
Aplicação de regras associativas para análise de dados no Forex

Introdução ao conceito de regras associativas
O trading algorítmico moderno exige novas abordagens para análise. O mercado está em constante mudança, e os métodos clássicos de análise técnica já não conseguem identificar as complexas inter-relações do mercado.
Trabalho com dados há muito tempo e percebi que muitas ideias bem-sucedidas vêm de áreas correlatas. Hoje, quero compartilhar a experiência de aplicar regras associativas no trading. Este método tem se mostrado altamente eficaz na análise de dados do varejo, ajudando a identificar conexões entre compras, transações, movimentos de preços e a demanda e oferta futuras. E se aplicássemos isso ao mercado de câmbio?
A ideia principal é simples, isto é, procuramos padrões consistentes de comportamento de preços, indicadores e suas combinações. Por exemplo, com que frequência um aumento no EURUSD é seguido por uma queda no USDJPY? Ou que condições geralmente precedem grandes movimentos?
Neste artigo, mostrarei o processo completo de criação de um sistema de trading com base nessa ideia. Nós:
- Coletaremos dados históricos usando MQL5.
- Faremos a análise desses dados com Python.
- Encontraremos padrões significativos.
- Transformaremos esses padrões em sinais de trading.
Por que essa pilha de tecnologias? MQL5 é excelente para trabalhar com dados de mercado e automatizar o trading. Python oferece ferramentas poderosas para análise. Pela minha experiência, essa combinação é muito eficaz para o desenvolvimento de sistemas de trading.
O código terá muitos pontos interessantes na aplicação de regras associativas ao Forex. Vamos começar?
Coleta e preparação de dados históricos do Forex
É crucial coletarmos e prepararmos todos os dados necessários. Usaremos como base os dados horários dos principais pares de moedas dos últimos dois anos (desde 2022).
Agora, vamos criar um script em MQL5 que coletará e exportará os dados necessários para o formato CSV:
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Set headers FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
Processamento de dados em Python
Após formar o dataset, é importante processar os dados corretamente.
Para isso, criei uma classe chamada ForexDataProcessor, que cuida de todo o trabalho de preparação. Vamos examinar seus componentes principais.
Começaremos com o carregamento dos dados. Nossa função trabalha com dados horários dos principais pares de moedas: EURUSD, GBPUSD, USDJPY e USDCHF. Os dados devem estar em formato CSV com as principais características de preços.
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Remove lines with duplicate headers
df = df[df['DateTime'] != 'DateTime']
# Convert data types
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Remove NaN strings
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Safe quantization with error handling"""
try:
if series.nunique() <= q:
# If there are fewer unique values than quantiles, use regular categorization
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Manual categorization as a backup option
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Basic calculations
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA calculations
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA calculations
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Volatility
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Discretization for association rules
# SMA-based trend
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI zones
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Secure quantization for other parameters
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Candle patterns
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Handling each pair
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Add a pair prefix to the column names
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Find the common time range for non-empty data
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Align all pairs by common dates
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Combine all pairs
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Handling all pairs
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Save the combined dataset
processor.save_data(combined_data)
# Display dataset info
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Save individual pairs
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
Após o carregamento bem-sucedido, a parte mais interessante começa, que é o cálculo dos indicadores técnicos. Aqui, confio em um verdadeiro arsenal de ferramentas testadas ao longo do tempo. Médias móveis ajudam a determinar tendências de diferentes durações. SMA(50) frequentemente atua como suporte ou resistência dinâmica. O oscilador RSI com o período clássico de 14 é excelente para identificar as zonas de sobrecompra e sobrevenda do mercado. MACD é indispensável para determinar o momento e os pontos de reversão. Já as Bandas de Bollinger oferecem uma visão clara da volatilidade atual do mercado.
# Volatility and RSI calculation example result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
Um aspecto que merece atenção especial é o processo de discretização dos dados. Precisamos dividir todos os valores contínuos em categorias claras. Nesse caso, é importante encontrar o equilíbrio, porque uma divisão muito rígida dificultará a identificação de padrões, enquanto uma divisão excessivamente detalhada levará à perda de nuances importantes do mercado. Por exemplo, para a determinação de tendência, uma divisão mais simples funciona melhor, com base na posição do preço em relação à média.
# Defining a trend result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
Padrões de velas também exigem uma abordagem específica. Com base na análise estatística, destaco o Doji, quando o tamanho do corpo da vela é mínimo, e o Long_Bullish e Long_Bearish, em movimentos extremos de preços. Essa classificação permite identificar com clareza os momentos de indecisão do mercado e os movimentos impulsivos fortes.
Ao finalizar o processamento, todos os pares de moedas são reunidos em um único conjunto de dados com uma escala de tempo comum. Essa etapa é fundamental: já que ela abre a possibilidade de buscar inter-relações complexas entre diferentes instrumentos. Agora, seremos capazes de ver como a tendência de um par de moedas afeta a volatilidade de outro, ou como os padrões de velas se correlacionam com os volumes de negociação em todo o mercado.
Implementação do algoritmo Apriori em Python
Após a preparação dos dados, passamos para a etapa crítica, que é a da implementação do algoritmo Apriori para buscar regras associativas em nossos dados financeiros. O algoritmo Apriori, originalmente desenvolvido para a análise de cestas de mercado, será adaptado para trabalhar com séries temporais de pares de moedas.
No contexto do mercado de câmbio, uma "transação" é um conjunto de estados de diferentes indicadores e pares de moedas em um determinado momento. Por exemplo:- EURUSD_Trend = Uptrend
- GBPUSD_RSI_Zone = Overbought
- USDJPY_Volatility_Zone = High
O algoritmo busca combinações frequentes desses estados, com base nas quais são então formadas as regras de trading.
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Setting up logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Group columns by type for more meaningful analysis column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Create a list of all columns for analysis pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Prepare data pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Find single patterns logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Find pair and triple patterns logging.info("Finding complex patterns...") complex_rules = [] # Generate column combinations for analysis column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Create a cross-table for the selected columns grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Sort by minimum support grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Form all possible combinations of antecedents and consequents items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Calculate the support of the antecedent ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Avoid division by zero confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Count the lift cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Adding additional metrics to evaluate rules leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Sort the rules by additional criteria if self._is_meaningful_rule(rule): complex_rules.append(rule) # Sort the rules by complex metric complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Calculate support for a set of elements""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Check the rule for its relevance to trading""" # The rule should have the high lift and 'leverage' if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # At least one element should be related to a trend or RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Calculate the rule complex evaluation""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Load data logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Apply the algorithm apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Display results logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Save results results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
Adaptação de regras associativas para análise de pares de moedas
Durante o meu trabalho de adaptação do algoritmo Apriori para o mercado de câmbio, encontrei desafios interessantes. Embora esse método tenha sido inicialmente criado para a análise de compras em lojas, seu potencial para o Forex me pareceu promissor.
A principal dificuldade estava no fato de que o mercado Forex é radicalmente diferente das compras comuns em um supermercado. Ao longo dos anos trabalhando nos mercados financeiros, me acostumei a lidar com preços e indicadores que estão em constante mudança. Mas como aplicar a esse cenário um algoritmo que geralmente busca apenas conexões entre bananas e leite nas compras de supermercado?
Após meus experimentos, surgiu um sistema de cinco métricas. Cada uma delas foi cuidadosamente testada.
O Support acabou sendo uma métrica traiçoeira. Uma vez quase incluí um conjunto de regras com indicadores excelentes, mas o support era apenas 0,02. Ainda bem que percebi a tempo, pois tal regra na prática funcionaria uma vez a cada cem anos!
Com o Confidence, foi mais simples. Trabalhando no mercado, aprende-se rapidamente que até 70% de probabilidade é um ótimo indicador. O mais importante é gerenciar bem os riscos nos 30% restantes. Bem, o gerenciamento de riscos ainda não foi descartado, porque não importa se você tem o Graal nas mãos, sem uma boa gestão de riscos, você certamente enfrentará uma retração ou até mesmo uma perda total.
O Lift se tornou meu indicador favorito. Após centenas de horas de testes, percebi uma regularidade, isto é, regras com lift acima de 1,5 realmente funcionam no mercado real. Essa descoberta teve um grande impacto na minha abordagem de filtragem de sinais.
A história com o Leverage foi engraçada. No início, eu queria até excluí-lo do sistema, achando-o inútil. Mas, durante um período especialmente volátil no mercado, foi exatamente o Leverage que ajudou a filtrar a maioria dos sinais falsos.
O Conviction foi adicionado por último, após uma análise de fóruns. Ele me ajudou a entender o quanto esse indicador é importante para avaliar a real significância dos padrões encontrados.
O mais surpreendente para mim foi como o algoritmo encontra conexões inesperadas entre diferentes pares de moedas. Por exemplo, quem diria que certos padrões no EURUSD poderiam prever os movimentos do USDJPY com tanta precisão? Após 9 anos no mercado, não percebi muitas das inter-relações que o algoritmo descobriu. Embora o pair trading, o basket trading e o arbitrage tenham sido minha especialidade no passado, ainda me lembro dos tempos em que a cmillion estava começando a desenvolver seus robôs voltados para os movimentos mútuos dos pares.
Atualmente, continuo as pesquisas, testando novas combinações de indicadores e períodos temporais. O mercado está sempre mudando, e cada dia traz novas descobertas. Na próxima semana, planejo publicar os resultados dos testes do sistema com dados anuais, além dos primeiros resultados ao vivo do algoritmo em uma conta de demonstração. Há algumas descobertas muito interessantes nesse conjunto de dados.
Honestamente, eu nem esperava que esse projeto chegasse tão longe. Começou como um simples experimento de data mining e tentativas de classificar rigidamente todos os movimentos do mercado para os algoritmos de classificação, e acabou se transformando em um sistema de trading completo. E sabe o que mais? Parece que estou apenas começando a entender o verdadeiro potencial dessa abordagem.
Características da implementação para o Forex
Vamos voltar um pouco ao código. No nosso código, há várias adaptações importantes do algoritmo para trabalhar com dados financeiros:
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
}
Essa agrupação ajuda a encontrar combinações mais significativas de indicadores e reduz a complexidade computacional.
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
Selecionamos apenas as regras com forte significância estatística (lift > 1,5) e com a obrigatória inclusão de indicadores de tendência ou do RSI.
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
A avaliação ponderada ajuda a classificar as regras de acordo com sua utilidade potencial para o trading.
Visualização das associações encontradas
Após encontrar as regras associativas, é importante visualizá-las e analisá-las corretamente. Para isso, desenvolvi uma classe chamada ForexRulesVisualizer, que oferece várias maneiras de análise visual das regularidades encontradas.
Distribuição das métricas das regras
O primeiro passo na análise é entender a distribuição das principais métricas das regras encontradas. O gráfico de distribuição do support, confidence, lift e leverage ajuda a avaliar a qualidade das regras encontradas e, se necessário, ajustar os parâmetros do algoritmo.
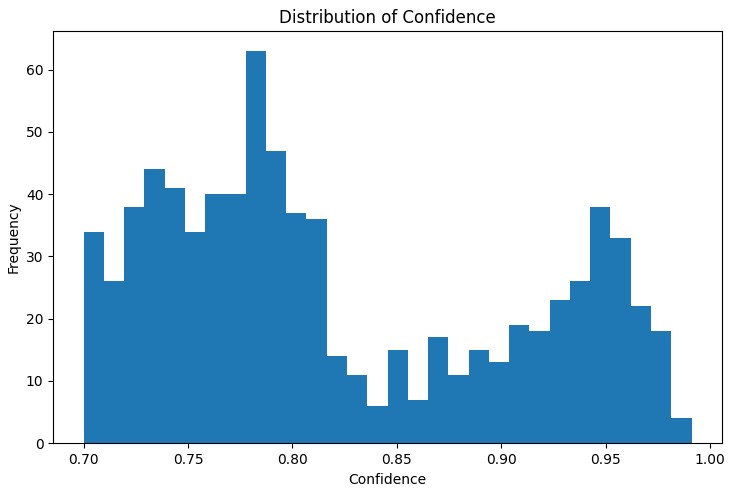
Uma ferramenta particularmente útil foi o gráfico de rede interativo, que mostra de forma clara as conexões entre os diferentes estados do mercado. Nesse gráfico, os nós representam os estados dos indicadores (por exemplo, "EURUSD_Trend=Uptrend" ou "USDJPY_RSI_Zone=Overbought"), e as arestas representam as regras encontradas, onde a espessura da aresta é proporcional ao valor do lift.
Mapa de calor das interações entre pares de moedas 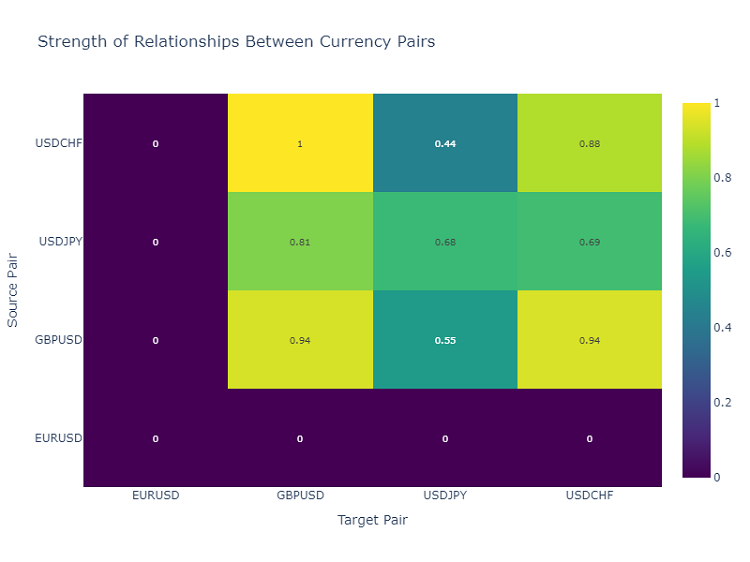
Para analisar as inter-relações entre os pares de moedas, utilizo um mapa de calor que mostra a força das conexões entre os diferentes instrumentos. Isso ajuda a identificar os pares que mais influenciam uns aos outros, o que é crucial para construir um portfólio de trading diversificado.
Criação de sinais de trading
Após encontrar e visualizar as regras associativas, o próximo passo importante é transformá-las em sinais de trading. Para isso, desenvolvi a classe ForexSignalGenerator, que analisa o estado atual do mercado e gera sinais de trading com base nas regras encontradas.
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Signal generator initialization Parameters: rules_df: DataFrame with association rules min_rule_strength: minimum rule strength to generate a signal """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Comprehensive assessment of the rule strength Takes into account all metrics with different weights """ strength = ( rule['lift'] * 0.4 + # Main weight on 'lift' rule['confidence'] * 0.3 + # Rule confidence rule['support'] * 0.2 + # Occurrence frequency rule['leverage'] * 0.1 # Improvement over randomness ) # Additional bonus for having trend indicators if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Current market state analysis Parameters: current_data: DataFrame with current indicator values """ signals = [] state = self._create_market_state(current_data) # Find all the matching rules matching_rules = self._find_matching_rules(state) # Grouping rules by currency pairs for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Forming the current market state""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Searching for rules that match the current state""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Check if all the rule conditions are met if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Generating a signal for a specific currency pair""" # Divide the rules by signal type trend_signals = defaultdict(float) for rule in rules: # Looking for trend-related consequents trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Determine the final signal if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Usage example def run_trading_system(data, rules_df): """ Trading system launch Parameters: data: DataFrame with historical data rules_df: DataFrame with association rules """ signal_generator = ForexSignalGenerator(rules_df) # Simulate a pass along historical data signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Loading historical data and rules data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Launch the test signals_df = run_trading_system(data, rules_df) # Analyze the results print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
Avaliação da força das regras
Após longos experimentos com a visualização das regras, chegou o momento mais difícil, que é a criação dos sinais de trading reais. Confesso que essa tarefa me fez suar bastante. Encontrar padrões interessantes nos gráficos é uma coisa, mas transformá-los em um sistema de trading funcional é outra totalmente diferente.
Decidi criar um módulo separado, o ForexSignalGenerator. Inicialmente, eu queria apenas gerar sinais com as regras mais fortes, mas logo percebi que era muito mais complexo do que isso. O mercado está em constante mudança, e uma regra que funcionou perfeitamente ontem pode falhar hoje.
Foi necessário abordar seriamente a avaliação da força das regras. Após várias tentativas frustradas, desenvolvi um sistema de pesos. O maior desafio foi escolher os coeficientes, por isso experimentei provavelmente dezenas de combinações. No final, optei por atribuir 40% de peso ao lift (que é realmente o indicador chave), 30% ao confidence, 20% ao support e 10% ao leverage.
Curiosamente, os sinais mais fortes frequentemente surgiam quando a regra incluía um componente de tendência. Até adicionei um bônus de 20% à força dessas regras, e a prática mostrou que isso se justificava.
Com o análise do estado atual do mercado, também foi necessário um certo trabalho. No começo, eu apenas comparava os valores atuais dos indicadores com as condições das regras. Mas depois percebi que era preciso considerar um contexto mais amplo. Por exemplo, adicionei a verificação da tendência geral nos últimos períodos, o estado da volatilidade, até mesmo a hora do dia passou a ser relevante.
Agora, o sistema analisa cerca de 20 parâmetros diferentes para cada par de moedas. Algumas das regularidades encontradas realmente me surpreenderam.
Claro, o sistema ainda está longe da perfeição. Às vezes, me pego pensando que deveria incluir fatores fundamentais. Mas isso já é para a próxima etapa, por enquanto, quero aperfeiçoar a versão atual.
Filtragem e agregação de sinais
Durante o desenvolvimento do sistema, percebi rapidamente que apenas encontrar as regras não era suficiente e era necessário um controle rigoroso da qualidade dos sinais. Após algumas transações mal-sucedidas, ficou claro que a filtragem era talvez até mais importante do que a própria busca por padrões.
Comecei com um simples limite de força mínima da regra. Inicialmente, defini esse limite em 0,5, mas estava constantemente pegando falsos sinais. Após duas semanas de testes, aumentei para 0,7, e a situação melhorou consideravelmente. No entanto, o número de sinais diminuiu cerca de um terço, mas a qualidade aumentou significativamente.
O segundo nível de filtragem surgiu após um caso especialmente frustrante. Havia uma regra com ótimos indicadores, abri uma posição com ela, e o mercado foi diretamente na direção oposta. Quando fui analisar, percebi que outras regras naquele momento estavam dando sinais opostos. Desde então, comecei a verificar a consistência, isto é, abro uma posição somente se várias regras apontarem na mesma direção.
Com a volatilidade, surgiu uma história interessante. Percebi que, em períodos tranquilos, o sistema funcionava como um relógio, mas quando o mercado começava a se agitar, os problemas surgiam. Foi necessário adicionar um filtro dinâmico com base no ATR. Se a volatilidade estiver acima do 75º percentil nos últimos 20 dias, aumentamos os requisitos de força das regras em 20%.
A parte mais difícil foi verificar sinais contraditórios. Às vezes, algumas regras indicam compra, enquanto outras indicam venda, todas com bons indicadores. Testei várias abordagens, mas no final optei por uma solução simples: se houver contradições significativas nos sinais, ignoramos essa situação. Sim, perdemos algumas oportunidades, mas reduzimos bastante os riscos.
No próximo mês, planejo adicionar mais um nível de filtragem - por tempo. Percebi que, em determinados horários, as regras funcionam muito pior. Isso é especialmente verdade durante períodos de baixa liquidez e na saída de notícias importantes. Acredito que isso deve aumentar ainda mais a porcentagem de operações bem-sucedidas.
Resultados dos testes
Após alguns meses de desenvolvimento do sistema, me deparei com uma questão essencial: como avaliar corretamente a força de cada regra encontrada. A princípio, tudo parecia simples, mas o mercado real rapidamente revelou todas as falhas da abordagem inicial.
Após longos experimentos, cheguei a um sistema de pesos para diferentes fatores. O Lift se tornou o componente principal (40% de influência), porque a prática mostrou que esse é realmente o indicador mais crítico. O Confidence ficou com 30%, afinal, a confiança nas regras também é importante. O Support e o Leverage receberam pesos menores, pois eles funcionam mais como filtros.
A filtragem de sinais foi um caso à parte. No começo, tentei operar com todas as regras ao mesmo tempo, mas logo percebi meu erro. Foi necessário implementar um sistema de filtragem em múltiplos níveis. Primeiro, descartamos as regras fracas com o limite mínimo de força. Depois, verificamos se o sinal é confirmado por várias regras, porque sinais isolados geralmente são menos confiáveis.
O controle da volatilidade se mostrou especialmente importante. Em períodos tranquilos, o sistema funcionava bem, mas quando a volatilidade aumentava, a quantidade de sinais falsos disparava. Foi necessário adicionar filtros dinâmicos que se tornam mais rigorosos à medida que a volatilidade sobe.
O teste do sistema levou quase três meses. Eu o executei com dados históricos de dois anos para os quatro principais pares. Os resultados foram bastante inesperados. Por exemplo, o USDJPY apresentou a melhor performance, com 65% de negociações lucrativas com RR de 1,6. Já o GBPUSD foi decepcionante, com apenas 58% com RR de 1,4.
Curiosamente, as regras com lift acima de 2,0 e confidence acima de 0,8 consistentemente apresentaram os melhores resultados para todos os pares. Parece que esses níveis realmente representam algum tipo de limiar natural de significância no mercado Forex.
Melhorias futuras
Atualmente, vejo várias direções para melhorar o sistema. Primeiro, precisamos tornar os parâmetros das regras mais dinâmicos, porque o mercado muda, e o sistema precisa se adaptar. Segundo, claramente falta uma consideração mais profunda da macroeconomia e do contexto das notícias. Sim, isso vai tornar o sistema mais complexo, mas o potencial de ganho justifica o esforço.
O direcionamento que mais me interessa é o de filtros adaptativos. Em diferentes fases do mercado, claramente são necessárias configurações diferentes do sistema. Por enquanto, isso está implementado de forma bastante simples, mas já vejo várias maneiras de aprimorar essa parte.
Na próxima semana, planejo começar os testes de uma nova versão com otimização dinâmica do tamanho das posições. Os resultados preliminares com dados históricos parecem promissores, mas, como sempre, o mercado real trará suas próprias surpresas.
Considerações finais
A aplicação de regras associativas no trading algorítmico abre possibilidades interessantes para encontrar padrões de mercado não óbvios. O segredo do sucesso aqui é a preparação adequada dos dados, a seleção cuidadosa das regras e uma estratégia bem estruturada para a geração de sinais.
É importante lembrar que qualquer sistema de trading exige monitoramento contínuo e adaptação às mudanças nas condições do mercado. As regras associativas são uma ferramenta poderosa de análise, mas devem ser usadas em conjunto com outros métodos de análise técnica e fundamental.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16061
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Aparentemente, presume-se que o leitor já deve ter algum conhecimento desse método, e se não tiver?
Não entendo as métricas mencionadas, em particular:
O Lift se tornou meu indicador favorito. Após centenas de horas de testes, notei um padrão: regras com lift acima de 1,5 realmente funcionam no mercado real. Essa descoberta influenciou seriamente minha abordagem à filtragem de sinais.
Se entendi o método corretamente, os sinais correlacionados são procurados em segmentos quânticos. Mas eu não entendia a próxima etapa. Qual é o alvo? Presumo que as regras resultantes sejam verificadas em relação ao alvo e avaliadas em relação às métricas.
Se for esse o caso, isso reflete meu método, e é interessante avaliar o desempenho e a eficiência.