
Aplicando el método de Montecarlo al aprendizaje por refuerzo
Breve resumen del material anterior y método de mejora del algoritmo
En el artículo anterior ya nos familiarizamos con el algoritmo de Random Decision Forest y escribimos un sencillo experto autodidacta basado en Reinforcement learning (aprendizaje por refuerzo).
Se destacaron las principales ventajas de este enfoque:
- la sencillez de escritura del algoritmo comercial y la alta velocidad de entrenamiento. El aprendizaje por refuerzo (en lo sucesivo AR) se implementa fácilmente en cualquier experto comercial y aumenta su velocidad de optimización.
Al mismo tiempo, este enfoque tiene una desventaja sustancial:
- el algoritmo tiende a la sobreoptimización (reentrenamiento), en otras palabras, refleja una tendencia a la generalización débil en el conjunto general cuya distribución de resultados es desconocida. Esto significa que no busca leyes de mercado fundamentales y reales que sean propias de un periodo histórico completo del instrumento financiero, sino que es reentrenado en la situación de mercado actual, mientras que las leyes globales permanecen al otro lado de la "comprensión" del agente entrenado. En cualquier caso, la optimización genética tiene el mismo defecto y funciona mucho más lento al darse un gran número de variables.
Existen dos técnicas especiales para luchar contra el reentrenamiento:
- Feature ingeneering o creación de características. La tarea principal de este enfoque es seleccionar unas características y una variable objetivo tales que describan el conjunto general con un error bajo. Dicho de otra forma, se trata de la búsqueda de leyes verosímiles con métodos estadísticos y econométricos a través de la iteración de predictores. Esta tarea es bastante compleja en los mercados no estacionarios, además, en lo que respecta a determinadas estrategias, es irresoluble. No obstante, debemos intentar elegir la estrategia óptima.
- Regularizationo regularización, se usa para generalizar el modelo mediante la introducción de correcciones al nivel del algoritmo más utilizado. Recordemos que en el artículo anterior, para ello en RDF se usa el parámetro r. La regularización permite lograr un equilibrio de errores entre las muestras de entrenamiento y prueba, aumentando la estabilidad del modelo de datos (cuando esto se puede hacer en principio).
Enfoque mejorado del aprendizaje por refuerzo
Las técnicas nombradas más arriba se incluyen en el algoritmo de una forma original. Por una parte, la construcción de las características se realiza a través de la iteración de los incrementos de precio y la elección de varios de los mejores; por otra parte, mejorando el parámetro r, se seleccionan los modelos con menor error de clasificiación de datos nuevos (out-of-bag).
Además, ahora disponemos de la posibilidad de crear varios agentes de AR simultáneamente, para los que se pueden configurar varios ajustes, lo que, en teoría, deberá aumentar la fiabilidad del modelo en los nuevos datos. La iteración de modelos se realiza en el optimizador con el método de Montecarlo (muestreo aleatorio de marcas), y el mejor modelo se guarda en un archivo para su uso posterior.
Creando la clase base CRLAgent
Para que sea más cómodo trabajar con ella, la biblioteca ha sido ejecutada en POO, lo que permite conectarla fácilmente a un experto y declarar el número necesario de agentes de AR.
Aquí vamos a describir algunos campos de la clase para comprender mejor la estructura de interacción dentro del programa.
//+------------------------------------------------------------------+ //|RL agent base class | //+------------------------------------------------------------------+ class CRLAgent { public: CRLAgent(string,int,int,int,double, double); ~CRLAgent(void); static int agentIDs; void updatePolicy(double,double&[]); //Actualizamos la política del aprendiz después de cada transacción void updateReward(); //Actualizamos la recompensa tras cerrar una transacción double getTradeSignal(double&[]); //Obtenemos la señal comercial de un agente entrenado o aleatoriamente int trees; double r; int features; double rferrors[], lastrferrors[]; string Name;
Los tres primeros métodos sirven para formar la política (estrategia) del aprendendiz (agente), la actualización de las recompensas y la obtención de la señal comercial del agente entrenado. Estos se describen con detalle en el primer artículo.
A continuación, se declaran los campos auxiliares, que determinan los ajustes del bosque aleatorio (variables de enetrada), las matrices para el guardado de errores del modelo y el nombre del agente (grupo de agentes).
private: CMatrixDouble RDFpolicyMatrix; CDecisionForest RDF; CDFReport RDF_report; double RFout[]; int RDFinfo; int agentID; int numberOfsamples; void getRDFstructure(); double getLastProfit(); int getLastOrderType(); void RecursiveElimination(); double bestFeatures[][2]; int bestfeatures_num; double prob_shift; bool random; };
Después se declara la matriz para guadar la política parametrizada del aprendiz, el objeto del bosque aleatorio y el objeto auxiliar para guardar los errores.
Para guardar el identificador único del agente, tenemos una variable estática:
static int CRLAgent::agentIDs=0;
El constructor inicializa todas las variables antes de empezar a trabajar:
CRLAgent::CRLAgent(string AgentName,int number_of_features, int bestFeatures_number, int number_of_trees,double regularization, double shift_probability) { random=false; MathSrand(GetTickCount()); ArrayResize(rferrors,2); ArrayResize(lastrferrors,2); Name = AgentName; ArrayResize(RFout,2); trees = number_of_trees; r = regularization; features = number_of_features; bestfeatures_num = bestFeatures_number; prob_shift = shift_probability; if(bestfeatures_num>features) bestfeatures_num = features; ArrayResize(bestFeatures,1); numberOfsamples = 0; agentIDs++; agentID = agentIDs; getRDFstructure(); }
Al final, el control se transfiere al método getRDFstructure(), que ejecuta las siguientes acciones:
//+------------------------------------------------------------------+ //|Load learned agent | //+------------------------------------------------------------------+ CRLAgent::getRDFstructure(void) { string path=_Symbol+(string)_Period+Name+"\\"; if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(FileIsExist(path+"RFlasterrors"+(string)agentID+".rl",FILE_COMMON)) { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,lastrferrors,0); FileClose(getRDF); } while (getRDF<0); } else { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } while (getRDF<0); } return; } if(FileIsExist(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON)) { int getRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_READ|FILE_TXT|FILE_COMMON); CSerializer serialize; string RDFmodel=""; while(FileIsEnding(getRDF)==false) RDFmodel+=" "+FileReadString(getRDF); FileClose(getRDF); serialize.UStart_Str(RDFmodel); CDForest::DFUnserialize(serialize,RDF); serialize.Stop(); getRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,bestFeatures,0); FileClose(getRDF); getRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,rferrors,0); FileClose(getRDF); getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } else random = true; }
Si el proceso de optimización del experto esté en marcha, se comprueba la presencia de los archivos de los errores registrados en las anteriores iteraciones del optimizador. De esta forma, en cada nueva iteración se comparan los errores del modelo para la posterior selección del menor.
Si el experto ha sido iniciado en el modo de simulación, se cargará el modelo entrenado desde los archivos para su uso. Asimismo, se borran los últimos errores del modelo y se establecen unos valores por defecto iguales a la unidad, para que el nuevo proceso de optimización comience desde cero.
Después de la próxima pasada, en el optimizador tiene lugar el entrenamiento del aprendiz de la forma que sigue:
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination();
Se transfiere el control al método indicado, que ha sido pensado para iterar secuencialmente las características, concretamente los incrementos de precio. Vamos a ver cómo funciona:
//+------------------------------------------------------------------+ //|Recursive feature elimitation for matrix inputs | //+------------------------------------------------------------------+ CRLAgent::RecursiveElimination(void) { //feature transformation, making every 2 features as returns with different lag's ArrayResize(bestFeatures,0); ArrayInitialize(bestFeatures,0); CDecisionForest mRDF; CMatrixDouble m; CDFReport mRep; m.Resize(RDFpolicyMatrix.Size(),3); int modelCounterInitial = 0; for(int bf=1;bf<features;bf++) { for(int i=0;i<RDFpolicyMatrix.Size();i++) { m[i].Set(0,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][bf]); //rellanamos la matriz con los incrementos (dividimos el precio del índice cero de la matriz por el precio con desplazamiento bf) m[i].Set(1,RDFpolicyMatrix[i][features]); m[i].Set(2,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),1,2,trees,r,RDFinfo,mRDF,mRep); //Entrenamos el bosque aleatorio, donde el predictor será solo el incremento elegido ArrayResize(bestFeatures,ArrayRange(bestFeatures,0)+1); bestFeatures[modelCounterInitial][0] = mRep.m_oobrelclserror; //guardamos el error en la muestra oob bestFeatures[modelCounterInitial][1] = bf; //guardamos el retraso del incremento modelCounterInitial++; } ArraySort(bestFeatures); //clasificamos la matriz (por dimensión cero), es decir por el error oob ArrayResize(bestFeatures,bestfeatures_num); //dejamos solo las mejores características bestfeatures_num m.Resize(RDFpolicyMatrix.Size(),2+ArrayRange(bestFeatures,0)); for(int i=0;i<RDFpolicyMatrix.Size();i++) { // rellenamos de nuevo la matriz, ahora ya con las mejores características for(int l=0;l<ArrayRange(bestFeatures,0);l++) { m[i].Set(l,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][(int)bestFeatures[l][1]]); } m[i].Set(ArrayRange(bestFeatures,0),RDFpolicyMatrix[i][features]); m[i].Set(ArrayRange(bestFeatures,0)+1,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),ArrayRange(bestFeatures,0),2,trees,r,RDFinfo,RDF,RDF_report); // entrenamos el bosque aleatorio con las mejores características elegidas }
Veamos al completo el método de entrenamiento del agente:
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination(); if(RDF_report.m_oobrelclserror<lastrferrors[1]) { string path=_Symbol+(string)_Period+Name+"\\"; //FileDelete(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON); CSerializer serialize; serialize.Alloc_Start(); CDForest::DFAlloc(serialize,RDF); serialize.SStart_Str(); CDForest::DFSerialize(serialize,RDF); serialize.Stop(); int setRDF; do { setRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); if(setRDF<0) continue; lastrferrors[0]=RDF_report.m_relclserror; lastrferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,lastrferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_WRITE|FILE_TXT|FILE_COMMON); FileWrite(setRDF,serialize.Get_String()); FileClose(setRDF); setRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); rferrors[0]=RDF_report.m_relclserror; rferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,rferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileWriteArray(setRDF,bestFeatures); FileClose(setRDF); } while(setRDF<0); } } } return 1-RDF_report.m_oobrelclserror; }
Después de seleccionar las características y entrenar el agente, se comparan los errores de clasificación del agente en la pasada de optimización actual con el error mínimo guardado en el transcurso de la optimización en general. Si el error del agente actual es menor, el modelo actual se guardará como el mejor, y las posteriores comparaciones se realizarán con el error de este modelo.
De forma separada, debemos analizar el método de Montecarlo, o muestreo aleatorio de variables objetivo:
//+------------------------------------------------------------------+ //|Get trade signal | //+------------------------------------------------------------------+ double CRLAgent::getTradeSignal(double &featuresValues[]) { double res=0.5; if(!MQLInfoInteger(MQL_OPTIMIZATION) && !random) { double kerfeatures[]; ArrayResize(kerfeatures,ArrayRange(bestFeatures,0)); ArrayInitialize(kerfeatures,0); for(int i=0;i<ArraySize(kerfeatures);i++) { kerfeatures[i] = featuresValues[0]/featuresValues[(int)bestFeatures[i][1]]; } CDForest::DFProcess(RDF,kerfeatures,RFout); return RFout[1]; } else { if(countOrders()==0) if(rand()/32767.0<0.5) res = 0; else res = 1; else { if(countOrders(0)!=0) if(rand()/32767.0>prob_shift) res = 0; else res = 1; if(countOrders(1)!=0) if(rand()/32767.0<prob_shift) res = 0; else res = 1; } } return res; }
Si el asesor no se encuentra en el modo de optimización, para obtener señales comerciales se usa ya un modelo entrenado, cargado al inicializar el experto. De lo contrario, si el proceso de optimización está en marcha o no existen los archivos del modelo, las señales proceden casualmente en el caso de que no haya posiciones abiertas (50/50), y con probabilidad desplazada (indicada por la variable prob_shift), en el caso de que haya posiciones abiertas. De esta forma, por ejemplo, si ya existe una transacción abierta de compra, podemos desplazar la probabilidad de aparición de la señal de venta hasta 0.1 (en lugar de 0.5), así, el número total de muestras en el conjunto de entrenamiento se reducirá, y las posiciones se mantendrán más tiempo. Al mismo tiempo, al establecer prob_shift >= 0.5, el número de transacciones aumentará.
Creando la clase CRLAgents
Ahora podemos tener multitud de agentes (aprendices) que ejecuten distintas tareas en el sistema comercial. Para gestionar los grupos de aprendices homogéneos de manera más cómoda, se ha pensado esta clase.
//+------------------------------------------------------------------+ //|Multiple RL agents class | //+------------------------------------------------------------------+ class CRLAgents { private: struct Agents { double inpVector[]; CRLAgent *ag; double rms; double oob; }; void getStatistics(); string groupName; public: CRLAgents(string,int,int,int,int,double,double); ~CRLAgents(void); Agents agent[]; void updatePolicies(double); void updateRewards(); double getTradeSignal(); double learnAllAgents(); void setAgentSettings(int,int,int,double); };
La estructura Agents usa los parámetros de cada aprendiz, mientras que la matriz de estructuras contiene su número total. Cuando solo hay un agente, también tiene sentido utilizar precisamente esta clase.
El constructor utiliza todos los parámetros necesarios para el entrenamiento:
CRLAgents::CRLAgents(string AgentsName,int agentsQuantity,int features, int bestfeatures, int treesNumber,double regularization, double shift_probability) { groupName=AgentsName; ArrayResize(agent,agentsQuantity); for(int i=0;i<agentsQuantity;i++) { ArrayResize(agent[i].inpVector,features); ArrayInitialize(agent[i].inpVector,0); agent[i].ag = new CRLAgent(AgentsName, features, bestfeatures, treesNumber, regularization, shift_probability); agent[i].rms = agent[i].ag.rferrors[0]; agent[i].oob = agent[i].ag.rferrors[1]; } }
Entre ellos: el nombre del grupo de agentes, el número de trabajadores, el número de características para cada trabajador, el número de mejores características seleccionadas, el número de árboles en el bosque, el parámetro de regularización (división en conjuntos de entrenamiento y prueba), y el desplazamiento de la probabilidad para el control del número de transacciones.
Como podemos ver, en la matriz de estructuras se colocan los objetos de los aprendices con las mismas variables de entrada, así como los errores de entrenamiento y prueba.
El método de entrenamiento de agentes ejecuta la llamada del método de entrenamiento para cada clase básica CRLAgent, y retorna el error promediado en el conjunto de prueba de todos los agentes:
//+------------------------------------------------------------------+ //|Learn all agents | //+------------------------------------------------------------------+ double CRLAgents::learnAllAgents(void){ double err=0; for(int i=0;i<ArraySize(agent);i++) err+=agent[i].ag.learnAnAgent(); return err/ArraySize(agent); }
Este error se usa como criterio de optimización personalizado para visualizar la dispersión del error al iterar los modelos con el método de Montecarlo.
Puesto que al crear cierto número de aprendices en un subgrupo sus ajustes permanecen iguales, existe un método de corrección de parámetros para cada aprendiz por separado:
//+------------------------------------------------------------------+ //|Change agents settings | //+------------------------------------------------------------------+ CRLAgents::setAgentSettings(int agentNumber,int features,int bestfeatures,int treesNumber,double regularization,double shift_probability) { agent[agentNumber].ag.features=features; agent[agentNumber].ag.bestfeatures_num=bestfeatures; agent[agentNumber].ag.trees=treesNumber; agent[agentNumber].ag.r=regularization; agent[agentNumber].ag.prob_shift=shift_probability; ArrayResize(agent[agentNumber].inpVector,features); ArrayInitialize(agent[agentNumber].inpVector,0); }
A diferencia de la clase básica CRLAgent, en CRLAgents la señal comercial se muestra como la media para las señales de todos los aprendices que entran en el subgrupo:
//+------------------------------------------------------------------+ //|Get common trade signal | //+------------------------------------------------------------------+ double CRLAgents::getTradeSignal() { double signal[]; double sig=0; ArrayResize(signal,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) sig+=signal[i]=agent[i].ag.getTradeSignal(agent[i].inpVector); return sig/(double)ArraySize(agent); }
Finalmente, el método de obtención de estadísticas muestra la información sobre los errores para la prueba y el entrenamiento para todos los agentes al final de una pasada única en el simulador:
//|Get agents statistics | //+------------------------------------------------------------------+ void CRLAgents::getStatistics(void) { double arr[]; double arrrms[]; ArrayResize(arr,ArraySize(agent)); ArrayResize(arrrms,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) { arrrms[i]=agent[i].rms; arr[i]=agent[i].oob; } Print(groupName+" TRAIN LOSS"); ArrayPrint(arrrms); Print(groupName+" OOB LOSS"); ArrayPrint(arr); }
Creando un robot comercial basado en la biblioteca RL Monte Carlo
Solo queda escribir un sencillo experto para mostrar las posibilidades de la biblioteca. Vamos a comenzar por el primer caso, cuando se crea un agente que se entrena con los precios de cierre del instrumento comercial.
#include <RL Monte Carlo.mqh>
input int number_of_passes = 10; input double shift_probab = 0,5; input double regularize=0.6; sinput int number_of_best_features = 5; sinput double treshhold = 0.5; sinput double MaximumRisk=0.01; sinput double CustomLot=0; CRLAgents *ag1=new CRLAgents("RlMonteCarlo",1,500,number_of_best_features,50,regularize,shift_probab);
Incluimos la biblioteca y definimos los inputs que podemos optimizar. number_of_passes ha sido pensado para determinar el número de pasadas en el optimizador del terminal, y no se transmite a ninguna parte. Puesto que las entradas y salidas son seleccionadas por el trabajador de forma aleatoria, podemos obtener la estrategia óptima tras múltiples pasadas y determinar el menor error. Cuantas más pasadas se establezcan, mayor será la probabilidad de obtener la estrategia óptima.
Los demás ajustes ya se han expuesto más arriba y se transmiten directamente al modelo creado anteriormente. Aquí hemos creado un agente que se relaciona con el grupo "RlMonteCarlo". A su entrada se suministran 500 características, de entre ellas se seleccionan las 5 mejores. El modelo tendrá 50 árboles de decisiones, con una división de muestras de entrenamiento y prueba de 0.6 (parámetro r), sin desplazamiento de probabilidad.
En la función OnTester retornaremos el criterio de optimización personalizado (en forma de error promediado en la muestra de prueba de todos los aprendices), entrenándolos de forma preliminar:
//+------------------------------------------------------------------+ //| Expert ontester function | //+------------------------------------------------------------------+ double OnTester() { if(MQLInfoInteger(MQL_OPTIMIZATION)) return ag1.learnAllAgents(); else return NULL; }
Al desinicializar el experto, se eliminan los aprendices y se libera la memoria:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { delete ag1; }
El vector de los predictores se rellena de la forma siguiente:
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
En este caso, simplemente se toman los 500 últimos precios de cierre. Recordemos que, en el modelo, se considera predictor la razón entre el elemento cero de la matriz y algún otro (con un cierto retraso), por eso estableceremos una matriz que reciba los precios de cierre, as series. Después de ello, se llama el método de obtención de la señal comercial.
La última función es la comercial:
//+------------------------------------------------------------------+ //| Place orders | //+------------------------------------------------------------------+ void placeOrders() { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) { if(OrderType()==0 && Tsignal>0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} if(OrderType()==1 && Tsignal<0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} } if(countOrders(0)!=0 || countOrders(1)!=0) return; if(Tsignal<0.5-treshhold && (OrderSend(Symbol(),OP_BUY,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } if(Tsignal>0.5+treshhold && (OrderSend(Symbol(),OP_SELL,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } }
Se ha introducido de forma adicional el parámetro treshold (umbral), que permite establecer el umbral de activación de la señal. Por ejemplo, si la probabilidad de una señal de compra es inferior a 0.6, la orden no se abrirá.
Optimizando el experto RL Monte Carlo Trader
Vamos a echar un vistazo a los ajustes que se pueden optimizar:
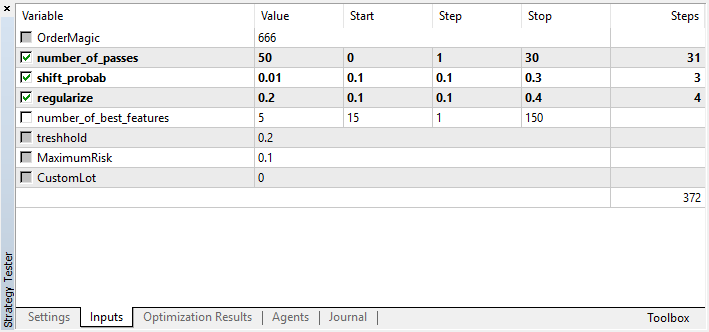
Recordemos que number_of_passes no transmite ningún valor al aprendiz, sino que simplemente establece el número de pasadas del optimizador. Supongamos que usted ya ha decidido qué ajustes utilizar y quiere usar exclusivamente la iteración con el método Montecarlo, entonces será conveniente optimizar solo de acuerdo con este criterio. Puede optimizar los otros cuatro ajustes a su gusto.
Otra peculiaridad de la versión actual es que no existe la necesidad de desactivar los agentes de simulación, puesto que las pasadas en el optimizador no dependen las unas de las otras, y la secuencia de guardado de modelos no es importante.
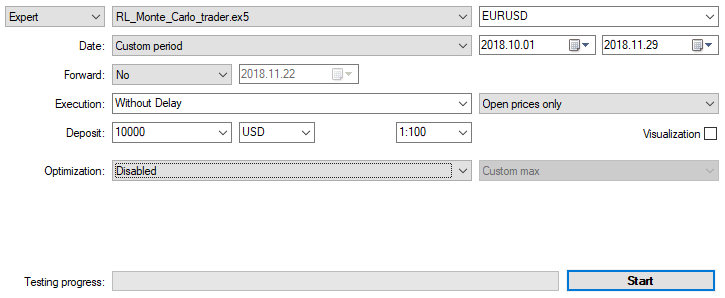
Vamos a optimizar el experto con los ajustes indicados más arriba en el gráfico de 15 minutos por dos meses, según los precios de apertura. Como criterio de optimización debemos elegir "Criterio personalizado máximo". El proceso de optimización puede establecerse en cualquier momento, cuando se alcance un valor asumible para el criterio de optimización:
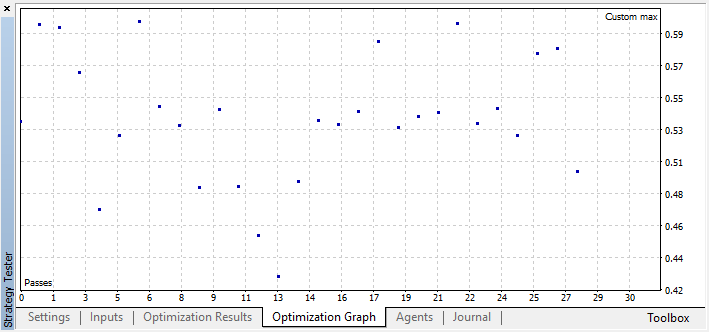
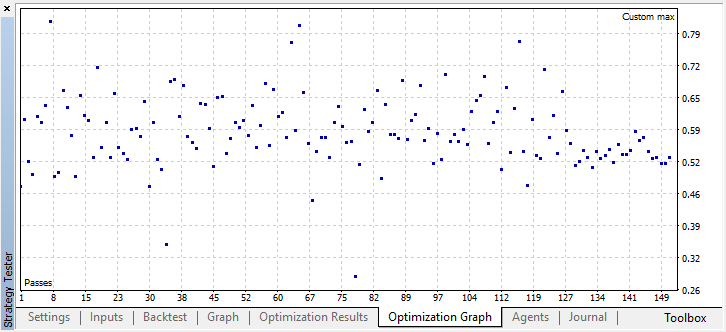
Por ejemplo, hemos detenido el proceso de optimización ya en el paso 44, puesto que uno de los mejores modelos ha superado el umbral de precisión de 0.6. Esto significa que el error de clasifición en el conjunto de prueba ha caído por debajo de 0.4. Merece la pena considerar que cuanto mejor sea el modelo, menor será el error, pero para que el algoritmo genético funcione correctamente (si desea usarlo), los valores de los errores son invertidos.
Usted puede comprobar los ajustes del mejor modelo en la pestaña "optimización", clasificando los valores según el criterio personalizado máximo:
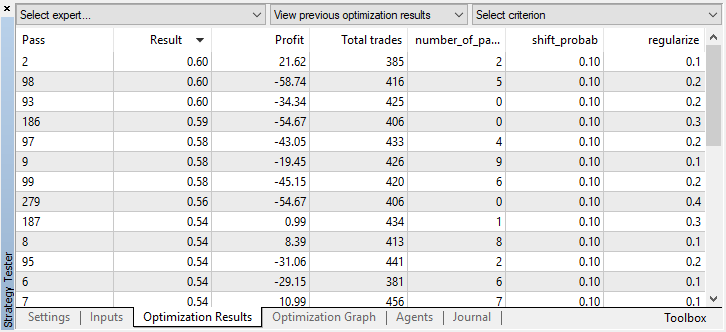
En este caso, el mejor modelo se ha obtenido con un desplazamiento de la probabilidad de 0.1 y un parámetro r de 0.2 (el conjunto de entrenamiento constituye un total del 20% de toda la matriz de transacciones, mientras que el 80% es el subconjunto de prueba).
Después de detener la optimización, solo tenemos que activar el modo de simulación única (puesto que el mejor modelo se guarda en el archivo y se carga solo él):
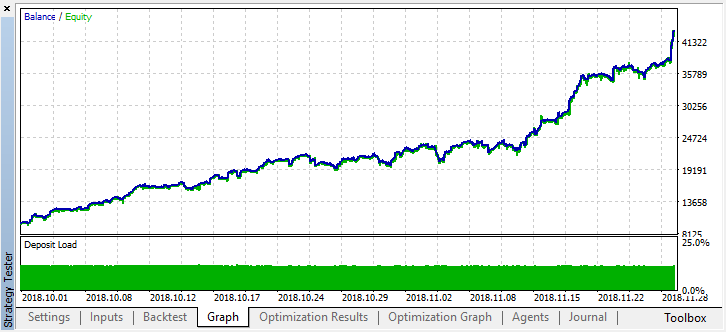
Vamos a retroceder en la historia hasta hace dos meses y mirar cómo funciona el modelo en los cuatro meses completos:
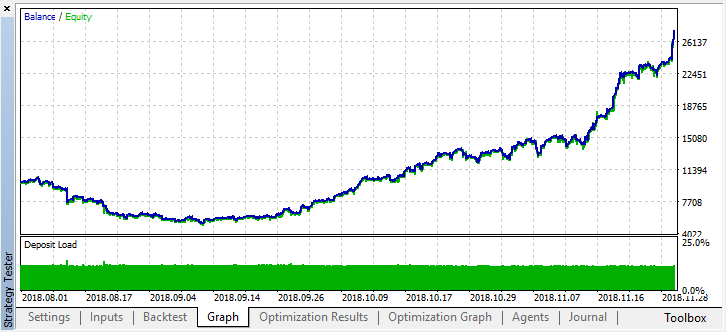
Podemos ver que el modelo obtenido ha aguantado dos meses más (septiembre casi al completo), pero en agosto se ha roto. Vamos a intentar mejorar el modelo, estableciendo un umbral "treshhold" igual a 0.2:
Ahora se nota mejor que al reducir el número de transacciones, ha aumentado la precisión del modelo. Es posible realizar la simulación con una profundidad mayor, considerando que el periodo de entrenamiento sea de la duración adecuada.
Vamos a pasar a la variante del experto en la que se han añadido varios aprendices, para comparar la efectividad del enfoque multiagente con la efectividad de un agente.
Para ello, al crear un grupo de agentes, añadiremos la terminación "Multi", para que los archivos de diferentes sistemas no se mezclen, e indicaremos el número de trabajadores, por ejemplo, cinco:
CRLAgents *ag1=new CRLAgents("RlMonteCarloMulti",5,500,number_of_best_features,50,regularize,shift_probab);
Pero todos los agentes han resultado iguales (tienen ajustes idénticos). Podemos configurar cada trabajador por separado en la función de inicialización del experto:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ag1.setAgentSettings(0,500,20,50,regularize,shift_probab); ag1.setAgentSettings(1,200,15,50,regularize,shift_probab); ag1.setAgentSettings(2,100,10,50,regularize,shift_probab); ag1.setAgentSettings(3,50,5,50,regularize,shift_probab); ag1.setAgentSettings(4,25,2,50,regularize,shift_probab); return(INIT_SUCCEEDED); }
Aquí hemos decido no pasarnos de listos, para no terminar de confundir al lector, así que hemos colocado el número de características para los agentes en orden decreciente, de 500 a 25. Asimismo, el número de mejores características seleccionadas se reduce de 20 a 2. Estos ajustes se han dejado sin cambios, pero se los puede modificar y añadir nuevos parámetros optimizables. Esperamos que los lectores hagan por sí mismos estos experimentos y compartan sus resultados en los comentarios a este artículo.
Recordemos que el rellanado de las matrices con los valores de los predictores se realiza en la función:
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
Aquí solo tenemos que rellenar la matriz inpVector con los precios de cierre para cada aprendiz, dependiendo de su tamaño, por eso la función es universal para este caso, y no necesita cambios.
Iniciamos la optimización con exactamente los mismos ajustes que se dan en la optimización con un agente:
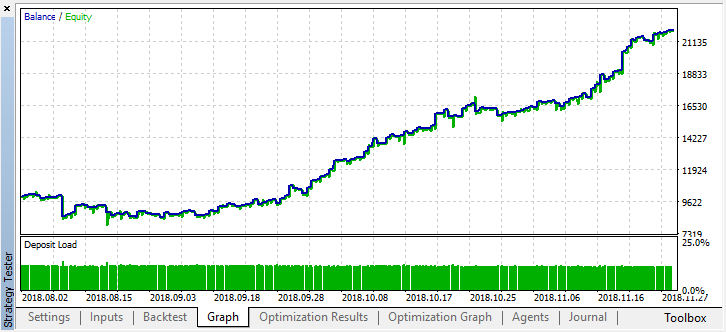
El mejor resultado ha superado la marca de 0.7, lo cual es bastante mejor que en el primer caso. Iniciamos una pasada única en el simulador:
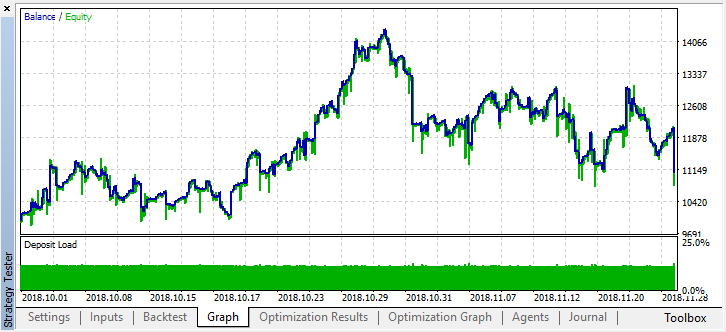
Al mismo tiempo, el resultado real en forma de gráfico de balance es ahora bastante peor, ¿por qué ha sucedido así? Vamos a mirar el número de transacciones aleatorias de la mejor pasada, ¡solo son 21!
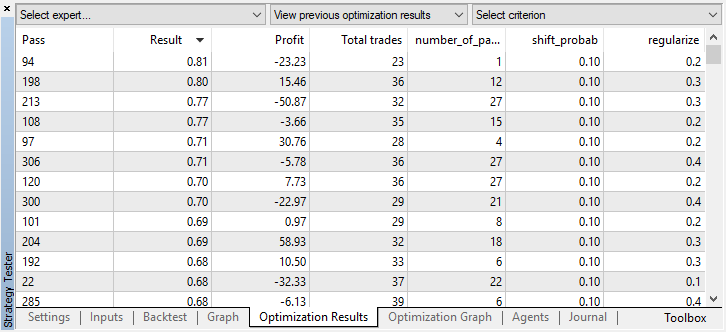
Ha sucedido esto porque al realizar el muestro aleatorio, las señales de varios agentes se han superpuesto unas a otras, y el número total de transacciones se ha reducido. Para corregir el error, debemos establecer el parámetro shift_probab más próximo a 0.5, en ese caso, el número de transacciones de cada agente por separado será mayor, y el número total de transacciones también aumentará. Por otra parte, podemos simplemente aumentar el periodo de entrenamiento, pero, en primer lugar, deberemos comprobar si es posible seguir trabajando con ese modelo en lo sucesivo. Esteblecemos "treshhold" en 0.2 y vemos qué hemos obtenido:
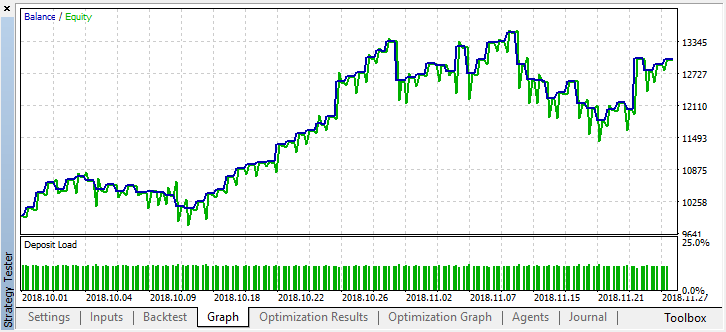
Por lo menos, el modelo no pierde dinero, aunque el número de transacciones se ha reducido más. Preste atención a que después de la pasada única, en el registro del simulador se muestran los errores, si usted los ha olvidado:
2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo TRAIN LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.02703 0.20000 0.09091 0.05714 0.14286 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo OOB LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.21622 0.23333 0.21212 0.17143 0.19048
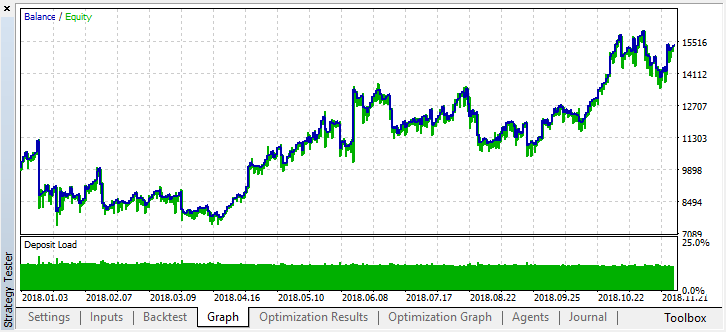
Ahora vamos a simular este modelo desde comienzos del año. Los resultados son bastante estables:
Bien, establecemos shift_probab, digamos, en 0.3, e iniciamos el optimizador sin este parámetro para los mismos dos meses en 15 minutos (solo estamos intentando encontrar un equilibrio en el número de transacciones):
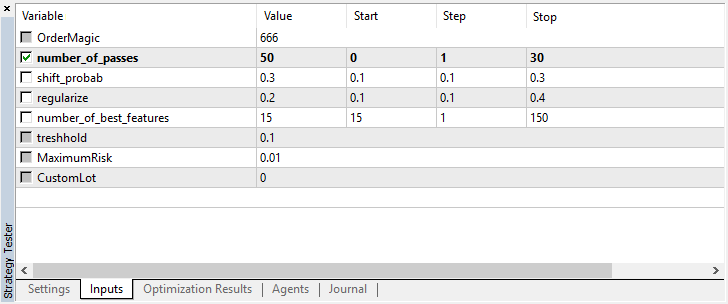
No hemos castigado mucho la computadora, ya que la complejidad de los cálculos es ahora mayor, y tras varias iteraciones, nos hemos dado por contentos con este resultado en el optimizador:
2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti TRAIN LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.13229 0.16667 0.16262 0.14599 0.20937 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti OOB LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.45377 0.45758 0.44650 0.45693 0.46120
El error en OOB (muestra de prueba) ha quedado bastante alto, no obstante, con un umbral de 0.2, en 4 meses, el modelo ha mostrado beneficios, aunque se ha comportado de forma inestable en los datos de prueba.
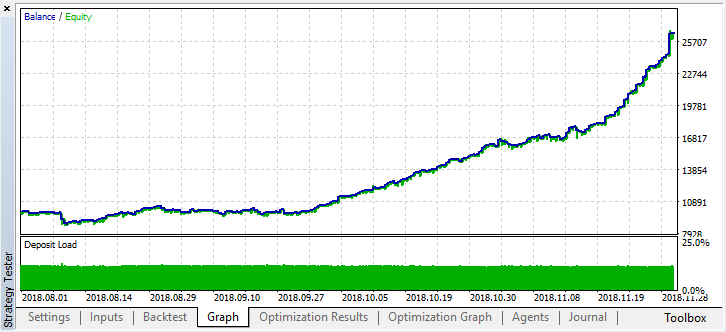
Debemos recordar que todos los aprendices se han entrenado con los mismos datos, es decir, los precios de cierre, por eso no ha tenido mucho sentido añadir nuevos. Sin embargo, este ha sido un ejemplo sencillo de adición de nuevos agentes.
Conclusiones del trabajo realizado
El aprendizaje por refuerzo es, quizá, uno de los métodos más interesantes del aprendizaje de máquinas. Resulta siempre tentador pensar que la inteligencia artificial es capaz de resolver tareas comerciales en los mercados financieros entrenando por sí misma, sin supervisión. Pero, al mismo tiempo, debemos poseer amplios conocimientos en la esfera del aprendizaje de máquinas, la estadística y la teoría de probabilidad para crear semejante "milagro". Notemos que el método de Montecarlo y la selección de modelos con el menor error en los datos de prueba ha mejorado considerablemente el modelo propuesto en el primer artículo: el modelo ahora se reentrena menos.
Conviene recordar que la elección del mejor modelo es necesaria tanto para el número de transacciones, como para el menor error de clasificación en la muestra out-of-bag. Lo ideal sería que los errores en las muestras de entrenamiento y prueba fuesen aproximadamente iguales, y que no alcanzasen el valor 0.5 (la mitad de los ejemplos se ha predicho erróneamente).
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/4777
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
 Uso práctico de las redes neuronales de Kohonen en el trading algorítmico (Parte I) Instrumental
Uso práctico de las redes neuronales de Kohonen en el trading algorítmico (Parte I) Instrumental
 Optimización separada de una estrategia en condiciones de tendencia y flat
Optimización separada de una estrategia en condiciones de tendencia y flat
 Utilidad para la selección y navegación en MQL5 y MQL4: añadiendo las pestañas de "recordatorios" y guardando objetos gráficos
Utilidad para la selección y navegación en MQL5 y MQL4: añadiendo las pestañas de "recordatorios" y guardando objetos gráficos
 Desarrollando una utilidad para la selección y navegación de instrumentos en los lenguajes MQL5 y MQL4
Desarrollando una utilidad para la selección y navegación de instrumentos en los lenguajes MQL5 y MQL4
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
leer los 2 posts anteriores
¿Podría aclarar lo que significan estos mensajes? Es decir, cómo resolver esto para hacer que el trabajo EA
¿Podría aclarar qué significan estos mensajes? Es decir, cómo solucionar esto para que el EA funcione
Añadir void antes de declarar las clases, como la persona escribió en los posts anteriores