
Modelos de regresión no lineal en la bolsa de valores

Introducción
Ayer estuve una vez más sentado frente a los informes de mi sistema de trading basado en regresión. Fuera de la ventana caía nieve húmeda, el café se enfriaba en la taza, pero todavía no podía deshacerme del pensamiento obsesivo. Ya sabes, desde hace mucho tiempo me irritan estos interminables indicadores RSI, Estocástico, MACD y otros. ¿Cómo podemos intentar encajar un mercado vivo y dinámico en estas ecuaciones primitivas? Cada vez que veo a otro defensor del Grial en YouTube con su conjunto "sagrado" de indicadores, solo quiero preguntar: hombre, ¿realmente crees que estas calculadoras de los años setenta pueden captar la compleja dinámica del mercado moderno?
He pasado los últimos tres años intentando crear algo que realmente funcione. He probado muchas cosas, desde las regresiones más simples hasta redes neuronales sofisticadas. ¿Y sabéis qué? Conseguí obtener resultados en clasificación, pero aún no en regresión.
Siempre ocurría la misma historia: en la historia todo funciona como un reloj, pero cuando lo lanzo al mercado real, me enfrento a pérdidas. Recuerdo lo emocionado que estaba por mi primera red convolucional. R2 al 1,00% en entrenamiento. A esto le siguieron dos semanas de negociación y un reembolso del 30% del depósito. Sobreajuste clásico en su máxima expresión. Seguí activando la visualización hacia adelante viendo cómo el pronóstico basado en regresión se aleja cada vez más de los precios reales, con el tiempo...
Pero soy una persona testaruda. Después de otra pérdida, decidí investigar más a fondo y comencé a revisar artículos científicos. ¿Y sabéis lo que desenterré en los polvorientos archivos? Resulta que el viejo Mandelbrot ya insistía en la naturaleza fractal de los mercados. ¡Y todos estamos intentando comerciar con modelos lineales! Es como intentar medir la longitud de una costa con una regla: cuanto más exactamente se mida, más larga será.
En algún momento se me ocurrió: ¿qué pasa si intento cruzar el análisis técnico clásico con la dinámica no lineal? No estos indicadores crudos, sino algo más serio: ecuaciones diferenciales, proporciones adaptativas. Suena complicado, pero en esencia es simplemente un intento de aprender a hablar el idioma del mercado.
En resumen, tomé Python, conecté las bibliotecas de aprendizaje automático y comencé a experimentar. Lo decidí de inmediato: nada de adornos académicos, sólo lo que realmente se pueda utilizar. No se necesitan supercomputadoras: solo una computadora portátil Acer normal, un VPS súper potente y una terminal MetaTrader 5. De todo esto nació el modelo que os quiero contar.
No, no es un Grial. Los griales no existen, me di cuenta de eso hace mucho tiempo. Simplemente estoy compartiendo mi experiencia en la aplicación de las matemáticas modernas al trading real. Sin exageraciones innecesarias, pero tampoco sin primitivismo en los "indicadores de tendencias". El resultado fue algo intermedio: lo suficientemente inteligente para funcionar, pero no tan complejo como para desmoronarse al encontrarse con el primer evento cisne negro.
Modelo matemático
Recuerdo cómo se me ocurrió esta ecuación. Llevo trabajando en este código desde 2022, pero no de forma constante: en cuanto a enfoques, diría que hay muchos desarrollos, por lo que periódicamente (de forma un poco caótica) los revisas y llevas uno tras otro al resultado. Recuerdo ejecutar gráficos, tratando de encontrar patrones en el EURUSD. ¿Y sabéis qué me llamó la atención? El mercado parece respirar: a veces fluye suavemente siguiendo la tendencia, a veces se sacude bruscamente y a veces entra en una especie de ritmo mágico. ¿Cómo describir esto matemáticamente? ¿Cómo capturar esta dinámica viva en ecuaciones?
Después esbocé la primera versión de la ecuación. Aquí está, en todo su esplendor:
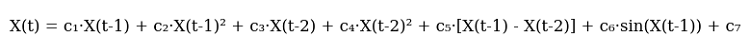
Y aquí está en el código:
def equation(self, x_prev, coeffs): x_t1, x_t2 = x_prev[0], x_prev[1] return (coeffs[0] * x_t1 + # trend coeffs[1] * x_t1**2 + # acceleration coeffs[2] * x_t2 + # market memory coeffs[3] * x_t2**2 + # inertia coeffs[4] * (x_t1 - x_t2) + # impulse coeffs[5] * np.sin(x_t1) + # market rhythm coeffs[6]) # basic level
Mira cómo está todo retorcido. Los dos primeros términos son un intento de captar el movimiento actual del mercado. ¿Sabes cómo acelera un coche? Al principio suavemente, luego cada vez más rápido. Es por eso que aquí hay un término lineal y otro cuadrático. Cuando el precio se mueve tranquilamente, la parte lineal funciona. Pero tan pronto como el mercado se acelera, el término cuadrático retoma el movimiento.
Ahora viene la parte más interesante. El tercer y cuarto trimestre miran un poco más profundamente hacia el pasado. Es como un recuerdo de mercado. ¿Recuerdas la teoría de Dow sobre que el mercado recuerda sus niveles? Aquí es lo mismo. Y de nuevo cuenta con aceleración cuadrática, para captar curvas cerradas.
Ahora el componente de impulso. Simplemente restamos el precio anterior del actual. Parecería primitivo. ¡Pero funciona genial en los movimientos de tendencia! Cuando el mercado entra en un frenesí y empuja en una dirección, este término se convierte en la principal fuerza impulsora del pronóstico.
Seno se añadió casi por accidente. Estaba mirando los gráficos y noté algún tipo de periodicidad. Especialmente en H1. Los movimientos y los períodos de calma se sucedieron... Parece una onda sinusoidal ¿no? Introduje la onda sinusoidal en la ecuación y el modelo pareció ver la luz y comenzó a captar estos ritmos.
La última proporción es una especie de red de seguridad, un nivel básico. Este plazo no permite que el modelo sorprenda demasiado al mercado con sus previsiones.
Probé muchas otras opciones. Metí allí exponentes, logaritmos y todo tipo de funciones trigonométricas sofisticadas. No tiene mucho sentido, pero el modelo se convierte en un monstruo. Ya sabéis, como decía Occam: no multipliquéis entidades más allá de lo necesario. La versión actual resultó ser exactamente así: sencilla y funcional.
