
Redes neurais e m trading: Aumento da eficiência do Transformer por meio da redução da nitidez (Conclusão)

Introdução
No artigo anterior , conhecemos os aspectos teóricos do framework SAMformer (Sharpness-Aware Multivariate Transformer), que representa um modelo inovador, desenvolvido para resolver os problemas inerentes ao Transformer tradicional nas tarefas de previsão de séries temporais multivariadas de longo prazo. Entre os principais problemas do Transformer padrão estão a alta complexidade de treinamento, a baixa capacidade de generalização em pequenas amostras e a tendência de cair em mínimos locais ruins. Essas limitações dificultam o uso de modelos baseados na arquitetura Transformer em tarefas com conjuntos de dados brutos limitados e alta exigência de precisão nas previsões.
A ideia central do SAMformer é o uso de uma arquitetura rasa, que reduz a complexidade computacional e evita o sobreajuste. Um dos componentes centrais é o mecanismo de otimização com consideração da nitidez (Sharpness-Aware Optimization, SAM), que aumenta a robustez do modelo a pequenas variações nos parâmetros, melhorando a capacidade de generalização e a qualidade da solução final.
Graças a essas características, o SAMformer demonstra resultados de previsão superiores tanto em conjuntos de dados de séries temporais sintéticos quanto reais. O modelo alcança alta precisão com uma redução significativa no número de parâmetros, tornando-o mais eficiente e adequado para uso em ambientes com restrição de recursos. Essas propriedades abrem oportunidades para a ampla aplicação do SAMformer em várias áreas, como finanças, medicina, gestão da cadeia de suprimentos e energia, onde a previsão de longo prazo desempenha um papel fundamental.
A visualização autoral do framework é apresentada abaixo.
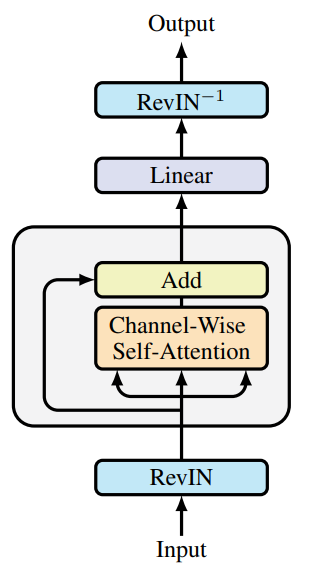
Já iniciamos a implementação das abordagens propostas. E no artigo anterior foi apresentada a implementação de novos kernels no lado do programa OpenCL. Além disso, foram discutidos os complementos para a camada totalmente conectada. Hoje, continuaremos o trabalho iniciado.
1. Camada convolucional com otimização SAM
Continuamos o trabalho iniciado. E na etapa seguinte, vamos complementar a camada convolucional com o funcional da SAM otimização. E, como não é difícil de imaginar, nossa nova classe CNeuronConvSAMOCL será criada como herdeira da nossa camada convolucional CNeuronConvOCL. A estrutura do novo objeto é apresentada abaixo.
class CNeuronConvSAMOCL : public CNeuronConvOCL { protected: float fRho; //--- CBufferFloat cWeightsSAM; CBufferFloat cWeightsSAMConv; //--- virtual bool calcEpsilonWeights(CNeuronBaseOCL *NeuronOCL); virtual bool feedForwardSAM(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronConvSAMOCL(void) { activation = GELU; } ~CNeuronConvSAMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronConvSAMOCL; } virtual int Activation(void) const { return (fRho == 0 ? (int)None : (int)activation); } virtual int getWeightsSAMIndex(void) { return cWeightsSAM.GetIndex(); } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Observe que na estrutura apresentada já declaramos 2 buffers para gravação dos parâmetros ajustados. Um buffer para as conexões de saída, de forma semelhante à camada totalmente conectada (cWeightsSAM). O segundo é para as de entrada (cWeightsSAMConv). É importante dizer que na classe pai não fica evidente tal duplicação de buffers de parâmetros. Afinal, o buffer dos parâmetros principais das conexões de saída é declarado na camada totalmente conectada pai.
Aqui nos deparamos com um dilema: herdar da camada totalmente conectada com o funcional da otimização SAM ou da camada convolucional existente. No primeiro caso, não precisaríamos criar o buffer dos parâmetros ajustados das conexões de saída, pois ele seria herdado da classe pai. Mas, nesse caso, teríamos que duplicar completamente os métodos da camada convolucional.
Na segunda opção de herança, recebemos da classe pai todo o funcional da camada convolucional. Mas falta o buffer dos parâmetros ajustados das conexões de saída, que é necessário para o funcionamento correto da camada totalmente conectada subsequente com a otimização SAM.
Optamos pela segunda opção de herança, pois exigia menos trabalho para implementar todo o funcional necessário.
Como antes, os objetos internos adicionais são declarados estaticamente, o que nos permite deixar o construtor e o destrutor vazios. No entanto, no construtor da classe, definimos GELU como a função de ativação padrão. Todo o restante do processo de inicialização dos objetos herdados e dos recém-declarados é realizado no método Init. E aqui você pode notar a substituição de dois métodos homônimos, que se diferenciam pela composição dos parâmetros. Primeiro, vamos analisar o método com o maior número de parâmetros.
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, optimization_type, batch)) return false;
Nos parâmetros do método, recebemos as principais constantes que permitem definir de forma inequívoca a arquitetura do objeto criado. E imediatamente repassamos praticamente todos os parâmetros recebidos ao método homônimo da classe pai, no qual já estão implementados todos os pontos de controle necessários e o algoritmo de inicialização de todos os objetos herdados.
Após a execução bem-sucedida do método da classe pai, salvamos na variável interna o coeficiente da região de desfoque. Este é o único parâmetro que não repassamos ao método da classe pai.
fRho = fabs(rho); if(fRho == 0) return true;
E logo verificamos o valor salvo. Com um coeficiente da região de desfoque igual a zero, o algoritmo de otimização SAM se degenera no algoritmo base de otimização de parâmetros do modelo, para o qual todos os objetos necessários já foram inicializados no método da classe pai. E podemos encerrar tranquilamente o trabalho do método com um resultado positivo.
Caso contrário, primeiro inicializamos com valores zero um buffer suficiente para as conexões de entrada ajustadas.
cWeightsSAMConv.BufferFree(); if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
E então, se necessário, de forma análoga inicializamos o buffer dos parâmetros ajustados das conexões de saída.
cWeightsSAM.BufferFree(); if(!Weights) return true; if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
Observe que este último buffer só é inicializado quando há parâmetros de conexões de saída. Isso ocorre no caso de o nosso objeto ser seguido por uma camada totalmente conectada.
E após a inicialização bem-sucedida de todos os objetos internos, finalizamos o método, retornando previamente o resultado lógico da execução das operações para o programa chamador.
O segundo método de inicialização do nosso objeto substitui completamente o método da classe pai e contém os mesmos parâmetros. No entanto, como você provavelmente já imaginou, nele falta o parâmetro crítico da otimização SAM: o coeficiente de desfoque. No corpo do método, atribuímos um coeficiente de desfoque no nível de 0.7. Este coeficiente de desfoque foi mencionado no trabalho autoral dedicado ao framework SAMformer. Em seguida, chamamos o método de inicialização da classe descrito anteriormente.
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { return CNeuronConvSAMOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, 0.7f, optimization_type, batch); }
Essa abordagem nos permite, com uma simples mudança no tipo do objeto, substituir a camada convolucional por uma equivalente com otimização SAM, praticamente em qualquer uma das soluções arquitetônicas abordadas anteriormente.
Assim como no caso da camada totalmente conectada, todo o funcional da propagação para frente e da distribuição do gradiente do erro é herdado da classe pai. No entanto, precisaremos criar 2 métodos wrapper para a chamada dos kernels do programa OpenCL: calcEpsilonWeights e feedForwardSAM. O primeiro método serve para a chamada do kernel criado anteriormente para o cálculo dos parâmetros ajustados da camada. O segundo repete integralmente o algoritmo do método pai de propagação para frente, apenas substituindo o buffer de parâmetros da camada pelo buffer de parâmetros ajustados. Não vamos nos deter agora na análise detalhada dos algoritmos desses métodos. Eles correspondem integralmente aos algoritmos já abordados de enfileiramento de kernels para execução. E eu proponho que você os explore por conta própria. O código completo desses métodos pode ser encontrado no anexo.
O algoritmo do método de otimização de parâmetros sobrescrito da nossa classe vai lhe lembrar o método análogo da camada totalmente conectada com otimização SAM. Só que, neste caso, não verificamos o tipo da camada anterior. Afinal, diferentemente da totalmente conectada, o objeto da camada convolucional em sua estrutura já contém a matriz de parâmetros aplicada aos dados brutos. Consequentemente, o buffer dos parâmetros ajustados utilizado também é próprio. Dessa forma, da camada anterior ele precisa apenas do buffer dos dados brutos, que todos os nossos objetos possuem.
Ainda assim, verificamos o coeficiente de dispersão. Pois, com um coeficiente zero, a otimização SAM se degenera no algoritmo base de otimização. Nesses casos, simplesmente usamos o método homônimo da classe pai.
bool CNeuronConvSAMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(fRho <= 0) return CNeuronConvOCL::updateInputWeights(NeuronOCL);
Por outro lado, ao utilizar a otimização SAM, primeiro somamos o gradiente do erro e os resultados da propagação para frente para obter o tensor de objetivos do objeto atual.
if(!SumAndNormilize(Gradient, Output, Gradient, iWindowOut, false, 0, 0, 0, 1)) return false;
Em seguida, recalculamos os parâmetros do modelo considerando o coeficiente da região de desfoque. Para isso, chamamos o método wrapper de enfileiramento do kernel correspondente. É fácil perceber que as camadas convolucional e totalmente conectada possuem métodos com o mesmo nome. Contudo, ao serem executados, realizam o enfileiramento de kernels distintos, que cumprem funções semelhantes, mas dentro dos algoritmos das respectivas camadas neurais.
if(!calcEpsilonWeights(NeuronOCL)) return false;
A mesma lógica se aplica aos métodos de propagação para frente com os parâmetros ajustados.
if(!feedForwardSAM(NeuronOCL)) return false;
Após a execução bem-sucedida da propagação para frente repetida, determinamos o desvio em relação aos valores-alvo.
float error = 1; if(!calcOutputGradients(Gradient, error)) return false;
E chamamos o método homônimo da classe pai para a correção dos parâmetros do modelo.
//--- return CNeuronConvOCL::updateInputWeights(NeuronOCL); }
O resultado lógico da execução das operações será retornado ao programa chamador, e finalizaremos o método.
Vamos falar sobre o salvamento dos parâmetros do modelo treinado. Aqui seguimos as decisões discutidas ao descrever os métodos da camada totalmente conectada com otimização SAM. Não salvamos os dados dos buffers de parâmetros ajustados. À informação salva pela classe pai, adicionamos apenas o coeficiente de desfoque.
bool CNeuronConvSAMOCL::Save(const int file_handle) { if(!CNeuronConvOCL::Save(file_handle)) return false; if(FileWriteFloat(file_handle, fRho) < INT_VALUE) return false; //--- return true; }
Entretanto, ao carregar os parâmetros de um modelo previamente treinado, precisamos preparar os buffers necessários. E aqui é importante entender que os critérios para a criação dos buffers de parâmetros ajustados das conexões de entrada e saída são diferentes.
No método de carregamento de dados, primeiro lemos os dados salvos pela classe pai.
bool CNeuronConvSAMOCL::Load(const int file_handle) { if(!CNeuronConvOCL::Load(file_handle)) return false;
E depois lemos o valor do coeficiente de desfoque, verificando previamente a existência dos dados no arquivo.
if(FileIsEnding(file_handle)) return false; fRho = FileReadFloat(file_handle);
A presença de um coeficiente de desfoque positivo é o critério geral para a criação dos buffers de parâmetros ajustados. Por isso, verificamos o valor do parâmetro carregado. E, caso ele não atenda às nossas condições, limpamos os buffers não utilizados no contexto do OpenCL e na memória principal. Em seguida, finalizamos o método com um resultado positivo.
cWeightsSAMConv.BufferFree(); cWeightsSAM.BufferFree(); cWeightsSAMConv.Clear(); cWeightsSAM.Clear(); if(fRho <= 0) return true;
Observe que este é um caso em que o ponto de controle não é crítico para o funcionamento do programa. Como já mencionado anteriormente, a ausência de um coeficiente de desfoque positivo leva a uma degeneração do SAM no método base de otimização de parâmetros. Consequentemente, o funcionamento do nosso objeto se resume aos métodos da classe pai.
No caso de passar por este ponto de controle, inicializamos e criamos no contexto de memória OpenCL o buffer dos parâmetros ajustados das conexões de entrada.
if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
Para a criação do buffer dos parâmetros ajustados das conexões de saída, há um critério adicional, que é a existência de tais conexões. Por isso, antes de sua criação, verificamos a validade do ponteiro para o buffer correspondente.
if(!Weights) return true;
E, neste caso, a ausência de um ponteiro válido não é crítica para o funcionamento do programa, apenas indica particularidades da arquitetura do modelo. Portanto, na ausência de um ponteiro válido, finalizamos o método com um resultado positivo.
No caso da presença de um buffer carregado das conexões de saída, inicializamos e criamos um buffer de tamanho equivalente para os parâmetros ajustados.
if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
Depois disso, retornamos o resultado lógico da execução das operações ao programa chamador e finalizamos o método.
Com isso, concluímos a análise dos algoritmos dos métodos da camada convolucional com uso das abordagens de otimização SAM no CNeuronConvSAMOCL. O código completo desta classe e de todos os seus métodos pode ser encontrado no anexo.
2. Adicionando SAM no Transformer
Nesta etapa, criamos objetos das camadas totalmente conectada e convolucional utilizando as abordagens de otimização SAM dos parâmetros. E chegou o momento de implementar as abordagens propostas na arquitetura do Transformer. Na verdade, foi exatamente isso que os autores do framework SAMformer propuseram. E aqui, com o objetivo de avaliar objetivamente o impacto das abordagens propostas no funcionamento do modelo, decidimos não criar novas classes. Em vez disso, vamos adicionar as abordagens propostas à estrutura da classe já existente. Usaremos como base o transformer com atenção relativa R-MAT.
Como você sabe, na classe CNeuronRMAT foi construída uma rede linear composta por objetos alternados sequencialmente de CNeuronRelativeSelfAttention e CResidualConv. No primeiro, está implementado o módulo de atenção relativa com retroalimentação, e no segundo, o módulo de camadas convolucionais com retroalimentação. Para implementar as abordagens de otimização SAM, basta substituir na estrutura desses objetos todas as camadas convolucionais pelas equivalentes que utilizam a otimização SAM. A nova estrutura das classes é apresentada abaixo.
class CNeuronRelativeSelfAttention : public CNeuronBaseOCL { protected: uint iWindow; uint iWindowKey; uint iHeads; uint iUnits; int iScore; //--- CNeuronConvSAMOCL cQuery; CNeuronConvSAMOCL cKey; CNeuronConvSAMOCL cValue; CNeuronTransposeOCL cTranspose; CNeuronBaseOCL cDistance; CLayer cBKey; CLayer cBValue; CLayer cGlobalContentBias; CLayer cGlobalPositionalBias; CLayer cMHAttentionPooling; CLayer cScale; CBufferFloat cTemp; //--- virtual bool AttentionOut(void); virtual bool AttentionGradient(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronRelativeSelfAttention(void) : iScore(-1) {}; ~CNeuronRelativeSelfAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRelativeSelfAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual uint GetWindow(void) const { return iWindow; } virtual uint GetUnits(void) const { return iUnits; } };
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvSAMOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); };
Observe que, para o módulo convolucional com retroalimentação, apenas alteramos o tipo do objeto na estrutura da classe. Não fazemos ajustes nos métodos das classes. Isso foi possível graças à sobrecarga dos métodos de inicialização da camada convolucional com a inicialização SAM. Lembro que, dentro da classe CNeuronConvSAMOCL, criamos 2 métodos de inicialização: um com e outro sem o coeficiente de desfoque nos parâmetros do método. É evidente que o método de inicialização sem a indicação do coeficiente de desfoque substitui o método homônimo da classe pai, que utilizávamos anteriormente para a inicialização das camadas convolucionais. Portanto, ao inicializar os objetos CResidualConv, quando o método de inicialização da camada convolucional for chamado, o programa acessará o método que já sobrescrevemos. Nele será adicionado o coeficiente de desfoque, definido por padrão, e será invocado o método de inicialização completa da camada convolucional utilizando as abordagens da otimização SAM.
No caso do módulo de atenção relativa, a situação é um pouco mais complexa. O fato é que o módulo de atenção relativa que utilizamos, CNeuronRelativeSelfAttention, possui uma arquitetura bastante complexa, que inclui modelos aninhados adicionais de vieses treináveis. A arquitetura deles é definida no método de inicialização do objeto. Portanto, para adicionar as abordagens de otimização SAM aos modelos internos, precisaremos fazer ajustes no método de inicialização do módulo de atenção relativa.
Os parâmetros do método permanecem inalterados, e os primeiros passos do seu algoritmo também não sofrem alterações. O tipo dos objetos para a geração das entidades Query, Key e Value já alteramos na estrutura da classe.
bool CNeuronRelativeSelfAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; //--- iWindow = window; iWindowKey = window_key; iUnits = units_count; iHeads = heads; //--- int idx = 0; if(!cQuery.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cQuery.SetActivationFunction(GELU); idx++; if(!cKey.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cValue.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cTranspose.Init(0, idx, OpenCL, iUnits, iWindow, optimization, iBatch)) return false; idx++; if(!cDistance.Init(0, idx, OpenCL, iUnits * iUnits, optimization, iBatch)) return false;
Em seguida, nos modelos de geração dos vieses BKey e BValue, realizamos a substituição dos tipos dos objetos convolucionais, mantendo os demais parâmetros.
idx++; CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false;
idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false;
Nos modelos de geração dos vieses do contexto global e das posições, utilizamos camadas totalmente conectadas com otimização SAM.
idx++; CNeuronBaseOCL *neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false; idx++; CBufferFloat *buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false;
idx++; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false; idx++; buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false;
E para as operações MLP de pooling, utilizamos novamente camadas convolucionais com o uso das abordagens de otimização SAM.
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iHeads, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(None); CNeuronSoftMaxOCL *softmax = new CNeuronSoftMaxOCL(); if(!softmax || !softmax.Init(0, idx, OpenCL, iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(softmax) ) return false; softmax.SetHeads(iUnits);
Observe que, para a primeira camada, utilizamos a camada totalmente conectada base. Isso porque ela é utilizada apenas para gravar os resultados do bloco de atenção multi-cabeça.
A mesma situação ocorre com o bloco de escalonamento. Para a primeira camada, utilizamos a totalmente conectada base, pois ela se destina a gravar os resultados da multiplicação dos coeficientes de importância pelos resultados da atenção multi-cabeça. Em seguida, vêm as camadas convolucionais com otimização SAM.
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iUnits, optimization, iBatch) || !cScale.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey, iWindowKey, 2 * iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(LReLU); idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, 2 * iWindow, 2 * iWindow, iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(None); //--- if(!SetGradient(conv.getGradient(), true)) return false; //--- SetOpenCL(OpenCL); //--- return true; }
Com isso, concluímos o trabalho de implementação das abordagens de otimização SAM no Transformer com atenção relativa. O código completo dos objetos atualizados pode ser encontrado no anexo.
3. Arquitetura dos modelos
Acima, criamos novos objetos e fizemos alterações em alguns já existentes. A próxima etapa do nosso trabalho será o ajuste da arquitetura dos modelos. E, diferentemente de alguns dos artigos mais recentes, hoje o ajuste da arquitetura dos modelos será mais global. Começamos pela arquitetura do Codificador do ambiente, apresentada no método CreateEncoderDescriptions. Como antes, nos parâmetros do método recebemos um ponteiro para um array dinâmico destinado a registrar a sequência das camadas neurais do modelo.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
No corpo do método, verificamos a validade do ponteiro recebido e, se necessário, criamos uma nova instância do array dinâmico.
As duas primeiras camadas permanecem inalteradas. São a camada de dados brutos e a de normalização em lotes. O tamanho dos dados dessas camadas é idêntico e deve ser suficiente para registrar o tensor dos dados brutos.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, os autores do framework SAMformer propõem o uso de atenção por canais. Por isso, utilizamos uma camada de transposição de dados, que nos ajudará a apresentar os dados brutos na forma de uma sequência de canais de atenção.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window= BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Depois, usamos o bloco de atenção relativa, no qual já implementamos as abordagens de otimização SAM.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRMAT; descr.window=HistoryBars; descr.count=BarDescr; descr.window_out = EmbeddingSize/2; // Key Dimension descr.layers = 1; // Layers descr.step = 2; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
E aqui é importante destacar dois pontos. Primeiro: estamos usando atenção por canais. Por isso, a janela de análise é igual à profundidade do histórico analisado, e o número de elementos é igual ao número de canais independentes. Segundo: como propuseram os autores do framework, utilizamos apenas uma camada de atenção. No entanto, diferentemente da implementação original, usamos duas cabeças de atenção. Além disso, mantivemos o bloco FeedForward. Lembro que os autores do framework utilizaram uma única cabeça de atenção e removeram o bloco FeedForward.
Em seguida, precisamos reduzir a dimensionalidade do tensor de resultados para o tamanho especificado. Esta operação será realizada em duas etapas. Primeiro, utilizaremos uma camada convolucional com otimização SAM para reduzir a dimensionalidade de cada canal individualmente.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount/BarDescr; descr.probability = 0.7f; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Depois, utilizaremos uma camada totalmente conectada com otimização SAM para obter a incorporação (embedding) geral do estado atual do ambiente no tamanho especificado.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Em ambos os casos, usamos descr.probability para indicar o coeficiente da região de desfoque.
E finalizamos o método retornando o resultado lógico da execução das operações ao programa chamador. A própria arquitetura do modelo é retornada por meio do ponteiro do array dinâmico que recebemos anteriormente nos parâmetros do programa chamador.
Após a criação da arquitetura do Codificador do ambiente, passamos para a descrição das camadas do Ator e do Crítico. A descrição de ambos os modelos é gerada no método CreateDescriptions. E, como nesse método criamos a descrição de 2 modelos, também recebemos nos parâmetros do método 2 ponteiros para arrays dinâmicos.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
No corpo do método, verificamos a validade dos ponteiros recebidos e, se necessário, criamos novos arrays dinâmicos.
Primeiro, descrevemos a arquitetura do Ator. A primeira camada deste modelo é representada por uma camada totalmente conectada utilizando as abordagens de otimização SAM. O tamanho desta camada corresponde ao vetor de descrição do estado da conta.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.probability=0.7f; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Observe que utilizamos a camada totalmente conectada com otimização SAM para registrar os dados brutos. Já no modelo do Codificador do ambiente, em situação análoga, utilizamos a camada totalmente conectada base. Isso se deve à presença de uma camada totalmente conectada subsequente com otimização SAM, que para funcionar plenamente exige o buffer dos parâmetros ajustados da camada anterior.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Assim como no Codificador do estado do ambiente, utilizamos descr.probability para indicar o coeficiente da região de desfoque. Para todos os modelos, usamos um coeficiente da região de desfoque único, no nível de 0.7.
Duas camadas totalmente conectadas consecutivas com otimização SAM criam as incorporações (embeddings) do estado atual da conta, que posteriormente combinamos com a incorporação do estado correspondente do ambiente. Essa funcionalidade é realizada por uma camada de concatenação de dados.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Depois, utilizamos o bloco de tomada de decisão composto por 3 camadas totalmente conectadas com otimização SAM.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Na saída da última camada, geramos um tensor com o dobro do tamanho do vetor-alvo de representação das ações do Ator. Isso nos permite adicionar estocasticidade às ações. Como antes, para isso utilizamos a camada de estado latente do autocodificador.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Lembro que a camada latente do autocodificador divide o tensor dos dados brutos em duas partes: a primeira parte reflete os valores médios das distribuições para cada elemento da sequência de saída, enquanto a segunda parte contém as variâncias das respectivas distribuições. O treinamento desses valores médios e variâncias no módulo de tomada de decisão nos permite limitar a área de geração dos valores aleatórios à camada latente do autocodificador, que utilizamos para introduzir estocasticidade na política do Ator.
Aqui vale acrescentar que a camada latente do autocodificador gera valores independentes para cada elemento da sequência de saída. No entanto, esperamos obter desses valores um conjunto coerente de parâmetros para realizar uma operação: o volume da operação, os níveis de take profit e stop loss. Para conferir coerência aos parâmetros da operação, utilizamos uma camada convolucional com otimização SAM, que analisa separadamente os parâmetros das operações de compra e de venda.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Para limitar a faixa dos resultados dessa camada, utilizamos a função de ativação sigmoide.
E o último toque do nosso modelo Ator é a camada de previsão direta com reforço de frequência (CNeuronFreDFOCL), que permite alinhar os resultados do modelo com os valores-alvo no domínio da frequência.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O Crítico recebeu uma arquitetura semelhante. Só que, na entrada do modelo, alimentamos os parâmetros da operação de trading gerada pelo Ator, em vez da descrição do estado da conta fornecida ao Ator. Também utilizamos 2 camadas totalmente conectadas com SAM otimização para obter a incorporação (embedding) da operação de trading.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
A incorporação da operação de trading é combinada com a incorporação do estado do ambiente na camada de concatenação de dados.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Em seguida, utilizamos o bloco de tomada de decisão composto por 3 camadas totalmente conectadas consecutivas com otimização SAM. Mas, diferentemente do Ator, neste caso não utilizamos estocasticidade nos resultados.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
E no topo do modelo Crítico adicionamos a camada de previsão direta com reforço de frequência.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Após concluir a geração da descrição da arquitetura dos modelos, finalizamos o método retornando previamente o resultado lógico da execução das operações ao programa chamador. A descrição da arquitetura dos modelos é retornada pelos ponteiros dos arrays dinâmicos que foram recebidos nos parâmetros do método.
Com isso, concluímos o trabalho de construção dos modelos. A arquitetura completa deles pode ser consultada no anexo. Lá também está disponível o código completo dos programas de interação com o ambiente e de treinamento dos modelos, os quais foram trazidos dos trabalhos anteriores sem alterações.
4. Testes
Realizamos um trabalho considerável na implementação das abordagens propostas pelos autores do framework SAMformer. E agora chegou o momento de verificar a eficácia da solução implementada em dados históricos reais. Como antes, o treinamento dos modelos foi realizado com dados históricos reais do instrumento EURUSD ao longo de todo o ano de 2023. Durante os experimentos, utilizamos dados do timeframe H1. Todos os parâmetros dos indicadores analisados foram mantidos nos valores padrão.
Como mencionado anteriormente, os programas utilizados para a interação com o ambiente e o treinamento dos modelos permaneceram inalterados. Isso nos permite utilizar os conjuntos de treinamento criados anteriormente para o treinamento inicial dos modelos. Além disso, como escolhemos o framework R-MAT como modelo base para a implementação da otimização SAM, decidimos não atualizar o conjunto de treinamento durante o processo de treinamento do modelo. É claro que esperamos que isso impacte negativamente os resultados do treinamento dos modelos. Mas essa abordagem nos permitirá comparar os resultados com o modelo base, eliminando a influência de alterações no conjunto de treinamento.
O treinamento dos 3 modelos foi realizado simultaneamente. E os resultados do teste da política treinada do Ator são apresentados abaixo. O teste do modelo foi realizado com dados históricos reais de janeiro de 2024, mantendo os demais parâmetros utilizados no treinamento do modelo.
Mas antes, vale dizer algumas palavras sobre o treinamento dos modelos. Em primeiro lugar, a otimização SAM pressupõe o suavização do relevo da função de perda. Isso, por sua vez, permite considerar a possibilidade de utilizar uma taxa de aprendizado maior. E, se antes o treinamento dos modelos usava principalmente uma taxa de aprendizado em torno de 3.0e-04, neste caso aumentamos para 1.0e-03.
Além disso, o uso de apenas uma camada de atenção permitiu reduzir a quantidade de parâmetros treináveis, e com isso compensar o custo do segundo passo de propagação para frente necessário na execução do algoritmo de otimização SAM dos parâmetros.
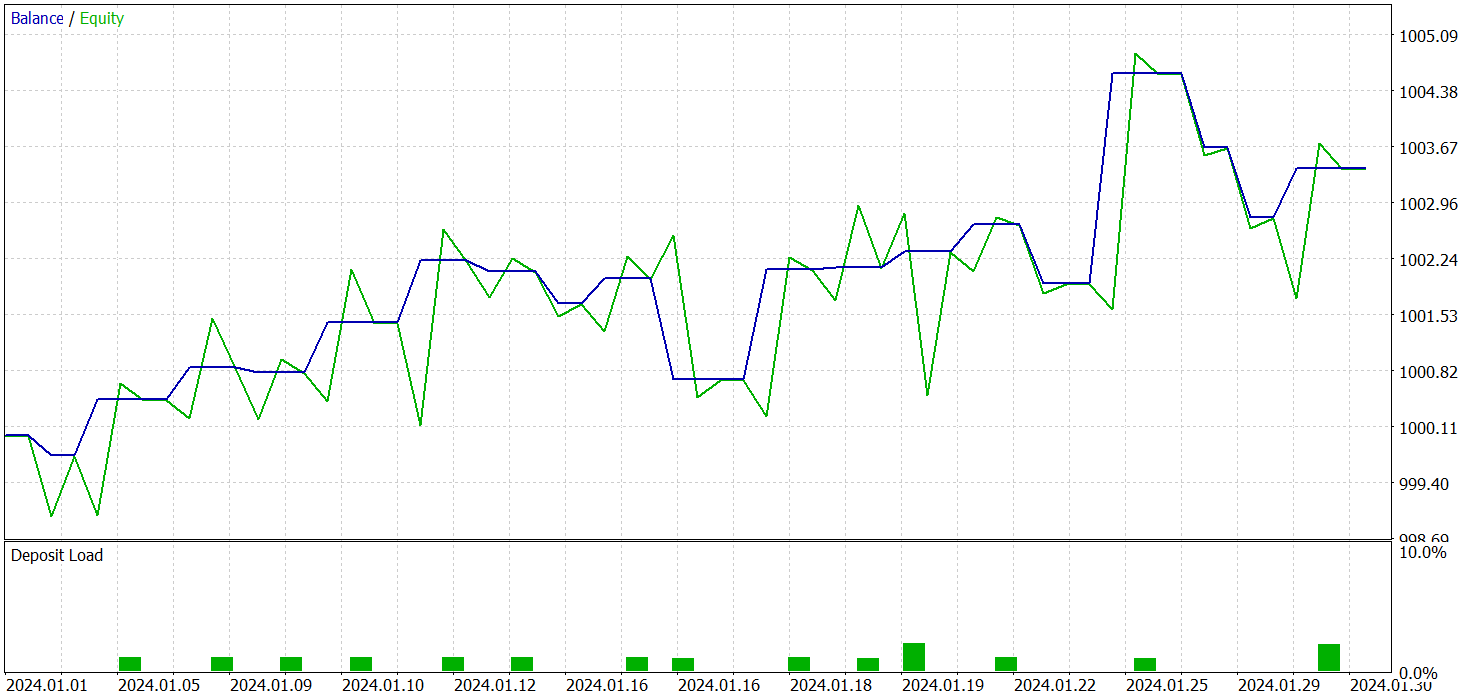
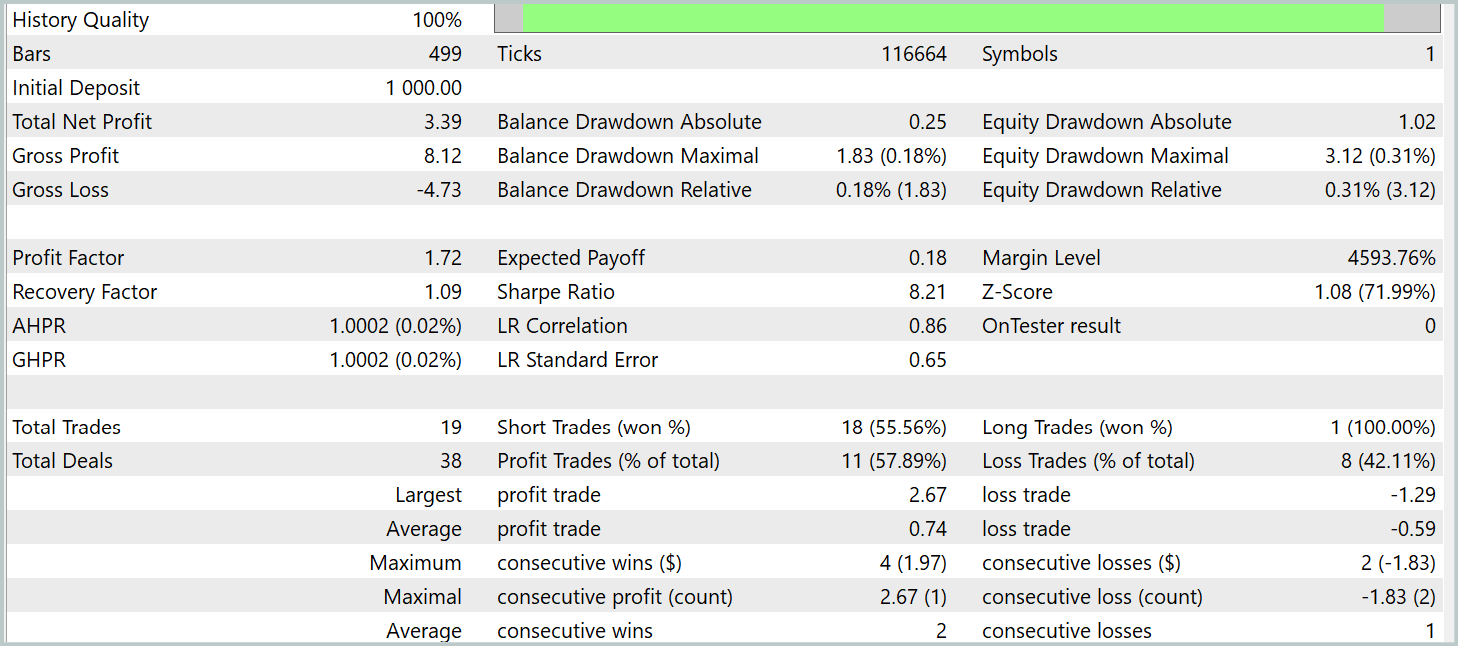
Como resultado do treinamento do modelo, conseguimos obter uma política capaz de gerar lucro fora do conjunto de treinamento. Durante o período de teste, o modelo realizou 19 operações de trading, das quais 11 foram fechadas com lucro (57,89%). Para comparação, o modelo R-MAT que implementamos anteriormente realizou 15 operações no mesmo período, das quais 9 foram fechadas com lucro (60,0%). No entanto, a rentabilidade total do novo modelo é quase 2 vezes maior que o lucro do modelo base.
Considerações finais
O framework SAMformer representa uma solução eficaz para as principais limitações da arquitetura Transformer, que surgem na previsão de séries temporais multivariadas de longo prazo. O Transformer tradicional enfrenta uma série de dificuldades, incluindo alta complexidade de treinamento e baixa capacidade de generalização, especialmente em pequenos conjuntos de treinamento.
As principais vantagens do SAMformer são sua arquitetura rasa e o uso do mecanismo de otimização com consideração da nitidez (Sharpness-Aware Minimization). Essas abordagens permitem que o modelo evite com sucesso mínimos locais ruins, melhorando a estabilidade e a precisão do treinamento, além de proporcionar uma capacidade de generalização superior.
Na parte prática do nosso trabalho, implementamos nossa visão das abordagens propostas utilizando os recursos do MQL5 e treinamos os modelos com dados históricos reais. Os resultados dos testes dos modelos treinados confirmam a eficácia das abordagens propostas e demonstram que sua aplicação permite aumentar a eficiência dos modelos base sem custos adicionais de treinamento. E, em alguns casos, até permite reduzir os custos de treinamento.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA de treinamento dos Modelos |
| 4 | StudyEncoder.mq5 | Expert Advisor | EA de treinamento do Codificador |
| 5 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação da rede neural |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16403
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Renda anual dos bancos russos em dólares. Divida por 12 e compare.
Em yuans 6, em títulos de yuans mais de 10.
Em renminbi 6, em títulos em renminbi mais de 10.
Mas os resultados dos testes em EURUSD e o resultado em USD são apresentados no artigo. Ao mesmo tempo, a carga sobre o depósito é de 1-2%, e ninguém escreveu que se trata de um graal.
Mas o artigo apresenta os resultados dos testes em EURUSD e o resultado em USD. Ao mesmo tempo, a carga sobre o depósito é de 1 a 2%, e ninguém escreveu que se trata de um graal.
Ok. O limite em quid nos bancos dá 5%.
Lucro total de 0,35% ao mês? Não seria mais lucrativo simplesmente colocar o dinheiro no banco?