
Von der Grundstufe bis zur Mittelstufe: Union (II)

Einführung
Der hier dargestellte Inhalt ist ausschließlich für Bildungszwecke bestimmt. Die Anwendung sollte unter keinen Umständen zu einem anderen Zweck als zum Erlernen und Beherrschen der vorgestellten Konzepte verwendet werden.
Im vorherigen Artikel „Von der Grundstufe zur Mittelstufe: Union (I)“, haben wir begonnen, darüber zu diskutieren, was eine Union ist. In der Tat hat sich dieses Thema seit dem ersten Artikel aufgebaut, da alles, was bisher besprochen wurde, und alles, was in zukünftigen Artikeln behandelt werden wird, in irgendeiner Weise miteinander verbunden ist. Die Ausführungen in diesem Artikel stellen nur den ersten Teil des umfassenderen Themas der Union dar. Dieses Thema ist recht umfangreich, ähnlich wie das Thema der Arrays, das eng damit zusammenhängt.
In diesem Artikel werden wir uns daher näher mit der Union befassen. Wir werden auch unser Verständnis von Arrays ein wenig erweitern. Lehnen Sie sich also zurück, machen Sie es sich bequem, und lassen Sie uns in das erste Thema dieses Artikels eintauchen.
Arrays und Unions
Unions sind ein wirklich interessantes Thema in der Programmierung, das die Tür zu fortgeschritteneren Konzepten öffnet. Es ist jedoch wichtig, mit Vorsicht vorzugehen. Ein häufiger Fehler ist die Annahme, dass das Verstehen der Grundlagen gleichbedeutend mit der Beherrschung des Konzepts ist.
Viele Menschen missverstehen Unions, weil sie glauben, dass sie sich bei der Deklaration einer Union auf ein einfaches, bei der Deklaration definiertes Modell beschränkt haben. In Wirklichkeit ist viel mehr möglich, wenn wir die Konzepte richtig anwenden.
Im vorigen Artikel habe ich erwähnt, dass wir bei der Erstellung - oder genauer gesagt bei der Deklaration - einer Union einen neuen, spezialisierten Datentyp definieren. In gewisser Weise ähnlich wie eine Zeichenkette behandelt wird. Einige Leser könnten jedoch ein ungutes Gefühl haben oder skeptisch sein, wenn sie sehen, dass bestimmte Konstrukte mit einem solchen Datentyp verwendet werden.
Um zu zeigen, wie nützlich dies sein kann und warum sich jemand dafür entscheiden könnte, müssen wir ein kleines, aber entscheidendes Detail verstehen. Da eine Union in der Tat ein neuer und spezieller Datentyp ist, können wir ihn auf verschiedene Weise verwenden, sowohl in seiner Deklaration als auch in der Art und Weise, wie wir ihn in einem bestimmten Kontext manipulieren. Schauen wir uns unser erstes Beispiel an.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits; 07. uchar u8_bits[4]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info[2]; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. for (uchar c = 0; c < info.Size(); c++) 20. info[c] = Swap(info[c]); 21. View(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg[], ulong value) 25. { 26. arg[0].u32_bits = (uint)(value >> 32); 27. arg[1].u32_bits = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg[]) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg[c].u32_bits); 35. } 36. //+------------------------------------------------------------------+ 37. un_01 Swap(const un_01 &arg) 38. { 39. un_01 info = arg; 40. 41. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = info.u8_bits[i]; 44. info.u8_bits[i] = info.u8_bits[j]; 45. info.u8_bits[j] = tmp; 46. } 47. 48. return info; 49. } 50. //+------------------------------------------------------------------+
Code 01
Wenn wir Code 01 ausführen, wird das MetaTrader 5-Terminal die folgende Ausgabe anzeigen:
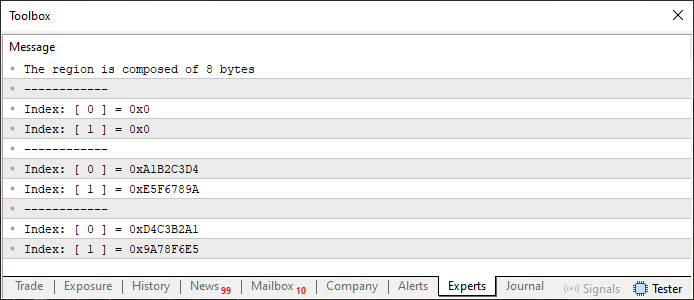
Abbildung 01
In diesem Code 01-Beispiel wenden wir alles an, was wir bisher gelernt haben, sowohl bei der Arbeit mit Arrays als auch bei der Arbeit mit Unions. Beachten Sie Zeile 12: Wir deklarieren ein statisches Array. Auf den ersten Blick mag dies etwas seltsam erscheinen, vor allem, wenn Sie bisher davon ausgegangen sind, dass nur primitive Typen in Arrays verwendet werden können. Aber hier verwenden wir einen speziellen Typ, den wir in Zeile 4 definiert haben. So einfach ist das.
In Zeile 14 sagt uns die erste gedruckte Information, dass die Variable „info“ aus 8 Bytes besteht. Auf den ersten Blick mag dies nicht viel Sinn ergeben. Wenn das Ihre Reaktion ist, liebe Leserin, lieber Leser, empfehle ich Ihnen, den vorherigen Artikel noch einmal zu lesen. Denn „info“ ist tatsächlich 8 Byte groß - das liegt am größten Mitglied in der Union, u32_bits, das vom Typ uint ist. Im Wesentlichen deklarieren wir etwas, das der unten dargestellten Struktur sehr ähnlich ist.
. . . 12. uint info[2]; . . .
