
Обучаем нейросети на осцилляторах без подглядывания в будущее
Введение в look ahead bias или почему модели машинного обучения не работают на новых нестационарных данных
Среди трейдеров, которые занимаются машинным обучением, важной частью экспериментов по созданию торговых систем является подготовка данных. На вход модели обычно подаются индикаторы или приращения цен. В качестве меток часто используются будущие ценовые приращения —то, как график цены вел себя в будущем.
В данном методе разметки сделок кроется самая неприятная особенность, которая приводит к неудовлетворительной производительности моделей на новых нестационарных данных, после обучения на истории. Неэффективность такого метода разметки кроется в "look ahead bias", который определяется как смещение или предвзятость модели относительно истинных закономерностей. Предвзятость "заглядывания вперед" в анализе финансовых временных рядов возникает, когда модель или стратегия использует информацию, которая не была доступна на момент принятия решения.
Следствием этого являются:
- Завышенные и нереалистичные результаты на исторических данных (backtest). Модель показывает почти идеальную прибыльность, потому что она, по сути, "подсматривала в ответы" во время обучения.
- Резкое падение производительности на Out-of-Sample (OOS) данных и в реальной торговле. Когда модель сталкивается с новыми данными, где будущее неизвестно, она не может найти тех идеальных закономерностей, к которым "привыкла", и ее предсказания становятся бесполезными.
- Низкая робастность (устойчивость) модели. Стратегия оказывается чрезмерно подогнанной под историю (overfitting) и не способной адаптироваться к меняющейся рыночной волатильности и режимам.
Возникает потребность использовать другую, более реалистичную разметку, при которой информация из будущего недоступна.
Разметка сделок на базе осцилляторов для избавления от look ahead
В этой статье предложены методы разметки сделок на основе осцилляторов без заглядывания в будущее. Они позволяют создавать более реалистичные и устойчивые на новых данных разметки лейблов с низкой ошибкой классификации. Поскольку осцилляторы генерируют сигналы на покупку и продажу без заглядывания в будущее, алгоритмы машинного обучения не сталкиваются с предвзятостью в разметке и сохраняют свою эффективность на всем историческом интервале торговых инструментов. Благодаря тому, что осцилляторы имеют фиксированную формулу и показания уровней перекупленности и перепроданности, модели обучаются с низкой ошибкой и проходят кросс-валидацию, ведь задача сводится к банальной аппроксимации функции одного осциллятора или их набора.
Несмотря на всю привлекательность такого подхода, он имеет ряд недостатков. Во-первых, не каждый временной ряд можно качественно предсказать или разметить посредством одного лишь осциллятора. Часто зоны перекупленности и перепроданности некорректны и неинформативны, что приводит к ложным сигналам и убыткам. Во-вторых, возникает проблема выбора типа, формулы и периода осциллятора, а также правильных зон перекупленности и перепроданности. Наряду с этим, необходим перебор торговых инструментов для определения того, на каком из них осцилляторы дают наилучшие прогнозы. В-третьих, осцилляторы — это индикаторы разворота. На трендовых рынках они не дают явных предсказаний относительно будущей рыночной динамики и склонны "залипать" в крайних положениях, поэтому их лучше использовать на флэтовых инструментах, на которых вероятность возврата к среднему из зон относительно велика.
Машинное обучение как средство быстрой сборки и корректировки стратегии
Можно сказать, что проще всего было бы подобрать осциллятор под конкретный временной ряд, оптимизировать условия открытия сделок и проверить работу алгоритма на истории. Но также можно унифицировать процесс создания таких стратегий путем добавления пары классификаторов, которые будут отвечать за генерацию торговых сигналов.
Преимущество такого подхода состоит в том, что разметка сделок на основе осцилляторов является более гибкой, чем строгие сигналы на открытие и закрытие сделок. К разметке можно добавить ряд других условий, без необходимости переписывать всю стратегию, тогда как алгоритм обучения моделей всегда остается одним и тем же. В случае хардкодинга торговых стратегий, при добавлении каждого нового индикатора или условия, экспоненциально усложняется логика кода. Но алгоритму машинного обучения все равно с каким количеством признаков работать: он автоматически оценит важность каждого из них и построит прогноз, взвешивая все факторы. Это позволяет легко проводить эксперименты, массово добавляя и убирая фичи и перебирая функции разметки без изменения ядра торговой системы.
Библиотека осцилляторов, которую можно дополнить своими разметчиками
Я написал несколько разметчиков сделок на основе осцилляторов. Полный список функций разметки, которые находятся в библиотеке oscillators_labeling.py.
get_labels_cci(dataset, cci_period=20, oversold_level=-100.0, overbought_level=100.0) -> pd.DataFrame get_labels_stochastic(dataset, stoch_period=14, smooth_k=3, oversold_level=20.0, overbought_level=80.0) -> pd.DataFrame get_labels_bb(dataset, bb_period=20, num_std=2.0) -> pd.DataFrame get_labels_fourier(dataset, lookback_period=20, high_pass_cutoff_idx=5, std_multiplier=1.5) -> pd.DataFrame get_labels_rsi(dataset, rsi_period=14, oversold_level=30.0, overbought_level=70.0) -> pd.DataFrame get_labels_profit_rsi_profit_check(dataset, rsi_period=14, oversold_level=30.0, overbought_level=70.0, min_forecast_period=1, max_forecast_period=15, markup=0.0) -> pd.DataFrame
В библиотеке представлены функции на основе всем известных индикаторов, таких как CCI, Stochastic, Bollindger bands, RSI, а также на основе разложения фурье (для истинных ценителей поиска циклических компонент во временных рядах). Особое внимание будет уделено последней экспериментальной функции на основе RSI — в нее добавлена проверка на прибыльность сделок.
Настройка разметчиков сделок сводится к определению периодов осцилляторов и зон перекупленности и перепроданности. Условия для разметки сделок у всех общие: если цена находится выше уровня перекупленности, формируется сигнал на продажу и наоборот. Если цена находится между уровнями, то сигнал размечается как "не торговать".
Поскольку не все сделки окажутся прибыльными, добавлена функция с проверкой на их прибыльность. Этот разметчик уже с подглядыванием в будущее, но он позволяет сделать кривую баланса более гладкой.
Что происходит внутри функций разметки и как создавать свои собственные
Рассмотрим весь процесс разметки сделок на примере осциллятора RSI. Несмотря на кажущееся обилие кода, есть простой способ создавать свои собственные разметчики с помощью ИИ. Для этого достаточно передать ему данный пример и попросить сделать то же самое, но для другого осциллятора. Поэтому если вы не знакомы с языком Python или какими-то его особенности, это станет отличным вариантом и сэкономит вам время.
Первым блоком расчета меток является функция для построения индикатора по ценам закрытия. Она возвращает значения индикатора. Для ускорения расчетов используется Numba. Следующая функция сравнивает текущие значения осциллятора с пороговыми значениями и возвращает метки. Третья функция вызывает первые две, а затем добавляет в переданный ей датафрейм колонку с метками и возвращает его. Четвертая дополнительная функция делает то же самое что и третья, но с дополнительной проверкой сделок на прибыльность. Она размечает сделки на покупку и продажу не только по условию порогов, но и проверяет, привели ли эти сделки к прибыли, иначе они размечаются как "не торговать".
@njit def calculate_rsi(close_data, period=14): """Экспоненциальное сглаживание RSI (метод Уайлдера)""" rsi = np.zeros(len(close_data)) # Первый расчет - простое среднее gains = 0.0 losses = 0.0 for j in range(1, period + 1): change = close_data[j] - close_data[j - 1] if change > 0: gains += change else: losses += abs(change) avg_gain = gains / period avg_loss = losses / period if avg_loss == 0: rsi[period] = 100.0 else: rs = avg_gain / avg_loss rsi[period] = 100.0 - (100.0 / (1.0 + rs)) # Экспоненциальное сглаживание для остальных значений for i in range(period + 1, len(close_data)): change = close_data[i] - close_data[i - 1] gain = max(change, 0.0) loss = max(-change, 0.0) # Экспоненциальное сглаживание Уайлдера avg_gain = (avg_gain * (period - 1) + gain) / period avg_loss = (avg_loss * (period - 1) + loss) / period if avg_loss == 0: rsi[i] = 100.0 else: rs = avg_gain / avg_loss rsi[i] = 100.0 - (100.0 / (1.0 + rs)) return rsi @njit def calculate_labels_rsi(close_data, rsi_data, oversold_level=30.0, overbought_level=70.0): """ Разметка на основе уровней RSI. """ labels = [] for i in range(len(close_data)): curr_rsi = rsi_data[i] # Сигнал на покупку: RSI в зоне перепроданности if curr_rsi < oversold_level: labels.append(0.0) # Buy # Сигнал на продажу: RSI в зоне перекупленности elif curr_rsi > overbought_level: labels.append(1.0) # Sell else: labels.append(2.0) # Hold - RSI в нейтральной зоне return labels def get_labels_rsi(dataset, rsi_period=14, oversold_level=30.0, overbought_level=70.0) -> pd.DataFrame: dataset = dataset.copy() close_data = dataset['close'].values rsi_data = calculate_rsi(close_data, rsi_period) dataset['rsi'] = rsi_data labels = calculate_labels_rsi(close_data, rsi_data, oversold_level, overbought_level) # Обрезаем датасет dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.drop(columns=['rsi']) return dataset.dropna() def get_labels_profit_rsi_profit_check(dataset, rsi_period=14, oversold_level=30.0, overbought_level=70.0, min_forecast_period=1, max_forecast_period=15, markup=0.0) -> pd.DataFrame: dataset = dataset.copy() close_data = dataset['close'].values rsi_data = calculate_rsi(close_data, rsi_period) # Используем NaN для начального заполнения, так как для последнего max_forecast_period # элементов невозможно определить будущую цену. labels = [np.nan] * len(close_data) # Начинаем итерацию с индекса, после которого RSI уже посчитан start_index = rsi_period # Обходим до конца, который позволяет спрогнозировать будущую цену for i in range(start_index, len(close_data) - max_forecast_period): curr_rsi = rsi_data[i] curr_pr = close_data[i] # 1. Сначала определяем сигнал по RSI rsi_signal = 2.0 # Hold по умолчанию # Сигнал на покупку: RSI в зоне перепроданности if curr_rsi < oversold_level: rsi_signal = 0.0 # Buy # Сигнал на продажу: RSI в зоне перекупленности elif curr_rsi > overbought_level: rsi_signal = 1.0 # Sell # 2. Если есть сигнал (Buy или Sell), проверяем его прибыльность if rsi_signal != 2.0: # Выбираем случайный период прогноза rand_period = random.randint(min_forecast_period, max_forecast_period) future_pr = close_data[i + rand_period] # Проверка прибыльности для сигнала Buy (0.0) if rsi_signal == 0.0: # Покупка прибыльна, если будущая цена > текущей цены + markup if (future_pr - markup) > curr_pr: labels[i] = 0.0 # Buy - Прибыльно else: labels[i] = 2.0 # Hold - Не прибыльно # Проверка прибыльности для сигнала Sell (1.0) elif rsi_signal == 1.0: # Продажа прибыльна, если будущая цена < текущей цены - markup if (future_pr + markup) < curr_pr: labels[i] = 1.0 # Sell - Прибыльно else: labels[i] = 2.0 # Hold - Не прибыльно else: # Нет сигнала RSI -> Hold labels[i] = 2.0 # Обрезаем датасет и добавляем метки dataset['labels'] = labels dataset = dataset.iloc[start_index:].copy() # Очищаем от NaN (в конце, где невозможно определить будущую цену) return dataset.dropna()
Какие признаки следует использовать для обучения моделей
Интересной особенностью предложенного подхода является соответствие принципу "что на входе, то и на выходе", по аналогии с "Garbage in, garbage out". Но в данном случае наши данные — не мусор, а содержат вполне понятные функциональные зависимости между значениями индикаторов и их порогами. Поэтому на вход моделей, то есть в качестве признаков, можно подавать те же самые осцилляторы, которые используются при разметке. Любые другие признаки, например, приращения, также отлично подходят, поскольку относятся к тому же временному ряду, а модель машинного обучения сама настроит параметры для соответствия используемой разметки. Единственная разница может быть лишь в том, что понадобится больше сторонних признаков для аппроксимации функции осциллятора, что несколько утяжелит модель, она будет содержать больше параметров. Но это может также порождать другие интересные эффекты в плане вариативности моделей, которые будут отличаться по своим свойствам.
Я предлагаю 3 вида признаков, которые вы можете дополнить самостоятельно. Это признаки на основе разниц цены и скользящих средних, индикатор RSI и индикатор RSI Уайлдера.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC - pFixedC.rolling(i).mean() count += 1 return pFixed.dropna() def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() count = 0 for period in hyper_params['periods']: delta = data.diff() gain = (delta.where(delta > 0, 0)).rolling(window=period).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=period).mean() rs = gain / loss pFixed[str(count)] = 100 - (100 / (1 + rs)) count += 1 return pFixed.dropna() def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() count = 0 for period in hyper_params['periods']: delta = data.diff() gain = delta.where(delta > 0, 0) loss = -delta.where(delta < 0, 0) avg_gain = gain.ewm(alpha=1/period, adjust=False).mean() avg_loss = loss.ewm(alpha=1/period, adjust=False).mean() rs = avg_gain / avg_loss pFixed[str(count)] = 100 - (100 / (1 + rs)) count += 1 return pFixed.dropna()
Беглый взгляд на результаты обучения после разметки без подглядывания (No look ahead)
Теперь все готово для тестирования предложенного подхода. В качестве испытуемого возьмем валютную пару AUDCAD, которая является флэтовой. Настроим гиперапраметры алгоритма следующим образом:
hyper_params = {
'symbol': 'AUDCAD_H1',
'export_path': '/Users/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.01000,
'take_profit': 0.01000,
'periods': [i for i in range(5, 50, 5)],
'backward': datetime(2015, 1, 1),
'forward': datetime(2021, 1, 1),
} Далее обучим модели, используя поочередно все разметчики сделок (нужный раскомментировать) и сразу же их протестируем.
options = [] for i in range(1): print('Learn ' + str(i) + ' model') dataset = get_features(get_prices()) # dataset = get_labels_cci(dataset, cci_period=50, # oversold_level=-130, overbought_level=130) # dataset = get_labels_stochastic(dataset, stoch_period=30, smooth_k=15, # oversold_level=10, overbought_level=90) # dataset = get_labels_bb(dataset, bb_period=25, num_std=2) # dataset = get_labels_rsi(dataset, rsi_period=9, # oversold_level=28, overbought_level=72) # dataset = get_labels_fourier(dataset, lookback_period=100, high_pass_cutoff_idx=5, # std_multiplier=1.5) dataset = get_labels_profit_rsi_profit_check(dataset, rsi_period=7, oversold_level=30.0, overbought_level=70.0, min_forecast_period=1, max_forecast_period=5, markup=hyper_params['markup']) dataset['meta_labels'] = (dataset['labels'] != 2.0).astype(float) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() options.append(fit_final_models(data)) options.sort(key=lambda x: x[0]) data = get_features(get_prices()) test_model(data, options[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=True)Ниже представлены результаты применения разных разметчиков к данным без оптимизации их параметров.

На основе CCI

На основе Stochastic

На основе Bollinger bands

На основе RSI

На основе Fourier
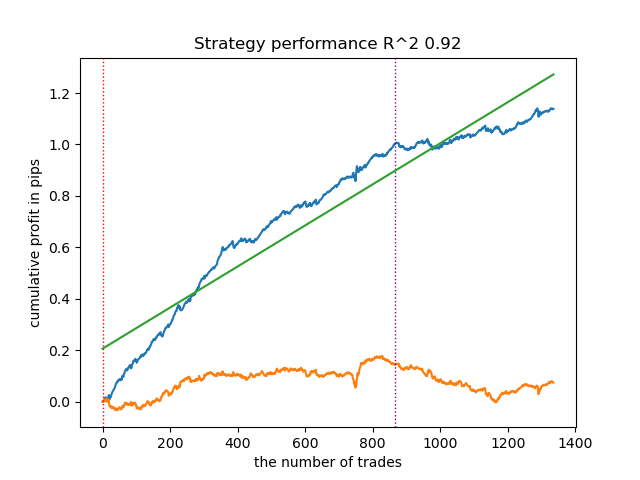
На основе RSI с проверкой на прибыль
Все кривые, кроме последней, демонстрируют схожую динамику на обучающей и тестовой выборках. Ввиду того, что последний разметчик использует подглядывание в будущее, его результативность на тестовой выборке несколько хуже, чем на обучающей. Это вызвано ничем иным, как подглядыванием, или look ahead bias. Он все равно позволяет получить прибыль, поскольку метки с подглядыванием перемешаны с исходными чистыми метками на основе осцилляторов. На этом возможности подхода не ограничиваются, ведь можно добавить множество различных осцилляторов и даже придумать свои собственные.
Для сравнения можно привести вариант стандартной разметки, которой часто пользуются трейдеры и которая фигурировала в некоторых моих прошлых статьях. Эта функция всегда смотрит на будущие цены для определения направления сделки.
def get_labels(dataset, min = 1, max = 15) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'].iloc[i] future_pr = dataset['close'].iloc[i + rand] if (future_pr + hyper_params['markup']) < curr_pr: labels.append(1.0) elif (future_pr - hyper_params['markup']) > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Видно, что модель явно переобучена, а подбор специфических признаков под такие метки никогда не дает положительный результат.
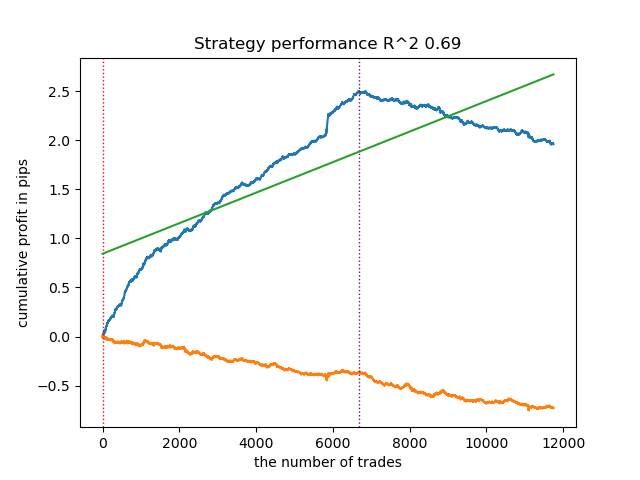
Разметка на основе подглядывания в будущее
Экспорт обученных моделей и встреча с реальными торговыми условиями
Давайте обучим финальную модель, используя один из предложенных разметчиков. Пусть это будет разметка на основе осциллятора RSI без подглядывания. Для демонстрации силы разметки я обучил модель за период 2015-2017 годов, а форвард период 2018-2025.
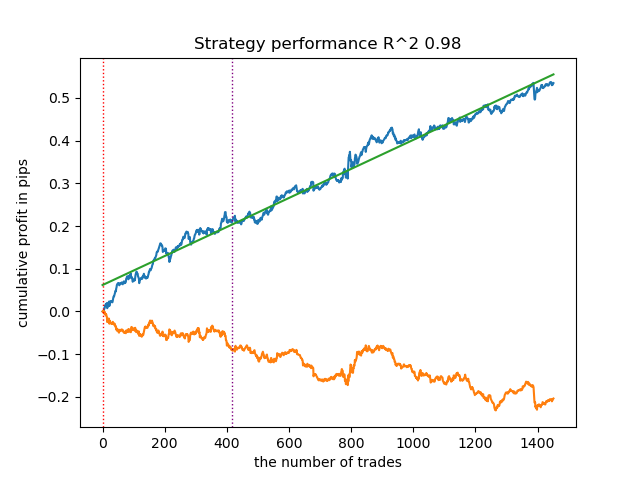
Теперь следует вызвать функцию экспорта моделей в формате ONNX в каталог include терминала.
export_model_to_ONNX(options[-1],0)
Экспортированная библиотека выглядит следующим образом:
#include <Math\Stat\Math.mqh> #resource "catmodel0.onnx" as uchar ExtModel[] #resource "catmodel_m0.onnx" as uchar ExtModel2[] int Periods[9] = {5,10,15,20,25,30,35,40,45}; void fill_arays( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods)-1; i>=0; i--) { CopyClose(NULL,PERIOD_CURRENT,1,Periods[i],pr); ret[0] = pr[ArraySize(pr)-1] - MathMean(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Осталось скомпилировать бота и прогнать в тестере стратегий. Отличительной особенностью разметки без подглядывания является то, что спред никак не закладывается в разметку, из-за чего он может значительно повлиять на результаты финального тестирования.

Заключение
На основании небольшого исследования можно сделать вывод, что трейдеры часто неправильно делают разметку сделок для своих моделей машинного обучения. Показаны варианты разметки сделок, которые не приводят к переобучению моделей и стабильно работают долгое время. Открываются новые перспективы для анализа разнообразных разметчиков сделок, которые основаны на осцилляторах. Подход позволяет значительно снизить количество признаков и сложность моделей, что благотворно сказывается на их устойчивости, и это полностью ломает привычную парадигму погдонки признаков под целевые.
Архив Python files.zip содержит следующие файлы для разработки в среде Python:
| Имя файла | Описание |
|---|---|
| no look ahead.py | Основной скрипт для обучения моделей |
| oscillators_labeling.py | Обновленный модуль с разметчиками сделок |
| tester_lib.py | Обновленный кастомный тестер стратегий, основанных на машинном обучении |
| AUDCAD_H1.csv | Файл с котировками, экспортированный из терминала MetaTrader 5 |
Архив MQL5 files.zip cодержит файлы для терминала MetaTrader 5:
| Имя файла | Описание |
|---|---|
| no look ahead trader.ex5 | Скомпилированный бот из данной статьи |
| no look ahead trader.mq5 | Исходник бота из статьи |
| папка Include//Mean reversion | Расположены модели ONNX и заголовочный файл для подключения к боту |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Автор здесь не при чем
У меня нет претензий к автору. Но сути проблемы это не меняет. Вы, как выпускающий редактор, не находите здесь введение в заблуждение (с помощью некорректной картинки)?
Как раз в тему, смотри анонс
Как раз в тему, смотри анонс
Тут слова расходятся с логикой. На картинке приведены ошибочные, а не идеализированные метки.
Про случайные метки надо бы поподробнее. Никакой ML не будет работать со случайными метками. Тут видимо имелось в виду что-то другое, а не то, что метки ставятся куда попало.
Тут слова расходятся с логикой. На картинке приведены ошибочные, а не идеализированные метки.
Про случайные метки надо бы поподробнее. Никакой ML не будет работать со случайными метками. Тут видимо имелось в виду что-то другое, а не то, что метки ставятся куда попало.
На новых данных идеализированные превратятся в ошибочные :) обсуждать можно бесконечно.
Случайные метки зависят от случайных ценовых изменений, которые были в будущем. Там в статье об этом написано.
Аналогичный вопрос к вам: что значит "никакой МЛ не будет работать со случайными метками"? Может быть вы хотели сказать что-то другое? :)На новых данных идеализированные превратятся в ошибочные :) обсуждать можно бесконечно.
Случайные метки зависят от случайных ценовых изменений, которые были в будущем. Там в статье об этом написано.
Аналогичный вопрос к вам: что значит "никакой МЛ не будет работать со случайными метками"? Может быть вы хотели сказать что-то другое? :)В этом фрагменте формулировки слегка неоднозначные, но суть подхода ясна и из статьи. К статье у меня не было претензий.
Можно и не обсуждать, по мне так метки всегда из истории, а не в будущем, а если речь про их вклад в эффективность модели в будущем, то огульно записывать их все в ошибочные - некорректно. Пусть каждый останется при своем мнении.
Моя фраза про случайные метки - вроде бы и не моя, а общеизвестный факт из МЛ.