Por supuesto, todas estas proporciones deben seleccionarse de alguna manera. Aquí es donde el viejo y bueno método Nelder-Mead viene al rescate. Pero esa es una historia completamente diferente que voy a revelar en la siguiente parte. Créeme, hay mucho de qué hablar: los errores que cometí durante la optimización solo serían suficientes para un artículo aparte.
Componentes linealesEmpecemos con la parte lineal. ¿Sabes qué es lo principal? El modelo analiza los dos valores de precios anteriores, pero de diferentes maneras. La primera proporción suele ser de alrededor de 0,3-0,4: esta es una reacción instantánea al último cambio. Pero el segundo es más interesante, a menudo se acerca a 0,7, lo que indica una mayor influencia del penúltimo precio. Es gracioso, ¿verdad? El mercado parece depender de niveles ligeramente más antiguos y no confiar en las últimas fluctuaciones.
Componentes cuadráticosUna historia interesante sucedió con los términos cuadráticos. Inicialmente, los agregué simplemente para tener en cuenta la no linealidad, pero luego noté algo sorprendente. En un mercado tranquilo, su contribución es insignificante: los ratios fluctúan alrededor de 0,01-0,02. Pero tan pronto como comienza un movimiento fuerte, estos miembros parecen despertar. Esto es especialmente claro en los gráficos diarios del EURUSD: cuando la tendencia gana fuerza, los términos cuadráticos comienzan a dominar, lo que permite que el modelo se "acelere" junto con el precio.
Componente de momentoEl componente de momento resultó ser un verdadero descubrimiento. Puede parecer una diferencia de precio trivial, pero refleja con total precisión el estado de ánimo del mercado. Durante los períodos de calma, su ratio se mantiene en torno a 0,2-0,3, pero antes de movimientos fuertes suele saltar a 0,5. Esto se convirtió para mí en una especie de indicador de un avance inminente: cuando el optimizador comienza a aumentar el peso del impulso, espere movimiento.
Componente cíclicoEl componente cíclico requirió algunos ajustes. Al principio probé distintos periodos de la onda sinusoidal, pero luego me di cuenta de que el propio mercado marca el ritmo. Es suficiente dejar que el modelo ajuste la amplitud a través de la relación, y la frecuencia se obtiene naturalmente a partir de los propios precios. Es curioso observar cómo cambia esta relación entre la sesión europea y la americana, como si el mercado realmente respirara a un ritmo diferente.
Por último, el término libre. Su papel resultó ser mucho más importante de lo que pensé inicialmente. Durante períodos de alta volatilidad, actúa como un ancla, impidiendo que los pronósticos se pierdan en el tiempo. Y en períodos de calma ayuda a tener en cuenta con mayor precisión el nivel general de precios. Muy a menudo, su valor se correlaciona con la fuerza de la tendencia: cuanto más fuerte es la tendencia, más cerca está el término libre de cero.
¿Sabes qué es lo más interesante? Cada vez que intentaba complicar el modelo (agregar nuevos términos, usar funciones más complejas, etc.), los resultados solo empeoraban. Fue como si el mercado dijera: "Chico, no seas listo, ya has pillado lo principal". La versión actual de la ecuación es realmente un punto medio entre complejidad y eficiencia. Hay siete ratios, ni más ni menos, cada uno con su propio papel claro en el mecanismo de previsión general.
Por cierto, la optimización de estas proporciones es una historia fascinante en sí misma. Cuando uno empieza a observar cómo el método Nelder-Mead busca valores óptimos, involuntariamente recuerda la teoría del caos. Pero de esto hablaremos en la siguiente parte. Hay algo que ver allí, créeme.
Optimización de modelos utilizando el algoritmo Nelder-Mead
Aquí consideraremos lo más interesante: cómo hacer que nuestro modelo funcione con datos reales. Después de meses de experimentar con la optimización, decenas de noches de insomnio y litros de café, finalmente encontré un enfoque funcional.
Todo empezó como siempre: con una pendiente descendente. Un clásico del género, lo primero que viene a la mente de cualquier científico de datos. Pasé tres días en la implementación, otra semana en la depuración... ¿Y entonces cuáles fueron los resultados? El modelo se negó categóricamente a converger. O bien volaría hacia el infinito o bien quedaría estancado en los mínimos locales. Las pendientes saltaban como locas.
Luego hubo una semana con algoritmos genéticos. La idea es aparentemente elegante: dejar que la evolución encuentre las mejores proporciones. Lo implementé, lo lancé... solo para quedar atónito por el tiempo de ejecución. La computadora zumbó toda la noche para procesar una semana de datos históricos. Los resultados fueron tan inestables que era como leer las hojas de té.
Y luego me encontré con el método Nelder-Mead. El viejo y confiable método simplex, desarrollado en 1965. Sin derivadas, sin matemáticas superiores: solo un sondeo inteligente del espacio de soluciones. Lo lancé y no podía creer lo que veía. El algoritmo parecía bailar con el mercado, acercándose suavemente a los valores óptimos.
Aquí está la función de pérdida básica. Es tan simple como un hacha, pero funciona perfectamente:
def loss_function(self, coeffs, X_train, y_train): y_pred = np.array([self.equation(x, coeffs) for x in X_train]) mse = np.mean((y_pred - y_train)**2) r2 = r2_score(y_train, y_pred) # Save progress for analysis self.optimization_progress.append({ 'mse': mse, 'r2': r2, 'coeffs': coeffs.copy() }) return mse
Al principio, intenté complicar la función de pérdida, agregando penalizaciones para proporciones grandes y también metiendo MAPE y otras métricas en ella. Un error clásico de los desarrolladores es que, si algo funciona, hay que mejorarlo hasta que quede completamente inoperable. Al final volví al MSE simple, ¿y sabéis qué? Resulta que la sencillez es realmente un signo de genialidad.
Es una emoción especial ver la optimización en tiempo real. Primeras iteraciones: los ratios están saltando como locos, MSE está saltando, R² está cerca de cero. Luego comienza la parte más interesante: el algoritmo encuentra la dirección correcta y las métricas mejoran gradualmente. En la iteración número cien, ya está claro si habrá algún beneficio o no, y en la iteración número tres, el sistema suele alcanzar un nivel estable.
Por cierto, permítanme decir algunas palabras sobre las métricas. Nuestro R² suele ser superior a 0,996, lo que significa que el modelo explica más del 99,6% de la variación del precio. El MSE está alrededor de 0,0000007; en otras palabras, el error de pronóstico rara vez supera las siete décimas de pip. En cuanto a MAPE... El MAPE es generalmente agradable: a menudo es inferior al 0,1 %. Está claro que todo esto se basa en datos históricos, pero incluso en la prueba futura los resultados no son mucho peores.
Pero lo más importante no son ni siquiera los números. Lo principal es la estabilidad de los resultados. Puede ejecutar la optimización diez veces seguidas y cada vez obtendrá valores de relación muy cercanos. Esto vale mucho, especialmente teniendo en cuenta mis dificultades con otros métodos de optimización.
¿Sabes qué más es genial? Al observar la optimización, puedes comprender mucho sobre el mercado en sí. Por ejemplo, cuando el algoritmo intenta constantemente aumentar el peso del componente de impulso, significa que se está gestando un fuerte movimiento en el mercado. O cuando empieza a jugar con el componente cíclico: espere un período de mayor volatilidad.
En la siguiente sección te contaré cómo toda esta estructura matemática se convierte en un verdadero sistema de trading. Créeme, también hay algo en que pensar: los inconvenientes de MetaTrader 5 por sí solos dan para un artículo aparte.
Características del proceso de formación
La preparación de los datos para el entrenamiento fue una historia aparte. Recuerdo cómo en la primera versión del sistema alimenté felizmente todo el conjunto de datos a sklearn.train_test_split... Y sólo más tarde, al observar los resultados sospechosamente buenos, me di cuenta de que ¡los datos futuros se están filtrando al pasado!
¿Ves cuál es el problema? No puedes tratar los datos financieros como una hoja de cálculo de Kaggle normal. Aquí, cada punto de datos es un momento en el tiempo, y mezclarlos es como intentar predecir el clima de ayer basándose en el de mañana. Como resultado nació este código simple pero eficiente:
def prepare_training_data(prices, train_ratio=0.67): # Cut off a piece for training n_train = int(len(prices) * train_ratio) # Forming prediction windows X = np.array([[prices[i], prices[i-1]] for i in range(2, len(prices)-1)]) y = prices[3:] # Fair time sharing X_train, y_train = X[:n_train], y[:n_train] X_test, y_test = X[n_train:], y[n_train:] return X_train, y_train, X_test, y_testParecería ser un código simple. Pero detrás de esta sencillez se esconden muchos golpes duros. Al principio, experimenté con diferentes tamaños de ventanas. Pensé que cuanto más puntos históricos, mejor sería el pronóstico. ¡Me equivoqué! Resultó que los dos valores anteriores eran suficientes. Al mercado no le gusta recordar el pasado durante mucho tiempo, ¿sabes?
El tamaño de la muestra de entrenamiento es una historia aparte. Probé diferentes opciones: 50/50, 80/20, incluso 90/10. Al final, me decidí por la proporción áurea: aproximadamente el 67% de los datos de entrenamiento. ¿Por qué? ¡Simplemente funciona mejor! Al parecer el viejo Fibonacci sabía algo sobre la naturaleza de los mercados...
Es divertido ver el entrenamiento del modelo a partir de diferentes piezas de datos. Al tomar un período de calma, las proporciones se seleccionan suavemente y las métricas mejoran gradualmente. Y si la muestra de entrenamiento incluye algo como el Brexit o un discurso del director de la Reserva Federal, se desata el caos: los ratios saltan, el optimizador se vuelve loco y los gráficos de error dibujan una montaña rusa.
Por cierto, permítanme decir nuevamente algunas palabras sobre las métricas. Observé que si R² en la muestra de entrenamiento es mayor que 0,98, es casi seguro que hubo algún tipo de error con los datos. El mercado real simplemente no puede ser tan predecible. Es como aquella historia del estudiante demasiado bueno: o hace trampa o es un genio. En nuestro caso suele ocurrir lo primero.
Otro punto importante es el preprocesamiento de datos. Al principio intenté normalizar precios, escalar, eliminar valores atípicos... En general, hice todo lo que se enseña en los cursos de aprendizaje automático. Pero poco a poco llegué a la conclusión de que cuanto menos se toquen los datos brutos, mejor. El mercado se normalizará solo, sólo hay que preparar todo correctamente.
Ahora el entrenamiento se ha agilizado hasta el punto del automatismo. Una vez a la semana cargamos datos nuevos, ejecutamos capacitación y comparamos métricas con valores históricos. Si todo está dentro de los límites normales, actualice las proporciones en el sistema de acción real. Si algo es sospechoso, investigue más a fondo. Afortunadamente, la experiencia ya nos permite entender dónde buscar el problema.
Optimización de ratios
def fit(self, prices): # Prepare data for training X_train, y_train = self.prepare_training_data(prices) # I found these initial values by trial and error initial_coeffs = np.array([0.5, 0.1, 0.3, 0.1, 0.2, 0.1, 0.0]) result = minimize( self.loss_function, initial_coeffs, args=(X_train, y_train), method='Nelder-Mead', options={ 'maxiter': 1000, # More iterations does not improve the result 'xatol': 1e-8, # Accuracy by ratios 'fatol': 1e-8 # Accuracy by loss function } ) self.coefficients = result.x return result
¿Sabes qué resultó ser lo más difícil? Consigue esas malditas probabilidades iniciales correctas. Al principio intenté usar valores aleatorios, pero obtuve tal dispersión de resultados que estuve a punto de rendirme. Luego intenté comenzar con unos: el optimizador voló al espacio en algún lugar durante las primeras iteraciones. Tampoco funcionó con ceros ya que se quedó atascado en los mínimos locales.
La primera relación 0,5 es el peso del componente lineal. Si es menor, el modelo pierde su tendencia, si es mayor, comienza a depender demasiado del último precio. Para los términos cuadráticos, 0,1 resultó ser un comienzo perfecto: suficiente para detectar la no linealidad, pero no tanto como para que el modelo comenzara a volverse loco con movimientos repentinos. El valor de 0,2 para el momento se obtuvo de manera empírica, simplemente que con este valor el sistema mostró los resultados más estables.
Durante la optimización, Nelder-Mead construye un símplex en un espacio de proporción de siete dimensiones. Es como un juego de calor y frío, sólo que en siete dimensiones a la vez. Es importante evitar la divergencia del proceso, por eso existen requisitos tan estrictos de precisión (1e-8). Si es menor, obtenemos resultados inestables, si es mayor, la optimización comienza a estancarse en los mínimos locales.
