
行列ユーティリティ - 行列とベクトルの標準ライブラリの機能を拡張する

「完璧には決して到達できません。なぜなら、常に改善の余地があるからです。
しかし、完璧になるまでの道程で、より良くなることを学ぶのです。」
はじめに
Pythonでは、Utilsクラスは、クラスのインスタンスを作成せずに再利用できる関数とコード行を持つ汎用ユーティリティクラスです。
行列の標準ライブラリは行列の初期化、変換、操作などの非常に重要な機能とメソッドを提供してくれますが、他のライブラリと同様に、アプリケーションで必要とされる追加機能を実行するために拡張することができます。
以下に紹介する関数とメソッドは順不同です。
内容
- CSVファイルから行列を読み込む
- CSVファイルからエンコード値を読み込む
- CSVファイルに行列を書き込む
- 行列をベクトルに変換する
- ベクトルを行列に変換する
- 配列をベクトルに変換する
- ベクトルを配列に変換する
- 行列から1列を削除する
- 行列から複数の列を削除する
- 行列から1行を削除する
- ベクトルから単一の値を削除する
- 行列を訓練行列とテスト行列に分割する
- XY行列分割
- 計画行列を作成する
- ワンホットエンコーディング行列
- ベクトルからクラスを取得する
- 乱数値のベクトルを作成する
- ベクトルを他のベクトルに加算する
- ベクトルをベクトルにコピーする
CSVファイルから行列を読み込む
CSVファイルからデータベースを読み込み、行列に格納することが難なくできるため、非常に重要な関数です。なぜなら、取引システムのコーディングの過程で、取引シグナルや取引履歴を含むCSVファイルを読み込んでプログラムにアクセスさせる必要があることは多いからです。
この関数の最初のステップは,CSVファイルを読み込むことです.CSVファイルの最初の行は文字列のみであると仮定されており、たとえ最初の行に値があったとしても,行列には文字列値が含まれないため、最初の行の値は代わりにcsv_header配列に格納されます。while(!FileIsEnding(handle)) { string data = FileReadString(handle); //--- if(rows ==0) { ArrayResize(csv_header,column+1); csv_header[column] = data; } if(rows>0) //Avoid the first column which contains the column's header mat_[rows-1,column] = (double(data)); column++; //---
この配列は、先ほど読み込んだCSVファイルの列名を記録しておくのに役立ちます。
以下が完全なコードです。
matrix CMatrixutils::ReadCsv(string file_name,string delimiter=",") { matrix mat_ = {}; int rows_total=0; int handle = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,delimiter); ResetLastError(); if(handle == INVALID_HANDLE) { printf("Invalid %s handle Error %d ",file_name,GetLastError()); Print(GetLastError()==0?" TIP | File Might be in use Somewhere else or in another Directory":""); } else { int column = 0, rows=0; while(!FileIsEnding(handle)) { string data = FileReadString(handle); //--- if(rows ==0) { ArrayResize(csv_header,column+1); csv_header[column] = data; } if(rows>0) //Avoid the first column which contains the column's header mat_[rows-1,column] = (double(data)); column++; //--- if(FileIsLineEnding(handle)) { rows++; mat_.Resize(rows,column); column = 0; } } rows_total = rows; FileClose(handle); } mat_.Resize(rows_total-1,mat_.Cols()); return(mat_); }
以下が使用法です。
以下は、行列に読み込みたいCSVファイルです。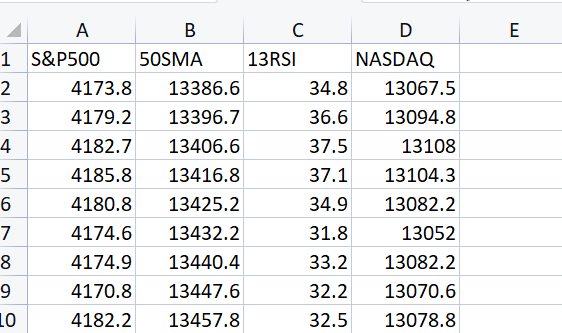
CSVファイルを行列に読み込みます。
Print("---> Reading a CSV file to Matrix\n"); Matrix = matrix_utils.ReadCsv("NASDAQ_DATA.csv"); ArrayPrint(matrix_utils.csv_header); Print(Matrix);出力
CS 0 06:48:21.228 matrix test (EURUSD,H1) "S&P500" "50SMA" "13RSI" "NASDAQ" CS 0 06:48:21.228 matrix test (EURUSD,H1) [[4173.8,13386.6,34.8,13067.5] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4179.2,13396.7,36.6,13094.8] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4182.7,13406.6,37.5,13108] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4185.8,13416.8,37.1,13104.3] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4180.8,13425.2,34.9,13082.2] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4174.6,13432.2,31.8,13052] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4174.9,13440.4,33.2,13082.2] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4170.8,13447.6,32.2,13070.6] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4182.2,13457.8,32.5,13078.8]
この関数を作ろうと思ったのは、標準ライブラリからCSVファイルを読み込む方法が見つからなかったからです。ファイルからCSVに値を読み込む方法として使用することにします(Matrix.FromFile())。

どなたかドキュメントからその方法をご存知の方がいらっしゃいましたら、本稿のディスカッションセクションでお知らせください。
CSVファイルからエンコードされた値を読み取る
しばしば、文字列値を含むCSVファイルを読み込む必要があるかもしれません。このような文字列を含むCSVファイルは、分類アルゴリズムを作ろうとするときによく遭遇します。人気高い気象データセットをご覧ください。

この CSVファイルをエンコードするために、そのデータをすべて単一の文字列配列に読み込むことになります。行列は文字列の値を扱うことができないからです。ReadCsvEncode()関数の内部でまずおこなわなければならないことは、与えられた CSVファイルの列を知ることです。次に、これらの列を反復処理し、各反復でcsvが開かれ、単一の列が完全に読み取られ、その列の値がすべての値の配列(toArr[])に格納されます。
//--- Obtaining the columns matrix Matrix={}; //--- Loading the entire Matrix to an Array int csv_columns=0, rows_total=0; int handle = CSVOpen(file_name,delimiter); if (handle != INVALID_HANDLE) { while (!FileIsEnding(handle)) { string data = FileReadString(handle); csv_columns++; //--- if (FileIsLineEnding(handle)) break; } } FileClose(handle); ArrayResize(csv_header,csv_columns); //--- string toArr[]; int counter=0; for (int i=0; i<csv_columns; i++) { if ((handle = CSVOpen(file_name,delimiter)) != INVALID_HANDLE) { int column = 0, rows=0; while (!FileIsEnding(handle)) { string data = FileReadString(handle); column++; //--- if (column==i+1) { if (rows>=1) //Avoid the first column which contains the column's header { counter++; ArrayResize(toArr,counter); //array size for all the columns toArr[counter-1]=data; } else csv_header[column-1] = data; } //--- if (FileIsLineEnding(handle)) { rows++; column = 0; } } rows_total += rows-1; } FileClose(handle); } //---
これが終わってtoArr[]を出力すると次のようになります。
CS 0 06:00:15.952 matrix test (US500,D1) [ 0] "Sunny" "Sunny" "Overcast" "Rain" "Rain" "Rain" "Overcast" "Sunny" "Sunny" "Rain" "Sunny" "Overcast" CS 0 06:00:15.952 matrix test (US500,D1) [12] "Overcast" "Rain" "Hot" "Hot" "Hot" "Mild" "Cool" "Cool" "Cool" "Mild" "Cool" "Mild" CS 0 06:00:15.952 matrix test (US500,D1) [24] "Mild" "Mild" "Hot" "Mild" "High" "High" "High" "High" "Normal" "Normal" "Normal" "High" CS 0 06:00:15.952 matrix test (US500,D1) [36] "Normal" "Normal" "Normal" "High" "Normal" "High" "Weak" "Strong" "Weak" "Weak" "Weak" "Strong" CS 0 06:00:15.952 matrix test (US500,D1) [48] "Strong" "Weak" "Weak" "Weak" "Strong" "Strong" "Weak" "Strong" "No" "No" "Yes" "Yes" CS 0 06:00:15.952 matrix test (US500,D1) [60] "Yes" "No" "Yes" "No" "Yes" "Yes" "Yes" "Yes" "Yes" "No"
この配列に注目すると、インデックス0から13までが1列目、インデックス14から27までが2列目というように、CSVファイルから取得した値が順番に並んでいることにお気づきだと思います。あとはそこから値を取り出してエンコードし、最終的に行列に格納するのは簡単です。
ulong mat_cols = 0,mat_rows = 0; if (ArraySize(toArr) % csv_columns !=0) printf("This CSV file named %s has unequal number of columns = %d and rows %d Its size = %d",file_name,csv_columns,ArraySize(toArr) / csv_columns,ArraySize(toArr)); else //preparing the number of columns and rows that out matrix needs { mat_cols = (ulong)csv_columns; mat_rows = (ulong)ArraySize(toArr)/mat_cols; } //--- Encoding the CSV Matrix.Resize(mat_rows,mat_cols); //--- string Arr[]; //temporary array to carry the values of a single column int start =0; vector v = {}; for (ulong j=0; j<mat_cols; j++) { ArrayCopy(Arr,toArr,0,start,(int)mat_rows); v = LabelEncoder(Arr); Matrix.Col(v, j); start += (int)mat_rows; } return (Matrix);
LabelEncoder()関数はその名の通り、列配列の中の似たような特徴に同じラベルを貼るものです。
vector CMatrixutils::LabelEncoder(string &Arr[]) { string classes[]; vector Encoded((ulong)ArraySize(Arr)); Classes(Arr,classes); for (ulong A=0; A<classes.Size(); A++) for (ulong i=0; i<Encoded.Size(); i++) { if (classes[A] == Arr[i]) Encoded[i] = (int)A; } return Encoded; }
この関数は簡単なもので、配列全体に対して与えられたクラスを反復処理して、類似した特徴を見つけ、それらにラベルを付けます。作業の大部分は、黒で強調表示されたClasses()関数内で行われます。
void CMatrixutils::Classes(const string &Array[],string &classes_arr[]) { string temp_arr[]; ArrayResize(classes_arr,1); ArrayCopy(temp_arr,Array); classes_arr[0] = Array[0]; for(int i=0, count =1; i<ArraySize(Array); i++) //counting the different neighbors { for(int j=0; j<ArraySize(Array); j++) { if(Array[i] == temp_arr[j] && temp_arr[j] != "nan") { bool count_ready = false; for(int n=0; n<ArraySize(classes_arr); n++) if(Array[i] == classes_arr[n]) count_ready = true; if(!count_ready) { count++; ArrayResize(classes_arr,count); classes_arr[count-1] = Array[i]; temp_arr[j] = "nan"; //modify so that it can no more be counted } else break; //Print("t vectors vector ",v); } else continue; } } }
この関数は、与えられた配列に存在するクラスを取得し、参照される配列classes_arr[]に渡します。 この関数には、代わりにベクトル内のクラスを見つけるための変形があります。この関数の詳細については、こちらをご覧ください。
vector CMatrixutils::Classes(vector &v)
この関数の使用方法は次の通りです。
Matrix = matrix_utils.ReadCsvEncode("weather dataset.csv"); ArrayPrint(matrix_utils.csv_header); Print(Matrix);
出力
CS 0 06:35:10.798 matrix test (US500,D1) "Outlook" "Temperature" "Humidity" "Wind" "Play" CS 0 06:35:10.798 matrix test (US500,D1) [[0,0,0,0,0] CS 0 06:35:10.798 matrix test (US500,D1) [0,0,0,1,0] CS 0 06:35:10.798 matrix test (US500,D1) [1,0,0,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,1,0,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,2,1,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,2,1,1,0] CS 0 06:35:10.798 matrix test (US500,D1) [1,2,1,1,1] CS 0 06:35:10.798 matrix test (US500,D1) [0,1,0,0,0] CS 0 06:35:10.798 matrix test (US500,D1) [0,2,1,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,1,1,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [0,1,1,1,1] CS 0 06:35:10.798 matrix test (US500,D1) [1,1,0,1,1] CS 0 06:35:10.798 matrix test (US500,D1) [1,0,1,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,1,0,1,0]]
CSVファイルに行列を書き込む
これも重要な関数で、行列に新しい列が追加されるたびにハードコードすることなく、行列をCSVファイルに書き出すのに役立ちます。CSVファイルに柔軟に書き込めるようにすることは、フォーラムで多くの人が苦労してきたことです(投稿1、投稿2、投稿3)。ここでは、行列を使った方法を紹介します。row = Matrix.Row(i); for(ulong j=0, cols =1; j<row.Size(); j++, cols++) { concstring += (string)NormalizeDouble(row[j],digits) + (cols == Matrix.Cols() ? "" : ","); }
これは、最終的には、手動で異なる列で書かれたCSVファイルと同じように見えます。行列は文字列の値を運ぶことができないので、このcsvファイルにヘッダーを書き込むために、文字列の配列を使う必要がありました。
CSVファイルから取り出したこの行列を、新しいCSVファイルに書き戻してみましょう。
string csv_name = "matrix CSV.csv"; Print("\n---> Writing a Matrix to a CSV File > ",csv_name); string header[4] = {"S&P500","SMA","RSI","NASDAQ"}; matrix_utils.WriteCsv(csv_name,Matrix,header);
以下は、新しく書き込んだCSVファイルです。

いいですね。
行列をベクトルに変換する
なぜ行列をベクトルに変換するのか、という疑問を持つ人がいるかもしれません。例えば、CSVファイルから行列を読み込んで線形回帰モデルを作成する場合、独立変数はnx1または1xnの行列になりますが、MSEなどの損失関数を使用する場合、行列を使用してモデルを評価することはできず、この独立変数のベクトルとモデルによる予測値のベクトルが使用されます。
そのコードは次のとおりです。
vector CMatrixutils::MatrixToVector(const matrix &mat) { vector v = {}; if (!v.Assign(mat)) Print("Failed to turn the matrix to a vector"); return(v); }
以下が使用法です。
matrix mat = { {1,2,3}, {4,5,6}, {7,8,9} }; Print("\nMatrix to play with\n",mat,"\n"); //--- Print("---> Matrix to Vector"); vector vec = matrix_utils.MatrixToVector(mat); Print(vec);
以下が出力です。
2022.12.20 05:39:00.286 matrix test (US500,D1) ---> Matrix to Vector 2022.12.20 05:39:00.286 matrix test (US500,D1) [1,2,3,4,5,6,7,8,9]
ベクトルを行列に変換する
先ほどの関数とは正反対ですが、これが想像以上に重要です。独立変数はベクトルで格納されることが多いので、演算をおこなうためにnx1の行列に変換する必要があるかもしれません。この2つの逆関数は、既存の変数に手を加えることでより少ない変数のコードを作るために重要です。
matrix CMatrixutils::VectorToMatrix(const vector &v) { matrix mat = {}; if (!mat.Assign(v)) Print("Failed to turn the vector to a 1xn matrix"); return(mat); }
以下が使用法です。
Print("\n---> Vector ",vec," to Matrix"); mat = matrix_utils.VectorToMatrix(vec); Print(mat);
以下が出力です。
2022.12.20 05:50:05.680 matrix test (US500,D1) ---> Vector [1,2,3,4,5,6,7,8,9] to Matrix 2022.12.20 05:50:05.680 matrix test (US500,D1) [[1,2,3,4,5,6,7,8,9]]
配列をベクトルに変換する
機械学習プログラムの内部に多くの配列が必要な方はいらっしゃいますか。配列はとても便利なものですが、サイズにとても敏感です。非常に頻繁に調整していじると、範囲外エラーでチャートから外れて、ターミナルがプログラムをチャートから除外する助けになってしまう可能性があります。 ベクトルは同じことをおこないますが、配列より柔軟です。オブジェクト指向であることは言うまでもありません。関数からベクトルを返すことはできますが、コードのコンパイルエラーや警告を避けずに配列を返すことはできません。
vector CMatrixutils::ArrayToVector(const double &Arr[]) { vector v((ulong)ArraySize(Arr)); for(ulong i=0; i<v.Size(); i++) v[i] = Arr[i]; return (v); }
以下が使用法です。
Print("---> Array to vector"); double Arr[3] = {1,2,3}; vec = matrix_utils.ArrayToVector(Arr); Print(vec);
以下が出力です。
CS 0 05:51:58.853 matrix test (US500,D1) ---> Array to vector CS 0 05:51:58.853 matrix test (US500,D1) [1,2,3]
ベクトルを配列に変換する
配列を完全に放棄することはできません。ベクトルを配列に変換して、配列を受け取る関数の引数にプラグインする必要がある場合や、配列の並べ替え、シリーズとして設定、スライスなど、ベクトルではできない操作が必要になる場合があります。
bool CMatrixutils::VectorToArray(const vector &v,double &arr[]) { ArrayResize(arr,(int)v.Size()); if(ArraySize(arr) == 0) return(false); for(ulong i=0; i<v.Size(); i++) arr[i] = v[i]; return(true); }
以下が使用法です。
Print("---> Vector to Array"); double new_array[]; matrix_utils.VectorToArray(vec,new_array); ArrayPrint(new_array);
以下が出力です。
CS 0 06:19:14.647 matrix test (US500,D1) ---> Vector to Array CS 0 06:19:14.647 matrix test (US500,D1) 1.0 2.0 3.0
行列から1列を削除する
CSVの列を行列に読み込んだからといって、そこからすべての列が必要なわけではありません。教師あり機械学習モデルを作成する際には、無関係な列を削除する必要がありますし、独立変数でいっぱいの行列から応答変数を削除する必要があるかもしれないことは言うまでもありません。
以下は、そのためのコードです。
void CMatrixutils::MatrixRemoveCol(matrix &mat, ulong col) { matrix new_matrix(mat.Rows(),mat.Cols()-1); //Remove the one Column for (ulong i=0, new_col=0; i<mat.Cols(); i++) { if (i == col) continue; else { new_matrix.Col(mat.Col(i),new_col); new_col++; } } mat.Copy(new_matrix); }
この関数の内部には何も不思議なことはなく,元の行列と同じ行数で,1列少ないサイズの新しい行列が作成されます.
matrix new_matrix(mat.Rows(),mat.Cols()-1); //Remove the one column新しい行列では、不要になった列を無視し、それ以外はすべて格納されるだけです。
関数の最後で,この新しい行列を古い行列にコピーします。
mat.Copy(new_matrix);
先ほどCSVファイルから読み込んだ行列から、インデックス1(2列目)の列を削除してみましょう。
Print("Col 1 ","Removed from Matrix"); matrix_utils.MatrixRemoveCol(Matrix,1); Print("New Matrix\n",Matrix);
以下が出力です。
CS 0 07:23:59.612 matrix test (EURUSD,H1) Column of index 1 removed new Matrix CS 0 07:23:59.612 matrix test (EURUSD,H1) [[4173.8,34.8,13067.5] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4179.2,36.6,13094.8] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4182.7,37.5,13108] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4185.8,37.1,13104.3] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4180.8,34.9,13082.2] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4174.6,31.8,13052] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4174.9,33.2,13082.2] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4170.8,32.2,13070.6] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4182.2,32.5,13078.8]
行列から複数の列を削除する
前の関数は単一の列を削除しようとする場合に当てはまりましたが、一度にすべて削除したい列が多数含まれる大きな行列が存在する場合もあります。これを実現するには、基本的に列を安全に削除するために、必要な列を削除せず、範囲外の値にアクセスしないようにするためのトリッキーな操作を実行する必要があります。
新しい行列の列数/サイズは、削除したい列の合計から列数を引いたものと同じにする必要があります。各列の行数は一定に保たれます(古い行列と同じ)。
最初にしなければならないのは、削除したい選択された列と、古い行列の利用可能な列をすべて反復処理して、列が削除されることになっている場合は、その列の値をすべて 0 に設定することです。これは、クリーンな操作で終わらせるためにおこなう賢い操作です。vector zeros(mat.Rows()); zeros.Fill(0); for(ulong i=0; i<size; i++) for(ulong j=0; j<mat.Cols(); j++) { if(cols[i] == j) mat.Col(zeros,j); }最後に、行列を再び2回反復処理して、ゼロ値で埋め尽くされたすべての列を確認し、それらの列を1つずつ削除する必要があります。
vector column_vector; for(ulong A=0; A<mat.Cols(); A++) for(ulong i=0; i<mat.Cols(); i++) { column_vector = mat.Col(i); if(column_vector.Sum()==0) MatrixRemoveCol(mat,i); }
2回反復することに注意してください。各列が削除された後にこの行列のサイズが調整されるため、これらは非常に重要です。したがって、列をスキップしたかどうかを確認するために再度ループバックすることが非常に重要なのです。
以下は、この関数の完全なコードです。
void CMatrixutils::MatrixRemoveMultCols(matrix &mat,int &cols[]) { ulong size = (int)ArraySize(cols); if(size > mat.Cols()) { Print(__FUNCTION__," Columns to remove can't be more than the available columns"); return; } vector zeros(mat.Rows()); zeros.Fill(0); for(ulong i=0; i<size; i++) for(ulong j=0; j<mat.Cols(); j++) { if(cols[i] == j) mat.Col(zeros,j); } //--- vector column_vector; for(ulong A=0; A<mat.Cols(); A++) for(ulong i=0; i<mat.Cols(); i++) { column_vector = mat.Col(i); if(column_vector.Sum()==0) MatrixRemoveCol(mat,i); } }
この関数を実際に使って、インデックス0とインデックス2の列を削除してみましょう。
Print("\nRemoving multiple columns"); int cols[2] = {0,2}; matrix_utils.MatrixRemoveMultCols(Matrix,cols); Print("Columns at 0,2 index removed New Matrix\n",Matrix);
以下が出力です。
CS 0 07:32:10.923 matrix test (EURUSD,H1) Columns at 0,2 index removed New Matrix CS 0 07:32:10.923 matrix test (EURUSD,H1) [[13386.6,13067.5] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13396.7,13094.8] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13406.6,13108] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13416.8,13104.3] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13425.2,13082.2] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13432.2,13052] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13440.4,13082.2] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13447.6,13070.6] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13457.8,13078.8]
行列から1行を削除する
また、データセットから無関係な行を削除したり、列の数を減らして何が有効かを確認する必要がある場合もあります。これは行列から列を取り除くことほど重要ではないので、あるのはこの1つの行を取り除くための関数だけです。複数行のものはありません。必要に応じてご自分でコーディングしてください。
行列から行を削除しようとしたときと同じ考え方で、新たに作る行列では不要な行を無視すればよいのです。
void CMatrixutils::MatrixRemoveRow(matrix &mat, ulong row) { matrix new_matrix(mat.Rows()-1,mat.Cols()); //Remove the one Row for(ulong i=0, new_rows=0; i<mat.Rows(); i++) { if(i == row) continue; else { new_matrix.Row(mat.Row(i),new_rows); new_rows++; } } mat.Copy(new_matrix); }
以下が使用法です。
Print("Removing row 1 from matrix"); matrix_utils.MatrixRemoveRow(Matrix,1); printf("Row %d Removed New Matrix[%d][%d]",0,Matrix.Rows(),Matrix.Cols()); Print(Matrix);
以下が出力です。
CS 0 06:36:36.773 matrix test (US500,D1) Removing row 1 from matrix CS 0 06:36:36.773 matrix test (US500,D1) Row 1 Removed New Matrix[743][4] CS 0 06:36:36.773 matrix test (US500,D1) [[4173.8,13386.6,34.8,13067.5] CS 0 06:36:36.773 matrix test (US500,D1) [4182.7,13406.6,37.5,13108] CS 0 06:36:36.773 matrix test (US500,D1) [4185.8,13416.8,37.1,13104.3] CS 0 06:36:36.773 matrix test (US500,D1) [4180.8,13425.2,34.9,13082.2] CS 0 06:36:36.773 matrix test (US500,D1) [4174.6,13432.2,31.8,13052] CS 0 06:36:36.773 matrix test (US500,D1) [4174.9,13440.4,33.2,13082.2] CS 0 06:36:36.773 matrix test (US500,D1) [4170.8,13447.6,32.2,13070.6]
ベクトルのインデックスを削除する
この関数は、ベクトルから特定のインデックスにある単一の項目を削除するのに役立ちます。これは、ベクトルから指定されたインデックスに位置する数値を無視し、残りの値を新しいベクトルに格納し、最終的に主なベクトルか関数の引数から参照されるベクトルにコピーすることでこのような結果を達成することができます。
void CMatrixutils::VectorRemoveIndex(vector &v, ulong index) { vector new_v(v.Size()-1); for(ulong i=0, count = 0; i<v.Size(); i++) if(i != index) { new_v[count] = v[i]; count++; } v.Copy(new_v); }
この関数の使用方法は次の通りです。
vector v= {0,1,2,3,4}; Print("Vector remove index 3"); matrix_utils.VectorRemoveIndex(v,3); Print(v);
以下が出力です。
2022.12.20 06:40:30.928 matrix test (US500,D1) Vector remove index 3 2022.12.20 06:40:30.928 matrix test (US500,D1) [0,1,2,4]
行列を訓練行列とテスト行列に分割する
教師あり機械学習モデルを作る上で、この関数がいかに重要であるかは、いくら強調してもしきれません。あるデータセットで学習させ、もう一方のデータセットでモデルをテストするために、データセットを学習用とテスト用に分割する必要がある場合は多くあります。
この関数は,デフォルトではデータセットの70%を学習サンプルに,残りの30%をテストサンプルに分割し,ランダムな状態は存在しません。データは時系列で選択され、最初の70%のデータは学習行列に、残りの30%はテスト行列に格納されます。
Print("---> Train / Test Split"); matrix TrainMatrix, TestMatrix; matrix_utils.TrainTestSplitMatrices(Matrix,TrainMatrix,TestMatrix); Print("\nTrain Matrix(",TrainMatrix.Rows(),",",TrainMatrix.Cols(),")\n",TrainMatrix); Print("\nTestMatrix(",TestMatrix.Rows(),",",TestMatrix.Cols(),")\n",TestMatrix);
以下が出力です。
CS 0 07:38:46.011 matrix test (EURUSD,H1) Train Matrix(521,4) CS 0 07:38:46.011 matrix test (EURUSD,H1) [[4173.8,13386.6,34.8,13067.5] CS 0 07:38:46.011 matrix test (EURUSD,H1) [4179.2,13396.7,36.6,13094.8] CS 0 07:38:46.011 matrix test (EURUSD,H1) [4182.7,13406.6,37.5,13108] CS 0 07:38:46.011 matrix test (EURUSD,H1) [4185.8,13416.8,37.1,13104.3] CS 0 07:38:46.011 matrix test (EURUSD,H1) [4180.8,13425.2,34.9,13082.2] .... .... CS 0 07:38:46.012 matrix test (EURUSD,H1) TestMatrix(223,4) CS 0 07:38:46.012 matrix test (EURUSD,H1) [[4578.1,14797.9,65.90000000000001,15021.1] CS 0 07:38:46.012 matrix test (EURUSD,H1) [4574.9,14789.2,63.9,15006.2] CS 0 07:38:46.012 matrix test (EURUSD,H1) [4573.6,14781.4,63,14999] CS 0 07:38:46.012 matrix test (EURUSD,H1) [4571.4,14773.9,62.1,14992.6] CS 0 07:38:46.012 matrix test (EURUSD,H1) [4572.8,14766.3,65.2,15007.1]
XY行列分割
データセットを行列に読み込んで教師あり学習モデルを作ろうとするとき、次に必要なことは、独立変数がその値の行列に格納されるのと同じように、行列から目的変数を抽出して独立に格納することです。これはそのための関数です。if(y_index == -1) value = matrix_.Cols()-1; //Last column in the matrix
以下が使用法です。
Print("---> X and Y split matrices"); matrix x; vector y; matrix_utils.XandYSplitMatrices(Matrix,x,y); Print("independent vars\n",x); Print("Target variables\n",y);
以下が出力です。
CS 0 05:05:03.467 matrix test (US500,D1) ---> X and Y split matrices CS 0 05:05:03.467 matrix test (US500,D1) independent vars CS 0 05:05:03.468 matrix test (US500,D1) [[4173.8,13386.6,34.8] CS 0 05:05:03.468 matrix test (US500,D1) [4179.2,13396.7,36.6] CS 0 05:05:03.468 matrix test (US500,D1) [4182.7,13406.6,37.5] CS 0 05:05:03.468 matrix test (US500,D1) [4185.8,13416.8,37.1] CS 0 05:05:03.468 matrix test (US500,D1) [4180.8,13425.2,34.9] CS 0 05:05:03.468 matrix test (US500,D1) [4174.6,13432.2,31.8] CS 0 05:05:03.468 matrix test (US500,D1) [4174.9,13440.4,33.2] CS 0 05:05:03.468 matrix test (US500,D1) [4170.8,13447.6,32.2] CS 0 05:05:03.468 matrix test (US500,D1) [4182.2,13457.8,32.5] .... .... 2022.12.20 05:05:03.470 matrix test (US500,D1) Target variables 2022.12.20 05:05:03.470 matrix test (US500,D1) [13067.5,13094.8,13108,13104.3,13082.2,13052,13082.2,13070.6,13078.8,...]
XとYの分割関数の内部では、Y変数として選択された列がY行列に格納され、残りの列はX行列に格納されます。
void CMatrixutils::XandYSplitMatrices(const matrix &matrix_,matrix &xmatrix,vector &y_vector,int y_index=-1) { ulong value = y_index; if(y_index == -1) value = matrix_.Cols()-1; //Last column in the matrix //--- y_vector = matrix_.Col(value); xmatrix.Copy(matrix_); MatrixRemoveCol(xmatrix, value); //Remove the y column }
計画行列を作成する
設計行列は、最小二乗法に不可欠なもので、X行列(独立変数の行列)の最初の列を1の値で埋めただけのものです。この計画行列は、線形回帰モデルの係数を求めるのに役立ちます。DesignMatrix()関数の中で、1の値で満たされたベクトルが作成され、それが行列の最初の列に挿入され、残りの列はその順序に従うように設定されます。以下が完全なコードです。

matrix CMatrixutils::DesignMatrix(matrix &x_matrix) { matrix out_matrix(x_matrix.Rows(),x_matrix.Cols()+1); vector ones(x_matrix.Rows()); ones.Fill(1); out_matrix.Col(ones,0); vector new_vector; for(ulong i=1; i<out_matrix.Cols(); i++) { new_vector = x_matrix.Col(i-1); out_matrix.Col(new_vector,i); } return (out_matrix); }
以下が使用法です。
Print("---> Design Matrix\n"); matrix design = matrix_utils.DesignMatrix(x); Print(design);
以下が出力です。
CS 0 05:28:51.786 matrix test (US500,D1) ---> Design Matrix CS 0 05:28:51.786 matrix test (US500,D1) CS 0 05:28:51.786 matrix test (US500,D1) [[1,4173.8,13386.6,34.8] CS 0 05:28:51.786 matrix test (US500,D1) [1,4179.2,13396.7,36.6] CS 0 05:28:51.786 matrix test (US500,D1) [1,4182.7,13406.6,37.5] CS 0 05:28:51.786 matrix test (US500,D1) [1,4185.8,13416.8,37.1] CS 0 05:28:51.786 matrix test (US500,D1) [1,4180.8,13425.2,34.9] CS 0 05:28:51.786 matrix test (US500,D1) [1,4174.6,13432.2,31.8] CS 0 05:28:51.786 matrix test (US500,D1) [1,4174.9,13440.4,33.2] CS 0 05:28:51.786 matrix test (US500,D1) [1,4170.8,13447.6,32.2] CS 0 05:28:51.786 matrix test (US500,D1) [1,4182.2,13457.8,32.5]
ワンホットエンコード行列
ワンホットエンコードをやってみましょう。これは分類ニューラルネットワークを作ろうとするときに必要になる非常に重要な関数です。この関数は,MLPにとって,最終層のニューロンからの出力と実際の値との関係を明確にするものであり,非常に重要であることがわかります。
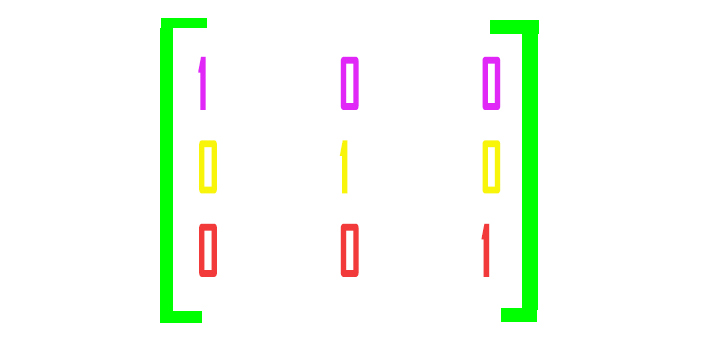
ホットエンコードされた行列では、各行のベクトルは、1つの値を除いて0値で構成されます。この値は、ヒットさせたい正しい値の値で、値は1になります。
このことをよく理解するために、以下の例を見てみましょう。
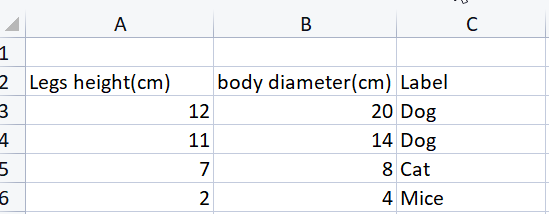
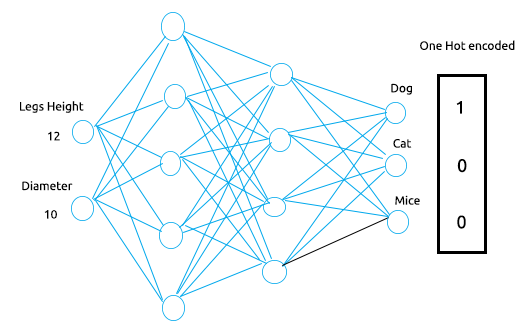
このデータセットで、脚の長さと胴体の直径から、犬、猫、マウスの3つのクラスを分類できるようにニューラルネットワークを学習させたいとします。
多層パーセプトロンは、入力層に脚の高さと胴体の直径を表す2つの入力ノード/ニューロン、出力層に犬、猫、ネズミの3つの結果を表す3つのノードを有します。
このMLPに高さと直径でそれぞれ12と20の値を入力すると、ニューラルネットワークはこれを犬であると分類するはずですよ。ワンホットエンコーディングがおこなうことは、指定された学習データセットの正しい値を持つノードに1の値を配置することです。この場合、犬のノードに1の値が配置され、残りは0の値を持ちます。
残りの値はゼロなので、モデルが与えた確率のそれぞれに、ホットエンコードされたベクトルの値を代入することで、コスト関数を計算することができます。このエラーは、前の層のそれぞれの前のノードでネットワークに伝播されます。
では、実際にワンホットエンコードを実行してみましょう。
これがMetaEditorの行列です。
matrix dataset = { {12,28, 1}, {11,14, 1}, {7,8, 2}, {2,4, 3} };
これはCSVで見たデータセットと同じものですが、行列に文字列は使えないので、ターゲットのラベルが整数になっています。ところで、計算ではいつ、どこで文字列を使用できるのでしょうか。
matrix dataset = { {12,28, 1}, {11,14, 1}, {7,8, 2}, {2,4, 3} }; vector y_vector = dataset.Col(2); //obtain the column to encode uint classes = 3; //number of classes in the column Print("One Hot encoded matrix \n",matrix_utils.OneHotEncoding(y_vector,classes));
以下は出力です。
