Нейросети в трейдинге: Модель двойного внимания для прогнозирования трендов

Введение
Цена финансового инструмента представляет собой высоко волатильный временной ряд. На нее влияют множество факторов, включая процентные ставки, инфляцию, денежно-кредитную политику и настроение инвесторов. Моделирование взаимосвязи между ценой финансового инструмента и этими факторами, а также прогнозирование их динамики представляет собой сложную задачу для исследователей и инвесторов.
Существует обширное количество исследований, посвященных прогнозированию и анализу финансовых временных рядов. Статистические методы анализа часто предполагают, что временные ряды генерируются линейными процессами, что приводит к их низкой эффективности в нелинейном прогнозировании. Методы машинного и глубокого обучения показали себя более успешными в моделировании финансовых временных рядов благодаря своей способности нелинейного отображения. Значительное количество исследований было проведено для извлечения признаков в конкретные временные моменты и их использования для моделирования и прогнозирования результатов. Однако такие подходы игнорируют взаимодействие данных и краткосрочную непрерывность колебаний.
С целью устранения указанных пробелов, в работе "A Dual-Attention-Based Stock Price Trend Prediction Model With Dual Features" был предложен метод двойного извлечения данных. Он опирается как на одиночные временные точки, так и на множественные временные моменты. Этот метод сочетает краткосрочные рыночные признаки с долгосрочными временными признаками для повышения точности прогнозирования. Предлагаемая модель основана на архитектуре "Энкодер—Декодер" и использует механизм внимания на этапах Энкодера и Декодера, что позволяет выявлять наиболее релевантные признаки в длинных временных рядах.
В указанной работе представлена новая модель прогнозирования трендов цен на акции (Trend Prediction Model — TPM), которая использует механизмы двойного извлечения признаков и двойного внимания. Цель модели TPM заключается в прогнозировании направления и продолжительности движения цен на акции. Авторы метода выделяют следующие основные вклады предложенных подходов:
- Новый метод двойного извлечения признаков, основанный на различных временных диапазонах, который эффективно извлекает важную рыночную информацию и оптимизирует результаты прогнозирования. В TPM используются метод кусочно-линейной регрессии и сверточная нейронная сеть для извлечения долгосрочных и краткосрочных рыночных признаков финансовых временных рядов, соответственно. Описание рыночной информации с помощью двойных признаков улучшает производительность модели прогнозирования.
- Модель прогнозирования тенденций цен на акции (TPM) с использованием структуры "Энкодер—Декодер" и двойного механизма внимания. Добавление механизмов внимания на этапах Энкодера и Декодера позволяет модели TPM адаптивно выбирать наиболее релевантные краткосрочные рыночные признаки и комбинировать их с долгосрочными временными признаками для повышения точности прогнозирования.
1. Алгоритм TPM
Проведя анализ существующих методов прогнозирования временных рядов, авторы алгоритма TPM пришли к следующим выводам:
- Одномерный финансовый временной ряд содержит недостаточно информации для прогнозирования предстоящего ценового движения с необходимой долей уверенности.
- Традиционные методы извлечения признаков ограничены в изучении рыночного поведения.
- Изучение временного ряда с помощью одной нейронной сети является неполным.
В методе TPM указанные проблемы решаются использованием механизмов двойного извлечения признаков и двойного внимания. Предложенный алгоритм включает 2 фазы. Сначала используется метод кусочно-линейной регрессии для сегментирования финансового временного ряда и извлечения исторических долгосрочных временных признаков на основе подпоследовательностей с различными временными интервалами. А краткосрочные пространственные рыночные признаки на основе каждой временной точки генерируются с помощью сверточной нейронной сети.
Затем, во второй фазе TPM, извлеченные ранее двойные признаки анализируются модель прогнозирования трендов, основанной на двойном механизме внимания. Предложенная модель построена на архитектуре Энкодер—Декодер.
Энкодер построен на базе рекуррентного LSTM-блока с добавлением механизма внимания, который применяется для адаптивного извлечения наиболее релевантных краткосрочных рыночных признаков.
Декодер так же строится с использованием LSTM-блока и механизма внимания, который выбирает и декодирует наиболее релевантные комбинированные признаки для прогнозирования тренда цен на акции.
Поскольку информация, предоставляемая одномерным финансовым временным рядом, недостаточна, сложно моделировать и прогнозировать тренд цен на акции на основе таких данных. Авторы метода TPM используют для анализа базовые рыночные данные, такие как цены открытия и закрытия бара, максимальная и минимальная цены, объем. И преобразуют их в ряд технических индикаторов.
Учитывая непрерывность изменений данных, TPM извлекает долгосрочные временные признаки с помощью метода кусочно-линейной регрессии (PLR). Метод PLR сглаживает шум краткосрочных колебаний, уменьшает размерность данных и повышать вычислительную производительность.
Очевидно, что результат сегментации временного ряда зависит от максимального порога ошибки δ. Взяв данные CSI 300 в качестве примера, авторы метода используют метод PLR для сегментации его исторической цены закрытия. При значении порога δ равном 2.0, временной ряд можно разделить на 16 подпоследовательностей. Однако при значении порога δ равно 4.0 тот же временной ряд можно сегментировать только на 4 подпоследовательности. Следовательно, с увеличением значения порога игнорируется больше колебаний данных и формируется меньшее количество подпоследовательностей. Значение порога влияет на достоверность признаков исторического временного ряда. Каждая подпоследовательность представляет собой колебание данных за определенный период времени. Наклон sm и продолжительность dm каждой подпоследовательности генерируются как долгосрочные временные признаки для прогнозирования тренда цен на акции.
Учитывая взаимодействие различных данных в один и тот же момент времени, краткосрочные пространственные рыночные признаки каждого временного шага извлекаются с помощью сверточной нейронной сети (CNN). Для анализируемого финансового временного ряда строится рыночная матрицу, которая описывает фондовый рынок. В рыночной матрице каждая строка представляет одно измерение анализируемых данных, и количество строк равно n. Тогда каждая колонка представляет собой одну временную точку. Поскольку CNN сохраняет соседские отношения и пространственную локализацию исходных данных, она может захватывать нелинейную связь между рыночной матрицей и трендом акций. И выводить пространственные признаки краткосрочного исторического временного ряда.
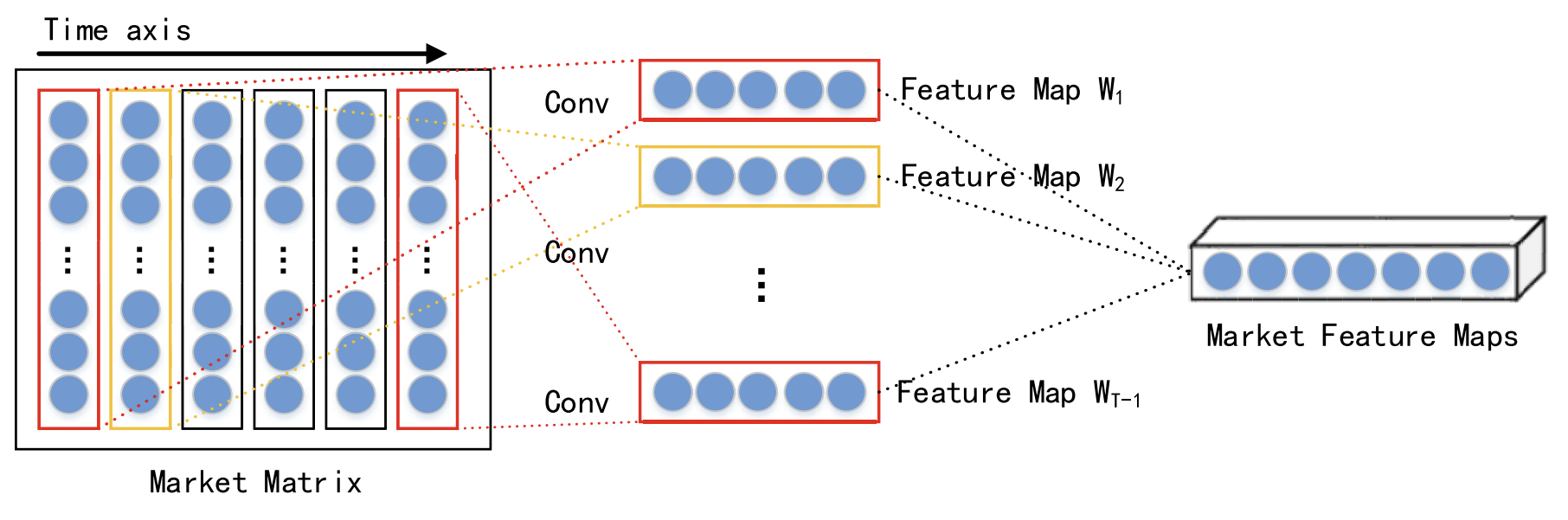
Авторы метода в своей работе выбираются свертки различного размера, такие как 1 × 3 и 1 × 5, для извлечения абстрактных многоуровневых пространственных рыночных признаков. Нелинейная функция активации, выбранная в виде функции ReLU.
После слоев свертки выполняется слой максимального объединения (max pooling), который уменьшает размер карт признаков и предотвращает переобучение.
Результаты работы несколько слоев свертки и максимального объединения передаются в проекционный слой.
Как уже было сказано выше, извлеченные краткосрочные и долгосрочные признаки обрабатываются моделью с использование структуры Энкодер—Декодер. В рамках этой структуры Энкодер сжимает исходную информацию в вектор фиксированного размера, а Декодер обрабатывает эти векторы для получения конечного результата. Однако, когда исходной информации слишком много, Энкодер не может эффективно идентифицировать всю релевантную информацию, что приводит к ухудшению производительности модели. Механизм внимания может оптимизировать эту проблему, декодируя скрытое состояние соответствующих нейронов.
Очевидно, что у Декодера с механизмом внимания есть проблема — он не может явно выбирать релевантные исходные данные, поэтому авторы метода TPM добавляют механизм внимания как на этапе Энкодера, так и на этапе Декодера.
Вторая фаза алгоритма TPM основывается на двойном механизме внимания. Структура Энкодер—Декодер делится на два этапа. На первом этапе в Энкодере на основе LSTM с механизмом внимания анализируются краткосрочные пространственные рыночные признаки, извлеченные с помощью CNN. Соответствующие краткосрочные признаки в каждой временной точке выбираются адаптивно и кодируются в векторы.
На втором этапе закодированные векторы и долгосрочные временные признаки, извлеченные с помощью PLR, подаются в Декодер на основе LSTM, который декодирует соответствующие векторы и признаки на основе механизма внимания для предсказания тренда фондового рынка. Благодаря двойному механизму внимания TPM может адаптивно выбирать наиболее релевантные пространственные рыночные и временные признаки для моделирования и прогнозирования тренда.
В каждой временной точке t Энкодер изучает взаимосвязь между исходным признаком Wt и скрытым состоянием Ht:
![]()
где Ht — скрытое состояние Энкодера в момент времени t, fen(•) — нелинейная функция, а ʘen обозначает параметры Энкодера.
Авторы метода используют LSTM в качестве нелинейной функции fen для захвата временных зависимостей и формирования Энкодера краткосрочных признаков. LSTM способна эффективно моделировать динамическое временное поведение временных рядов и избегать проблем затухания или взрыва градиентов в RNN.
Авторы метода вводят механизм внимания на этапе Энкодера и делят исходные признаки WMarket в соответствии с размерностью признаков m. Скрытое состояние Ht-1 и состояние ячейки (контекст) Ct-1, рассчитанные в момент времени t-1, соответствующие размерности исходных признаков идентифицируются и используются для обновления исходных признаков в следующий момент времени t.
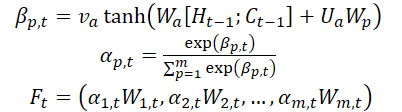
где va, Wa и Ua — параметры, функция SoftMax используется для расчета важности αm,t каждой размерности признака.
Все размерности Wt обновляются до Ft и вводятся в Энкодер. После чего обновляется скрытое состояние временной точки t.
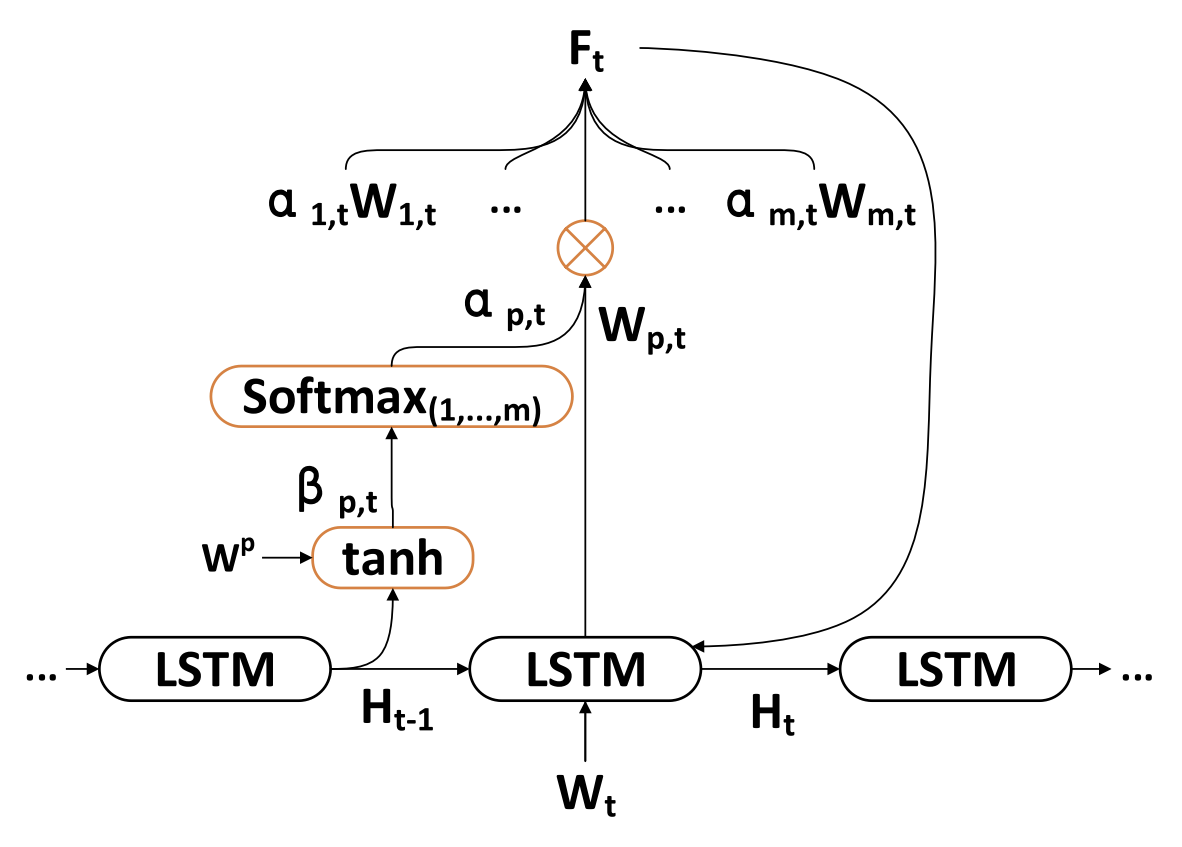
Таким образом, в каждый момент времени t мы можем выбирать релевантные размерности пространственных рыночных признаков. Последовательно обновлять исходные признаки и скрытое состояние Энкодера. И генерировать наиболее релевантный вектор кодирования краткосрочных признаков.
Декодер представляет собой LSTM-блок для прогнозирования тренда фондового рынка. Долгосрочные временные признаки ZT-1, извлеченные методом PLR.
В каждый момент времени t Декодер изучает взаимосвязь между вектором кодирования Wt, долгосрочным признаком Lt и скрытым состоянием Ht:
![]()
где H't — скрытое состояние Декодера в момент времени t, fde(•) — нелинейная функция, а ʘde обозначает параметры декодера.
Авторы TPM используют LSTM в качестве нелинейной функции fde для захвата временных зависимостей и формирования Декодера долгосрочных признаков. Процедура вычисления аналогична этапу Энкодера.
Авторы TPM вводят механизм внимания на этапе Декодера для получения связанных скрытых состояний Энкодера всех временных точек.
Контекстный вектор, который подается на Декодер, получается через все скрытые состояния Энкодера.
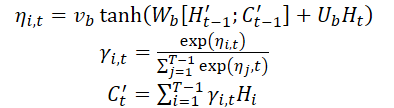
После получения контекстного вектора C't, он комбинируется с долгосрочными временными признаками Lt для генерации смешанного признака yt:
![]()
С помощью вышеописанных формул, в каждый момент времени t выбираются наиболее релевантные скрытые состояния Энкодера всех временных точек и долгосрочные временные признаки для генерации смешанных векторов признаков.
После чего изучаем нелинейную отображающую функцию F(•) между трендом фондового рынка и двойными признаками. В итоге мы используем линейную функцию для получения прогноза тренда фондового рынка в момент времени T.
Для обучения модели использовали метод стохастического градиентного спуска и оптимизатор с импульсом. Размером пакета обучения 64 и скоростью обучения 0.001.
В качестве функции потерь используется квадратичная функция ошибки с членами регуляризации.
Авторская визуализация метода TPM представлена ниже.
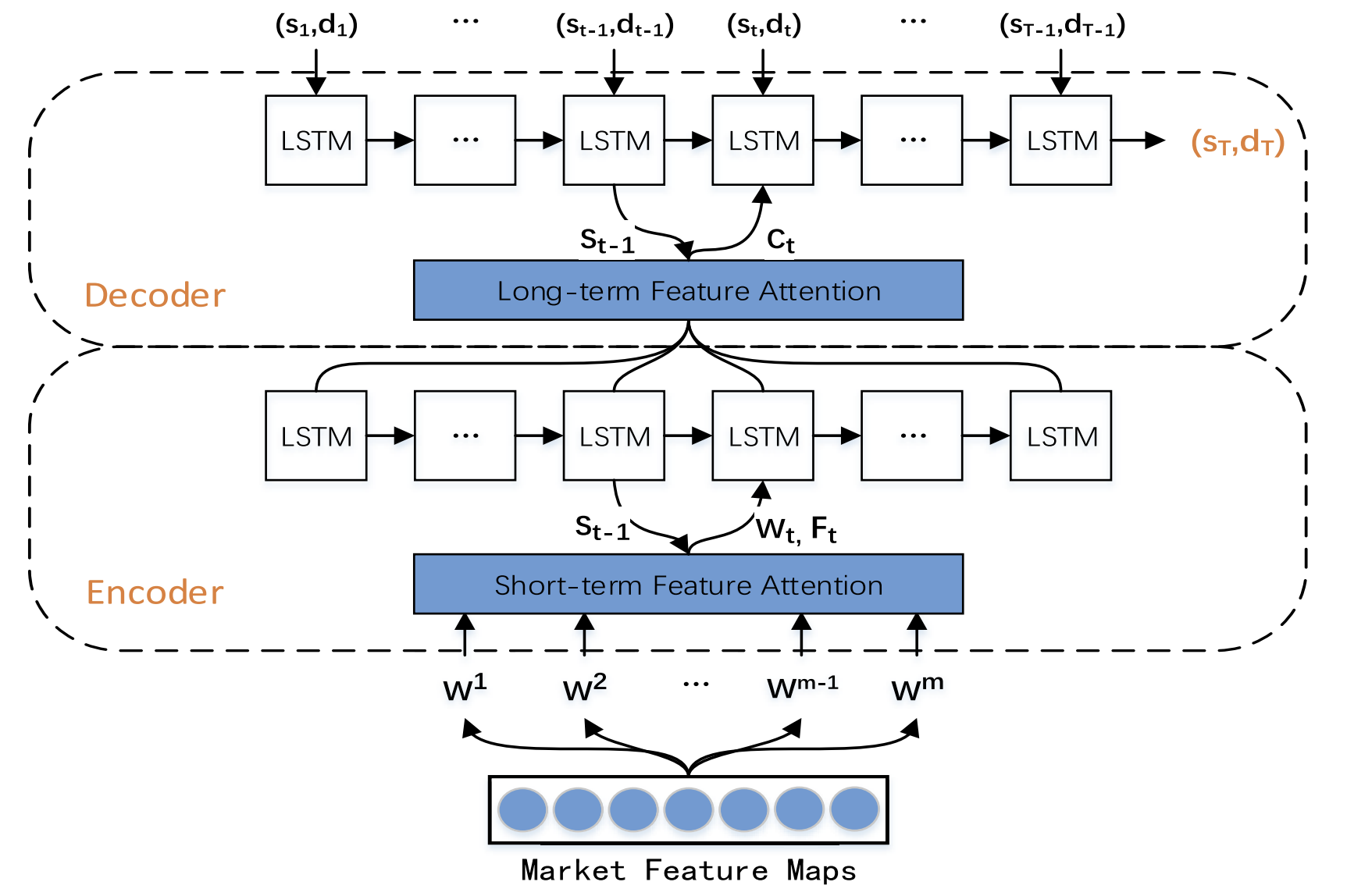
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов предложенного метода TPM мы переходим к практической части нашей работы, в которой мы реализуем свое видение предложенных подходов. Как обычно, в своей реализации мы сохраняем общую концепцию предложенного подхода, но допускаем некоторые отклонения в деталях реализации. Конечно, это может в разной степени отразится на конечных результатах работы модели.
И начнем мы свою работу с построения Энкодера.
2.1 Энкодер TPM
Энкодер нашей модели мы реализуем в классе CNeuronTPMEncoder, который унаследует базовый функционал от ранее созданного LSTM-блока CNeuronLSTMOCL. Выбор родительского класса не случаен. Ведь, как Вы помните, Энкодер метода TPM построен на основе LSTM-блока с добавлением механизмов внимания.
Кроме того, в своей реализации мы решили включить извлечение краткосрочных признаков непосредственно в Энкодер. А извлекать признаки мы будем при помощи ранее созданного блока создания пирамидальной структуры данных CSCM. Но есть один нюанс: ранее с помощью CSCM-блока мы извлекали признаки унитарных временных рядов. Сейчас же нам предстоит немного изменить поток данных для извлечения признаком отдельных временных точек.
В целом структура Энкодера представлена ниже.
class CNeuronTPMEncoder : public CNeuronLSTMOCL { protected: bool bTSinRow; //--- CNeuronCSCMOCL cFeatureExtraction; CNeuronBaseOCL cMemAndHidden; CNeuronConcatenate cConcatenated; CNeuronSoftMaxOCL cSoftMax; CNeuronBaseOCL cAttentionOut; CNeuronTransposeOCL cTranspose; CBufferFloat cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronTPMEncoder(void){}; ~CNeuronTPMEncoder(void){}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint lenth, uint hidden_size, bool ts_in_row, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronTPMEncoder; } virtual void SetOpenCL(COpenCLMy *obj); };
Здесь мы видим уже привычный набор переопределяемых методов и несколько вложенных объектов, с назначением которых мы познакомимся в процессе реализации.
Как и ранее, все вложенные объекты мы объявляем статическими, что позволяет нам оставить "пустыми" конструктор и деструктор класса. Непосредственно инициализация экземпляра нашего нового класса осуществляется в методе Init.
bool CNeuronTPMEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint lenth, uint hidden_size, bool ts_in_row, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronLSTMOCL::Init(numOutputs, myIndex, open_cl, hidden_size, optimization_type, batch)) return false; if(!SetInputs(variables * lenth)) return false;
В параметрах данный метод получает основные параметры создаваемого объекта. В данном случае их 3:
- variables — количество унитарных последовательностей в анализируемом мультимодальном временном ряде;
- lenth — размер анализируемой последовательности (глубина истории);
- hidden_size — размер скрытого пространства LSTM-блока.
Кроме того, мы добавили флаг ts_in_row, который свидетельствует о расположении отдельных унитарных последовательностей в строках тензора исходных данных.
В теле метода мы вызываем одноименный метод родительского класса, в котором осуществлен минимально-необходимый блок контроля параметров создаваемого слоя и инициализация унаследованных объектов.
Тут же мы передаем размер тензора исходных данных родительского класса, который равен произведению размера унитарной последовательности на количество таких последовательностей в исходных данных.
Здесь стоит обратить внимание, что внутри LSTM-блока мы использовали полносвязные слои и тензора исходных данных в данном случае не имеет значения.
Следующим шагом мы инициализируем блок извлечения краткосрочных признаков.
uint windows[] = {variables, 6, 5, 4}; if(!cFeatureExtraction.Init(0, 0, OpenCL, windows, lenth, variables, ts_in_row, optimization, batch)) return false;
Для этого мы сначала зададим размеры окно сверточных слоев извлечения признаков и вызовем метод инициализации CSCM-блока.
Обратите внимание, что при вызове метода инициализации CSCM-блока мы переставили параметры размера унитарных последовательностей и их количества. Что обусловлено необходимостью извлечения признаков из отдельных временных шагов (баров), а не унитарных последовательностей, как предусмотрено методом MSFformer.
Следующим этапом мы перейдем к инициализации вложенных объектов блока внимания. Здесь мы сначала создадим слой, в буферах которого мы конкатенируем скрытое состояние и контекст LSTM-блока на предыдущем шаге.
if(!cMemAndHidden.Init(0, 1, OpenCL, hidden_size * 2, optimization, batch)) return false;
Для вычисления коэффициентов важности отдельных признаков мы воспользуемся слоем конкатенации, результаты которого нормализуем функцией SoftMax.
if(!cConcatenated.Init(0, 2, OpenCL, variables * lenth, variables * lenth, hidden_size * 2, optimization, batch)) return false; cConcatenated.SetActivationFunction(TANH); if(!cSoftMax.Init(0, 3, OpenCL, variables * lenth, optimization, batch)) return false; cSoftMax.SetHeads(variables);
Обратите внимание, что на данном этапе нормализация данных осуществляется в рамках унитарных последовательностей.
И добавим слой для записи результатов внимания.
if(!cAttentionOut.Init(0, 4, OpenCL, variables * lenth, optimization, batch)) return false;
При необходимости мы инициализируем слой транспонирования данных.
bTSinRow = ts_in_row; if(!bTSinRow) { if(!cTranspose.Init(0, 5, OpenCL, variables, lenth, optimization, iBatch)) return false; }
И добавим вспомогательный буфер записи промежуточных значений.
//--- if(!cTemp.BufferInit(variables * lenth, 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
После успешной инициализации всех вложенных объектов мы передаем логический результат выполненных операций вызывающей программе и завершаем работу метода.
Завершив работу по инициализации объекта, мы переходим к построению алгоритма прямого прохода нового класса, который мы реализуем в методе feedForward.
bool CNeuronTPMEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- FEATURE EXTRACTION if(!cFeatureExtraction.FeedForward(NeuronOCL)) return false;
Как обычно, в параметрах данного метода мы получаем указатель на объект предшествующего нейронного слоя. Но в данном случае мы не проверяем полученный указатель, а передаем его в метод прямого прохода внутреннего слоя извлечения краткосрочных признаков. В теле вызываемого метода уже реализован контроль полученного указателя.
Следующим этапом мы объединим скрытое состояние и контекст нашего объекта, которые сохранились после предыдущего прямого прохода.
//--- Memory and Hidden if(!Concat(m_iHiddenState, m_iMemory, m_iHiddenState, m_iMemory, cMemAndHidden.getOutputIndex(), 1, 1, 0, 0, Neurons())) return false;
На этом мы завершаем подготовительную работу и переходим к блоку внимания. В котором мы рассчитаем коэффициенты важности отдельных признаков.
if(!cConcatenated.FeedForward(cFeatureExtraction.AsObject(), cMemAndHidden.getOutput())) return false; if(!cSoftMax.FeedForward(cConcatenated.AsObject())) return false; int map = cSoftMax.getOutputIndex();
При необходимости, транспонируем тензор коэффициентов важности.
if(!bTSinRow) { if(!cTranspose.FeedForward(cSoftMax.AsObject())) return false; map = cTranspose.getOutputIndex(); }
И осуществим поэлементное умножение полученных коэффициентов на соответствующие краткосрочные признаки. Для поэлементного умножения 2 тензоров мы воспользуемся кернелом прямого прохода слоя Dropout.
Напомню, что данный кернел мы создавали для умножения исходных данных на маску исключения нейронов. В данном случае, в качестве маски мы используем коэффициенты важности.
Определим размерность пространства задач.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = int(cSoftMax.Neurons() + 3) / 4;
Передадим параметры кернелу.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_input, cFeatureExtraction.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_map, map)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_out, cAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Dropout, def_k_dout_dimension, cSoftMax.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И поставим его в очередь выполнения.
if(!OpenCL.Execute(def_k_Dropout, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
После выполнения кернела в буфере слоя cAttentionOut мы получаем краткосрочные признаки с учетом их коэффициента важности. Теперь мы можем воспользоваться базовым функционалом LSTM-блока для представления тензора признаков на выходе нашего Энкодера.
//--- LSTM if(!CNeuronLSTMOCL::feedForward(cAttentionOut.AsObject())) return false; //--- return true; }
Не забываем на каждом этапе контролировать процесс выполнения операций. А после успешного их выполнения мы передаем логический результат их выполнения вызывающей программе и завершаем работу метода.
После реализации алгоритмов прямого прохода мы, обычно, переходим к построению методов обратного прохода. И данный класс не является исключением. Следующим этапом мы реализуем метод распределения градиента ошибки до всех вложенных объектов и тензора исходных данных в соответствии с их влиянием на конечный результат работы модели. Указанный функционал мы реализуем в методе calcInputGradients.
В параметрах данному методу, аналогично рассмотренному выше, мы получаем указатель на объект предыдущего нейронного слоя.
bool CNeuronTPMEncoder::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
И в теле метода мы сразу проверяем актуальность полученного указателя.
Затем, воспользовавшись унаследованным функционалом, мы проведем градиент ошибки через алгоритм LSTM-блока до уровня результатов нашего блока внимания.
if(!CNeuronLSTMOCL::calcInputGradients(cAttentionOut.AsObject())) return false;
После чего распределим градиент ошибки по 2 направлениям: коэффициенты важности признаков и сами признаки. Алгоритм постановки кернела в очередь аналогичен рассмотренному выше.
//--- uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = cSoftMax.Neurons(); ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_f, cFeatureExtraction.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_fg, cTemp.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_s, (bTSinRow ? cSoftMax.getOutputIndex() : cTranspose.getOutputIndex()))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_sg, (bTSinRow ? cSoftMax.getGradientIndex() : cTranspose.getGradientIndex()))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_g, cAttentionOut.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CGConv_HiddenGradient, def_k_cgc_activationf, NeuronOCL.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CGConv_HiddenGradient, def_k_cgc_activations, int(None))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_CGConv_HiddenGradient, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Но здесь следует обратить внимание на 2 момента. Во-первых, буфер распределения градиентов ошибки коэффициентов внимания зависит от необходимости использования слоя транспонирования коэффициентов важности. А во-вторых, сами краткосрочные признаки мы используем как при умножении на коэффициенты важности, так и при расчете этих коэффициентов. Поэтому на данном этапе градиент ошибки краткосрочных признаков мы пока сохраним во временном буфере данных.
Следующим этапом мы, при необходимости, транспонируем градиент ошибки коэффициентов важности отдельных признаков.
if(bTSinRow) { if(!cSoftMax.calcHiddenGradients(cTranspose.AsObject())) return false; }
После чего проведем градиент ошибки через алгоритм блока внимания до уровня краткосрочных признаков.
if(!cConcatenated.calcHiddenGradients((CObject*)cSoftMax.AsObject(),(CBufferFloat *)NULL,(CBufferFloat *)NULL) || !DeActivation(cConcatenated.getOutput(), cConcatenated.getGradient(), cConcatenated.getGradient(), cConcatenated.Activation())) return false; if(!cFeatureExtraction.calcHiddenGradients(cConcatenated.AsObject(), cMemAndHidden.getOutput(), cMemAndHidden.getGradient())) return false;
И суммируем градиент ошибки на уровне краткосрочных признаков из 2 потоков информации.
if(!DeActivation(cFeatureExtraction.getOutput(), GetPointer(cTemp), GetPointer(cTemp), NeuronOCL.Activation()) || !SumAndNormilize(cFeatureExtraction.getGradient(), GetPointer(cTemp), cFeatureExtraction.getGradient(), 1, false)) return false;
В завершении работы метода мы опустим градиент ошибки до уровня предыдущего слоя и передадим логический результат выполнения операций вызывающей программе.
if(!NeuronOCL.calcHiddenGradients(cFeatureExtraction.AsObject())) return false; //--- return true; }
После распределения градиента ошибки нам остается оптимизировать параметры модели в сторону минимизации общей ошибки. Данный функционал мы выполняем в методе updateInputWeights, путем вызова одноименных методов вложенных объектов, которые содержат обучаемые параметры.
bool CNeuronTPMEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronLSTMOCL::updateInputWeights(cAttentionOut.AsObject())) return false; if(!cFeatureExtraction.UpdateInputWeights(NeuronOCL)) return false; if(!cConcatenated.UpdateInputWeights(cFeatureExtraction.AsObject(), cMemAndHidden.getOutput())) return false; //--- return true; }
На этом мы завершаем рассмотрение алгоритмов реализации основного функционала класса нашего Энкодера. А с полным кодом всех методов данного класса Вы можете самостоятельно ознакомиться во вложении. Там же вы найдете полный код всех программ, используемых при подготовке данной статьи.
2.2 Декодер TPM
После реализации алгоритмов Энкодера TPM мы переходим ко второму этапу — построению Декодера. Думаю, при ознакомлении с теоретическими аспектами метода TPM Вы заметили большое сходство в построении алгоритмов Энкодера и Декодера. Однако, наличие даже незначительных отличий требует построение нового класса.
Аналогично Энкодеру, новый класс нашего Декодера CNeuronTPM мы наследуем от класса LSTM-блока. Структура нового класса представлена ниже.
class CNeuronTPM : public CNeuronLSTMOCL { protected: CNeuronTPMEncoder cEncoder; CNeuronPLROCL cFeatureExtraction; CNeuronBaseOCL cMemAndHidden; CNeuronConcatenate cConcatenated; CNeuronSoftMaxOCL cSoftMax; CNeuronBaseOCL cAttentionOut; CNeuronConcatenate cAttAndFeature; CBufferFloat cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronTPM(void){}; ~CNeuronTPM(void){}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint lenth, uint hidden_size, bool ts_in_row, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronTPM; } virtual void SetOpenCL(COpenCLMy *obj); };
Здесь легко заметить сходство с рассмотренным выше классом Энкодера. Добавлено лишь 2 вложенных объекта. И можно заметить изменение типа слоя извлечения признаков — в Декодера используем PLR для извлечения долгосрочных признаков.
Думаю, вы заметили, что класс Энкодера содержит указание на принадлежность, но этого нет в Декодере. На то есть причины. Энкодер и Декодер используют исходные данные для извлечения признаков разного уровня. И чтобы не усложнять структуру модели на верхнем уровне, было принято решение объединить Энкодер и Декодер в один блок. Выше построенный класс Энкодера мы добавили внутренним слоем в новый класс, тем самым объединив алгоритм TPM в рамках текущего класса. О чем и свидетельствует его наименование CNeuronTPM.
Параметры метода инициализации нового класса полностью идентичны рассмотренному выше методу инициализации Энкодера.
bool CNeuronTPM::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint lenth, uint hidden_size, bool ts_in_row, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronLSTMOCL::Init(numOutputs, myIndex, open_cl, hidden_size, optimization_type, batch)) return false; if(!SetInputs(hidden_size)) return false;
В теле метода мы так же вызываем метод инициализации родительского класса, только размер тензора его исходных данных уже соответствует размеру скрытого состояния Энкодера. Ведь на вход декодера мы подаем взвешенный вектор признаков, полученных от Энкодера.
Тут же мы инициализируем объект Энкодера.
if(!cEncoder.Init(0, 0, OpenCL, variables, lenth, hidden_size, ts_in_row, optimization, iBatch)) return false;
И слой извлечения признаков.
if(!cFeatureExtraction.Init(0, 1, OpenCL, variables, lenth, !ts_in_row, optimization, iBatch)) return false;
Дальнейший алгоритм инициализации объектов блока внимания напомнит аналогичные операции при инициализации Энкодера, но есть отличия в размерах тензоров исходных данных.
if(!cMemAndHidden.Init(0, 2, OpenCL, hidden_size * 2, optimization, iBatch)) return false; if(!cConcatenated.Init(0, 3, OpenCL, hidden_size, hidden_size, hidden_size * 2, optimization, iBatch)) return false; cConcatenated.SetActivationFunction(TANH); if(!cSoftMax.Init(0, 4, OpenCL, hidden_size, optimization, iBatch)) return false; cSoftMax.SetHeads(1); if(!cAttentionOut.Init(0, 5, OpenCL, hidden_size, optimization, iBatch)) return false;
Как уже говорилось ранее, в LSTM-блоке мы используем полносвязные слои. Поэтому, тензор краткосрочных признаков, полученных от Энкодера можно считать "обезличенным" в контексте унитарных последовательностей анализируемого исходного мультимодального временного ряда. Это позволяет нам осуществлять нормализацию коэффициентов важности в целом по всему тензору. И на данном этапе нам не важна ориентация тензора исходных данных.
Добавим слой проекции взвешенных краткосрочных и долгосрочных признаков анализируемого временного ряда, который мы и будем подавать на вход LSTM-блока.
if(!cAttAndFeature.Init(0, 6, OpenCL, hidden_size, hidden_size, variables * lenth, optimization, iBatch)) return false;
В завершении операций инициализации класса мы добавим буфер хранения временных данных.
if(!cTemp.BufferInit(variables * lenth, 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
Логический результат инициализации вложенных объектов мы возвращаем вызывающей программе.
После инициализации вложенных объектов мы переходим к реализации алгоритма прямого прохода в методе feedForward. Аналогично другим одноименным методам, в параметрах мы получаем указатель на объект предшествующего нейронного слоя.
bool CNeuronTPM::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Encoder if(!cEncoder.FeedForward(NeuronOCL)) return false;
И тут же поученный указатель мы передаем в метод прямого прохода нашего Энкодера.
Далее мы передадим тот же указатель для извлечения долгосрочных признаков анализируемого временного ряда.
//--- FEATURE EXTRACTION if(!cFeatureExtraction.FeedForward(NeuronOCL)) return false;
Работа блока внимания аналогична рассмотренному выше такому же блоку Энкодера.
//--- Memory and Hidden if(!Concat(m_iHiddenState, m_iMemory, m_iHiddenState, m_iMemory, cMemAndHidden.getOutputIndex(), 1, 1, 0, 0, Neurons())) return false; //--- Attention if(!cConcatenated.FeedForward(cEncoder.AsObject(), cMemAndHidden.getOutput())) return false; if(!cSoftMax.FeedForward(cConcatenated.AsObject())) return false;
Умножим коэффициенты важности на вектор краткосрочных признаков Энкодера.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = int(cSoftMax.Neurons() + 3) / 4; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_input, cEncoder.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_map, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_out, cAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Dropout, def_k_dout_dimension, cSoftMax.Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_Dropout, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Взвешенный вектор краткосрочных признаков мы объединяем с долгосрочными признаками в слое конкатенации.
//--- Attention and Features if(!cAttAndFeature.FeedForward(cAttentionOut.AsObject(), cFeatureExtraction.getOutput())) return false;
Подготовленные таким образом данные мы подаем на вход LSTM-блока.
//--- LSTM if(!CNeuronLSTMOCL::feedForward(cAttAndFeature.AsObject())) return false; //--- return true; }
Проверяем логический результат выполнения операций и возвращаем его вызывающей программе.
Далее мы обычно переходим к построению методов обратного прохода. Но я думаю, что Вы заметили сходство методов прямого прохода Энкодера и Декодера. Конечно, есть нюансы. Подобные нюансы есть и в методах обратного прохода. Однако в целом алгоритмы довольно схожи. И я предлагаю вам самостоятельно ознакомиться с ними во вложении.
2.3 Архитектура обучаемых моделей
Выше мы рассмотрели алгоритмы реализации метода TPM средствами MQL5. Данный метод был разработан для прогнозирования тенденций ценового движения акций. И вполне естественно, что мы внедрим его в наш Энкодер состояния окружающей среды, архитектура которого представлена в методе CreateEncoderDescriptions.
В параметрах метод получает указатель на динамический массив, в котором мы сохраним заложенную архитектуру модели.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы получаем актуальность полученного указателя и, при необходимости, создаем новый экземпляр объекта динамического массива.
На вход модели мы, как обычно, подаем не обработанные данные описания состояния окружающей среды. Для записи исходных данных мы используем базовый полносвязный слой, размер которого должен быть достаточным для записи анализируемого тензора.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полученные исходные данные проходят первичную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И затем мы передадим подготовленные данные в наш TPM-модуль.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTPM; descr.count = LatentCount; descr.window = BarDescr; descr.window_out = HistoryBars; descr.step = int(false); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полученные из TPM-модуля данные проходят через 3 слойный MLP, на выходе которого мы ожидаем получить прогнозные значения анализируемого временного ряда.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = BarDescr * NForecast; descr.optimization = ADAM; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
К прогнозным значениям мы добавим статистические показатели исходного временного ряда, которые были ранее удалены в слое пакетной нормализации.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
И согласуем полученные прогнозные результаты в частотном представлении.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Модели Актера и Критика были перенесены из предыдущих работ без изменений. И вы можете самостоятельно с ними ознакомиться во вложении.
2.4 Советники обучения моделей
При обучении моделей нам следует обратить внимание на особенности обучения рекуррентных моделей. Как вы знаете, основной особенностью рекуррентных моделей является чувствительность к последовательности подачи исходных данных. Следовательно, в процессе обучения модели нам необходимо использовать данные из обучающей выборки с соблюдением их исторической последовательности. С другой стороны, такой подход снижает эффективность обучения большинства моделей, так как способствует переобучению в рамках малых временных отрезков с неспособностью обобщения на весь обучающей период.
Для минимизации негативного влияния упомянутых факторов мы в процессе обучения будем случайным образом извлекать из буфера воспроизведения опыта небольшие подвыборки с соблюдением исторической последовательности для обучения модели. После чего сэмплировать новый пакет обучения. Рассмотрим реализацию предложенного подхода на примере метода обучения Энкодера состояния окружающей среды (советник "...\Experts\TPM\StudyEncoder.mq5").
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
В теле метода мы сначала генерируем вектор вероятностей выбора проходов из обучающей выборки, ранжированный по доходности проходов. После чего мы объявляем необходимые локальные переменные.
vector<float> result, target, state; bool Stop = false;
Тут же мы добавляем переменную с указанием размера пакета обучения одной подвыборки.
int Batch = 100;
Далее мы организовываем систему вложенных циклов. В рамках внешнего цикла мы сэмплируем траекторию из обучающей выборки и состояние начала обучающей подвыборки на выбранной траектории.
uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int st = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(st <= 0) { iter -= Batch; continue; }
Очистим буферы скрытого состояния и контекста LSTM-блока.
Encoder.Clear();
После чего мы организуем вложенный цикл последовательного перебора состояний в их исторической последовательности от выбранного состояния окружающей среды.
for(int i = st; (i < MathMin(st + Batch, Buffer[tr].Total - NForecast) && !IsStopped() && !Stop); i++) { state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum() == 0) { iter += i - st - Batch; break; } bState.AssignArray(state);
В теле вложенного цикла мы перенесем анализируемое состояние окружающей среды в буфер данных. По полученным данным спрогнозируем последующую траекторию ценового движения.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Затем мы загрузим целевые значения последующей траектории из буфера воспроизведения опыта.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
И проверим точность наши прогнозов. В рамках обратного прохода скорректируем параметры модели в сторону минимизации ошибки прогнозирования последующего движения.
if(!Encoder.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Проинформируем пользователя о ходе процесса обучения и прейдем к следующей итерации системы циклов.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - st) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После успешного выполнения всех итераций системы циклов мы очищаем поле комментариев на графике инструмента. Выводим результаты обучения в журнал терминала и инициализируем завершение работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
В советник обучения моделей Актера и Критика были внесены аналогичные правки. Несмотря на то, что в указанные модели не были добавлены рекуррентные блоки, внесение данных правок необходимо для организации корректной работы Энкодера состояния окружающей среды. Ведь и Актер, и Критик используют их в качестве исходных данных.
С полным кодом советников обучения моделей вы можете самостоятельно ознакомиться во вложении. Там же вы можете найти полный код всех программ, классов и их методов, используемых при подготовке данной статьи.
3. Тестирование
В данной статье мы познакомились с методом прогнозирования предстоящих траекторий акций TPM и реализовали своё видение предложенных подходов. И теперь пришло время проверить результаты нашей работы на реальных данных. Как всегда, мы обучим представленные модели на реальных исторических данных инструмента EURUSD таймфрейма H1 за 2023 год.
Вначале мы обучаем модель Энкодера состояния окружающей среды. Данная модель анализирует только исторические данные ценового движения без оценки действий Актера. Это позволяет нам полностью обучить модель на первичной обучающей выборки без необходимости её обновления. И здесь можно сказать, что модель обучается достаточно быстро и показала не плохие результаты. Ниже представлен график сравнения прогнозной и реальной траектории ценового движения.
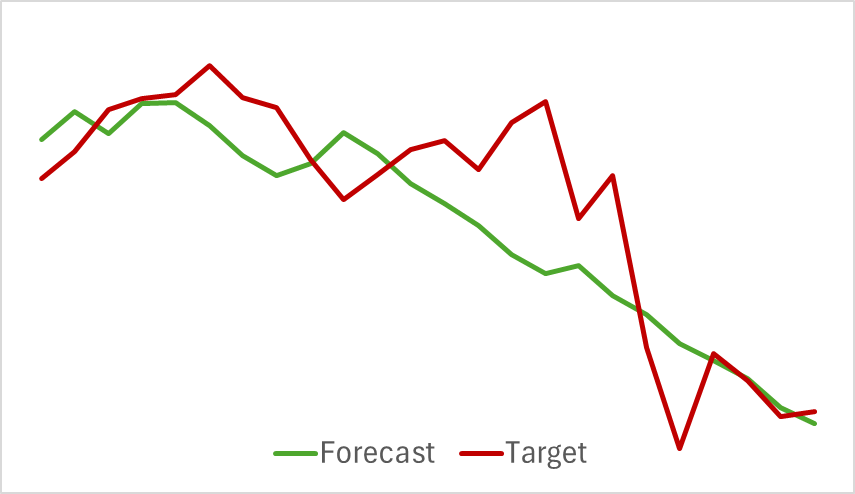
На графике видно тесное переплетение 2 линий. При этом можно отметить, что прогнозная траектория имеет более сглаженный вид. Потенциально это может сделать более стабильным обучения Актера.
Но, как вы знаете, наша основная задача поиск оптимальной политики Актера. И после обучения Энкодера состояния окружающей среды мы переходим ко второй стадии процесса обучения — обучение политики Актера. Данный процесс имеете итерационный характер. Так как в процессе обучения происходит смещение действий Актера, и они могут выходить за пределы пространства ранее собранной обучающей выборки, то нам необходимо периодически осуществлять обновление буфера воспроизведения опыта, пополняя его состояниями и вознаграждениями близкими к действиям текущей политики Актера.
После ряда чередующихся итераций обучения моделей Актера и Критика с обновлениями обучающей выборки нам удалось получить политику способную генерировать прибыль на историческом периоде обучающей выборки.
С целью проверки эффективности работы модели вне обучающей выборки (на новых данных) мы проводим тестирование модели на исторических данных Января 2024 года с сохранением прочих вводных.
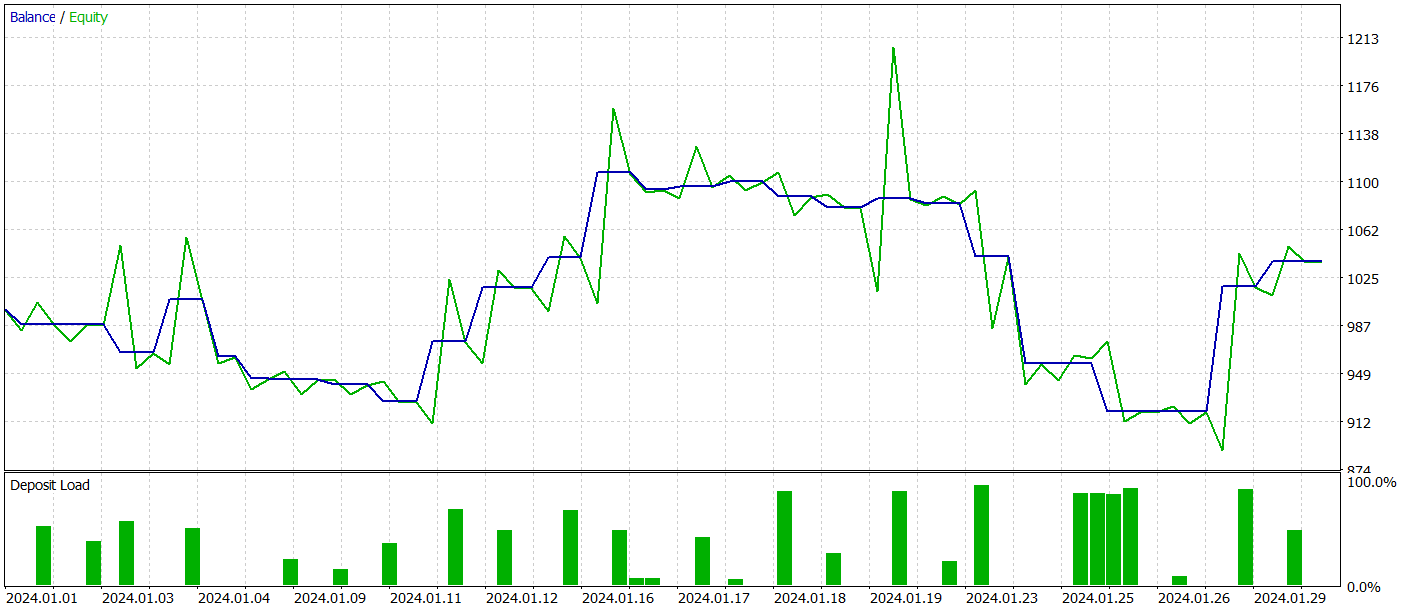
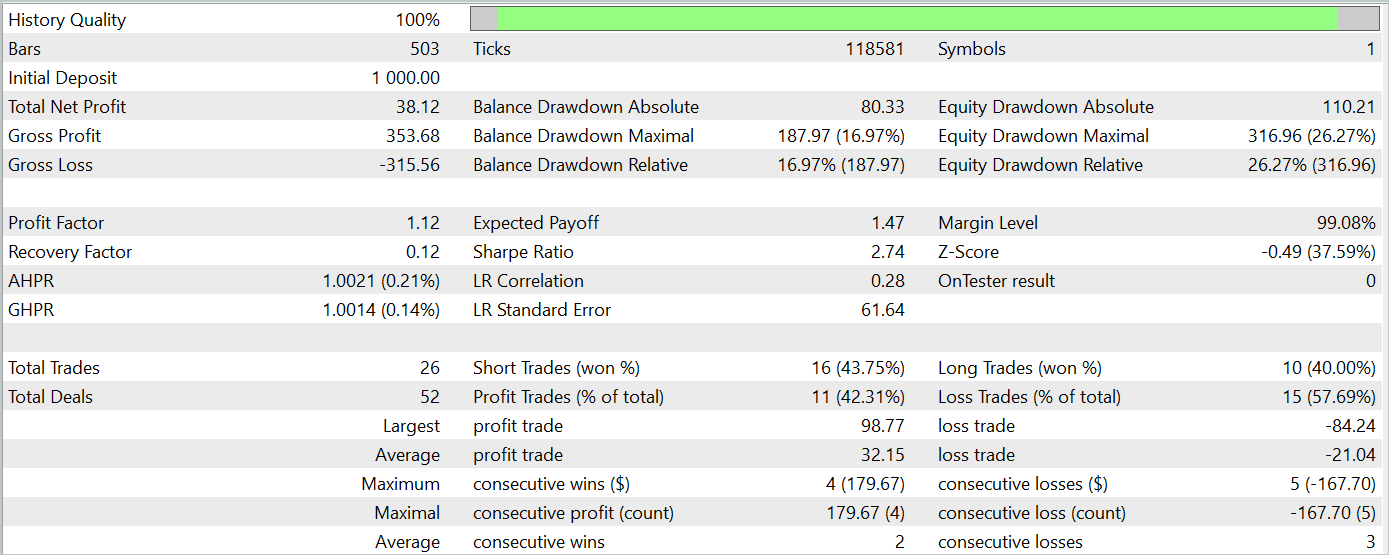
За период тестирования модель совершила 26 сделок и только 11 из них было закрыто с прибылью, что составило чуть более 42%. Однако, как максимальная, так и средняя прибыльная сделка превышают аналогичные убыточные показатели. Это позволило получить общую прибыль за период тестирования. По результатам тестирования профит фактор составил 1.12.
Тем не менее, если посмотреть на график баланса, то можно заметить значительную просадку в начале 3 декады месяца. И это сильно настораживает. Несмотря на полученную прибыль модель еще требует доработки.
Заключение
В данной статье мы познакомились с интересным методом прогнозирования тенденций ценового движения TPM. Данный метод успешно сочетает в себе преимущества сверточных моделей для анализа краткосрочных зависимостей и PLR для выявления долгосрочных тенденций.
В практической части нашей статьи мы реализовали собственное видение предложенных подходов средствами MQL5. Обучили и протестировали предложенные модели. По результатам тестирования, обученная модель смогла получить прибыль на данных, не входящих в обучающую выборку. Однако график баланса не показал желаемого однонаправленного движения и грешит наличие просадок.
В целом, предложенный метод имеет потенциал, но обученная нами модель нуждается еще в доработке.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Модель глубокого обучения GRU на Python с использованием ONNX в советнике, GRU vs LSTM
Модель глубокого обучения GRU на Python с использованием ONNX в советнике, GRU vs LSTM
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования