
Нейросети в трейдинге: Повышение эффективности Transformer путем снижения резкости (Окончание)

Введение
В предыдущей статье мы познакомились с теоретическими аспектами фреймворка SAMformer (Sharpness-Aware Multivariate Transformer), который представляет собой инновационную модель, разработанную для решения проблем, присущих традиционным Transformer в задачах долгосрочного прогнозирования многомерных временных рядов. К основным проблемам ванильного Transformer можно отнести высокую сложность обучения, низкую способность к обобщению на небольших выборках и склонность к попаданию в плохие локальные минимумы. Эти ограничения затрудняют применение моделей на основе архитектуры Transformer в задачах с ограниченным набором исходных данных и высокими требованиями к точности прогнозирования.
Ключевая идея SAMformer заключается в использовании неглубокой архитектуры, которая уменьшает вычислительную сложность и предотвращает переобучение. Одним из центральных компонентов является механизм оптимизации с учетом резкости (Sharpness-Aware Optimization, SAM), который повышает устойчивость модели к небольшим изменениям параметров, улучшая обобщающую способность и качество финального решения.
Благодаря этим особенностям, SAMformer демонстрирует превосходные результаты прогнозирования как на синтетических, так и на реальных наборах данных временных рядов. Модель достигает высокой точности при значительном уменьшении количества параметров, что делает её более эффективной и подходящей для использования в ресурсозависимых средах. Эти свойства открывают возможности для широкого применения SAMformer в различных областях, таких как финансы, медицина, управление цепочками поставок и энергетика, где долгосрочное прогнозирование играет ключевую роль.
Авторская визуализация фреймворка представлена ниже.
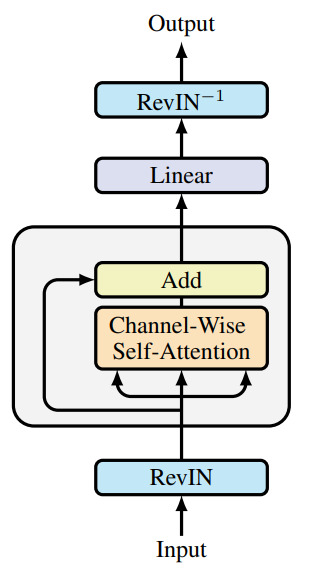
Мы уже начали реализацию предложенных подходов. И в предыдущей статье была представлена реализация новых кернелов на стороне OpenCL-программы. А также были рассмотрены дополнения к полносвязному слою. Сегодня мы продолжим начатую работу.
1. Сверточный слой с SAM оптимизацией
Продолжаем начатую работу. И на следующем этапе мы дополним сверточный слой функционалом SAM оптимизации. И, как не сложно догадаться, свой новый класс CNeuronConvSAMOCL мы создадим наследником нашего сверточного слоя CNeuronConvOCL. Структура нового объекта представлена ниже.
class CNeuronConvSAMOCL : public CNeuronConvOCL { protected: float fRho; //--- CBufferFloat cWeightsSAM; CBufferFloat cWeightsSAMConv; //--- virtual bool calcEpsilonWeights(CNeuronBaseOCL *NeuronOCL); virtual bool feedForwardSAM(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronConvSAMOCL(void) { activation = GELU; } ~CNeuronConvSAMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronConvSAMOCL; } virtual int Activation(void) const { return (fRho == 0 ? (int)None : (int)activation); } virtual int getWeightsSAMIndex(void) { return cWeightsSAM.GetIndex(); } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Обратите внимание, что в представленной структуре мы объявляем уже 2 буфера для записи скорректированных параметров. Один буфер для исходящих связей, аналогично полносвязному слою (cWeightsSAM). Второй — для входящих (cWeightsSAMConv). Надо сказать, что в родительском классе явно не просматривается такого дублирования буферов параметров. Ведь буфер основных параметров исходящих связей объявляется в родительском полносвязном слое.
Здесь же перед нами стояла дилемма наследования от полносвязного слоя с функционалом SAM оптимизации или от существующего сверточного слоя. В первом случае мы бы не создавали буфер скорректированных исходящих связей, так как он наследовался бы от родительского класса. Но в таком случае нам бы пришлось полностью дублировать методы сверточного слоя.
При втором варианте наследования мы получаем от родительского класса весь функционал сверточного слоя. Но отсутствует буфер скорректированных параметров исходящих связей, который необходим для корректной работы последующего полносвязного слоя с SAM оптимизацией.
Мы избрали второй вариант наследования, так как он требовал меньшего объема работы для реализации всего необходимого функционала.
Как и ранее, дополнительные внутренние объекты мы объявляем статично, что позволяет нам оставить пустыми конструктор и деструктор. Тем не менее, в конструкторе класса мы устанавливаем GELU в качестве функции активации по умолчанию. Весь остальной процесс инициализации унаследованных и вновь объявленных объектов осуществляется в методе Init. И здесь вы можете заметить переопределение двух одноименных методов, отличающихся по составу параметров. Вначале рассмотрим метод с максимальным количеством параметров.
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, optimization_type, batch)) return false;
В параметрах метода мы получаем основные константы, позволяющие однозначно определить архитектуру создаваемого объекта. И мы сразу передаем практически все полученные параметры одноименному методу родительского класса, в котором уже реализованы все необходимые точки контроля и алгоритм инициализации всех унаследованных объектов.
После успешного выполнения метода родительского класса, мы сохраняем во внутренней переменной коэффициент области размытия. Это единственный параметр, который мы не передавали в метод родительского класса.
fRho = fabs(rho); if(fRho == 0) return true;
И тут же проверяем сохраненное значение. При нулевом коэффициенте области размытия, алгоритм SAM оптимизации вырождается в заданный базовый алгоритм оптимизации параметров модели, для которого все необходимые объекты уже инициализированы в методе родительского класса. И мы смело завершаем работу метода с положительным результатом.
В противном случае, мы сначала инициализируем нулевыми значениями достаточный буфер скорректированных входящих связей.
cWeightsSAMConv.BufferFree(); if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
А затем, в случае необходимости, аналогичным образом инициализируем буфер скорректированных параметров исходящих связей.
cWeightsSAM.BufferFree(); if(!Weights) return true; if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
Обратите внимание, что последний буфер инициализируется только при наличии параметров исходящих связей. А это происходит в том случае, когда за нашим объектом будет следовать полносвязный слой.
И после успешной инициализации всех внутренних объектов, мы завершаем работу метода, предварительно вернув логический результат выполнения операций вызывающей программе.
Второй метод инициализации нашего объекта полностью переопределяет метод родительского класса и содержит идентичные параметры. При этом, как вы наверное догадались, в нем отсутствует критичный для SAM оптимизации параметр коэффициента размытия. В теле метода мы подставляем коэффициент размытия на уровне 0.7. Данный коэффициент размытия упоминался в авторской работе, посвященной фреймворку SAMformer. После чего вызываем описанный выше метод инициализации класса.
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { return CNeuronConvSAMOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, 0.7f, optimization_type, batch); }
Такой подход позволяет нам простым изменением типа объекта заменить сверточный слой на аналогичный с SAM оптимизацией, практически в любом из рассмотренных ранее архитектурных решений.
Как и в случае полносвязного слоя, весь функционал прямого прохода и распределения градиента ошибки мы наследуем от родительского класса. Однако нам предстоит создать 2 метода-обертки для вызова кернелов OpenCL-программы: calcEpsilonWeights и feedForwardSAM. Первый метод служит для вызова созданного ранее кернела вычисления скорректированных параметров слоя. Второй — полностью повторяет алгоритм родительского метода прямого прохода, только буфер параметров слоя подменяется буфером скорректированных параметров. Мы не будем сейчас останавливаться на детальном рассмотрении алгоритмов указанных методов. Они полностью соответствуют рассмотренным ранее алгоритмам постановки кернелов в очередь выполнения. И я предлагаю вам ознакомиться с ними самостоятельно. Полный код указанных методов вы найдете во вложении.
Алгоритм переопределяемого метода оптимизации параметров нашего класса вам напомнит аналогичный метод полносвязного слоя с SAM оптимизацией. Только в данном случае мы не проверяем тип предшествующего слоя. Ведь в отличие от полносвязного, объект сверточного слоя в своей структуре содержит матрицу параметров, применяемых к исходным данным. Соответственно, и буфер скорректированных параметров он использует свой. Таким образом от предшествующего объекта ему нужен только буфер исходных данных, который имеют все наши объекты.
Тем не менее мы проверяем коэффициент рассеивания. Ведь при нулевом коэффициенте SAM оптимизация вырождается в базовый алгоритм оптимизации. В таких случаях мы лишь используем одноименный метод родительского класса.
bool CNeuronConvSAMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(fRho <= 0) return CNeuronConvOCL::updateInputWeights(NeuronOCL);
В случае же использования SAM оптимизации мы сначала суммируем градиент ошибки и результаты прямого прохода для получения тензора целей текущего объекта.
if(!SumAndNormilize(Gradient, Output, Gradient, iWindowOut, false, 0, 0, 0, 1)) return false;
Затем мы пересчитываем параметры модели с учетом коэффициента области размытия. Для этого мы вызываем метод-обертку постановки в очередь выполнения соответствующего кернела. Легко заметить, что сверточный и полносвязный слои имеют методы с одинаковым названием. Однако, при их выполнении осуществляется постановка в очередь различных кернелов, которые выполняют похожий функционал, но в рамках алгоритмов соответствующих нейронных слоев.
if(!calcEpsilonWeights(NeuronOCL)) return false;
Аналогичная ситуация для методов прямого прохода со скорректированными параметрами.
if(!feedForwardSAM(NeuronOCL)) return false;
После успешного прохождения повторного прямого прохода, мы определяем отклонение от целевых значений.
float error = 1; if(!calcOutputGradients(Gradient, error)) return false;
И вызываем одноименный метод родительского класса для корректировки параметров модели.
//--- return CNeuronConvOCL::updateInputWeights(NeuronOCL); }
Логический результат выполнения операций мы вернем вызывающей программе и завершим работу метода.
Поговорим о сохранении параметров обученной модели. Здесь мы придерживаемся решений, обсуждаемых при описании методов полносвязного слоя с SAM оптимизацией. Мы не сохраняем данные буферов скорректированных параметров. К информации, сохраняемой родительским классом, мы добавляем лишь коэффициент размытия.
bool CNeuronConvSAMOCL::Save(const int file_handle) { if(!CNeuronConvOCL::Save(file_handle)) return false; if(FileWriteFloat(file_handle, fRho) < INT_VALUE) return false; //--- return true; }
Однако при загрузке параметров предварительно обученной модели, нам необходимо подготовить необходимые буферы. И здесь следует понимать, что критерии создания буферов скорректированных параметров входящих и исходящих связей отличаются.
В методе загрузки данных сначала мы считываем данные, сохраненные родительским классом.
bool CNeuronConvSAMOCL::Load(const int file_handle) { if(!CNeuronConvOCL::Load(file_handle)) return false;
А затем считываем значение коэффициента размытия, предварительно проверив наличие данных в файле.
if(FileIsEnding(file_handle)) return false; fRho = FileReadFloat(file_handle);
Наличие положительного коэффициента размытия является общим критерием для создания буферов скорректированных параметров. Поэтому мы проверяем значение загруженного параметра. И если оно не удовлетворяет нашим условиям, то очищаем неиспользуемые буферы в OpenCL-контексте и основной памяти. После чего завершаем работу метода с положительным результатом.
cWeightsSAMConv.BufferFree(); cWeightsSAM.BufferFree(); cWeightsSAMConv.Clear(); cWeightsSAM.Clear(); if(fRho <= 0) return true;
Обратите внимание, это тот случай, когда точка контроля не является критичной для работы программы. Как уже говорилось ранее, отсутствие положительного коэффициента размытия приводит к вырождению SAM в базовый метод оптимизации параметров. Следовательно, и работа нашего объекта сводится к методам родительского класса.
В случае прохождения данной точки контроля, мы инициализируем и создаем в памяти OpenCL-контекста буфер скорректированных параметров входящих связей.
if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
Для создания буфера скорректированных параметров исходящих связей есть дополнительный критерий — наличие подобных связей. Поэтому перед его созданием мы проверяем актуальность указателя на соответствующий буфер.
if(!Weights) return true;
И в данном случае отсутствие актуального указателя не является критичным для работы программы, а лишь указывает на особенности архитектуры модели. Поэтому при отсутствии актуального указателя мы завершаем работу метода с положительным результатом.
В случае же наличия загруженного буфера исходящих связей, мы инициализируем и создаем аналогичного размера буфер для скорректированных параметров.
if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
После чего возвращаем логический результат выполнения операций вызывающей программе и завершаем работу метода.
На этом мы завершаем рассмотрение алгоритмов методов сверточного слоя с использованием подходов SAM оптимизации CNeuronConvSAMOCL. С полным кодом данного класса и всех его методов вы можете ознакомиться во вложении.
2. Добавляем SAM в Transformer
На данном этапе мы создали объекты полносвязного и сверточного слоев с использованием подходов SAM оптимизации параметров. И пришло время имплементировать предложенные подходы в архитектуру Transformer. Собственно, что и предлагалось авторами фреймворка SAMformer. И здесь, с целью объективной оценки влияния предложенных подходов на работу модели, мы не стали создавать новые классы. Вместо этого мы добавим предложенные подходы в структуру уже существующего класса. За основу мы возьмем трансформер с относительным внимание R-MAT.
Как вы знаете, в классе CNeuronRMAT построена линейная модель из последовательно чередующихся объектов CNeuronRelativeSelfAttention и CResidualConv. В первом реализован модуль относительного внимания с обратной связью, а во втором — модуль сверточных слоев с обратной связью. Для имплементации подходов SAM оптимизации нам достаточно заменить в структуре указанных объектов все сверточные слои на аналогичные с использованием SAM оптимизации. Новая структура классов представлена ниже.
class CNeuronRelativeSelfAttention : public CNeuronBaseOCL { protected: uint iWindow; uint iWindowKey; uint iHeads; uint iUnits; int iScore; //--- CNeuronConvSAMOCL cQuery; CNeuronConvSAMOCL cKey; CNeuronConvSAMOCL cValue; CNeuronTransposeOCL cTranspose; CNeuronBaseOCL cDistance; CLayer cBKey; CLayer cBValue; CLayer cGlobalContentBias; CLayer cGlobalPositionalBias; CLayer cMHAttentionPooling; CLayer cScale; CBufferFloat cTemp; //--- virtual bool AttentionOut(void); virtual bool AttentionGradient(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronRelativeSelfAttention(void) : iScore(-1) {}; ~CNeuronRelativeSelfAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRelativeSelfAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual uint GetWindow(void) const { return iWindow; } virtual uint GetUnits(void) const { return iUnits; } };
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvSAMOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); };
Обратите внимание, что для сверточного модуля с обратной связью мы только изменяем тип объекта в структуре класса. При этом не вносим корректировок в методы классов. Это стало возможным, благодаря перегрузке методов инициализации сверточного слоя с SAM инициализацией. Напомню, что в рамках класса CNeuronConvSAMOCL мы создали 2 метода инициализации: с и без коэффициента размытия в параметрах метода. Очевидно, что метод инициализации без указания коэффициента размытия переопределяет одноименный метод родительского класса, который мы использовали ранее при инициализации сверточных слоев. Следовательно, при инициализации объектов CResidualConv, когда вызывается метод инициализации сверточного слоя, программа будет обращаться уже к переопределенному нами методу. В котором добавится коэффициент размытия, установленный по умолчанию, и вызовется метод полноценной инициализации сверточного слоя с использованием подходов SAM оптимизации.
В случае же модуля относительного внимания, дела обстоят немного сложнее. Дело в том, что используемый нами модуль относительного внимания CNeuronRelativeSelfAttention имеет довольно сложную архитектуру, которая включает в себя дополнительные вложенные модели обучаемых смещений. Их архитектура задается в методе инициализации объекта. Следовательно, для добавления подходов SAM оптимизации внутренним моделям нам придется внести правки в метод инициализации модуля относительного внимания.
Параметры метода остаются без изменений, и первые шаги его алгоритма остаются без изменений. Тип объектов для генерации сущностей Query, Key и Value мы уже изменили в структуре класса.
bool CNeuronRelativeSelfAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; //--- iWindow = window; iWindowKey = window_key; iUnits = units_count; iHeads = heads; //--- int idx = 0; if(!cQuery.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cQuery.SetActivationFunction(GELU); idx++; if(!cKey.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cValue.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cTranspose.Init(0, idx, OpenCL, iUnits, iWindow, optimization, iBatch)) return false; idx++; if(!cDistance.Init(0, idx, OpenCL, iUnits * iUnits, optimization, iBatch)) return false;
Далее в моделях генерации смещений BKey и BValue мы осуществляем замену типов сверточных объектов с сохранением прочих параметров.
idx++; CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false;
idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false;
В моделях генерации смещений глобального контекста и позиций мы используем полносвязные слои с SAM оптимизацией.
idx++; CNeuronBaseOCL *neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false; idx++; CBufferFloat *buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false;
idx++; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false; idx++; buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false;
А для MLP операций пулинга мы вновь используем сверточные слои с использованием подходов SAM оптимизации.
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iHeads, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(None); CNeuronSoftMaxOCL *softmax = new CNeuronSoftMaxOCL(); if(!softmax || !softmax.Init(0, idx, OpenCL, iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(softmax) ) return false; softmax.SetHeads(iUnits);
Обратите внимание, что для первого слоя мы используем базовый полносвязный слой. Так как он используется лишь для записи результатов работы блока многоголового внимания.
Аналогичная ситуация с блоком масштабирования. В качестве первого слоя мы используем базовый полносвязный, так как он предназначен для записи результатов умножения коэффициентов значимости на результаты многоголового внимания. А за ним следуют сверточные слои с SAM оптимизацией.
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iUnits, optimization, iBatch) || !cScale.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey, iWindowKey, 2 * iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(LReLU); idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, 2 * iWindow, 2 * iWindow, iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(None); //--- if(!SetGradient(conv.getGradient(), true)) return false; //--- SetOpenCL(OpenCL); //--- return true; }
На этом мы завершаем работу по имплементации подходов SAM оптимизации в Transformer с относительным вниманием. С полным кодом обновленных объектов вы можете ознакомиться во вложении.
3. Архитектура моделей
Выше мы создали новые объекты и внесли изменения в некоторые существующие. Следующим этапом нашей работы будет корректировка архитектуры моделей. И в отличие от ряда последних статей, сегодня корректировка архитектуры моделей будет более глобальная. И начнем мы с архитектуры Энкодера окружающей среды, которая представлена в методе CreateEncoderDescriptions. Как и ранее, в параметрах метода мы получаем указатель на динамический массив для записи последовательности нейронных слове модели.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы проверяем актуальность полученного указателя и, при необходимости, создаем новый экземпляр динамического массива.
Первые 2 слоя мы оставляем без изменений. Это слой исходных данных и пакетной нормализации. Размер данных слоев идентичен и должен быть достаточным для записи тензора исходных данных.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее авторы фреймворка SAMformer предлагают использовать внимание по каналам. Поэтому мы используем слой транспонирования данных, который поможет нам представить исходные данные в виде последовательности каналов внимания.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window= BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Затем мы используем блок относительного внимания, в который мы уже внедрили подходы SAM оптимизации.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRMAT; descr.window=HistoryBars; descr.count=BarDescr; descr.window_out = EmbeddingSize/2; // Key Dimension descr.layers = 1; // Layers descr.step = 2; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И тут следует обратить внимание на 2 момента. Во-первых, мы используем канальное внимание. Поэтому окно анализа равно глубине анализируемой истории, а количество элементов приравнивается числу независимых каналов. Во-вторых, как и предлагали авторы фреймворка, мы используем только 1 слой внимания. Однако, в отличие от авторской реализации, мы используем 2 головы внимания. Кроме того, мы оставили блок FeedForward. Напомню, что авторы фреймворка использовали 1 голову внимания и удалили блок FeedForward.
Далее нам предстоит понизить размерность тензора результатов до заданного размера. Данную операцию мы будем выполнять в 2 этапа. Сначала мы воспользуемся сверточным слоем с SAM оптимизацией для понижения размерности отдельных каналов.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount/BarDescr; descr.probability = 0.7f; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
А затем воспользуемся полносвязным слоем с SAM оптимизацией для получения общего эмбединга текущего состояния окружающей среды заданного размера.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
В обоих случаях мы используем descr.probability для указания коэффициента области размытия.
И завершаем работу метода, вернув логический результат выполнения операций вызывающей программе. А саму архитектуру модели мы возвращаем по указателю динамического массива, который ранее получили в параметрах от вызывающей программы.
После создания архитектуры Энкодера окружающей среды, мы переходим к описанию слоев Актера и Критика. Описание обеих моделей мы генерируем в методе CreateDescriptions. И так как в данном методе мы создаем описание 2 моделей, то и в параметрах метода получаем 2 указателя на динамические массивы.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
В теле метода мы проверяем актуальность полученных указателей и, при необходимости, создаем новые динамические массивы.
Первой мы опишем архитектуру Актера. Первый слой данной модели представлен в виде полносвязного слоя с использованием подходов SAM оптимизации. Размер данного слоя равен вектору описания состояния счета.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.probability=0.7f; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Обратите внимание, что мы используем полносвязный слой с SAM оптимизацией для записи исходных данных. А для модели Энкодера окружающей среды в аналогичной ситуации использовался базовый полносвязный слой. Это связано с наличием последующего полносвязного слоя с SAM оптимизацией, которому для полноценной работы потребуется буфер скорректированных параметров предшествующего слоя.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Как и в Энкодере состояния окружающей среды, мы используем descr.probability для указания коэффициента области размытия. Для всех моделей мы используем единый коэффициент области размытия на уровне 0.7.
Два последовательных полносвязных слоя с SAM оптимизацией создают эмбединги текущего состояния счета, который мы далее объединяем с эмбедингом соответствующего состояния окружающей среды. Данный функционал выполняется слоем конкатенации данных.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Далее используется блок принятия решений из 3 полносвязных слоев с SAM оптимизацией.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
На выходе последнего слоя мы генерируем тензор, в 2 раза превышающий целевой вектор представления действий Актера. Это позволяет нам добавить стохастичность действий. Как и ранее, для этого мы используем слой латентного состояния автоэнкодера.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Напомню, что латентный слой автоэнкодера разделяет тензор исходных данных на две части: первая часть отражает средние значения распределений для каждого элемента выходной последовательности, в то время как вторая часть содержит дисперсии соответствующих распределений. Обучение этих средних значений и дисперсий в модуле принятия решений позволяет нам ограничить область генерации случайных значений латентным слоем автоэнкодера, который мы используем для внесения стохастичности в политику Актера.
Тут стоит добавить, что латентный слой автоэнкодера генерирует независимые значения для каждого элемента выходной последовательности. Однако мы ожидаем в них получить комплекс значений для совершения сделки: объем операции, уровни тейк-профита и стоп-лосса. Для придания целостности параметрам сделки, мы используем сверточный слой с SAM оптимизацией, который отдельно анализирует параметры длинных и коротких сделок.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Для ограничения области результатов данного слоя мы используем сигмовидную функцию активации.
И последним штрихом нашей модели Актера является слой прямого прогнозирования с частотным усилением (CNeuronFreDFOCL), который позволяет согласовать результаты работы модели с целевыми значениями в частотной области.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Похожую архитектуру получил и Критик. Только на вход модели мы подаем параметры сгенерированной Актером торговой операции, вместо описания состояния счета, передаваемого Актеру. Мы так же используем 2 полносвязных слоя с SAM оптимизацией для получения эмбединга торговой операции.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
Эмбединг торговой операции объединяется с эмбедингом состояния окружающей среды в слое конкатенации данных.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
И далее мы используем блок принятия решения из 3 последовательных полносвязных слоев с SAM оптимизацией. Но в отличие от Актера, в данном случае не используется стохастичность результатов.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
А на вершину модели Критика мы добавляем слой прямого прогнозирования с частотным усилением.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
После завершения генерации описания архитектуры моделей, мы завершаем работу метода, предварительно вернув логический результат выполнения операций вызывающей программе. Описание архитектуры моделей возвращается по указателям динамических массивов, которые были получены в параметрах метода.
На этом мы завершаем работу по построению моделей. А с их полной архитектурой вы можете познакомиться во вложении. Там же вы найдете полный код программ взаимодействия с окружающей средой и обучения моделей, которые были перенесены из предыдущих работ без изменений.
4. Тестирование
Мы проделали довольно большую работу по имплементации подходов, предложенных авторами фреймворка SAMformer. И теперь пришло время проверить эффективность реализованного решения на реальных исторических данных. Как и ранее, обучение моделей мы осуществляем на реальных исторических данных инструмента EURUSD за весь 2023 год. В процессе проведения экспериментов мы использовали данные таймфрейма H1. Все параметры анализируемых индикаторов были взяты по умолчанию.
Как было сказано выше, программы, используемые для взаимодействия с окружающей средой и обучения моделей, остались без изменений. Это позволяет нам использовать ранее созданные обучающие выборки для первичного обучения моделей. Более того, так как в качестве базовой модели для внедрения SAM оптимизации был избран фреймворк R-MAT, то мы решили не обновлять обучающую выборку в процессе обучения модели. Конечно, мы ожидаем, что это негативно скажется на результатах обучения моделей. Но такой подход позволит нам сравнить результаты с базовой моделью, исключая влияние изменения обучающей выборки.
Обучение всех 3 моделей мы осуществляли одномоментно. А результаты тестирования обученной политики Актера представлены ниже. Тестирование модели осуществлялось на реальных исторических данных за январь 2024 года с сохранением прочих параметров, используемых при обучении модели.
Но вначале стоит сказать несколько слов об обучении моделей. Прежде всего, SAM оптимизация предполагает сглаживание ландшафта функции потерь. А это, в свою очередь, позволяет рассматривать возможность использования большей скорости обучения. И если ранее при обучении моделей в основном использовалась скорость обучения на уровне 3.0e-04, то в данном случае мы увеличили её до 1.0e-03.
Кроме того, использование только одного слоя внимания позволило сократить количество обучаемых параметров, а вместе с тем и компенсировать затраты на повторное прохождение прямого прохода при выполнении алгоритма SAM оптимизации параметров.
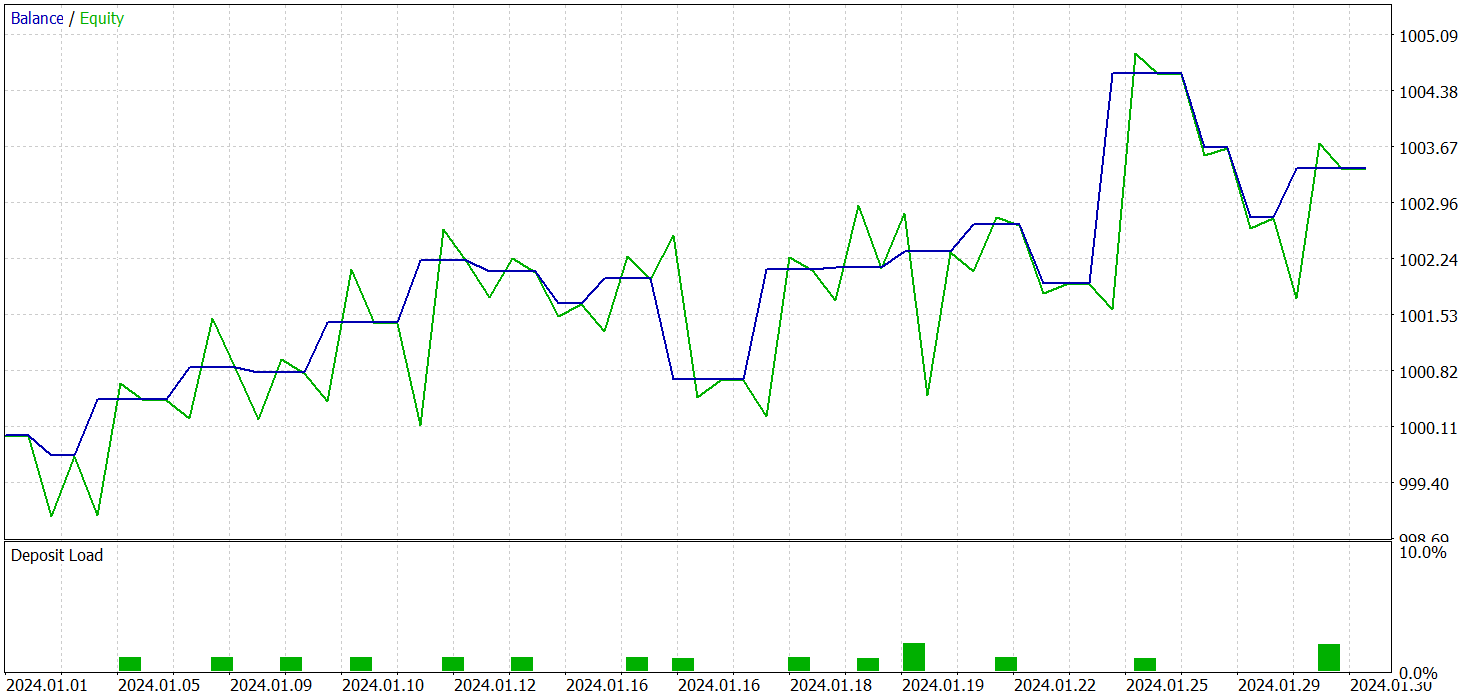
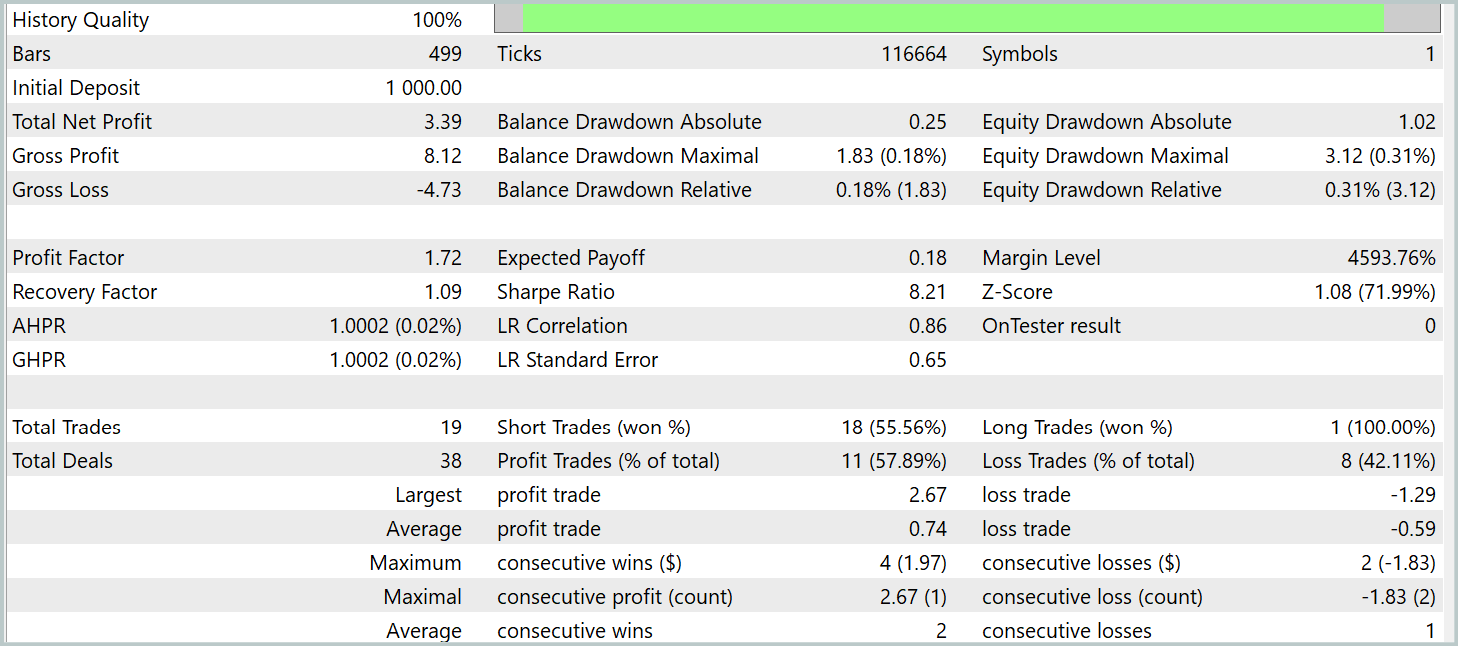
И в результате обучения модели нам удалось получить политику, способную генерировать прибыль вне обучающей выборки. За период тестирования модель совершила 19 торговых операций, 11 из которых было закрыто с прибылью (57,89%). Для сравнения, реализованная нами ранее модель R-MAT за тот же период совершила 15 торговых операций, 9 из которых было закрыто с прибылью (60.0%). При этом суммарная доходность новой модели почти в 2 раза превышает прибыль базовой.
Заключение
Фреймворк SAMformer представляет собой эффективное решение основных ограничений архитектуры Transformer, которые возникают при долгосрочном прогнозировании многомерных временных рядов. Традиционный Transformer сталкивается с рядом трудностей, включая высокую сложность обучения и слабую способность к обобщению, особенно на малых обучающих выборках.
Ключевыми преимуществами SAMformer являются его неглубокая архитектура и использование механизма оптимизации с учетом резкости (Sharpness-Aware Minimization). Эти подходы позволяют модели успешно избегать плохих локальных минимумов, улучшая стабильность и точность обучения, а также обеспечивая превосходную обобщающую способность.
В практической части нашей работы мы реализовали свое видение предложенных подходов средствами MQL5 и обучили модели на реальных исторических данных. Результаты тестирования обученных моделей подтверждают эффективность предложенных подходов и демонстрирует, что их внедрение позволяет повысить эффективность базовых моделей без дополнительных затрат на обучение. А в ряде случаев даже позволяет снизить затраты на обучение.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Годовой доход банков россии в доларах. Поделите на 12 и сравните.
В юанях 6, в юаневых облигашках более 10.
В юанях 6, в юаневых облигашках более 10.
Но в статье приведены результаты тестирования по EURUSD и результат в USD. При этом нагрузка на депозит 1-2%.И никто не писал, что это грааль.
Но в статье приведены результаты тестирования по EURUSD и результат в USD. При этом нагрузка на депозит 1-2%.И никто не писал, что это грааль.
ок. кэп в баксах в банках дают 5 %
Итого профит 0.35% в месяц? Не выгоднее ли просто положить деньги в банк?