CS 0 08:54:04.744 matrix test (EURUSD,H1) One Hot encoded matrix CS 0 08:54:04.744 matrix test (EURUSD,H1) [[1,0,0] CS 0 08:54:04.744 matrix test (EURUSD,H1) [1,0,0] CS 0 08:54:04.744 matrix test (EURUSD,H1) [0,1,0] CS 0 08:54:04.744 matrix test (EURUSD,H1) [0,0,1]]
ベクトルからクラスを取得する
この関数は、指定されたベクトルで使用可能なクラスを含むベクトルを返します。例えば、[1,2,3]のベクトルには3種類のクラスがあり、[1,0,1,0]のベクトルには2種類のクラスがある、というようにです。この関数の役割は、利用可能な別個のクラスを返すことです。
vector v = {1,0,0,0,1,0,1,0}; Print("classes ",matrix_utils.Classes(v));
以下が出力です。
2022.12.27 06:41:54.758 matrix test (US500,D1) classes [1,0]
乱数値のベクトルを作成します。
ランダムな変数からなるベクトルを生成する必要があるとき,この関数が役に立ちます。この関数の最も一般的な使用方法は、NNの重みとバイアスベクトルを生成することです。また、ランダムなデータセットのサンプルを作るのにも使えます。
vector Random(int min, int max, int size); vector Random(double min, double max, int size);
以下が使用法です。
v = matrix_utils.Random(1.0,2.0,10); Print("v ",v);
以下が出力です。
2022.12.27 06:50:03.055 matrix test (US500,D1) v [1.717642750328074,1.276955473494675,1.346263008514664,1.32959990234077,1.006469924008911,1.992980742820521,1.788445692312387,1.218909268471328,1.732139042329173,1.512405774101993]
あるベクトルを別のベクトルに追加します。
これは 文字列の連結のようなものですが、代わりにベクトルを連結しています。私自身、この関数を使いたいと思うことが多々ありました。以下は、その構成です。
vector CMatrixutils::Append(vector &v1, vector &v2) { vector v_out = v1; v_out.Resize(v1.Size()+v2.Size()); for (ulong i=v2.Size(),i2=0; i<v_out.Size(); i++, i2++) v_out[i] = v2[i2]; return (v_out); }
以下が使用法です。
vector v1 = {1,2,3}, v2 = {4,5,6}; Print("Vector 1 & 2 ",matrix_utils.Append(v1,v2));
以下が出力です。
2022.12.27 06:59:25.252 matrix test (US500,D1) Vector 1 & 2 [1,2,3,4,5,6]
ベクトルを別のベクトルにコピーする
最後に、Arraycopyのように、ベクトルを操作して、ベクトルを別のベクトルにコピーしてみましょう。ベクトル全体を別のベクトルにコピーする必要がない場合も多く、ベクトルの一部分だけをコピーする必要がある場合もあります。標準ライブラリのCopyはこれができません。
bool CMatrixutils::Copy(const vector &src,vector &dst,ulong src_start,ulong total=WHOLE_ARRAY) { if (total == WHOLE_ARRAY) total = src.Size()-src_start; if ( total <= 0 || src.Size() == 0) { printf("Can't copy a vector | Size %d total %d src_start %d ",src.Size(),total,src_start); return (false); } dst.Resize(total); dst.Fill(0); for (ulong i=src_start, index =0; i<total+src_start; i++) { dst[index] = src[i]; index++; } return (true); }
以下が使用法です。
vector all = {1,2,3,4,5,6}; matrix_utils.Copy(all,v,3); Print("copied vector ",v);
以下が出力です。
2022.12.27 07:15:41.420 matrix test (US500,D1) copied vector [4,5,6]
最後に
できることはたくさんありますし、utilsファイルに追加できる関数もたくさんありますが、今回紹介した関数やメソッドは、行列をしばらく使っている方や、機械学習にヒントを得たような複雑な取引システムを作ろうとするときに、よく必要になるものだと思います。
このUtility Matrixクラスの開発状況は、私のGitHubレポ(https://github.com/MegaJoctan/MALE5)でご覧になれます。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/11858
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
記事をありがとう。
MetatreaderでNNベースのEAをトレーニングするのは大変でした。
メタトレーダー・オプティマイザーのトレーニング・エージェントが読み込むために、重みとバイアスをCSVファイルに書き込もうとしたのですが、100以下のステップで止まってしまいます。
このような数の変数をトレーニングする方法をご存知ですか?
記事にしてくれてありがとう。
MetatreaderでNNベースのEAをトレーニングするのは難しいですね。
メタトレーダー・オプティマイザーのトレーニング・エージェントが読み込むために、重みとバイアスをCSVファイルに書き込もうとしたのですが、100以下のステップで止まってしまいます。
このような数の変数をトレーニングする方法をご存知ですか?
コードや関係するものすべてを見ないとわかりません。私はストラテジー・テスターでNNを訓練しません。私のNNはすべて自分で訓練しています。
記事にしてくれてありがとう。
MetatreaderでNNベースのEAをトレーニングするのは難しいですね。
メタトレーダー・オプティマイザーのトレーニング・エージェントが読み込むために、重みとバイアスをCSVファイルに書き込もうとしたのですが、100以下のステップで止まってしまいます。
このような数の変数をトレーニングする方法をご存知ですか?
テスターの高速遺伝的アルゴリズムを使用している場合は、報酬の設定方法によって「動機」が異なるので注意が必要です。
Msigwa氏が言ったように、逆伝播でネットを訓練するのが望ましい。より多くの重みを訓練することができ、ネットワークの報酬は "正確さ "の向上だけである。