
強化学習におけるモンテカルロ法の応用
これまでの資料のまとめとアルゴリズム改善方法
前回の記事で、Random Decision Forestアルゴリズムを学び、Reinforcement learning(強化学習)に基づいた簡単な自己学習EAを作成しました。
このアプローチの主な利点は、次の通りです。
- 取引アルゴリズムを書くことの容易さと『学習』の高速性。強化学習(以下、単にRL)は、どのEAにも簡単に組み込むことができ、最適化のスピードを上げられます。
同時に、このアプローチには1つの大きな欠点があります。
- このアルゴリズムは、再最適化(再学習)、つまり一般母集団の弱い一般化(一般化)が行われる傾向があります。その結果の分布は不明です。これはつまり、これは、金融商品の過去の全期間に特有の実際の基本的な市場パターンを探すのではなく、現在の市場状況に基づいて過剰適合し、グローバルパターンは訓練を受けたエージェントの理解の反対側にとどまることを意味している。ただし、遺伝的最適化には同じ欠点があり、多数の変数がある場合は非常に遅くなる。
再学習と戦うためには、2つの主なテクニックがあります。
- Feature ingeneeringまたは属性の構築。このアプローチの主な目的は、そのような特徴と、母集団全体を低い誤差で記述することになる目標変数の選択です。言い換えれば、これは予測子の検索による統計的および計量経済学的方法によるもっともらしい規則性を検索することです。非定常市場では、この作業はかなり複雑で、特定の戦略では難解です。ただし、最適な戦略を選択するように努力する必要があります。
- Regularization ー または正則化 ー 使用されるアルゴリズムのレベルで修正することによってモデルを粗くするために使用されます。前回の記事から、RDFではrパラメータが、これに使用されていることを覚えていると思います。正則化により、トレーニングサンプルとテストサンプルの間の誤差のバランスをとることができ、新しいデータに対するモデルの安定性が向上します(原則として可能な場合)。
強化学習へのアプローチの改善
上記の技法は、独自の方法でアルゴリズムに組み込まれています。一方では、属性の構築は価格の増分を列挙していくつかの最良のものを選択することによって実行され、他方では、新しい(out-of-bag)データに関する分類誤差が最小のモデルが、rパラメータの調整によって選択されます。
さらに、異なる設定を設定できるいくつかのRLエージェントを同時に作成する新しい機会があります。これは、理論上、新しいデータに対するモデルの安定性を高めるはずです。モデルの列挙は、最適なモデルがさらなる使用のためにファイルに書き込まれている間に、モンテカルロ法(ラベルのランダムサンプリング)を使用してオプティマイザで実行されます。
CRLAgent基本クラスの作成
便宜上、このライブラリーはOOPに基づいているため、EAに接続して必要な数のRLエージェントを宣言することが容易になります。
ここでは、プログラム内の対話構造をより深く理解するためのクラスフィールドについて説明します。
//+------------------------------------------------------------------+ //|RL agent base class | //+------------------------------------------------------------------+ class CRLAgent { public: CRLAgent(string,int,int,int,double, double); ~CRLAgent(void); static int agentIDs; void updatePolicy(double,double&[]); //各取引の後に学習ポリシーを更新する void updateReward(); //取引終了後に報酬を更新する double getTradeSignal(double&[]); //学習したエージェントまたはランダムで取引シグナルを取得する int trees; double r; int features; double rferrors[], lastrferrors[]; string Name;
最初の3つの方法は、学習者(エージェント)の方針(戦略)を形成し、報酬を更新し、学習をしたエージェントから取引シグナルを受信するために使用されます。これについては最初の記事で詳しく説明しています。
さらに、ランダムフォレストの設定、属性の数(入力変数)、モデルエラーを格納するための配列、およびエージェントの名前(エージェントのグループ)を定義する補助フィールドが宣言されています。
private: CMatrixDouble RDFpolicyMatrix; CDecisionForest RDF; CDFReport RDF_report; double RFout[]; int RDFinfo; int agentID; int numberOfsamples; void getRDFstructure(); double getLastProfit(); int getLastOrderType(); void RecursiveElimination(); double bestFeatures[][2]; int bestfeatures_num; double prob_shift; bool random; };
次にパラメータ化された学習者ポリシーを保存するためのマトリックス、ランダムフォレストオブジェクト、およびエラーを格納するための補助オブジェクトが、さらに宣言されます。
以下の静的変数は、エージェントの固有IDを格納するためにあります。
static int CRLAgent::agentIDs=0;
コンストラクタは、作業を始める前にすべての変数を初期化します。
CRLAgent::CRLAgent(string AgentName,int number_of_features, int bestFeatures_number, int number_of_trees,double regularization, double shift_probability) { random=false; MathSrand(GetTickCount()); ArrayResize(rferrors,2); ArrayResize(lastrferrors,2); Name = AgentName; ArrayResize(RFout,2); trees = number_of_trees; r = regularization; features = number_of_features; bestfeatures_num = bestFeatures_number; prob_shift = shift_probability; if(bestfeatures_num>features) bestfeatures_num = features; ArrayResize(bestFeatures,1); numberOfsamples = 0; agentIDs++; agentID = agentIDs; getRDFstructure(); }
最後に、コントロールはgetRDFstructure()メソッドに委任され、次のアクションが実行されます。
//+------------------------------------------------------------------+ //|Load learned agent | //+------------------------------------------------------------------+ CRLAgent::getRDFstructure(void) { string path=_Symbol+(string)_Period+Name+"\\"; if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(FileIsExist(path+"RFlasterrors"+(string)agentID+".rl",FILE_COMMON)) { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,lastrferrors,0); FileClose(getRDF); } while (getRDF<0); } else { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } while (getRDF<0); } return; } if(FileIsExist(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON)) { int getRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_READ|FILE_TXT|FILE_COMMON); CSerializer serialize; string RDFmodel=""; while(FileIsEnding(getRDF)==false) RDFmodel+=" "+FileReadString(getRDF); FileClose(getRDF); serialize.UStart_Str(RDFmodel); CDForest::DFUnserialize(serialize,RDF); serialize.Stop(); getRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,bestFeatures,0); FileClose(getRDF); getRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,rferrors,0); FileClose(getRDF); getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } else random = true; }
EAの最適化プロセスが実行されている場合は、前回のオプティマイザ反復で記録されたエラーファイルの存在を確認します。したがって、新しい反復ごとに、それに続く最小の反復の選択のために比較されます。
EAがテストモードで起動された場合、訓練されたモデルはさらなる使用のためにファイルからダウンロードされます。また、モデルの最新のエラーが消去され、新しい最適化がゼロから始まるように1に等しいデフォルト値が設定されます。
次にオプティマイザを実行した後、学習は次のように実行されます。
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination();
コントロールは、属性の連続的な選択、つまり価格の増加を目的とした指定された方法に委任されます。それがどのように機能するか見てみましょう。
//+------------------------------------------------------------------+ //|Recursive feature elimination for matrix inputs | //+------------------------------------------------------------------+ CRLAgent::RecursiveElimination(void) { //feature transformation, making every 2 features as returns with different lag's ArrayResize(bestFeatures,0); ArrayInitialize(bestFeatures,0); CDecisionForest mRDF; CMatrixDouble m; CDFReport mRep; m.Resize(RDFpolicyMatrix.Size(),3); int modelCounterInitial = 0; for(int bf=1;bf<features;bf++) { for(int i=0;i<RDFpolicyMatrix.Size();i++) { m[i].Set(0,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][bf]); //行列を増分で埋める(配列のゼロインデックスの価格はbfシフトのある価格で除算される) m[i].Set(1,RDFpolicyMatrix[i][features]); m[i].Set(2,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),1,2,trees,r,RDFinfo,mRDF,mRep); //選択された増分のみが予測子として使用されるランダムフォレストを 学習 ArrayResize(bestFeatures,ArrayRange(bestFeatures,0)+1); bestFeatures[modelCounterInitial][0] = mRep.m_oobrelclserror; //エラーをoobセットに保存します bestFeatures[modelCounterInitial][1] = bf; //インクリメント "lag"を保存する modelCounterInitial++; } ArraySort(bestFeatures); //配列を(ゼロ次元で)ソートする。つまり、oobはエラーでここに表示する ArrayResize(bestFeatures,bestfeatures_num); //最高のbestfeatures_num属性のみを残す m.Resize(RDFpolicyMatrix.Size(),2+ArrayRange(bestFeatures,0)); for(int i=0;i<RDFpolicyMatrix.Size();i++) { //再度行列を埋めまるが、今回は最適な属性を使用する for(int l=0;l<ArrayRange(bestFeatures,0);l++) { m[i].Set(l,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][(int)bestFeatures[l][1]]); } m[i].Set(ArrayRange(bestFeatures,0),RDFpolicyMatrix[i][features]); m[i].Set(ArrayRange(bestFeatures,0)+1,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),ArrayRange(bestFeatures,0),2,trees,r,RDFinfo,RDF,RDF_report); //選択した最良の属性でランダムフォレストを訓練する }
エージェントのトレーニング方法全体を見てみましょう。
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination(); if(RDF_report.m_oobrelclserror<lastrferrors[1]) { string path=_Symbol+(string)_Period+Name+"\\"; //FileDelete(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON); CSerializer serialize; serialize.Alloc_Start(); CDForest::DFAlloc(serialize,RDF); serialize.SStart_Str(); CDForest::DFSerialize(serialize,RDF); serialize.Stop(); int setRDF; do { setRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); if(setRDF<0) continue; lastrferrors[0]=RDF_report.m_relclserror; lastrferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,lastrferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_WRITE|FILE_TXT|FILE_COMMON); FileWrite(setRDF,serialize.Get_String()); FileClose(setRDF); setRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); rferrors[0]=RDF_report.m_relclserror; rferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,rferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileWriteArray(setRDF,bestFeatures); FileClose(setRDF); } while(setRDF<0); } } } return 1-RDF_report.m_oobrelclserror; }
属性を選択してエージェントをトレーニングした後、現在の最適化パスにおけるエージェントの分類誤差が、全体として最適化中に記憶された最小誤差と比較されます。現在のエージェントの誤差が小さい場合、現在のモデルは最良のものとして保存され、その後の比較ではこのモデルの誤差が使用されます。
別に、モンテカルロ法、またはターゲット変数のランダムサンプリングを検討する必要があります。
//+------------------------------------------------------------------+ //|Get trade signal | //+------------------------------------------------------------------+ double CRLAgent::getTradeSignal(double &featuresValues[]) { double res=0.5; if(!MQLInfoInteger(MQL_OPTIMIZATION) && !random) { double kerfeatures[]; ArrayResize(kerfeatures,ArrayRange(bestFeatures,0)); ArrayInitialize(kerfeatures,0); for(int i=0;i<ArraySize(kerfeatures);i++) { kerfeatures[i] = featuresValues[0]/featuresValues[(int)bestFeatures[i][1]]; } CDForest::DFProcess(RDF,kerfeatures,RFout); return RFout[1]; } else { if(countOrders()==0) if(rand()/32767.0<0.5) res = 0; else res = 1; else { if(countOrders(0)!=0) if(rand()/32767.0>prob_shift) res = 0; else res = 1; if(countOrders(1)!=0) if(rand()/32767.0<prob_shift) res = 0; else res = 1; } } return res; }
EAが最適化モードになっていない場合は、EAの初期化時にダウンロードされたトレーニング済みのモデルが取引シグナルの受信に使用されます。それ以外の場合では、最適化プロセスが進行中の場合、またはモデルファイルがない場合、シグナルはオープンポジションがない場合(50/50)、オープンオーダーがある場合はprob_shift変数で設定されたオフセット確率でランダムに発生します。このように、たとえば、買い取引がすでに存在する場合、売りシグナルの確率を(0.5の代わりに)0.1までにシフトできます。その結果、学習セット内のサンプルの総数が減少し、ポジションが長く保持されます。同時にprob_shift> = 0.5に設定すると、取引数が増えます。
CRLAgentsクラスを作成する
これで、トレーディングシステムでさまざまなタスクを実行する多数のエージェント(Lernenres)を手に入れることができます。現在のクラスは同質な学習者グループのより便利な管理のために開発されました。
//+------------------------------------------------------------------+ //|Multiple RL agents class | //+------------------------------------------------------------------+ class CRLAgents { private: struct Agents { double inpVector[]; CRLAgent *ag; double rms; double oob; }; void getStatistics(); string groupName; public: CRLAgents(string,int,int,int,int,double,double); ~CRLAgents(void); Agents agent[]; void updatePolicies(double); void updateRewards(); double getTradeSignal(); double learnAllAgents(); void setAgentSettings(int,int,int,double); };
Agents構造体は各学習者のパラメータを受け入れ、構造体の配列はそれらの総数を含みます。単一のエージェントの場合、この特定のクラスを使用することも意味があります。
コンストラクタは、学習に必要なすべてのパラメータを取ります。
CRLAgents::CRLAgents(string AgentsName,int agentsQuantity,int features, int bestfeatures, int treesNumber,double regularization, double shift_probability) { groupName=AgentsName; ArrayResize(agent,agentsQuantity); for(int i=0;i<agentsQuantity;i++) { ArrayResize(agent[i].inpVector,features); ArrayInitialize(agent[i].inpVector,0); agent[i].ag = new CRLAgent(AgentsName, features, bestfeatures, treesNumber, regularization, shift_probability); agent[i].rms = agent[i].ag.rferrors[0]; agent[i].oob = agent[i].ag.rferrors[1]; } }
その中には、エージェントグループの名前、ワーカーの数、各ワーカーのサインの数、最適なサインの数、フォレスト内の木の数、正規化パラメーター(トレーニングとテストサンプルへの分離)、およびトランザクション数を制御する確率オフセットがあります。
見ての通り、同じ変数を持つ学習者オブジェクトと、トレーニングおよびテストエラーは、構造体配列に配置されます。
エージェントの学習方法は、各CRLAgent基本クラスの学習方法を呼び出し、すべてのエージェントのテストセットの平均誤差を返します。
//+------------------------------------------------------------------+ //|Learn all agents | //+------------------------------------------------------------------+ double CRLAgents::learnAllAgents(void){ double err=0; for(int i=0;i<ArraySize(agent);i++) err+=agent[i].ag.learnAnAgent(); return err/ArraySize(agent); }
この誤差は、モンテカルロ法を使用してモデルを反復するときに誤差の広がりを視覚化するためのカスタム最適化基準として使用されます。
1つのサブグループに一定数の学習者を作成するとき、それらの設定は同じままです。したがって、各学習者のパラメータを調整する方法があります。
//+------------------------------------------------------------------+ //|Change agents settings | //+------------------------------------------------------------------+ CRLAgents::setAgentSettings(int agentNumber,int features,int bestfeatures,int treesNumber,double regularization,double shift_probability) { agent[agentNumber].ag.features=features; agent[agentNumber].ag.bestfeatures_num=bestfeatures; agent[agentNumber].ag.trees=treesNumber; agent[agentNumber].ag.r=regularization; agent[agentNumber].ag.prob_shift=shift_probability; ArrayResize(agent[agentNumber].inpVector,features); ArrayInitialize(agent[agentNumber].inpVector,0); }
CRLAgent基本クラスとは異なり、CRLAgentでは、サブグループに属するすべての学習者のシグナルの平均として取引シグナルが表示されます。
//+------------------------------------------------------------------+ //|Get common trade signal | //+------------------------------------------------------------------+ double CRLAgents::getTradeSignal() { double signal[]; double sig=0; ArrayResize(signal,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) sig+=signal[i]=agent[i].ag.getTradeSignal(agent[i].inpVector); return sig/(double)ArraySize(agent); }
最後に、統計を取得する方法では、テスターでのシングルパスの最後に、すべてのエージェントのテストとトレーニングに関するエラーに関するデータが表示されます。
//+------------------------------------------------------------------+ //|Get agents statistics | //+------------------------------------------------------------------+ void CRLAgents::getStatistics(void) { double arr[]; double arrrms[]; ArrayResize(arr,ArraySize(agent)); ArrayResize(arrrms,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) { arrrms[i]=agent[i].rms; arr[i]=agent[i].oob; } Print(groupName+" TRAIN LOSS"); ArrayPrint(arrrms); Print(groupName+" OOB LOSS"); ArrayPrint(arr); }
RL Monte Carloライブラリーに基づくEAの作成
ライブラリの機能を説明するための簡単なEAの作成が残っています。取引商品の終値でトレーニングするために作成されるエージェントは1つだけという事例から始めましょう。
#include <RL Monte Carlo.mqh>
input int number_of_passes = 10; input double shift_probab = 0,5; input double regularize=0.6; sinput int number_of_best_features = 5; sinput double treshhold = 0.5; sinput double MaximumRisk=0.01; sinput double CustomLot=0; CRLAgents *ag1=new CRLAgents("RlMonteCarlo",1,500,number_of_best_features,50,regularize,shift_probab);
ライブラリを含め、最適化できるインプットを定義します。number_of_passesは、端末オプティマイザでのパス数を決定するためのもので、どこにも渡されません。出入り口は作業者によって無作為に選択されるため、複数のパスを経て最小の誤差を定義した後で最適な戦略を達成することが可能です。より多くのパスがインストールされるほど、最適な戦略を取得する可能性が高くなります。
残りの設定はすでに上で概説されており、上で作成されたモデルに直接送信されます。ここでは、RlMonteCarloグループに属する単一のエージェントを作成しました。500個の属性が入力として渡され、そのうち5個の属性が選択されます。このモデルは、確率オフセットなしで、トレーニングセットとテストセットが0.6(rパラメータ)分離された50の決定木を持つことになっています。
OnTester関数では、以前にトレーニングしたカスタム最適化基準(すべての学習者のテストサンプルの平均誤差の形式で)を返します。
//+------------------------------------------------------------------+ //| Expert ontester function | //+------------------------------------------------------------------+ double OnTester() { if(MQLInfoInteger(MQL_OPTIMIZATION)) return ag1.learnAllAgents(); else return NULL; }
EAの初期化解除中に、学習者は削除され、メモリは解放されます。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { delete ag1; }
予測子のベクトルは次のように記入されます。
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
この場合、最後の500終値を取ります。覚えているかもしれませんが、配列のゼロ要素と他の要素(一定の遅れを持つ)の比率は、モデルの予測子と見なされるため、終値を受け入れる配列をas seriesとして設定します。その後取引シグナル取得メソッドが呼び出されます。
最後の機能は取引です。
//+------------------------------------------------------------------+ //| Place orders | //+------------------------------------------------------------------+ void placeOrders() { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) { if(OrderType()==0 && Tsignal>0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} if(OrderType()==1 && Tsignal<0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} } if(countOrders(0)!=0 || countOrders(1)!=0) return; if(Tsignal<0.5-treshhold && (OrderSend(Symbol(),OP_BUY,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } if(Tsignal>0.5+treshhold && (OrderSend(Symbol(),OP_SELL,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } }
さらに、パラメータtreshold(threshold)が追加されました。これにより、シグナルをトリガするためのしきい値を設定できます。たとえば、買いシグナルの確率が0.6未満の場合、注文は開かれません。
RLモンテカルロトレーダーEAの最適化
最適化できる設定を見てみましょう。
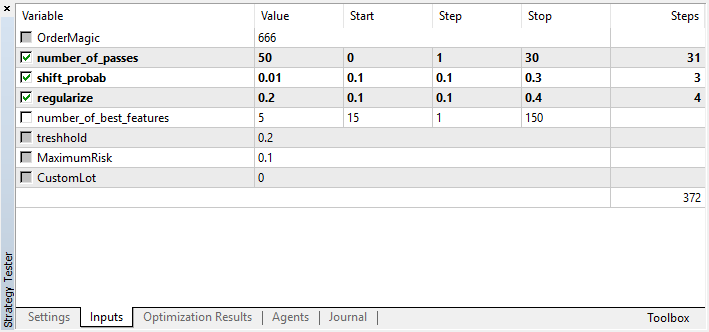
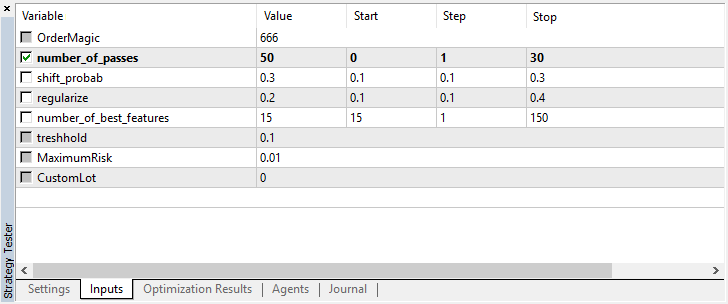
number_of_passesは値を学習者に渡さないことに注意してください。代わりに、オプティマイザパスの数を設定するだけです。あなたが他の設定を決め、もっぱらモンテカルロベースの列挙型のみを使用したいとします。その場合は、この基準によってのみ最適化する必要があります。必要に応じて、残りの4つの設定を最適化することができます。
現在のバージョンのもう1つの機能は、オプティマイザのパスが互いに独立しており、モデルを保存する順序が重要ではないため、テストエージェントを無効にする必要がないことです。
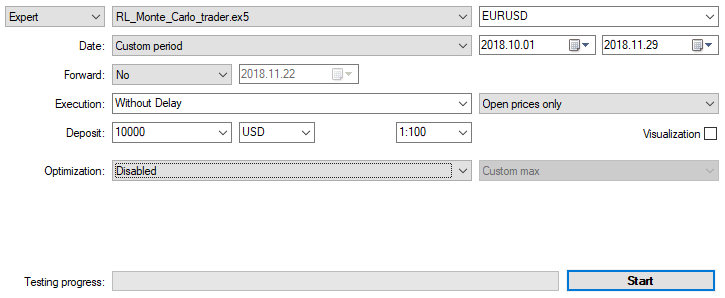
2ヶ月以内にM15の始値で、上記で指定された設定でEAを最適化しましょう。最適化基準として『最大カスタム値』を選択する必要があります。最適化基準の許容値に達すると、最適化プロセスはいつでも停止できます。
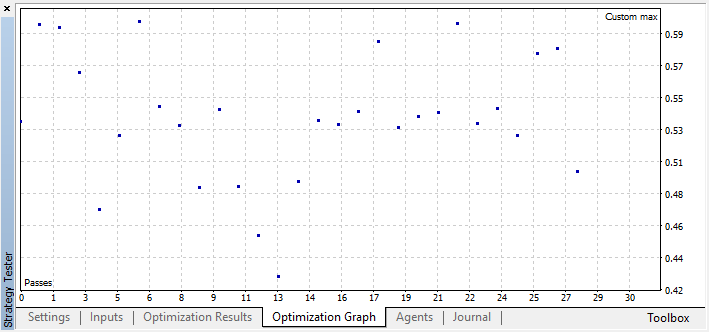
たとえば、最適モデルの1つが精度しきい値0.6を超えたため、ステップ44で最適化を停止しました。これは、テストサンプルの分類誤差が0.4を下回ったことを意味します。モデルが良くなればなるほど、エラーは少なくなりますが、遺伝的アルゴリズムを正しく動作させるためには(エラーを使用したい場合)、エラー値が逆になることを考慮する必要があります。
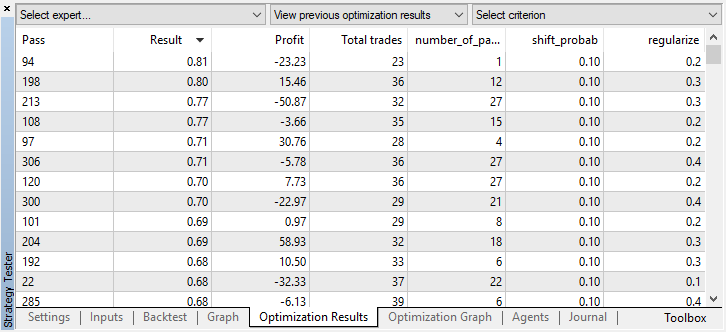
[最適化]タブで最適なモデル設定を確認して、カスタム基準の最大値で値を並べ替えることができます。
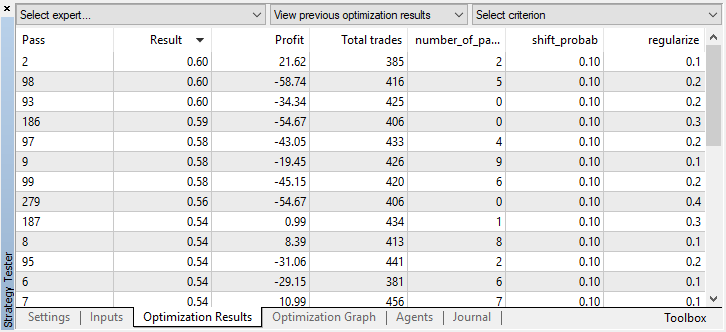
この場合、最良のモデルは0.1の確率オフセットと0.2のrパラメータで得られます(トレーニングセットはディールマトリックス全体の20%にすぎず、80%はテストサブセットです)。
最適化を停止したら、シングルテストモードをオンにします(最良のモデルがファイルに書き込まれ、それだけがロードされるため)。
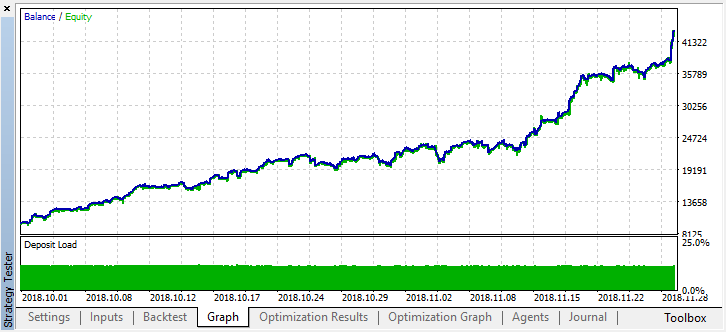
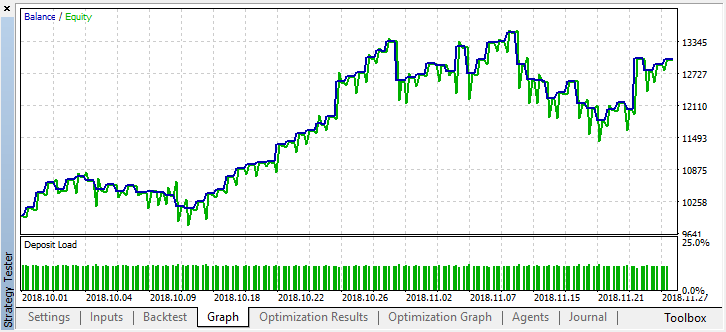
2か月前の履歴をスクロールして、モデルが4か月全体にわたってどのように機能するかを見てみましょう。
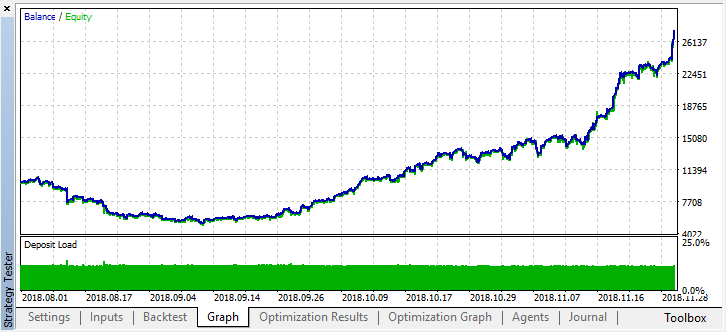
結果として得られたモデルは、8月に故障し、もう1か月(ほぼ9月全体)続いたことがわかります。'treshhold'を0.2に設定してモデルを微調整しましょう。
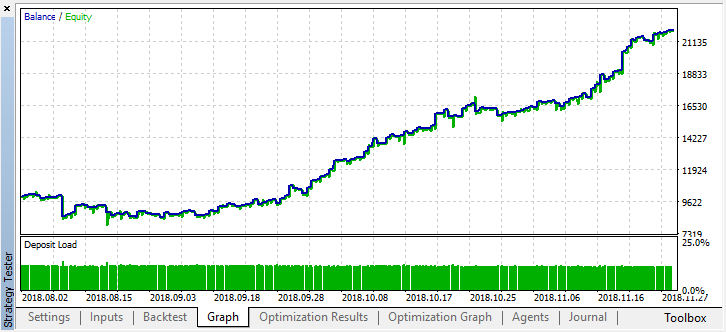
取引数の減少に伴い、モデルの精度が向上し、著しく改善されました。トレーニング期間が適切な長さであれば、これを考慮に入れれば、さらに深いテストを行うことができます。
マルチエージェントアプローチの有効性とシングルエージェントの有効性を比較するために、複数の学習者が追加されたEAのバリエーションに目を向けます。
これを行うには、エージェントのグループを作成するときに、異なるシステムのファイルが混在しないように末尾に『Multi』を追加し、ワーカーの数を指定します。たとえば、5です。
CRLAgents *ag1=new CRLAgents("RlMonteCarloMulti",5,500,number_of_best_features,50,regularize,shift_probab);
しかし、すべてのエージェントは同じであることがわかりました(それらは同じ設定を持っています)。EA初期化機能で各ワーカーを別々に設定できます。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ag1.setAgentSettings(0,500,20,50,regularize,shift_probab); ag1.setAgentSettings(1,200,15,50,regularize,shift_probab); ag1.setAgentSettings(2,100,10,50,regularize,shift_probab); ag1.setAgentSettings(3,50,5,50,regularize,shift_probab); ag1.setAgentSettings(4,25,2,50,regularize,shift_probab); return(INIT_SUCCEEDED); }
ここでは、これ以上複雑にならないようにし、エージェントの属性の数を500から25の降順に配置しました。また、最良の選択属性の数を20から2に減らしました。他の設定は変更されませんが、変更して新しい最適化パラメータを追加できます。読者自身がこのような実験を行い、この記事へのコメントで結果を共有することを願っています。。
覚えているかもしれませんが、関数の中で配列は予測子の値で埋められています。
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
ここでは、各学習者のサイズに応じて、inpVector配列に終値を入力するだけです。したがって、この場合、関数は普遍的であり、変更する必要はありません。
単一エージェントの場合とまったく同じ設定で最適化を実行します。
最良の結果は0.7を超えました。これは最初の場合よりもはるかに優れています。テスターで1回実行します。
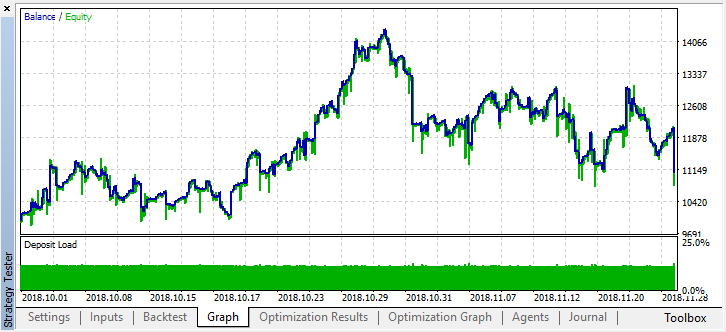
バランスグラフに反映された実際の結果はさらに悪化しました。どうしてでしょうか?ベストランのランダムトレードの数を見てみましょう。21しかありません!
これは、いくつかのエージェントのシグナルが無作為抽出により重複し、トレードの総数が減少したためです。これを修正するには、shift_probabパラメータを0.5 に設定します。この場合、個々のエージェントごとの取引数が多くなるため、合計トランザクション数も増加します。その一方で、単純に学習期間を長くすることもできますが、最初にそのようなモデルでさらに作業が可能かどうかを確認します。"treshhold"を0.2に設定して何が起こったのかを見てみましょう。
少なくとも、モデルはお金を失うことはありませんが、取引数はさらに減少しています。1回のテスト実行後に次のエラーがテスターログに表示されます。
2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo TRAIN LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.02703 0.20000 0.09091 0.05714 0.14286 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo OOB LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.21622 0.23333 0.21212 0.17143 0.19048
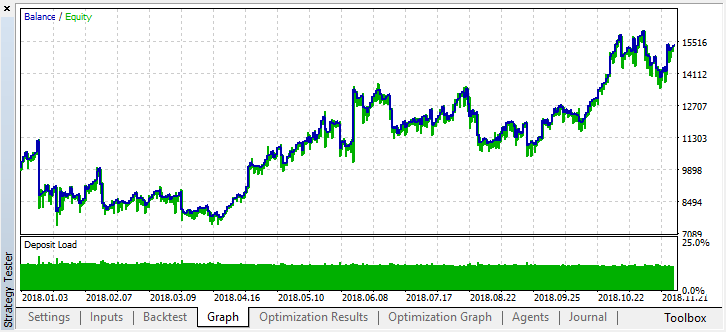
それでは、このモデルを年の初めから試してみましょう。結果はかなり安定しています。
shift_probabを0.3に設定し、M15で同じ2か月間、このパラメータなしでオプティマイザを起動します(取引量のバランスを見つけるため)。
計算の複雑さが多少増したため、オプティマイザで数回繰り返した後も、次の結果をそのまま使用することにしました。
2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti TRAIN LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.13229 0.16667 0.16262 0.14599 0.20937 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti OOB LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.45377 0.45758 0.44650 0.45693 0.46120
テストセットの誤差はかなり大きいままでしたが、しきい値が0.2の場合、モデルは4か月以内に利益を示しましたが、テストデータではかなり不安定な動作をしました。
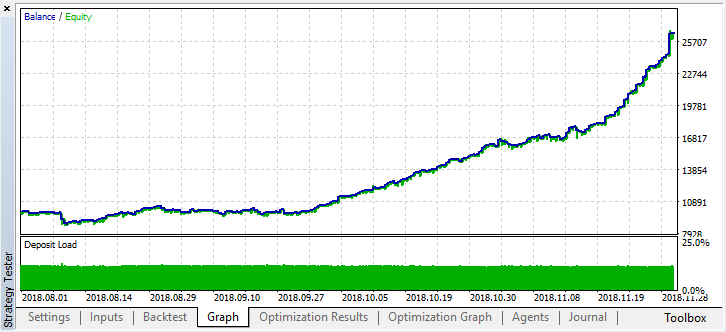
すべての学習者は同じデータ(終値)で訓練されているので、新しいデータを追加する理由はありませんでした。 とにかく、これは新しいエージェントを追加する簡単な例でした。
行われた作業からの結論
強化学習は、おそらく機械学習の最も興味深い方法の1つです。人工知能は独立して学びながら金融市場における取引問題を解決することができると考えるのは常に魅力的です。同時に、そのような『奇跡』を生み出すためには、機械学習、統計学、そして確率論に関する幅広い知識が必要です。モンテカルロ法とテストデータの最小誤差によるモデルの選択は、最初の記事で提供されたモデルを大幅に改善しました。モデルの再学習は少なくなりました。
最良のモデルは、取引数とout-of-bagセットの最小分類誤差の両方の観点から選択されるべきです。理想的には、トレーニングセットとテストセットの誤差はほぼ等しく、0.5の値に達しないようにする必要があります(例の半分は誤って予測されています)。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/4777
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
 MеtaTrader 5 チャート上の水平図
MеtaTrader 5 チャート上の水平図
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
2つ前の記事を読む
これらのメッセージが何を意味するのか明確にしていただけますか?つまり、EAを機能させるためにどのように解決すればよいのでしょうか?
これらのメッセージが何を意味するのか明確にしていただけますか?つまり、EAを機能させるために、どのように解決すればよいのでしょうか?
以前の記事で書かれていたように、クラスを宣言する前にvoidを追加する。