Обсуждение статьи "Применение метода Монте-Карло в обучении с подкреплением"
Я хотел бы внести свой вклад в наблюдения:
Преимущества этой версии:
*************************************
1. В отличие от предыдущих версий, эта версия не торгует постоянно. Торгует выборочно, когда сигнал хороший. Это огромное преимущество для удовлетворения ваших потребностей. Иначе это хорошо.))) ..
2. Он может быть оптимизирован быстро и легко.
3. Размер модели тренера невелик, поэтому мы можем тренировать большие данные
Недостатки этой версии:
*******************************************
1. Много раз это занимает много времени для будущих проходов и, следовательно, мы должны вручную остановить процесс оптимизации.
2. По некоторым причинам запуск тестов не так прост. Я должен перезапустить свой терминал MT5, и все же иногда он не работает.
Мои предложения по улучшению:
*************************************
1. Попробуйте использовать как минимум от 4 до 5 входных функций для обучения, таких как открытое, закрытое, высокое, низкое.
2.Try использовать «MathMoments ()» функции должным образом при получении оптимизирован в получении торговых сигналов:
https://www.mql5.com/en/docs/standardlibrary/mathematics/stat/mathsubfunctions/statmathmoments
3. Попробуйте внедрить итеративный учебный курс на ежедневной или еженедельной основе.
Это случайный результат.
4. Попробуйте несколько временных периодов.
Мне нужно сделать это. как мы можем сделать это лучше :))))

- www.mql5.com
Метод Монте- Карло, безусловно, эффективный метод для изучения случайных процессов. Однако, применение этого метода (как и любого другого), должно учитывать природу процесса (для нас - это финансовые рынки).
Проблема современной аналитики в том, что до сих пор – ни традиционный ТА, ни другие методы, не смогли выявить элементарную структуру движения рыночных цен (как, например, атом в физике). А имеющиеся структуры (паттерны ТА, волны Эллиотта и прочие) не являются элементарными, так как не являются непрерывными для анализа (проявляются неоднозначно либо редко). Поэтому, использование современных методов – это почти слепой поиск так называемой «лучшей модели» методом перебора (в данном случае методом Монте- Карло).
Но это проблема индустрии аналитики в целом. А автор, в рамках метода, показал оригинальные решения – спасибо за работу!
Респект автору, за очередную, интересную статью, за открытый и конструктивный подход к МО, не смотря на тайную, мышиную возню других участников темы и цугундер администрации:)
Конкретно по сабжу - не совсем понятен смысл стрельбы Монте Карло для поиска целевых, ведь они и так, практически однозначно детерминированы и м.б. на порядок быстрее найдены, в соответствии с вершинами зигзага или значениями тех же ретурнов.
ИМХО, рациональнее было бы применить этот метод к гораздо более неопределенной и многомерной задаче, такой как выбор и ранжирование предикторов. По идее, при решении этой задачи предикторы нужно оценивать в комплексе, а описанный в статье перебор и поочередное обучение на каждом в отдельности выглядит как составление систем уравнений с одним неизвестным.
Респект автору, за очередную, интересную статью, за открытый и конструктивный подход к МО, не смотря на тайную, мышиную возню других участников темы и цугундер администрации:)
Конкретно по сабжу - не совсем понятен смысл стрельбы Монте Карло для поиска целевых, ведь они и так, практически однозначно детерминированы и м.б. на порядок быстрее найдены, в соответствии с вершинами зигзага или значениями тех же ретурнов.
ИМХО, рациональнее было бы применить этот метод к гораздо более неопределенной и многомерной задаче, такой как выбор и ранжирование предикторов. По идее, при решении этой задачи предикторы нужно оценивать в комплексе, а описанный в статье перебор и поочередное обучение на каждом в отдельности выглядит как составление систем уравнений с одним неизвестным.
Респект автору, за очередную, интересную статью, за открытый и конструктивный подход к МО, не смотря на тайную, мышиную возню других участников темы и цугундер администрации:)
Конкретно по сабжу - не совсем понятен смысл стрельбы Монте Карло для поиска целевых, ведь они и так, практически однозначно детерминированы и м.б. на порядок быстрее найдены, в соответствии с вершинами зигзага или значениями тех же ретурнов.
ИМХО, рациональнее было бы применить этот метод к гораздо более неопределенной и многомерной задаче, такой как выбор и ранжирование предикторов. По идее, при решении этой задачи предикторы нужно оценивать в комплексе, а описанный в статье перебор и поочередное обучение на каждом в отдельности выглядит как составление систем уравнений с одним неизвестным.
Насчёт того, что "однозначно детерминированы" - это неверно, так как фигуры ТА и "ретурны" - это очень неоднозначные и ненадёжные для анализа вещи.
Поэтому, автор их и не использует, а экспериментирует с методом Монте-Карло.
Привет максим
Один вопрос.
«shift_probab» и «регуляризация» Используемые значения предназначены только для оптимизации и НЕ В ТЕЧЕНИЕ живой торговли . Я прав?
Или необходимо установить оптимизированные значения shift_probab и регуляризации на графике после завершения каждой оптимизации для реальной торговли?
Благодарю.
Привет, через Монте Карло идёт перебор целевых случайным образом, по всем канонам РЛ. То есть существует множество стратегий (шагов), агент ищет оптимальную, через минимальную ошибку на оос. Конструирование новых фичей также реализовано в одной из библиотек через МГУА (см кодобазу). В этой статье реализован просто перебор существующих фичей, без конструирования новых. См. метод Recursive elimination. То есть перебираются как фичи так и целевые. Позже смогу предложить другие варианты, их на самом деле можно придумать много. Но сравнительные тесты занимают много времени.
Привет, конечно, случайный выбор действий это каноны РЛ, более того, он м.б. необходим т.к. от разных действий агента может меняется окружение, что порождает устремленное к бесконичности к-во вариантов и конечно Монте-Карло вполне м.б. применен для оптимизации последовательности таких действий.
Но в нашем случае окружение - рыночные котировки от действий агента практически не зависят, тем более в рассматриваемой реализации, где используются исторические, заранее изветные данные, а поэтому и выбор последовательности действий(трейдов) агента м.б. сделан без стохастических методов.
P.S. например, по котировкам можно находить целевую последовательность трейдов с максимально возможной прибылью https://www.mql5.com/ru/code/9234

- www.mql5.com
Привет максим
Один вопрос.
«shift_probab» и «регуляризация» Используемые значения предназначены только для оптимизации и НЕ В ТЕЧЕНИЕ живой торговли . Я прав?
Или необходимо установить оптимизированные значения shift_probab и регуляризации на графике после завершения каждой оптимизации для реальной торговли?
Благодарю.
Привет, конечно, случайный выбор действий это каноны РЛ, более того, он м.б. необходим т.к. от разных действий агента может меняется окружение, что порождает устремленное к бесконичности к-во вариантов и конечно Монте-Карло вполне м.б. применен для оптимизации последовательности таких действий.
Но в нашем случае окружение - рыночные котировки от действий агента практически не зависят, тем более в рассматриваемой реализации, где используются исторические, заранее изветные данные, а поэтому и выбор последовательности действий(трейдов) агента м.б. сделан без стохастических методов.
P.S. например, по котировкам можно находить целевую последовательность трейдов с максимально возможной прибылью https://www.mql5.com/ru/code/9234
Насчёт того, что "однозначно детерминированы" - это неверно, так как фигуры ТА и "ретурны" - это очень неоднозначные и ненадёжные для анализа вещи.
Поэтому, автор их и не использует, а экспериментирует с методом Монте-Карло.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Применение метода Монте-Карло в обучении с подкреплением:
Применение Reinforcement learning для разработки самообучающихся экспертов. В предыдущей статье мы познакомились с алгоритмом Random Decision Forest и написали простого самообучающегося эксперта на основе Reinforcement learning (обучения с подкреплением). Было отмечено основное преимущество такого подхода как простота написания торгового алгоритма и высокая скорость "обучения". Обучение с подкреплением (далее просто RL) легко внедряется в любого торгового эксперта и увеличивает скорость его оптимизации.
После остановки оптимизации просто включим одиночный режим тестирования (поскольку лучшая модель записана в файл и загружена будет только она):
Отмотаем историю на два месяца назад и посмотрим, как модель отработает за полные четыре месяца:
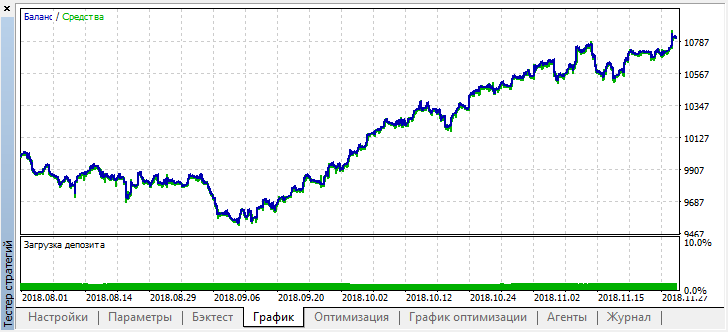
Видно, что полученная модель продержалась еще месяц (почти весь сентябрь), а вот в августе сломалась.Автор: Maxim Dmitrievsky