
Die Anwendung der Monte Carlo Methode beim Reinforcement-Learning
Eine kurze Zusammenfassung des vorherigen Artikels und der Methoden zur Verbesserung des Algorithmus
Im vorigen Artikel haben wir den Algorithmus Random Decision Forest betrachtet und einen einfachen, selbstlernenden EA geschrieben, der auf dem Reinforcement-Learning basiert.
Der folgende Hauptvorteil dieses Ansatzes wurde erläutert:
- Leichtigkeit bei der Entwicklung eines Handelsalgorithmus und hohe "Lerngeschwindigkeit". Reinforcement-Learning (RL) lässt sich leicht in jedes Trading EA integrieren und beschleunigt dessen Optimierung.
Gleichzeitig hat dieser Ansatz einen großen Nachteil:
- Der Algorithmus ist anfällig für Überoptimierung (Overfitting). Mit anderen Worten, er ist gekennzeichnet durch eine schwache Verallgemeinerung der Grundgesamtheit, deren Verteilung der Ergebnisse unbekannt ist. Das bedeutet, dass er nicht nach echten fundamentalen Marktmustern sucht, die für die gesamte historische Periode eines Finanzinstruments charakteristisch sind, sondern über die aktuelle Marktsituation hinausgeht (sie überholt), während die globalen Muster auf der anderen Seite des "Verständnisses" des ausgebildeten Agenten verbleiben. Die Genoptimierung hat jedoch den gleichen Nachteil und arbeitet bei einer großen Anzahl von Variablen viel langsamer.
Es gibt zwei Hauptmethoden zur Bekämpfung der Überanpassung:
- Feature Engineering, oder das Konstruieren von Attributen. Das Hauptziel dieses Ansatzes ist die Auswahl solcher Merkmale und einer Zielvariablen, die die allgemeine Bevölkerung mit einem geringen Fehler beschreiben würde. Mit anderen Worten, dies ist eine Suche nach plausiblen Regelmäßigkeiten mit statistischen und ökonometrischen Methoden durch die Suche nach Prädiktoren. In nicht-stationären Märkten ist diese Aufgabe recht kompliziert und für bestimmte Strategien unlösbar. Wir sollten uns jedoch bemühen, die optimale Strategie zu wählen.
- Regularization wird verwendet, um das Modell durch Korrekturen auf der Ebene des verwendeten Algorithmus aufzurauen. Aus dem vorherigen Artikel erinnern wir uns, dass der Parameter r dafür im RDF verwendet wird. Die Regularisierung ermöglicht es, das Gleichgewicht zwischen dem Training und den Testproben zu erreichen und die Stabilität des Modells auf neuen Daten zu erhöhen (wenn es möglich ist).
Verbesserter Ansatz für das Reinforcement-Learning
Die oben genannten Techniken sind im Algorithmus auf die ursprüngliche Weise enthalten. Einerseits erfolgt die Konstruktion der Attribute durch Aufzählung der Preissteigerungen und Auswahl mehrerer bester Preissteigerungen, andererseits werden die Modelle mit dem kleinsten Klassifizierungsfehler bei neuen Daten (Out-of-Bag) durch Abstimmung des Parameters r ausgewählt.
Darüber hinaus gibt es eine neue Möglichkeit, mehrere RL-Agenten gleichzeitig zu erstellen, auf die Sie verschiedene Einstellungen vornehmen können, was theoretisch die Stabilität des Modells auf den neuen Daten erhöhen sollte. Die Modellaufzählung erfolgt im Optimierer nach der Monte-Carlo-Methode (Zufallsstichprobenverfahren von Kennzeichnen), während das beste Modell zur weiteren Verwendung in eine Datei geschrieben wird.
Erstellen der CRLAgent Basisklasse
Die Bibliothek basiert auf OOP, was es einfach macht, sie mit einem EA zu verbinden und eine erforderliche Anzahl von RL-Agenten zu deklarieren.
Hier werde ich für ein besseres Verständnis der die Interaktionsstruktur einige Klassenfelder beschreiben.
//+------------------------------------------------------------------+ //|RL agent base class | //+------------------------------------------------------------------+ class CRLAgent { public: CRLAgent(string,int,int,int,double, double); ~CRLAgent(void); static int agentIDs; void updatePolicy(double,double&[]); //Update der Politik des lernenden nach jedem Deal void updateReward(); //Update der Leistung nach jedem geschlossenen Deal double getTradeSignal(double&[]); //Erhalt eines Handelssignals vom trainierten Agenten oder zufällig int trees; double r; int features; double rferrors[], lastrferrors[]; string Name;
Die ersten drei Methoden werden verwendet, um die Richtlinie (Strategie) des Lernenden (Agenten) zu bilden, die Belohnungen zu aktualisieren und ein Handelssignal von einem ausgebildeten Agenten zu erhalten. Sie wurden im ersten Artikel ausführlich beschrieben.
Hilfsfelder, die die zufälligen Waldeinstellungen, die Anzahl der Attribute (Eingaben), Arrays zur Speicherung von Modellfehlern und den Namen des Agenten (Agentengruppe) definieren, werden weiter deklariert.
private: CMatrixDouble RDFpolicyMatrix; CDecisionForest RDF; CDFReport RDF_report; double RFout[]; int RDFinfo; int agentID; int numberOfsamples; void getRDFstructure(); double getLastProfit(); int getLastOrderType(); void RecursiveElimination(); double bestFeatures[][2]; int bestfeatures_num; double prob_shift; bool random; };
Die Matrix zum Speichern der parametrisierten Lernstrategie, des Objekts des Random Forest und des Hilfsobjekts zum Speichern von Fehlern wird weiter deklariert.
Die folgende statische Variable ist für die Speicherung der eindeutigen ID eines Agenten vorgesehen:
static int CRLAgent::agentIDs=0;
Der Konstruktor initialisiert anfangs alle Variablen:
CRLAgent::CRLAgent(string AgentName,int number_of_features, int bestFeatures_number, int number_of_trees,double regularization, double shift_probability) { random=false; MathSrand(GetTickCount()); ArrayResize(rferrors,2); ArrayResize(lastrferrors,2); Name = AgentName; ArrayResize(RFout,2); trees = number_of_trees; r = regularization; features = number_of_features; bestfeatures_num = bestFeatures_number; prob_shift = shift_probability; if(bestfeatures_num>features) bestfeatures_num = features; ArrayResize(bestFeatures,1); numberOfsamples = 0; agentIDs++; agentID = agentIDs; getRDFstructure(); }
Ganz am Ende wird de Kontrolle an die Methode getRDFstructure() übergeben, die dann Folgendes durchführt:
//+------------------------------------------------------------------+ //|Load learned agent | //+------------------------------------------------------------------+ CRLAgent::getRDFstructure(void) { string path=_Symbol+(string)_Period+Name+"\\"; if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(FileIsExist(path+"RFlasterrors"+(string)agentID+".rl",FILE_COMMON)) { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,lastrferrors,0); FileClose(getRDF); } while (getRDF<0); } else { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } while (getRDF<0); } return; } if(FileIsExist(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON)) { int getRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_READ|FILE_TXT|FILE_COMMON); CSerializer serialize; string RDFmodel=""; while(FileIsEnding(getRDF)==false) RDFmodel+=" "+FileReadString(getRDF); FileClose(getRDF); serialize.UStart_Str(RDFmodel); CDForest::DFUnserialize(serialize,RDF); serialize.Stop(); getRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,bestFeatures,0); FileClose(getRDF); getRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,rferrors,0); FileClose(getRDF); getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } else random = true; }
Wenn die EA-Optimierung gestartet wird, werden die Dateien auf die Fehler überprüft, die bei den vorherigen Optimierungsdurchläufen aufgezeichnet wurden. Modellfehler werden bei jeder neuen Iteration für die anschließende Auswahl der kleinsten verglichen.
Wenn der EA im Testmodus gestartet wird, wird das trainierte Modell aus den Dateien zur weiteren Verwendung heruntergeladen. Außerdem werden die letzten Fehler des Modells gelöscht und Standardwerte gleich eins gesetzt, so dass die neue Optimierung bei Null beginnt.
Nach dem nächsten Lauf im Optimierer wird der Lernende wie folgt geschult:
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination();
Die Kontrolle wird an die angegebene Methode delegiert, die für die sequentielle Auswahl von Attributen, nämlich Preiserhöhungen, vorgesehen ist. Schauen wir, wie es funktioniert:
//+------------------------------------------------------------------+ //|Recursive feature elimitation for matrix inputs | //+------------------------------------------------------------------+ CRLAgent::RecursiveElimination(void) { //Merkmalstransformation, so dass jedes 2. Merkmal mit unterschiedlicher Verzögerung erscheint. ArrayResize(bestFeatures,0); ArrayInitialize(bestFeatures,0); CDecisionForest mRDF; CMatrixDouble m; CDFReport mRep; m.Resize(RDFpolicyMatrix.Size(),3); int modelCounterInitial = 0; for(int bf=1;bf<features;bf++) { for(int i=0;i<RDFpolicyMatrix.Size();i++) { m[i].Set(0,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][bf]); //Ausfüllen der Matrix mit Inkrementen (Preis mit Index Null des Arras wird dividiert durch den Preis mit dem Versatz bf) m[i].Set(1,RDFpolicyMatrix[i][features]); m[i].Set(2,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),1,2,trees,r,RDFinfo,mRDF,mRep); //Trainieren eines Random Forest, bei dem nur ein gewähltes Inkrement als Prädiktor verwendet wird ArrayResize(bestFeatures,ArrayRange(bestFeatures,0)+1); bestFeatures[modelCounterInitial][0] = mRep.m_oobrelclserror; //sichern des Fehlers der OOB-Einstellung bestFeatures[modelCounterInitial][1] = bf; //sichern des Inkrements "lag" (Verzögerung) modelCounterInitial++; } ArraySort(bestFeatures); //Sortieren das Arrays (der Dimension Null), d.h. oob erscheint hier versehentlich ArrayResize(bestFeatures,bestfeatures_num); //übrig bleibt nur die besten Merkmale bestfeatures_num m.Resize(RDFpolicyMatrix.Size(),2+ArrayRange(bestFeatures,0)); for(int i=0;i<RDFpolicyMatrix.Size();i++) { // erneutes Ausfüllen der Matrix, aber jetzt mit den besten Attributen for(int l=0;l<ArrayRange(bestFeatures,0);l++) { m[i].Set(l,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][(int)bestFeatures[l][1]]); } m[i].Set(ArrayRange(bestFeatures,0),RDFpolicyMatrix[i][features]); m[i].Set(ArrayRange(bestFeatures,0)+1,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),ArrayRange(bestFeatures,0),2,trees,r,RDFinfo,RDF,RDF_report); // trainieren eines Random Forest mit den gewählten Attributen }
Schauen wir uns die Methode an, den Agenten vollständig zu trainieren:
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination(); if(RDF_report.m_oobrelclserror<lastrferrors[1]) { string path=_Symbol+(string)_Period+Name+"\\"; //FileDelete(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON); CSerializer serialize; serialize.Alloc_Start(); CDForest::DFAlloc(serialize,RDF); serialize.SStart_Str(); CDForest::DFSerialize(serialize,RDF); serialize.Stop(); int setRDF; do { setRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); if(setRDF<0) continue; lastrferrors[0]=RDF_report.m_relclserror; lastrferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,lastrferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_WRITE|FILE_TXT|FILE_COMMON); FileWrite(setRDF,serialize.Get_String()); FileClose(setRDF); setRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); rferrors[0]=RDF_report.m_relclserror; rferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,rferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileWriteArray(setRDF,bestFeatures); FileClose(setRDF); } while(setRDF<0); } } } return 1-RDF_report.m_oobrelclserror; }
Nach Auswahl der Attribute und dem Training des Agenten wird der Klassifizierungsfehler des Agenten im aktuellen Optimierungslauf mit dem minimalen Fehler verglichen, der während der gesamten Optimierung gespeichert wurde. Wenn der Fehler des aktuellen Agenten kleiner ist, wird das aktuelle Modell als das beste gespeichert, und nachfolgende Vergleiche verwenden den Fehler dieses Modells.
Die Monte-Carlo-Methode (zufällige Stichprobenziehung von Preisvariablen) sollte gesondert betrachtet werden:
//+------------------------------------------------------------------+ //|Get trade signal | //+------------------------------------------------------------------+ double CRLAgent::getTradeSignal(double &featuresValues[]) { double res=0.5; if(!MQLInfoInteger(MQL_OPTIMIZATION) && !random) { double kerfeatures[]; ArrayResize(kerfeatures,ArrayRange(bestFeatures,0)); ArrayInitialize(kerfeatures,0); for(int i=0;i<ArraySize(kerfeatures);i++) { kerfeatures[i] = featuresValues[0]/featuresValues[(int)bestFeatures[i][1]]; } CDForest::DFProcess(RDF,kerfeatures,RFout); return RFout[1]; } else { if(countOrders()==0) if(rand()/32767.0<0.5) res = 0; else res = 1; else { if(countOrders(0)!=0) if(rand()/32767.0>prob_shift) res = 0; else res = 1; if(countOrders(1)!=0) if(rand()/32767.0<prob_shift) res = 0; else res = 1; } } return res; }
Wenn der EA nicht im Optimierungsmodus ist, wird das bereits trainierte Modell, das bei der Initialisierung des EA heruntergeladen wurde, zum Empfangen von Handelssignalen verwendet. Andernfalls, wenn der Optimierungsprozess im Gange ist oder wenn keine Modelldateien vorhanden sind, treten die Signale zufällig in Abwesenheit von offenen Positionen (50/50) und mit einer Offsetwahrscheinlichkeit auf, die durch die Variable prob_shift bei Vorhandensein von offenen Aufträgen festgelegt wurde. So können Sie beispielsweise, wenn bereits eine offene Kauftransaktion existiert, die Wahrscheinlichkeit eines Verkaufssignals auf 0,1 (statt 0,5) verändern. Dadurch nimmt die Gesamtzahl der Stichproben im Trainingsset ab und die Positionen werden länger gehalten. Gleichzeitig steigt bei der Einstellung von prob_shift >= 0,5 die Anzahl der Deals.
Erstellen der Klasse CRLAgents
Jetzt können wir mehrere Agenten (Lernende) haben, die verschiedene Aufgaben in einem Handelssystem ausführen. Die vorliegende Klasse wurde für eine komfortablere Verwaltung der homogenen Lerngruppen entwickelt.
//+------------------------------------------------------------------+ //|Multiple RL agents class | //+------------------------------------------------------------------+ class CRLAgents { private: struct Agents { double inpVector[]; CRLAgent *ag; double rms; double oob; }; void getStatistics(); string groupName; public: CRLAgents(string,int,int,int,int,double,double); ~CRLAgents(void); Agents agent[]; void updatePolicies(double); void updateRewards(); double getTradeSignal(); double learnAllAgents(); void setAgentSettings(int,int,int,double); };
Die Agentenstruktur akzeptiert die Parameter jedes Lernenden, und das Array der Strukturen enthält seine Gesamtzahl. Im Falle eines einzelnen Agenten ist es auch sinnvoll, diese spezielle Klasse zu verwenden.
Der Konstruktor nimmt alle notwendigen Parameter zum Lernen:
CRLAgents::CRLAgents(string AgentsName,int agentsQuantity,int features, int bestfeatures, int treesNumber,double regularization, double shift_probability) { groupName=AgentsName; ArrayResize(agent,agentsQuantity); for(int i=0;i<agentsQuantity;i++) { ArrayResize(agent[i].inpVector,features); ArrayInitialize(agent[i].inpVector,0); agent[i].ag = new CRLAgent(AgentsName, features, bestfeatures, treesNumber, regularization, shift_probability); agent[i].rms = agent[i].ag.rferrors[0]; agent[i].oob = agent[i].ag.rferrors[1]; } }
Dazu gehören: Name der Agentengruppe, Anzahl der Mitarbeiter, Anzahl der Attribute für jeden Mitarbeiter, Anzahl der am besten ausgewählten Attribute, Anzahl der "Bäume im Wald", Regularisierungsparameter (Trennung in Trainings- und Testsätze) und Offset der Wahrscheinlichkeit, die Anzahl der Positionen zu verwalten.
Wie wir sehen können, werden die Lernobjekte mit den gleichen Eingaben sowie Trainings- und Testfehler in das Strukturarray gestellt.
Die Lernmethode des Agent ruft die Lernmethode für jede der CRLAgent-Basisklassen auf und gibt den durchschnittlichen Fehler in einem Testset für alle Agenten zurück:
//+------------------------------------------------------------------+ //|Learn all agents | //+------------------------------------------------------------------+ double CRLAgents::learnAllAgents(void){ double err=0; for(int i=0;i<ArraySize(agent);i++) err+=agent[i].ag.learnAnAgent(); return err/ArraySize(agent); }
Dieser Fehler wird als benutzerdefiniertes Optimierungskriterium verwendet, um die Fehlerstreuung bei der Iteration von Modellen nach der Monte-Carlo-Methode zu visualisieren.
Wenn Sie eine bestimmte Anzahl von Lernenden in einer Untergruppe anlegen, bleiben ihre Einstellungen unverändert. Daher gibt es eine Methode zur Anpassung der Parameter jedes einzelnen Lernenden:
//+------------------------------------------------------------------+ //|Change agents settings | //+------------------------------------------------------------------+ CRLAgents::setAgentSettings(int agentNumber,int features,int bestfeatures,int treesNumber,double regularization,double shift_probability) { agent[agentNumber].ag.features=features; agent[agentNumber].ag.bestfeatures_num=bestfeatures; agent[agentNumber].ag.trees=treesNumber; agent[agentNumber].ag.r=regularization; agent[agentNumber].ag.prob_shift=shift_probability; ArrayResize(agent[agentNumber].inpVector,features); ArrayInitialize(agent[agentNumber].inpVector,0); }
Im Gegensatz zur Basisklasse CRLAgent wird in CRLAgents ein Handelssignal als Mittelwert für die Signale aller Lernenden einer Untergruppe dargestellt:
//+------------------------------------------------------------------+ //|Get common trade signal | //+------------------------------------------------------------------+ double CRLAgents::getTradeSignal() { double signal[]; double sig=0; ArrayResize(signal,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) sig+=signal[i]=agent[i].ag.getTradeSignal(agent[i].inpVector); return sig/(double)ArraySize(agent); }
Die Methode zur Erlangung von Statistiken zeigt Daten über Fehler bei der Prüfung und Schulung aller Agenten am Ende eines kurzen Durchlaufs im Tester:
//|Get agents statistics | //+------------------------------------------------------------------+ void CRLAgents::getStatistics(void) { double arr[]; double arrrms[]; ArrayResize(arr,ArraySize(agent)); ArrayResize(arrrms,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) { arrrms[i]=agent[i].rms; arr[i]=agent[i].oob; } Print(groupName+" TRAIN LOSS"); ArrayPrint(arrrms); Print(groupName+" OOB LOSS"); ArrayPrint(arr); }
Die Entwicklung eines Handelsroboters auf Basis der RL Monte Carlo Bibliothek
Jetzt müssen wir nur noch einen einfachen EA schreiben, um die Bibliotheksfunktionen zu demonstrieren. Beginnen wir mit dem ersten Fall, in dem nur ein Agent erstellt wird, der mit den Schlusskursen eines Handelsinstruments trainiert wird.
#include <RL Monte Carlo.mqh>
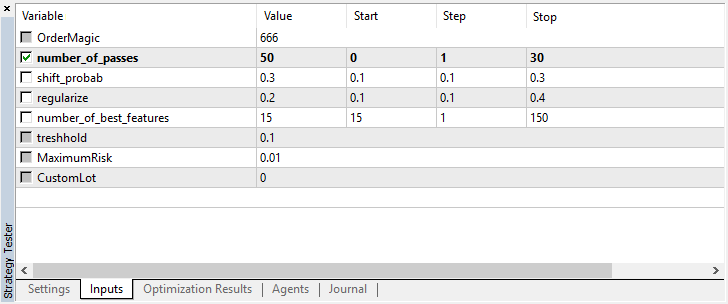
input int number_of_passes = 10; input double shift_probab = 0,5; input double regularize=0.6; sinput int number_of_best_features = 5; sinput double treshhold = 0.5; sinput double MaximumRisk=0.01; sinput double CustomLot=0; CRLAgents *ag1=new CRLAgents("RlMonteCarlo",1,500,number_of_best_features,50,regularize,shift_probab);
Binden Sie die Bibliothek ein und definieren Sie zu optimierenden Eingabeparameter. number_of_passes dient zum Bestimmen der Anzahl der Durchläufe im Terminaloptimierer und wird nicht weitergegeben. Da die Positions-Eröffnungen und -Schließungen vom Arbeiter zufällig ausgewählt werden, ist es möglich, nach mehreren Durchgängen eine optimale Strategie zu erreichen und den kleinsten Fehler zu definieren. Je mehr Durchgänge installiert sind, desto höher ist die Wahrscheinlichkeit, die optimale Strategie zu erhalten.
Die restlichen Einstellungen werden oben beschrieben und direkt an das erstellte Modell übergeben. Hier haben wir einen einzelnen Agenten der Gruppe RlMonteCarlo angelegt. 500 Attribute werden an seine Eingabe übergeben und 5 beste Attribute sind darunter auszuwählen. Das Modell soll 50 Entscheidungsbäume mit einer Trennung von Trainings- und Testsätzen 0,6 (r Parameter) ohne den Wahrscheinlichkeitsoffset haben.
In der Funktion OnTester wird das benutzerdefinierte Optimierungskriterium (als gemittelter Fehler auf einem Testmuster bei allen Lernenden) zurückgegeben, nachdem sie zuvor trainiert wurden:
//+------------------------------------------------------------------+ //| Expert ontester function | //+------------------------------------------------------------------+ double OnTester() { if(MQLInfoInteger(MQL_OPTIMIZATION)) return ag1.learnAllAgents(); else return NULL; }
Lernende und der von ihnen verwendete Speicher werden gelöscht bzw. freigegeben.
//+------------------------------------------------------------------+ //| Deinitialisierungsfunktion des Experten | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { delete ag1; }
Der Vektor der Prädiktoren wird wie folgt gefüllt:
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
Die letzten 500 Schlusskurse werden in diesem Fall einfach übernommen. Denken Sie daran, dass der Prädiktor im Modell das Verhältnis des Null-Elements des Arrays zu einem anderen ist (mit einer bestimmten Verzögerung). Daher werden wir ein Array installieren, das Schlusskurse als Zeitreihe akzeptiert. Die Methode zur Erlangung des Handelssignals wird danach aufgerufen.
Die letzte Funktion ist die Handelsfunktion:
//+------------------------------------------------------------------+ //| Place orders | //+------------------------------------------------------------------+ void placeOrders() { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) { if(OrderType()==0 && Tsignal>0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} if(OrderType()==1 && Tsignal<0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} } if(countOrders(0)!=0 || countOrders(1)!=0) return; if(Tsignal<0.5-treshhold && (OrderSend(Symbol(),OP_BUY,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } if(Tsignal>0.5+treshhold && (OrderSend(Symbol(),OP_SELL,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } }
Der Parameter "threshold" wurde zusätzlich eingeführt. Hiermit kann der Schwellenwert für die Signalaktivierung eingestellt werden. Wenn beispielsweise die Wahrscheinlichkeit des Kaufsignals kleiner als 0,6 ist, wird die Order nicht geöffnet.
Optimierung des RL Monte Carlo Traders EA
Werfen wir einen Blick auf die zu optimierenden Einstellungen:
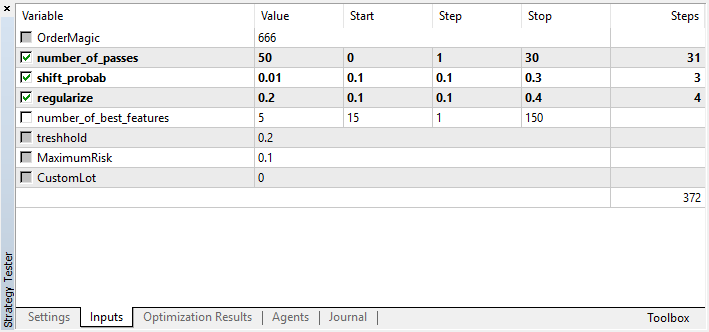
Beachten Sie, dass number_of_passes keine Werte an den Lernenden übergibt. Stattdessen wird lediglich die Anzahl der Optimiererdurchläufe festgelegt. Angenommen, Sie haben sich für andere Einstellungen entschieden und möchten nun ausschließlich die Monte-Carlo-basierte Enumeration verwenden. In diesem Fall sollten Sie nur nach diesem Kriterium optimieren. Sie können die restlichen vier Einstellungen noch optimieren, wenn Sie möchten.
Ein weiteres Merkmal der aktuellen Version ist, dass es nicht notwendig ist, Testagenten zu deaktivieren, da die Durchläufe im Optimierer unabhängig voneinander sind und die Reihenfolge der Speicherung der Modelle nicht wichtig ist.
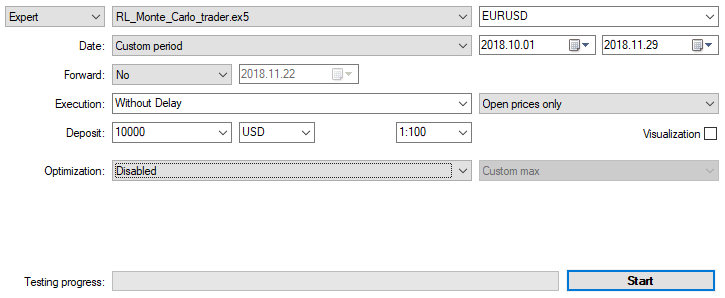
Lassen Sie uns den EA mit den oben genannten Einstellungen auf M15 mit den Eröffnungspreisen über zwei Monate optimieren. Als Optimierungskriterium sollte "Custom max" gewählt werden. Der Optimierungsprozess kann zu jedem Zeitpunkt gestoppt werden, wenn ein akzeptabler Wert des Optimierungskriteriums erreicht ist:
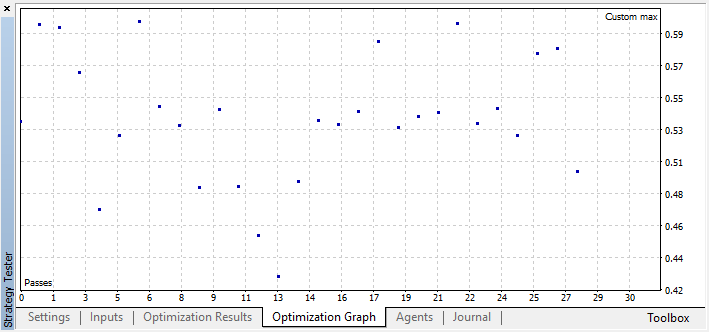
Zum Beispiel habe ich die Optimierung bei Schritt 44 gestoppt, weil eines der besten Modelle den Schwellenwert für die Genauigkeit von 0,6 überschritten hat. Das bedeutet, dass der Klassifizierungsfehler in der Testgruppe unter 0,4 gefallen ist. Beachten Sie, dass je besser das Modell, desto geringer der Fehler, aber für den korrekten Betrieb des genetischen Algorithmus (wenn Sie ihn verwenden möchten), die Fehlerwerte invertiert werden.
Sie können die besten Modelleinstellungen auf der Registerkarte Optimierung überprüfen, indem Sie die Werte nach benutzerdefinierten Kriterien sortieren:
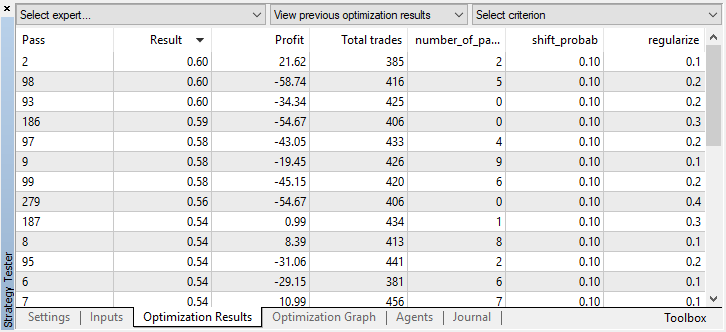
In diesem Fall wird das beste Modell mit einem Wahrscheinlichkeitsoffset von 0,1 und mit dem Parameter r von 0,2 erhalten (der Trainingssatz beträgt nur 20% der gesamten Deal-Matrix, während 80% eine Testuntermenge sind).
Nach Beendigung der Optimierung aktivieren Sie einfach den Einzeltestmodus (da das beste Modell in die Datei geschrieben wird und nur dieses Modell hochgeladen werden soll):
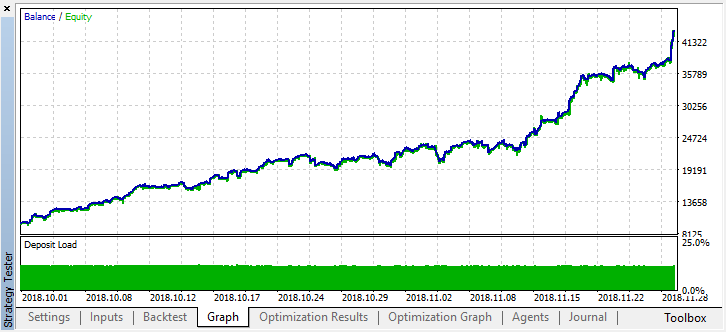
Lassen Sie uns die Historie für zwei Monate zurückblättern und sehen, wie das Modell für die vollen vier Monate funktioniert:
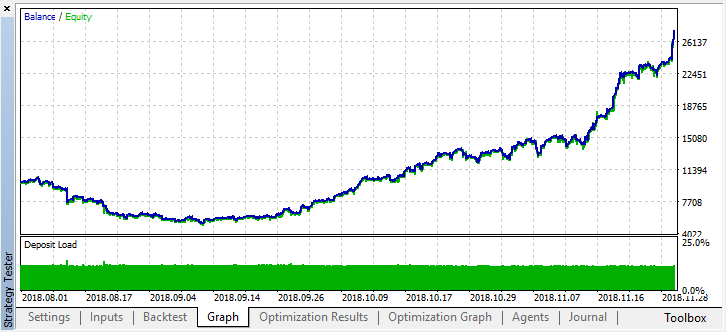
Wir sehen, dass das resultierende Modell einen weiteren Monat (fast den gesamten September) dauerte, während es im August zusammenbrach. Versuchen wir, das Modell zu verfeinern, indem wir "treshhold" auf 0,2 setzen:
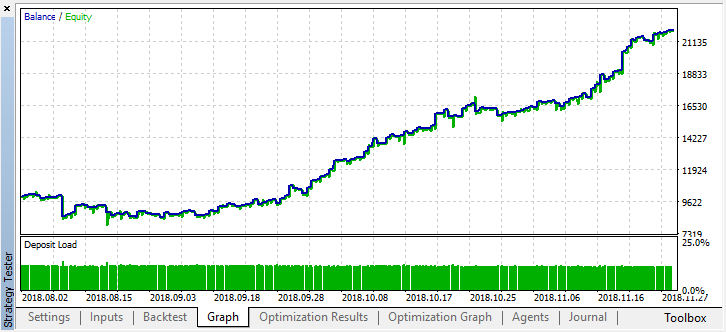
Es ist spürbar besser geworden. Die Genauigkeit des Modells hat sich erhöht, während die Anzahl der Deals reduziert wurde. Eine vertiefte Prüfung ist möglich, sofern die Trainingszeit die entsprechende Länge hat.
Betrachten wir nun die EA-Variante mit mehreren Lernenden, um die Effizienz des Multi-Agent-Ansatzes mit der des Single-Agent-Ansatzes zu vergleichen.
Fügen Sie dazu beim Anlegen einer Gruppe von Agenten die Endung "Multi" hinzu, damit die Dateien verschiedener Systeme nicht gemischt werden. Wir legen auch die Anzahl der "Mitarbeiter" fest, z.B. fünf:
CRLAgents *ag1=new CRLAgents("RlMonteCarloMulti",5,500,number_of_best_features,50,regularize,shift_probab);
Alle Agenten haben sich als gleichartig erwiesen (sie haben identische Einstellungen). Sie können jeden Mitarbeiter in der EA-Initialisierungsfunktion separat konfigurieren:
//+------------------------------------------------------------------+ //| Initialisierungsfunktion des Experten | //+------------------------------------------------------------------+ int OnInit() { ag1.setAgentSettings(0,500,20,50,regularize,shift_probab); ag1.setAgentSettings(1,200,15,50,regularize,shift_probab); ag1.setAgentSettings(2,100,10,50,regularize,shift_probab); ag1.setAgentSettings(3,50,5,50,regularize,shift_probab); ag1.setAgentSettings(4,25,2,50,regularize,shift_probab); return(INIT_SUCCEEDED); }
Hier beschloss ich, die Dinge nicht weiter zu komplizieren und lokalisierte die Anzahl der Attribute für Agenten in absteigender Reihenfolge von 500 bis 25. Außerdem wurde die Anzahl der am besten ausgewählten Attribute von 20 auf zwei reduziert. Andere Einstellungen wurden unverändert beibehalten. Sie können sie ändern und neue optimierte Parameter hinzufügen. Ich ermutige Sie, mit den Einstellungen zu experimentieren und Ihre Ergebnisse in den Kommentaren mit anderen unten zu teilen.
Wie Sie sich vielleicht erinnern, werden die Arrays in der Funktion mit Prädiktorwerten gefüllt:
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
Hier füllen wir einfach das Array inpVector mit den Schlusskursen für jeden Lernenden in Abhängigkeit von seiner Größe, daher ist die Funktion für diesen Fall universell und muss nicht geändert werden.
Starten Sie die Optimierung mit den gleichen Einstellungen wie bei einem einzelnen Agenten:
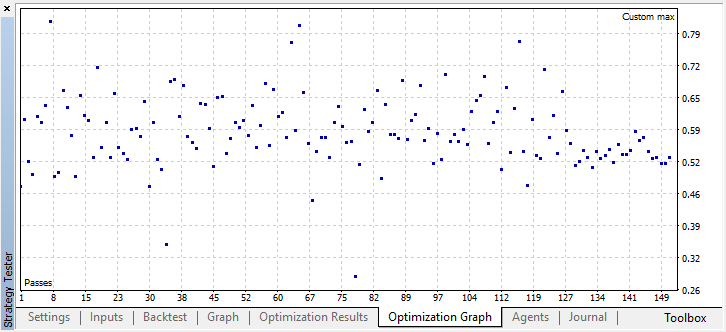
Das beste Ergebnis übertrifft 0.7, und das ist um Vieles besser als im ersten Fall. Starten wir einen einzelnen Durchlauf im Tester:
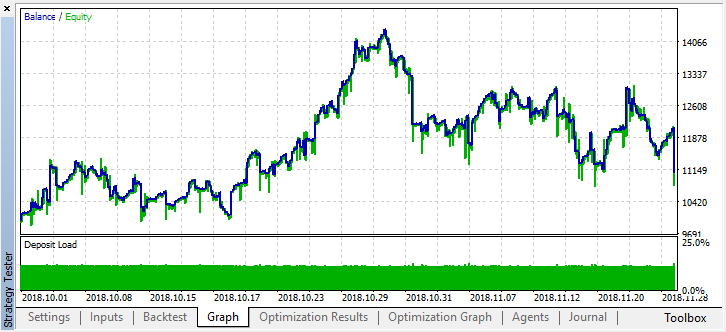
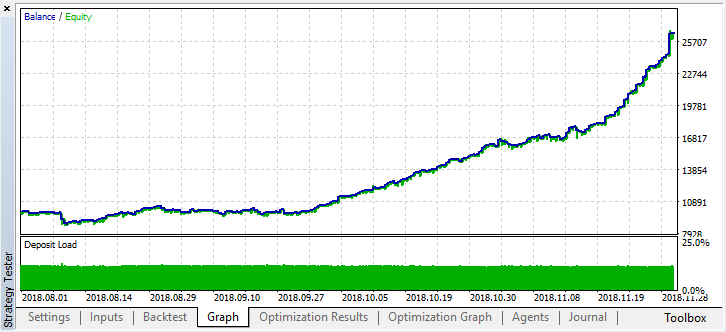
Das reale Ergebnis, das sich in der Saldenkurve widerspiegelt, verschlechterte sich deutlich. Warum? Schauen wir auf die Anzahl der zufälligen Positionen des besten Durchlaufs. Es gibt nur 21!
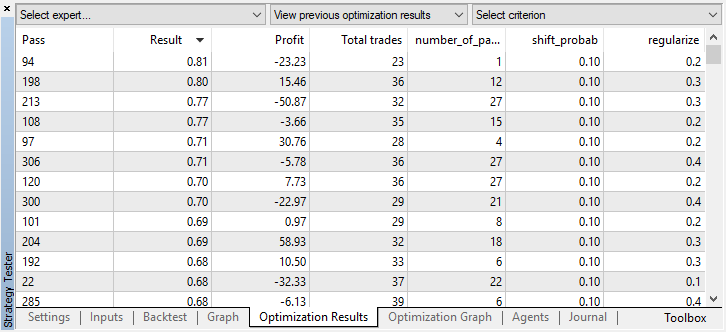
Es stellte sich heraus, dass sich die Signale mehrerer Agenten aufgrund von Stichproben überschnitten und die Gesamtzahl der Positionen zurückging. Um dies zu beheben, setzen Sie den Parameter shift_probab näher an 0,5. In diesem Fall wird die Anzahl der Positionen für jeden einzelnen Agenten größer sein, wodurch auch die Anzahl der gesamten Transaktionen steigt. Auf der anderen Seite können Sie die Lernzeit einfach erhöhen, aber zuerst sollten wir sehen, ob es möglich ist, mit einem solchen Modell weiter zu arbeiten. Wir stellen den Schwellenwert auf 0,2 und sehen mal, was passiert:
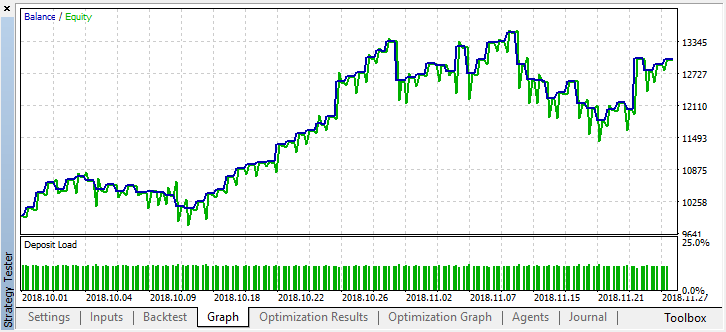
Zumindest verliert das Modell kein Geld, obwohl die Anzahl der Positionen weiter gesunken ist. Die folgenden Fehler werden nach einem einzigen Testlauf im Testerprotokoll angezeigt:
2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo TRAIN LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.02703 0.20000 0.09091 0.05714 0.14286 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo OOB LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.21622 0.23333 0.21212 0.17143 0.19048
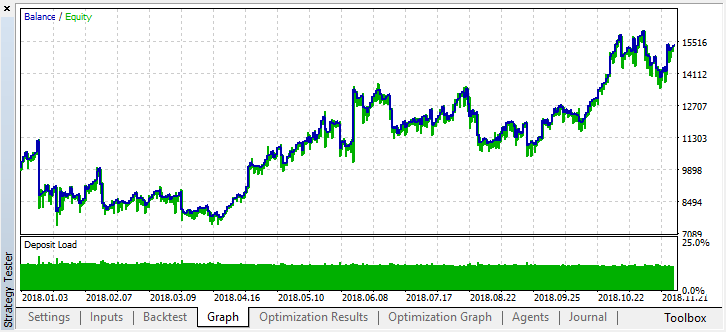
Nun wollen wir dieses Modell ab Anfang des Jahres testen. Die Ergebnisse sind ziemlich stabil:
Setzen Sie shift_probab auf 0.3 und starten Sie den Optimierer ohne diesen Parameter auf M15 für die gleichen 2 Monate (um den Mengenausgleich zu finden):
Da die Komplexität der Berechnungen etwas zugenommen hat, entschied ich mich, nach mehreren Durchläufen im Optimierer bei den folgenden Ergebnissen zu bleiben:
2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti TRAIN LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.13229 0.16667 0.16262 0.14599 0.20937 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti OOB LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.45377 0.45758 0.44650 0.45693 0.46120
Der Fehler im Testset blieb recht beträchtlich, aber an der Schwelle von 0,2 zeigte das Modell innerhalb von 4 Monaten einen Gewinn, obwohl es sich bei den Testdaten eher instabil verhielt.
Beachten Sie, dass alle Lernenden auf der Grundlage der gleichen Daten (Schlusskurse) trainiert wurden, so dass es keinen Grund gab, neue hinzuzufügen. Wie auch immer, es war ein einfaches Beispiel für das Hinzufügen neuer Agenten.
Schlussfolgerungen
Reinforcement-Learning ist vielleicht eine der interessantesten Methoden des maschinellen Lernens. Es ist immer wieder verlockend zu glauben, dass künstliche Intelligenz in der Lage ist, Handelsprobleme auf den Finanzmärkten zu lösen und gleichzeitig unabhängig zu lernen. Gleichzeitig sollte man über ein breites Wissen über maschinelles Lernen, Statistik und Wahrscheinlichkeitstheorie verfügen, um ein solches "Wunder" zu entwickeln. Die Monte-Carlo-Methode und die Auswahl eines Modells nach dem kleinsten Fehler bei den Testdaten haben das im ersten Artikel angebotene Modell deutlich verbessert. Das Modell tendiert weniger zur Überadaptierung.
Das beste Modell sollte sowohl in Bezug auf die Anzahl der Geschäfte als auch auf den kleinsten Klassifizierungsfehler am Out-of-Bag-Set ausgewählt werden. Im Idealfall sollten Fehler in den Trainings- und Testsets etwa gleich sein und den Wert von 0,5 nicht erreichen (die Hälfte der Beispiele wird falsch vorhergesagt).
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/4777
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
 Die praktische Verwendung eines neuronalen Kohonen-Netzes im algorithmischen Handel. Teil II. Optimierung und Vorhersage
Die praktische Verwendung eines neuronalen Kohonen-Netzes im algorithmischen Handel. Teil II. Optimierung und Vorhersage
 Horizontale Diagramm auf den Charts des MеtaTrader 5
Horizontale Diagramm auf den Charts des MеtaTrader 5
 Die praktische Anwendung von Korrelationen im Handel
Die praktische Anwendung von Korrelationen im Handel
 Auswahl- und Navigationsprogramm in MQL5 und MQL4: Hinzufügen einer automatischen Suche nach Mustern und das Darstellen der gefundenen Symbole
Auswahl- und Navigationsprogramm in MQL5 und MQL4: Hinzufügen einer automatischen Suche nach Mustern und das Darstellen der gefundenen Symbole
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Lesen Sie die 2 vorherigen Beiträge
Könnten Sie bitte klären, was diese Meldungen bedeuten? Das heißt, wie man dies lösen, damit der EA funktioniert
Könnten Sie bitte klären, was diese Meldungen bedeuten? Das heißt, wie man das Problem lösen kann, damit der EA funktioniert
Fügen Sie void hinzu, bevor Sie Klassen deklarieren, wie die Person in früheren Beiträgen schrieb