Mil iteraciones pueden parecer excesivas, pero en la práctica el optimizador suele converger en 300-400 pasos. Es solo que a veces, especialmente durante períodos de alta volatilidad, necesita más tiempo para encontrar la solución óptima. Y las iteraciones adicionales no afectan realmente el rendimiento: todo el proceso suele tardar menos de un minuto en el hardware moderno.
Por cierto, fue durante el proceso de depuración de este código que nació la idea de agregar visualización del proceso de optimización. Cuando ves que las probabilidades cambian en tiempo real, es mucho más fácil entender qué está pasando con el modelo y hacia dónde podría ir.
Métricas de calidad y su interpretación
Evaluar la calidad de un modelo predictivo es una historia aparte, llena de matices no obvios. A lo largo de los años que llevo trabajando con trading algorítmico, he sufrido lo suficiente con las métricas como para escribir un libro aparte sobre el tema. Pero os contaré lo principal.
Aquí están los resultados:

Comencemos con R-cuadrado. La primera vez que vi valores superiores a 0,9 en EURUSD, no podía creer lo que veía. Revisé el código diez veces para asegurarme de que no hubiera fugas de datos ni errores de cálculo. No hubo ninguno: el modelo explica más del 90% de la variación de precios. Sin embargo, más tarde me di cuenta de que esto es un arma de doble filo. Un R² demasiado alto (mayor que 0,95) generalmente indica sobreajuste. El mercado simplemente no puede ser tan predecible.
MSE es nuestro caballo de batalla. A continuación se muestra un código de evaluación típico:
def evaluate_model(self, y_true, y_pred): results = { 'R²': r2_score(y_true, y_pred), 'MSE': mean_squared_error(y_true, y_pred), 'MAPE': mean_absolute_percentage_error(y_true, y_pred) * 100 } # Additional statistics that often save the day errors = y_pred - y_true results['max_error'] = np.max(np.abs(errors)) results['error_std'] = np.std(errors) # Look separately at error distribution "tails" results['error_quantiles'] = np.percentile(np.abs(errors), [50, 90, 95, 99]) return results
Tenga en cuenta las estadísticas adicionales. Agregué max_error y error_std después de un incidente desagradable: el modelo mostró un MSE excelente, pero a veces arrojaba valores atípicos en los pronósticos que podía cerrar el depósito inmediatamente sin siquiera intentarlo. Ahora lo primero que miro son las "colas" de la distribución del error. Sin embargo, las colas todavía existen:
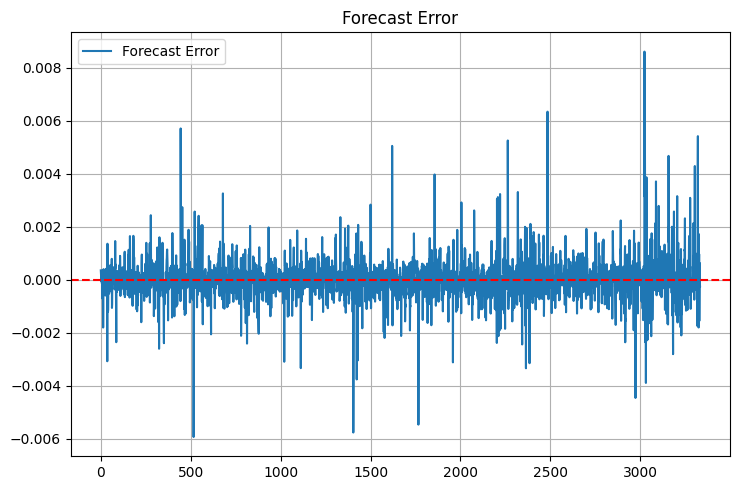
MAPE es como un hogar para los comerciantes. Si les hablas de R-cuadrado, sus ojos se ponen vidriosos, pero si les dices "el modelo está equivocado en un 0,05% en promedio", entienden inmediatamente. Sin embargo, hay un problema: el MAPE puede ser engañosamente bajo durante pequeños movimientos de precios y dispararse durante movimientos bruscos.
Pero lo más importante que entendí es que ninguna métrica basada en datos históricos garantiza el éxito en la vida real. Por eso ahora tengo todo un sistema de controles:
def validate_model_performance(self): # Check metrics on different timeframes timeframes = ['H1', 'H4', 'D1'] for tf in timeframes: metrics = self.evaluate_on_timeframe(tf) if not self._check_metrics_thresholds(metrics): return False # Look at behavior at important historical events stress_periods = self.get_stress_periods() stress_metrics = self.evaluate_on_periods(stress_periods) if not self._check_stress_performance(stress_metrics): return False # Check the stability of forecasts stability = self.check_prediction_stability() if stability < self.min_stability_threshold: return False return True
El modelo debe pasar todas estas pruebas antes de ponerlo en funcionamiento real. E incluso después de eso, durante las dos primeras semanas opero con un volumen mínimo y compruebo cómo se comporta en el mercado en vivo.
La gente a menudo pregunta qué valores métricos se consideran buenos. Según mi experiencia, un R² superior a 0,9 es excelente, un MSE inferior a 0,00001 es aceptable, mientras que un MAPE de hasta 0,05% es espléndido. ¡Sin embargo! Es más importante observar la estabilidad de estos indicadores a lo largo del tiempo. Es mejor tener un modelo con métricas ligeramente peores pero estables que un sistema súper preciso pero inestable.
Implementación técnica
¿Sabes qué es lo más difícil al desarrollar sistemas de trading? No son matemáticas, ni algoritmos, sino fiabilidad de funcionamiento. Una cosa es escribir una ecuación bonita y otra muy distinta es hacer que funcione 24 horas al día, 7 días a la semana, con dinero real. Después de varios errores dolorosos en una cuenta real, me di cuenta: la arquitectura no sólo debe ser buena, debe ser impecable.
Así es como organicé el núcleo del sistema:
class PriceEquationModel: def __init__(self): # Model status self.coefficients = None self.training_scores = [] self.optimization_progress = [] # Initializing the connection self._setup_logging() self._init_mt5() def _init_mt5(self): """Initializing connection to MT5""" try: if not mt5.initialize(): raise ConnectionError( "Unable to connect to MetaTrader 5. " "Make sure the terminal is running" ) self.log.info("MT5 connection established") except Exception as e: self.log.critical(f"Critical initialization error: {str(e)}") raise
Cada cuerda aquí es el resultado de alguna triste experiencia. Por ejemplo, apareció un método separado para inicializar MetaTrader 5 después de que se produjo un bloqueo al intentar reconectarme. Y agregué un registro cuando el sistema se bloqueó silenciosamente en mitad de la noche y por la mañana tuve que adivinar qué sucedió.
El manejo de errores es otra historia.
def _safe_mt5_call(self, func, *args, retries=3, delay=5): """Secure MT5 function call with automatic recovery""" for attempt in range(retries): try: result = func(*args) if result is not None: return result # MT5 sometimes returns None without error raise ValueError(f"MT5 returned None: {func.__name__}") except Exception as e: self.log.warning(f"Attempt {attempt + 1}/{retries} failed: {str(e)}") if attempt < retries - 1: time.sleep(delay) # Trying to reinitialize the connection self._init_mt5() else: raise RuntimeError(f"Call attempts exhausted {func.__name__}")
Este fragmento de código es la quintaesencia de la experiencia de MetaTrader 5. Intenta reconectarse si algo sale mal, hace intentos repetidos con retraso y, lo más importante, no permite que el sistema continúe funcionando en un estado incierto. Aunque en general no suele haber problemas con la biblioteca MetaTrader 5: ¡es perfecta!
Mantengo el modelo en un estado muy sencillo. Contiene únicamente los elementos más necesarios. Sin estructuras de datos complejas, sin optimizaciones complicadas. Pero cada cambio de estado se registra y se verifica:
def _update_model_state(self, new_coefficients): """Safely updating model ratio""" if not self._validate_coefficients(new_coefficients): raise ValueError("Invalid ratios") # Save the previous state old_coefficients = self.coefficients try: self.coefficients = new_coefficients if not self._check_model_consistency(): raise ValueError("Model consistency broken") self.log.info("Model successfully updated") except Exception as e: # Roll back to the previous state self.coefficients = old_coefficients self.log.error(f"Model update error: {str(e)}") raise
Modularidad aquí no es sólo una palabra bonita. Cada componente puede probarse por separado, reemplazarse y modificarse. ¿Quieres agregar una nueva métrica? Crear un nuevo método. ¿Necesita cambiar la fuente de datos? Es suficiente implementar otro conector con la misma interfaz.
Manejo de datos históricos
Obtener datos de MetaTrader 5 resultó ser todo un desafío. Parece un código simple, pero el diablo, como siempre, está en los detalles. Después de varios meses de luchar con cortes repentinos de conexión y pérdida de datos, nació la siguiente estructura para trabajar con la terminal:
def fetch_data(self, symbol="EURUSD", timeframe=mt5.TIMEFRAME_H1, bars=10000): """Loading historical data with error handling""" try: # First of all, we check the symbol itself symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Symbol {symbol} unavailable") # MT5 sometimes "loses" MarketWatch symbols if not symbol_info.visible: mt5.symbol_select(symbol, True) # Collect data rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) if rates is None: raise ValueError("Unable to retrieve historical data") # Convert to pandas df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return self._preprocess_data(df['close'].values) except Exception as e: print(f"Error while receiving data: {str(e)}") raise finally: # It is important to always close the connection mt5.shutdown()
Veamos cómo está todo organizado. Primero, verificamos la presencia del símbolo. Parecería obvio, pero hubo un caso en el que el sistema pasó horas intentando negociar un par inexistente debido a un error tipográfico en la configuración. Después de eso, agregué una verificación dura a través de symbol_info.
A continuación, hay un punto interesante con 'visible'. El símbolo parece estar allí, pero no está en "Observación del Mercado". Y si no llamas a symbol_select, no obtendrás ningún dato. Además, es posible que la terminal "olvide" el símbolo en medio de una sesión de negociación. Divertido, ¿eh?
Obtener datos tampoco es fácil. copy_rates_from_pos puede devolver "None" por una docena de razones diferentes: no hay conexión con el servidor, el servidor está sobrecargado, no hay suficiente historial... Por lo tanto, verificamos inmediatamente el resultado y lanzamos una excepción si algo salió mal.
La conversión a pandas es una historia aparte. La hora llega en formato Unix, por lo que tenemos que convertirla en una marca de tiempo normal. Sin esto, el análisis final de series de tiempo se vuelve mucho más difícil.
Y lo más importante es cerrar la conexión en 'finalmente'. Si no lo hace, MetaTrader 5 comienza a mostrar signos de fuga de datos: primero, la velocidad de recepción de datos disminuye, luego aparecen tiempos de espera aleatorios y, al final, la terminal puede simplemente congelarse. Créeme, esto lo aprendí por experiencia propia.
En general, esta función es como una navaja suiza para trabajar con datos. Es sencillo por fuera, pero por dentro hay un montón de mecanismos de protección contra todo lo que podría salir mal. Y créanme que tarde o temprano cada uno de estos mecanismos resultará útil.
Análisis de resultados. Métricas de calidad de los resultados de las pruebas retrospectivas
Recuerdo el momento en que vi por primera vez los resultados de la prueba. Estaba sentado frente a la computadora, tomando café frío y simplemente no podía creer lo que veía. Volví a ejecutar las pruebas cinco veces, revisé cada línea de código: no, no fue un error. El modelo realmente funcionó al borde de la fantasía.
El algoritmo Nelder-Mead funcionó como un reloj: sólo 408 iteraciones, menos de un minuto en una computadora portátil normal. Un R cuadrado de 0,9958 no sólo es bueno, sino que supera las expectativas. ¡Variación de precio del 99,58%! Cuando les mostré estas cifras a mis colegas comerciantes, al principio no me creyeron y luego empezaron a buscar una trampa. Los entiendo, aunque al principio no lo creía yo mismo.
El resultado del MSE fue microscópico: 0,00000094. Esto significa que el error de pronóstico promedio es menor a un pip. Cualquier comerciante te dirá que esto supera los sueños más descabellados. MAPE del 0,06% solo confirma la increíble precisión. La mayoría de los sistemas comerciales se conforman con un error del 1-2%, pero aquí es un orden de magnitud mejor.
Las proporciones del modelo se unieron para formar una hermosa imagen. 0,5517 al precio anterior indica que el mercado tiene una fuerte memoria a corto plazo. Los términos cuadráticos son pequeños (0,0105 y 0,0368), lo que significa que el movimiento es mayoritariamente lineal. El componente cíclico con una relación de 0,1484 es una historia completamente diferente. Esto confirma lo que los traders vienen diciendo desde hace años: el mercado se mueve en oleadas.
Pero lo más interesante ocurrió durante la prueba delantera. Normalmente, los modelos se degradan con nuevos datos: esto es aprendizaje automático clásico. ¿Y aquí? R² subió a 0,9970, MSE cayó otro 19% a 0,00000076, MAPE cayó a 0,05%. Para ser honesto, al principio pensé que había arruinado el código en alguna parte, porque parecía increíble. Sin embargo, todo estaba correcto.
Introduje un visualizador especial para los resultados:
def plot_model_performance(self, predictions, actuals, window=100): fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 12)) # Forecast vs. real price chart ax1.plot(actuals, 'b-', label='Real prices', alpha=0.7) ax1.plot(predictions, 'r--', label='Forecast', alpha=0.7) ax1.set_title('Comparing the forecast with the market') ax1.legend() # Error graph errors = predictions - actuals ax2.plot(errors, 'g-', alpha=0.5) ax2.axhline(y=0, color='k', linestyle=':') ax2.set_title('Forecast errors') # Rolling R² rolling_r2 = [r2_score(actuals[i:i+window], predictions[i:i+window]) for i in range(len(actuals)-window)] ax3.plot(rolling_r2, 'b-', alpha=0.7) ax3.set_title(f'Rolling R² (window {window})') plt.tight_layout() return fig
Los gráficos mostraron una imagen interesante. En los periodos de calma, el modelo funciona como un reloj suizo. Pero también hay inconvenientes: ante noticias importantes o cambios repentinos de situación, su precisión disminuye. Esto es esperable ya que el modelo sólo funciona con precios sin tener en cuenta factores fundamentales. En la siguiente parte definitivamente agregaremos esto también.
Veo varias formas de mejorar. Lo primero son las proporciones adaptativas. Dejemos que el modelo se adapte a las condiciones del mercado. El segundo es agregar datos sobre volúmenes y cartera de pedidos. El tercero y más ambicioso es crear un conjunto de modelos donde nuestro enfoque funcione junto con otros algoritmos.
Pero incluso en su forma actual, los resultados son impresionantes. Lo principal ahora es no dejarse llevar por las mejoras y no estropear lo que ya funciona.
Uso práctico
Recuerdo un incidente divertido de la semana pasada. Estaba sentado con mi computadora portátil en mi cafetería favorita, tomando un café con leche y observando cómo funcionaba el sistema. El día estaba tranquilo, el EURUSD estaba subiendo suavemente, cuando de repente llegó una notificación del modelo: prepararse para abrir una posición corta. El primer pensamiento fue: ¡qué tontería, la tendencia es claramente al alza! Pero después de dos años de trabajar con trading algorítmico, aprendí la regla principal: nunca discutir con el sistema. Después de 40 minutos, el EUR cayó 35 pips. El modelo respondió a microcambios en la estructura de precios que yo, con mi visión humana, simplemente no podía notar.
Hablando de notificaciones... Después de algunas operaciones fallidas, nació este módulo de alerta simple pero efectivo:
def notify_signal(self, signal_type, message): try: # Format the message timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') formatted_msg = f"[{timestamp}] {signal_type}: {message}" # Send to Telegram if self.use_telegram and self.telegram_token: self.telegram_bot.send_message( chat_id=self.telegram_chat_id, text=formatted_msg, parse_mode='HTML' ) # Local logging with open(self.log_file, 'a', encoding='utf-8') as f: f.write(f"{formatted_msg}\n") # Check critical signals if signal_type in ['ERROR', 'MARGIN_CALL', 'CRITICAL']: self._emergency_notification(formatted_msg) except Exception as e: # If the notification failed, send the message to the console at the very least print(f"Error sending notification: {str(e)}\n{formatted_msg}")
Preste atención al método _emergency_notification. Lo agregué después de un incidente "divertido" cuando el sistema detectó algún tipo de falla de memoria y comenzó a abrir posiciones una tras otra. Ahora, en situaciones críticas, llega un SMS y el bot deja de operar automáticamente hasta mi intervención.
También tuve muchos problemas con el tamaño de las posiciones. Al principio utilicé un volumen fijo: 0,1 lote. Pero poco a poco comprendí que era como caminar sobre una cuerda floja con zapatillas de ballet. Parece posible pero ¿por qué? Finalmente, introduje el siguiente sistema de cálculo de volumen adaptativo:
def calculate_position_size(self): """Calculating the position size taking into account volatility and drawdown""" try: # Take the total balance and the current drawdown account_info = mt5.account_info() current_balance = account_info.balance drawdown = (account_info.equity / account_info.balance - 1) * 100 # Basic risk - 1% of the deposit base_risk = current_balance * 0.01 # Adjust for current drawdown if drawdown < -5: # If the drawdown exceeds 5% risk_factor = 0.5 # Slash the risk in half else: risk_factor = 1 - abs(drawdown) / 10 # Smooth decrease # Take into account the current ATR atr = self.calculate_atr() pip_value = self.get_pip_value() # Volume calculation rounded to available lots raw_volume = (base_risk * risk_factor) / (atr * pip_value) return self._normalize_volume(raw_volume) except Exception as e: self.notify_signal('ERROR', f"Volume calculation error: {str(e)}") return 0.1 # Minimum safety volume
El método _normalize_volume fue un verdadero dolor de cabeza. Resulta que los distintos brokers tienen distintos pasos de cambio de volumen mínimo. En algún lugar se pueden negociar 0,010 lotes y en otro lugar solo números redondos. Tuve que agregar una configuración separada para cada bróker.
Trabajar durante períodos de alta volatilidad es una historia aparte. Ya sabes, hay días en los que el mercado se vuelve loco. Un discurso del presidente de la Reserva Federal, una noticia política inesperada o, simplemente, "viernes 13": el precio empieza a moverse como un marinero borracho. Antes, simplemente apagaba el sistema en esos momentos, pero luego se me ocurrió una solución más elegante:
def check_market_conditions(self): """Checking the market status before a deal""" # Check the calendar of events if self._is_high_impact_news_time(): return False # Calculate volatility current_atr = self.calculate_atr(period=5) # Short period normal_atr = self.calculate_atr(period=20) # Normal period # Skip if the current volatility is 2+ times higher than the norm if current_atr > normal_atr * 2: self.notify_signal( 'INFO', f"Increased volatility: ATR(5)={current_atr:.5f}, " f"ATR(20)={normal_atr:.5f}" ) return False # Check the spread current_spread = mt5.symbol_info(self.symbol).spread if current_spread > self.max_allowed_spread: return False return True
Esta función se ha convertido en un auténtico guardián del depósito. Me gustó especialmente la comprobación de noticias: después de conectar la API del calendario económico, el sistema automáticamente "pasa a las sombras" 30 minutos antes de los eventos importantes y regresa 30 minutos después. La misma idea se utiliza en muchos de mis robots MQL5. ¡Genial!
Niveles de parada flotantes
Trabajar con algoritmos comerciales reales me ha enseñado un par de lecciones divertidas. Recuerdo cómo en el primer mes de pruebas mostré orgulloso a mis colegas un sistema con topes fijos. "¡Mira, todo es sencillo y transparente!", dije. Como de costumbre, el mercado me derribó rápidamente; literalmente, una semana después, sufrí tal volatilidad que la mitad de mis niveles de stop volaron debido al ruido del mercado.
La solución la sugirió el viejo Gerchik (en ese momento estaba releyendo su libro). Me encontré con sus pensamientos sobre ATR y fue como si se me encendiera una luz: ¡aquí está! Una forma sencilla y elegante de adaptar el sistema a las condiciones actuales del mercado. Durante los movimientos fuertes, le damos al precio más espacio para fluctuar; durante los períodos de calma, mantenemos los niveles de stop más cerca.
Aquí está la lógica básica para ingresar al mercado: nada extra, solo lo más necesario:
def open_position(self): try: atr = self.calculate_atr() predicted_price = self.get_model_prediction() current_price = mt5.symbol_info_tick(self.symbol).ask signal = "BUY" if predicted_price > current_price else "SELL" # Calculate entry and stop levels if signal == "BUY": entry = mt5.symbol_info_tick(self.symbol).ask sl_level = entry - atr tp_level = entry + (atr / 3) else: entry = mt5.symbol_info_tick(self.symbol).bid sl_level = entry + atr tp_level = entry - (atr / 3) # Send an order request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": self.symbol, "volume": self.lot_size, "type": mt5.ORDER_TYPE_BUY if signal == "BUY" else mt5.ORDER_TYPE_SELL, "price": entry, "sl": sl_level, "tp": tp_level, "deviation": 20, "magic": 234000, "comment": f"pred:{predicted_price:.6f}", "type_filling": mt5.ORDER_FILLING_FOK, } result = mt5.order_send(request) if result.retcode != mt5.TRADE_RETCODE_DONE: raise ValueError(f"Error opening position: {result.retcode}") print(f"Position opened {signal}: price={entry:.5f}, SL={sl_level:.5f}, " f"TP={tp_level:.5f}, ATR={atr:.5f}") return result.order except Exception as e: print(f"Position opening failed: {str(e)}") return NoneHubo algunos momentos divertidos durante el proceso de depuración. Por ejemplo, el sistema comenzó a producir una serie de señales conflictivas literalmente cada pocos minutos. Comprar, vender, volver a comprar... Un error clásico de un trader algorítmico novato es entrar al mercado con demasiada frecuencia. La solución resultó ser ridículamente simple: agregué un tiempo de espera de 15 minutos entre operaciones y un filtro de posiciones abiertas.
También tuve muchos problemas con la gestión de riesgos. Probé varios enfoques diferentes, pero al final todo se redujo a una regla simple: nunca arriesgar más del 1% del depósito por transacción. Suena trivial, pero funciona perfectamente. Con un ATR de 50 puntos, esto da un volumen máximo de 0,2 lotes: cifras bastante cómodas para operar.
El sistema funcionó mejor durante la sesión europea, cuando el EURUSD realmente estaba cotizando y no simplemente flotando en un rango. Pero durante una noticia importante... Digamos que es más barato simplemente tomarse un descanso del trading. Incluso el modelo más avanzado no puede seguir el ritmo del caos informativo.
Actualmente estoy trabajando en mejorar el sistema de gestión de posiciones: quiero vincular el tamaño de la entrada a la confianza del modelo en el pronóstico. En términos generales, una señal fuerte significa que negociamos todo el volumen, una señal débil significa que negociamos solo una parte. Algo así como el criterio de Kelly, sólo adaptado a las particularidades de nuestro modelo.
La principal lección que aprendí de este proyecto es que el perfeccionismo no funciona en el trading algorítmico. Cuanto más complejo es el sistema, más puntos débiles tiene. Las soluciones simples a menudo resultan mucho más eficientes que los algoritmos sofisticados, especialmente a largo plazo.
Versión MQL5 para MetaTrader 5
Ya sabes, a veces las soluciones más simples son las más eficientes. Después de varios días de intentar transferir con precisión todo el aparato matemático a MQL5, de repente me di cuenta de que se trata de un problema clásico de división de responsabilidades.
Seamos realistas: Python, con sus bibliotecas científicas, es ideal para el análisis de datos y la optimización de proporciones. Y MQL5 es una gran herramienta para ejecutar la lógica comercial. Entonces ¿por qué intentar hacer un martillo con un destornillador?
Como resultado, nació una solución simple y elegante: utilizamos Python para seleccionar proporciones y MQL5 para negociar. Veamos cómo funciona:
double g_coeffs[7] = {0.2752466, 0.01058082, 0.55162082, 0.03687016, 0.27721318, 0.1483476, 0.0008025};
Estos siete números son la quintaesencia de todo nuestro modelo matemático. Contienen semanas de optimización, miles de iteraciones del algoritmo Nelder-Mead y horas de análisis de datos históricos. Lo más importante: ¡funcionan!
double GetPrediction(double price_t1, double price_t2) { return g_coeffs[0] * price_t1 + // Linear t-1 g_coeffs[1] * MathPow(price_t1, 2) + // Quadratic t-1 g_coeffs[2] * price_t2 + // Linear t-2 g_coeffs[3] * MathPow(price_t2, 2) + // Quadratic t-2 g_coeffs[4] * (price_t1 - price_t2) + // Price change g_coeffs[5] * MathSin(price_t1) + // Cyclic g_coeffs[6]; // Constant }
La ecuación de pronóstico en sí se transfirió a MQL5 prácticamente sin cambios.
Merece especial atención el mecanismo de entrada al mercado. A diferencia de la versión de prueba de Python, aquí hemos implementado una lógica de gestión de posiciones más avanzada. El sistema puede mantener varias posiciones simultáneamente, aumentando el volumen cuando se confirma la señal:
void OpenPosition(bool buy_signal, double lot) { MqlTradeRequest request; MqlTradeResult result; ZeroMemory(request); request.action = TRADE_ACTION_DEAL; request.symbol = Symbol(); request.volume = lot; request.type = buy_signal ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; request.price = buy_signal ? SymbolInfoDouble(Symbol(), SYMBOL_ASK) : SymbolInfoDouble(Symbol(), SYMBOL_BID); // ... other parameters }
Aquí se produce el cierre automático de todas las posiciones al alcanzar el beneficio objetivo.
if(total_profit >= ProfitTarget) { CloseAllPositions(); return; }
Presté especial atención al procesamiento de las nuevas barras: no hubo sacudidas sin sentido con cada tick.
bool isNewBar() { datetime lastbar_time = datetime(SeriesInfoInteger(Symbol(), PERIOD_CURRENT, SERIES_LASTBAR_DATE)); if(last_time == 0) { last_time = lastbar_time; return(false); } if(last_time != lastbar_time) { last_time = lastbar_time; return(true); } return(false); }
El resultado es un robot comercial compacto pero funcional. Sin adornos innecesarios: solo lo que realmente necesita para hacer el trabajo. El código completo ocupa menos de 300 líneas e incluye todas las comprobaciones y protecciones necesarias.
¿Sabes qué es lo mejor? Este enfoque de separar las preocupaciones entre Python y MQL5 ha demostrado ser increíblemente flexible. ¿Quieres experimentar con nuevas proporciones? Simplemente recalculelos en Python y actualice la matriz en MQL5. ¿Necesita agregar nuevas condiciones comerciales? La lógica comercial en MQL5 se puede ampliar fácilmente sin necesidad de reescribir la parte matemática.
Aquí está la prueba del EA:
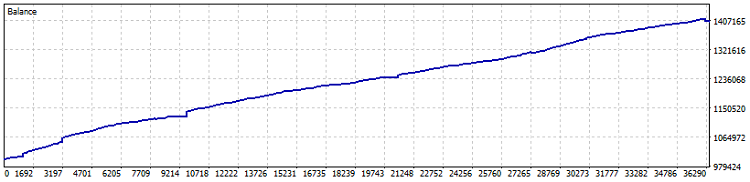
Prueba en cuenta Netting, 40% de beneficio desde 2015 (la optimización del ratio se realizó durante el último año). El drawdown en cifras es del 0,82% y el beneficio mensual es superior al 4%. Pero es mejor poner en marcha una máquina de este tipo sin apalancamiento: dejar que obtenga beneficios a un ritmo ligeramente mejor que los bonos y los depósitos en dólares. Por separado, durante la prueba, se negociaron 7.800 lotes. Esto supone como mínimo un uno y medio por ciento adicional de rentabilidad.
En general, creo que la idea de transferir las proporciones es buena. Al final, lo principal en el trading algorítmico no es la complejidad del sistema, sino su fiabilidad y previsibilidad. A veces, siete números, seleccionados correctamente con la ayuda de las matemáticas modernas, son suficientes para esto.
¡Importante! El EA utiliza el promedio de posición DCA (promedio de tiempo, en sentido figurado), por lo que es muy riesgoso. Si bien las pruebas en Netting con algunas configuraciones conservadoras muestran resultados sobresalientes, recuerde siempre el peligro de promediar posiciones y que un EA de este tipo puede vaciar su depósito a cero de una sola vez.
Ideas para mejorar
Ya es de noche profunda ahora. Estoy terminando el artículo, tomando café, mirando los gráficos en el monitor y pensando en cuánto más se puede hacer con este sistema. Ya sabes, en el trading algorítmico suele ocurrir así: justo cuando parece que todo está listo, aparecen una docena de nuevas ideas para mejorar.
¿Y sabéis qué es lo más interesante? Todas estas mejoras deben funcionar como un solo organismo. No basta con incluir un montón de funciones interesantes: es necesario que se complementen entre sí armoniosamente, creando un sistema de comercio verdaderamente confiable.
En última instancia, nuestro objetivo no es crear un sistema perfecto: simplemente no existe. El objetivo es hacer que el sistema sea lo suficientemente inteligente para generar dinero, pero lo suficientemente simple para no desmoronarse en el peor momento posible. Como dice el dicho, lo mejor es enemigo de lo bueno.
| Archivos | Descripción del archivo |
|---|---|
| MarketSolver.py | Código para seleccionar ratios y también comercio online a través de Python si es necesario |
| MarketSolver.mql5 | Código de EA MQL5 para operar con ratios seleccionados |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16473
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Dominando los registros (Parte 1): Conceptos fundamentales y primeros pasos en MQL5
Dominando los registros (Parte 1): Conceptos fundamentales y primeros pasos en MQL5
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
No hay omisiones en el Asesor Experto publicado. Esto obviamente no es un código de una cuenta real, no hay filtros mencionados aquí.
Sólo una demostración de la idea, que no está mal tampoco.
Estoy de acuerdo
¡Sólo kapets (lo siento)! Durante varias horas de estudio de tus materiales por 10ª vez veo que andamos por los mismos caminos (pensamientos).
Realmente espero que sus fórmulas me ayuden a formalizar matemáticamente lo que ya veo/uso. Sólo ocurrirá en un caso: si las entiendo. Mi madre solía decir: "Estudia, hijo". Lloro lágrimas amargas con las matemáticas. Veo que muchas cosas son sencillas, pero no sé CÓMO. Intento meterme en parábolas, regresiones, desviaciones.... Es difícil llegar a 6º con 65 años.
// No basta con poner un montón de características chulas: necesitas que se complementen armoniosamente, creando un sistema de trading realmente fiable.
Sí. Tanto la selección de características como la posterior optimización son como enderezar el ocho de una rueda de bicicleta. Hay que aflojar algunos radios, apretar otros y hacerlo obedeciendo estrictamente las leyes de este proceso. Entonces la rueda estará nivelada, pero si se adopta el enfoque equivocado, si los radios se aprietan de forma incorrecta, es posible hacer un "diez" de una rueda normal.
En nuestra empresa, los "radios" deben ayudarse mutuamente, no tirar de la manta sobre sí mismos en detrimento de otros "radios".
No creo que sea eficaz predecir el precio basándose únicamente en los dos últimos datos.
¿Está de acuerdo?
No creo que sea eficaz predecir el precio basándose únicamente en los dos últimos datos.
¿No está de acuerdo?