
Neuronale Netze im Handel: Verbesserung des Wirkungsgrads der Transformer durch Verringerung der Schärfe (letzter Teil)

Einführung
Im vorangegangenen Artikel haben wir die theoretischen Aspekte des SAMformer(Sharpness-Aware Multivariate Transformer) Frameworks kennengelernt. Es handelt sich um ein innovatives Modell, das entwickelt wurde, um die inhärenten Grenzen traditioneller Transformer bei langfristigen Vorhersageaufgaben für multivariate Zeitreihendaten zu überwinden. Zu den Hauptproblemen eines einfachen Transformers gehören die hohe Trainingskomplexität, die schlechte Generalisierung bei kleinen Datensätzen und die Tendenz, in suboptimale lokale Minima zu fallen. Diese Einschränkungen behindern die Anwendbarkeit von Transformer-basierten Modellen in Szenarien mit begrenzten Eingangsdaten und hohen Anforderungen an die Vorhersagegenauigkeit.
Die Schlüsselidee hinter SAMformer liegt in der Verwendung einer flachen Architektur, die die Komplexität der Berechnungen reduziert und eine Überanpassung verhindert. Eine der zentralen Komponenten ist derSAM-Optimierungsmechanismus (Sharpness-Aware Minimization), der die Robustheit des Modells gegenüber leichten Parameterschwankungen erhöht und damit seine Generalisierungsfähigkeit und die Qualität der endgültigen Vorhersagen verbessert.
Dank dieser Funktionen liefert SAMformer eine hervorragende Prognoseleistung sowohl für synthetische als auch für reale Zeitreihendaten. Das Modell erreicht eine hohe Genauigkeit und reduziert gleichzeitig die Anzahl der Parameter erheblich, wodurch es effizienter wird und sich für den Einsatz in ressourcenbeschränkten Umgebungen eignet. Diese Vorteile eröffnen SAMformer eine breite Anwendung in Bereichen wie Finanzen, Gesundheitswesen, Lieferkettenmanagement und Energie, wo langfristige Prognosen eine entscheidende Rolle spielen.
Die Originalvisualisierung des Rahmens finden Sie unten.
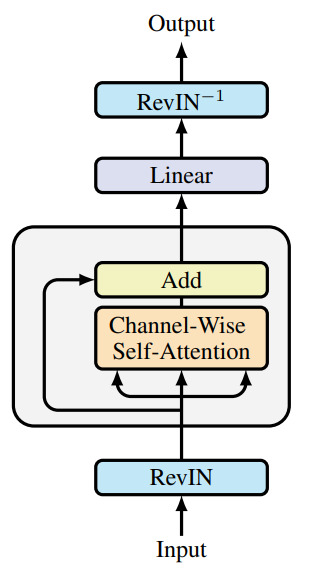
Wir haben bereits mit der Umsetzung der vorgeschlagenen Ansätze begonnen. Im letzten Artikel haben wir neue Kernel auf der OpenCL-Seite vorgestellt. Wir haben auch Verbesserungen der vollständig vernetzten Schicht diskutiert. Heute werden wir diese Arbeit fortsetzen.
1. Faltungsschicht mit SAM-Optimierung
Wir setzen die Arbeit fort, die wir begonnen haben. In einem nächsten Schritt erweitern wir die Faltungsschicht mit SAM-Optimierungsfunktionen. Wie zu erwarten, ist unsere neue Klasse CNeuronConvSAMOCL als Unterklasse der bestehenden Faltungsschicht CNeuronConvOCL implementiert. Die Struktur des neuen Objekts wird im Folgenden dargestellt.
class CNeuronConvSAMOCL : public CNeuronConvOCL { protected: float fRho; //--- CBufferFloat cWeightsSAM; CBufferFloat cWeightsSAMConv; //--- virtual bool calcEpsilonWeights(CNeuronBaseOCL *NeuronOCL); virtual bool feedForwardSAM(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronConvSAMOCL(void) { activation = GELU; } ~CNeuronConvSAMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronConvSAMOCL; } virtual int Activation(void) const { return (fRho == 0 ? (int)None : (int)activation); } virtual int getWeightsSAMIndex(void) { return cWeightsSAM.GetIndex(); } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Beachten Sie, dass die vorgestellte Struktur zwei Puffer zur Speicherung der eingestellten Parameter enthält. Ein Puffer ist für ausgehende Verbindungen vorgesehen, ähnlich wie bei der vollständig verbundenen Schicht (cWeightsSAM). Eine weitere ist für eingehende Verbindungen (cWeightsSAMConv). Beachten Sie, dass die übergeordnete Klasse eine solche Duplizierung von Parameterpuffern nicht ausdrücklich vorsieht. Der Puffer für die Gewichte der ausgehenden Verbindungen wird nämlich in der übergeordneten, vollständig verbundenen Schicht definiert.
Hier standen wir vor dem Dilemma, ob wir die SAM-Funktionalität von der vollständig verknüpften Schicht oder von der bestehenden Faltungsschicht übernehmen sollten. Im ersten Fall bräuchten wir keinen neuen Puffer für angepasste ausgehende Verbindungen zu definieren, da er vererbt würde. Dies würde jedoch bedeuten, dass wir die Methoden der Faltungsschicht komplett neu implementieren müssten.
Im zweiten Szenario behalten wir durch die Übernahme der Faltungsschicht deren gesamte Funktionalität bei. Allerdings fehlt bei diesem Ansatz der Puffer für angepasste ausgehende Gewichte, der für das ordnungsgemäße Funktionieren der anschließenden SAM-optimierten Schicht mit voller Vernetzung erforderlich ist.
Wir haben uns für die zweite Möglichkeit der Vererbung entschieden, da sie weniger Aufwand für die Implementierung der benötigten Funktionen erfordert.
Wie zuvor deklarieren wir zusätzliche interne Objekte statisch, sodass wir den Konstruktor und Destruktor leer lassen können. Dennoch setzen wir im Konstruktor der Klasse GELU als Standard-Aktivierungsfunktion festgelegt. Alle übrigen Initialisierungsschritte sowohl für geerbte als auch für neu deklarierte Objekte werden in der Methode Init durchgeführt. Hier werden Sie feststellen, dass zwei Methoden mit demselben Namen, aber unterschiedlichen Parametersätzen überschrieben werden. Wir werden zunächst die Version mit der umfangreichsten Parameterliste untersuchen.
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, optimization_type, batch)) return false;
In den Methodenparametern erhalten wir die wichtigsten Konstanten, mit denen wir die Architektur des zu erstellenden Objekts eindeutig bestimmen können. Wir übergeben fast alle diese Parameter sofort an die gleichnamige Methode der Elternklasse, in der alle notwendigen Kontrollpunkte und Initialisierungsalgorithmen für geerbte Objekte bereits implementiert sind.
Nach der erfolgreichen Ausführung der Methode der übergeordneten Klasse speichern wir den Koeffizienten der Unschärferegion in einer internen Variablen. Dies ist der einzige Parameter, den wir nicht an die übergeordnete Methode übergeben.
fRho = fabs(rho); if(fRho == 0) return true;
Wir prüfen dann sofort den gespeicherten Wert. Ist der Unschärfekoeffizient gleich Null, degeneriert der Optimierungsalgorithmus SAM zur Basisparameter-Optimierungsmethode. In diesem Fall sind alle erforderlichen Komponenten bereits von der übergeordneten Klasse initialisiert worden. Wir können also ein erfolgreiches Ergebnis zurückgeben.
Andernfalls initialisieren wir zunächst den Puffer für die eingestellten eingehenden Verbindungen mit Nullwerten.
cWeightsSAMConv.BufferFree(); if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
Als Nächstes wird, falls erforderlich, der Puffer für die angepassten Ausgangsparameter in ähnlicher Weise initialisiert.
cWeightsSAM.BufferFree(); if(!Weights) return true; if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
Beachten Sie, dass dieser letzte Puffer nur initialisiert wird, wenn ausgehende Verbindungsparameter vorhanden sind. Dies ist der Fall, wenn auf die Faltungsschicht eine vollständig verbundene Schicht folgt.
Nach erfolgreicher Initialisierung aller internen Komponenten gibt die Methode das logische Ergebnis der Operation an das aufrufende Programm zurück.
Die zweite Initialisierungsmethode in unserer Klasse überschreibt die Methode der Elternklasse vollständig und hat identische Parameter. Wie Sie vielleicht schon vermutet haben, fehlt jedoch der Parameter Unschärfekoeffizient, der für die Optimierung von SAM entscheidend ist. Im Methodenkörper wird ein Standard-Weichzeichnungskoeffizient von 0,7 zugewiesen. Dieser Koeffizient wurde in dem ursprünglichen Artikel zur Einführung des Rahmens von SAMformer erwähnt. Anschließend rufen wir die zuvor beschriebene Methode zur Initialisierung der Klasse auf.
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { return CNeuronConvSAMOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, 0.7f, optimization_type, batch); }
Dieser Ansatz ermöglicht es uns, eine reguläre Faltungsschicht mit ihrem SAM-optimierten Gegenstück in fast jeder der zuvor besprochenen Architekturkonfigurationen auszutauschen, indem wir einfach den Objekttyp ändern.
Wie bei der vollständig verknüpften Schicht wird die gesamte Funktionalität des Vorwärtsdurchlaufs und der Gradientenverteilung von der übergeordneten Klasse geerbt. Wir führen jedoch zwei Wrapper-Methoden für den Aufruf von OpenCL-Programmkernen ein: calcEpsilonWeights und feedForwardSAM. Die erste Methode ruft den Kernel auf, der für die Berechnung der angepassten Parameter zuständig ist. Die zweite Methode entspricht der übergeordneten Methode für den Vorwärtsdurchlauf, verwendet aber stattdessen den angepassten Parameterpuffer. Wir werden hier nicht auf die detaillierte Logik dieser Methoden eingehen. Sie folgen denselben Kernel-Queuing-Algorithmen, die bereits besprochen wurden. Sie können deren vollständige Implementierungen im beigefügten Quellcode erkunden.
Die Parameteroptimierungsmethode dieser Klasse ähnelt sehr ihrem Gegenstück in der vollverknüpften SAM-optimierten Schicht. In diesem Fall prüfen wir jedoch nicht den Typ der vorhergehenden Ebene. Im Gegensatz zu vollständig verknüpften Schichten enthält eine Faltungsschicht ihre eigene interne Parametermatrix, die auf die Eingabedaten angewendet wird. Daher verwendet es seinen eigenen angepassten Parameterpuffer. Alles, was sie von der vorherigen Schicht benötigt, ist der Eingangsdatenpuffer, den alle unsere Objekte bereitstellen.
Nichtsdestotrotz überprüfen wir den Wert des Unschärfekoeffizienten. Wenn er Null ist, wird die SAM-Optimierung effektiv umgangen. In diesem Fall verwenden wir einfach die Methode der übergeordneten Klasse.
bool CNeuronConvSAMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(fRho <= 0) return CNeuronConvOCL::updateInputWeights(NeuronOCL);
Wenn die SAM-Optimierung aktiviert ist, wird zunächst der Fehlergradient mit den Ergebnissen des Feedforward-Passes kombiniert, um den Zieltensor des aktuellen Objekts zu ermitteln:
if(!SumAndNormilize(Gradient, Output, Gradient, iWindowOut, false, 0, 0, 0, 1)) return false;
Als Nächstes aktualisieren wir die Modellparameter mit Hilfe des Unschärfekoeffizienten. Dazu muss der Wrapper aufgerufen werden, der den entsprechenden Kernel einreiht. Beachten Sie, dass sowohl Faltungsschichten als auch vollständig verbundene Schichten Methoden mit identischen Namen verwenden. Sie stehen jedoch in einer Warteschlange für verschiedene Kernel, die für die jeweiligen internen Architekturen spezifisch sind.
if(!calcEpsilonWeights(NeuronOCL)) return false;
Das Gleiche gilt für die Methoden für den Vorwärtsdurchlauf mit angepassten Parametern.
if(!feedForwardSAM(NeuronOCL)) return false;
Nach einem erfolgreichen zweiten Vorwärtsdurchlauf wird die Abweichung von den Zielwerten berechnet.
float error = 1; if(!calcOutputGradients(Gradient, error)) return false;
Anschließend rufen wir die Methode der übergeordneten Klasse auf, um die Parameter des Modells zu aktualisieren.
//--- return CNeuronConvOCL::updateInputWeights(NeuronOCL); }
Schließlich wird das logische Ergebnis an das aufrufende Programm zurückgegeben, womit die Methode abgeschlossen ist.
Noch ein paar Worte zur Speicherung der Parameter des trainierten Modells. Beim Speichern des trainierten Modells folgen wir demselben Ansatz, der im Zusammenhang mit der voll verknüpften SAM-Schicht beschrieben wurde. Wir speichern die Puffer mit den eingestellten Parametern nicht. Stattdessen wird nur der Unschärfekoeffizient zu den von der übergeordneten Klasse gespeicherten Daten hinzugefügt.
bool CNeuronConvSAMOCL::Save(const int file_handle) { if(!CNeuronConvOCL::Save(file_handle)) return false; if(FileWriteFloat(file_handle, fRho) < INT_VALUE) return false; //--- return true; }
Beim Laden eines vorab trainierten Modells müssen wir die erforderlichen Puffer vorbereiten. Es ist wichtig zu beachten, dass die Kriterien für die Erstellung von Puffern für angepasste eingehende und ausgehende Parameter unterschiedlich sind.
Zunächst laden wir die von der übergeordneten Klasse gespeicherten Daten.
bool CNeuronConvSAMOCL::Load(const int file_handle) { if(!CNeuronConvOCL::Load(file_handle)) return false;
Als Nächstes wird geprüft, ob die Datei weitere Daten enthält, und dann der Unschärfekoeffizient gelesen.
if(FileIsEnding(file_handle)) return false; fRho = FileReadFloat(file_handle);
Ein positiver Unschärfekoeffizient ist die wichtigste Voraussetzung für die Initialisierung der angepassten Parameterpuffer. Wir prüfen also den Wert des geladenen Parameters. Wenn diese Bedingung nicht erfüllt ist, werden alle unbenutzten Puffer im OpenCL-Kontext und im Hauptspeicher gelöscht. Danach schließen wir die Methode mit einem positiven Ergebnis ab.
cWeightsSAMConv.BufferFree(); cWeightsSAM.BufferFree(); cWeightsSAMConv.Clear(); cWeightsSAM.Clear(); if(fRho <= 0) return true;
Dies ist einer der Fälle, in denen der Kontrollpunkt für die Programmausführung unkritisch ist. Wie bereits erwähnt, reduziert ein Unschärfekoeffizient von Null SAM auf eine einfache Optimierungsmethode. In diesem Fall greift unser Objekt also auf die Funktionalität der übergeordneten Klasse zurück.
Wenn die Bedingung erfüllt ist, wird der OpenCL-Kontext für die angepassten Eingangsparameter initialisiert und Speicher zugewiesen.
if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
Um den Puffer für angepasste Ausgangsparameter zu erstellen, muss eine weitere Bedingung erfüllt sein: das Vorhandensein solcher Verbindungen. Deshalb überprüfen wir die Gültigkeit des Zeigers vor der Initialisierung.
if(!Weights) return true;
Auch hier ist das Fehlen eines gültigen Zeigers kein kritischer Fehler. Sie spiegelt lediglich die Architektur des Modells wider. Wenn es also keinen aktuellen Zeiger gibt, beenden wir die Methode mit einem positiven Ergebnis.
Wenn ein Puffer für ausgehende Verbindungen gefunden wird, wird ein ähnlich großer Puffer für die eingestellten Parameter initialisiert und angelegt.
if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
Dann geben wir das logische Ergebnis der Operation an den Aufrufer zurück und beenden die Ausführung der Methode.
Damit schließen wir unsere Untersuchung der Faltungsschichtmethoden ab, die SAM-Optimierung in CNeuronConvSAMOCL implementieren. Der vollständige Code dieser Klasse und alle ihre Methoden sind im Anhang zu finden.
2. Hinzufügen von SAM zum Transformer
In diesem Stadium haben wir sowohl voll verknüpfte als auch Faltungsschichten erstellt, die eine SAM-basierte Parameteroptimierung beinhalten. Es ist nun an der Zeit, diese Ansätze in die Transformer-Architektur zu integrieren. Dies entspricht genau dem Vorschlag der Autoren des SAMformer. Um die Auswirkungen dieser Techniken auf die Modellleistung objektiv zu bewerten, haben wir beschlossen, keine völlig neuen Klassen zu erstellen. Stattdessen haben wir die SAM-basierten Ansätze direkt in die Struktur einer bestehenden Klasse integriert. Für die Basisarchitektur haben wir den Transformer R-MAT mit relativer Aufmerksamkeit gewählt.
Wie Sie wissen, implementiert die Klasse CNeuronRMAT eine lineare Folge der abwechselnden Objekte CNeuronRelativeSelfAttention und CResidualConv. Der erste implementiert den Mechanismus der relativen Aufmerksamkeit mit Rückkopplung, während der zweite einen rückkopplungsbasierten Faltungsblock enthält. Um die Optimierung in SAM zu integrieren, reicht es aus, alle Faltungsschichten in diesen Objekten durch ihre SAM-fähigen Gegenstücke zu ersetzen. Die aktualisierte Klassenstruktur ist unten dargestellt.
class CNeuronRelativeSelfAttention : public CNeuronBaseOCL { protected: uint iWindow; uint iWindowKey; uint iHeads; uint iUnits; int iScore; //--- CNeuronConvSAMOCL cQuery; CNeuronConvSAMOCL cKey; CNeuronConvSAMOCL cValue; CNeuronTransposeOCL cTranspose; CNeuronBaseOCL cDistance; CLayer cBKey; CLayer cBValue; CLayer cGlobalContentBias; CLayer cGlobalPositionalBias; CLayer cMHAttentionPooling; CLayer cScale; CBufferFloat cTemp; //--- virtual bool AttentionOut(void); virtual bool AttentionGradient(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronRelativeSelfAttention(void) : iScore(-1) {}; ~CNeuronRelativeSelfAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRelativeSelfAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual uint GetWindow(void) const { return iWindow; } virtual uint GetUnits(void) const { return iUnits; } };
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvSAMOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); };
Beachten Sie, dass wir für das Feedback-Faltungsmodul nur den Objekttyp in der Klassenstruktur ändern. Es sind keine Änderungen an den Klassenmethoden erforderlich. Dies ist dank unserer überladenen Initialisierungsmethoden für Faltungsschichten mit SAM-Initialisierung möglich. Erinnern Sie sich, dass die Klasse CNeuronConvSAMOCL zwei Initialisierungsmethoden bietet: eine mit dem Unschärfekoeffizienten als Parameter und eine ohne ihn. Die Methode ohne den Unschärfekoeffizienten setzt die Methode der Elternklasse außer Kraft, die zuvor zur Initialisierung von Faltungsschichten verwendet wurde. Daher ruft das Programm bei der Initialisierung der Objekte CResidualConv unsere überschriebene Initialisierungsmethode auf, die automatisch einen Standard-Weichzeichnungskoeffizienten zuweist und die vollständige Initialisierung der Faltungsschicht mit SAM-Optimierung auslöst.
Die Situation beim Modul für relative Aufmerksamkeit ist etwas komplexer. Das Modul CNeuronRelativeSelfAttention hat eine komplexere Architektur, die zusätzliche verschachtelte trainierbare Bias-Modelle umfasst. Ihre Architektur wird in der Objektinitialisierungsmethode definiert. Um die SAM-Optimierung für diese internen Modelle zu ermöglichen, müssen wir daher die Initialisierungsmethode des Moduls für relative Aufmerksamkeit selbst ändern.
Die Parameter der Methode bleiben unverändert, und auch die ersten Schritte des Algorithmus werden beibehalten. Die Objekttypen für die Generierung der Entitäten Query (Abfrage), Key (Schlüssel) und Value (Wert) sind bereits in der Klassenstruktur aktualisiert worden.
bool CNeuronRelativeSelfAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; //--- iWindow = window; iWindowKey = window_key; iUnits = units_count; iHeads = heads; //--- int idx = 0; if(!cQuery.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cQuery.SetActivationFunction(GELU); idx++; if(!cKey.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cValue.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cTranspose.Init(0, idx, OpenCL, iUnits, iWindow, optimization, iBatch)) return false; idx++; if(!cDistance.Init(0, idx, OpenCL, iUnits * iUnits, optimization, iBatch)) return false;
Außerdem ersetzen wir in den Modellen zur Erzeugung der Verschiebungen von BKey- und BValue die Typen der Faltungsobjekte unter Beibehaltung der übrigen Parameter.
idx++; CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false;
idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false;
In den Modellen zur Erzeugung globaler Kontext- und Positionsverzerrungen verwenden wir vollständig verbundene Schichten mit SAM-Optimierung.
idx++; CNeuronBaseOCL *neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false; idx++; CBufferFloat *buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false;
idx++; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false; idx++; buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false;
Für die Pooling-Operation MLP verwenden wir wieder Faltungsschichten mit SAM-Optimierungsansätzen.
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iHeads, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(None); CNeuronSoftMaxOCL *softmax = new CNeuronSoftMaxOCL(); if(!softmax || !softmax.Init(0, idx, OpenCL, iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(softmax) ) return false; softmax.SetHeads(iUnits);
Beachten Sie, dass wir für die erste Schicht immer noch die Basisschicht verwenden, die vollständig verbunden ist. Denn sie wird ausschließlich zur Speicherung der Ausgabe des Multi-Head-Attention-Blocks verwendet.
Ähnlich verhält es sich mit dem Skalierungsblock. Die erste Schicht bleibt eine voll verknüpfte Basisschicht, da sie das Ergebnis der Multiplikation der Aufmerksamkeitsgewichte mit den Ausgängen des Multi-Head Attention Blocks speichert. Darauf folgen Faltungsschichten mit SAM-Optimierung.
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iUnits, optimization, iBatch) || !cScale.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey, iWindowKey, 2 * iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(LReLU); idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, 2 * iWindow, 2 * iWindow, iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(None); //--- if(!SetGradient(conv.getGradient(), true)) return false; //--- SetOpenCL(OpenCL); //--- return true; }
Damit schließen wir die Integration von SAM-Optimierungsansätzen in den Transformer mit relativer Aufmerksamkeit ab. Der vollständige Code für die aktualisierten Objekte ist im Anhang enthalten.
3. Modell der Architektur
Wir haben neue Objekte erstellt und einige bestehende aktualisiert. Der nächste Schritt ist die Anpassung der gesamten Modellarchitektur. Im Gegensatz zu einigen kürzlich erschienenen Artikeln sind die heutigen architektonischen Änderungen umfangreicher. Wir beginnen mit der Architektur der Umgebung Encoder, die in der Methode CreateEncoderDescriptions implementiert ist. Wie zuvor erhält diese Methode einen Zeiger auf ein dynamisches Array, in dem die Abfolge der Modellebenen aufgezeichnet wird.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Im Methodenrumpf prüfen wir die Relevanz des empfangenen Zeigers und erstellen gegebenenfalls eine neue Instanz des dynamischen Arrays.
Wir lassen die ersten 2 Schichten unverändert. Dies sind die Quelldaten- und Batch-Normalisierungsebenen. Die Größe dieser Schichten ist identisch und muss ausreichend sein, um den ursprünglichen Datentensor zu erfassen.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes schlagen die Autoren des SAMformer-Rahmens vor, die Aufmerksamkeit nach Kanälen zu verteilen. Daher verwenden wir eine Datentranspositionsebene, mit deren Hilfe wir die Originaldaten als eine Folge von Aufmerksamkeitskanälen darstellen können.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window= BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Dann verwenden wir den relativen Aufmerksamkeitsblock, in den wir bereits SAM-Optimierungsansätze eingefügt haben.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRMAT; descr.window=HistoryBars; descr.count=BarDescr; descr.window_out = EmbeddingSize/2; // Key Dimension descr.layers = 1; // Layers descr.step = 2; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Hier sind zwei wichtige Punkte zu beachten. Erstens, wir nutzen die Aufmerksamkeit der Kanäle. Daher entspricht das Analysefenster der Tiefe des analysierten Verlaufs, und die Anzahl der Elemente entspricht der Anzahl der unabhängigen Kanäle. Zweitens verwenden wir, wie von den Autoren des SAMformer-Rahmens vorgeschlagen, nur eine Aufmerksamkeitsebene. Anders als bei der ursprünglichen Implementierung verwenden wir jedoch zwei Aufmerksamkeitsköpfe. Wir haben auch den Block FeedForward beibehalten. Allerdings haben die Autoren des Rahmens nur einen Aufmerksamkeitskopf verwendet und die Komponente FeedForward entfernt.
Als Nächstes müssen wir die Dimensionalität des Ausgangstensors auf die gewünschte Größe reduzieren. Dies geschieht in zwei Schritten. Zunächst wenden wir eine Faltungsschicht mit SAM-Optimierung an, um die Dimensionalität der einzelnen Kanäle zu reduzieren.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount/BarDescr; descr.probability = 0.7f; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Dann verwenden wir eine vollständig verbundene Schicht mit SAM-Optimierung, um eine allgemeine Einbettung des aktuellen Umweltzustands einer bestimmten Größe zu erhalten.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
In beiden Fällen verwenden wir descr.probability, um den Flächenkoeffizienten der Unschärfe anzugeben.
Die Methode schließt mit der Rückgabe des logischen Ergebnisses der Operation an den Aufrufer ab. Die Modellarchitektur selbst wird über den als Parameter übergebenen dynamischen Array-Zeiger zurückgegeben.
Nachdem wir die Architektur des Environment Encoders definiert haben, beschreiben wir die Schichten von Actor (Akteur) und Critic (Kritiker). Die Beschreibungen der beiden Modelle werden mit der Methode CreateDescriptions erstellt. Da diese Methode zwei separate Modellbeschreibungen erstellt, enthalten ihre Parameter zwei Zeiger auf dynamische Arrays.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Innerhalb der Methode überprüfen wir die Gültigkeit der übergebenen Zeiger und erstellen gegebenenfalls neue dynamische Arrays.
Wir beginnen mit der Architektur des Akteurs. Die erste Schicht dieses Modells ist als vollständig verbundene Schicht mit SAM-Optimierung implementiert. Seine Größe entspricht dem Zustandsbeschreibungsvektor des Handelskontos.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.probability=0.7f; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Es ist erwähnenswert, dass wir hier eine SAM-optimierte, vollständig verbundene Schicht verwenden, um die Eingabedaten zu erfassen. In der Umgebung des Encoders wurde an ähnlicher Stelle eine voll verknüpfte Basisschicht verwendet. Dieser Unterschied ist auf das Vorhandensein einer nachfolgenden, vollständig verbundenen Schicht mit SAM-Optimierung zurückzuführen, die von der vorhergehenden Schicht einen Puffer mit angepassten Parametern für einen korrekten Betrieb verlangt.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Wie beim Umgebungskodierer verwenden wir descr.probability, um den Koeffizienten der Unschärferegion festzulegen. Für alle Modelle wird ein einheitlicher Koeffizient von 0,7 verwendet.
Zwei aufeinanderfolgende SAM-optimierte, vollständig verbundene Schichten erzeugen Einbettungen des aktuellen Zustands des Handelskontos, die dann mit der entsprechenden Einbettung des Umgebungszustands verkettet werden. Diese Verkettung wird von einer speziellen Datenverkettungsschicht durchgeführt.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Ergebnis wird an einen Entscheidungsblock weitergeleitet, der aus drei SAM-optimierten, vollständig verbundenen Schichten besteht.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Am Ausgang der letzten Schicht erzeugen wir einen Tensor, der doppelt so groß ist wie der Zielvektor des Akteurs. Diese Konstruktion ermöglicht es uns, Stochastik in die Aktionen einzubauen. Wie bisher verwenden wir dazu die latente Zustandsschicht eines Autoencoders.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Erinnern Sie sich daran, dass die latente Schicht eines Autoencoders den Eingabetensor in zwei Teile aufteilt: Der erste Teil enthält die Mittelwerte der Verteilungen für jedes Element der Ausgabesequenz, und der zweite Teil enthält die Varianzen der entsprechenden Verteilungen. Das Training dieser Mittelwerte und Varianzen im Entscheidungsfindungsmodul ermöglicht es uns, den Bereich der generierten Zufallswerte über die latente Schicht des Autoencoders einzuschränken und so Stochastizität in die Politik des Akteurs einzuführen.
Es sollte hinzugefügt werden, dass die latente Schicht des Autoencoders unabhängige Werte für jedes Element der Ausgabesequenz erzeugt. In unserem Fall erwarten wir jedoch einen kohärenten Satz von Parametern für die Ausführung eines Handels: Positionsgröße, Take-Profit und Stop-Loss. Um die Konsistenz zwischen diesen Handelsparametern zu gewährleisten, verwenden wir eine SAM-optimierte Faltungsschicht, die die Parameter für Long- und Short-Trades getrennt analysiert.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Um den Ausgabebereich dieser Schicht zu begrenzen, verwenden wir eine sigmoidale Aktivierungsfunktion.
Den letzten Schliff erhält unser Actor-Modell durch eine frequenzverstärkte Vorwärtsdurchlauf-Vorhersageschicht (CNeuronFreDFOCL), die es ermöglicht, die Ergebnisse des Modells mit den Zielwerten im Frequenzbereich abzugleichen.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Modell des Kritikers hat eine ähnliche Architektur. Anstatt jedoch den Zustand des an den Akteur übergebenen Kontos zu beschreiben, füttern wir das Modell mit den Parametern der vom Akteur generierten Handelsoperation. Wir verwenden auch 2 vollständig verbundene Schichten mit SAM-Optimierung, um die Einbettung von Handelsoperationen zu erreichen.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
Die Einbettung der Handelsoperationen wird mit der Einbettung des Umweltzustands in der Datenverkettungsschicht kombiniert.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Und dann verwenden wir einen Entscheidungsblock aus 3 aufeinanderfolgenden, vollständig verknüpften Schichten mit SAM-Optimierung. Im Gegensatz zum Akteur wird in diesem Fall jedoch nicht die stochastische Natur der Ergebnisse genutzt.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
Auf das Kritiker-Modell wird eine Vorwärtsvorhersage-Schicht mit Frequenzverstärkung aufgesetzt.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Nach Abschluss der Generierung der Modellarchitekturbeschreibungen wird die Methode durch Rückgabe des logischen Ergebnisses der Operationen an den Aufrufer beendet. Die Architekturbeschreibungen selbst werden über die in den Methodenparametern enthaltenen dynamischen Array-Zeiger zurückgegeben.
Damit ist unsere Arbeit an der Modellkonstruktion abgeschlossen. Die vollständige Architektur finden Sie in den Anhängen. Dort finden Sie auch den vollständigen Quellcode für die Programme zur Interaktion mit der Umgebung und zur Modellschulung, die ohne Änderungen aus früheren Arbeiten übernommen wurden.
4. Tests
Wir haben viel Arbeit in die Umsetzung der von den Autoren des Rahmens von SAMformer vorgeschlagenen Ansätze gesteckt. Nun ist es an der Zeit, die Effektivität unserer Implementierung anhand echter historischer Daten zu bewerten. Wie zuvor wurde das Modelltraining mit aktuellen historischen Daten für das Instrument EURUSD durchgeführt, die das gesamte Jahr 2023 abdecken. Bei allen Experimenten wurde der Zeitrahmen H1 verwendet. Alle Indikatorparameter wurden auf ihre Standardwerte gesetzt.
Wie bereits erwähnt, blieben die Programme, die für die Interaktion mit der Umwelt und die Ausbildung der Modelle zuständig sind, unverändert. Dadurch können wir die zuvor erstellten Trainingsdatensätze für das anfängliche Training unserer Modelle wiederverwenden. Da der Rahmen von R-MAT als Basis für die SAM-Optimierung gewählt wurde, haben wir beschlossen, die Trainingsmenge während des Modelltrainings nicht zu aktualisieren. Natürlich erwarten wir, dass sich diese Wahl negativ auf die Modellleistung auswirkt. Sie ermöglicht jedoch einen direkteren Vergleich mit dem Basismodell, da sie jeglichen Einfluss von Änderungen im Trainingsdatensatz ausschließt.
Das Training für alle drei Modelle wurde gleichzeitig durchgeführt. Die Ergebnisse des Tests der trainierten Politik des Akteurs werden im Folgenden vorgestellt. Die Tests wurden mit echten historischen Daten für Januar 2024 durchgeführt, wobei alle anderen Trainingsparameter unverändert blieben.
Bevor ich auf die Ergebnisse eingehe, möchte ich einige Punkte zur Modellausbildung erwähnen. Erstens glättet die SAM-Optimierung von Natur aus die Verlustlandschaft. Dies wiederum ermöglicht es uns, höhere Lernraten zu berücksichtigen. Während wir in früheren Arbeiten hauptsächlich eine Lernrate von 3,0e-04 verwendet haben, haben wir sie in diesem Fall auf 1,0e-03 erhöht.
Zweitens wurde durch die Verwendung nur einer einzigen Aufmerksamkeitsschicht die Gesamtzahl der trainierbaren Parameter reduziert, was dazu beitrug, den Rechenaufwand zu kompensieren, der durch den zusätzlichen Vorwärtsdurchlauf, der für die SAM-Optimierung erforderlich ist, entsteht.
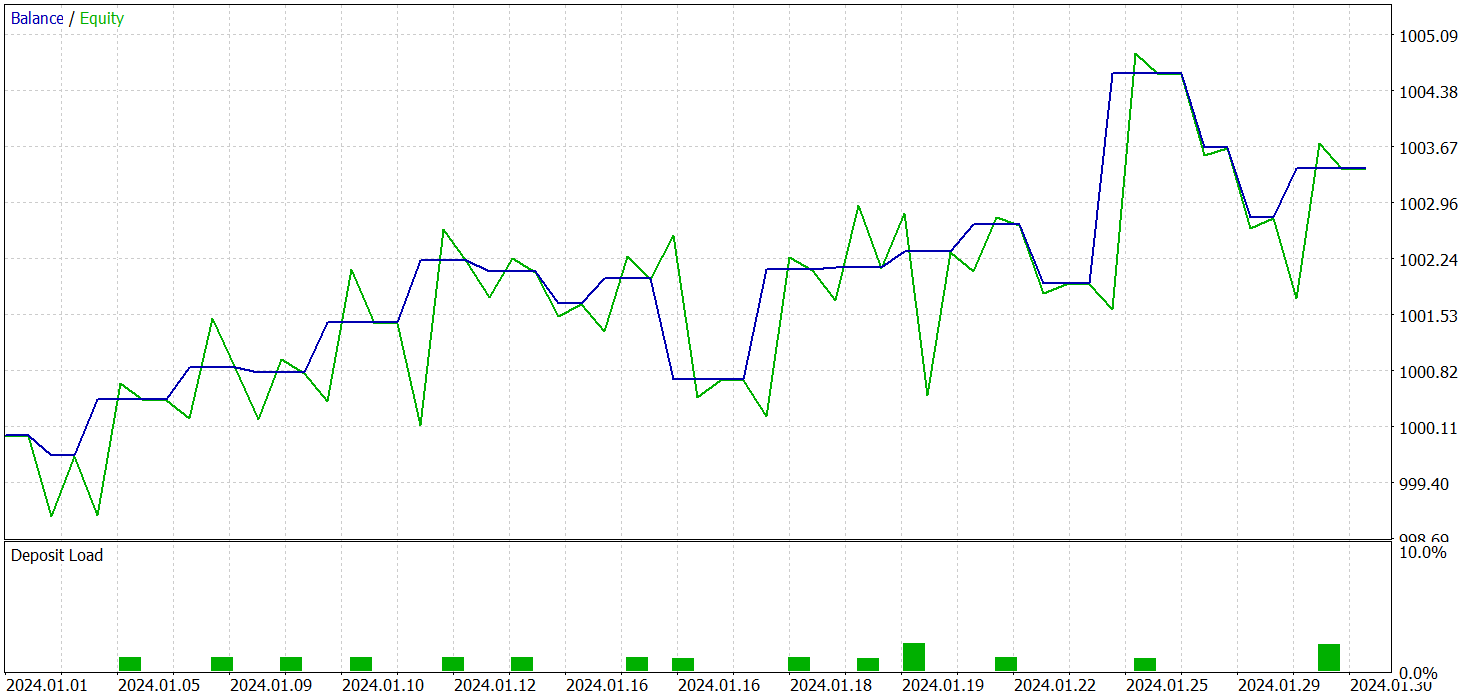
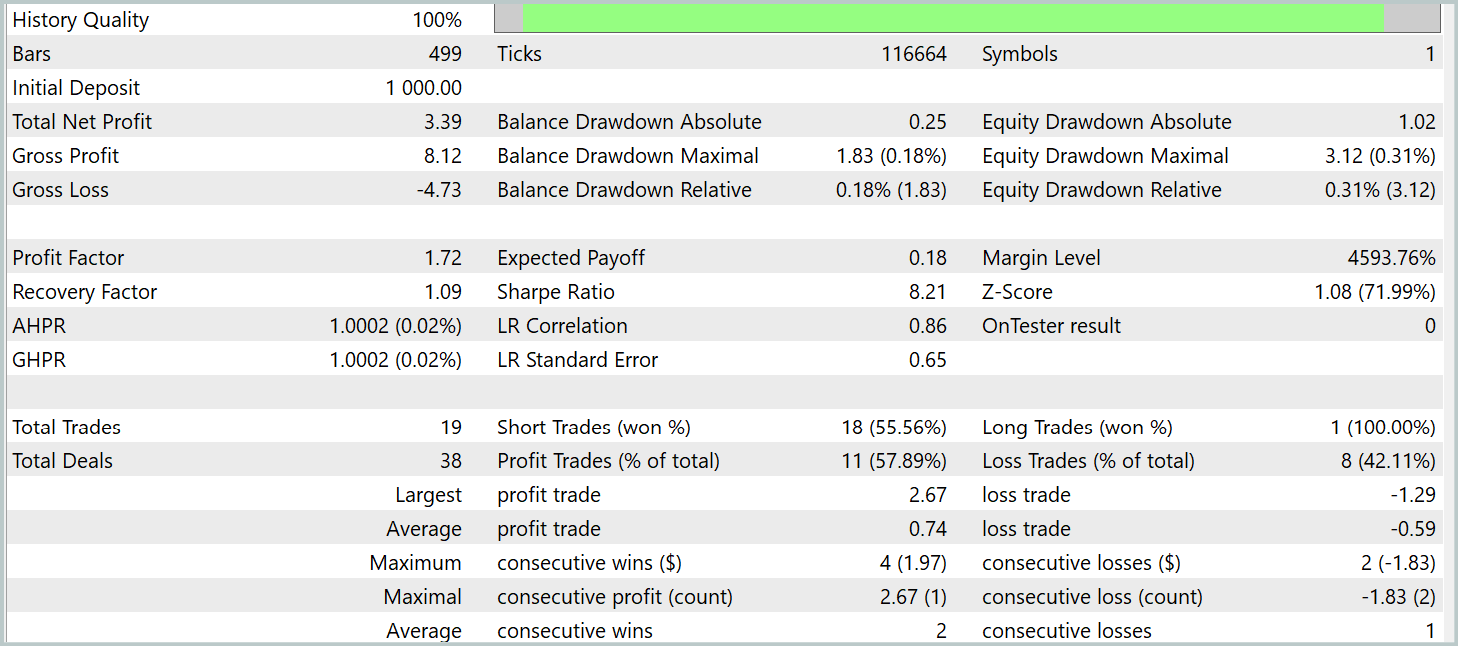
Als Ergebnis des Trainings haben wir eine Strategie erhalten, die in der Lage ist, auch außerhalb des Trainingsdatensatzes Gewinne zu erzielen. Während des Testzeitraums führte das Modell 19 Handelsgeschäfte aus, von denen 11 profitabel waren (57,89 %). Im Vergleich dazu führte unser zuvor implementiertes R-MAT-Modell im gleichen Zeitraum 15 Trades aus, von denen 9 profitabel waren (60,0 %). Die Gesamtrendite des neuen Modells war fast doppelt so hoch wie die des Basismodells.
Schlussfolgerung
Der Rahmen von SAMformer bietet eine effektive Lösung für die wichtigsten Einschränkungen der Transformer-Architektur im Zusammenhang mit langfristigen Prognosen für multivariate Zeitreihen. Ein herkömmlicher Transformer steht vor großen Herausforderungen, einschließlich hoher Trainingskomplexität und schlechter Generalisierungsfähigkeit, insbesondere bei der Arbeit mit kleinen Trainingsdatensätzen.
Die Hauptstärken von SAMformer liegen in seiner flachen Architektur und der Integration der Sharpness-Aware Minimization (SAM). Diese Ansätze helfen dem Modell, schlechte lokale Minima zu vermeiden, die Trainingsstabilität und -genauigkeit zu verbessern und eine hervorragende Generalisierungsleistung zu erzielen.
Im praktischen Teil unserer Arbeit haben wir unsere eigene Interpretation dieser Methoden in MQL5 implementiert und die Modelle auf realen historischen Daten trainiert. Die Testergebnisse bestätigen die Wirksamkeit der vorgeschlagenen Ansätze und zeigen, dass ihre Integration die Leistung der Basismodelle verbessern kann, ohne zusätzliche Trainingskosten zu verursachen. Und in einigen Fällen können Sie damit sogar die Ausbildungskosten senken.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für das Sammeln von Beispielen nach der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modellausbildung Expert Advisor |
| 4 | StudyEncoder.mq5 | Expert Advisor | Expert Advisor zum Training des Encoder |
| 5 | Test.mq5 | Expert Advisor | Modellprüfung Expert Advisor |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Bibliothek | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16403
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Jahreseinkommen der russischen Banken in Dolar. Teilen Sie durch 12 und vergleichen Sie.
In Yuan 6, in Yuan-Anleihen mehr als 10.
In Renminbi 6, in Renminbi-Anleihen mehr als 10.
Aber die Ergebnisse der Prüfung auf EURUSD und das Ergebnis in USD sind in dem Artikel angegeben. Zur gleichen Zeit, die Last auf die Kaution ist 1-2%. Und niemand schrieb, dass es ein Gral ist.
Aber der Artikel gibt die Ergebnisse der Prüfung auf EURUSD und das Ergebnis in USD. Zur gleichen Zeit, die Last auf die Kaution ist 1-2%. Und niemand schrieb, dass es ein Gral ist.
ok. cap in quid in Banken geben 5%.
Ein Gesamtgewinn von 0,35 % pro Monat? Wäre es nicht rentabler, das Geld einfach auf die Bank zu bringen?