Diskussion zum Artikel "Nichtlineare Regressionsmodelle an der Börse"
Das ist sehr merkwürdig:
Было несколько забавных моментов в процессе отладки. Например, система начала выдавать серию противоречивых сигналов буквально каждые несколько минут. Купить, продать, снова купить... Классическая ошибка начинающего алгоритмического трейдера — слишком частые входы в рынок. Решение оказалось до смешного простым — добавил таймаут в 15 минут между сделками и фильтр на открытые позиции.
Es stellt sich heraus, dass widersprüchliche Signale des Modells nach dem Zufallsprinzip künstlich ausgedünnt werden. Und wenn der bedingte Handelsstartpunkt um 15 Minuten verschoben wird, bekommen wir dann im gleichen Zeitintervall Trades in andere Richtungen?
Ich mag den Höhenflug, die Versuche, die Schaffung von TC aus verschiedenen ungewöhnlichen Blickwinkeln anzugehen :)
Eigentlich ist dies der Prozess der Kreativität, die manchmal zum Auftreten von genialen Lösungen führt.


Die Prognosen selbst sehen eher kurzfristig aus:
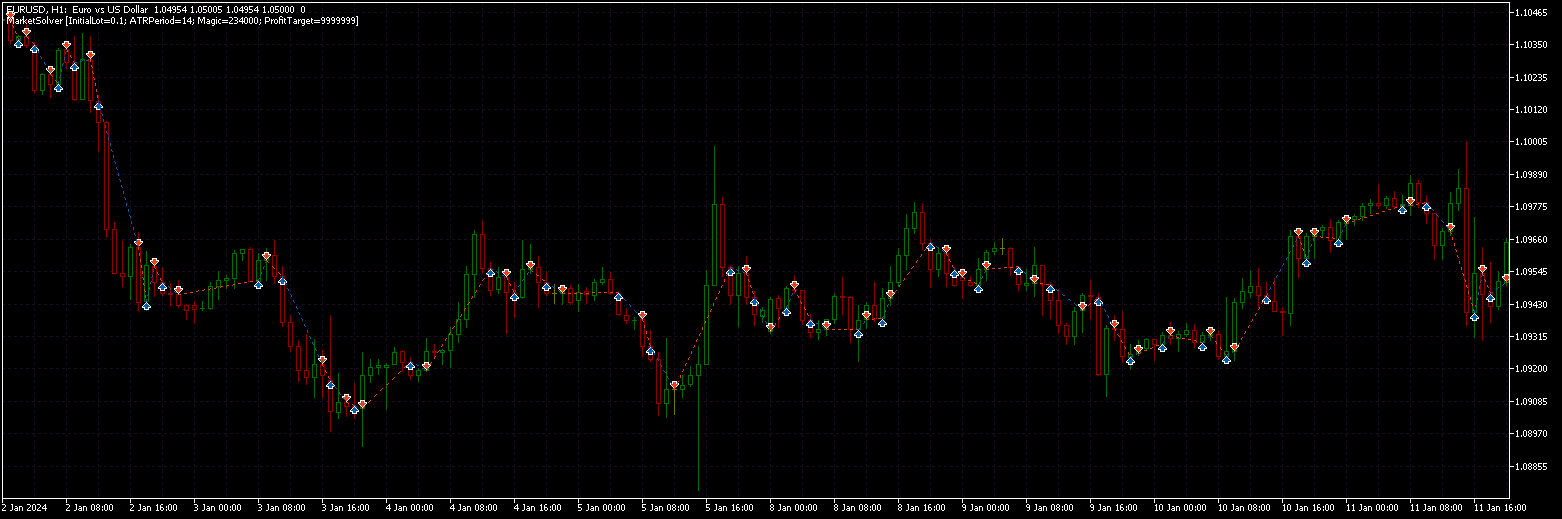
Der modifizierte EA ist angehängt (Tester-Version). Closing on profit ist durch den Parameter deaktiviert.
Eine weitere Sache, die mir auffiel, war das asymmetrische Signal (Prognose >= ask - kaufen, Prognose < ask (warum nicht bid?) - verkaufen). Aber wenn man eine Position für eine Stunde oder länger hält, spielt das wahrscheinlich keine Rolle.
Eine weitere Sache, die mir auffiel, war das asymmetrische Signal (Prognose >= ask - kaufen, Prognose < ask (warum nicht bid?) - verkaufen). Aber wenn man eine Position für eine Stunde oder länger hält, spielt das wahrscheinlich keine Rolle.
Haben Sie die Antwort auf die Frage gefunden?
Dies ist der wichtigste Punkt eines jeden TS, man darf keine Signale verpassen, sonst bricht die ganze Logik zusammen, oder ist es hier nicht so?
Forum zum Thema Handel, automatisierte Handelssysteme und Testen von Handelsstrategien.
Diskussion über den Artikel "Nichtlineare Regressionsmodelle an der Börse".
Stanislav Korotky, 2024.11.27 19:05
Das ist sehr merkwürdig:
Es stellt sich heraus, dass widersprüchliche Signale des Modells künstlich und zufällig ausgedünnt werden. Und wenn der bedingte Handelsstartpunkt um 15 Minuten verschoben wird, werden wir dann im gleichen Zeitintervall Abschlüsse in andere Richtungen erhalten?
Der Artikel ist interessant, weil er deutlich zeigt, wie wenige Variablen erforderlich sind, um die Geschichte der Preisbewegung mit ausreichender Genauigkeit zu beschreiben, um im Tester Gewinne zu erzielen.
Ich verstehe nur nicht, dass im Text von regelmäßigen Überoptimierungen die Rede ist, aber ein Chart mit festen Werten vorgeschlagen wird. Oder werden die Koeffizienten dort mit einer gewissen Fensterfrequenz ausgewählt und in einem mehrdimensionalen Array gespeichert? Ich habe den Code nicht geparst.
Haben Sie versucht, andere Methoden zur Optimierung der Formel zu verwenden? Andrei Dick beschäftigt sich intensiv damit. Vielleicht erlaubt Ihnen einer der von ihm beschriebenen Algorithmen, ganz auf Python zu verzichten?
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Nichtlineare Regressionsmodelle an der Börse :
Ich habe die letzten drei Jahre damit verbracht, etwas zu entwickeln, das tatsächlich funktioniert. Ich habe viele Dinge ausprobiert - von den einfachsten Regressionen bis hin zu ausgeklügelten neuronalen Netzen. Und wissen Sie was? Es ist mir gelungen, Ergebnisse bei der Klassifizierung zu erzielen, aber noch nicht bei der Regression.
Es war jedes Mal die gleiche Geschichte - in der Geschichte läuft alles wie am Schnürchen, aber wenn ich es auf den realen Markt bringe, muss ich Verluste hinnehmen. Ich weiß noch, wie begeistert ich von meinem ersten Faltungsnetzwerk war. R2 bei 1,00% im Training. Es folgten zwei Wochen Handel und ein Minus von 30 % der Einlage. Klassische Überanpassung in ihrer schönsten Form. Ich schaltete die Visualisierung vorwärts und beobachtete, wie sich die regressionsbasierte Prognose mit der Zeit immer weiter von den realen Preisen entfernte...
Aber ich bin ein starrköpfiger Mensch. Nach einem weiteren Verlust beschloss ich, tiefer zu graben und begann, wissenschaftliche Artikel zu sichten. Und wissen Sie, was ich in den verstaubten Archiven ausgegraben habe? Es stellt sich heraus, dass der alte Mandelbrot bereits von der fraktalen Natur der Märkte gesprochen hat. Und wir alle versuchen, mit linearen Modellen zu handeln! Es ist, als würde man versuchen, die Länge einer Küstenlinie mit einem Lineal zu messen - je genauer man misst, desto länger wird sie.
Irgendwann dämmerte es mir: Was ist, wenn ich versuche, die klassische technische Analyse mit nichtlinearer Dynamik zu kreuzen? Nicht diese groben Indikatoren, sondern etwas Ernsthafteres - Differentialgleichungen, adaptive Verhältnisse. Das hört sich kompliziert an, ist aber im Grunde genommen nur ein Versuch, den Markt in seiner Sprache zu verstehen.
Kurz gesagt, ich nahm Python, schloss die Bibliotheken für maschinelles Lernen an und begann zu experimentieren. Ich habe mich sofort entschieden - kein akademischer Schnickschnack, nur das, was wirklich brauchbar ist. Keine Supercomputer - nur ein normaler Acer-Laptop, ein superstarker VPS und ein MetaTrader 5-Terminal. Aus all dem entstand das Modell, von dem ich Ihnen erzählen möchte.
Autor: Yevgeniy Koshtenko