Ich glaube nicht, dass Sie das verwirren wird. Es gibt jedoch eine versteckte Anweisung in derselben Zeile, die einem aufmerksamen Programmierer ebenfalls auffallen könnte. Das ist genau das, was wir unten sehen:
. . . 12. uchar info[2][4]; . . .
Wow! Moment mal - was wollen Sie damit sagen? Gibt es zwei verschiedene Möglichkeiten, denselben Code anzuzeigen? Zwei Arten, das Gleiche zu schreiben? Jetzt bin ich wirklich verwirrt - das ergibt für mich keinen Sinn.
Und genau deshalb, liebe Leserin, lieber Leser, habe ich die Notwendigkeit betont, das zu studieren und zu praktizieren, was in jedem Artikel gezeigt wird. Ein häufiges Problem, das ich vor allem bei Anfängern sehe, ist ein übermäßiges Vertrauen in Syntax und Codierungsmuster. Viele versuchen gar nicht erst, das zugrunde liegende Konzept zu verstehen, sondern konzentrieren sich nur auf den Code, wie er geschrieben ist.
Wie im vorigen Artikel erwähnt, schaffen wir mit der Erstellung einer Vereinigung eine Möglichkeit, Daten in kleinere Segmente zu unterteilen und gemeinsam zu nutzen. Sie können einen langen Speicherblock in kleinere Teile aufteilen, um bestimmte Segmente davon zu bearbeiten. Auf diese Weise können wir bestimmte Punkte drehen, verschieben oder verändern, ohne explizit bestimmte Operatoren zu verwenden. Nicht weil die Union magisch sind, sondern weil sie es uns ermöglichen, ein und dieselben Daten im Speicher gleichzeitig auf mehrere Arten zu interpretieren.
Auch wenn ich es vorhin nicht erwähnt habe, bedeuten beide Schreibweisen von Zeile 12 dasselbe. Der Unterschied liegt lediglich darin, wie die Daten segmentiert werden. Im ersten Fall haben wir ein Array mit zwei Elementen, die jeweils 4 Byte groß sind. Im zweiten Fall haben wir wieder zwei Elemente, jedes immer noch 4 Bytes, aber anders strukturiert. Für viele Menschen sind mehrdimensionale Arrays schwer zu verstehen. Aber eigentlich ist ein mehrdimensionales Array (wie das in der zweiten Version von Zeile 12) nur dasselbe Array, nur in einer anderen Form geschrieben.
Mehrdimensionale Arrays sind in verschiedenen Zusammenhängen unglaublich nützlich, aber sie werden leichter zu verstehen sein, wenn wir uns mit dem Thema Matrizen befassen, das wir in einem späteren Artikel behandeln werden. Bis dahin ist es nicht nötig, darauf einzugehen. Haben Sie Geduld, lieber Leser, und konzentrieren Sie sich auf das, was wir hier und jetzt erforschen. Mit anderen Worten: Leben Sie in der Gegenwart, machen Sie sich keine Gedanken über das, was als Nächstes kommt.
Nach dieser ersten Erläuterung und der Klärung einiger möglicherweise verwirrender Punkte in Bezug auf den Code 01 können wir nun zu etwas Neuem übergehen.
Ein wichtiger Hinweis: Ich werde nicht näher darauf eingehen, wie Code 01 funktioniert, da dies bereits in früheren Artikeln behandelt wurde. Alles, was dort gemacht wird, ist schon einmal gezeigt und erklärt worden. Wenn Sie Schwierigkeiten haben, es zu verstehen, empfehle ich Ihnen, sich das frühere Material anzusehen. Ich möchte, dass Sie verstehen, was getan wird, damit Sie Ihre eigene Lösung erstellen können - eine, die genau das gleiche Ergebnis wie in den Bildern zeigt. Nicht ein ähnliches, sondern ein identisches Ergebnis.
Nach dieser Klarstellung kommen wir zu unserem nächsten Beispiel, das wir im Folgenden vorstellen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. info = Swap(info); 20. View(info); 21. } 22. //+------------------------------------------------------------------+ 23. void Set(un_01 &arg, ulong value) 24. { 25. arg.u32_bits[0] = (uint)(value >> 32); 26. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 27. } 28. //+------------------------------------------------------------------+ 29. void View(const un_01 &arg) 30. { 31. Print("------------"); 32. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 33. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 34. } 35. //+------------------------------------------------------------------+ 36. un_01 Swap(const un_01 &arg) 37. { 38. un_01 info = arg; 39. 40. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 41. { 42. tmp = info.u8_bits[i]; 43. info.u8_bits[i] = info.u8_bits[j]; 44. info.u8_bits[j] = tmp; 45. } 46. 47. return info; 48. } 49. //+------------------------------------------------------------------+
Code 02
Schauen wir uns nun ein Codebeispiel an, das bei der Ausführung ein anderes Ergebnis liefert. Dies ist der Fall bei Code 02. Auf den ersten Blick scheint er fast identisch mit Code 01 zu sein, nicht wahr? Sobald sie jedoch ausgeführt wird, erzeugt sie eine andere Ausgabe:
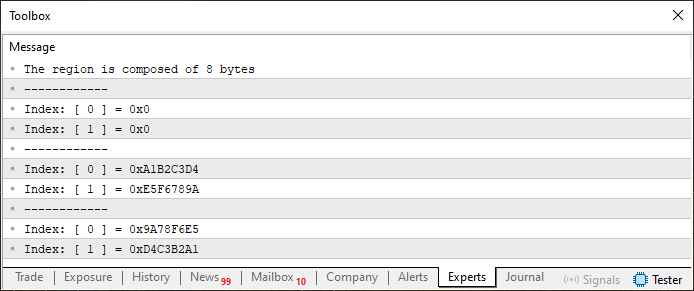
Abbildung 02
Sie denken jetzt vielleicht: „Aber das sieht genauso aus wie in Bild 01!“ Schauen Sie sich Abbildung 02 noch einmal genauer an und vergleichen Sie sie mit Abbildung 01. Erscheinen sie Ihnen immer noch identisch, auch wenn Sie jeden Wert sorgfältig geprüft haben? Denn in Wirklichkeit sind sie unterschiedlich. Und der Grund dafür liegt in der Art und Weise, wie die Vereinigung erklärt wird. Dieses Mal enthält die Vereinigung zwei Arrays, die beide statisch sind. Aber irgendetwas daran scheint nicht ganz logisch zu sein. In Code 01 hatte das in Zeile 7 deklarierte Array vier Elemente. Aber jetzt sind es acht. Warum? Hätten wir nicht einfach die gleichen vier Elemente beibehalten können?
Um dies richtig zu verstehen, müssen wir es aufschlüsseln. Zunächst müssen wir uns überlegen, warum die Anzahl der Elemente geändert wurde und welche Auswirkungen dies auf die Union hat. Aufgrund eines kleinen mathematischen Details und um den Code nicht unnötig zu verkomplizieren, werden wir die Anzahl der Elemente in dem in Zeile 7 deklarierten Array so ändern, dass sie immer GERADE ist. Wenn es sich um eine ungerade Zahl handelt, führt dies zu einem kleinen Problem, das die Interpretation der Ergebnisse erschwert. Verwenden Sie dort also immer eine gerade Zahl. Nehmen wir an, dass wir anstelle von acht Elementen nur sechs festlegen. Alles andere im Code bleibt unverändert. Daraus ergibt sich die folgende Struktur:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[6]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
Fragment 01
Hier haben wir nur den Wert in Zeile 7 geändert. Wenn wir den Code 02 mit dieser Änderung ausführen, erhalten wir die unten dargestellte Ausgabe:
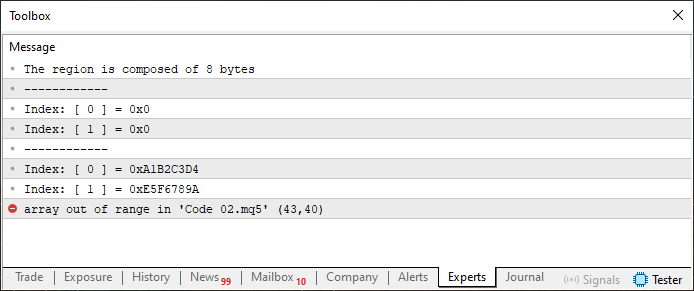
Abbildung 03
Hmm, das ist nicht gut gelaufen. Ändern wir nun den Wert in Zeile 7 erneut, diesmal auf zehn Elemente. Die aktualisierte Version sieht wie folgt aus:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[10]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
Fragment 02
Wenn Sie diese Version ausführen, sieht die Ausgabe wie folgt aus:
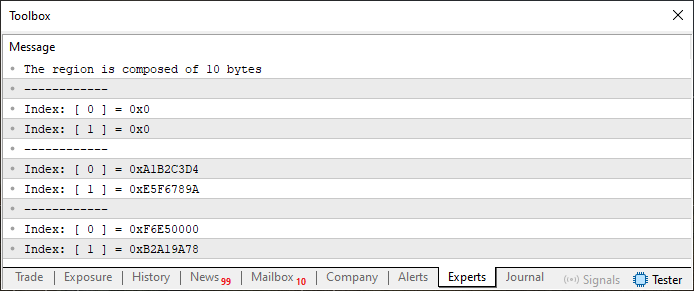
Abbildung 04
Auch dieses Ergebnis sieht nicht sehr vielversprechend aus. Einige der Werte scheinen verschwunden zu sein. An dieser Stelle fragen Sie sich vielleicht: Warum ist das passiert? Nun, genau deshalb sind wir hier - um Ihnen zu helfen, etwas zu verstehen, das auf den ersten Blick vielleicht nicht viel Sinn ergibt. Aber mit zunehmender Erfahrung und ständiger Übung wird es einfacher zu erkennen, wie und warum sich die Dinge so verhalten, wie sie es tun. Der Schlüssel ist immer, sich auf das Verständnis des angewandten Konzepts zu konzentrieren.
Gehen wir zurück zum ersten geänderten Fall, der zu Abbildung 03 führte und einen Fehler auslöste, der anzeigte, dass der Code versuchte, auf Speicher außerhalb der Grenzen zuzugreifen. Dieser Fehler trat auf, weil die Variable „info“ aus acht Bytes besteht. Passen Sie jetzt gut auf: Innerhalb der Union enthält das Array u8_bits sechs Elemente oder sechs Bytes, da jedes Element vom Typ uchar ist, der ein Byte breit ist. Wenn also die Variable j (die zu diesem Zeitpunkt auf das achte Element von u8_bits verweist) verwendet wird, versucht das Programm, auf Speicherbereiche zuzugreifen, die nicht zum Array gehören. Deshalb schlägt der Code in Zeile 43 fehl. Aber dieser Fehler ist nicht auf die Verwendung von mehr oder weniger Elementen in u8_bits zurückzuführen. Bevor wir uns damit befassen, wie man den Code richtig anpasst, um sechs Elemente in u8_bits zu ermöglichen, wollen wir zunächst verstehen, was im zweiten Fall passiert - dem von Bild 04.
In diesem zweiten Szenario können Sie sehen, dass info zehn Bytes bzw. zehn Elemente enthält. Das liegt daran, dass u8_bits ebenfalls mit zehn Elementen deklariert wurde. Wenn also die Funktion Swap ausgeführt wird (wie in Zeile 36 zu sehen), wird ein Teil der Werte durch Nullen überschrieben, die durch die Prozedur in Zeile 15 initialisiert wurden. Mit anderen Worten: ZeroMemory löscht den gesamten mit der Variablen „info“ verbundenen Speicherblock.
Aus diesem Grund scheinen einige Werte „verschwunden“ zu sein. Aber in Wirklichkeit wurden sie einfach verschoben oder an anderer Stelle im Speicher ersetzt. Um dies zu demonstrieren, werden wir eine kleine Änderung am Code vornehmen. Um die gleichen Probleme zu vermeiden, die wir in den Bildern 03 und 04 gesehen haben, ist die neue Version des Codes unten dargestellt:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. Set(info, 0xA1B2C3D4E5F6789A); 17. View(info); 18. Debug(info); 19. info = Swap(info); 20. View(info); 21. Debug(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg, ulong value) 25. { 26. arg.u32_bits[0] = (uint)(value >> 32); 27. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 35. } 36. //+------------------------------------------------------------------+ 37. void Debug(const un_01 &arg) 38. { 39. string sz = ""; 40. 41. Print("*************"); 42. for(uchar c = 0; c < (uchar)arg.u8_bits.Size(); c++) 43. sz = StringFormat("%s0x%X ", sz, arg.u8_bits[c]); 44. PrintFormat("Number of elements in %cinfo.u8_bits.Size()%c is %d\nInternal content is [ %s ]", 34, 34, arg.u8_bits.Size(), sz); 45. Print("*************"); 46. } 47. //+------------------------------------------------------------------+ 48. un_01 Swap(const un_01 &arg) 49. { 50. un_01 info = arg; 51. 52. for (uchar i = 0, j = (uchar)(info.u8_bits.Size() - 1), tmp; i < j; i++, j--) 53. { 54. tmp = info.u8_bits[i]; 55. info.u8_bits[i] = info.u8_bits[j]; 56. info.u8_bits[j] = tmp; 57. } 58. 59. return info; 60. } 61. //+------------------------------------------------------------------+
Code 03
Wenn wir diesen Code ausführen, werden wir etwas ähnliches wie das folgende Bild sehen.
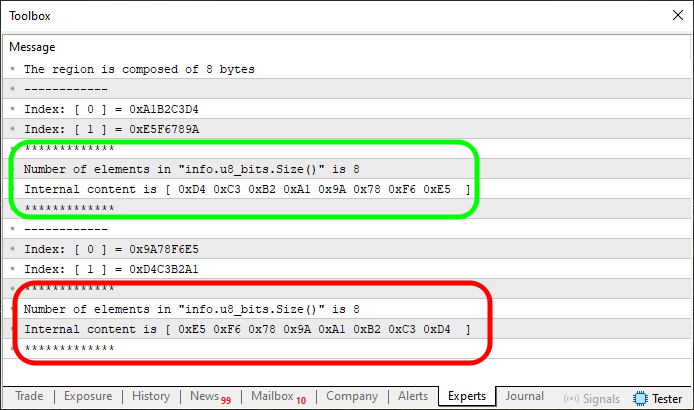
Abbildung 05
An dieser Stelle sind die Dinge viel einfacher zu verstehen. Zwei spezifische Regionen sind in Abbildung 05 hervorgehoben. Denken Sie daran, dass dieser Code 03 eine modifizierte Version von Code 02 ist, und auch hier interessiert uns die Zeile 7. Um die Vorgänge zu vereinheitlichen und besser zu verstehen, haben wir denselben Wert für das Array in Zeile 7 in Code 03 wiederverwendet, der zuvor in Code 02 verwendet wurde. Dies ergibt die in Abbildung 05 dargestellte Ausgabe.
Passen Sie gut auf, lieber Leser. Dies ist wichtig, wenn Sie diese Ergebnisse auf Ihrem eigenen Rechner reproduzieren wollen. In Zeile 52 von Code 03 habe ich eine Änderung vorgenommen, um den gleichen Fehler wie in Abbildung 03 zu vermeiden. Mit dieser Änderung können wir nun tun, was wir zuvor versucht haben.
Wenden wir zunächst Fragment 01 auf Code 03 an. Wenn wir dies tun, erhalten wir das unten gezeigte Ergebnis:
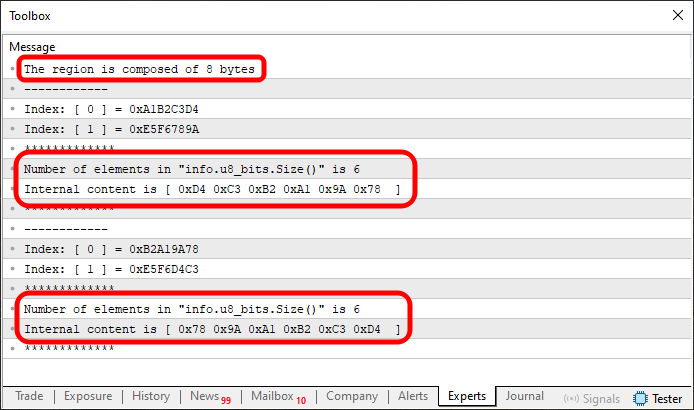
Abbildung 06
Auch hier habe ich wichtige Punkte markiert, denn es ist wichtig, dass Sie verstehen, was unter der Haube passiert. Auch wenn wir mit einer geringeren Anzahl von Elementen in u8_bits arbeiten, wird die Operation trotzdem ausgeführt. Schauen Sie sich jedoch den Inhalt von Index eins an. Sie werden feststellen, dass ein Teil der Daten unverändert bleibt. Warum? Bevor wir diese Frage beantworten, wenden wir das Fragment 02 auf den Code 03 an.
Daraufhin erhalten wir das in der folgenden Abbildung dargestellte Ergebnis:
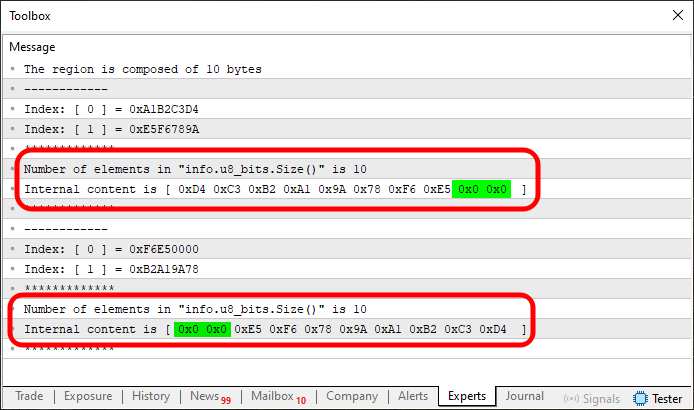
Abbildung 07
Ja, es ist jetzt klar, dass die Dinge nicht so einfach sind, wie sie anfangs schienen. Aber keine Sorge, lieber Leser. Hier ist eigentlich alles einfach und praktisch. Man muss sich nur die Zeit nehmen, sich zu konzentrieren und zu üben. Sie können den Artikel nicht einfach durchlesen und erwarten, dass Sie ihn beherrschen. Sie brauchen praktische Erfahrung. Sowohl in Abbildung 06 als auch in Abbildung 07 ist zu sehen, dass der Speicher wie erwartet gedreht oder gespiegelt wird. Die Werte, die in den Array-Indizes angezeigt werden, wenn man direkt auf die u32_bits-Elemente zugreift, sind jedoch möglicherweise nicht das, was man ursprünglich erwartet hat. Das liegt daran, dass wir es mit unterschiedlichen Speicherzusammensetzungen zu tun haben.
Wenn das von Ihnen deklarierte Array den Speicherbereich vollständig abdeckt, erhalten Sie eine perfekte Darstellung. Aus diesem Grund erscheint Abbildung 05 genau wie erwartet. Wenn Sie diesen Speicherblock jedoch unter- oder überfüllen, Teile unbedeckt lassen oder mehr als nötig hinzufügen, wird das Ergebnis verzerrt und verstreut. Dies ist in den Abbildungen 06 und 07 zu sehen. Bei der einen ist die Region unterbesetzt, bei der anderen überbesetzt.
Verstehen Sie nun, warum es so wichtig war, die Anzahl der Elemente in Zeile 7 zu ändern? Wenn man das nicht richtig handhabt, kommt es in bestimmten Situationen zu einer falschen Speicherabdeckung. Deshalb ist es wichtig, zu experimentieren und verschiedene Wege auszuprobieren, um Dinge zu erreichen. Die angehängten Dateien sind nicht nur Dekorationselemente für den Artikel, sondern dienen dazu, dass Sie sie nutzen und daraus lernen können. Testen Sie sie, optimieren Sie sie, und beobachten Sie, was sich ändert. Erst dann werden Sie ein solides Verständnis für jedes in diesen Artikeln behandelte Programmierelement entwickeln. So wird man von einem „Copy-Paste“-Programmierer zu einem wirklich hervorragenden Programmierer.
Wir haben eine solide Grundlage für das Studium und die Interpretation der hier vorgestellten Materialien geschaffen. Ich glaube, Sie sind bereit, ein Problem in Angriff zu nehmen, das bereits in dem Artikel „Von der Grundstufe bis zur Mittelstufe: Arrays (IV)“ vorgestellt wurde. Wir werden diesen Code sogar noch besser machen. Um das zu erklären, wechseln wir zu einem neuen Thema.
Etwas Gutes noch besser machen
Was wir hier vorhaben, ist sowohl lustig als auch praktisch. Um das Folgende vollständig zu verstehen, müssen Sie jedoch den Inhalt des vorherigen Abschnitts beherrschen. Andernfalls könnten Sie sich verwirrt und verloren vorkommen. Also nichts überstürzen. Nehmen Sie sich die Zeit, alles bisher Gezeigte sorgfältig zu studieren, und erst dann sollten Sie sich der nächsten Herausforderung mit MQL5 stellen.
Nun, da die Warnung aus dem Weg geräumt ist, lassen Sie uns zum Kern dieses Themas kommen. Zu Beginn werden wir uns ein Stück Code ansehen, das in dem bereits erwähnten Artikel geteilt wurde. Dieses Beispiel ist unten dargestellt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
Code 04
Die Ausführung dieses Codes 04 führt zu dem unten dargestellten Ergebnis:
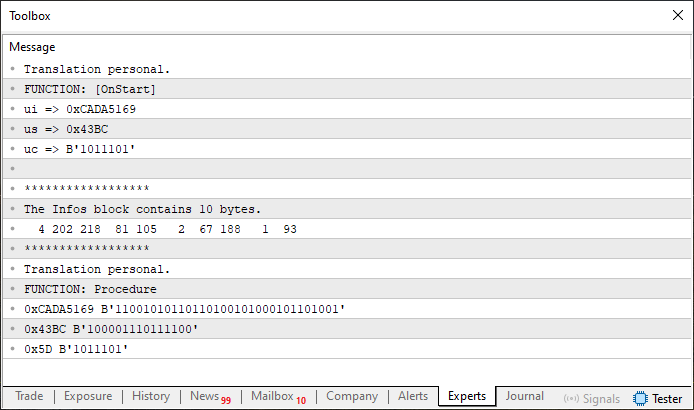
Abbildung 08
Hier ist die Herausforderung: Ihre Aufgabe ist es, Code 04 in etwas zu verwandeln, das einfacher und eleganter zu implementieren ist, indem Sie das nutzen, was Sie bis jetzt gelernt haben. Sie denken jetzt vielleicht: „Wie soll ich als jemand, der gerade erst programmieren lernt, das Gelernte umsetzen und den Code tatsächlich verbessern? Das ist Wahnsinn!“ Doch wer sich nicht selbst herausfordert oder seine Komfortzone verlässt, fällt schnell zurück.
Ständig werden neue Techniken und bessere Konzepte entwickelt, die unsere Arbeit erleichtern, unseren Code effizienter machen und echte Programmierer von denen unterscheiden, die nur kopieren und einfügen. Denn bei jedem Schritt sehen wir neue Möglichkeiten, das gleiche Ergebnis zu erzielen, aber auf einfachere Weise. Gehen wir also der Frage nach, wie wir die Konzepte von vorhin anwenden können, um Code 04 zu verbessern. Zu diesem Zweck müssen wir zunächst analysieren, was der aktuelle Code tatsächlich tut.
Im Wesentlichen werden Sie sehen, dass einige Variablen in einer bestimmten Reihenfolge deklariert und verwendet werden. Die Variable mit der größten Speicherbreite ist vom Typ uint, wird in Zeile 8 deklariert und zwischen den Zeilen 28 und 35 verwendet. Die anderen verwendeten Datentypen sind kleiner. Mit diesem Wissen können wir über eine Lösung nachdenken, bei der das in Zeile 12 deklarierte Array „Info“ die Informationen so erhält, dass es dieselbe interne Speicherstruktur erzeugt. Aber was genau ist diese Speicherstruktur? Wie können wir wissen, ob unsere neue Implementierung korrekt ist?
Sehen Sie sich Abbildung 08 an - an einer bestimmten Stelle wird der genaue Inhalt des Arrays „Info“ angezeigt. Alles, was wir also tun müssen, ist, das gleiche Ergebnis zu erzielen, aber so, dass der Code angenehmer zu nutzen ist.
Großartig. Das ist das Ziel. Und wie in diesem und dem vorangegangenen Artikel gezeigt, können wir die Union nutzen, um die Daten besser zu organisieren. Und wie genau machen wir das? Zunächst müssen Sie eine ordnungsgemäß deklarierte Vereinigung erstellen, die die Werte enthält. Da wir uint-, ushort- und uchar-Werte verwenden werden (basierend auf den Operationen zwischen den Zeilen 28 und 48), könnten Sie denken, dass Sie drei verschiedene Unions benötigen. Aber eigentlich brauchen Sie nur einen. So sieht es im folgenden Codefragment aus:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { . . .
Fragment 03
Sehr gut. Schauen Sie sich Fragment 03 an. In Zeile sechs erstellen wir eine Union, und in den folgenden Zeilen deklarieren wir diskrete Typen, die später verwendet werden sollen. Auf den ersten Blick mag dies etwas verwirrend erscheinen. Der Teil, der uns wirklich interessiert, ist jedoch Zeile elf. Hier ermöglichen wir den Zugriff auf den gesamten Speicherbereich, der von den Union-Datentypen umfasst wird. Beachten Sie, dass ich ein statisches Array mit einer Anzahl von Elementen deklariere, die der Größe des größten diskreten Typs innerhalb der Union entspricht. Dies ist ein guter Ansatz, wenn Sie nicht sicher sind, wie viele Bytes innerhalb einer Union benötigt werden.
Jetzt werden Sie vielleicht denken: „Warten Sie einen Moment. Wenn ich es richtig verstehe, ändern wir nicht nur eine bestimmte Variable, wenn wir einen Wert (oder besser gesagt, eine Variable) in einer Union ändern. Das wirkt sich auch auf alle anderen aus, da sie sich denselben Speicherplatz teilen. Ist das richtig?“ Ja, liebe Leserin, lieber Leser, Sie haben völlig recht. Daraus könnte man dann schließen: „Wir können die in diesem Fragment deklarierte Vereinigung nicht verwenden. Denn sobald wir einer der Variablen einen Wert zuweisen, werden auch die anderen davon betroffen sein.“ Und auch hier haben Sie Recht. Ich habe jedoch noch nicht erklärt, was wir hier nutzen werden.
Wir sind nicht wirklich an dem spezifischen Wert interessiert, der einer bestimmten Variablen zugewiesen ist. Das, was uns interessiert, ist in dem Array enthalten. Darauf kommt es bei der Konstruktion des Systems an. Wenn Sie das in den vorangegangenen Artikeln vorgestellte Material gründlich verstanden haben (und, was noch wichtiger ist, wenn Sie geübt haben), sollten Sie erkannt haben, dass wir ein Feld in ein anderes kopieren können. Wenn wir wissen, wie viele Elemente wir kopieren wollen und aus welchem Array wir kopieren, können wir den Codeblock in den Zeilen 28 bis 48 erheblich verbessern. Es ist ganz einfach: Wir kopieren Arrays. Dazu verwenden wir den unten stehenden Code.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
Code 05
Wenn wir Code 05 ausführen, sehen wir folgendes Ergebnis.
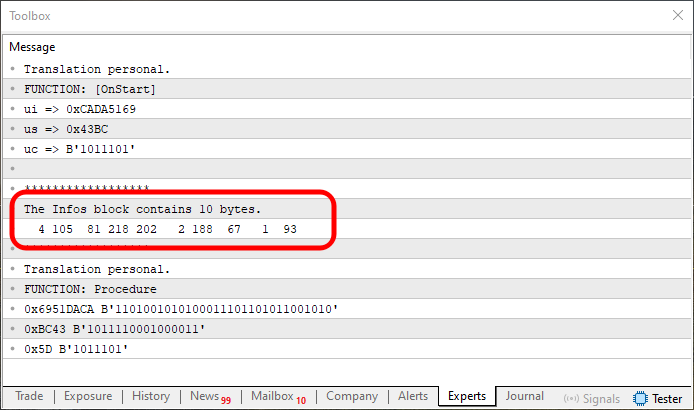
Abbildung 09
Es scheint funktioniert zu haben. Aber genau das ist hier nicht passiert. Wenn Sie den markierten Bereich in Abbildung 09 genau betrachten und mit Abbildung 08 vergleichen, werden Sie feststellen, dass die Werte gedreht oder gespiegelt erscheinen. Das ist jedoch kein Problem für uns, denn ich habe bereits gezeigt, wie man Werte umkehren oder spiegeln kann. Doch bevor wir diesen Weg einschlagen, möchte ich Ihnen eine andere mögliche Lösung zeigen, die je nach Fall ausreichend sein könnte.
Beachten Sie, dass die in Abbildung 09 gezeigten Werte nicht nur im Speicher, sondern auch zwischen der in OnStart angezeigten Ausgabe und der in Procedure angezeigten Ausgabe gespiegelt werden. Je nach spezifischem Kontext - und das ist wichtig zu betonen - können wir jedoch die Tatsache ignorieren, dass das Array gespiegelt ist, und stattdessen den unten dargestellten Ansatz anwenden.
. . . 62. //+------------------------------------------------------------------+ 63. void Procedure(const uchar &arg[]) 64. { 65. un_Model data; 66. 67. Print("Translation personal.\n" + 68. "FUNCTION: ", __FUNCTION__); 69. 70. for (uchar c = 0; c < arg.Size(); ) 71. { 72. ZeroMemory(data.array); 73. c += (uchar)(ArrayCopy(data.array, arg, 0, c + 1, arg[c]) + 1); 74. Print("0x", ValueToString(data.u32, FORMAT_HEX), " B'", ValueToString(data.u32, FORMAT_BINARY), "'"); 75. } 76. } 77. //+------------------------------------------------------------------+
Fragment 04
Wenn (und das möchte ich deutlich betonen) es akzeptabel ist, Fragment 04 innerhalb von Code 05 zu verwenden, dann sieht die resultierende Ausgabe wie unten dargestellt aus:
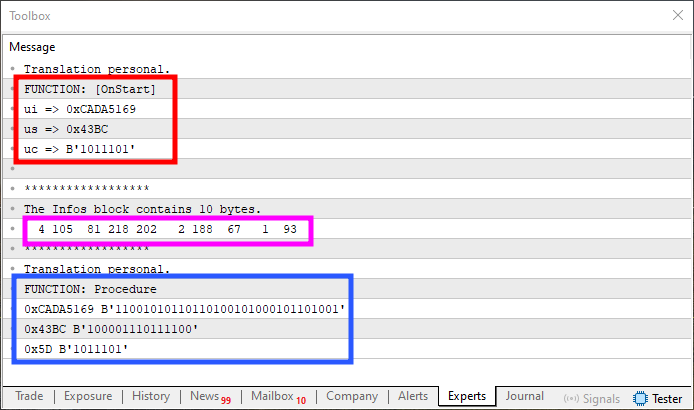
Abbildung 10
Passen Sie jetzt gut auf, liebe Leserin, lieber Leser. In der rot hervorgehobenen Region von Abbildung 10 sind die Originalwerte zu sehen. Im blauen Bereich sehen wir die Ausgangswerte. Beachten Sie, dass diese Werte, anders als in Abbildung 09, nicht gespiegelt werden, sondern mit den Originalen übereinstimmen. Der rosa hervorgehobene Bereich, der genau den Inhalt des Speichers darstellt, ist jedoch weiterhin gespiegelt oder ungeordnet - genau wie in Abbildung 09. Die Eingangs- und Ausgangswerte in Abbildung 10 sind jedoch identisch mit denen in Abbildung 08.
Wenn also der tatsächliche Speicherinhalt ignoriert werden kann und das Ziel lediglich darin besteht, korrekte Ein- und Ausgabewerte zu erhalten (wie in Abbildung 10 dargestellt), dann könnte die in Fragment 04 vorgestellte Lösung tatsächlich gültig sein. Aber je nach Situation ist diese Art von Lösung möglicherweise nicht für das geeignet, was wir wirklich wollen oder verwenden dürfen. In solchen Fällen ist es notwendig, die Daten explizit zu spiegeln, damit das Endergebnis genau dem entspricht, was in Abbildung 08 gezeigt wird.
Um dies zu erreichen, müssen wir eine kleine Anpassung des Codes vornehmen, insbesondere um die Werte zu spiegeln, bevor sie in den zu übertragenden Speicher abgelegt werden. Das ist ganz einfach. Ersetzen Sie einfach den vorherigen Code durch den folgenden.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { 16. const uint ui = 0xCADA5169; 17. ushort us = 0x43BC; 18. uchar uc = B'01011101'; 19. 20. uchar Infos[], 21. counter = 0; 22. 23. PrintFormat("Translation personal.\n" + 24. "FUNCTION: [%s]\n" + 25. "ui => 0x%s\n" + 26. "us => 0x%s\n" + 27. "uc => B'%s'\n", 28. __FUNCTION__, 29. ValueToString(ui, FORMAT_HEX), 30. ValueToString(us, FORMAT_HEX), 31. ValueToString(uc, FORMAT_BINARY) 32. ); 33. 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(uc)); 51. } 52. 53. Print("******************"); 54. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 55. ArrayPrint(Infos); 56. Print("******************"); 57. 58. Procedure(Infos); 59. 60. ArrayFree(Infos); 61. } 62. //+------------------------------------------------------------------+ 63. un_Model Swap(const un_Model &arg) 64. { 65. un_Model info = arg; 66. 67. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 68. { 69. tmp = info.array[i]; 70. info.array[i] = info.array[j]; 71. info.array[j] = tmp; 72. } 73. 74. return info; 75. } 76. //+------------------------------------------------------------------+ 77. void Procedure(const uchar &arg[]) 78. { 79. Print("Translation personal.\n" + 80. "FUNCTION: ", __FUNCTION__); 81. 82. ulong value; 83. 84. for (uchar c = 0; c < arg.Size(); ) 85. { 86. value = 0; 87. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 88. value = (value << 8) | arg[c]; 89. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 90. } 91. } 92. //+------------------------------------------------------------------+
Code 06
In Ordnung, wir haben die Änderung vorgenommen. Aber auch wenn die Anpassung vorgenommen wurde, sehen Sie sich das Ergebnis an.
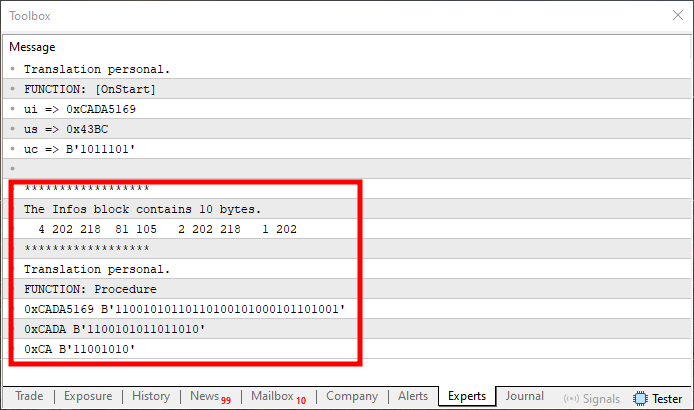
Abbildung 11
Dies ist die Art von Problemen, die Anfänger oft entmutigt. Das liegt daran, dass nur der erste Wert korrekt ist, was dem entspricht, was wir in Abbildung 08 gesehen haben. Die übrigen Werte sind falsch. Warum? Das Problem liegt in der Art und Weise, wie der Startwert gehandhabt wird - er muss korrekt gesetzt werden. Dies geschieht in den Zeilen 45 und 50. Da der „Start“-Wert derzeit auf Null gesetzt ist, ergibt sich die falsche Startposition. Der Kopiervorgang betrifft nur das erste Element des Arrays innerhalb der Vereinigung. Und wie Sie im vorigen Thema gesehen haben, wurde diese Anordnung umgedreht. Was jetzt das erste Element ist, war also ursprünglich das letzte.
Um dies zu beheben, müssen wir die Zeilen 45 und 50 wie unten gezeigt ändern:
. . . 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(us), sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(uc), sizeof(uc)); 51. } . . .
Fragment 05
Wenn Sie Code 06 mit den in Fragment 05 gezeigten Änderungen ausführen, erhalten Sie die in Abbildung 12 gezeigte Ausgabe - genau das, was wir anhand von Abbildung 08 erwartet haben. Mit anderen Worten: Es funktioniert perfekt. Wenn Sie sich Fragment 05 ansehen, werden Sie jedoch schnell feststellen, dass wir es leicht in eine Schleife einbinden können, da es eine ganze Reihe von sich wiederholenden Abschnitten gibt. Hier ist der endgültige Code, der im Anhang zu finden ist.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
Code 07
Abschließende Überlegungen
In diesem Artikel haben wir mehrere faszinierende Themen mit dem klaren Ziel untersucht, zu verstehen, wie Daten im Speicher abgelegt werden und wie sie funktionieren. Auch wenn das, was hier behandelt wurde, von Ihnen verlangt, ein wenig weiter zu gehen, als viele bereit sind zu gehen, wird jeder Fortschritt im Verständnis dessen, was hier gezeigt wurde, Ihnen in der Zukunft von großem Nutzen sein.
Hier sehen Sie, dass nicht alles so kompliziert ist, wie es auf den ersten Blick scheint, und nicht alles ist so einfach, dass man alles mit einer schnellen Lektüre verstehen kann. Es ist wichtig, ständig zu üben und zu lernen. Aber zunächst müssen Sie sich bemühen, die Konzepte zu verstehen, die mit der Entwicklung einer Anwendung verbunden sind.
Einfach zu akzeptieren, dass ein von einem anderen Programmierer geschriebener Code uns besser geeignet erscheint, wird uns nicht helfen, etwas Geeignetes zu schaffen. Auf den ersten Blick mag es geeignet erscheinen, aber wenn man es einsetzt, könnte es einen enttäuschen, weil es unerwartete Probleme gibt, die man ohne das richtige Wissen nicht lösen kann. Erkunden Sie also die Codes im Anhang und versuchen Sie zu üben und zu lernen, was Sie hier sehen. Wir sehen uns im nächsten Artikel wieder.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15503
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.