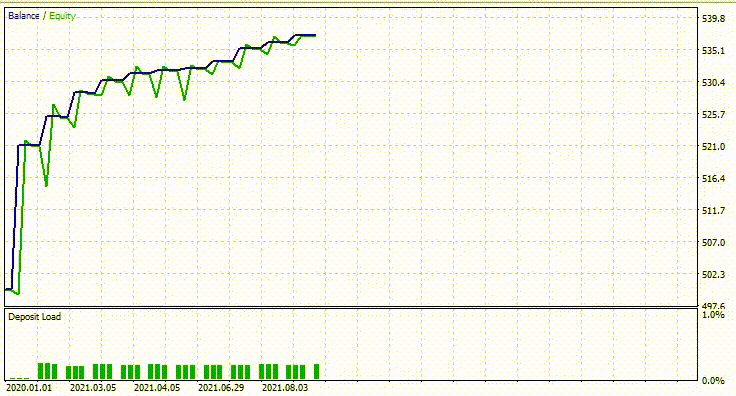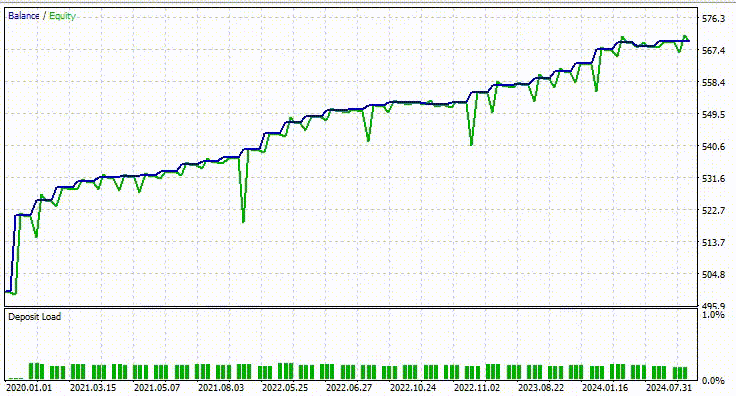
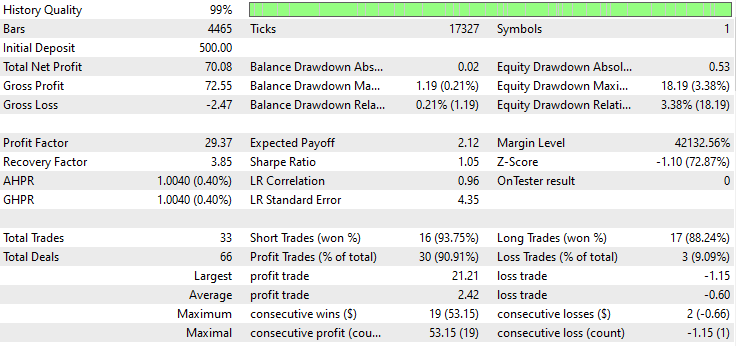
¡Impresionante! El EA produjo un 90% de operaciones rentables. El modelo de IA era simplemente una RNN simple.
Ahora veamos qué tan bien se desempeñan LSTM y GRU en el mismo mercado.
Una combinación de red neuronal convolucional (CNN) y memoria a largo plazo (LSTM)
A diferencia de la RNN simple, que es incapaz de comprender patrones dentro de largas secuencias de datos o información, la LSTM puede comprender relaciones y patrones en largas secuencias de información.
Los LSTM suelen ser más eficientes y precisos que las RNN simples. Creemos un modelo CNN con LSTM en él y luego observemos cómo le va en las acciones de Tesla.
Código Python
from tensorflow.keras.layers import LSTM # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(LSTM(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
Como todas las RNN se pueden implementar de la misma manera, tuve que hacer solo un cambio en el bloque de código utilizado para crear una RNN simple.
Después de entrenar y validar el modelo, su precisión fue del 53% en los datos de prueba.
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 36ms/step Classification Report precision recall f1-score support 0 0.67 0.44 0.53 117 1 0.45 0.68 0.54 78 accuracy 0.53 195 macro avg 0.56 0.56 0.53 195 weighted avg 0.58 0.53 0.53 195
En el lenguaje de programación MQL5, podemos utilizar la misma biblioteca que usamos para el EA RNN simple.
#resource "\\Files\\lstm+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
El resto del código se mantiene igual que en el EA CNN + RNN.
Utilicé la misma configuración del probador que antes, a continuación se muestra el resultado.
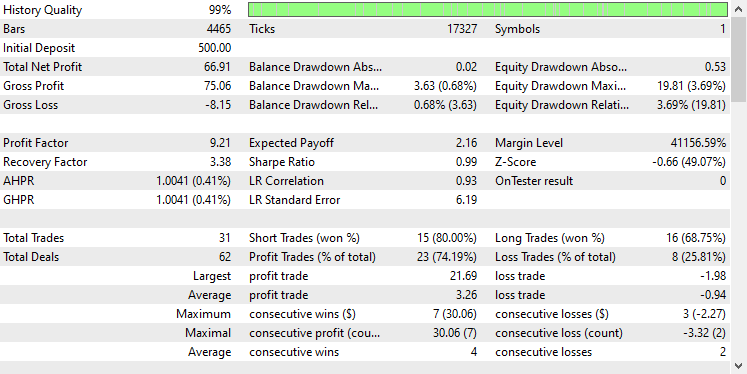
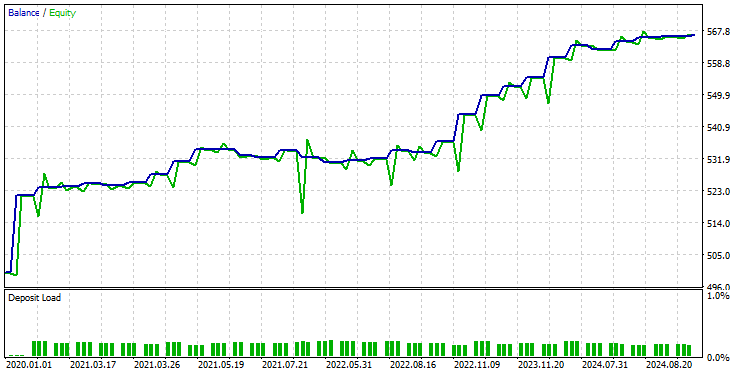
En esta ocasión, la precisión global de las operaciones es de aproximadamente el 74%, un porcentaje inferior al del modelo anterior, pero que sigue siendo sobresaliente.
Una combinación de Red Neuronal Convolucional (CNN) y Unidad Recurrente GRU
Al igual que el LSTM, los modelos GRU también son capaces de comprender las relaciones entre largas secuencias de información y datos a pesar de tener un enfoque minimalista en comparación con el del modelo LSTM.
Podemos implementarlo de la misma manera que otros modelos RNN, solo hacemos el cambio en el tipo de modelo en el código para construir la arquitectura del modelo CNN.
from tensorflow.keras.layers import GRU # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(GRU(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
Después de entrenar y validar el modelo, éste logró una precisión similar a la de LSTM, un 53% de precisión en los datos de prueba.
7/7 ━━━━━━━━━━━━━━━━━━━━ 1s 41ms/step Classification Report precision recall f1-score support 0 0.69 0.39 0.50 117 1 0.45 0.73 0.55 78 accuracy 0.53 195 macro avg 0.57 0.56 0.53 195 weighted avg 0.59 0.53 0.52 195
Cargamos el modelo GRU en formato ONNX y sus parámetros escaladores en archivos binarios.
#resource "\\Files\\gru+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
Nuevamente el resto del código es el mismo que el utilizado en el EA RNN simple.
Tras probar el modelo en el probador con la misma configuración, el resultado fue el siguiente.
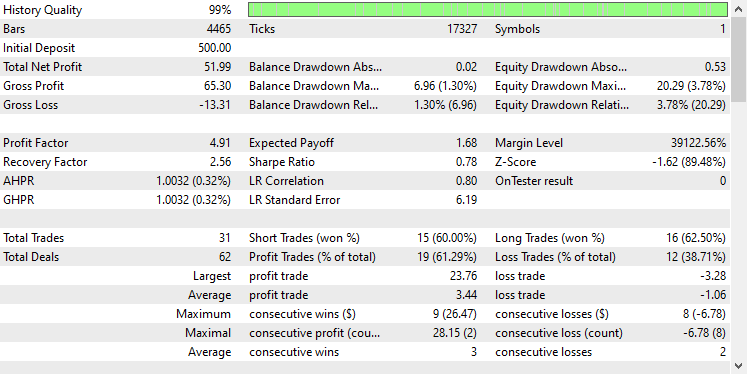
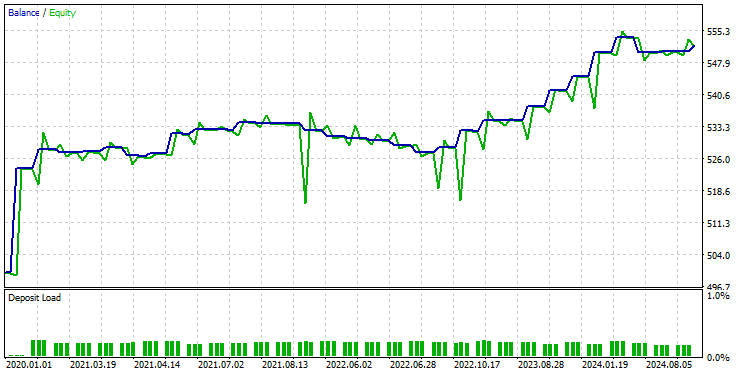
El modelo GRU proporcionó una precisión de aproximadamente el 61%, no tan buena como la de los dos modelos anteriores, pero una precisión decente.
Reflexiones finales
La integración de redes neuronales convolucionales (CNN) con redes neuronales recurrentes (RNN) puede ser un enfoque poderoso para la predicción del mercado de valores, ofreciendo el potencial de descubrir patrones ocultos y dependencias temporales en los datos. Sin embargo, esta combinación es relativamente poco común y conlleva ciertos desafíos. Uno de los riesgos principales es el sobreajuste, especialmente cuando se aplican modelos tan sofisticados a problemas relativamente simples. El sobreajuste puede provocar que el modelo funcione bien con datos de entrenamiento pero no pueda generalizarse a datos nuevos.
Además, la complejidad de combinar CNN y RNN genera costos computacionales significativos, en particular si se decide ampliar el modelo agregando capas más densas o aumentando el número de neuronas. Es esencial equilibrar cuidadosamente la complejidad del modelo con los recursos disponibles y el problema en cuestión.
Paz.
Sigue el desarrollo de modelos de aprendizaje automático y mucho más de lo tratado en esta serie de artículos en este repositorio de GitHub.
Tabla de archivos adjuntos
Nombre del archivo | Tipo de archivo | Descripción y uso |
|---|---|---|
Experts\CNN + GRU EA.mq5 Experts\CNN + LSTM EA.mq5 Experts\CNN + RNN EA.mq5 | Asesores expertos | Robot comercial para cargar los modelos ONNX y probar la estrategia comercial en MetaTrader 5. |
ConvNet.mqh preprocessing.mqh | Archivos de inclusión |
|
Files\ *.onnx | Modelos ONNX | Modelos de aprendizaje automático analizados en este artículo en formato ONNX |
| Files\*.bin | Archivos binarios | Archivos binarios para cargar parámetros del escalador de estandarización para cada modelo |
Jupyter Notebook\cnns-rnns.ipynb | Python/Jupyter notebook | Todo el código Python analizado en este artículo se puede encontrar dentro de este cuaderno. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/15585
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.


- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso