
Do básico ao intermediário: Acesso aleatório (II)

Introdução
No artigo anterior Do básico ao intermediário: Acesso aleatório (I), foi dada uma breve introdução no que seria um modelo de acesso aleatório, tanto para escrita quanto também para leitura de dados e informações em um arquivo. No entanto, naquele artigo, devido ao fato de não desejarmos tornar o conteúdo muito denso e com muitas informações sendo despejada de uma só vez. Não foi explicado uma questão, que se não for é uma das que mais gera confusão e dores de cabeça para quem está implementando algo que precise utilizar arquivos de uma forma geral.
Agora preste atenção no que irei dizer, pois entender isto da maneira adequada é mais importante do que entender o que será explicado no decorrer deste artigo. Nem sempre, realmente precisamos implementar ou saber que tipo de dado estará sendo armazenado em um arquivo. Na maior parte das vezes, os arquivos são estruturados de uma certa maneira. Seja ela qual for. Porém esta forma como cada arquivo estará sendo estruturado, nos força, ou melhor dizendo, nos permite utilizar certos tipos de dados, onde não precisamos nos preocupar em saber como a leitura ou escrita estará sendo feita.
Pode parecer um tanto quanto estranho dizer isto que estou mencionando. Mas na prática, normalmente é assim que as coisas acontecem. Raramente, se não em momentos muito específicos, realmente precisaremos saber que tipo de dado, realmente está sendo armazenado em uma determinada posição do arquivo. Mas quando este tipo de coisa acontece, saber e entender o que precisa ser feito, é muito mais importante do que possa parecer. Isto por que, dependendo da forma como você estiver imaginando que as coisas estarão acontecendo, você como programador, pode acabar tendo muitas dificuldades em resolver certos problemas envolvendo arquivos. Por conta disto, peço a você, meu caro leitor, uma atenção muito grande a cada ponto que será explicado neste artigo. Pois entender o que será visto aqui, pode ser a diferença entre ler da maneira adequada um arquivo, e simplesmente não conseguir entender absolutamente nada que está naquele mesmo arquivo.
Acesso aleatório a arquivos (Parte 2)
Quando falamos sobre uniões, em artigos anteriores nesta mesma série de artigos. Mostrei que você precisa ficar muito atento ao tipo de dado e quantidade de bytes que cada tipo contém. Sem saber tal coisa, fica muito complexo compreender de fato o que está sendo representado dentro de um tipo de dado qualquer.
Uniões em si, são um tema, que muita gente as vezes ignora ou se quer vem de fato a fazer uso em seus códigos. Porém, com relação a estruturas e arrays a conversa é completamente diferente. Neste caso, muitas das vezes, é muito difícil, para não dizer quase impossível, criar certas modelos de dados, sem de fato entender tais conceitos de programação. Já que estruturas e arrays são coisas muitos mais comuns em códigos do que uniões propriamente ditas.
Ok, mas existe um problema que muitos acabam tendo que se confrontar. E neste caso, as coisas podem realmente ficar muito feias. Já que existe um tipo de modelagem em que estruturas, arrays e uniões, estarão todos presentes ao mesmo tempo. E quando isto acontece, ou você entende de fato como se trabalha com tais conceitos, ou ficará a ver navios. E esta modelagem envolve justamente o fato de que você estará trabalhando com arquivos de acesso aleatório.
Talvez você esteja querendo me passar medo. Não acredito que arquivos possam ser assim tão complicados como você está dizendo. Não é bem assim, meu caro leitor. Você talvez ainda não conseguiu entender o nível da coisa com a qual estamos lidando. Arquivos é de longe a forma mais complexa de dado, que pode ser criado e pensado por um programador. Tanto que isto é verdade, que quando um novo padrão de arquivo surge, surge junto com o mesmo, uma série de documentos somente para explicar como se trabalha com aquele novo padrão.
Sem acesso a tais documentos, que explicam como é o padrão interno de um arquivo. Se você o abrir, não irá conseguir entender absolutamente nada que esteja dentro dele. Salvo o fato de que o arquivo venha a ser um documento de texto puro. Esta talvez venha a ser a única exceção na qual não é preciso nenhum tipo de documento explicando como utilizar o padrão interno de um arquivo. Para exemplificar isto que foi dito, vamos pegar um exemplo mais simples de todos, que seria o formato bitmap. Este formato é descrito em diversos documentos espalhados pela WEB. Sendo de fato um formato muito simples e bastante prático, voltado justamente para que possamos armazenar imagens sem nenhum tipo de compactação complexa.
Se bem que existe uma leve compactação em alguns casos. Mas isto é um mero detalhe que podemos ignorar neste momento. A questão aqui é exatamente outra. No caso, a questão aqui, envolve o conceito de se entender ou não o que está sendo colocado dentro de um arquivo qualquer. Por exemplo, se você abrir uma imagem em um editor hexadecimal irá ver algo parecido com o que é mostrado logo abaixo.
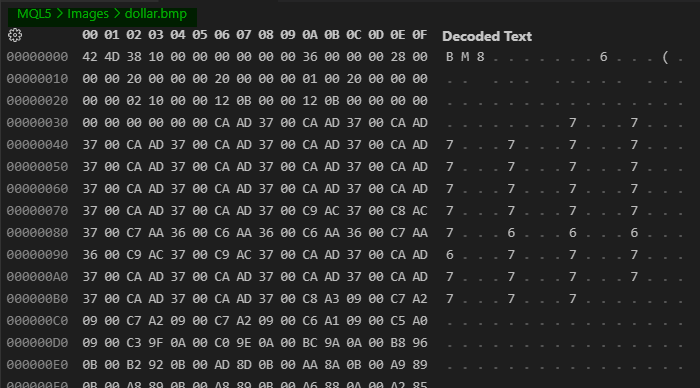
Imagem 01
Observe nesta imagem 01, uma coisa um tanto quanto curiosa, meu caro leitor. Veja que em verde estou destacando qual é o arquivo que está sendo mostrado aqui. No entanto, olhando para estes dados, você com toda a certeza não saberia dizer que tipo de conteúdo existe neste arquivo. Salvo o fato de que existem algumas marcações que nos ajuda a identificá-lo. Como por exemplo os três primeiros valores presentes neste arquivo. Obviamente um outro programador, ou mesmo um outro programa, poderiam vir a utilizar estes mesmos três valores para indicar um outro tipo completamente diferente de arquivo. Apesar de isto não ser comum, nada impede de que alguém venha a fazer isto.
No entanto, considerando o fato de que isto não venha a ocorrer, você logo pode imaginar que isto seria um arquivo bitmap. E como tão deverá ser lido como sendo um bitmap. Agora pergunto: Você saberia como obter as informações deste arquivo, sem ter a documentação que explica como este arquivo está sendo estruturado? Muito provavelmente não. Isto por que, fora o fato de termos os três primeiros valores nos arremetendo ao que seria um formato bitmap. Não existe nenhuma outra informação nos dizendo como o arquivo está sendo estruturado internamente. Assim sendo, se você não souber que tipo de programa precisa ser utilizado para visualizar o conteúdo real do arquivo. Você ficará impedido de saber que tipo de informação existe naquele arquivo.
E é mais ou menos assim que programas trabalham. Parece mágica, mas no entanto, o sistema operacional verifica o que seria o cabeçalho do arquivo. E dependendo do cabeçalho ele pode ou não estar vinculado a alguma aplicação específica. Caso esteja, quando você pedir para visualizar o conteúdo do arquivo, o sistema operacional irá utilizar o programa mais adequado a aquele tipo de cabeçalho. Apesar de muitos acharem que isto esteja relacionado a outras questões. E as vezes pode até estar. Mas não vem ao caso neste momento.
Ok, mas onde estou querendo chegar com esta questão? Bem, no artigo anterior, vimos como poderíamos ler e escrever em um arquivo de forma completamente aleatória, fazendo uso de chamadas como FileSeek e outras auxiliares. Mas ali, fizemos um trabalho com um objetivo de ler um byte e a cada byte lido, ou escrito, o índice de posição do arquivo avançava automaticamente uma posição. Mas será que é sempre assim? Para responder esta questão precisamos entrar em uma outra questão, que foi abordada em outros artigos, como quando falamos de uniões, estruturas e arrays. Apesar de termos visto tais temas de maneira separada e aos poucos, aqui iremos utilizar todos estes temas ao mesmo tempo. Isto para conseguir entender como o índice de posição do arquivo avança a cada leitura ou escrita que estivermos fazendo.
Certo, agora vamos esquecer o que foi visto na imagem 01, pois ela não irá nos ajudar neste momento. Precisamos iniciar com algo que seja mais simples. Porém adequado ao que será explicado. E para isto, vamos utilizar o código visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. const datetime dt = D'31.10.2024 15:30:10'; 08. const int i32 = 356248; 09. 10. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_ANSI)) == INVALID_HANDLE) 11. { 12. Print("Error..."); 13. return; 14. }; 15. 16. FileWrite(handle, i32, "Info", dt); 17. 18. FileFlush(handle); 19. 20. FileSeek(handle, 0, SEEK_SET); 21. while (!FileIsEnding(handle)) 22. Print(FileTell(handle), " >> ", FileReadString(handle)); 23. 24. FileClose(handle); 25. } 26. //+------------------------------------------------------------------+
Código 01
Bem, este código 01, quando executado irá gerar um arquivo cujo conteúdo é mostrado logo abaixo.

Imagem 02
Mas este mesmo código 01, também irá fazer com que no terminal tenhamos a seguinte saída mostrada logo abaixo.
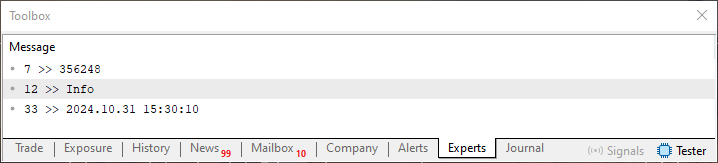
Imagem 03
Agora vem a parte que nos interessa. Observe que nesta imagem 03, temos um valor numérico antes de uma informação que estará sendo lida do arquivo. Pois bem este valor numérico que podemos ver antes da informação é a posição onde a informação atual termina e começa uma nova informação. Assim, se soubermos qual o valor anterior da posição de leitura ou escrita do arquivo, conseguimos saber quantas unidades de informação foram escritas ou lidas. Mas espere, o correto não seria dizer bytes lidos ou escritos? Não meu caro leitor e em breve você irá entender o motivo.
Ok, então vamos mudar o código para saber quantas unidades de informação foram escritas ou lidas. No caso estamos apenas lendo. Mas você deve considerar o que está sendo explicado para ambos os casos. Então surge o código logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_ANSI)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. 18. FileWrite(handle, i32, "Info", dt); 19. 20. FileFlush(handle); 21. 22. FileSeek(handle, 0, SEEK_SET); 23. while (!FileIsEnding(handle)) 24. { 25. old = FileTell(handle); 26. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 27. } 28. 29. FileClose(handle); 30. } 31. //+------------------------------------------------------------------+
Código 02
Quando executado este código 02 irá produzir o resultado que é visto logo abaixo.
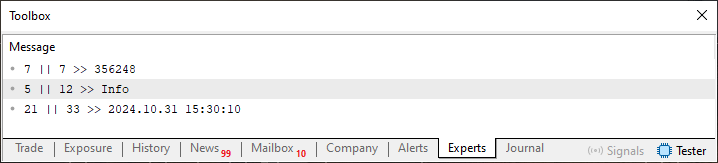
Imagem 04
Como este código 02 assim como o resultado da execução é muito fácil de entender, podemos ir para o próximo nível. Mas quero que você entenda o seguinte meu caro leitor. Neste atual momento, a leitura que estamos fazendo está forçando o sistema a ler um valor de cada vez nos baseando no que seria um delimitador presente no arquivo. Este delimitador é obtido pelo uso de um caractere de tabulação como pode ser visto na imagem logo abaixo.

Imagem 05
Note que nesta imagem estou destacando justamente o que seria este caractere de tabulação. Mas e se mudarmos um pouco o código o que aconteceria? Bem, para ver isto, vamos usar o código logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE| FILE_READ | FILE_ANSI | FILE_TXT)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. 18. FileWrite(handle, i32, "Info", dt); 19. 20. FileFlush(handle); 21. 22. FileSeek(handle, 0, SEEK_SET); 23. while (!FileIsEnding(handle)) 24. { 25. old = FileTell(handle); 26. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 27. } 28. 29. FileClose(handle); 30. } 31. //+------------------------------------------------------------------+
Código 03
Quando você executar este código 03, irá ver o que é mostrado logo abaixo.
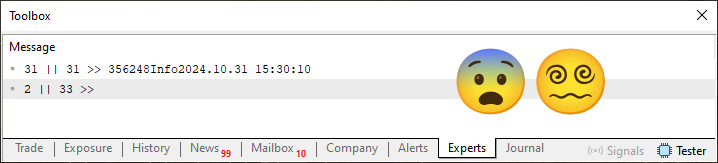
Imagem 06
Mas que doideira é esta? Não entendi, o que mudou no código que fez as coisas ficarem assim? Bem, não vou dizer, você terá que observar o código para encontrar o que foi modificado. No entanto, se você olhar o conteúdo binário do arquivo irá ver o que é mostrado logo abaixo.

Imagem 07
Cara, você fez alguma coisa. Diz aí onde foi que você mexeu? Novamente, meu amigo leitor, você terá que olhar o código para entender onde foi que eu mexi. De qualquer forma, você pode notar que o resultado não é mais aquele que existia antes. Isto por que, agora mudamos a formatação do próprio arquivo. E como a aplicação não sabe mais como ler o arquivo a fim de recuperar as informações temos esta total bagunça sendo mostrada como resultado.
Agora preste atenção, para resolver esta bagunça, precisamos dizer de alguma maneira, para o código onde um valor termina e onde outro começa. Isto pode ser feito de diversas maneiras diferentes. Aqui iremos ver apenas uma de tantas formas de se fazer isto. Sendo que cada caso é um caso, não existindo assim uma forma única de resolver a questão. Mas vamos com calma, pois quero que você entenda como isto será feito da maneira adequada.
Primeiro iremos modificar o código para algo parecido com o que é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_BIN)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. FileWriteString(handle, (string)i32); 18. FileWriteString(handle, "info"); 19. FileWriteString(handle, StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS))); 20. 21. FileFlush(handle); 22. 23. FileSeek(handle, 0, SEEK_SET); 24. while (!FileIsEnding(handle)) 25. { 26. old = FileTell(handle); 27. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 28. } 29. 30. FileClose(handle); 31. } 32. //+------------------------------------------------------------------+
Código 04
Muito bem, apesar do resultado em termos do que será visto no terminal ser a mesma coisa que é vista ao executar o código 03. Este código 04 gera um arquivo um pouco diferente. Este pode ser visto logo abaixo.

Imagem 08
Agora preste atenção meu caro leitor. Como foi dito, existem diferentes formas de se fazer o mesmo tipo de coisa. Mas aqui iremos usar um método muito parecido com o que existe na antiga e finada linguagem de programação BASIC. Assim, o próximo passo a ser dado é visto no código logo na sequência.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. ulong old; 08. 09. const datetime dt = D'31.10.2024 15:30:10'; 10. const int i32 = 356248; 11. 12. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_BIN)) == INVALID_HANDLE) 13. { 14. Print("Error..."); 15. return; 16. }; 17. FileWriteInteger(handle, 0, CHAR_VALUE); 18. FileWriteString(handle, (string)i32); 19. FileWriteInteger(handle, 0, CHAR_VALUE); 20. FileWriteString(handle, "info"); 21. FileWriteInteger(handle, 0, CHAR_VALUE); 22. FileWriteString(handle, StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS))); 23. 24. FileFlush(handle); 25. 26. FileSeek(handle, 0, SEEK_SET); 27. while (!FileIsEnding(handle)) 28. { 29. old = FileTell(handle); 30. Print(FileTell(handle) - old, " || ", FileTell(handle), " >> ", FileReadString(handle)); 31. } 32. 33. FileClose(handle); 34. } 35. //+------------------------------------------------------------------+
Código 05
Agora muita, mas muita atenção. Este código 05, irá criar um arquivo como o que é visto logo abaixo.

Imagem 09
Olhando esta imagem 09 você pode notar que estou marcando alguns pontos onde o valor em hexadecimal é igual a zero. Porque? O motivo é que iremos usar justamente a posição onde estes valores estão, para dizer como o texto deverá ser reconstruído pela aplicação. Isto a fim de conseguirmos mostrar o texto correto diretamente no terminal. Se você olhar no terminal, quando executar este código 05 irá notar algo estranho, porém perfeitamente compreensível por aqueles que vem estudando o que vem sendo explicado e mostrado nos artigos. Isto por que quando iremos tentar imprimir algo no terminal, teremos como sendo o primeiro caractere do arquivo um valor igual a zero. E por conta disto teremos um resultado, que a princípio pode parecer bem inusitado.
No entanto, mesmo neste código 05, se você mudar o valor presente na função FileSeek na linha 26, a fim de pular este primeiro valor zero que está presente logo no início do arquivo, irá notar que algum tipo de informação será apresentada no terminal. Teste isto depois, para ver e entender como o programa irá se comportar. Assim sendo, fica a dica para algo que você pode experimentar depois. Porém aqui, no artigo não iremos fazer isto, já que quero que você veja por si mesmo como você pode conseguir controlar os resultados, conforme o código vai sendo modificado. Porém, vamos voltar a nossa questão primária.
Já que o arquivo que estamos gerando agora, deve ser entendido, como sendo um arquivo do tipo binário. FileReadString, precisa saber quantos bytes precisarão ser lidos. Isto para que tenhamos uma informação correta e completa do texto a ser mostrado no terminal. Para fazer isto, vamos modificar novamente o código, como algo que é mostrado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle; 07. 08. const datetime dt = D'31.10.2024 15:30:10'; 09. const int i32 = 356248; 10. 11. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_ANSI | FILE_BIN)) == INVALID_HANDLE) 12. { 13. Print("Error..."); 14. return; 15. }; 16. FWriteString(handle, (string)i32); 17. FWriteString(handle, "info"); 18. FWriteString(handle, StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS))); 19. 20. FileFlush(handle); 21. 22. FileSeek(handle, 0, SEEK_SET); 23. while (!FileIsEnding(handle)) 24. { 25. uchar old = (uchar) FileReadInteger(handle, CHAR_VALUE); 26. Print(old, " || ", FileTell(handle), " >> ", FileReadString(handle, old)); 27. } 28. 29. FileClose(handle); 30. } 31. //+------------------------------------------------------------------+ 32. void FWriteString(int &handle, const string szArg) 33. { 34. long offs = (long) FileWriteInteger(handle, 0, CHAR_VALUE); 35. long size = (long) FileWriteString(handle, szArg); 36. ulong ftell = FileTell(handle); 37. FileSeek(handle, (size + offs) * -1, SEEK_CUR); 38. FileWriteInteger(handle, (uchar)size, CHAR_VALUE); 39. FileSeek(handle, ftell, SEEK_SET); 40. } 41. //+------------------------------------------------------------------+
Código 06
Muito bem, agora sim temos um código que irá gerar algum resultado interessante no terminal. Ao executarmos este código iremos ver, como resultado, o que é mostrado na imagem logo abaixo.
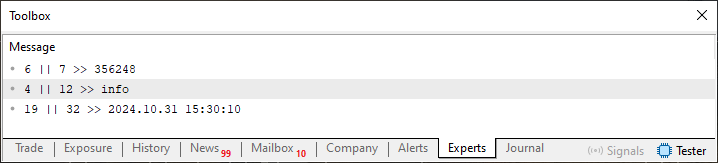
Imagem 10
Agora com relação ao arquivo. Se você abrir o mesmo, em um editor hexadecimal, irá ver algo parecido com o que é mostrado logo na sequência.

Imagem 11
Observe que neste caso, como podemos ver nesta imagem 11, estou destacando alguns valores. Estes valores, é a parte importante para nós. Isto por que eles indicam a quantidade de caracteres que deverão ser lidos pela função FileReadString. Ou dizendo de uma outra maneira. Estes mesmos valores que estão sendo destacados na imagem 11, nos diz quantos caracteres na sequência deverão ser lidos. Basicamente e de forma bem clara, você pode ver estes mesmos valores, sendo também mostrados na imagem 10. Mas então, por que este código 06 funcionou, enquanto os demais apenas geraram um arquivo que não apresentava nenhum resultado plausível no terminal?
Para entender isto, precisamos olhar com calma, justamente o procedimento que foi criado na linha 32 deste código 06. Este procedimento de certa forma é o coração da nossa aplicação. Já que o mesmo irá fazer um acesso aleatório ao arquivo a fim de montar a parte do conteúdo que será gravado no arquivo. No entanto, este mesmo procedimento foca o trabalho em um tipo, ou melhor dizendo, em uma largura de bytes. Tornando assim as coisas bem dependentes do tipo de informação que estaremos armazenando no arquivo.
Agora preste atenção a alguns detalhes aqui, pois os mesmos são importantes. Na linha 34 estamos pedindo para que seja armazenados um byte. E este mesmo um byte servirá para ajustar o offset depois. Este offset é um ponto crucial. Mas iremos chegar neste ponto com calma. Primeiro vamos entender como esta rotina da linha 32 funciona. Ok, agora que temos um offset, gravamos a informação da string no arquivo. Isto é feito pela linha 35. Detalhe, a string NÃO DEVE CONTER MAIS QUE 255 símbolos. Já que este é o limite definido pelo byte escrito antes. Agora na linha 36 guardamos de maneira temporária a posição atual do arquivo. Isto por que iremos voltar na posição do byte onde está a largura da mensagem e mudar o conteúdo daquele byte. Isto é feito pela linha 37. A gravação em si é feita pela linha 38. Observe que todos estes acessos, poderiam ser substituídos por um único acesso, isto se fizéssemos uso de um array. Porém, por hora, vamos deixar as coisas assim, apenas para que seja simples entender o que está sendo feito.
Muito bem, uma vez que os dados tenham sido gravados, a linha 20 força o arquivo a ser gravado imediatamente, caso ainda exista algum dado no buffer. Logo depois a linha 22 aponta para o início do arquivo, e neste momento entramos no laço da linha 23, este irá forçar uma leitura de forma que primeiro iremos ler o caractere que nos diz a quantidade de símbolos a serem lidos. Logo depois usamos a linha 26, para ler e apresentar estes mesmos símbolos.
Observe que precisamos ter um casamento entre a linha 25 e a linha 34. Isto para que a aplicação saiba quantos bytes realmente representam o número de símbolos a serem lidos. E é neste ponto em que entra a questão do offset. Muito bem, mas este mesmo tipo de construção também poderia ser modelado de uma outra maneira. Que ao meu ver, torna bem mais simples o trabalho de desenvolvimento do código. Assim como também a sua manutenção e melhorias.
Agora pare e pense um pouco, meu caro leitor. O que estamos fazendo aqui neste arquivo que estamos criando, é justamente algo que já foi visto em outro artigo, nesta mesma sequência. Porém, na época ainda não tínhamos elementos suficientes, para que pudéssemos explicar certos detalhes, que aqui podemos de fato executar. O que quero dizer, é que olhando a forma como as coisas estão sendo implementadas, na verdade estamos trabalhando é com uma estrutura de informações. Por conta disto, é importante que você não se apegue ao código e sim procure entender os conceitos adotados e pense nas possibilidades que temos para obter os mesmos tipos de resultados. Algumas são mais simples, enquanto outras mais eficientes. De qualquer forma, entender o conceito é mais importante do que tentar decorar e rabiscar códigos a esmo.
Ok, para mostrar que podemos trabalhar de diversas maneiras diferentes e sempre conseguindo obter o mesmo tipo de resultado. Vamos brincar um pouco com o que foi visto até aqui. E para isto, iremos trabalhar com um código um tanto quanto diferente em certas questões. Este pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int handle, 07. start = 1; 08. uchar arr[]; 09. 10. const datetime dt = D'31.10.2024 15:30:10'; 11. const int i32 = 356248; 12. 13. if ((handle = FileOpen("Hello World.txt", FILE_WRITE | FILE_READ | FILE_BIN)) == INVALID_HANDLE) 14. { 15. Print("Error..."); 16. return; 17. }; 18. 19. start += arr[start - 1] = (uchar) StringToCharArray((string)i32, arr, start); 20. start += arr[start - 1] = (uchar) StringToCharArray("info", arr, start); 21. start += arr[start - 1] = (uchar) StringToCharArray(StringFormat("%s", TimeToString(dt, TIME_DATE | TIME_SECONDS)), arr, start); 22. 23. FileWriteArray(handle, arr, 0, start - 1); 24. FileFlush(handle); 25. 26. ArrayFree(arr); 27. 28. FileSeek(handle, 0, SEEK_SET); 29. FileReadArray(handle, arr); 30. 31. FileClose(handle); 32. 33. for (uint i = 0; i < arr.Size(); i+= arr[i]) 34. Print(i, " >> ", CharArrayToString(arr, i + 1, arr[i])); 35. } 36. //+------------------------------------------------------------------+
Código 07
Quando este código 07 for executado iremos ter como resultado visto no terminal, o que é mostrado na imagem logo na sequência.
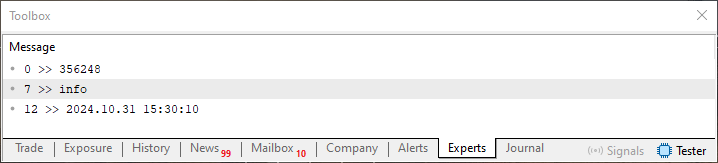
Imagem 12
Agora vamos entender uma coisa aqui, meu amigo leitor. Diferente dos demais códigos visto até este momento. Aqui estávamos fazendo algumas coisas de maneira um tanto quanto diferente. Isto porque, estamos removendo aquela quantidade de acessos a unidade de disco, por um trabalho diretamente na memória. E isto pode ser visto claramente aqui no código 07. Mas que tipo de impacto isto traz ao código e também a uso da aplicação? Já que tanto o objetivo, quanto também o resultado aparentemente se manteve intacto.
Bem meu caro leitor, o fato de removermos todos aqueles acessos ao disco, e jogarmos grande parte dele, para manipulações feitas em memória. Torna tanto a aplicação mais ágil, quanto também evita um atraso, ou queda na performance da plataforma MetaTrader 5, devido aos incessantes pedidos de despejo. Já que tecnicamente estamos forçando a escrita apenas nas linhas 25 e 26. Porém, neste código 07, temos algumas coisas que talvez não façam muito sentido, para quem esteja iniciando na programação. Mesmo tendo os artigos anteriores para ajudar a entender grande parte do código. Acredito que preciso dar uma breve explicação sobre porque este código 07 funciona e gera o mesmo tipo de resultado visto nos códigos anteriores.
Para começar, note o fato de termos na linha sete estamos iniciando uma variável que irá nos ser muito util. Assim como na linha oito, estamos declarando um array dinâmico. Este array, será nosso arquivo em memória. Agora preste bastante atenção ao que está sendo feito nas linhas 19, 20 e 21. Nestas linhas vistas no código 07, estamos fazendo o mesmo tipo de coisa que foi feita nas linhas 16, 17 e 18 do código 06. No entanto, aqui neste código 07, estas mesmas três linhas mencionadas, também fazem o trabalho do que seria o equivalente ao procedimento FWriteString, que também é visto no código 06.
Mas espere um pouco. Agora fiquei um tanto quanto confuso, com relação a este código 07. Você está me dizendo que estas linhas 19, 20 e 21, substituem todo aquilo que estava sendo feito no código 06, a fim de escrever os dados no arquivo? Sim, meu caro leitor. Mas estas linhas no código 07, ao meu ver não parecem estar fazendo isto. Pelo menos não estou conseguindo enxergar isto neste momento. Poderia explicar isto melhor. Mas é claro que posso explicar. Então vamos entender o que uma das linhas está fazendo, já que as demais funcionam da mesma maneira.
Talvez o que esteja deixando as coisas um tanto quanto confusas, é o fato de que estas linhas estão compactadas. Então vamos ver como a linha 19 funciona. Em primeiro lugar, você deve se lembrar de que a variável start já terá um valor quando a função StringToCharArray for executada. Assim sendo, o valor que start contiver, irá nos dizer onde começa a colocação dos caracteres para dentro do array, que estiverem presentes na string. Veja a documentação para mais detalhes a respeito desta função StringToCharArray. Uma vez que todos os caracteres tenham sido transferidos para o array, a função irá retornar à quantidade de caracteres adicionados. Assim, usamos o valor start para colocar no início do array, a quantidade de caracteres. Nos dando desta forma, o mesmo tipo de modelagem efetuado pelo código 06.
Porém, toda via e, entretanto, existe uma diferença aqui. StringToCharArray irá contar todos os caracteres, inclusive o caractere NULL. Ou seja, o valor de contagem será diferente do que era feito no código 06. Muita atenção a este detalhe. Contudo, o último passo a ser dado na linha, que no caso é a linha 19, será atualizar a posição apontada pela variável start.
Agora vem a parte interessante do código, que é justamente a linha 23. Se você entendeu o que aconteceu nas linhas 19, 20 e 21 irá ter notado que a variável start sempre estará apontando para um caractere NULL dentro do array. Sendo este caractere o ultimo presente no array. Porém devido ao fato de que tal caractere não nos interessa, usamos a função FileWriteArray, para armazenarmos em disco, todos os caracteres exceto um, que é o último caractere dentro do array. Com isto teremos um arquivo binário muito semelhante ao que seria criado pelo código 06. No entanto incompatível com o mesmo, devido justamente ao caractere de contagem no início da string. Por este motivo, é que mudamos também a rotina de leitura, para a que pode ser vista logo na linha 29. Ali estamos lendo todo o arquivo de uma só fez. Mas para que possamos apresentar o mesmo de maneira adequada dando assim o resultado esperado, fazemos uso do laço da linha 33.
Considerações finais
Neste artigo vimos como poderíamos implementar um sistema de acesso aleatório para escrever dados em um arquivo. Isto a fim de criar algum tipo de padrão protocolar. Porém, fazer isto diretamente em arquivo, nem sempre é de fato uma boa ideia.
Muitas das vezes, o melhor caminho seria criar um arquivo em memória, dentro de um array qualquer. E somente depois que o array estiver com todos os valores devidamente preenchidos é que passamos a fase de gravação dos dados em arquivo de disco. Isto torna o processo mais eficiente, já que a memória é muito mais rápida do que discos físicos. Mesmo unidades SSD são mais lentas que uma memória RAM. Além disto, não faz muito sentido, ficar lendo byte por byte em um arquivo. O melhor é de fato ler um grande bloco diretamente para a memória e trabalhar com ele ali, onde podemos pesquisar byte a byte em busca de alguma informação específica.
Apesar de termos trabalhando apenas e tal somente com tipos que contém um único byte aqui. Você pode estender o que foi visto aqui, para poder trabalhar com tipos mais longos, ou complexo. E isto sem nenhum tipo de dificuldade, já que para fazer isto, você pode reduzir as coisas a unidades do tipo estruturas ou uniões. E ambas já foram vistas e explicadas aqui nesta sequência.
| Arquivo MQ5 | Descrição |
|---|---|
| Code 01 | Demonstração de acesso a arquivo |
| Code 02 | Demonstração de acesso a arquivo |
| Code 03 | Demonstração de acesso a arquivo |
| Code 04 | Demonstração de acesso a arquivo |
| Code 05 | Demonstração de acesso a arquivo |
| Code 06 | Demonstração de acesso a arquivo |
| Code 07 | Demonstração de acesso a arquivo |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Assistente Connexus (Parte 5): Métodos HTTP e códigos de status
Assistente Connexus (Parte 5): Métodos HTTP e códigos de status
 Criando um EA em MQL5 com base na estratégia de Rompimento do Intervalo Diário (Daily Range Breakout)
Criando um EA em MQL5 com base na estratégia de Rompimento do Intervalo Diário (Daily Range Breakout)
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso