
Reimaginando Estratégias Clássicas (Parte VIII): Mercados de Câmbio e Metais Preciosos no USDCAD

Ao longo desta série de artigos, buscamos explorar o vasto campo de possíveis aplicações da IA em estratégias de negociação. Nosso objetivo é fornecer as informações necessárias para que você tome uma decisão informada antes de investir seu capital em uma estratégia baseada em IA. Esperamos que você consiga identificar uma estratégia que seja adequada ao seu nível particular de tolerância ao risco.
Visão Geral da Estratégia de Negociação
Na discussão de hoje, procuraremos descobrir relações entre o mercado de moedas e o de metais preciosos. Os metais preciosos constituem uma parte integral de qualquer economia moderna. Isso se deve ao seu amplo uso industrial, variando da eletrônica à área da saúde. As flutuações no preço dos metais preciosos geram inflação para os produtores de bens acabados, o que pode reduzir os níveis de produção doméstica ou, por outro lado, levar a uma queda na demanda dos países que exportam esses metais.
O ouro é, simultaneamente, um dos principais produtos minerais de exportação do Canadá e dos Estados Unidos. A resistência natural do ouro à corrosão mantém sua alta demanda tanto por desenvolvedores de equipamentos eletrônicos sensíveis quanto por joalheiros. O paládio, por outro lado, é altamente demandado por diversas indústrias, especialmente a indústria automotiva. Existem mais de 20 componentes em um carro que requerem conversores catalíticos, sendo os mais conhecidos aqueles embutidos nos canos de escape. Cada um desses conversores contém quantidades significativas de paládio. Canadá e Estados Unidos são ambos líderes na exportação de veículos. Portanto, os preços desses metais preciosos têm impacto na produção doméstica desses dois países.
No passado, a correlação entre o preço do ouro e o dólar era inversa. Sempre que o dólar apresentava um desempenho ruim, os investidores tendiam a fechar quaisquer posições apostando no dólar e proteger seu dinheiro investindo em ouro. Contudo, nos tempos atuais de afrouxamento quantitativo, essas correlações já não são tão claras.
Visão Geral da Metodologia
Gostaríamos que nosso computador aprendesse uma estratégia própria a partir dos preços desses três mercados. Naturalmente, tendemos a acreditar mais em estratégias que nos pareçam intuitivas do que naquelas que não fazem sentido imediato. No entanto, ao aprender uma estratégia de forma algorítmica, nosso computador pode ser capaz de descobrir relações que levaríamos uma vida inteira para identificar. Alternativamente, também pode expor limitações na precisão de nossa estratégia.Nosso objetivo foi avaliar o quão confiáveis são os mercados de metais preciosos para prever os mercados cambiais. Tentamos prever a taxa de câmbio USDCAD usando 3 grupos de preditores:
- Cotações do par USDCAD
- Cotações de XAUUSD e XPDUSD
- Um conjunto combinado dos acima.
Buscamos todos os dados diretamente do terminal MetaTrader 5 usando um script personalizado escrito em MQL5. Exportamos os dados para o formato CSV e os processamos em Python. Além disso, observamos níveis significativos de correlação negativa: -0,5 entre XAUUSD e USDCAD, e -0,66 entre XPDUSD e USDCAD. Entretanto, apenas níveis moderados de correlação (0,37) foram observados diretamente entre os dois metais.
Tentamos visualizar os dados. Contudo, não conseguimos identificar relações discerníveis nos dados. Tentamos representar os dados em dimensões superiores, utilizando gráficos de dispersão 3D, mas sem sucesso. Os dados se mostraram difíceis de separar.
A partir daí, treinamos vários modelos para prever a taxa de câmbio do USDCAD usando os três grupos de preditores mencionados anteriormente; o modelo de melhor desempenho foi o Modelo Linear utilizando o primeiro grupo de preditores. Contudo, como o modelo linear não possui parâmetros ajustáveis, selecionamos o segundo melhor modelo, o Regressor Vetorial de Suporte Linear (LSVR), como nosso modelo de melhor desempenho.
Conseguimos ajustar os hiperparâmetros do modelo LSVR sem sobreajustar o conjunto de treinamento, evidenciado pelo fato de termos superado o desempenho do modelo padrão de LSVR em dados não vistos. Infelizmente, não conseguimos superar o Modelo Linear nos mesmos dados de validação. Utilizamos a média do RMSE calculado por validação cruzada em séries temporais com 5 divisões (sem embaralhamento aleatório) para realizar a seleção dos modelos tanto no treinamento quanto na validação.
Posteriormente, exportamos nosso modelo LSVR personalizado para o formato ONNX e construímos nosso próprio Expert Advisor com IA integrada utilizando MQL5.
Coleta de Dados
Incluímos um script prático para você utilizar e buscar dados do seu terminal MetaTrader 5. Basta anexar o script a qualquer gráfico que você deseje analisar e começar.
O script buscará a quantidade de barras que você especificar nas entradas e gravará os dados em formato CSV. Registrar o tempo é vital porque utilizaremos essa informação posteriormente ao unir nossos arquivos CSV em um único DataFrame no Python. Uniremos nossos dados apenas nos dias em que todos compartilhem registros em comum.
Observe que incluímos a propriedade: “#property script_show_inputs” — se você não incluir essa propriedade em seus scripts, não poderá ajustar as entradas do script.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //---Amount of data requested input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void OnStart() { //---File name string file_name = "Market Data " + Symbol() + ".csv"; //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i)); } } } //+------------------------------------------------------------------+
Agora que nossos dados estão prontos, podemos começar a limpar os dados em Python.
Limpeza de Dados
Primeiramente, vamos importar as bibliotecas padrão que precisaremos.
#Import the libraries we need import pandas as pd import numpy as np
Esta é a versão das bibliotecas que estamos utilizando nesta demonstração.
#Display library versions print(f"Pandas version {pd.__version__}") print(f"Numpy version {np.__version__}")
Versão do Numpy 1.26.4
Agora, vamos ler os dados CSV que buscamos.
#Read in the data we need usdcad = pd.read_csv("\\home\\volatily\\.wine\\drive_c\\Program Files\\MetaTrader 5\\MQL5\\Files\\Market Data USDCAD.csv") usdcad = usdcad[::-1] xauusd = pd.read_csv("\\home\\volatily\\.wine\\drive_c\\Program Files\\MetaTrader 5\\MQL5\\Files\\Market Data XAUUSD.csv") xauusd = xauusd[::-1] xpdusd = pd.read_csv("\\home\\volatily\\.wine\\drive_c\\Program Files\\MetaTrader 5\\MQL5\\Files\\Market Data XPDUSD.csv") xpdusd = xpdusd[::-1]
Utilize a coluna de tempo como índice.
#Set the time column as the index usdcad.set_index("Time",inplace=True) xauusd.set_index("Time",inplace=True) xpdusd.set_index("Time",inplace=True)
Faça a junção (merge) dos dados.
#Let's merge the data
merged_data = usdcad.merge(xauusd,suffixes=('',' XAU'),left_index=True,right_index=True)
merged_data = merged_data.merge(xpdusd,suffixes=('',' XPD'),left_index=True,right_index=True)
Este é o visual dos nossos dados.
merged_data
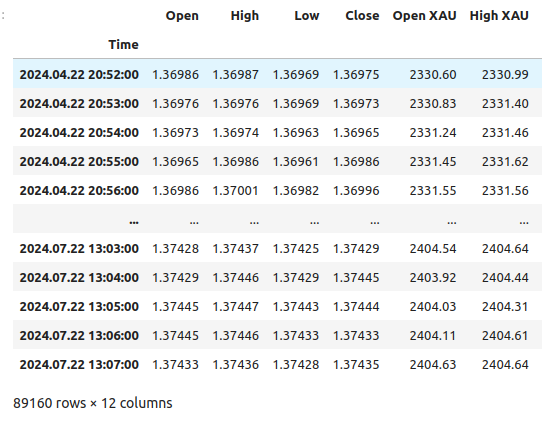
Figura 1: Nosso quadro de dados mesclado
Vamos definir quão longe no futuro desejamos fazer a previsão.
#Define the forecast horizon look_ahead = 20
Definimos os 3 grupos de preditores que desejamos testar.
#Define the predictors and target ohlc_predictors = ['Open','High','Low','Close'] new_predictors = ['Open XAU','High XAU','Low XAU','Close XAU','Open XPD','High XPD','Low XPD','Close XPD'] predictors = ohlc_predictors + new_predictors
Rotulando os dados.
#Let's add labels to the data merged_data["Target"] = merged_data["Close"].shift(-look_ahead)
Também vamos criar rótulos que serão úteis quando estivermos visualizando os dados. Esses rótulos irão resumir as mudanças em cada mercado.
#Let's also add labels to help us visualize the relationships merged_data["Binary Target"] = np.nan merged_data["XAU Target"] = np.nan merged_data["XPD Target"] = np.nan #Define the target values #Changes in the USDCAD Exchange rate merged_data.loc[merged_data["Close"] > merged_data["Target"],"Binary Target"] = 0 merged_data.loc[merged_data["Close"] < merged_data["Target"],"Binary Target"] = 1 #Changes in the price of Gold merged_data.loc[merged_data["Close XAU"] > merged_data["Close XAU"].shift(-look_ahead),"XAU Target"] = 0 merged_data.loc[merged_data["Close XAU"] < merged_data["Close XAU"].shift(-look_ahead),"XAU Target"] = 1 #Changes in the price of Palladium merged_data.loc[merged_data["Close XPD"] > merged_data["Close XPD"].shift(-look_ahead),"XPD Target"] = 0 merged_data.loc[merged_data["Close XPD"] < merged_data["Close XPD"].shift(-look_ahead),"XPD Target"] = 1 #Drop any NA values merged_data.dropna(inplace=True)
Análise Exploratória de Dados
Para visualizar nossos dados, primeiramente importaremos as bibliotecas necessárias.
#Explorartory data analysis import seaborn as sns import matplotlib.pyplot as plt
Exibindo as versões das bibliotecas.
#Display library version print(f"Seaborn version: {sns.__version__}")
Primeiro, vamos resetar o índice do nosso DataFrame mesclado.
#Reset the index
merged_data.reset_index(inplace=True)
Agora, vamos criar um mapa de calor de correlação. Como podemos ver, há níveis significativamente fortes de correlação entre os dois metais preciosos e o par USDCAD. Isso está em linha com nossa análise fundamentalista sobre o papel desempenhado por esses metais no Produto Interno Bruto de ambos os países. Infelizmente, isso não resultou em melhor desempenho ao tentar prever a taxa de câmbio do USDCAD.#Correlation heatmap fig , ax = plt.subplots(figsize=(7,7)) sns.heatmap(merged_data.loc[:,predictors].corr(),annot=True,ax=ax)

Fig 2: Nosso mapa de calor de correlação
Criamos dois gráficos categóricos resumindo todas as instâncias em que o preço do Ouro ou do Paládio subiu, coluna 1, ou caiu, coluna 2. A partir daí, colorimos cada ponto para indicar se a taxa de câmbio do USDCAD subiu, indicado pelos pontos laranja, ou caiu, indicado pelos pontos azuis. Como pode-se ver, temos uma mistura de ambos os resultados em ambas as colunas. Possivelmente sugerindo que as mudanças na taxa de câmbio do USDCAD são independentes das mudanças nos metais preciosos que escolhemos.
#Let's create categorical plots sns.catplot(data=merged_data,x="XAU Target",y="Close",hue="Binary Target")
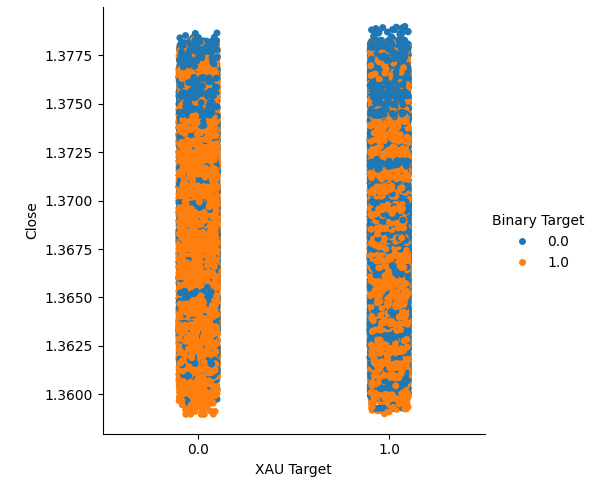
Fig 3: Gráfico categórico do preço do Ouro e do preço de fechamento do USDCAD
#Let's create categorical plots sns.catplot(data=merged_data,x="XPD Target",y="Close",hue="Binary Target")
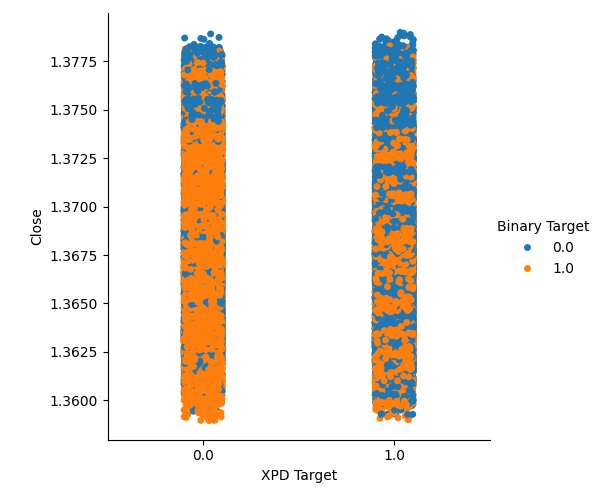
Fig 4: Gráfico categórico do preço do Paládio versus preço do USDCAD
Subsequentemente, criamos gráficos de dispersão para visualizar a variância entre o preço de fechamento do mercado de Paládio e o mercado de USDCAD. Infelizmente, isso não produziu nenhuma relação discernível que pudéssemos aproveitar. Colorimos cada ponto utilizando o mesmo mapa de cores laranja e azul descrito acima.
#Let's visualize scatter plots sns.scatterplot(data=merged_data,x="Close XPD",y="Close",hue="Binary Target")
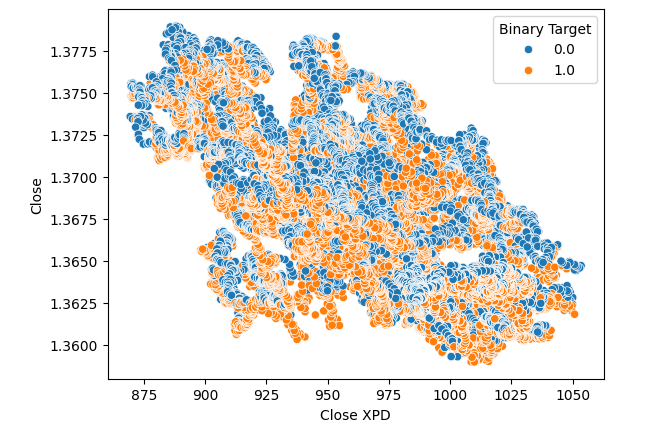
Fig 5: Gráfico de dispersão de XPDUSD versus USDCAD
Nenhuma melhoria foi observada quando substituímos o preço do Ouro pelo Paládio no gráfico de dispersão.
#Let's visualize scatter plots sns.scatterplot(data=merged_data,x="Close XAU",y="Close",hue="Binary Target")
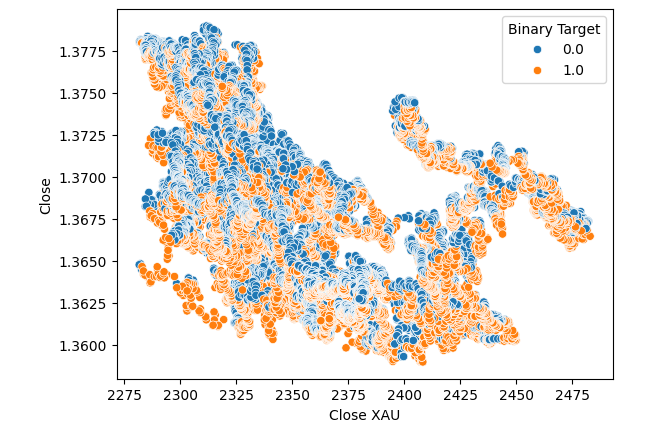
Fig 6: Gráfico de dispersão de XAUUSD versus o fechamento do USDCAD
Pensamos em testar uma relação entre os dois metais. No entanto, a relação ainda não era evidente para nós. Criamos um gráfico de dispersão do preço do Ouro contra o preço do Paládio e usamos a variação do par USDCAD para colorir cada ponto, mas isso não trouxe melhorias.
#Let's visualize scatter plots sns.scatterplot(data=merged_data,x="Close XPD",y="Close XAU",hue="Binary Target")
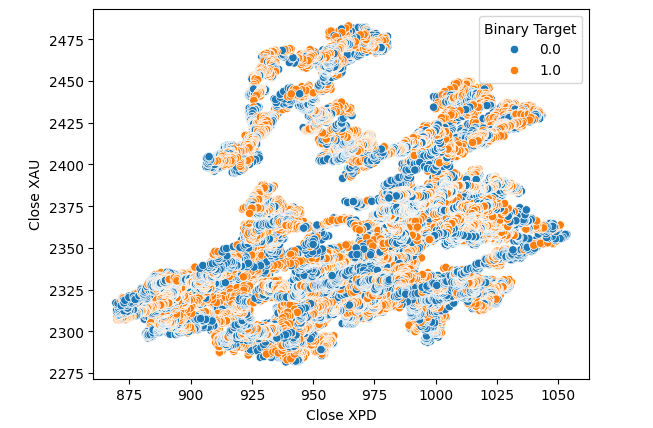
Fig 7: Gráfico de dispersão de XAUUSD contra XPDUSD
Às vezes, as relações podem estar ocultas porque não estamos observando variáveis suficientes ao mesmo tempo para perceber os efeitos. Criamos um gráfico de dispersão 3D, utilizando os preços de fechamento do Paládio, do Ouro e do USDCAD. Infelizmente, o gráfico gerado destacou o que parecem ser agrupamentos nos dados com baixos níveis de separação, basicamente reafirmando o que já sabíamos até agora.
#Visualizing 3D data fig = plt.figure(figsize=(7,7)) ax = fig.add_subplot(111,projection='3d') colors = ['blue' if movement == 0 else 'orange' for movement in merged_data.loc[0:1100,"Binary Target"]] ax.scatter(merged_data.loc[0:1100,"Close"],merged_data.loc[0:1100,"Close XAU"],merged_data.loc[0:1100,"Close XPD"],c=colors) #Set labels ax.set_xlabel('USDCAD') ax.set_ylabel('XAUUSD') ax.set_zlabel('XPDUSD')
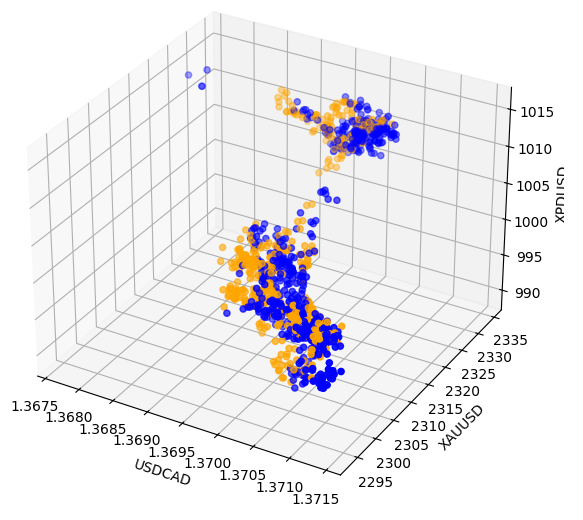
Fig 8: Visualização dos nossos dados de mercado em 3D
Modelagem de Dados
Vamos nos preparar para começar a modelar nossos dados. Primeiramente, importaremos as bibliotecas padrão.
#Modelling the data
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import RobustScaler
Exibindo as versões da biblioteca.
#Print library version print(f"Sklearn version {sklearn.__version__}")
Versão do Sklearn 1.4.1.post1
Antes de treinarmos qualquer modelo, precisamos escalar e padronizar os dados.
#Scale the data
scaled_data = pd.DataFrame(RobustScaler().fit_transform(merged_data.loc[:,predictors]),columns=predictors)
Agora vamos dividir os dados em duas metades, uma para treinamento e otimização, e a outra para validação e detecção de sobreajuste (overfitting).
#Split the data train_X,test_X,train_y,test_y = train_test_split(scaled_data,merged_data.loc[:,"Target"],shuffle=False,test_size=0.5)
Agora, importe os modelos.
#Preparing to model the data from sklearn.model_selection import TimeSeriesSplit from sklearn.linear_model import LinearRegression from sklearn.ensemble import RandomForestRegressor , GradientBoostingRegressor , BaggingRegressor from sklearn.svm import LinearSVR from sklearn.neighbors import KNeighborsRegressor from sklearn.neural_network import MLPRegressor from sklearn.metrics import root_mean_squared_error
Criar o objeto de divisão de séries temporais.
#Create the time series split object tscv = TimeSeriesSplit(gap=look_ahead,n_splits=5)
Armazene os modelos em uma lista para que possamos iterar sobre eles.
#Create a list of models models = [ LinearRegression(), RandomForestRegressor(), GradientBoostingRegressor(), BaggingRegressor(), LinearSVR(), KNeighborsRegressor(), MLPRegressor(hidden_layer_sizes=(100,10)) ]
Crie um DataFrame para armazenar nossos níveis de acurácia.
#List of models columns = [ "Linear Regression", "Random Forest", "Gradient Boost", "Bagging", "Linear SVR", "K-Neighbors", "Neural Network" ] #Create a dataframe to store our error metrics ohlc_error = pd.DataFrame(columns=columns,index=np.arange(0,5)) new_error = pd.DataFrame(columns=columns,index=np.arange(0,5)) all_error = pd.DataFrame(columns=columns,index=np.arange(0,5))
Defina os preditores a serem usados.
#Setting the current predictors
current_predictors = predictors
Faça a validação cruzada de cada modelo utilizando os preditores definidos acima.
#Perform cross validation for j in np.arange(0,len(models)): model = models[j] for i,(train,test) in enumerate(tscv.split(train_X)): model.fit(train_X.loc[train[0]:train[-1],current_predictors],train_y.loc[train[0]:train[-1]]) all_error.iloc[i,j] = root_mean_squared_error(train_y.loc[test[0]:test[-1]],model.predict(train_X.loc[test[0]:test[-1],current_predictors]))
Vamos observar nossos níveis de erro utilizando dados OHLC comuns. A partir de nossas visualizações e estatísticas resumidas, fica claro que o modelo de Regressão Linear teve o melhor desempenho nesta tarefa.
ohlc_error
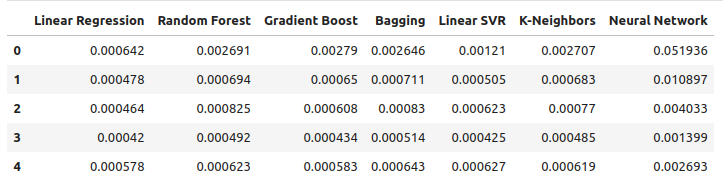
Fig 9: Nossos níveis de erro ao prever com dados OHLC do USDCAD
Plotando os dados.
ohlc_error.plot()
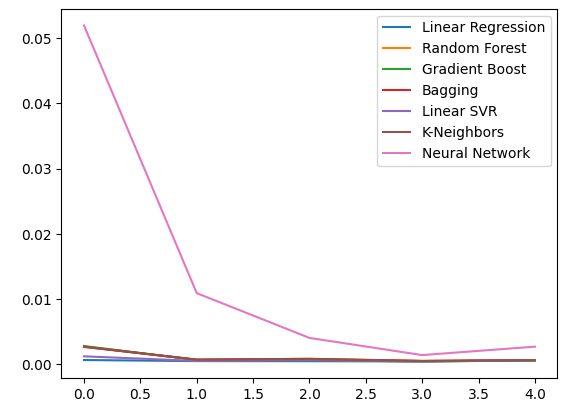
Fig 10: Acurácia dos nossos modelos utilizando o primeiro conjunto de preditores
Criando gráficos de caixa (box-plots).
fig = plt.figure(figsize=(5,5)) plt.boxplot(ohlc_error)
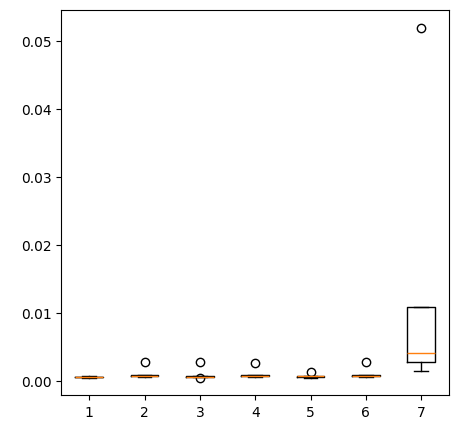
Fig 11: Acurácia dos nossos modelos ao prever com o primeiro grupo de preditores
Vamos observar nossos níveis de erro ao utilizar os metais preciosos para prever a taxa de câmbio do USDCAD. A regressão linear ainda é o modelo com melhor desempenho, porém, já não com ampla vantagem.
new_error
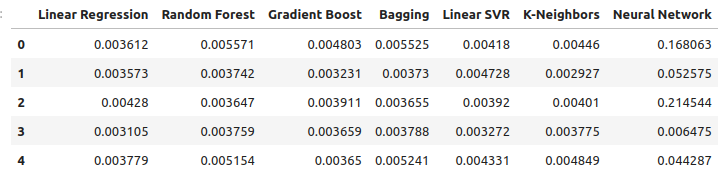
Fig 12: Nossos novos níveis de erro
Plotando os novos níveis de erro.
new_error.plot()
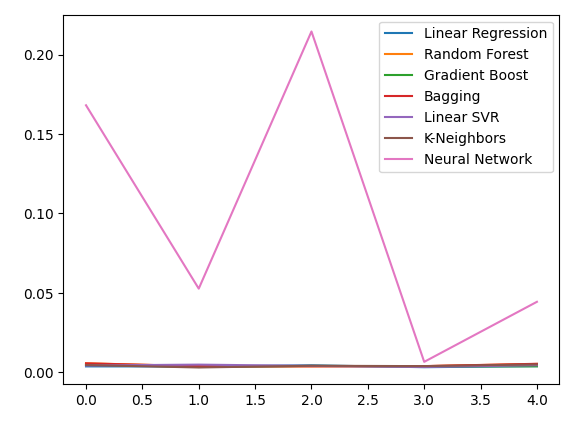
Fig 13: Nossos novos níveis de erro
Criando um box-plot dos novos resultados.
fig = plt.figure(figsize=(5,5)) plt.boxplot(new_error)
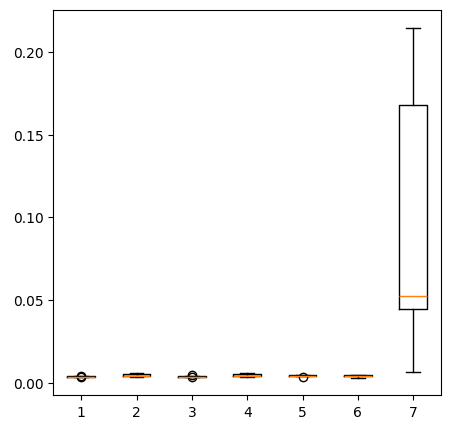
Fig 14: Nossos níveis de erro ao usar dados do mercado de metais preciosos
Agora, vamos considerar nosso desempenho ao utilizar todos os dados disponíveis. Observamos que o modelo linear ainda tem desempenho superior a todos os demais modelos. Vamos tentar otimizar o segundo melhor modelo, o LinearSVR, para superar a Regressão Linear.
all_error
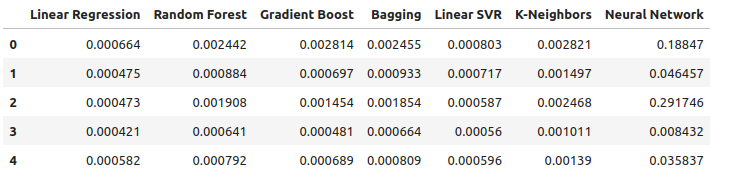
Fig 15: Nossa acurácia ao usar todos os dados disponíveis
Plotando os níveis de erro.
all_error.plot()
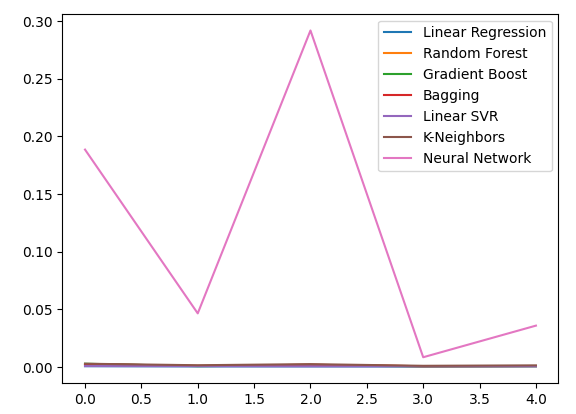
Fig 16: Gráficos de linhas da nossa acurácia usando todos os dados disponíveis
Criando um box-plot dos níveis de erro obtidos ao usar todos os dados disponíveis mostra que a regressão linear simples ainda é nossa melhor escolha.
fig = plt.figure(figsize=(5,5)) plt.boxplot(all_error)
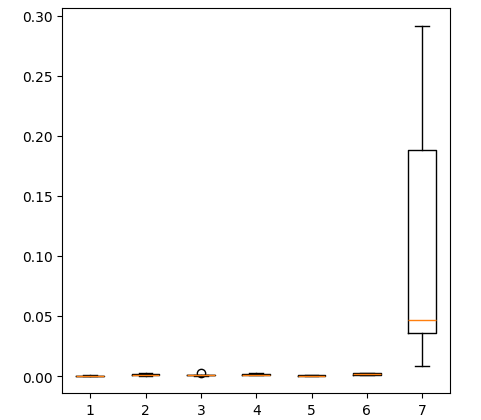
Fig 17: Box-plots da nossa acurácia ao utilizar todos os dados disponíveis
Os níveis médios de erro dos nossos modelos ao longo dos 5 conjuntos de validação mostram claramente que o modelo linear é nossa melhor escolha até agora. Contudo, o LinearSVR não está muito atrás.
all_error.mean()
Regressão Linear 0.000523
Random Forest 0.001333
Gradient Boost 0.001227
Bagging 0.001343
Linear SVR 0.000653
K-Neighbors 0.001837
Rede Neural 0.114188
dtype: object
Importância das Variáveis
Antes de começarmos a otimizar nosso modelo, vamos primeiro avaliar quais variáveis parecem importantes. Esperamos que os dados relacionados ao mercado de metais preciosos mostrem seu valor neste teste. Vamos começar testando os níveis de informação mútua (MI). MI é uma medida de quanto conhecimento se ganha sobre o valor do alvo ao saber o valor de um dos preditores. MI está em escala logarítmica, portanto, um valor de MI acima de 2 é raro de se encontrar na prática.
Começamos importando as bibliotecas que precisamos.
#Mutual information score
from sklearn.feature_selection import mutual_info_regression
Agora, calculamos os valores de MI para cada um dos nossos preditores.
#Prepare the data for plotting mi = mutual_info_regression(train_X,train_y) mi = mi.reshape(1,12) mi_scores = pd.DataFrame(mi,columns=predictors)
A visualização dos valores de MI sugere que os dados do mercado USDCAD podem ser mais informativos do que todos os dados do mercado de metais preciosos. Isso é validado por nosso teste de validação cruzada, no qual observamos que o Modelo Linear usando apenas as cotações do mercado USDCAD produziu o menor erro.
#Prepare the data for plotting mi = mutual_info_regression(train_X,train_y) mi = mi.reshape(1,12) mi_scores = pd.DataFrame(mi,columns=predictors) #Plot the scores mi_scores.plot.bar()
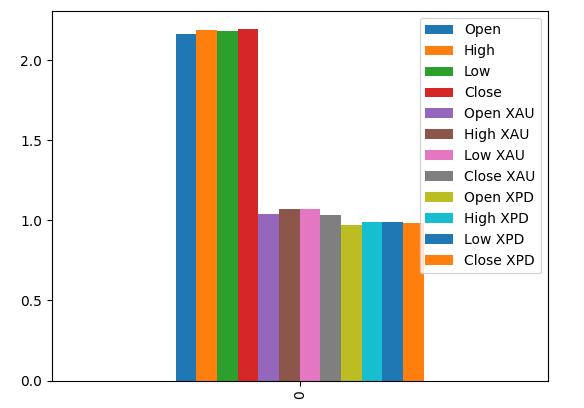
Fig 18: Valores de informação mútua entre nossos 3 conjuntos de dados
Em seguida, vamos calcular os valores SHAP. Os valores SHAP são explicadores de caixa-preta que nos ajudam a identificar a importância global das variáveis em nossos modelos de machine learning.
Importe a biblioteca SHAP.
#The Linear SVR appears to be performing second best
import shap
Inicialize o modelo LSVR.
#Initialize the model
model = LinearSVR()
model.fit(train_X,train_y)
Calcule os valores SHAP.
#Compute SHAP values
explainer = shap.Explainer(model,train_X)
explanations = explainer(train_X)
Mostre a importância global das variáveis.
#Plot SHAP values
shap.plots.violin(explanations)
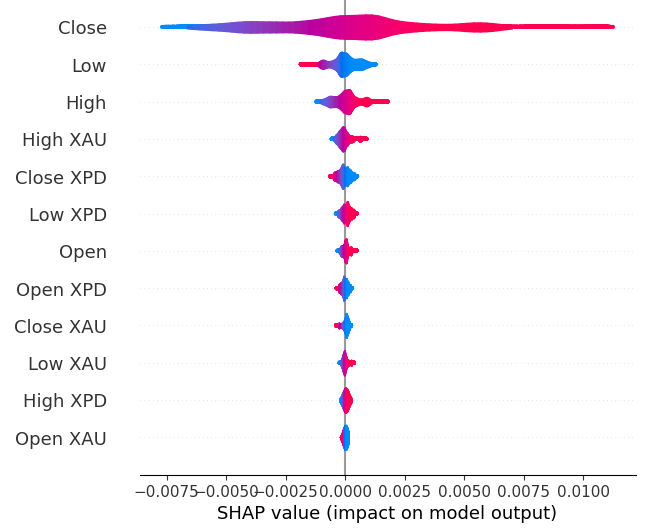
Fig 19: Níveis de importância segundo SHAP
Nossas explicações via SHAP discordam da análise de Informação Mútua. Exploramos esse problema de discordância extensivamente em artigos anteriores — o melhor que podemos dizer é que avaliar a importância das variáveis pode ser desafiador e deve ser feito com cautela. Contudo, ambas as explicações sugerem que há informações úteis contidas nos mercados de metais preciosos.
Ajuste de Hiperparâmetros
Ajustar nosso modelo pode nos permitir um desempenho melhor em dados não vistos do que ao utilizar o modelo com parâmetros padrão.Para ajustar nosso modelo, primeiro vamos importar as bibliotecas necessárias.
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV
Agora inicialize o modelo.
#Reinitialize the model
model = LinearSVR()
Em seguida, definimos nossos parâmetros de ajuste. Passamos o modelo e um dicionário com os valores possíveis de parâmetros, seguido pelo número total de iterações que desejamos executar. Queremos realizar validação cruzada com 5 divisões para medir o erro quadrático médio negativo. Isso significa que selecionaremos o modelo com o menor erro de validação. Por fim, ao configurar n_jobs = -1, permitimos que a busca ocorra em paralelo em todos os núcleos disponíveis do processador.
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"epsilon" : [0,10,100,1000],
"tol":[0.01,0.001,0.0001,0.00001,0.0000001],
"C":[1,10,100,1000,10000],
"loss":['epsilon_insensitive', 'squared_epsilon_insensitive']
},
n_iter=1000,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
)
Treine o otimizador (tuner).
#Let's fit the tuner tuner_results = tuner.fit(train_X,train_y)
Os melhores parâmetros que encontramos.
#Let's see the best parameters we found tuner_results.best_params_
{'tol': 1e-05, 'loss': 'squared_epsilon_insensitive', 'epsilon': 0, 'C': 10000}
Testando para Overfitting
Para testar o sobreajuste, primeiro precisamos inicializar nossos modelos.#Testing for overfitting benchmark = LinearRegression() default_lsvr = LinearSVR() customized_lsvr = LinearSVR(tol=1e-05,loss='squared_epsilon_insensitive',epsilon=0,C=10000)
Agora, reinicialize os índices para que possamos executar a validação cruzada.
#Reset the indexes
test_y = test_y.reset_index()
test_X = test_X.reset_index()
Formate os dados.
#Format the data test_y = test_y.loc[:,"Target"] test_X = test_X.loc[:,predictors]
Criando um data frame para armazenar nossos níveis de erro.
#Create dataframes to store our error levels test_error = pd.DataFrame(columns=["Linear Regression","LSVR","Customized LSVR"],index=[0,1,2,3,4])
Treine os modelos no conjunto de treinamento.
#Fit the models on the training set
benchmark.fit(train_X,train_y)
default_lsvr.fit(train_X,train_y)
customized_lsvr.fit(train_X,train_y)
Armazene os modelos em uma lista.
models = [benchmark,default_lsvr,customized_lsvr]
Validação cruzada de cada modelo no conjunto de teste.
for j in np.arange(0,len(models)): model = models[j] for i,(train,test) in enumerate(tscv.split(test_X)): model.fit(test_X.loc[train[0]:train[-1],:],test_y.loc[train[0]:train[-1]]) test_error.iloc[i,j] = root_mean_squared_error(test_y.loc[test[0]:test[-1]],model.predict(test_X.loc[test[0]:test[-1],:]))
Nosso erro de teste.
test_error
| Regressão Linear | LSVR | LSVR Personalizado |
|---|---|---|
| 0.000598 | 0.000542 | 0.000743 |
| 0.000472 | 0.000573 | 0.000722 |
| 0.000318 | 0.000451 | 0.000333 |
| 0.000341 | 0.000366 | 0.000499 |
| 0.00043 | 0.000839 | 0.00043 |
De acordo com nosso desempenho médio em todas as 5 dobras, nosso modelo linear ainda foi o modelo de melhor desempenho. No entanto, conseguimos superar o modelo padrão.
#Let's calculate our mean performances test_error.mean()
Regressão Linear 0.000432
LSVR 0.000554
LSVR Personalizado 0.000545
dtype: object
Visualizando nosso erro de teste.
#Let's visualize our error test_error.plot()
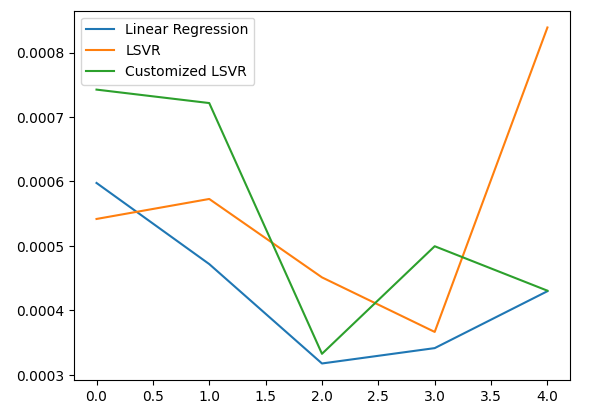
Fig 20: Visualizando nosso erro de teste
Criando um box-plot das taxas de erro de teste.
#Create a boxplot of the error
sns.boxplot(data=test_error)
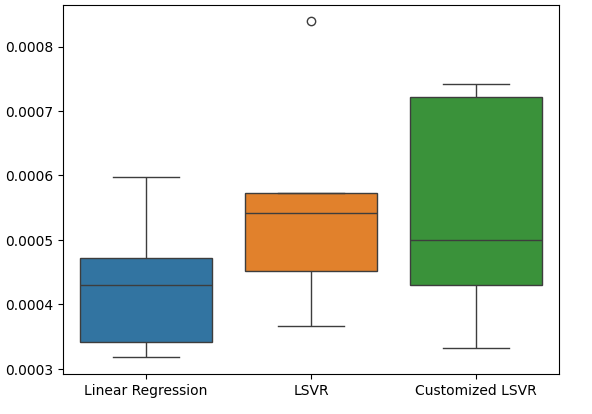
Fig 21: Visualizando nosso erro de teste
Preparando o Modelo para Exportação em ONNX
Antes de podermos exportar nosso modelo para o formato ONNX, precisamos primeiro escalar e padronizar os dados, subtraindo a média e dividindo pelo desvio padrão. A partir disso, gravaremos nossos fatores de escala em um arquivo CSV para podermos reproduzir o procedimento no MQL5.
Primeiro, crie o DataFrame para armazenar nossos fatores de escala.
#Let's scale our data scaling_factors = pd.DataFrame(columns=predictors,index=['mean','standard deviation']) X = merged_data.loc[:,predictors] y = merged_data.loc[:,"Target"]
Depois armazene a média e o desvio padrão e, por fim, realize o procedimento de escalonamento.
#Let's fill each column for i in np.arange(0,len(predictors)): scaling_factors.iloc[0,i] = X.iloc[:,i].mean() scaling_factors.iloc[1,i] = X.iloc[:,i].std() X.iloc[:,i] = ( ( X.iloc[:,i] - scaling_factors.iloc[0,i] ) / scaling_factors.iloc[1,i])
Salve os fatores de escala.
#Save the scaling factors as a CSV scaling_factors.to_csv("/home/volatily/.wine/drive_c/Program Files/MetaTrader 5/MQL5/Files/usd_cad_xau_xpd_scaling_factors.csv")
Exportando o Modelo para ONNX
ONNX significa Open Neural Network Exchange (ONNX) e é um framework de machine learning de código aberto e interoperável que permite aos desenvolvedores criar, compartilhar e implementar modelos de aprendizado de máquina de forma independente da linguagem. Isso é possível ao representar cada modelo de machine learning como uma árvore de nós e grafos que pode ser remontada ao modelo original por qualquer linguagem que suporte a API ONNX.
Primeiro, vamos importar as bibliotecas necessárias.
#Let's prepare to export our model to ONNX format import onnx import netron import skl2onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Exibindo as versões das bibliotecas.
#Display library versions print(f"Onnx version: {onnx.__version__}") print(f"Netron version: {netron.__version__}") print(f"Skl2onnx version: {skl2onnx.__version__}")
Versão do Onnx: 1.15.0
Versão do Netron: 7.8.0
Versão do Skl2onnx: 1.16.0
Agora, vamos definir os tipos de entrada do nosso modelo.
#Define the input type
initial_types = [('float_input',FloatTensorType([1,12]))]
Vamos treinar o modelo com todos os dados que temos.
#Train the model on all the data we have customized_lsvr = LinearSVR(tol=1e-05,loss='squared_epsilon_insensitive',epsilon=0,C=10000) customized_lsvr.fit(X,y)
Converter o modelo para o formato ONNX.
#Covert the sklearn model
onnx_model = convert_sklearn(customized_lsvr,initial_types=initial_types)
Salvar o modelo ONNX.
#Save the onnx model onnx_name = "USDCAD XAUUSD XPDUSD M1 Float.onnx" onnx.save(onnx_model,onnx_name)
Visualizar o modelo ONNX.
#View the onnx model
netron.start(onnx_name)

Fig 22: Visualizando nosso modelo ONNX no Netron

Fig 23: Os parâmetros do nosso modelo ONNX estão de acordo com nossas expectativas para entrada e saída do modelo
Implementação no MQL5
Para implementarmos um Expert Advisor com IA integrada em MQL5, precisamos primeiro carregar o modelo ONNX que exportamos anteriormente.
//+------------------------------------------------------------------+ //| USDCAD AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Resources | //+------------------------------------------------------------------+ #resource "\\Files\\USDCAD XAUUSD XPDUSD M1 Float.onnx" as const uchar onnx_buffer[];
Em seguida, devemos carregar a biblioteca de negociação para que possamos abrir e fechar posições.
//+------------------------------------------------------------------+ //| Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Também devemos definir algumas variáveis globais que utilizaremos ao longo do programa.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; double mean_values[12],std_values[12]; vectorf model_output = vectorf::Zeros(1); int model_forecast,state; double ask,bid;
Vamos definir funções auxiliares que utilizaremos em nosso programa. Precisamos de uma função responsável por carregar nosso modelo ONNX e definir as formas de entrada e saída. Faremos isso usando uma função que retorna true se for bem-sucedida, e false caso contrário. Nossa função primeiro cria o modelo a partir do buffer criado anteriormente, e então tenta definir e validar os formatos de entrada e saída.
//+------------------------------------------------------------------+ //| This function is responsible for loading our ONNX model | //+------------------------------------------------------------------+ bool load_onnx(void) { //--- First we must create the model from the buffer onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Now we shall define our I/O shape ulong input_shape [] = {1,12}; ulong output_shape [] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set ONNX input shape!"); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set ONNX output shape!"); return(false); } //--- Everything went fine return(true); } //+------------------------------------------------------------------+
Esta função é responsável por ler o arquivo CSV com nossos valores de escalonamento e armazená-los nos arrays de escopo global que definimos.
//+------------------------------------------------------------------+ //| This function will read our scaling factors and store them | //+------------------------------------------------------------------+ bool load_scaling_factors(void) { //--- Read in the file string file_name = "usd_cad_xau_xpd_scaling_factors.csv"; //--- Try open the file int result = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,","); //Strings of ANSI type (one byte symbols). //--- Check the result if(result != INVALID_HANDLE) { Print("Opened the file"); //--- Store the values of the file int counter = 0; string value = ""; while(!FileIsEnding(result) && !IsStopped()) //read the entire csv file to the end { if(counter > 100) //if you aim to read 10 values set a break point after 10 elements have been read break; //stop the reading progress value = FileReadString(result); Print("Trying to read string: ",value," count value: ",counter); //--- Check where we are if((counter >= 14) && (counter < 26)) { mean_values[counter - 14] = (float) value; } //--- Check where we are if((counter >= 27) && (counter < 39)) { std_values[counter - 27] = (float) value; } //--- Reading a new row if(FileIsLineEnding(result)) { Print("row++"); } counter++; } //---Close the file ArrayPrint(mean_values); ArrayPrint(std_values); FileClose(result); return(true); } //--- We failed to find the file else { Comment("Failed to find the file containing scaling factors"); return(false); } }
Também precisamos de uma função responsável por buscar as cotações de preços atualizadas do mercado.
//+------------------------------------------------------------------+ //| Update market prices | //+------------------------------------------------------------------+ void update_market_prices(void) { ask = SymbolInfoDouble(_Symbol,SYMBOL_ASK); bid = SymbolInfoDouble(_Symbol,SYMBOL_BID); }
Por fim, precisamos de uma função para obter previsões do nosso modelo. Nossa função predict escalará os dados antes de passá-los ao modelo.
//+------------------------------------------------------------------+ //| Model predict | //+------------------------------------------------------------------+ void model_predict(void) { //--- First fetch the market data vectorf model_input = { iOpen("USDCAD",PERIOD_CURRENT,0),iHigh("USDCAD",PERIOD_CURRENT,0),iLow("USDCAD",PERIOD_CURRENT,0),iClose("USDCAD",PERIOD_CURRENT,0), iOpen("XAUUSD",PERIOD_CURRENT,0),iHigh("XAUUSD",PERIOD_CURRENT,0),iLow("XAUUSD",PERIOD_CURRENT,0),iClose("XAUUSD",PERIOD_CURRENT,0), iOpen("XPDUSD",PERIOD_CURRENT,0),iHigh("XPDUSD",PERIOD_CURRENT,0),iLow("XPDUSD",PERIOD_CURRENT,0),iClose("XPDUSD",PERIOD_CURRENT,0) }; //--- Now standardize and scale the data for(int i =0; i < 12; i++) { model_input[i] = ((model_input[i] - mean_values[i]) / std_values[i]); } //--- Now fetch a prediction from our model OnnxRun(onnx_model,ONNX_DEFAULT,model_input,model_output); //--- Store our model's forecat if(model_output[0] > iClose("USDCAD",PERIOD_CURRENT,0)) { model_forecast = 1; } else if(model_output[0] < iClose("USDCAD",PERIOD_CURRENT,0)) { model_forecast = -1; } }
Ao inicializar nosso Expert Advisor, primeiro carregaremos o arquivo ONNX e depois leremos os valores de escalonamento. Se qualquer um desses procedimentos falhar, abortaremos todo o processo.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- This function will load our ONNX model if(!load_onnx()) { return(INIT_FAILED); } //--- This function will load our scaling factors if(!load_scaling_factors()) { return(INIT_FAILED); } //--- return(INIT_SUCCEEDED); }
Sempre que nosso Expert Advisor for removido do gráfico, devemos liberar os recursos que não são mais necessários.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we do not need OnnxRelease(onnx_model); ExpertRemove(); }
Finalmente, sempre que recebermos alterações nos preços de bid e ask, armazenaremos os preços atualizados na memória e obteremos uma nova previsão do nosso modelo de IA. Se não tivermos nenhuma posição aberta, abriremos a posição sugerida pelo modelo. Caso já exista uma posição aberta, verificaremos se a nova previsão do modelo não está indo contra nossa posição atual.
void OnTick() { //--- Update the market prices update_market_prices(); //--- Fetch a forecast from our model model_predict(); //--- Find a trading oppurtunity if(PositionsTotal() == 0) { if(model_forecast == -1) { Trade.Sell(0.2,_Symbol,ask,0,0,"USDCAD AI"); state = -1; } else if(model_forecast == 1) { Trade.Buy(0.2,_Symbol,ask,0,0,"USDCAD AI"); state = 1; } } //--- Check for reversals if(PositionsTotal() > 0) { if(state != model_forecast) { Alert("Reversal detected by our AI system, closing all positions now!"); Trade.PositionClose(_Symbol); } } } //+------------------------------------------------------------------+

Fig 24: Nosso Expert Advisor em ação.

Fig 25: Nosso sistema de IA detectou uma possível reversão
Conclusão
No artigo de hoje, demonstramos como você pode descobrir relações ocultas que podem existir entre mercados interrelacionados. No entanto, vale ressaltar que nossa análise empírica mostra que podemos obter melhores resultados utilizando apenas dados de mercado comuns e modelos lineares mais simples. Isso pode ser verdade porque, como todos sabemos, os dados de mercado podem ser ruidosos. E em casos de dados ruidosos, modelos mais simples tendem a superar modelos mais complexos, pois os modelos complexos são mais sensíveis às variações nos dados de entrada.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/15762
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Mais uma vez, obrigado Gamuchirai, outro modelo excelentemente documentado. É muito útil ter exemplos práticos sobre como determinar a importância dos recursos, a correlação e visualizar o resultado usando os diferentes modelos de dados. À medida que lemos, aprendemos sobre Aprendizado de Máquina, obrigado. A lição de hoje para mim foi sobre os valores "SHAP". Mais uma vez, obrigado pelo trabalho, estou sempre me surpreendendo com as ferramentas que o Python tem à disposição