
Применение метода Монте-Карло в обучении с подкреплением
Краткое изложение предыдущего материала и методика улучшения алгоритма
В предыдущей статье мы познакомились с алгоритмом Random Decision Forest и написали простого самообучающегося эксперта на основе Reinforcement learning (обучения с подкреплением).
Было отмечено основное преимущество такого подхода:
- простота написания торгового алгоритма и высокая скорость "обучения". Обучение с подкреплением (далее просто RL) легко внедряется в любого торгового эксперта и увеличивает скорость его оптимизации.
В то же время у такого подхода есть один существенный недостаток:
- алгоритм склонен к переоптимизации (переобучению), другими словами — к слабой генерализации (обобщению) на генеральной совокупности, распределение исходов которой неизвестно. Это означает, что он не ищет реальные фундаментальные рыночные закономерности, свойственные всему историческому периоду финансового инструмента, а оверфитится (переобучается) на текущую рыночную ситуацию, тогда как глобальные закономерности остаются по ту сторону "понимания" обученного агента. Впрочем, генетическая оптимизация обладает тем же недостатком и работает на порядки медленнее при большом количестве переменных.
Существует две основные техники для борьбы с переобучением:
- Feature ingeneering или конструирование признаков. Основной задачей этого подхода является подбор таких признаков и целевой переменной, которые описывали бы всю генеральную совокупность с низкой ошибкой. Другими словами — это поиск правдоподобных закономерностей статистическими и эконометрическими методами через перебор предикторов. На нестационарных рынках эта задача является достаточно сложной и, для определенных стратегий, неразрешимой. Тем не менее, нужно стремиться выбирать оптимальную стратегию.
- Regularization — или регуляризация — используется для огрубления модели посредством внесения поправок на уровне используемого алгоритма. Из предыдущей статьи мы помним, что в RDF для этого используется параметр r. Регуляризация позволяет добиться баланса ошибок между обучающей и тестовой выборками, увеличивая устойчивость модели на новых данных (когда это в принципе возможно).
Усовершенствованный подход к обучению с подкреплением
Обозначенные выше техники включены в алгоритм оригинальным способом. С одной стороны, конструирование признаков осуществляется через перебор ценовых приращений и выбор нескольких наилучших, с другой стороны, через тюнинг параметра r, селектируются модели с наименьшей ошибкой классификации на новых (out-of-bag) данных.
В дополнение, появилась новая возможность создания нескольких RL агентов одновременно, которым можно задавать различные настройки, что, в теории, должно повысить устойчивость модели на новых данных. Перебор моделей осуществляется в оптимизаторе методом Монте-Карло (случайным сэмплированием меток), а наилучшая модель записывается в файл для дальнейшего использования.
Создание базового класса CRLAgent
Для удобства работы, библиотека выполнена на ООП, что позволяет легко подключать ее к эксперту и объявлять необходимое количество RL агентов.
Здесь я опишу некоторые поля класса для более глубокого понимания структуры взаимодействия внутри программы.
//+------------------------------------------------------------------+ //|RL agent base class | //+------------------------------------------------------------------+ class CRLAgent { public: CRLAgent(string,int,int,int,double, double); ~CRLAgent(void); static int agentIDs; void updatePolicy(double,double&[]); //Обновляем политику лернера после каждой сделки void updateReward(); //Обновляем вознаграждение после закрытия сделки double getTradeSignal(double&[]); //Получаем торговый сигнал от обученного агента или рэндомно int trees; double r; int features; double rferrors[], lastrferrors[]; string Name;
Первые три метода служат для формирования политики (стратегии) лернера (агента), обновления вознаграждений и получения торгового сигнала от обученного агента. Они подробно описаны в первой статье.
Далее объявлены вспомогательные поля, определяющие настройки случайного леса, количество признаков (входных переменных), массивы для хранения ошибок модели и имя агента (группы агентов).
private: CMatrixDouble RDFpolicyMatrix; CDecisionForest RDF; CDFReport RDF_report; double RFout[]; int RDFinfo; int agentID; int numberOfsamples; void getRDFstructure(); double getLastProfit(); int getLastOrderType(); void RecursiveElimination(); double bestFeatures[][2]; int bestfeatures_num; double prob_shift; bool random; };
Далее объявлена матрица для сохранения параметризованной политики лернера, объект случайного леса и вспомогательный объект для хранения ошибок.
Для хранения уникального идентификатора агента присутствует статическая переменная:
static int CRLAgent::agentIDs=0;
Конструктор инициализирует все переменные перед началом работы:
CRLAgent::CRLAgent(string AgentName,int number_of_features, int bestFeatures_number, int number_of_trees,double regularization, double shift_probability) { random=false; MathSrand(GetTickCount()); ArrayResize(rferrors,2); ArrayResize(lastrferrors,2); Name = AgentName; ArrayResize(RFout,2); trees = number_of_trees; r = regularization; features = number_of_features; bestfeatures_num = bestFeatures_number; prob_shift = shift_probability; if(bestfeatures_num>features) bestfeatures_num = features; ArrayResize(bestFeatures,1); numberOfsamples = 0; agentIDs++; agentID = agentIDs; getRDFstructure(); }
В самом конце управление передается методу getRDFstructure(), который выполняет следующие действия:
//+------------------------------------------------------------------+ //|Load learned agent | //+------------------------------------------------------------------+ CRLAgent::getRDFstructure(void) { string path=_Symbol+(string)_Period+Name+"\\"; if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(FileIsExist(path+"RFlasterrors"+(string)agentID+".rl",FILE_COMMON)) { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,lastrferrors,0); FileClose(getRDF); } while (getRDF<0); } else { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } while (getRDF<0); } return; } if(FileIsExist(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON)) { int getRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_READ|FILE_TXT|FILE_COMMON); CSerializer serialize; string RDFmodel=""; while(FileIsEnding(getRDF)==false) RDFmodel+=" "+FileReadString(getRDF); FileClose(getRDF); serialize.UStart_Str(RDFmodel); CDForest::DFUnserialize(serialize,RDF); serialize.Stop(); getRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,bestFeatures,0); FileClose(getRDF); getRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,rferrors,0); FileClose(getRDF); getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } else random = true; }
В случае, если запущен процесс оптимизации эксперта, проверяется наличие файлов ошибок, которые были записаны на предыдущих итерациях оптимизатора. Таким образом, на каждой новой итерации сравниваются ошибки модели — для последующего выбора наименьшей.
В случае, если эксперт запущен в режиме тестирования, происходит загрузка обученной модели из файлов для последующего использования. Также, последние ошибки модели стираются и задаются значения по умолчанию равные единице, чтобы новый процесс оптимизации начинался с нуля.
После очередного прогона в оптимизаторе происходит обучение лернера следующим образом:
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination();
Передается управление указанному методу, который предназначен для последовательного отбора признаков, а именно приращений цен. Давайте посмотрим как это работает:
//+------------------------------------------------------------------+ //|Recursive feature elimitation for matrix inputs | //+------------------------------------------------------------------+ CRLAgent::RecursiveElimination(void) { //feature transformation, making every 2 features as returns with different lag's ArrayResize(bestFeatures,0); ArrayInitialize(bestFeatures,0); CDecisionForest mRDF; CMatrixDouble m; CDFReport mRep; m.Resize(RDFpolicyMatrix.Size(),3); int modelCounterInitial = 0; for(int bf=1;bf<features;bf++) { for(int i=0;i<RDFpolicyMatrix.Size();i++) { m[i].Set(0,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][bf]); //заполняем матрицу приращениями (цену нулевого индекса массива делим на цену со смещением bf) m[i].Set(1,RDFpolicyMatrix[i][features]); m[i].Set(2,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),1,2,trees,r,RDFinfo,mRDF,mRep); //Обучаем случайный лес, где предиктором является только выбранное приращение ArrayResize(bestFeatures,ArrayRange(bestFeatures,0)+1); bestFeatures[modelCounterInitial][0] = mRep.m_oobrelclserror; //сохраняем ошибку на oob выборке bestFeatures[modelCounterInitial][1] = bf; //сохраняем "лаг" приращения modelCounterInitial++; } ArraySort(bestFeatures); //сортируем массив (по нулевому измерению), то есть по ошибке oob ArrayResize(bestFeatures,bestfeatures_num); //оставляем только лучшие bestfeatures_num признаков m.Resize(RDFpolicyMatrix.Size(),2+ArrayRange(bestFeatures,0)); for(int i=0;i<RDFpolicyMatrix.Size();i++) { // снова заполняем матрицу, теперь уже всеми лучшими признаками for(int l=0;l<ArrayRange(bestFeatures,0);l++) { m[i].Set(l,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][(int)bestFeatures[l][1]]); } m[i].Set(ArrayRange(bestFeatures,0),RDFpolicyMatrix[i][features]); m[i].Set(ArrayRange(bestFeatures,0)+1,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),ArrayRange(bestFeatures,0),2,trees,r,RDFinfo,RDF,RDF_report); // обучаем случайный лес на выбранных лучших признаках }
Посмотрим метод обучения агента целиком:
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination(); if(RDF_report.m_oobrelclserror<lastrferrors[1]) { string path=_Symbol+(string)_Period+Name+"\\"; //FileDelete(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON); CSerializer serialize; serialize.Alloc_Start(); CDForest::DFAlloc(serialize,RDF); serialize.SStart_Str(); CDForest::DFSerialize(serialize,RDF); serialize.Stop(); int setRDF; do { setRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); if(setRDF<0) continue; lastrferrors[0]=RDF_report.m_relclserror; lastrferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,lastrferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_WRITE|FILE_TXT|FILE_COMMON); FileWrite(setRDF,serialize.Get_String()); FileClose(setRDF); setRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); rferrors[0]=RDF_report.m_relclserror; rferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,rferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileWriteArray(setRDF,bestFeatures); FileClose(setRDF); } while(setRDF<0); } } } return 1-RDF_report.m_oobrelclserror; }
После того, как выполнен отбор признаков и агент обучен, происходит сравнение ошибки классификации агента на текущем проходе оптимизации с минимальной ошибкой, сохраненной в ходе оптимизации в целом. В том случае, если ошибка текущего агента меньше, то текущая модель сохраняется как лучшая, и последующие сравнения происходят с ошибкой этой модели.
Отдельно следует рассмотреть метод Монте-Карло, или случайного сэмплирования целевых переменных:
//+------------------------------------------------------------------+ //|Get trade signal | //+------------------------------------------------------------------+ double CRLAgent::getTradeSignal(double &featuresValues[]) { double res=0.5; if(!MQLInfoInteger(MQL_OPTIMIZATION) && !random) { double kerfeatures[]; ArrayResize(kerfeatures,ArrayRange(bestFeatures,0)); ArrayInitialize(kerfeatures,0); for(int i=0;i<ArraySize(kerfeatures);i++) { kerfeatures[i] = featuresValues[0]/featuresValues[(int)bestFeatures[i][1]]; } CDForest::DFProcess(RDF,kerfeatures,RFout); return RFout[1]; } else { if(countOrders()==0) if(rand()/32767.0<0.5) res = 0; else res = 1; else { if(countOrders(0)!=0) if(rand()/32767.0>prob_shift) res = 0; else res = 1; if(countOrders(1)!=0) if(rand()/32767.0<prob_shift) res = 0; else res = 1; } } return res; }
Если советник находится не в режиме оптимизации, то для получения торговых сигналов используется уже обученная модель, загруженная при инициализации эксперта. Иначе, если идет процесс оптимизации или же отсутствуют файлы модели, сигналы происходят случайно в случае отсутствия открытых позиций (50/50) и со смещенной вероятностью, заданной переменной prob_shift при наличии открытых ордеров. Таким образом, например, если уже существует открытая сделка на покупку, то можно сместить вероятность возникновения сигнала на продажу до 0.1 (вместо 0.5), таким образом, итоговое количество сэмплов в обучающей выборке уменьшится, а позиции будут удерживаться дольше. В то же время, при задании prob_shift >= 0.5, количество сделок будет увеличиваться.
Создание класса CRLAgents
Теперь мы можем иметь множество агентов(лерненров), выполняющих различные задачи в торговой системе. Для более удобного менеджмента групп однородных лернеров предусмотрен настоящий класс.
//+------------------------------------------------------------------+ //|Multiple RL agents class | //+------------------------------------------------------------------+ class CRLAgents { private: struct Agents { double inpVector[]; CRLAgent *ag; double rms; double oob; }; void getStatistics(); string groupName; public: CRLAgents(string,int,int,int,int,double,double); ~CRLAgents(void); Agents agent[]; void updatePolicies(double); void updateRewards(); double getTradeSignal(); double learnAllAgents(); void setAgentSettings(int,int,int,double); };
Структура Agents принимает параметры каждого лернера, а массив структур содержит общее их количество. В случае одного агента также имеет смысл пользоваться именно этим классом.
Конструктор принимает все необходимые параметры для обучения:
CRLAgents::CRLAgents(string AgentsName,int agentsQuantity,int features, int bestfeatures, int treesNumber,double regularization, double shift_probability) { groupName=AgentsName; ArrayResize(agent,agentsQuantity); for(int i=0;i<agentsQuantity;i++) { ArrayResize(agent[i].inpVector,features); ArrayInitialize(agent[i].inpVector,0); agent[i].ag = new CRLAgent(AgentsName, features, bestfeatures, treesNumber, regularization, shift_probability); agent[i].rms = agent[i].ag.rferrors[0]; agent[i].oob = agent[i].ag.rferrors[1]; } }
Среди которых: имя группы агентов, количество воркеров, количество признаков для каждого воркера, количество лучших отобранных признаков, количество деревьев в лесе, параметр регуляризации (разделения на тренировочную и тестовую выборки), и смещение вероятности для контроля количества сделок.
Видно, что в массив структур помещаются объекты лернеров с теми же входными переменными, а также ошибки на трейн и тест.
Метод обучения агентов выполняет вызов метода обучения для каждого из базового класса CRLAgent, и возвращает усредненную ошибку на тестовой выборке по всем агентам:
//+------------------------------------------------------------------+ //|Learn all agents | //+------------------------------------------------------------------+ double CRLAgents::learnAllAgents(void){ double err=0; for(int i=0;i<ArraySize(agent);i++) err+=agent[i].ag.learnAnAgent(); return err/ArraySize(agent); }
Эта ошибка используется как кастомный критерий оптимизации для того, чтобы просто визуализировать разброс ошибок при переборе моделей методом Монте-Карло.
Поскольку при создании некоторого количества лернеров в одной подгруппе, их настройки остаются одинаковыми, существует метод корректировки параметров каждого отдельного лернера:
//+------------------------------------------------------------------+ //|Change agents settings | //+------------------------------------------------------------------+ CRLAgents::setAgentSettings(int agentNumber,int features,int bestfeatures,int treesNumber,double regularization,double shift_probability) { agent[agentNumber].ag.features=features; agent[agentNumber].ag.bestfeatures_num=bestfeatures; agent[agentNumber].ag.trees=treesNumber; agent[agentNumber].ag.r=regularization; agent[agentNumber].ag.prob_shift=shift_probability; ArrayResize(agent[agentNumber].inpVector,features); ArrayInitialize(agent[agentNumber].inpVector,0); }
В отличие от базового класса CRLAgent, в CRLAgents торговый сигнал выводится как среднее для сигналов всех лернеров, входящих в подгруппу:
//+------------------------------------------------------------------+ //|Get common trade signal | //+------------------------------------------------------------------+ double CRLAgents::getTradeSignal() { double signal[]; double sig=0; ArrayResize(signal,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) sig+=signal[i]=agent[i].ag.getTradeSignal(agent[i].inpVector); return sig/(double)ArraySize(agent); }
Наконец, метод получения статистики выводит информацию по ошибкам для тест и трейн для всех агентов в конце одиночного прогона в тестере:
//|Get agents statistics | //+------------------------------------------------------------------+ void CRLAgents::getStatistics(void) { double arr[]; double arrrms[]; ArrayResize(arr,ArraySize(agent)); ArrayResize(arrrms,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) { arrrms[i]=agent[i].rms; arr[i]=agent[i].oob; } Print(groupName+" TRAIN LOSS"); ArrayPrint(arrrms); Print(groupName+" OOB LOSS"); ArrayPrint(arr); }
Создание торгового робота на основе библиотеки RL Monte Carlo
Осталось написать простого эксперта для демонстрации возможностей библиотеки. Начнем с первого случая, когда создается всего один агент, который обучается на ценах закрытия торгового инструмента.
#include <RL Monte Carlo.mqh>
input int number_of_passes = 10; input double shift_probab = 0,5; input double regularize=0.6; sinput int number_of_best_features = 5; sinput double treshhold = 0.5; sinput double MaximumRisk=0.01; sinput double CustomLot=0; CRLAgents *ag1=new CRLAgents("RlMonteCarlo",1,500,number_of_best_features,50,regularize,shift_probab);
Подключаем библиотеку и определяем инпуты, которые можно оптимизировать. number_of_passes предназначен для определения количества проходов в оптимизаторе терминала, и никуда не передаётся. Поскольку входы и выходы подбираются воркером случайным образом, то через множественные проходы и определение наименьшей ошибки можно добиться получения оптимальной стратегии. Чем больше проходов установлено, тем выше вероятность получить оптимальную стратегию.
Остальные настройки уже изложены выше и передаются напрямую в модель, которая создана выше. Здесь мы создали одного агента, относящегося к группе "RlMonteCarlo", на вход ему подается 500 признаков, из них будет отобрано 5 лучших признаков. Модель будет иметь 50 деревьев решений, с разделением тренировочной и тестовой выборок 0.6 (параметр r), без смещения вероятности.
В функции OnTester будем возвращать кастомный критерий оптимизации (в виде усредненной ошибки на тестовой выборке по всем лернерам), предварительно обучив их:
//+------------------------------------------------------------------+ //| Expert ontester function | //+------------------------------------------------------------------+ double OnTester() { if(MQLInfoInteger(MQL_OPTIMIZATION)) return ag1.learnAllAgents(); else return NULL; }
При деинициализации эксперта удаляются лернеры и освобождается память:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { delete ag1; }
Вектор предикторов заполняется следующим образом:
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
В данном случае просто берется 500 последних цен закрытия. Помним, что предиктором в модели считается отношение нулевого элемента массива к какому-нибудь другому (с определенным лагом), поэтому установим массив, принимающий цены закрытия, as series. После этого вызывается метод получения торгового сигнала.
Последняя функция является торговой:
//+------------------------------------------------------------------+ //| Place orders | //+------------------------------------------------------------------+ void placeOrders() { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) { if(OrderType()==0 && Tsignal>0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} if(OrderType()==1 && Tsignal<0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} } if(countOrders(0)!=0 || countOrders(1)!=0) return; if(Tsignal<0.5-treshhold && (OrderSend(Symbol(),OP_BUY,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } if(Tsignal>0.5+treshhold && (OrderSend(Symbol(),OP_SELL,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } }
Дополнительно введен параметр treshold (порог), который позволяет задать порог срабатывания сигнала. Например, если вероятность сигнала на покупку меньше 0.6, то ордер открыт не будет.
Оптимизация эксперта RL Monte Carlo Trader
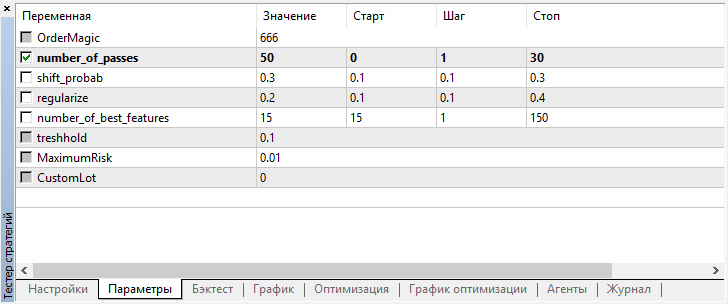
Посмотрим на настройки, которые можно оптимизировать:
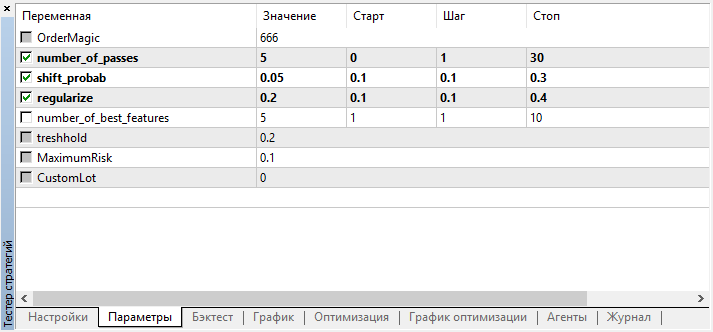
Помним, что number_of_passes не передает лернеру никаких значений, а просто задает количество проходов оптимизатора. Допустим, вы определились с прочими настройками и хотите использовать исключительно перебор методом Монте-Карло, тогда следует оптимизировать только по этому критерию. Остальные четыре настройки можно оптимизировать по желанию.
Еще одна особенность текущей версии заключается в том, что нет необходимости отключать агентов тестирования, поскольку проходы в оптимизаторе не зависят друг от друга и последовательность сохранения моделей не важна.
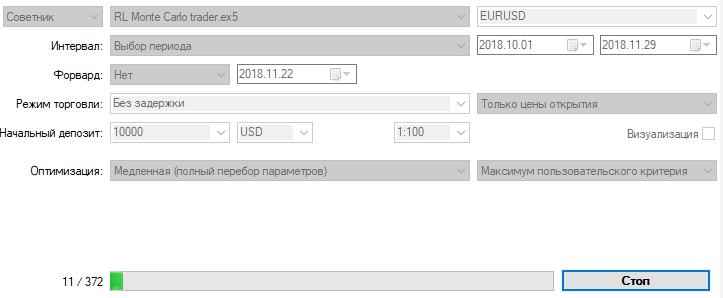
Оптимизируем эксперта с указанными выше настройками на 15-минутном графике за два месяца, по ценам открытия. В качестве критерия оптимизации должен быть выбран "Максимум пользовательского критерия". Процесс оптимизации может быть остановлен в любой момент, когда достигнуто приемлемое значение критерия оптимизации:
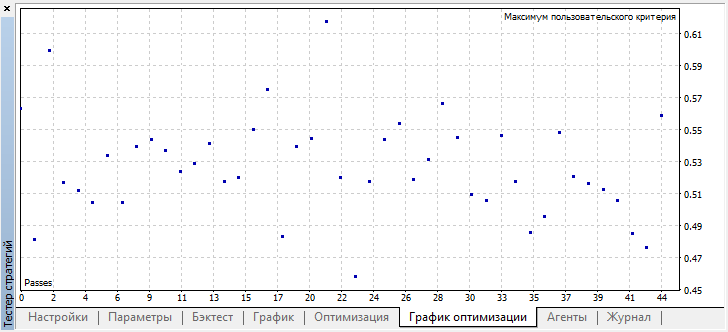
Например, я остановил процесс оптимизации уже на 44 шаге, поскольку одна из лучших моделей превысила порог точности 0.6. Это означает, что ошибка классификации на тестовой выборке упала ниже 0.4. Стоит учесть, что чем лучше модель тем ниже ошибка, но для корректной работы генетического алгоритма (при желании его использовать) значения ошибок перевернуты.
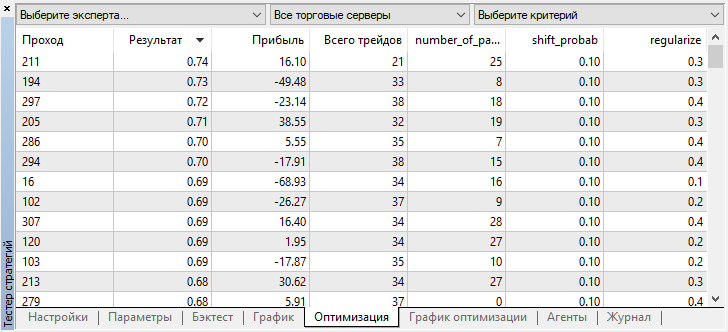
Вы можете проверить настройки лучшей модели во вкладке "оптимизация", отсортировав значения по максимуму пользовательского критерия:
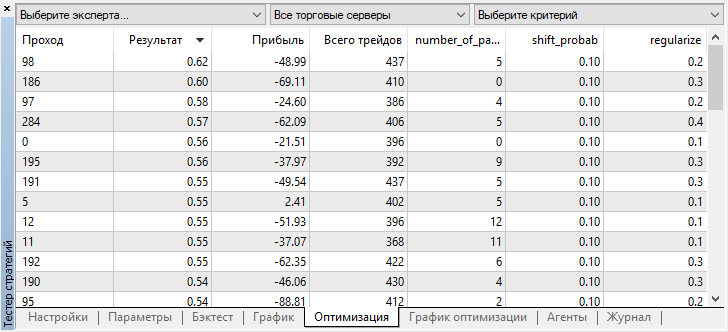
В данном случае лучшая модель получена со смещением вероятности 0.1 и с параметром r 0.2 (тренировочная выборка составляет всего 20% от всей матрицы сделок, тогда как 80% является тестовой подвыборкой).
После остановки оптимизации просто включим одиночный режим тестирования (поскольку лучшая модель записана в файл и загружена будет только она):

Отмотаем историю на два месяца назад и посмотрим, как модель отработает за полные четыре месяца:
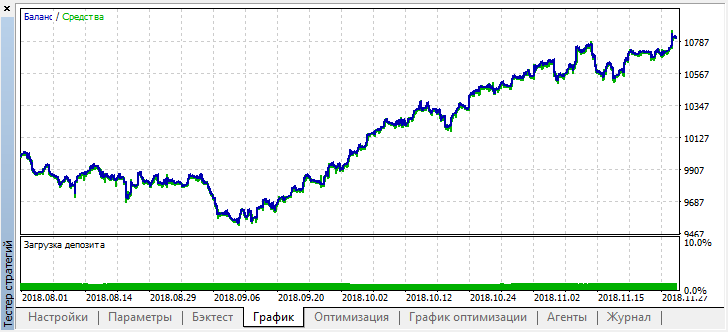
Видно, что полученная модель продержалась еще месяц (почти весь сентябрь), а вот в августе сломалась. Попробуем "затюнить" модель, установив порог "treshhold" равный 0.2:
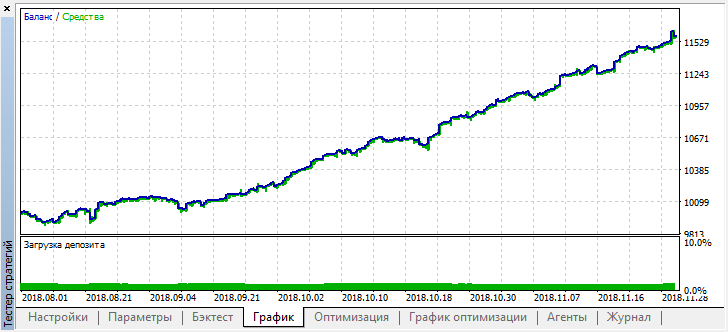
Стало заметно лучше, при уменьшении количества сделок точность модели повысилась. Проводить тестирование на бОльшую глубину можно, при учете если период обучения был соответствующей длины.
Переходим к варианту эксперта, в котором добавлено несколько лернеров, чтобы сравнить эффективность мультиагентного подхода с эффективностью одного агента.
Для этого, при создании группы агентов добавим окончание "Multi", чтобы файлы разных систем не перемешивались, и укажем количество воркеров, например, пять:
CRLAgents *ag1=new CRLAgents("RlMonteCarloMulti",5,500,number_of_best_features,50,regularize,shift_probab);
Но все агенты получились одинаковые (имеют идентичные настройки). Настроить каждого воркера отдельно можно в функции инициализации эксперта:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ag1.setAgentSettings(0,500,20,50,regularize,shift_probab); ag1.setAgentSettings(1,200,15,50,regularize,shift_probab); ag1.setAgentSettings(2,100,10,50,regularize,shift_probab); ag1.setAgentSettings(3,50,5,50,regularize,shift_probab); ag1.setAgentSettings(4,25,2,50,regularize,shift_probab); return(INIT_SUCCEEDED); }
Здесь я решил не мудрить слишком, чтобы окончательно вас не запутать, а просто расположил количество признаков для агентов по убыванию, от 500 к 25. Также, количество лучших отобранных признаков уменьшается от 20 до двух. Прочие настройки оставлены без изменения, но их можно менять и добавлять новые оптимизируемые параметры. Надеюсь, что читатели сами проведут такие эксперименты и поделятся результатами в комментариях к данной статье.
Вспомним, что заполнение массивов значениями предикторов осуществляется в функции:
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
Здесь мы просто заполняем массив inpVector ценами закрытия для каждого лернера, в зависимости от его размера, поэтому функция является универсальной для данного случая и в изменениях не нуждается.
Запустим оптимизацию с точно такими же настройками, как и для одного агента:
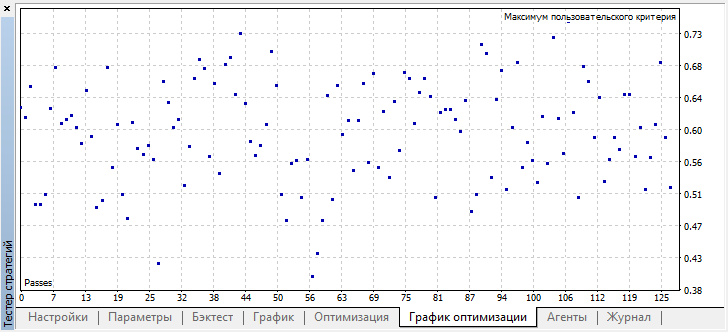
Наилучший результат превзошел отметку 0.7, что гораздо лучше чем в первом случае. Запустим одиночный прогон в тестере:
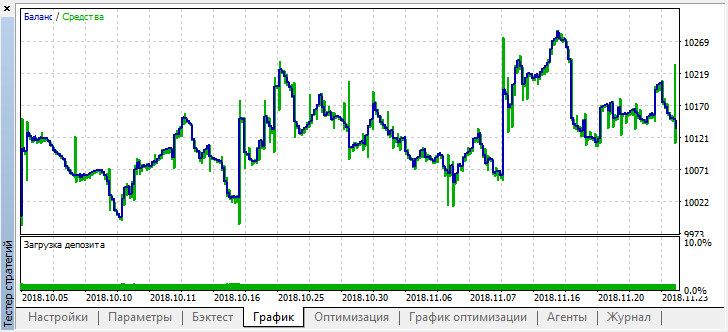
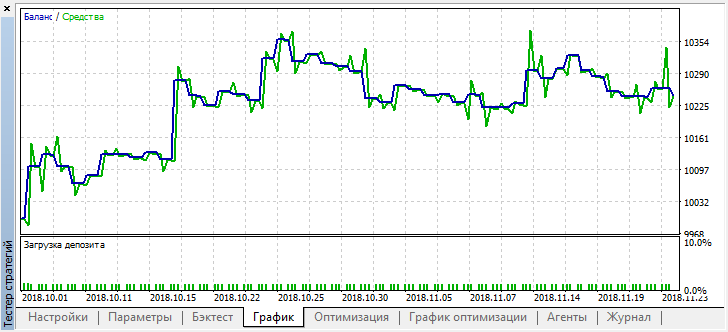
В то же время реальный результат в виде графика баланса стал гораздо хуже, почему так произошло? Посмотрим на количество случайных трейдов лучшего прогона, их всего 21!
Получилось так потому, что при случайном сэмплировании, сигналы нескольких агентов наложились друг на друга, и итоговое количество трейдов уменьшилось. Чтобы исправить это, необходимо устанавливать параметр shift_probab ближе к 0.5, в таком случае количество сделок у каждого отдельного агента станет больше, и количество общих сделок увеличится тоже. С другой стороны, можно просто увеличить период обучения, но для начала посмотрим, можно ли работать с такой моделью дальше. Установим "treshhold" на 0.2 и посмотрим что получилось:
По крайней мере, модель не теряет деньги, хотя количество сделок еще уменьшилось. Обратите внимание, что после одиночного прогона, в лог тестера выводятся ошибки, если вы вдруг их забыли:
2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo TRAIN LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.02703 0.20000 0.09091 0.05714 0.14286 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo OOB LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.21622 0.23333 0.21212 0.17143 0.19048
Теперь протестируем эту модель с начала года. Результаты оказались достаточно стабильными:
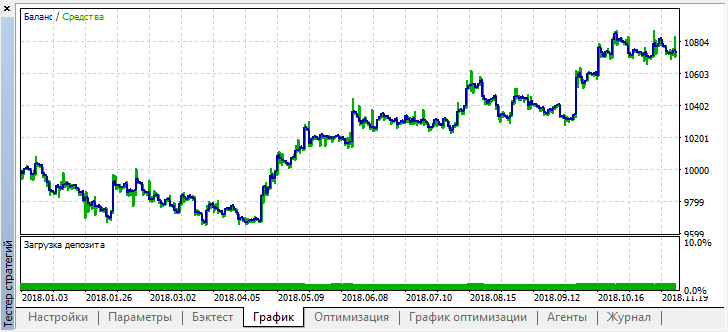
Хорошо, установим shift_probab, допустим, 0.3, и запустим оптимизатор без этого параметра, за те же 2 месяца на 15-минутках (просто попытаемся найти баланс количества сделок):
Я не стал долго мучить свой ноутбук, поскольку сложность вычислений несколько возросла, и после нескольких итераций в оптимизаторе удовлетворился таким результатом:
2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti TRAIN LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.13229 0.16667 0.16262 0.14599 0.20937 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti OOB LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.45377 0.45758 0.44650 0.45693 0.46120
Ошибка на OOB (тестовой выборке) осталась достаточно высокой, тем не менее, при пороге 0.2, за 4 месяца, модель показала прибыль, хотя и вела себя довольно неустойчиво на тестовых данных.
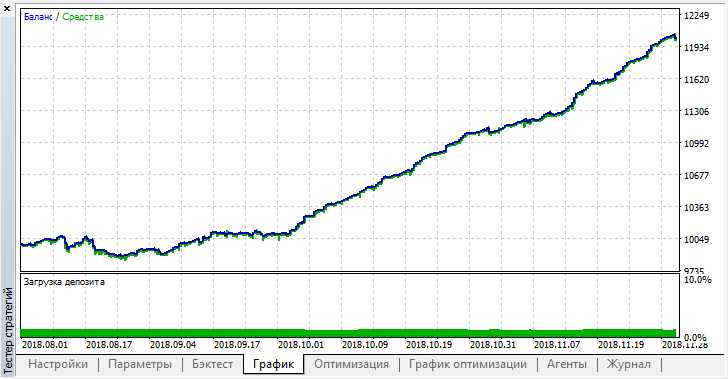
Следует понимать, что все лернеры обучались на тех же самых данных - ценах закрытия, поэтому не было большого смысла добавлять новых. Тем не менее, это был простой пример добавления новых агентов.
Выводы из проделанной работы
Обучение с подкреплением является, пожалуй, одним из самых интересных методов машинного обучения. Всегда заманчиво думать, что искусственный интеллект способен решать задачи торговли на финансовых рынках, обучаясь самостоятельно, без учителя. В то же время, следует обладать широкими знаниями в области машинного обучения, статистики и теории вероятностей, чтобы создать подобное "чудо". Отметим, что метод Монте-Карло и отбор модели по наименьшей ошибке на тестовых данных, значительно улучшил модель, предложенную в первой статье: модель стала меньше переобучаться.
Следует помнить, что выбирать лучшую модель необходимо как по количеству сделок, так и по наименьшей ошибке классификации на out-of-bag выборке. В идеале, ошибки на тренировочной и тестовой выборках должны быть примерно равны и не достигать значения 0.5 (половина примеров предсказана неправильно).
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
 Практическое использование нейросетей Кохонена в алгоритмическом трейдинге (Часть I): Инструментарий
Практическое использование нейросетей Кохонена в алгоритмическом трейдинге (Часть I): Инструментарий
 Раздельная оптимизация стратегии на тренде и флете
Раздельная оптимизация стратегии на тренде и флете
 Утилита для отбора и навигации на MQL5 и MQL4: добавляем вкладки "домашки" и сохраняем графические объекты
Утилита для отбора и навигации на MQL5 и MQL4: добавляем вкладки "домашки" и сохраняем графические объекты
 Как самостоятельно создать и протестировать в MetaTrader 5 инструменты Московской биржи
Как самостоятельно создать и протестировать в MetaTrader 5 инструменты Московской биржи
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
прочтите 2 предыдущих сообщения
Уточните, пожалуйста, что эти сообщения значат? Имеется ввиду, как решить это, чтобы советник заработал
Уточните, пожалуйста, что эти сообщения значат? Имеется ввиду, как решить это, чтобы советник заработал
Добавьте void перед объявлением классов, как в предыдущих сообщениях человек написал