
股票交易中的非线性回归模型

概述
昨天,我再次盯着基于回归的交易系统报告发呆。窗外湿雪纷飞,杯中的咖啡早已冷却,但我仍无法摆脱那个挥之不去的念头。您知道吗,那些无休止的相对强弱指数(RSI)、随机指标(Stochastic)、移动平均线收敛发散指标(MACD)等指标,早已让我感到厌烦。我们怎么能试图用这些简单的方程来拟合一个充满活力且动态变化的市场呢?每次看到YouTube上那些自称拥有“圣杯”指标的拥护者,展示他们那套“神圣”的指标组合时,我都想问——朋友,您真的相信这些70年代的“计算器”能捕捉到现代市场的复杂动态吗?
过去三年里,我一直在努力创造真正有效的东西。我尝试了很多方法——从最简单的回归到复杂的神经网络。您知道结果如何吗?我在分类任务上取得了成果,但在回归任务上仍未成功。
每次都重复同样的情况——在历史数据上一切运行得井井有条,但一到真实市场,就面临亏损。我还记得我对自己的第一个卷积网络感到多么兴奋。训练集上的R²值为1.00%。然而,两周的交易后,账户资金亏损了30%。典型的过拟合现象。我不断启用前向可视化功能,看着基于回归的预测与实际价格随着时间的推移越来越远……
但我是一个固执的人。又一次亏损后,我决定深入挖掘,开始翻阅科学文献。您知道我在尘封的档案中发现了什么吗?原来,曼德博罗特(Mandelbrot)早已大谈市场的分形特性。而我们却都在用线性模型进行交易!这就像试图用尺子测量海岸线的长度——您测量得越精确,海岸线就显得越长。
某一刻,我突然想到:如果我将经典的技术分析与非线性动力学结合起来会是怎样?不是那些简单的指标,而是更有用的东西——微分方程、自适应比率。这听起来很复杂,但本质上,这只是试图用市场的语言与市场对话。
简而言之,我拿起Python,连接上机器学习库,开始实验。我立刻决定——不搞学术上的花哨,只关注真正能用的东西。不用超级计算机——只用一台普通的宏碁(Acer)笔记本电脑、强大的虚拟专用服务器(VPS)和MetaTrader 5交易终端。由此,诞生了我想要与您分享的模型。
不,这不是圣杯。我早就意识到,圣杯并不存在。我只是在分享将现代数学应用于实际交易的经验。没有不必要的炒作,也没有“趋势指标”的简单化。结果是一种介于两者之间的情况:足够聪明,能够发挥作用,但又不会复杂到在遇到第一只黑天鹅事件时就崩溃。
数学模型
我还记得我是怎么想出这个方程的。自2022年以来,我就一直在研究这段代码,但并非持续不断:就方法而言,我会说——有很多开发工作,所以需要定期(有点杂乱无章地)回顾它们,并逐个将它们完善到最终结果。我记得我运行图表,试图捕捉欧元兑美元汇率中的模式。您知道我注意到了什么吗?市场似乎在呼吸——有时它顺着趋势平稳流动,有时它突然剧烈波动,有时它进入某种神奇的节奏。如何用数学来描述这一点?如何将这些生动的动态捕捉到方程中?
后来,我勾勒出了方程的第一个版本。它就在这里,尽显辉煌:
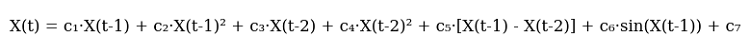
代码如下:
def equation(self, x_prev, coeffs): x_t1, x_t2 = x_prev[0], x_prev[1] return (coeffs[0] * x_t1 + # trend coeffs[1] * x_t1**2 + # acceleration coeffs[2] * x_t2 + # market memory coeffs[3] * x_t2**2 + # inertia coeffs[4] * (x_t1 - x_t2) + # impulse coeffs[5] * np.sin(x_t1) + # market rhythm coeffs[6]) # basic level
请看这一切是多么错综复杂。前两项旨在捕捉当前的市场走势。您知道汽车是如何加速的吗?先是平稳加速,然后越来越快。这就是这里既有线性项又有二次项的原因。当价格平稳波动时,线性部分发挥作用。但市场一旦加速,二次项就会捕捉到这一动态。
现在,最有趣的部分来了。第三和第四项则深入探究过去。这就像市场的记忆。您还记得道氏理论中关于市场会记住其价格水平的说法吗?此处也是一样的原理。而且,这里再次采用了二次加速——以捕捉急剧的转折。
接下来是动量部分。我们只需用当前价格减去前一个价格。这看起来似乎很简单。但它在趋势行情中表现得非常出色!当市场陷入狂热,一个劲地朝一个方向推动时,这一项就成为预测的主要驱动力。
正弦函数的加入几乎是偶然的。我看着图表,注意到某种周期性。尤其是在H1(1小时)时间框架上。波动期与平静期交替出现……这看起来像正弦波,不是吗?我将正弦波加入方程,模型似乎看到了曙光,开始捕捉这些节奏。
最后一个比率是一种安全网,一个基准水平。这一项防止模型的预测结果与市场实际表现大相径庭。
我尝试了许多其他选项。我加入了指数、对数和各种复杂的三角函数。但没什么实际意义,反而让模型变得一团糟。您知道吗,正如奥卡姆所说:如无必要,勿增实体。当前版本正是如此——简单且实用。
当然,所有这些比率都需要以某种方式选定。这时,经典的Nelder-Mead方法就派上用场了。但这是另一个故事,我将在下一部分揭晓。相信我,还有很多可以探讨的——仅我在优化过程中犯的错误就足以写一篇单独的文章了。
线性部分让我们从线性部分开始。您知道最重要的是什么吗?模型以不同的方式查看前两个价格值。第一个比率通常在0.3-0.4左右——这是对最近一次变动的即时反应。但第二个更有意思,它常常接近0.7,表明倒数第二个价格的影响更大。有趣吧?市场似乎更依赖稍旧的价格水平,而不信任最新的波动。
二次项部分关于二次项,发生了一件有趣的事情。最初,我加入它们只是为了考虑非线性,但后来我注意到了一些令人惊讶的情况。在平静的市场中,它们的贡献微乎其微——比率在0.01-0.02左右波动。但一旦开始大幅波动,这些项似乎就“苏醒”了。这在欧元兑美元的日线图上尤为明显——当趋势增强时,二次项开始占据主导地位,使模型能够随着价格“加速”。
动量部分动量部分真是个意外的发现。这看似只是一个简单的价格差异,但它却极其准确地反映了市场情绪!在平静时期,其比率保持在0.2-0.3左右,但在大幅波动前,它常常会跃升至0.5。这对我来说成了即将突破的一种指标——当优化器开始提高动量权重时,就预示着行情即将启动。
周期性部分周期性部分需要一些调整。起初,我尝试了不同的正弦波周期,但后来我意识到市场本身就设定了节奏。只需让模型通过比率调整振幅,频率则自然地从价格中得出。看着这个比率在欧洲和美国交易时段之间变化很有趣——仿佛市场真的以不同的节奏呼吸。
最后,是常数项。它的作用比我最初想象的要重要得多。在高波动性时期,它起到锚定作用,防止预测结果偏离实际。而在平稳时期,它有助于更准确地衡量整体价格水平。其值常常与趋势强度相关——趋势越强,常数项越接近0。
您知道最有趣的是什么吗?每次我试图使模型复杂化——加入新的项、使用更复杂的函数等,结果只会变得更糟。就好像市场在说:“朋友,别自作聪明,您已经抓住了重点。”当前版本的方程确实是基于复杂性和效率之间的完美平衡。有七个比率——不多也不少,每个比率在整体预测机制中都有其明确的角色。
顺便说一下,这些比率的优化本身就是一个引人入胜的故事。当您开始观察Nelder-Mead方法如何寻找最优值时,您会不由自主地想起混沌理论。但我们将在下一部分讨论这个议题——相信我,有很多值得一看的内容。
使用Nelder-Mead算法进行模型优化
下面,我们将探讨最有趣的部分——如何使我们的模型在真实数据上发挥作用。经过数月的优化实验、数十个不眠之夜和数杯咖啡后,我终于找到了一个可行的方法。
一切照旧——从梯度下降开始。这是数据科学家首先想到的经典方法。我花了三天时间实现,又花了一周时间调试……那么结果如何呢?模型始终拒绝收敛。它要么飞向无穷大,要么陷入局部最小值。梯度跳动得像疯了似的。
接着,我尝试了一周的遗传算法。这个想法看似美好——让进化找到最佳比率。我实现了它,启动了……结果被运行时间惊呆了。电脑整夜嗡嗡作响,只处理了一周的历史数据。结果如此不稳定,就像读茶渣一样难以捉摸。
然后,我偶然发现了Nelder-Mead方法。这是1965年开发的古老而简单的方法。无需导数,无需高等数学——只需巧妙地探测解空间。我启用了此方法,简直不敢相信自己的眼睛。算法似乎在与市场共舞,平稳地接近最优值。
这是基本的损失函数。它简单得像一把斧头,但却完美无瑕:
def loss_function(self, coeffs, X_train, y_train): y_pred = np.array([self.equation(x, coeffs) for x in X_train]) mse = np.mean((y_pred - y_train)**2) r2 = r2_score(y_train, y_pred) # Save progress for analysis self.optimization_progress.append({ 'mse': mse, 'r2': r2, 'coeffs': coeffs.copy() }) return mse
起初,我试图让损失函数变得复杂,对较大的比率添加惩罚项,还把平均绝对百分比误差(MAPE)和其他指标都纳入其中。一个典型的开发人员错误就是:如果某样东西有效,那就必须不断改进,直到它完全无法运行。最后,我还是回到了简单的均方误差(MSE),您猜怎么样?原来,简单才是天才的标识。
实时观察优化过程,有一种别样的兴奋感。前几次迭代时,比率疯狂跳动,均方误差也上下波动,R² 接近0。然后,最有趣的部分开始了——算法找到了正确的方向,各项指标逐渐改善。到第100次迭代时,是否会有成效已经一目了然,到第300次迭代时,系统通常就能达到稳定水平。
顺便说一句,让我来谈谈指标。我们的R²通常在0.996以上,这意味着该模型能够解释超过99.6%的价格波动。均方误差约为0.0000007,换句话说,预测误差很少超过0.7个点(pip,衡量价格变动的最小单位)。至于平均绝对百分比误差(MAPE)……MAPE通常令人满意——常常低于0.1%。显然,这些都是基于历史数据得出的,但在前瞻性测试中,结果也相差无几。
但最重要的还不是这些数字。最重要的是结果的稳定性。您可以连续运行十次优化,每次得到的比率值都非常接近。这一点非常有价值,尤其是考虑到我在其他优化方法上遇到的种种困难。
您知道还有什么重要的吗?通过观察优化过程,您可以对市场本身有更深入的了解。例如,当算法不断尝试增加动量成分的权重时,这意味着市场即将出现强劲走势。或者当它开始调整周期性成分时——预示着市场将进入一段波动加剧的时期。
在下一节中,我会讲述如何将所有这些数学结构转化为一个真正的交易系统。相信我,其中也有很多值得思考的地方——光是MetaTrader 5的陷阱就足够写一篇单独的文章了。
训练过程的特点
准备训练数据是另一回事。我记得在系统的第一个版本中,我兴高采烈地把整个数据集都给了sklearn.train_test_split函数……直到后来,看到好到令人怀疑的结果,我才意识到未来的数据渗透到了过去的数据中!
您看出问题所在了吗?您不能像对待普通的Kaggle电子表格那样对待金融数据。此处,每个数据点都是一个时间点,把它们混在一起,就像试图根据明天的天气来预测昨天的天气一样。结果,这段简单但高效的代码应运而生:
def prepare_training_data(prices, train_ratio=0.67): # Cut off a piece for training n_train = int(len(prices) * train_ratio) # Forming prediction windows X = np.array([[prices[i], prices[i-1]] for i in range(2, len(prices)-1)]) y = prices[3:] # Fair time sharing X_train, y_train = X[:n_train], y[:n_train] X_test, y_test = X[n_train:], y[n_train:] return X_train, y_train, X_test, y_test这段代码看似简单。但在这简洁背后,可是有着诸多艰难的摸索。起初,我尝试了不同的窗口大小。我以为历史数据点越多,预测效果就越好。但我错啦!结果发现,仅用前两个值就完全足够了。要知道,市场可不喜欢长久地铭记过去。
训练样本的大小是另一回事。我尝试了不同的比例——50/50、80/20,甚至90/10。最终,我选定了黄金比例——大约67%的数据作为训练数据。为什么呢?因为这个比例效果最优!显然,斐波那契(Fibonacci)对市场的本质有所了解……
看着模型用不同时间段的数据进行训练,十分有趣。如果选取的是一段平稳时期的数据,比率会平稳选定,各项指标也会逐渐改善。而如果训练样本中包含了像英国脱欧(Brexit)或者美联储主席讲话这样的事件,那可就乱套了:比率会上下跳动,优化器会失控,误差图表就像坐过山车一样。
顺便说一句,让我再谈谈指标。我注意到,如果训练样本的R²高于0.98,那几乎可以肯定,数据方面出了什么问题。真实的市场根本不可能有那么强的可预测性。这就像那个关于成绩优异学生的故事——要么他作弊了,要么他是个天才。在我们这种情况下,通常是前者。
另一个重要的点是数据预处理。起初,我尝试对价格进行标准化、缩放、去除异常值……一般来说,我把机器学习课程中学到的所有方法都试了个遍。但逐渐地,我得出了一个结论:对原始数据的干预越少越好。市场会自行进行“标准化”,您只需要正确地做好准备工作就行。
现在,训练流程已经简化到近乎自动化。我们每周加载一次新数据,进行训练,并将指标与历史值进行比较。如果一切都在正常范围内,就更新实盘交易系统中的比率。如果发现什么可疑之处,就深入研究。幸运的是,经验已经告诉我们该从哪里找问题。
比率优化
def fit(self, prices): # Prepare data for training X_train, y_train = self.prepare_training_data(prices) # I found these initial values by trial and error initial_coeffs = np.array([0.5, 0.1, 0.3, 0.1, 0.2, 0.1, 0.0]) result = minimize( self.loss_function, initial_coeffs, args=(X_train, y_train), method='Nelder-Mead', options={ 'maxiter': 1000, # More iterations does not improve the result 'xatol': 1e-8, # Accuracy by ratios 'fatol': 1e-8 # Accuracy by loss function } ) self.coefficients = result.x return result
您知道最难解决的问题是什么吗?就是得把那该死的初始比率设对。一开始,我尝试用随机值——结果得出的结果分布范围太广,我差点就放弃了。接着,我尝试从1开始——结果优化器在第一次迭代时就跑到九霄云外去了。从0开始也不行,因为会陷入局部最小值。
第一个比率0.5是线性成分的权重。如果这个值设小了,模型就会失去趋势性;如果设大了,它又会过于依赖最新价格。对于二次项,0.1被证明是一个完美的起点——足以捕捉非线性关系,但又不会让模型在价格突变时失控。动量项的值0.2是通过经验得出的;正是这个值让系统表现出了最稳定的结果。
在优化过程中,Nelder-Mead算法会在一个七维比率空间中构建一个单形。这就像一场“冷热”游戏,只不过是在七个维度上同时进行。防止过程发散非常重要,这就是为什么对精度有如此严格的要求(1e-8)。如果精度要求设低了,结果就不稳定;设高了,优化又会陷入局部最小值。
一千次迭代可能看起来有点多,但实际上优化器通常在300-400步就收敛了。只是有时候,特别是在高波动性时期,它需要更多时间来找到最优解。而且,额外的迭代并不会真正影响性能——基于现代硬件设备,整个过程通常不到一分钟。
顺便说一句,正是在调试这段代码的过程中,我萌生了添加优化过程可视化的想法。当您实时看到比率变化时,就更容易理解模型发生了什么,以及它可能会走向何方。
质量指标及其解读
评估预测模型的质量是另一回事,充满了不起眼的微妙之处。在从事算法交易工作的这些年里,我在指标方面吃了不少苦头,足以就此写一本书了。但我会告诉您最重要的内容。
结果如下:

我们先从R²(R-squared)说起。我第一次在欧元兑美元(EURUSD)上看到R²超过0.9时,简直不敢相信自己的眼睛。我检查了十遍代码,确保没有数据渗透或计算错误。结果并没有——模型确实解释了超过90%的价格波动。然而,后来我意识到这是一把双刃剑。R²(大于0.95)通常意味着过拟合。市场根本不可能有那么强的可预测性。
均方误差(MSE)是我们的主力指标。以下是一段典型的评估代码:
def evaluate_model(self, y_true, y_pred): results = { 'R²': r2_score(y_true, y_pred), 'MSE': mean_squared_error(y_true, y_pred), 'MAPE': mean_absolute_percentage_error(y_true, y_pred) * 100 } # Additional statistics that often save the day errors = y_pred - y_true results['max_error'] = np.max(np.abs(errors)) results['error_std'] = np.std(errors) # Look separately at error distribution "tails" results['error_quantiles'] = np.percentile(np.abs(errors), [50, 90, 95, 99]) return results
请注意新增的统计指标。在一次失败的经历后,我添加了最大误差(max_error)和误差标准差(error_std)——当时模型显示的均方误差(MSE)极佳,但有时预测结果会出现极端异常值,让我甚至不用尝试就能直接判定会亏光本金。现在,我首先关注的就是误差分布的“尾部”情况。不过,尾部问题依然存在:
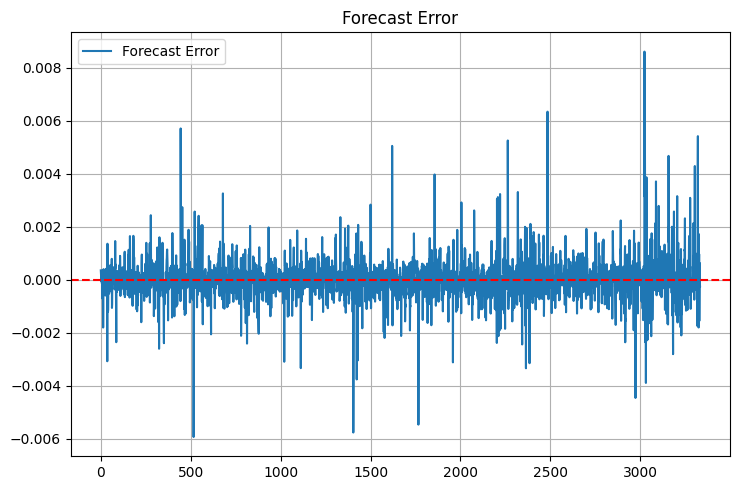
对于交易者而言,平均绝对百分比误差(MAPE)就像家一样熟悉。如果您跟他们说R²,他们会眼神呆滞;但如果您告诉他们“模型平均误差0.05%”,他们立刻就能明白。不过,这里有个陷阱——在价格小幅波动时,MAPE可能会低得具有欺骗性,而在价格剧烈波动时则会飙升。
但我明白最重要的一点是,任何基于历史数据的指标都不能保证在现实交易中取得成功。这就是为什么我现在建立了一整套核查体系:
def validate_model_performance(self): # Check metrics on different timeframes timeframes = ['H1', 'H4', 'D1'] for tf in timeframes: metrics = self.evaluate_on_timeframe(tf) if not self._check_metrics_thresholds(metrics): return False # Look at behavior at important historical events stress_periods = self.get_stress_periods() stress_metrics = self.evaluate_on_periods(stress_periods) if not self._check_stress_performance(stress_metrics): return False # Check the stability of forecasts stability = self.check_prediction_stability() if stability < self.min_stability_threshold: return False return True
在将模型投入真实交易之前,必须通过所有这些测试。即便如此,在最初的两周里,我也只会用最小交易量进行操作——我要观察它在真实市场中的表现。
人们经常问我,什么样的指标值才算好。根据我的经验,R²高于0.9算是非常出色,均方误差(MSE)小于0.00001尚可接受,而平均绝对百分比误差(MAPE)在0.05%以内则堪称优秀。但是!更重要的是观察这些指标随时间变化的稳定性。与其选择一个指标极佳但表现不稳定的系统,不如选择一个指标稍逊但稳定的模型。
技术实现
您知道开发交易系统最困难的是什么吗?不是数学,不是算法,而是运行的可靠性。写出一个漂亮的公式是一回事,而让它全天候(24/7)用真金白银稳定运行则是另一回事。在真实账户上经历了几次惨痛的失误后,我意识到:架构不仅要好,而且必须完美无瑕。
以下是我对系统核心的架构安排:
class PriceEquationModel: def __init__(self): # Model status self.coefficients = None self.training_scores = [] self.optimization_progress = [] # Initializing the connection self._setup_logging() self._init_mt5() def _init_mt5(self): """Initializing connection to MT5""" try: if not mt5.initialize(): raise ConnectionError( "Unable to connect to MetaTrader 5. " "Make sure the terminal is running" ) self.log.info("MT5 connection established") except Exception as e: self.log.critical(f"Critical initialization error: {str(e)}") raise
这里的每一行代码,都是基于过往惨痛经历的结晶。比如,我专门写了一个初始化MetaTrader 5的方法,就是因为在尝试重新连接时遭遇死锁问题,才不得不这么做。另外,我添加了日志记录功能,那是因为有次系统在半夜静悄悄地崩溃了,早上我只能一脸茫然地猜测到底发生了什么。
至于错误处理,那完全是另一码事了。
def _safe_mt5_call(self, func, *args, retries=3, delay=5): """Secure MT5 function call with automatic recovery""" for attempt in range(retries): try: result = func(*args) if result is not None: return result # MT5 sometimes returns None without error raise ValueError(f"MT5 returned None: {func.__name__}") except Exception as e: self.log.warning(f"Attempt {attempt + 1}/{retries} failed: {str(e)}") if attempt < retries - 1: time.sleep(delay) # Trying to reinitialize the connection self._init_mt5() else: raise RuntimeError(f"Call attempts exhausted {func.__name__}")
这段代码堪称MetaTrader 5使用经验的精华所在。一旦出现问题,它会尝试重新连接,间隔一段时间后重复尝试,而最重要的是,它绝不允许系统在状态不明的情况下继续运行。不过总体来说,MetaTrader 5库本身通常不会出什么问题——它简直完美!
我让模型保持极其简洁的状态。只包含最必要的元素。没有复杂的数据结构,也没有花哨的优化。但每次状态变更都会被记录并检查:
def _update_model_state(self, new_coefficients): """Safely updating model ratio""" if not self._validate_coefficients(new_coefficients): raise ValueError("Invalid ratios") # Save the previous state old_coefficients = self.coefficients try: self.coefficients = new_coefficients if not self._check_model_consistency(): raise ValueError("Model consistency broken") self.log.info("Model successfully updated") except Exception as e: # Roll back to the previous state self.coefficients = old_coefficients self.log.error(f"Model update error: {str(e)}") raise
这里的模块化可不只是个漂亮的说法。每个组件都能单独测试、替换或修改。想添加新指标?创建新方法就可以。需要更换数据源?只需实现一个接口相同的新连接器就完成了。
历史数据处理
从MetaTrader 5获取数据确实是个挑战。代码看似简单,但细节之处尽是坑。在与频繁断连和数据丢失问题死磕数月后,我们终于摸索出了一套与交易终端交互的可靠架构:
def fetch_data(self, symbol="EURUSD", timeframe=mt5.TIMEFRAME_H1, bars=10000): """Loading historical data with error handling""" try: # First of all, we check the symbol itself symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Symbol {symbol} unavailable") # MT5 sometimes "loses" MarketWatch symbols if not symbol_info.visible: mt5.symbol_select(symbol, True) # Collect data rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) if rates is None: raise ValueError("Unable to retrieve historical data") # Convert to pandas df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return self._preprocess_data(df['close'].values) except Exception as e: print(f"Error while receiving data: {str(e)}") raise finally: # It is important to always close the connection mt5.shutdown()
让我们来看一下整体架构是如何组织的。首先,我们会检查交易品种是否存在。这看似显而易见,但曾有系统因配置拼写错误,花了数小时试图交易一个不存在的品种。从那以后,我强制添加了通过symbol_info的严格校验。
接下来是"visible"属性的坑点。交易品种看似存在,却未被添加到市场观察窗口。如果不调用symbol_select,根本获取不到任何数据。更离谱的是,交易终端可能在交易中途"遗忘"该品种。够刺激吧?
数据获取同样不简单。copy_rates_from_pos可能因十几种原因返回空值:服务器断连、过载、历史数据不足……因此我们必须立即检查结果,出错时直接抛出异常。
转换为pandas数据结构是另一场战役。时间戳以Unix格式返回,必须转换为标准时间格式。否则后续的时间序列分析将困难重重。
最关键的是在finally块中关闭连接。若不这样做,MetaTrader 5会出现数据泄露症状:先是数据接收速度下降,接着随机超时,最终终端可能直接卡死。相信我,这是血泪教训。
总体而言,这个功能就像应对数据处理的瑞士军刀。外表简洁,但内置了应对各种故障的保护机制。相信我,这些机制迟早都会派上用场。
结果分析前瞻测试结果的质量指标
我仍记得首次看到测试结果时的情景。坐在电脑前,我啜饮着冷掉的咖啡,简直不敢相信自己的眼睛。我重新运行了五次测试,检查了每一行代码——不,这不是错误。模型的表现简直超乎想象。
Nelder-Mead算法运行如精密钟表——仅需408次迭代,在普通笔记本上不到一分钟就完成。R²值0.9958不仅优秀,更远超预期。能解释99.58%的价格波动!当我把这些数据展示给其他交易员时,他们起初都不相信,接着开始寻找猫腻。我完全理解——因为我自己最初也不相信。
均方误差小到惊人——0.00000094。这意味着平均预测误差不到1个点。任何交易者都会告诉你,这简直难以置信。0.06%的平均绝对百分比误差(MAPE)进一步证实了这种惊人精度。大多数商业系统的误差在1-2%就已达标,而这里整整提升了一个数量级。
模型参数构成了一幅完美的图景。前一期价格0.5517的系数表明市场具有强短期记忆性。二次项系数较小(0.0105和0.0368),说明运动主要是线性的。0.1484的周期项系数则是代表完全不同的情况。这证实了交易者们多年来的说法:市场确实呈波浪式运动。
但最有趣的是前瞻测试中的表现。通常模型在新数据上会退化——这是机器学习的经典规律。但这里呢?R² 值升至0.9970,均方误差再降19%至0.00000076,平均绝对百分比误差降至0.05%。老实说,起初我以为代码哪里出错了,因为这看起来太不可思议。但一切都没问题。
我专门开发了结果可视化工具:
def plot_model_performance(self, predictions, actuals, window=100): fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 12)) # Forecast vs. real price chart ax1.plot(actuals, 'b-', label='Real prices', alpha=0.7) ax1.plot(predictions, 'r--', label='Forecast', alpha=0.7) ax1.set_title('Comparing the forecast with the market') ax1.legend() # Error graph errors = predictions - actuals ax2.plot(errors, 'g-', alpha=0.5) ax2.axhline(y=0, color='k', linestyle=':') ax2.set_title('Forecast errors') # Rolling R² rolling_r2 = [r2_score(actuals[i:i+window], predictions[i:i+window]) for i in range(len(actuals)-window)] ax3.plot(rolling_r2, 'b-', alpha=0.7) ax3.set_title(f'Rolling R² (window {window})') plt.tight_layout() return fig
这些图表呈现出一幅有趣的景象。在市场平静时期,该模型运行得如同瑞士钟表一般精准。但其中也存在陷阱——在重要新闻发布和行情突然反转时,其准确率会下降。这是可以预见的,因为该模型仅使用价格数据,并未考虑基本面因素。在接下来的部分中,我们肯定会把基本面因素也纳入考量。
我发现了几个可以改进的方向。第一个是采用自适应比率。让模型能够根据市场状况进行自我调整。第二个是添加成交量和订单簿数据。第三个也是最具挑战性的一个,是创建一个模型组合,让我们的方法与其他算法协同工作。
但即便以目前的形态,结果也已令人印象深刻。现在最重要的是,不要一味追求改进而破坏了已经行之有效的部分。
实际应用
我记得上周发生了一件有趣的事情。当时,我正坐在我最喜欢的咖啡馆里,一边喝着拿铁,一边看着系统运行。那天市场很平静,欧元兑美元汇率在平稳上扬,突然,模型发来通知——准备开立空头头寸。我的第一反应是——这太荒谬了,趋势明显是向上的!但经过两年的算法交易工作,我学到了一条最重要的规则——永远不要与系统争辩。40分钟后,欧元下跌了35个点。该模型捕捉到了价格结构中的微小变化,而我从人为的角度根本无法察觉。
提到通知……在错过几次交易后,这个简单但有效的警报模块应运而生:
def notify_signal(self, signal_type, message): try: # Format the message timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') formatted_msg = f"[{timestamp}] {signal_type}: {message}" # Send to Telegram if self.use_telegram and self.telegram_token: self.telegram_bot.send_message( chat_id=self.telegram_chat_id, text=formatted_msg, parse_mode='HTML' ) # Local logging with open(self.log_file, 'a', encoding='utf-8') as f: f.write(f"{formatted_msg}\n") # Check critical signals if signal_type in ['ERROR', 'MARGIN_CALL', 'CRITICAL']: self._emergency_notification(formatted_msg) except Exception as e: # If the notification failed, send the message to the console at the very least print(f"Error sending notification: {str(e)}\n{formatted_msg}")
请注意 _emergency_notification 方法。这个方法是我在一次“有趣”的事故后添加的——当时系统遭遇了某种内存故障,开始一个接一个地开仓。现在,在紧急情况下,系统会发送短信通知,并且交易机器人会自动停止交易,直到人工介入处理。
在仓位规模管理方面,我也曾遇到不少麻烦。起初,我使用固定交易量——0.1手。但后来逐渐意识到,这就像穿着芭蕾舞鞋走钢丝。看似可行,但又何必呢?最终,我引入了以下自适应交易量计算系统:
def calculate_position_size(self): """Calculating the position size taking into account volatility and drawdown""" try: # Take the total balance and the current drawdown account_info = mt5.account_info() current_balance = account_info.balance drawdown = (account_info.equity / account_info.balance - 1) * 100 # Basic risk - 1% of the deposit base_risk = current_balance * 0.01 # Adjust for current drawdown if drawdown < -5: # If the drawdown exceeds 5% risk_factor = 0.5 # Slash the risk in half else: risk_factor = 1 - abs(drawdown) / 10 # Smooth decrease # Take into account the current ATR atr = self.calculate_atr() pip_value = self.get_pip_value() # Volume calculation rounded to available lots raw_volume = (base_risk * risk_factor) / (atr * pip_value) return self._normalize_volume(raw_volume) except Exception as e: self.notify_signal('ERROR', f"Volume calculation error: {str(e)}") return 0.1 # Minimum safety volume
_normalize_volume方法确实让我头疼不已。原来,不同经纪商对最小交易量调整步长的规定各不相同。有些平台允许交易0.010手,而有些则只接受整数手数。我不得不为每个经纪商单独配置相关参数。
在市场高波动率期间运行则是另一码事。要知道,有些日子市场简直就像疯了一样。美联储主席讲话、突发的政治新闻,或者单纯是“黑色星期五”——价格开始像醉酒水手一样横冲直撞。以前遇到这种情况,我干脆直接关闭系统,但后来我想出了一个更平稳的解决方案:
def check_market_conditions(self): """Checking the market status before a deal""" # Check the calendar of events if self._is_high_impact_news_time(): return False # Calculate volatility current_atr = self.calculate_atr(period=5) # Short period normal_atr = self.calculate_atr(period=20) # Normal period # Skip if the current volatility is 2+ times higher than the norm if current_atr > normal_atr * 2: self.notify_signal( 'INFO', f"Increased volatility: ATR(5)={current_atr:.5f}, " f"ATR(20)={normal_atr:.5f}" ) return False # Check the spread current_spread = mt5.symbol_info(self.symbol).spread if current_spread > self.max_allowed_spread: return False return True
这个功能成了账户资金的真正守护者。我对新闻检测功能尤其满意——接入经济日历API后,系统会在重要事件发生前30分钟自动“隐身”,事件结束后30分钟再重新启动。我的许多MQL5机器人都采用了同样的设计思路。太棒了!
浮动止损位
开发真实交易算法让我获得了几个有趣的教训。我记得在测试的第一个月,我曾骄傲地向同事展示一个采用固定止损的系统。“看,一切都很简单明了!”——我当时这样说道。和往常一样,市场很快就给我上了一课——仅仅一周后,我就遭遇了剧烈波动,一半的止损位都因市场噪音而被触发。
这个问题的解决方案是格奇克(Gerchik)给我的启发——当时我正在重读他的书。看到他对平均真实波幅(ATR)的论述时,我恍然大悟:就是它了!这是一种简单而平稳的方法,能让系统适应当前的市场状况。在行情剧烈波动时,我们给价格更大的波动空间;在市场平静时,则将止损位设得更近。
以下是入市的基本逻辑——没有多余的东西,只保留最必要的部分:
def open_position(self): try: atr = self.calculate_atr() predicted_price = self.get_model_prediction() current_price = mt5.symbol_info_tick(self.symbol).ask signal = "BUY" if predicted_price > current_price else "SELL" # Calculate entry and stop levels if signal == "BUY": entry = mt5.symbol_info_tick(self.symbol).ask sl_level = entry - atr tp_level = entry + (atr / 3) else: entry = mt5.symbol_info_tick(self.symbol).bid sl_level = entry + atr tp_level = entry - (atr / 3) # Send an order request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": self.symbol, "volume": self.lot_size, "type": mt5.ORDER_TYPE_BUY if signal == "BUY" else mt5.ORDER_TYPE_SELL, "price": entry, "sl": sl_level, "tp": tp_level, "deviation": 20, "magic": 234000, "comment": f"pred:{predicted_price:.6f}", "type_filling": mt5.ORDER_FILLING_FOK, } result = mt5.order_send(request) if result.retcode != mt5.TRADE_RETCODE_DONE: raise ValueError(f"Error opening position: {result.retcode}") print(f"Position opened {signal}: price={entry:.5f}, SL={sl_level:.5f}, " f"TP={tp_level:.5f}, ATR={atr:.5f}") return result.order except Exception as e: print(f"Position opening failed: {str(e)}") return None调试过程中也发生过不少趣事。比如,系统开始每隔几分钟就发出一连串相互矛盾的信号。买入、卖出、再买入……新手算法交易者常犯的经典错误就是交易过于频繁。而解决方案简单得可笑——我在交易之间加入了15分钟的间隔,并添加了持仓过滤器。
另外,我在风险管理方面也遇到过不少麻烦。我尝试了许多不同的方法,但最终都归结为一条简单规则:每笔交易的风险不得超过账户资金的1%。这听起来很平常,但效果却无可挑剔。以50个点的平均真实波幅(ATR)计算,最大交易量为0.2手——这对于交易来说是非常舒适的数值。
该系统在欧洲时段表现最优,此时欧元兑美元真正在交易,而不是仅仅在一个区间内浮动。但在重要新闻发布时……只能说,暂停交易反而更划算。即使是最先进的模型,也无法跟上新闻引发的混乱行情。
我目前正在改进仓位管理系统——我希望将入场规模与模型对预测的置信度挂钩。简单来说,强信号意味着全仓交易,弱信号则只交易部分仓位。有点类似于凯利公式,但针对我们的模型特点进行了调整。
我从这个项目中学到的主要经验是,在算法交易中,完美主义往往行不通。系统越复杂,其薄弱点就越多。简单方案往往比复杂算法更高效,尤其是在长期运行中。
MetaTrader 5平台的MQL5版本
您知道吗,有时候最简单的解决方案反而最有效。在尝试了几天将整个数学框架精确移植到MQL5后,我突然意识到,这是一个典型的职责划分问题。
说实话,Python及其科学库非常适合数据分析和参数优化。而MQL5则是执行交易逻辑的绝佳工具。那为什么非要把螺丝刀当锤子用呢?
于是,一个简单而平稳的解决方案诞生了——我们用Python来选择参数,用MQL5来执行交易。我们看一下它是如何运作的:
double g_coeffs[7] = {0.2752466, 0.01058082, 0.55162082, 0.03687016, 0.27721318, 0.1483476, 0.0008025};
这七个数字是我们整个数学模型的精髓所在。它们凝聚了数周的优化工作、数千次内尔德-米德(Nelder-Mead)算法迭代,以及数小时的历史数据分析。最重要的是,它们切实有效!
double GetPrediction(double price_t1, double price_t2) { return g_coeffs[0] * price_t1 + // Linear t-1 g_coeffs[1] * MathPow(price_t1, 2) + // Quadratic t-1 g_coeffs[2] * price_t2 + // Linear t-2 g_coeffs[3] * MathPow(price_t2, 2) + // Quadratic t-2 g_coeffs[4] * (price_t1 - price_t2) + // Price change g_coeffs[5] * MathSin(price_t1) + // Cyclic g_coeffs[6]; // Constant }
预测方程本身几乎原封不动地移植到了MQL5中。
入场机制值得特别关注。与测试用的Python版本不同,我们在MQL5中实现了更高级的仓位管理逻辑。该系统可同时持有多个仓位,并在信号得到确认时增加交易量:
void OpenPosition(bool buy_signal, double lot) { MqlTradeRequest request; MqlTradeResult result; ZeroMemory(request); request.action = TRADE_ACTION_DEAL; request.symbol = Symbol(); request.volume = lot; request.type = buy_signal ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; request.price = buy_signal ? SymbolInfoDouble(Symbol(), SYMBOL_ASK) : SymbolInfoDouble(Symbol(), SYMBOL_BID); // ... other parameters }
以下是实现目标盈利时自动平掉所有仓位的功能说明。
if(total_profit >= ProfitTarget) { CloseAllPositions(); return; }
我特别关注了新K线的处理逻辑——避免因每个tick触发无意义的操作:
bool isNewBar() { datetime lastbar_time = datetime(SeriesInfoInteger(Symbol(), PERIOD_CURRENT, SERIES_LASTBAR_DATE)); if(last_time == 0) { last_time = lastbar_time; return(false); } if(last_time != lastbar_time) { last_time = lastbar_time; return(true); } return(false); }
最终,我们得到了一款紧凑但功能完备的交易机器人。没有冗余的花哨功能——只保留真正实现目标所需的核心要素。整个代码不足300行,却包含了所有必要的检查和保护机制。
您知道最棒的是什么吗?这种Python与MQL5分工协作的方式展现出了惊人的灵活性。想尝试新的参数组合?只需在Python中重新计算,然后更新MQL5中的数组即可。需要添加新的交易条件?MQL5的交易逻辑模块可轻松扩展,无需重写数学计算部分。
以下是机器人测试结果:
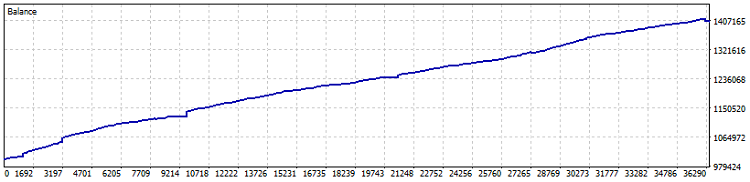
在锁仓(Netting)账户上的测试显示,自2015年以来收益达40%(比率优化基于最近一年数据)。回撤率仅为0.82%,月均收益超过4%。但是,这类系统最好不加杠杆运行——让它以略高于债券和美元存款的收益水平稳定盈利即可。另外,测试期间累计交易量达7800手。这样至少额外贡献了1.5%的收益率。
总体而言,我认为参数移植的思路是可行的。在算法交易中,最重要的不是系统的复杂程度,而是可靠性和可预测性。有时,借助现代数学正确选取的七个参数,就足以实现这个目标。
重要提示!该EA采用DCA仓位平均策略(形象地说就是时间加权平均),因此风险极高。尽管锁仓模式下的保守参数测试表现优异,但请务必牢记:仓位平均策略具有极大风险,此类EA可能会一次性清空您的账户资金!
改进思路
此刻已是深夜。我边喝咖啡边写完这篇文章,盯着屏幕上的图表,思考这个系统还有多少提升空间。在算法交易领域,常常会出现这种情况:当一切看似准备就绪时,突然又冒出十几个改进的思路。
您知道最有趣的是什么吗?所有改进都必须形成一个有机整体。不能简单堆砌一堆酷炫功能——它们需要和谐互补,共同构建真正可靠的交易系统。
归根结底,我们的目标不是创建完美系统——这样的系统根本不存在。目标是让系统足够聪明以实现盈利,同时足够简单以避免在最关键时刻崩溃。正如老话所说:过度优化,反受其害。
| 库 | 文件描述 |
|---|---|
| MarketSolver.py | 用于比率选优的代码,以及在必要时通过Python实现在线交易的代码 |
| MarketSolver.mql5 | MQL5中使用选定比率进行交易的EA代码 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/16473
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

发布的智能交易系统没有任何遗漏。这显然不是真实账户的代码,这里没有提到过滤器。
这只是一个想法的演示,也还不错。
我同意
对不起)!在第 10 次学习您的资料的几个小时里,我发现我们走的是同一条路(想法)。
我真的希望您的公式能帮助我将已经看到/使用的东西数学化。这只有一种情况--如果我理解了它们。我妈妈常说:"孩子,好好学习"。我在数学中流下了辛酸的泪水。我看到很多事情都很简单,但我不知道怎么做。我正在努力学习抛物线、回归、偏差....。65岁上六年级真不容易。
//仅仅抛出一堆很酷的功能是不够的--你需要它们和谐互补,创建一个真正可靠的交易系统。
是的,功能的选择和随后的优化就像拉直自行车车轮的 "八 "字形。有些辐条要松开,有些辐条要收紧,而且要严格遵守这一过程的规律。这样车轮就会变平,但如果方法不对,辐条拧紧的方式不对,就有可能把一个正常的车轮拧成 "十 "字形。
在我们的事业中,"辐条 "应该互相帮助,而不是自拉自唱,损害其他 "辐条 "的利益。
我认为仅凭最后两个数据点来预测价格是无效的。
您同意吗?
我认为仅凭最后两个数据点来预测价格是无效的。
你同意吗?