
Simulação de mercado (Parte 18): Iniciando o SQL (I)

Introdução
No artigo anterior Simulação de mercado (Parte 17): Sockets (XI), finalizei a demonstração de uma implementação que nos permite fazer a troca de informações entre o MetaTrader 5 e o Excel. Apesar de eu não ter me aprofundado muito no que diz respeito a fazer com que o Excel controle o MetaTrader 5. Isto por conta de que ao fazer isto, você deve fazer com o devido cuidado. E por ser algo totalmente dependente do que cada um pensa ou espera fazer. Apenas deixei algumas referências no final daquele artigo para que você tenha uma ideia do como fazer as coisas.
Não importa se vamos usar um ou outro programa de SQL. Seja MySQL, SQL Server, SQLite, OpenSQL ou qualquer outro. Todos tem algo em comum entre si. Este algo em comum é a linguagem SQL. Pois bem, mesmo que você não venha a usar de fato uma Workbench, poderá fazer manipulações ou trabalhar com um banco de dados diretamente no MetaEditor ou via MQL5. Isto pensando em fazer as coisas no MetaTrader 5. Mas para de fato conseguir fazer as coisas assim, você precisará de algum conhecimento sobre SQL. Existem muitos livros voltados a explicar sobre o assunto. Assim como diversos tutoriais disponíveis na Web. Tudo que você realmente precisa é entender alguns conceitos e compreender como usar a sua linguagem de programação, a fim de conseguir conversar com o SQL.
Porém existem limitações, ou melhor dizendo, alguns detalhes, dos quais você deverá saber, antes mesmo de começar a fazer uso do SQL. Isto por que você não conseguirá de forma alguma, estudar sobre SQL, se não conseguir se quer criar um banco de dados. Este talvez seja o ponto inicial a ser aprendido e compreendido por você, caro leitor.
Começando a trabalhar com bancos de dados
Existem algumas formas, bem básicas, de se fazer uso do SQL. A primeira é digitando diretamente os comandos em um prompt. Outra forma é usando um Workbench ou programa similar, como o MetaEditor. Uma outra forma é adicionando comandos SQL, em seu programa, que no caso será escrito em MQL5 e ao executar este programa no MetaTrader 5, ter acesso ao banco de dados. E por fim, existe uma última forma básica, que é usando soquetes para se comunicar com o servidor SQL, seja ele qual for. Todas estas formas básicas, são amplamente disponíveis em todos os sistemas de banco de dados que usam o SQL. Então tudo que será mostrado e explicado, poderá ser usado em qualquer sistema compatível. Não fique imaginando que não dá para fazer isto ou aquilo. Se você usar o SQL puro e nativo, conseguirá fazer as coisas.
Mas aqui mora um detalhe, do qual você deverá ficar alerta. Cada um dos programas que utilizam o SQL. Seja ele o OpenSQL, o MySQL, o SQLite, o SQL Server ou qualquer outro, podem ter comandos que são dirigidos a aquele programa específico. Neste caso, se você fizer uso daquele comando, não conseguirá executar as mesmas coisas em um outro programa SQL.
Uma outra coisa, nestes primeiros momentos, tudo que será feito, será feito usando a WorkBench do MySQL. O motivo explicarei um pouco mais para frente.
Dado estes avisos, podemos começar vendo o comando mais básico de todos. O de criar um banco de dados vazio. E sim, não adianta você criar um arquivo qualquer e renomear ele com a extensão .DB, pois isto não será entendido como sendo um banco de dados. É preciso usar um comando para fazer isto. Tal comando é muito simples. Mas antes de ver qualquer comando, vamos ver uma outra coisa.
É muito comum, e sendo quase considerado uma boa prática em programação SQL. Usar as palavras reservadas em caixa alta. Porém, para o SQL isto não faz diferença. Mas se você durante a digitação se esquecer de colocar os comandos em caixa alta. Não precisa se preocupar tudo que você precisará fazer será usar o ponto que está em destaque na imagem abaixo. Isto tornará todo o código, ou palavras reservadas do SQL, em caixa alta.

Os primeiros comandos em SQL
Agora sim, podemos começar a ver os comandos. E o primeiro comando a ser usado e aprendido é: CREATE DATABASE. Na imagem abaixo, você pode ver como ele se parece de fato.

O texto em azul e negrito é o código em SQL, já o texto em preto é o nome que o banco de dado terá. Este é o primeiro comando que você deverá usar. Depois de digitar este comando, você poderá clicar em um dos ícones de raio que podem ser vistos acima do código. Cada um destes raios, funcionam de uma maneira. Como estamos começando você pode clicar no que se encontra na extrema esquerda. Mas é bom que você procure entender o que cada um faz e como eles trabalham, pois isto lhe ajudará muito, principalmente quando for debugar um script. Falarei um pouco sobre isto em breve. Agora preste atenção a uma coisa. Se você desejar fazer uso do SQL diretamente no MetaEditor. Para criar o banco de dados, você deverá fazer algo diferente. Neste caso você deverá selecionar a opção destacada na imagem abaixo.

Ao fazer isto, o MetaEditor, irá lhe pedir para informar a localização e o nome do arquivo de banco de dados a ser criado. Tal coisa é bastante simples de ser feita e direta. Também podemos fazer esta mesma criação usando um código escrito em MQL5. Mas isto será visto depois, já que o melhor é que tenhamos um pouco mais de material para realmente criar as coisas diretamente via MQL5, ou qualquer outra linguagem que você venha a usar para trabalhar com o SQL. Porém, se você fizer uso de soquetes em um código MQL5 e se conectar ao servidor SQL, poderá enviar o comando mostrado na WorkBench e terá o mesmo resultado. Ou seja, a criação do banco de dados.
No entanto, este é tema para uma outra oportunidade. No momento, vamos fazer as coisas da maneira mais simples e direta. Ou seja, usando ou o MetaEditor ou uma WorkBench, ou até mesmo o prompt. Porém no prompt você tem realmente que entender como as coisas serão mostradas. Mas isto é somente uma questão de se acostumar com o prompt.
Porém, como a ideia aqui é ser o mais didático possível, vamos fazer uso apenas do MetaEditor e do WorkBench.
Muito bem, ao se fazer as coisas no MetaEditor, você terá no final algo parecido com a imagem abaixo. Repare que neste caso, para diferenciar os bancos de dados, o nomeie de forma diferente do que foi feito na WorkBench.

Neste ponto o MetaEditor, já estará pronto para que possamos fazer os próximos passos. Porém no que se refere ao que está sendo feito na WorkBench ainda não podemos passar para o próximo passo. Precisamos de alguns passos extras. Para entender o que será preciso fazer, você poderá clicar neste ponto em destaque na imagem abaixo. Isto depois de executar o comando presente no script.

Usar qualquer um destes dois pontos terá o mesmo resultado. Agora temos um detalhe, observe na imagem abaixo, que o nosso arquivo a ser usado como banco de dados foi criado. Mas veja que ele não se encontra selecionado para receber novos comandos do SQL.

Sempre que você for fazer algo em um banco de dados, precisa selecionar este banco. Uma das formas de fazer isto, é utilizando um comando de SQL. Este comando é o USE. Você pode ver ele logo abaixo.

Agora tem um detalhe aqui no uso da WorkBench. Se você estiver usando o prompt para fazer as coisas, você terá que digitar neste momento apenas o conteúdo da linha dois. E poderá seguir para o próximo passo. Porém, aqui na WorkBench, a coisa funciona um pouco diferente. Note que destaquei dois dos ícones de raio. Agora vamos entender como isto funciona. Quando estamos criando um script para SQL, muitas vezes digitamos diversos comandos. E o motivo de usar um script é para documentação. Mas ao usar um script, você teve tomar alguns outros cuidados. O primeiro é: Se o script for se executado em um único passo, você não terá problemas nele. Porém, se você for executar o mesmo script aos poucos, terá alguns problemas se tentar executá-lo desde o início. Por conta disto é que muitos desistem de estudar SQL. Pois não conseguem lidar com os problemas que vão surgindo.
Ok. O que queremos é que a linha dois seja executada. Para fazer isto temos três alternativas neste momento. A primeira, é selecionar a linha dois e pressionar o botão destacado que está a esquerda. A segunda alternativa é colocar o cursor de texto na linha dois é pressionar o botão destacado que esteja na direita. Repare que este tem um ícone de cursor junto dele. Isto faz com que apenas e somente a linha onde o cursor esteja, seja executa.
E existe uma terceira alternativa, esta na verdade é mais usada quando queremos forçar o código a ser executado desde o início. Mesmo quando ele foi executado de forma parcial. Para fazer isto precisaremos criar um teste aqui no SQL. Isto por que, se o código tentar executar desde o seu início, termos um erro imediatamente na execução da primeira linha. Mas como assim? O motivo é que o SQL irá tentar criar novamente o arquivo do banco de dados. E esta tentativa irá falhar por que o arquivo já existe. Assim todo o restante do código não será executado. Você pode experimentar isto clicando no ícone a esquerda sem selecionar nenhuma linha.
E como muitas das vezes poderemos estar trabalhando com um script, onde o banco de dados já existe, mas queremos apenas modificar algo no banco fazendo a mudança no próprio script. Apagar o banco de dados é uma alternativa a ser descartada. Então para solucionar isto, poderíamos comentar a primeira linha, adicionando um Traço-Traço como mostrado na imagem abaixo. Ou fazer algo um pouco diferente.

Aproveitando a imagem acima, você tem duas formas de fazer comentários em um código SQL. A primeira é justamente a mostrada na imagem, onde a linha um agora passou a ser entendida pelo SQL como sendo um comentário. Esta forma é útil quando se deseja comentar uma única linha. Mas também podemos comentar diversas linhas ao mesmo tempo. Para isto basta usada a mesma forma que fazemos no MQL5, ou seja, usando barra asterisco.
Muito bem, mas apesar da imagem acima, ser uma solução plausível, ela de fato não se harmoniza quando o código em SQL é longo e contém muitas partes que podem falhar, por já existirem no banco de dados. Assim sendo precisamos de uma solução um pouco mais elegante. Esta pode ser vista na imagem abaixo.

Veja que na linha um temos um comando um pouco diferente. Porém, este comando garante que o script será executado corretamente, e da forma como esperado. Isto por que se o arquivo de banco de dados não existir ele será criado. Porém, se ele já existir, o SQL não verá isto como erro, já que estamos testando a presença ou não do arquivo. Este tipo de construção usando o comando IF é bastante comum em SQL. Principalmente em scripts que serão usados e reutilizados diversas vezes ao longo da vida de um banco de dados. Observe que no final da execução termos como resultado o que é visto em destaque na imagem. Ou seja, o nosso arquivo de banco de dados terá sido selecionado para receber novas instruções.
Veja que é tudo muito simples e bastante prático. Tudo que você precisa fazer é entender o que cada instrução ou comando faz. Não perca o seu tempo decorando comandos e mais comandos com as suas combinações. Entenda o que cada um faz e os use conforme a sua necessidade. Muito bem, deste momento em diante estamos no mesmo patamar que havia sido feito dentro do MetaEditor. Então o próximo comando a ser dado, tanto poderá ser usado no MetaEditor, quanto no WorkBench. E ele já é um comando um pouco mais complicado do que estes que vimos até o momento. Mas lembre-se de que conhecimento vai se acumulando e não ficando disperso.
Criando uma tabela
Este comando para se criar uma tabela e será um dos que você usará com alguma frequência. Ainda mais durante a fase de aprendizado. Ele tem como objetivo criar de fato uma tabela, que receberá depois os dados e isto por meio de outro comando. Porém, diferente dos comandos anteriores, a partir deste ponto, começamos a ter alguns percalços que podem ser confusos no começo. Mas nada de pânico, é tudo uma questão de costume e estudo, e você conseguirá entender como usar este comando.
Todo o problema aqui, se dá por um único motivo. A partir de agora, você terá que começar a pensar em como os dados que serão colocados na tabela serão modelados. Isto antes de criar a tabela. Esta parte é com toda a certeza, a parte que mais pega no começo do aprendizado em SQL. O motivo é justamente o fato de que você precisará ter uma noção do que será feito antes de fazer. Nada adianta você planejar mil coisas e não fizer um planejamento adequado do tipo de dado que será colocado na tabela. A ordem em que eles serão colocados pouco importa, mas a correta seleção do tipo, importa e muito. Já que se você escolher o tipo errado, acabará por criar uma tabela que depois se tornará inadequada para novos dados.
Mas se você tentar criar algo muito genérico, acabará por consumir muito mais recursos e espaço do que consumiria se fizesse a escolha correta do tipo. Por conta desta questão sugiro que você procure, o quanto antes estudar, primeiro os tipos de dados disponíveis para serem usado. Isto antes de realmente começar a tentar desenvolver bancos de dados para um propósito específico. No final deste artigo, deixarei algumas referências para que você possa saber por onde começar.
Comece por ali, apesar de elas serem apenas um ponta pé inicial. Você deverá procurar mais informações sobre este tema. Felizmente, existem muitas pessoas dispostas a explicar em detalhes cada um dos tipos. Então não fique esperando a solução.
Para simplificar, e apenas para demonstrar o comando. Vamos supor o seguinte cenário: Você deseja criar e manter um histórico de cotação de alguns ativos presentes na B3 (Bolsa do Brasil). Então a forma mais fácil de fazer isto é usando o que pode ser visto logo abaixo. Isto usando o WorkBench.
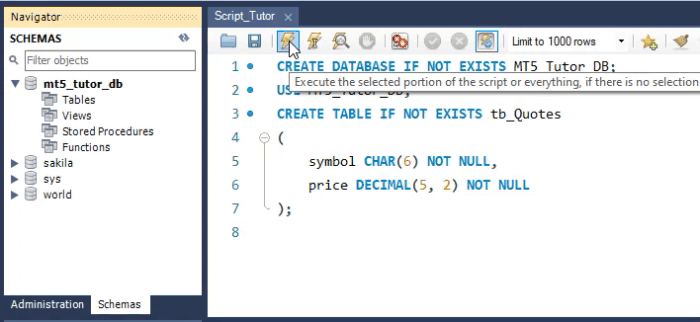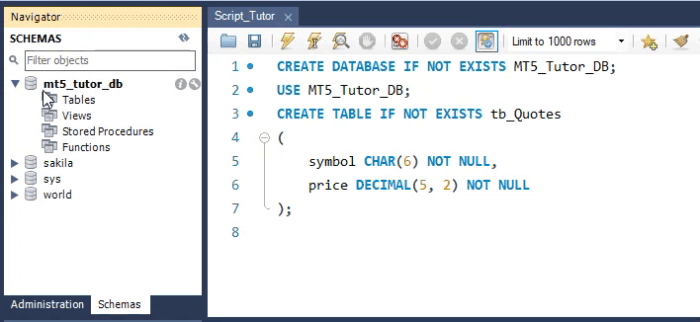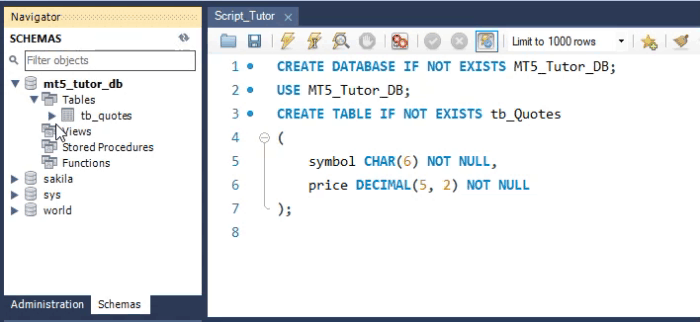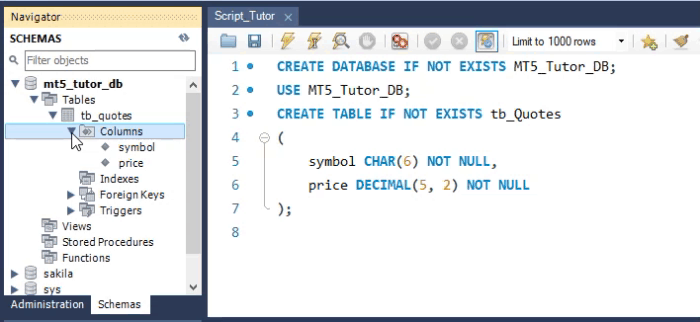
Veja que apesar do nosso código em SQL, estar usando muitas linhas para criar a tabela. Você deve entender que na verdade isto seria apenas uma única linha. E o resultado é o que você vê na área dos esquemas na WorkBench. Mas apesar desta tabela ter sido criada e poder receber valores, ela não é de fato adequada, em alguns casos. O motivo explicarei mais no final do artigo. Mas antes de saber o motivo, vamos ver como faríamos para criar a mesma tabela no MetaEditor. Isto pode ser visto na imagem abaixo.

Note que o comando é exatamente o mesmo, ou seja, o resultado também será. Praticamente todos os comandos que podemos dar no WorkBench, também podemos dar no MetaEditor. E eles funcionarão. Mas note que eu disse, praticamente todos os comandos, e não que todos os comandos serão executados. Existe um comando, que em breve falarei que pode ser executado no SQL, mas não pode ser executado via MetaEditor. Porém vamos com calma.
Primeiro vamos entender por que esta tabela que criamos não é assim tão adequada para determinados cenários. O primeiro motivo é a própria modelagem em si. Mas como assim? A ideia não seria ter o valor da cotação? Sim. Mas você talvez não tenha entendido uma coisa. Queremos o valor da cotação. Mas queremos manter um histórico desta cotação e esta modelagem não resolve o problema. Pois ela nos garante apenas a cotação em si. Mesmo que você tente criar um histórico, esta modelagem não será o suficiente.
Precisamos de mais coisas, uma destas coisas é a data ou horário, dependendo de cada caso específico. Mas vamos considerar que precisaremos apenas do preço de fechamento do dia. E todos os dias teremos uma nova entrada de dados na tabela. Assim este mesmo código visto acima terá que sofrer uma mudança na sua modelagem.
Talvez você esteja se perguntando: Mas por que você não fez isto logo de início? Por que fazer isto agora, depois que a tabela já foi criada? O motivo é que fiz isto de propósito justamente para mostrar como você faz para adicionar novas colunas na tabela. Como eu falei antes, não importa a ordem que você cria as coisas. O SQL fará com que elas fiquem de uma maneira adequada dentro do banco de dados. Mas voltando ao comando a ser dado é justamente o que é visto na animação abaixo.

Observe que este mesmo comando da linha oito for feito no MetaEditor, teremos o mesmo resultado que é visto na imagem. Ou seja, a criação de uma nova coluna que conterá dados a respeito da data em que a cotação foi obtida. Isto pode ser visto logo abaixo:
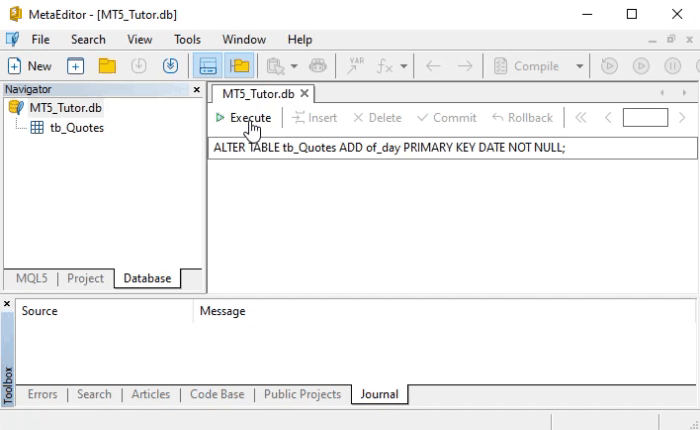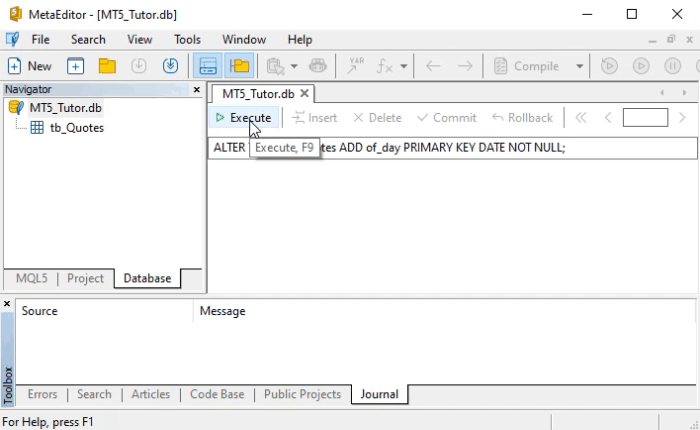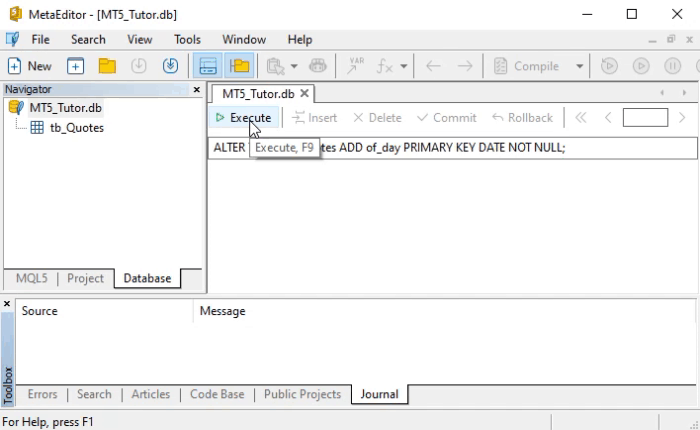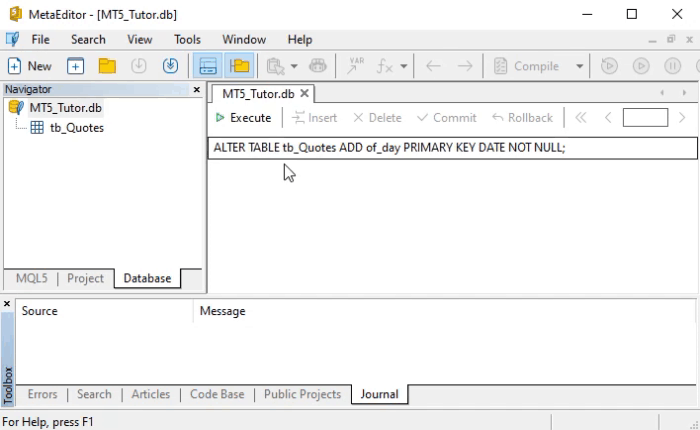
Depois de fazer o que é mostrado acima, execute o comando mostrado abaixo para obter o mesmo resultado visto lá no WorkBench.

Com relação aos valores a serem colocados nestes campos e a forma como você os deverá preparar será tema para um outro momento. Isto por que, o trabalho de lançar novos valores, ou mesmo remover valores de dentro de um banco de dados, é algo que deve ser feito com algum cuidado. Lembre-se: Você não quer ficar fazendo muitas mudanças no banco de dados no que rege, remover ou adicionar coisas. Isto por que, se você fizer as coisas de qualquer maneira, acabará por tornar o banco de dados algo insustentável a longo prazo. O ideal é colocar ou remover as coisas de uma maneira muito bem planejada e usar basicamente o banco de dados para pesquisa.
Pensando antes de agir
No decorrer deste artigo, menciono que apesar deste banco de dados, super simples funcionar, ele não é de fato ideal. Isto por que ele dependendo do que você realmente pretenda fazer dentro dele. O mesmo poderia ser melhor otimizado no que diz respeito ao uso do espaço. Mas você pode pensar neste momento o seguinte: Por que devo me preocupar com o espaço? Se começar a faltar espaço, adquiro uma nova unidade de disco. Bem, você pode até fazer isto, mas isto ainda assim, não resolveria o problema. Já que o problema é a forma como o banco está sendo usado, ou como ele foi dimensionado.
O que irei dizer aqui, é apenas uma pequena ideia do que realmente é o problema. Se você tiver mais experiência no uso de bancos de dados, saberá que a questão é bem mais profunda. Tanto que existem cursos, especialmente voltados para pessoas, que desejam e se tornam profissionais no que rege o assunto, banco de dados. Mas sem entrar em muitos detalhes, já que a coisa é muito mais ampla do que eu poderia dizer em um ou dois artigos.
Quero lhe mostrar, caro leitor, que não adianta você apenas estudar a programação SQL ou ver um ou outro tutorial sobre banco de dados. E sair por ai, dizendo que sabe trabalhar com banco de dados. Este tipo de coisa, realmente só poderá ser dita depois de muitos anos trabalhando na área. E mesmo assim, você dificilmente verá alguém realmente dizendo isto.
E o motivo é: Banco de dados é um nicho bastante amplo e com muitas coisas estudadas. E cada caso é um caso. Não existe de fato uma solução genérica.
Mas vamos entender um dos problemas neste singelo script de oito linhas. que criam um banco de dados. Cujo objetivo será comportar o histórico de cotações de ativos negociados na B3 ( Bolsa do Brasil ). Problema número um: Na área onde podemos colocar o preço, temos espaço para que coloquemos valores de $ 0,00 a $ 999,99. Ou seja, alguns ativos não poderão ser colocados dentro desta tabela. Isto por que o valor da cotação de tais ativos é diferente do esperado pela tabela. Você poderia resolver isto adicionando outra coluna para cobrir tais lacunas. Porém, isto faria com que uma das duas colunas. Esta que está no código ou a outra que seria criada, simplesmente ficar ocupando algum espaço desnecessário no banco de dados.
Problema número dois: O valor de registro que armazena a data da cotação faz uso do formato ISO 8601. E o que isto nos importa aqui no banco de dados? Bem, para responder esta pergunta, será preciso que você responda outra. De quando até quando adicionarei cotações na tabela? Dependendo da resposta desta pergunta, você poderia usar um formato diferente. Isto ocuparia menos espaço e consequentemente melhoria, o desempenho geral do banco de dados.
Para entender isto, pense no seguinte: Um ano contem 365 dias, porém nem todos os dias temos negociação na Bolsa de valores. Mas vamos considerar que tivéssemos negociação todos os dias. Assim se você fizesse uso de um valor, por exemplo SmallInt, que no caso é um valor com sinal. Você poderia contar de 0 a 32767. O que daria para que você conseguisse um total de pouco mais de 89 anos. Se você usa-se o mesmo tipo, só que sem sinal, ou seja, ele pode ir de 0 a 65535, você conseguiria um total de pouco mais de 179 anos. E no entanto, você estaria, de fato usando, apenas 2 bytes em vez de todos os bytes que o formato ISO 8601 utiliza. Pense só na quantidade de dados que daria de diferença em 179 anos de cotação diária.
Problema número três: Da mesma forma que o problema anterior. Este problema também envolve o custo de bytes. Só que desta vez o campo de registro é outro. No caso, é o nome do ativo. Este problema é ainda mais complicado do que o anterior. O motivo é que de tempos em tempos, alguns ativos mudam de nome. Mas se no seu entendimento, o fato de um ativo mudar de nome não faz com que a empresa que ele represente mude de comportamento. Então a mudança de nome de um ativo, não irá fazer com que seu histórico mude também.
Ok. Qualquer que seja o mercado, ele terá um número limitado de ativos sendo negociados. Entre estes ativos, apenas alguns poderão lhe chamar a atenção a fim de você quer um histórico de cotação. Por que então usar 6 bytes se podemos usar 1 byte para representar um ativo. Isto por que este 1 byte irá nos permitir um número de 255 ativos.
Agora voltemos ao problema anterior. Pense na quantidade de bytes que também serão economizados no logo prazo. Isto fora o fato, de que se o ativo mudar o seu nome, você precisará mexer em apenas um único registro no banco de dados. E não em todo o histórico de cotação a fim de colocar o novo nome.
Considerações finais
Neste artigo, tentei mostrar de forma que fosse a mais simples e palatável, como é feita a criação de um banco de dados simples e singelo. Mostrei que praticamente todas as instruções possíveis de serem usadas em uma WorkBench, também podem ser usadas no MetaEditor, a fim de se obter os mesmos resultados. No entanto, existe uma instrução que não é possível usar no MetaEditor. Esta não foi demonstrada neste artigo. Assim como a forma de inserir dados e fazer pesquisas no banco de dados.
Porém como este assunto é muito amplo, sugiro que você procure estudar o mesmo. Seja com pesquisas na Web, seja em um curso ou com aquisições de livros a respeito do mesmo. De qualquer forma, aqui ainda mostrarei alguns outros poucos comandos, para que possamos ter um material mínimo para usar o SQL no MQL5. Então no próximo artigo, veremos um pouco mais sobre SQL.
Referências:
| Arquivo | Descrição |
|---|---|
| Experts\Expert Advisor.mq5 | Demonstra a interação entre o Chart Trade e o Expert Advisor (É necessário o Mouse Study para interação) |
| Indicators\Chart Trade.mq5 | Cria a janela para configuração da ordem a ser enviada (É necessário o Mouse Study para interação) |
| Indicators\Market Replay.mq5 | Cria os controles para interação com o serviço de replay/simulador (É necessário o Mouse Study para interação) |
| Indicators\Mouse Study.mq5 | Permite interação entre os controles gráficos e o usuário (Necessário tanto para operar o replay simulador, quanto no mercado real) |
| Services\Market Replay.mq5 | Cria e mantém o serviço de replay e simulação de mercado (Arquivo principal de todo o sistema) |
| Code VS C++\Servidor.cpp | Cria e mantém um soquete servidor criado em C++ (Versão Mini Chat) |
| Code in Python\Server.py | Cria e mantém um soquete em python para comunicação entre o MetaTrader 5 e o Excel |
| Indicators\Mini Chat.mq5 | Permite implementar um mini chat via indicador (Necessário uso de um servidor para funcionar) |
| Experts\Mini Chat.mq5 | Permite implementar um mini chat via Expert Advisor (Necessário uso de um servidor para funcionar) |
| Scripts\SQLite.mq5 | Demonstra uso de script SQL por meio do MQL5 |
| Files\Script 01.sql | Demonstra a criação de uma tabela simples, com chave estrangeira |
| Files\Script 02.sql | Demonstra a adição de valores em uma tabela |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso