
Redes neuronales en el trading: Mejora de la eficiencia del Transformer mediante la reducción de la nitidez (Final)

Introducción
En el artículo anterior, aprendimos los aspectos teóricos del framework SAMformer (Sharpness-Aware Multivariate Transformer), un modelo innovador desarrollado para abordar los problemas inherentes a los Transformers tradicionales en problemas de previsión de series temporales multidimensionales a largo plazo. Los principales problemas del Transformer vainilla son su alta complejidad de aprendizaje, su baja capacidad de generalización en muestras pequeñas y su tendencia a alcanzar mínimos locales erróneos. Estas limitaciones dificultan la aplicación de modelos basados en la arquitectura del Transformer en tareas con un conjunto limitado de datos iniciales y elevados requisitos de precisión de predicción.
La idea clave del SAMformer consiste en utilizar una arquitectura poco profunda que reduzca la complejidad computacional y evite el sobreentrenamiento. Uno de los componentes centrales es el mecanismo de optimización con control de nitidez (Sharpness-Aware Optimization, SAM), que aumenta la robustez del modelo ante pequeños cambios de los parámetros, mejorando la generalizabilidad y la calidad de la solución final.
Gracias a estas características, el SAMformer demuestra un excelente rendimiento de previsión tanto en conjuntos de datos de series temporales sintéticas como reales. El modelo logra una gran precisión con una reducción significativa del número de parámetros, lo que lo hace más eficiente y adecuado para entornos que dependen de los recursos. Estas propiedades nos descubren una amplia gama de aplicaciones para el SAMformer en diversos campos como las finanzas, la medicina, la gestión de la cadena de suministro y la energía, donde la previsión a largo plazo desempeña un papel clave.
A continuación le mostramos la visualización del framework realizada por el autor.
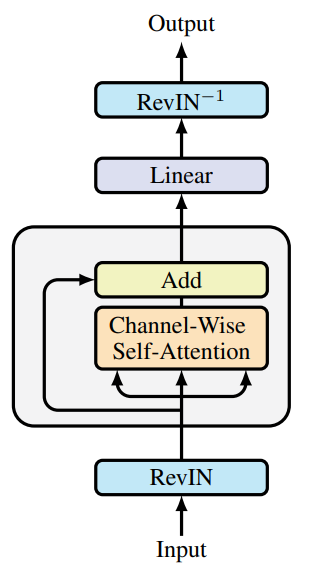
Ya hemos empezado a aplicar los planteamientos propuestos. Y el artículo anterior presentaba la implementación de nuevos kernels en el lado del programa OpenCL. Y también analizamos las adiciones a la capa totalmente conectada. Hoy continuaremos el trabajo iniciado.
1. Capa convolucional con optimización SAM
Vamos a continuar el trabajo comenzado. Y en el siguiente paso, aumentaremos la capa convolucional con la funcionalidad de optimización de SAM. Y, como no resulta difícil de adivinar, crearemos nuestra nueva clase CNeuronConvSAMOCL como heredera de nuestra capa convolucional CNeuronConvOCL. Más abajo resumiremos la estructura del nuevo objeto.
class CNeuronConvSAMOCL : public CNeuronConvOCL { protected: float fRho; //--- CBufferFloat cWeightsSAM; CBufferFloat cWeightsSAMConv; //--- virtual bool calcEpsilonWeights(CNeuronBaseOCL *NeuronOCL); virtual bool feedForwardSAM(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronConvSAMOCL(void) { activation = GELU; } ~CNeuronConvSAMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronConvSAMOCL; } virtual int Activation(void) const { return (fRho == 0 ? (int)None : (int)activation); } virtual int getWeightsSAMIndex(void) { return cWeightsSAM.GetIndex(); } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Nótese que en la estructura presentada declaramos ya 2 búferes para escribir los parámetros corregidos. Un búfer para los enlaces salientes, similar a una capa completamente conectada (cWeightsSAM). Y un segundo búfer para los enlaces entrantes (cWeightsSAMConv). Debo decir que la clase padre claramente no muestra semejante duplicación de búferes de parámetros. Al fin y al cabo, el búfer de parámetros básicos de los enlaces salientes se declara en la capa padre completamente conectada.
Aquí nos enfrentamos al dilema de heredar de una capa totalmente conectada con funcionalidad de optimización SAM o de la capa convolucional existente. En el primer caso, no crearíamos un búfer de enlaces salientes ajustados, ya que este se heredaría de la clase padre. Pero en ese caso tendríamos que duplicar completamente los métodos de la capa convolucional.
En la segunda opción de herencia, obtenemos la funcionalidad completa de la capa convolucional de la clase padre. Pero no existe el búfer de parámetros de enlaces salientes ajustados necesario para el correcto funcionamiento de la capa completamente conectada posterior con optimización SAM.
Así que hemos elegido la segunda opción de herencia porque requiere menos trabajo para implementar la funcionalidad completa necesaria.
Al igual que antes, declaramos los objetos internos adicionales de forma estática, lo cual nos permite dejar el constructor y el destructor vacíos. Sin embargo, en el constructor de la clase, estableceremos el parámetro GELU como función de activación por defecto. El resto del proceso de inicialización de objetos heredados y recién declarados se realizará en el método Init. Y aquí podemos notar el desbordamiento de dos métodos homónimos que difieren en la composición de los parámetros. Consideraremos en primer lugar el método con el máximo número de parámetros.
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, optimization_type, batch)) return false;
En los parámetros del método obtendremos las constantes principales que nos permitirán definir de forma inequívoca la arquitectura del objeto que hemos creado. E inmediatamente transmitiremos casi todos los parámetros recibidos al método homónimo de la clase padre, que ya implementará todos los puntos de control necesarios y el algoritmo de inicialización de todos los objetos heredados.
Después de ejecutar con éxito el método de la clase padre, almacenaremos el coeficiente del área de desenfoque en una variable interna. Este es el único parámetro que no transmitimos al método de la clase padre.
fRho = fabs(rho); if(fRho == 0) return true;
Y comprobaremos directamente el valor almacenado. Cuando el coeficiente del área de desenfoque sea cero, el algoritmo de optimización SAM degenerará en un algoritmo básico dado para optimizar los parámetros del modelo para el que ya se han inicializado todos los objetos necesarios en el método de la clase padre. Y finalizaremos decididamente el método con un resultado positivo.
En caso contrario, primero inicializaremos un búfer suficiente de enlaces entrantes corregidos con valores cero.
cWeightsSAMConv.BufferFree(); if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
Y después, si es necesario, inicializaremos de la misma manera el búfer de parámetros ajustados de los enlaces salientes.
cWeightsSAM.BufferFree(); if(!Weights) return true; if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
Tenga en cuenta que el último búfer solo se inicializará si están presentes los parámetros de enlaces salientes. Y este será el caso cuando nuestro objeto se vea seguido por una capa totalmente conectada.
Y después de inicializar con éxito todos los objetos internos, finalizaremos el método, devolviendo previamente el resultado lógico de las operaciones al programa que realiza la llamada.
El segundo método de inicialización de nuestro objeto redefinirá completamente el método de la clase padre y contendrá parámetros idénticos. Al mismo tiempo, como habrá adivinado, carecerá del parámetro del coeficiente de desenfoque, que resulta fundamental para la optimización de SAM. En el cuerpo del método, pondremos un factor de desenfoque de 0,7. Este factor de desenfoque se menciona en el artículo del autor sobre el framework SAMformer. Después llamaremos al método de inicialización de la clase descrito anteriormente.
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { return CNeuronConvSAMOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, 0.7f, optimization_type, batch); }
Este enfoque nos permite cambiar de forma sencilla el tipo de objeto para sustituir la capa convolucional por otra similar con optimización SAM, en casi cualquiera de las arquitecturas comentadas anteriormente.
Al igual que sucede con la capa totalmente conectada, heredaremos la funcionalidad completa de la pasada directa y la distribución del gradiente de error de la clase padre. Sin embargo, tendremos que crear 2 métodos de envoltorio para llamar a los kernels del programa OpenCL: calcEpsilonWeights y feedForwardSAM. El primer método se utilizará para llamar al kernel creado previamente para calcular los parámetros de capa ajustados. El segundo repetirá por entero el algoritmo del método padre de pasada directa, solo que el búfer de parámetros de capa será sustituido por el búfer de parámetros corregidos. No vamos a detenernos ahora en una revisión detallada de los algoritmos de los métodos anteriores, ya que son totalmente coherentes con los algoritmos de puesta en la cola de los kernels comentados anteriormente. Le sugiero que se familiarice con ellos por sí mismo. Encontrará el código completo de los métodos anteriores en el archivo adjunto.
El algoritmo del método redefinido para optimizar los parámetros de nuestra clase le recordará al método similar para la capa totalmente conectada con optimización SAM, solo que en este caso no comprobaremos el tipo de la capa precedente. Después de todo, a diferencia de las capas totalmente conectadas, los objetos de capa convolucionales contienen en su estructura una matriz de parámetros aplicados a los datos de origen. Como consecuencia, utilizará su propio búfer de parámetros corregidos. Así, del objeto anterior solo necesitaremos el búfer de datos iniciales que tienen todos nuestros objetos.
No obstante, comprobaremos el coeficiente de dispersión. De hecho, cuando el factor SAM sea cero, la optimización degenerará en un algoritmo de optimización básico. En estos casos, bastará con utilizar el método homónimo de la clase padre.
bool CNeuronConvSAMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(fRho <= 0) return CNeuronConvOCL::updateInputWeights(NeuronOCL);
En el caso de utilizar la optimización SAM, sin embargo, primero sumaremos el gradiente de error y los resultados de la pasada directa para obtener el tensor objetivo del objeto actual.
if(!SumAndNormilize(Gradient, Output, Gradient, iWindowOut, false, 0, 0, 0, 1)) return false;
A continuación, recalcularemos los parámetros del modelo para considerar el coeficiente de área de desenfoque. Para ello, llamamos al método de envoltorio de puesta en la cola de ejecución del kernel correspondiente. Resulta fácil ver que las capas convolucionales y completamente conectadas tienen métodos homónimos. Sin embargo, su ejecución implica poner en la cola distintos kernels que realizan funciones similares pero dentro de los algoritmos de sus respectivas capas neuronales.
if(!calcEpsilonWeights(NeuronOCL)) return false;
La situación es similar para los métodos de pasada directa con parámetros corregidos.
if(!feedForwardSAM(NeuronOCL)) return false;
Tras completar con éxito una pasada directa repetida, determinaremos la desviación de los valores objetivo.
float error = 1; if(!calcOutputGradients(Gradient, error)) return false;
Y llamaremos al método homónimo de la clase padre para ajustar los parámetros del modelo.
//--- return CNeuronConvOCL::updateInputWeights(NeuronOCL); }
Luego devolveremos el resultado lógico de las operaciones al programa que realiza la llamada y finalizaremos el método.
Vamos a hablar ahora del almacenamiento de los parámetros del modelo entrenado. En este caso, seguiremos las soluciones expuestas al describir los métodos de las capas completamente conectadas con optimización SAM. No guardaremos los datos de los búferes de los parámetros corregidos. A la información almacenada por la clase padre, solo añadiremos el factor de desenfoque.
bool CNeuronConvSAMOCL::Save(const int file_handle) { if(!CNeuronConvOCL::Save(file_handle)) return false; if(FileWriteFloat(file_handle, fRho) < INT_VALUE) return false; //--- return true; }
Sin embargo, al cargar los parámetros de un modelo preentrenado, deberemos preparar los búferes necesarios. Y aquí deberemos entender que los criterios para crear los búferes de los parámetros ajustados de los enlaces entrantes y salientes son diferentes.
En el método carga de datos, primero leeremos los datos almacenados por la clase padre.
bool CNeuronConvSAMOCL::Load(const int file_handle) { if(!CNeuronConvOCL::Load(file_handle)) return false;
Y, a continuación, leeremos el valor del factor de desenfoque, comprobado previamente si el dato está presente en el fichero.
if(FileIsEnding(file_handle)) return false; fRho = FileReadFloat(file_handle);
La presencia de un coeficiente de desenfoque positivo supone un criterio habitual para crear búferes de parámetros ajustados. Por lo tanto, comprobaremos el valor del parámetro cargado. Y si no cumple nuestras condiciones, borraremos los búferes no utilizados en el contexto OpenCL y en la memoria principal. A continuación, finalizaremos el método con un resultado positivo.
cWeightsSAMConv.BufferFree(); cWeightsSAM.BufferFree(); cWeightsSAMConv.Clear(); cWeightsSAM.Clear(); if(fRho <= 0) return true;
Tenga en cuenta que este será el caso cuando el punto de control no resulte crítico para el funcionamiento del programa. Como ya hemos comentado, la ausencia de un factor de desenfoque positivo hace que SAM degenere en un método básico de optimización de parámetros. En consecuencia, el funcionamiento de nuestro objeto también se reducirá a los métodos de la clase padre.
Si se supera este punto de control, inicializaremos y crearemos un búfer de parámetros corregidos de enlaces entrantes en la memoria contextual OpenCL.
if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
Para crear un búfer de parámetros ajustados de enlaces salientes, existe un criterio adicional: la existencia de enlaces similares. Por lo tanto, antes de crearlo, comprobaremos que el puntero al búfer correspondiente está actualizado.
if(!Weights) return true;
Y en este caso la ausencia del puntero real no será crítica para el funcionamiento del programa, sino que solo indicará las peculiaridades de la arquitectura del modelo. Por consiguiente, si no hay puntero real, finalizaremos el método con un resultado positivo.
En caso de que haya un búfer cargado de enlaces salientes, inicializaremos y crearemos un búfer de tamaño similar para los parámetros ajustados.
if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
Después retornaremos el resultado lógico de las operaciones al programa que realiza la llamada y finalizaremos el método.
Con esto concluiremos nuestra revisión de los algoritmos del método de capas convolucionales que utilizan enfoques de optimización SAM CNeuronConvSAMOCL. Encontrará el código completo de esta clase y todos sus métodos en el archivo adjunto.
2. Añadimos SAM al Transformer
En esta fase, crearemos los objetos de capas completamente conectadas y convolucionales utilizando enfoques de optimización de parámetros SAM. Y ya ha llegado el momento de aplicar los enfoques propuestos en la arquitectura del Transformer. En realidad, así lo sugieren los autores del framework SAMformer. También en este caso, para evaluar objetivamente el impacto de los enfoques propuestos en el rendimiento del modelo, no crearemos nuevas clases. En su lugar, añadiremos los enfoques propuestos a la estructura de una clase existente. Como base tomaremos un transformador con atención relativa R-MAT.
Como ya sabrá, la clase CNeuronRMAT construye un modelo lineal a partir de sucesivos objetos CNeuronRelativeSelfAttention y CResidualConv. El primero implementa un módulo de atención relativa con enlace inverso, mientras que el segundo implementa un módulo de capas convolucionales con enlace inverso. Para aplicar los enfoques de optimización SAM, solo tendremos que sustituir todas las capas convolucional de la estructura de los objetos anteriores por otras similares que utilicen la optimización SAM. La nueva estructura de clases se resume a continuación.
class CNeuronRelativeSelfAttention : public CNeuronBaseOCL { protected: uint iWindow; uint iWindowKey; uint iHeads; uint iUnits; int iScore; //--- CNeuronConvSAMOCL cQuery; CNeuronConvSAMOCL cKey; CNeuronConvSAMOCL cValue; CNeuronTransposeOCL cTranspose; CNeuronBaseOCL cDistance; CLayer cBKey; CLayer cBValue; CLayer cGlobalContentBias; CLayer cGlobalPositionalBias; CLayer cMHAttentionPooling; CLayer cScale; CBufferFloat cTemp; //--- virtual bool AttentionOut(void); virtual bool AttentionGradient(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronRelativeSelfAttention(void) : iScore(-1) {}; ~CNeuronRelativeSelfAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRelativeSelfAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual uint GetWindow(void) const { return iWindow; } virtual uint GetUnits(void) const { return iUnits; } };
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvSAMOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); };
Tenga en cuenta que para un módulo convolucional con enlace inverso, solo cambiamos el tipo de objeto en la estructura de clases. Al mismo tiempo, no realizaremos ningún ajuste en los métodos de las clases. Esto resultará posible sobrecargando los métodos de inicialización de la capa convolucional con la inicialización SAM. Permítame recordarle que dentro de la clase CNeuronConvSAMOCL crearemos 2 métodos de inicialización: uno con el factor de desenfoque en los parámetros del método y otro sin él. Obviamente, el método de inicialización en el que no se especifica el factor de desenfoque redefinirá el método homónimo de la clase padre que utilizamos anteriormente al inicializar las capas convolucionales. Como consecuencia, al inicializar los objetos CResidualConv, al llamar al método de inicialización de la capa convolucional, el programa ya hará referencia a nuestro método redefinido, que añadirá el factor de desenfoque por defecto y llamará al método de inicialización de la capa convolucional completa utilizando enfoques de optimización SAM.
En el caso del módulo de atención relativa, sin embargo, las cosas será un poco más complicadas. El hecho es que el módulo de atención relativa CNeuronRelativeSelfAttention que usamos tiene una arquitectura bastante compleja que incluye modelos anidados adicionales de desplazamientos entrenables. Su arquitectura se indica en el método de inicialización del objeto. Por lo tanto, para añadir enfoques de optimización SAM a los modelos internos, tendremos que realizar modificaciones en el método de inicialización del módulo de atención relativa.
Los parámetros del método no cambiarán y los primeros pasos de su algoritmo tampoco. Ya hemos cambiado el tipo de objetos para generar las entidades Query, Key y Value en la estructura de clases.
bool CNeuronRelativeSelfAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; //--- iWindow = window; iWindowKey = window_key; iUnits = units_count; iHeads = heads; //--- int idx = 0; if(!cQuery.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cQuery.SetActivationFunction(GELU); idx++; if(!cKey.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cValue.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cTranspose.Init(0, idx, OpenCL, iUnits, iWindow, optimization, iBatch)) return false; idx++; if(!cDistance.Init(0, idx, OpenCL, iUnits * iUnits, optimization, iBatch)) return false;
A continuación, en los modelos de generación de desplazamientos BKey y BValue, realizaremos la sustitución de los tipos de objetos convolucionales preservando otros parámetros.
idx++; CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false;
idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false;
En los modelos para generar el contexto global y los desplazamientos de posición, utilizaremos capas totalmente conectadas con optimización SAM.
idx++; CNeuronBaseOCL *neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false; idx++; CBufferFloat *buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false;
idx++; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false; idx++; buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false;
Y para las operaciones de agrupación de MLP, volveremos a utilizar capas convolucionales con enfoques de optimización SAM.
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iHeads, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(None); CNeuronSoftMaxOCL *softmax = new CNeuronSoftMaxOCL(); if(!softmax || !softmax.Init(0, idx, OpenCL, iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(softmax) ) return false; softmax.SetHeads(iUnits);
Obsérvese que para la primera capa utilizaremos la capa básica completamente conectada, ya que solo se utilizará para registrar los resultados de la unidad de atención multicabeza.
La situación será similar con el bloque de escalado. Utilizaremos como primera capa una capa completamente conectada básica, ya que está diseñada para registrar los resultados de la multiplicación de los coeficientes de sentido por los resultados de la atención multicabeza. A continuación, les seguirán las capas convolucionales con optimización SAM.
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iUnits, optimization, iBatch) || !cScale.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey, iWindowKey, 2 * iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(LReLU); idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, 2 * iWindow, 2 * iWindow, iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(None); //--- if(!SetGradient(conv.getGradient(), true)) return false; //--- SetOpenCL(OpenCL); //--- return true; }
Con esto concluiremos nuestro trabajo sobre la aplicación de enfoques de optimización SAM en el Transformer con atención relativa. Puede ver el código completo de los objetos actualizados en el archivo adjunto.
3. Arquitectura de los modelos
Más arriba ya hemos creado nuevos objetos y realizado cambios en algunos ya existentes. La próxima etapa de nuestro trabajo consistirá en ajustar la arquitectura de los modelos. Y a diferencia de lo que sucede en varios artículos recientes, el ajuste actual de la arquitectura del modelo será más global. Empezaremos con la arquitectura del Codificador del entorno, que está representada en el método CreateEncoderDescriptions. Al igual que antes, en los parámetros del método obtendremos el puntero al array dinámico para registrar la secuencia de palabras del modelo neuronal.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
En el cuerpo del método comprobaremos la relevancia del puntero obtenido y, de ser necesario, crearemos una nueva instancia del array dinámico.
Dejaremos las 2 primeras capas sin cambios. Hablamos de la capa de datos de origen y la capa de normalización de lotes. El tamaño de estas capas es idéntico y debería bastar para registrar el tensor de los datos originales.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, los autores del framework SAMformer sugieren utilizar la atención canalizada. Por lo tanto, utilizaremos una capa de transposición de datos para ayudarnos a representar los datos de origen como una secuencia de canales de atención.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window= BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, utilizaremos un bloque de atención relativa en el que ya hemos aplicado los enfoques de optimización de SAM.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRMAT; descr.window=HistoryBars; descr.count=BarDescr; descr.window_out = EmbeddingSize/2; // Key Dimension descr.layers = 1; // Layers descr.step = 2; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Y hay dos cosas a las que prestar atención. En primer lugar, usaremos la atención canalizada. Por lo tanto, la ventana de análisis será igual a la profundidad de la historia analizada, mientras que el número de elementos será igual al número de canales independientes. En segundo lugar, como sugieren los autores del framework, solo utilizaremos 1 nivel de atención. Sin embargo, a diferencia de la aplicación del autor, utilizaremos 2 cabezas de atención. Además, hemos dejado el bloque FeedForward en su lugar. Recordemos que los autores del framework utilizan 1 cabeza de atención y eliminan el bloque FeedForward.
A continuación, tendremos que reducir la dimensionalidad del tensor de resultados a un tamaño determinado. Realizaremos esta operación en 2 pasos. En primer lugar, usaremos una capa convolucional con optimización SAM para reducir la dimensionalidad de los canales individuales.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount/BarDescr; descr.probability = 0.7f; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Y, a continuación, utilizaremos una capa totalmente conectada con optimización SAM para obtener la incorporación global del estado actual del entorno de un tamaño determinado.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
En ambos casos, utilizaremos descr.probability para especificar el coeficiente del área de desenfoque.
Y finalizaremos el método retornando el resultado lógico de las operaciones al programa que realiza la llamada. Y devolveremos la arquitectura del propio modelo mediante el puntero del array dinámico que previamente hemos recibido en los parámetros del programa que realiza la llamada.
Tras crear la arquitectura del Codificador del entorno, describiremos las capas del Actor y el Crítico. Generaremos la descripción de ambos modelos en el método CreateDescriptions. Y al igual que en este método crearemos una descripción de los 2 modelos y obtendremos los 2 punteros a los arrays dinámicos en los parámetros del método.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
En el cuerpo del método comprobaremos la relevancia de los punteros obtenidos y, si es necesario, crearemos nuevos arrays dinámicos.
En primer lugar, describiremos la arquitectura del Actor. La primera capa de este modelo se representará como una capa completamente conectada utilizando enfoques de optimización SAM. El tamaño de esta capa será igual al vector de descripción del estado de la cuenta.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.probability=0.7f; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Obsérvese que utilizaremos una capa completamente conectada con optimización SAM para registrar los datos de origen. Y para el modelo del Codificador del entorno, utilizaremos una capa básica completamente conectada en una situación similar. Esto se debe a la presencia de una capa posterior completamente conectada optimizada por SAM que necesitará el búfer de parámetros ajustados de la capa anterior para funcionar plenamente.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Al igual que sucede en el Codificador de estado del entorno, utilizaremos descr.probability para especificar el coeficiente del área de desenfoque. Para todos los modelos, utilizaremos un único factor de área de desenfoque de 0,7.
Las dos capas consecutivas completamente conectadas optimizadas por SAM crearán incorporaciones del estado de la cuenta actual, que combinaremos con la incorporación del estado del entorno correspondiente. Esta funcionalidad será ejecutada por una capa de concatenación de datos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A continuación, utilizaremos un bloque de decisión de 3 capas completamente conectadas con optimización SAM.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
A la salida de la última capa, generaremos un tensor que será 2 veces el vector objetivo de la representación de la acción del Actor. Esto nos permitirá añadir estocasticidad a las acciones. Como antes, utilizaremos para ello la capa de estado latente del autocodificador.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Recordemos que la capa latente del autocodificador dividirá el tensor de los datos de entrada en dos partes: la primera reflejará los valores medios de las distribuciones de cada elemento de la secuencia de salida, mientras que la segunda contendrá la varianza de las distribuciones correspondientes. El entrenamiento de estos valores medios y varianza en el módulo de decisión nos permite restringir el dominio de generación de valores aleatorios a la capa latente del autocodificador, que utilizaremos para introducir estocasticidad en la política del Actor.
Aquí conviene añadir que la capa latente del autocodificador generará valores independientes para cada elemento de la secuencia de salida. Sin embargo, en ellos esperaremos una serie de valores para realizar operaciones: el volumen de la operación y los niveles de take profit y stop loss. Para dar coherencia a los parámetros de una operación, utilizaremos una capa convolucional con optimización SAM que analizará por separado los parámetros de las operaciones largas y cortas.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
Para restringir el dominio de los resultados de esta capa, utilizaremos una función de activación sigmoidal.
El toque final de nuestro modelo del Actor será la capa de predicción directa con refuerzo frecuencial (CNeuronFreDFOCL), que nos permitirá ajustar los resultados del modelo a los valores objetivo en el dominio de la frecuencia.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Una arquitectura similar se le dio al Crítico. Solo que en la entrada del modelo suministraremos los parámetros de la operación comercial generada por el Actor, en lugar de la descripción del estado de la cuenta pasada al Actor. También utilizaremos 2 capas completamente conectadas con optimización SAM para obtener la incorporación de la operación comercial.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
La incorporación de la operación comercial se combinará con la incorporación del estado del entorno en la capa de concatenación de datos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Y luego utilizaremos un bloque de decisión de 3 capas consecutivas completamente conectadas con optimización SAM. Pero, a diferencia del Actor, en este caso no se aprovechará la estocasticidad de los resultados.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
Y sobre el modelo del Crítico, añadiremos una capa de predicción directa con refuerzo frecuencial.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Una vez finalizada la generación de la descripción de la arquitectura del modelo, finalizaremos el método devolviendo primero el resultado lógico de las operaciones al programa que realiza la llamada. La descripción de la arquitectura de los modelos será devuelta por los punteros dinámicos del array que se han obtenido en los parámetros del método.
Con esto concluirá nuestro trabajo sobre la construcción de los modelos. Podrá ver su arquitectura completa en el archivo adjunto. También encontrará el código completo de los programas de interacción con el entorno y de formación de modelos, que se han trasladado de trabajos anteriores sin modificaciones.
4. Simulación
Ya hemos trabajado los suficiente para aplicar los enfoques propuestos por los autores del framework SAMformer. Y ahora ha llegado el momento de probar la eficacia de la solución implantada con datos históricos reales. Al igual que antes, entrenaremos los modelos con datos históricos reales del instrumento EURUSD para todo el año 2023. En el proceso de realización de los experimentos, utilizaremos los datos del periodo H1. Los parámetros de los indicadores analizados se han tomado por defecto.
Como ya hemos dicho, los programas utilizados para interactuar con el entorno y entrenar los modelos permanecen inalterados. Esto nos permitirá utilizar muestras de entrenamiento previamente creadas para el entrenamiento inicial de los modelos. Además, como hemos elegido el framework R-MAT como modelo básico para la implementación de la optimización SAM, hemos decidido no actualizar la muestra de entrenamiento durante el entrenamiento del modelo. Obviamente, esperamos que esto tenga un impacto negativo en los resultados del entrenamiento del modelo, pero este enfoque nos permitirá comparar los resultados con el modelo de referencia, excluyendo el impacto derivado del cambio de la muestra de entrenamiento.
Entrenaremos los 3 modelos en un punto temporal, mientras que los resultados de la prueba de la política entrenada del Actor serán los siguientes. El modelo se ha probado con datos históricos reales para enero de 2024, manteniendo los otros parámetros utilizados en el entrenamiento del modelo.
Pero antes, merece la pena decir unas palabras sobre el entrenamiento de modelos. En primer lugar, la optimización de SAM implicará suavizar el paisaje de la función de pérdida. Y esto, a su vez, nos permitirá considerar la posibilidad de utilizar una tasa de aprendizaje más elevada. Antes se utilizaba principalmente la tasa de aprendizaje de 3,0e-04 para entrenar los modelos, pero en este caso la aumentaremos a 1,0e-03.
Además, el uso de una sola capa de atención ha reducido el número de parámetros que había que entrenar y, al mismo tiempo, ha compensado el coste de la repetición de la pasada directa al ejecutar el algoritmo SAM para la optimización de los parámetros.
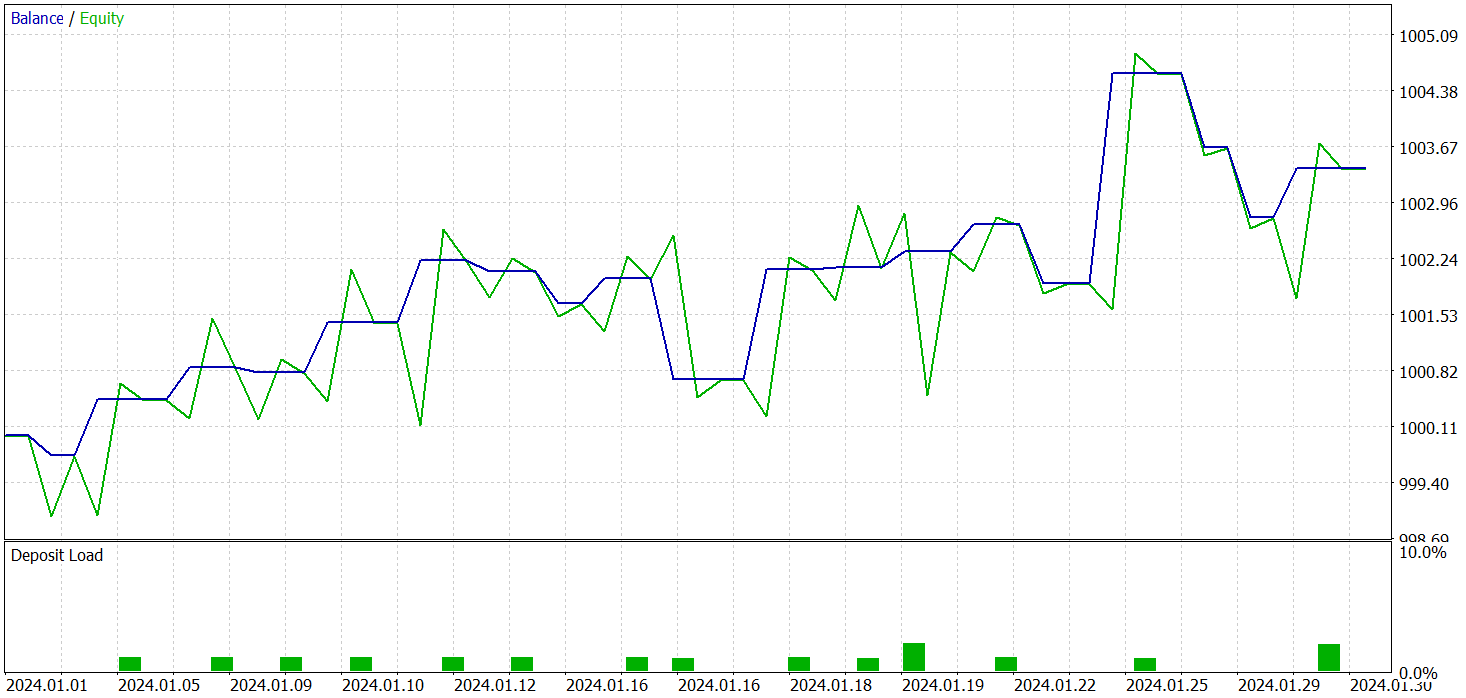
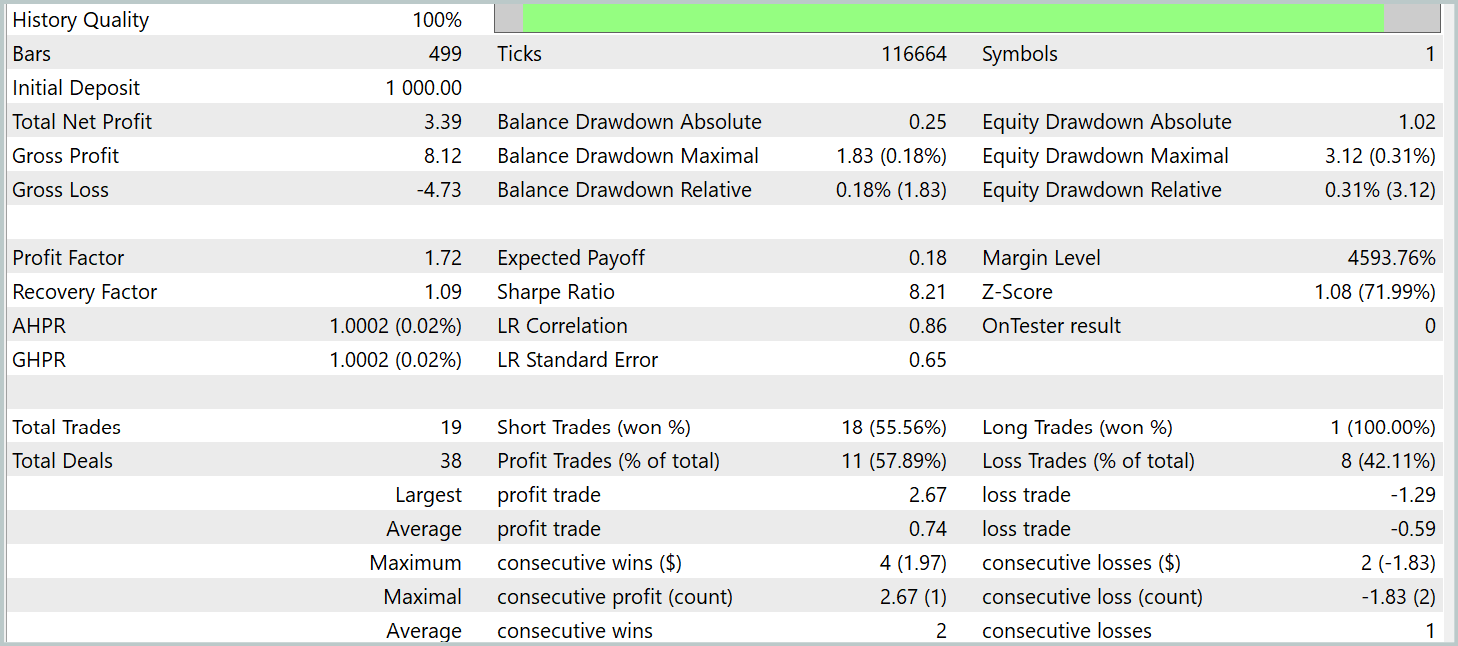
Y como resultado del entrenamiento del modelo, hemos logrado una política capaz de generar beneficios fuera de la muestra de entrenamiento. Durante el periodo de prueba, el modelo ha realizado 19 transacciones comerciales, 11 de las cuales se han cerrado con beneficio (57,89%). A modo de comparación, el modelo R-MAT que aplicamos anteriormente ha realizado 15 transacciones durante el mismo periodo, 9 de las cuales han cerrado con beneficios (60,0%). Al mismo tiempo, la rentabilidad total del nuevo modelo es casi 2 veces superior a la del modelo básico.
Conclusión
El framework SAMformer ofrece una solución eficaz a las principales limitaciones de la arquitectura del Transformer que surgen en la previsión a largo plazo de series temporales multidimensionales. El Transformer tradicional se enfrenta a una serie de retos, como la elevada complejidad del entrenamiento y la escasa capacidad de generalización, especialmente con muestras de entrenamiento pequeñas.
Las principales ventajas del SAMformer son su arquitectura superficial y el uso de un mecanismo de optimización con control de nitidez (Sharpness-Aware Minimization). Estos enfoques permiten al modelo evitar con éxito los malos mínimos locales, mejorando la estabilidad y la precisión del entrenamiento, y ofreciendo una generalizabilidad superior.
En la parte práctica de nuestro trabajo, hemos implementado nuestra visión de los enfoques propuestos mediante MQL5 y entrenado los modelos con datos históricos reales. Los resultados de las pruebas de los modelos entrenados confirman la eficacia de los planteamientos propuestos y demuestran que su aplicación puede mejorar el rendimiento de los modelos subyacentes sin costes de entrenamiento adicionales. En algunos casos, incluso permite reducir el coste del entrenamiento.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | StudyEncoder.mq5 | Asesor | Asesor de entrenamiento del Codificador |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16403
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Ingresos anuales de los bancos rusos en dolares. Divide por 12 y compara.
En yuanes 6, en bonos yuanes más de 10.
En renminbi 6, en bonos renminbi más de 10.
Pero el artículo da los resultados de las pruebas en EURUSD y el resultado en USD. Al mismo tiempo, la carga en el depósito es 1-2%. y nadie escribió que es un grial.
Pero el artículo da los resultados de las pruebas en EURUSD y el resultado en USD. Al mismo tiempo, la carga en el depósito es 1-2%. y nadie escribió que es un grial.
ok. cap en quid en los bancos dan 5%.
¿Un beneficio total del 0,35% al mes? ¿No sería más rentable poner el dinero en el banco?