
Desenvolvendo um EA multimoeda (Parte 20): Organizando o pipeline de etapas de otimização automática de projetos (I)
Introdução
Lembramos que, no contexto deste ciclo de artigos, estamos tentando criar um sistema de otimização automática que permita, sem a participação humana, encontrar boas combinações de parâmetros de uma única estratégia de trading, que depois serão combinadas em um EA (Expert Advisor) final. A tarefa está descrita em detalhes na parte 9 e na parte 11. O processo de busca será gerido por um EA otimizador, e todos os dados que precisarem ser salvos durante sua execução serão registrados na base de dados principal.
Na base de dados, temos tabelas para armazenar informações sobre várias classes de objetos. Alguns possuem um campo de status, que pode assumir valores de um conjunto fixo ("Na fila", "Em execução", "Concluído"), mas nem todas as classes utilizam esse campo. Mais especificamente, ele é utilizado apenas para as tarefas de otimização (task). Nosso EA otimizador busca na tabela de tarefas (tasks) aquelas com o status "Na fila", para selecionar a próxima tarefa a ser executada. Após a conclusão de cada tarefa, seu status na base de dados é alterado para "Concluída".
Vamos tentar implementar a atualização automática dos status não apenas para as tarefas, mas também para todas as outras classes de objetos (trabalhos, etapas, projetos) e organizar a execução automática de todas as etapas necessárias até que o EA final seja obtido, podendo operar de forma independente, sem conexão com a base de dados.
Planejando o caminho
Primeiramente, vamos revisar cuidadosamente todas as classes de objetos na base de dados que possuem um status e formularemos regras claras para a alteração do status. Se conseguirmos definir essas regras, poderemos implementá-las por meio de chamadas adicionais de SQL, seja a partir do EA otimizador, seja dos EAs (Expert Advisors) das etapas. Ou, talvez, consigamos implementá-las como gatilhos na base de dados, que serão acionados quando determinados eventos de alteração de dados ocorrerem.
Em seguida, precisamos definir a forma de determinar a ordem de execução das tarefas. Até agora, essa questão não foi muito relevante, pois, durante o desenvolvimento, treinamos a cada vez com uma nova base de dados, adicionando etapas do projeto, trabalhos e tarefas exatamente na ordem em que deveriam ser executados. No entanto, ao passarmos a armazenar na base de dados informações sobre vários projetos ou até mesmo adicionar automaticamente novos projetos, não será mais possível confiar nesse método de definição da ordem das tarefas. Por isso, vamos dedicar um tempo a esse ponto.
Para testar o funcionamento de todo o pipeline, no qual todas as tarefas do projeto de otimização automática serão executadas uma a uma, ainda precisamos automatizar algumas ações. Até agora, realizávamos essas ações manualmente. Por exemplo, após a conclusão da segunda etapa da otimização, temos a possibilidade de selecionar os melhores grupos para uso no EA final. Esta operação foi realizada ao iniciar o EA da terceira etapa manualmente, ou seja, fora do pipeline de otimização automática. Para definir os parâmetros de execução deste EA, também selecionávamos manualmente os identificadores das execuções da segunda etapa com os melhores resultados, utilizando uma interface externa ao MQL5 para acessar a base de dados. Vamos tentar automatizar isso também.
Assim, após as modificações, esperamos finalmente ter um pipeline totalmente pronto para a execução das etapas de otimização automática e a obtenção do EA final. Durante o processo, também consideraremos outras questões relacionadas à melhoria da organização do trabalho. Por exemplo, parece que os EAs da segunda e de etapas posteriores serão os mesmos para diferentes estratégias de trading. Vamos verificar se é realmente o caso. Também vamos analisar o que será mais conveniente — criar projetos menores ou, em projetos maiores, adicionar mais etapas ou trabalhos.
Regras de alteração de status
Vamos começar formulando as regras para a alteração dos status. Lembramos que, em nossa base de dados, estão armazenadas informações sobre os seguintes objetos, que possuem um campo de status (status):
- Projeto. Agrupa uma ou mais etapas, armazenado na tabela projects;
- Etapa. Agrupa um ou mais trabalhos, armazenado na tabela stages;
- Trabalho. Agrupa uma ou mais tarefas, armazenado na tabela jobs;
- Tarefa. Normalmente, agrupa várias execuções do testador, armazenado na tabela tasks.
Os possíveis valores de status são os mesmos para cada um desses quatro tipos de objetos e podem ser um dos seguintes:
- Queued. O objeto foi colocado na fila para processamento;
- Process. O objeto está sendo processado;
- Done. O processamento deste objeto foi concluído ou não começou.
Vamos descrever as regras de alteração de status dos objetos na base de dados, de acordo com o ciclo normal do pipeline de otimização automática do projeto. O ciclo começa quando o projeto é colocado na fila para otimização, ou seja, quando seu status é alterado para Queued.
Quando o status do projeto muda para Queued:
- definimos o status de todas as etapas deste projeto como Queued.
Quando o status de uma etapa muda para Queued:
- definimos o status de todos os trabalhos desta etapa como Queued.
Quando o status de um trabalho muda para Queued:
- definimos o status de todas as tarefas desse trabalho como Queued.
Quando o status de uma tarefa muda para Queued:
- limpamos a data de início e de término.
Dessa forma, a mudança do status do projeto para Queued resultará em uma atualização em cascata dos status de todas as etapas, trabalhos e tarefas desse projeto para Queued. Todos esses objetos permanecerão nesse status até que o EA Optimization.ex5 seja iniciado.
Após o início, deve ser encontrada pelo menos uma tarefa com status Queued. O critério de ordenação, caso haja várias tarefas, será discutido mais tarde. Para essa tarefa, o status é alterado para Process. Isso gera as seguintes ações:
Quando o status de uma tarefa muda para Process:
- definimos a data de início como o horário atual;
- removemos todas as execuções anteriores realizadas no contexto dessa tarefa;
- definimos o status do trabalho relacionado a essa tarefa como Process.
Quando o status de um trabalho muda para Process:
- definimos o status da etapa relacionada a esse trabalho como Process.
Quando o status de uma etapa muda para Process:
- definimos o status do projeto relacionado a essa etapa como Process.
Após isso, as tarefas dos trabalhos das etapas do projeto serão executadas sequencialmente. Mudanças subsequentes nos status podem ocorrer apenas após a conclusão da tarefa atual. Nesse momento, o status da tarefa muda para Done e isso pode resultar na atualização em cascata desse status também para os objetos superiores.
Quando o status de uma tarefa muda para Process:
- definimos a data de término como o horário atual;
- obtemos a lista de todas as tarefas que fazem parte do trabalho em que essa tarefa está inserida e que estão no status Queued. Se não houver nenhuma, definimos o status do trabalho relacionado a essa tarefa como Done.
Quando o status de um trabalho muda para Done:
- obtemos a lista de todos os trabalhos que fazem parte da etapa em que esse trabalho está inserido e que estão no status Queued. Se não houver nenhum, definimos o status da etapa relacionada a esse trabalho como Done.
Quando o status de uma etapa muda para Done:
- obtemos a lista de todas as etapas que fazem parte do projeto em que essa etapa está inserida e que estão no status Queued. Se não houver nenhuma, definimos o status do projeto relacionado a essa etapa como Done.
Dessa forma, quando a última tarefa do último trabalho da última etapa for concluída, o próprio projeto será marcado como concluído.
Agora que todas as regras foram formuladas, podemos passar para a criação dos gatilhos na base de dados que implementarão essas ações.
Criação dos gatilhos
Vamos começar do começo — com o gatilho para a mudança de status do projeto para Queued. Aqui está uma das formas possíveis de implementá-lo:
CREATE TRIGGER upd_project_status_queued AFTER UPDATE OF status ON projects WHEN NEW.status = 'Queued' BEGIN UPDATE stages SET status = 'Queued' WHERE id_project = NEW.id_project; END;
Após a execução desse gatilho, os status das etapas desse projeto também serão alterados para Queued. Com isso, devemos acionar os gatilhos correspondentes para as etapas, trabalhos e tarefas:
CREATE TRIGGER upd_stage_status_queued
AFTER UPDATE
ON stages
WHEN NEW.status = 'Queued' AND
OLD.status <> NEW.status
BEGIN
UPDATE jobs
SET status = 'Queued'
WHERE id_stage = NEW.id_stage;
END;
CREATE TRIGGER upd_job_status_queued
AFTER UPDATE OF status
ON jobs
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET status = 'Queued'
WHERE id_job = NEW.id_job;
END;
CREATE TRIGGER upd_task_status_queued
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET start_date = NULL,
finish_date = NULL
WHERE id_task = NEW.id_task;
END;
O início de uma tarefa será processado pelo seguinte gatilho, que definirá a data de início da tarefa, limpará os dados das execuções anteriores dessa tarefa e atualizará o status do trabalho para Process:
CREATE TRIGGER upd_task_status_process
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Process'
BEGIN
UPDATE tasks
SET start_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
DELETE FROM passes
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = 'Process'
WHERE id_job = NEW.id_job;
END;
Em seguida, os status da etapa e do projeto, nos quais essa tarefa está inserida, serão atualizados em cascata para Process:
CREATE TRIGGER upd_job_status_process AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Process' BEGIN UPDATE stages SET status = 'Process' WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_process AFTER UPDATE OF status ON stages WHEN NEW.status = 'Process' BEGIN UPDATE projects SET status = 'Process' WHERE id_project = NEW.id_project; END;
No gatilho que é acionado quando o status de uma tarefa é atualizado para Done, ou seja, quando a tarefa é concluída, vamos atualizar a data de término da tarefa e, então, dependendo de haver ou não outras tarefas na fila para execução no trabalho da tarefa atual, o status do trabalho será atualizado para Process ou Done:
CREATE TRIGGER upd_task_status_done
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Done'
BEGIN
UPDATE tasks
SET finish_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = (
SELECT CASE WHEN (
SELECT COUNT( * )
FROM tasks t
WHERE t.status = 'Queued' AND
t.id_job = NEW.id_job
)
= 0 THEN 'Done' ELSE 'Process' END
)
WHERE id_job = NEW.id_job;
END;
Da mesma forma, faremos com os status das etapas e dos projetos:
CREATE TRIGGER upd_job_status_done AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Done' BEGIN UPDATE stages SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM jobs j WHERE j.status = 'Queued' AND j.id_stage = NEW.id_stage ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_done AFTER UPDATE OF status ON stages WHEN NEW.status = 'Done' BEGIN UPDATE projects SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM stages s WHERE s.status = 'Queued' AND s.name <> 'Single tester pass' AND s.id_project = NEW.id_project ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_project = NEW.id_project; END;
Também vamos prever a possibilidade de alterar todos os objetos do projeto para o status Done quando o status do próprio projeto for alterado para Done. Esse cenário não foi incluído na lista de regras acima, pois não é uma ação obrigatória durante o curso normal da otimização automática. No gatilho correspondente, vamos definir o status de todas as tarefas não executadas ou em execução como Done, o que resultará na alteração do status para Done de todos os trabalhos e etapas do projeto:
CREATE TRIGGER upd_project_status_done AFTER UPDATE OF status ON projects WHEN NEW.status = 'Done' BEGIN UPDATE tasks SET status = 'Done' WHERE id_task IN ( SELECT t.id_task FROM tasks t JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage JOIN projects p ON p.id_project = s.id_project WHERE p.id_project = NEW.id_project AND t.status <> 'Done' ); END;
Após a criação de todos esses gatilhos, vamos analisar como determinar a ordem de execução das tarefas.
Pipeline
Enquanto estávamos trabalhando com um único projeto na base de dados, vamos começar analisando as regras para determinar a ordem de execução das tarefas nesse caso. Quando tivermos uma compreensão de como definir a ordem de execução das tarefas para um único projeto, podemos então pensar sobre a ordem de execução das tarefas para vários projetos sendo executados simultaneamente.
É óbvio que as tarefas de otimização que pertencem a um mesmo trabalho e diferem apenas pelo critério de otimização podem ser executadas em qualquer ordem: iniciar a otimização genética com critérios diferentes não utiliza informações de otimizações anteriores. O uso de diferentes critérios de otimização é empregado para aumentar a diversidade das boas combinações de parâmetros encontradas. Foi observado que os processos de otimização genética com os mesmos intervalos de parâmetros de entrada, mas com critérios diferentes, convergem para combinações distintas.
Portanto, não há necessidade de adicionar um campo de ordenação à tabela de tarefas. Podemos usar a ordem na qual as tarefas de um trabalho foram adicionadas à base de dados, ou seja, ordená-las pelo id_task.
Se, dentro de um mesmo trabalho, houver apenas uma tarefa, a ordem de execução dependerá da ordem de execução dos trabalhos. Os trabalhos foram planejados para agrupar ou, mais precisamente, para dividir as tarefas em diferentes combinações de símbolos e timeframes. Se tomarmos como exemplo que temos três símbolos (EURGBP, EURUSD, GBPUSD) e dois timeframes (H1, M30) e duas etapas (Stage1, Stage2), podemos escolher duas possíveis ordens:
- Agrupamento por símbolo e timeframe:
- EURGBP H1 Stage1
- EURGBP H1 Stage2
- EURGBP M30 Stage1
- EURGBP M30 Stage2
- EURUSD H1 Stage1
- EURUSD H1 Stage2
- EURUSD M30 Stage1
- EURUSD M30 Stage2
- GBPUSD H1 Stage1
- GBPUSD H1 Stage2
- GBPUSD M30 Stage1
- GBPUSD M30 Stage2
- Agrupamento por etapa:
- Stage1 EURGBP H1
- Stage1 EURGBP M30
- Stage1 EURUSD H1
- Stage1 EURUSD M30
- Stage1 GBPUSD H1
- Stage1 GBPUSD M30
- Stage2 EURGBP H1
- Stage2 EURGBP M30
- Stage2 EURUSD H1
- Stage2 EURUSD M30
- Stage2 GBPUSD H1
- Stage2 GBPUSD M30
No primeiro método de agrupamento (por símbolo e timeframe), seremos capazes de obter algo pronto após a conclusão do segundo estágio de cada trabalho, ou seja, o EA final. Ele incluirá conjuntos de instâncias únicas de estratégias de trading para os símbolos e timeframes que já passaram por ambas as etapas de otimização.
No segundo método de agrupamento (por etapa), o EA final só poderá ser obtido quando todas as tarefas da primeira etapa forem concluídas e pelo menos uma tarefa da segunda etapa também for concluída.
Para os trabalhos que utilizam apenas os resultados das etapas anteriores para o mesmo símbolo e timeframe, não haverá diferença entre esses dois métodos. No entanto, se olharmos um pouco mais à frente, haverá uma nova etapa onde os resultados das segundas etapas para diferentes símbolos e timeframes serão combinados. Ainda não chegamos à implementação dessa etapa como uma etapa de otimização automática, mas já preparamos o EA da etapa e até o executamos, mas manualmente. Para essa etapa, o primeiro método de agrupamento não é adequado, por isso usaremos o segundo método.
Vale ressaltar que, se realmente quisermos usar o primeiro método, talvez seja suficiente criar vários projetos para cada combinação de símbolo e timeframe. No entanto, por enquanto, o benefício disso não está claro.
Então, se tivermos vários trabalhos dentro de uma etapa, a ordem de execução pode ser qualquer uma, e para trabalhos de diferentes etapas, a ordem de execução será determinada pela ordem das etapas. Ou seja, assim como para as tarefas, não há necessidade de adicionar um campo de ordenação à tabela de trabalhos. Podemos usar a ordem na qual os trabalhos de uma etapa foram adicionados à base de dados, ou seja, ordená-los pelo id_job.
Para definir a ordem das etapas, também podemos aproveitar os dados já existentes na tabela de etapas (stages). Desde o início, adicionamos um campo para a etapa pai (id_parent_stage) nessa tabela, mas, devido à falta de necessidade, ainda não o utilizamos. De fato, quando temos apenas duas linhas na tabela para duas etapas, não há dificuldade em criá-las na ordem desejada — primeiro a linha para a primeira etapa e depois para a segunda. Quando elas aumentam e ainda surgem etapas de outros projetos, manter a ordem correta manualmente se torna mais difícil.
Portanto, vamos aproveitar a possibilidade de construir uma hierarquia de etapas em execução, onde cada etapa será executada após a conclusão de sua etapa pai. Nesse caso, pelo menos uma etapa não deve ter pai, para ocupar a posição mais alta na hierarquia. Vamos escrever uma consulta SQL de teste que conectará os dados das tabelas de tarefas, trabalhos e etapas e mostrará todas as tarefas da etapa atual. Na lista de colunas dessa consulta, vamos adicionar todos os campos, para que possamos ver as informações mais completas possíveis.
SELECT t.id_task,
t.optimization_criterion,
t.status AS task_status,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs,
j.status AS job_status,
s.id_stage,
s.name AS stage,
s.expert AS stage_expert,
s.status AS stage_status,
ps.name AS parent_stage,
ps.status AS parent_stage_status,
p.id_project,
p.status AS project_status
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
LEFT JOIN
stages ps ON ps.id_stage = s.id_parent_stage
JOIN
projects p ON p.id_project = s.id_project
WHERE t.id_task > 0 AND
t.status IN ('Queued', 'Process') AND
(ps.id_stage IS NULL OR
ps.status = 'Done')
ORDER BY j.id_stage,
j.symbol,
j.period,
t.status,
t.id_task;

Figura 1. Resultados da consulta para obter as tarefas da etapa atual após o início de uma tarefa
No futuro, vamos reduzir o número de colunas exibidas quando usarmos esse tipo de consulta para encontrar a próxima tarefa. Mas, por enquanto, vamos garantir que estamos obtendo a próxima etapa corretamente (junto com seus trabalhos e tarefas). Os resultados mostrados na Figura 1 correspondem ao momento em que a tarefa com id_task=3 foi iniciada, pertencente ao trabalho com id_job=10, que faz parte da etapa com id_stage=10. Esta etapa é chamada de "First", pertence ao projeto com id_project=1 e não tem uma etapa pai (parent_stage=NULL). Pode-se notar que a presença de uma tarefa em execução leva à mudança do status para Process tanto para o trabalho quanto para o projeto no qual esse trabalho está sendo executado. Mas para o outro trabalho com id_job=5, o status ainda permanece como Queued, já que nenhuma tarefa desse trabalho foi iniciada.
Agora, vamos tentar concluir a primeira tarefa (simplesmente alterando o valor do campo status para Done na tabela) e veremos os resultados dessa mesma consulta:

Figura 2. Resultados da consulta para obter as tarefas da etapa atual após a conclusão da tarefa iniciada
Como pode ser visto, a tarefa concluída desapareceu da lista, e a linha superior agora está ocupada por outra tarefa, que pode ser iniciada a seguir. Até agora, tudo está correto. Agora, vamos iniciar e concluir as duas primeiras tarefas dessa lista, e iniciar a terceira tarefa com id_task=7:

Figura 3. Resultados da consulta para obter as tarefas da etapa atual após a conclusão das tarefas do primeiro trabalho e o início da próxima tarefa
Agora, o trabalho com id_job=5 recebeu o status Process. Em seguida, vamos iniciar e concluir essas três tarefas, que agora estão mostradas nos resultados da última consulta. Elas desaparecerão uma a uma dos resultados da consulta. Após a conclusão da última, vamos novamente rodar a consulta e obter o seguinte:

Figura 4. Resultados da consulta para obter as tarefas da etapa atual após a conclusão de todas as tarefas do primeiro etapa
Agora, os resultados da consulta incluem tarefas de trabalhos pertencentes às etapas subsequentes. A etapa com id_stage=2 é a clusterização dos resultados da primeira etapa, e a etapa com id_stage=3 é a segunda etapa, onde ocorre a seleção dos bons exemplos de estratégias de trading obtidas na primeira etapa. Esta etapa não utiliza clusterização, por isso pode ser iniciada imediatamente após a primeira etapa. Assim, sua presença nesta lista não é um erro. Ambas as etapas têm como etapa pai a etapa chamada "First", que agora está no status Done.
Vamos simular a execução e a conclusão das duas primeiras tarefas e olhar novamente os resultados da consulta:

Figura 5. Resultados da consulta para obter as tarefas após a conclusão de todas as tarefas da etapa de clusterização
As linhas superiores dos resultados estão, como esperado, ocupadas pelas duas tarefas da segunda etapa (chamada "Second"), mas as duas últimas linhas agora contêm tarefas da segunda etapa com clusterização (chamada "Second with clustering"). Sua presença é um pouco inesperada, mas não contradiz a ordem permitida. De fato, se já realizamos a etapa de clusterização, podemos iniciar a etapa que usará os resultados dessa clusterização. As duas etapas mostradas nos resultados da consulta são independentes entre si, portanto, podem ser executadas em qualquer ordem.
Vamos novamente iniciar e concluir cada tarefa, selecionando sempre a tarefa superior nos resultados. A lista de tarefas, após cada mudança de status, comportou-se corretamente, com os status dos trabalhos e das etapas sendo atualizados de maneira adequada. Após a conclusão da última tarefa, os resultados da consulta ficaram vazios, pois todas as tarefas de todos os trabalhos e etapas foram concluídas e o projeto foi marcado como Done.
Agora, vamos integrar essa consulta no EA otimizador.
Modificação do EA otimizador
Precisaremos fazer alterações no método que obtém o identificador da próxima tarefa do otimizador, onde já existe uma consulta SQL que realiza essa tarefa. Vamos pegar a consulta desenvolvida acima e remover a obtenção de campos desnecessários, mantendo apenas o campo de identificação da tarefa, id_task. Também podemos substituir a ordenação pela combinação de campos da tabela de trabalhos (j.symbol, j.period) por uma ordenação pelo identificador do trabalho (j.id_job), uma vez que cada trabalho tem apenas um valor para esses dois campos. No final, vamos adicionar uma limitação para o número de linhas retornadas. Precisamos obter apenas uma linha.
Com isso, o método GetNextTaskId() ficará da seguinte forma:
//+------------------------------------------------------------------+ //| Get the ID of the next optimization task from the queue | //+------------------------------------------------------------------+ ulong COptimizer::GetNextTaskId() { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT t.id_task" " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " LEFT JOIN " " stages ps ON ps.id_stage = s.id_parent_stage " " JOIN " " projects p ON p.id_project = s.id_project " " WHERE t.id_task > 0 AND " " t.status IN ('Queued', 'Process') AND " " (ps.id_stage IS NULL OR " " ps.status = 'Done') " " ORDER BY j.id_stage, " " j.id_job, " " t.status, " " t.id_task" " LIMIT 1;"; // ... here we get the query result return res; }
Já que decidimos trabalhar com esse arquivo, também faremos outra modificação: removeremos a transmissão do status como parâmetro no método de obtenção do número de tarefas na fila. De fato, não usamos esse método para obter o número de tarefas com status Queued e Process, que serão utilizadas separadamente, e não como um total. Portanto, vamos modificar a consulta SQL no método TotalTasks() para que ela sempre retorne o número total de tarefas com esses dois status, e removeremos o parâmetro de entrada status do método.
//+------------------------------------------------------------------+ //| Get the number of tasks with the specified status | //+------------------------------------------------------------------+ int COptimizer::TotalTasks() { // Result int res = 0; // Request to get the number of tasks with the specified status string query = "SELECT COUNT(*)" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Process') " " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // ... here we get the query result return res; }
Vamos salvar as modificações feitas no arquivo Optimizer.mqh na pasta atual.
Além dessas modificações, precisaremos corrigir em vários arquivos o antigo nome de status "Processing" para "Process", já que concordamos em usar este último.
Também vale destacar que, para o futuro, seria ideal prever a possibilidade de obter informações sobre erros que possam ter ocorrido durante a execução de uma tarefa, que lança o programa Python. Atualmente, quando esse programa termina de maneira anormal, o EA otimizador simplesmente fica preso na etapa de espera pela conclusão da tarefa, ou mais precisamente, esperando pela atualização das informações na base de dados sobre esse evento. Se o programa terminou com erro, ele não conseguiu atualizar o status da tarefa na base de dados. Por isso, nesse estágio, o pipeline não pode avançar.
Até agora, a única maneira de superar esse impasse é reiniciar manualmente o programa Python com os parâmetros fornecidos pela tarefa, analisar as causas dos erros, corrigi-los e reiniciar o processo, o que agora será concluído com sucesso.
Modificação do SimpleVolumesStage3.mq5
A seguir, planejamos automatizar a terceira etapa, onde, para cada trabalho da segunda etapa (que se diferencia pelo símbolo e timeframe usados), selecionamos o melhor passe para incluir no EA final.
Até agora, o EA da terceira etapa recebia como parâmetros de entrada uma lista de identificadores de passes da segunda etapa, e precisávamos selecionar manualmente esses identificadores da base de dados de alguma forma. Além disso, esse EA realizava apenas a criação, a avaliação da retração e o salvamento na biblioteca de grupos desses passes. O EA final não era gerado após a execução do EA da terceira etapa, pois ainda era necessário realizar uma série de ações adicionais. Voltaremos à automação dessas ações mais tarde, mas por enquanto, vamos nos concentrar na modificação do EA da terceira etapa.
Para a seleção automática dos identificadores dos passes, podemos usar diferentes abordagens.
Por exemplo, de todos os resultados dos passes obtidos dentro de um trabalho da segunda etapa, podemos selecionar o melhor, baseado na média anual normalizada do lucro. Um desses passes será, por sua vez, o resultado de um grupo de 16 instâncias individuais de estratégias de trading. Nesse caso, o EA final incluirá um grupo de várias dessas instâncias de estratégias individuais. Se tivermos três símbolos e dois timeframes, tivemos 6 trabalhos na segunda etapa. Então, na terceira etapa, obteremos um grupo composto por 6 * 16 = 96 instâncias de estratégias individuais. Esse método é o mais simples de implementar.
Um exemplo de um método de seleção mais complexo seria: para cada trabalho da segunda etapa, pegamos uma certa quantidade dos melhores passes e tentamos várias combinações de todos os passes escolhidos. Isso é muito semelhante ao que fizemos na segunda etapa, mas agora teremos um grupo formado não por 16 instâncias individuais, mas por 6 grupos, sendo que no primeiro dos seis grupos, pegaremos um dos melhores passes do primeiro trabalho, no segundo grupo, um dos melhores passes do segundo trabalho, e assim por diante. Esse método é mais complexo, no entanto, não podemos afirmar de antemão que ele resultará em uma melhoria significativa dos resultados.
Portanto, vamos implementar primeiro o método mais simples e deixaremos a complexidade para um momento posterior.
Nessa etapa, já não será necessário realizar a otimização dos parâmetros do EA, agora será apenas um passe único. Para isso, nas configurações da etapa na base de dados, será necessário definir os parâmetros correspondentes: na coluna de otimização, o valor deve ser 0.

Figura 6. Conteúdo da tabela de etapas
No código do EA, adicionaremos um parâmetro de entrada para o identificador da tarefa de otimização, para que este EA possa ser executado no pipeline, com a correta gravação dos resultados do passe na base de dados:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "database911.sqlite"; // - File with the main database input group "::: Selection for the group" input string passes_ = ""; // - Comma-separated pass IDs input group "::: Saving to library" input string groupName_ = ""; // - Group name (if empty - no saving)
O parâmetro passes_ poderia ser removido, mas vamos mantê-lo por enquanto, por precaução. Escreveremos uma consulta SQL para obter a lista de identificadores dos melhores passes para os trabalhos da segunda etapa. Se o parâmetro passes_ estiver vazio, tomaremos os identificadores dos melhores passes. Caso contrário, se passarmos identificadores específicos no parâmetro passes_, esses serão usados.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); CTesterHandler::TesterInit(idTask_, fileName_); // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the connection to the main database is established, if(DB::Connect(fileName_)) { // Form a request to receive passes with the specified IDs string query = (passes_ == "" ? StringFormat("SELECT DISTINCT FIRST_VALUE(p.params) OVER (PARTITION BY p.id_task ORDER BY custom_ontester DESC) AS params " " FROM passes p " " WHERE p.id_task IN (" " SELECT pt.id_task " " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " JOIN " " jobs pj ON pj.id_stage = s.id_parent_stage " " JOIN " " tasks pt ON pt.id_job = pj.id_job " " WHERE t.id_task = %d " " ) ", idTask_) : StringFormat("SELECT params" " FROM passes " " WHERE id_pass IN (%s);", passes_) ); Print(query); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Structure for reading results struct Row { string params; } row; // For all query result strings, concatenate initialization rows while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // ... // Successful initialization return(INIT_SUCCEEDED); }
Vamos salvar as modificações feitas no arquivo SimpleVolumesStage3.mq5 na pasta atual.
Com isso, a modificação do EA da terceira etapa está concluída. Vamos alterar o status do projeto na base de dados para Queued e iniciar o EA otimizador.
Resultados do pipeline de otimização
Embora ainda não tenhamos implementado todas as etapas planejadas, já temos uma ferramenta que gera automaticamente um EA quase pronto. Após a conclusão da terceira etapa, na biblioteca de parâmetros (tabela strategy_groups), surgiram duas entradas:

A primeira contém o identificador do passe em que os melhores grupos da segunda etapa são combinados sem clusterização. A segunda contém o identificador do passe em que os melhores grupos da segunda etapa são combinados com clusterização. Podemos então, a partir da tabela passes, buscar as linhas de inicialização desses identificadores de passe e analisar os resultados dessas duas combinações.
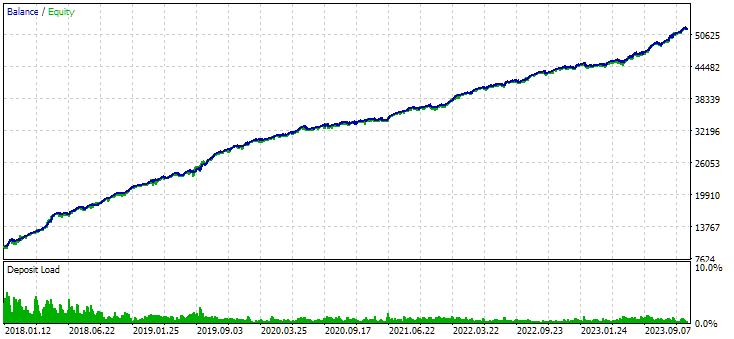
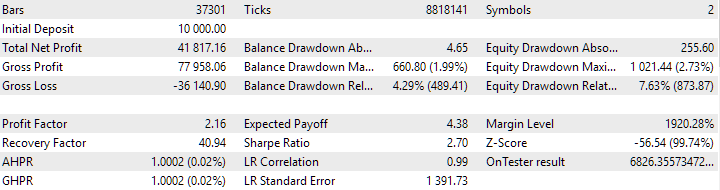
Figura 7. Resultados do grupo combinado de instâncias, obtido sem o uso de clusterização
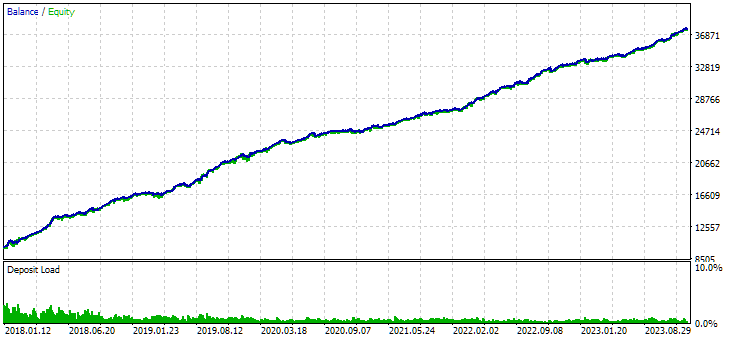
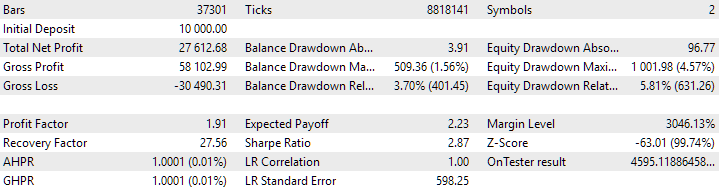
Figura 8. Resultados do grupo combinado de instâncias, obtido com o uso de clusterização
No caso sem clusterização, o lucro foi maior, enquanto no caso com clusterização, o índice de Sharpe foi mais alto e a linearidade foi melhor. No entanto, ainda não vamos analisar esses resultados em detalhes, pois eles ainda não são finais.
De acordo com o plano, a próxima etapa será a adição das etapas de construção do EA final. Será necessário exportar a biblioteca para gerar o arquivo incluível ExportedGroupsLibrary.mqh na pasta de dados. Em seguida, esse arquivo será copiado para a pasta de trabalho. Essa operação pode ser realizada por meio de um programa em Python ou utilizando funções de cópia do sistema a partir de uma DLL. Na última etapa, precisamos compilar o EA final e iniciar o terminal com a nova versão do EA.
Tudo isso exigirá um tempo considerável para implementação, então continuaremos a descrição dessa etapa no próximo artigo.
Considerações finais
Então, vamos dar uma olhada no que conseguimos até agora. Organizamos a execução automática das primeiras etapas do pipeline de otimização automática, garantindo que elas funcionem corretamente. Podemos observar os resultados intermediários e decidir, por exemplo, se vamos abandonar o uso da etapa de clusterização. Ou, ao contrário, podemos mantê-la e eliminar a opção sem clusterização.
A disponibilidade de uma ferramenta como essa nos ajudará no futuro a realizar experimentos e tentar responder a questões complexas. Por exemplo, suponha que estamos realizando uma otimização em diferentes intervalos de parâmetros de entrada na primeira etapa. O que seria melhor — agrupá-los separadamente ou juntos, para símbolos e timeframes iguais?
Ao adicionar etapas ao pipeline, podemos implementar a construção gradual de EAs cada vez mais complexos.
Finalmente, podemos refletir sobre a questão da reotimização parcial e até mesmo da reotimização contínua, realizando o experimento correspondente. Por reotimização, entende-se a reexecução da otimização em um intervalo de tempo diferente. Mas sobre isso falaremos em outra ocasião.
Obrigado pela atenção, até a próxima!
Aviso importante
Todos os resultados apresentados neste artigo e em todos os artigos anteriores da série são baseados exclusivamente em dados de testes históricos e não garantem nenhum tipo de lucro no futuro. O trabalho dentro deste projeto é de caráter investigativo. Todos os resultados publicados podem ser utilizados por qualquer interessado por sua própria conta e risco.
Conteúdo do arquivo
| # | Nome | Versão | Descrição | Últimas alterações |
|---|---|---|---|---|
| MQL5/Experts/Article.16134 | ||||
| 1 | Advisor.mqh | 1.04 | Classe base do Expert Advisor | Parte 10 |
| 2 | ClusteringStage1.py | 1.01 | Programa de clusterização dos resultados da primeira etapa de otimização | Parte 20 |
| 3 | Database.mqh | 1.07 | Classe para trabalhar com a base de dados | Parte 19 |
| 4 | database.sqlite.schema.sql | 1.05 | Esquema da base de dados | Parte 20 |
| 5 | ExpertHistory.mqh | 1.00 | Classe para exportar o histórico de transações para um arquivo | Parte 16 |
| 6 | ExportedGroupsLibrary.mqh | — | Arquivo gerado com a lista de nomes dos grupos de estratégias e suas respectivas linhas de inicialização | Parte 17 |
| 7 | Factorable.mqh | 1.02 | Classe base para objetos criados a partir de uma linha | Parte 19 |
| 8 | GroupsLibrary.mqh | 1.01 | Classe para trabalhar com a biblioteca de grupos selecionados de estratégias | Parte 18 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | EA para reprodução do histórico de transações com gerenciamento de risco | Parte 16 |
| 10 | HistoryStrategy.mqh | 1.00 | Classe de estratégia de trading para reprodução do histórico de transações | Parte 16 |
| 11 | Interface.mqh | 1.00 | Classe base para visualização de diferentes objetos | Parte 4 |
| 12 | LibraryExport.mq5 | 1.01 | EA que salva as linhas de inicialização dos passes selecionados da biblioteca no arquivo ExportedGroupsLibrary.mqh | Parte 18 |
| 13 | Macros.mqh | 1.02 | Macros úteis para operações com arrays | Parte 16 |
| 14 | Money.mqh | 1.01 | Classe base para gerenciamento de capital | Parte 12 |
| 15 | NewBarEvent.mqh | 1.00 | Classe para detectar novas barras para um símbolo específico | Parte 8 |
| 16 | Optimization.mq5 | 1.03 | EA que gerencia o lançamento das tarefas de otimização | Parte 19 |
| 17 | Optimizer.mqh | 1.01 | Classe para o gerente de otimização automática de projetos | Parte 20 |
| 18 | OptimizerTask.mqh | 1.01 | Classe para tarefa de otimização | Parte 20 |
| 19 | Receiver.mqh | 1.04 | Classe base para converter volumes abertos em posições de mercado | Parte 12 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | EA simplificado para reprodução do histórico de transações | Parte 16 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | EA para execução paralela de vários grupos de estratégias modelo. Os parâmetros serão extraídos da biblioteca interna de grupos. | Parte 17 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | EA para otimização de uma instância de estratégia de trading (Etapa 1) | Parte 19 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | EA para otimização de um grupo de instâncias de estratégias de trading (Etapa 2) | Parte 19 |
| 24 | SimpleVolumesStage3.mq5 | 1.02 | EA que salva o grupo normatizado de estratégias na biblioteca de grupos com o nome especificado. | Parte 20 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | Classe de estratégia de trading utilizando volumes de ticks | Parte 15 |
| 26 | Strategy.mqh | 1.04 | Classe base para estratégias de trading | Parte 10 |
| 27 | TesterHandler.mqh | 1.05 | Classe para processamento de eventos de otimização | Parte 19 |
| 28 | VirtualAdvisor.mqh | 1.07 | Classe de EA que trabalha com posições virtuais (ordens) | Parte 18 |
| 29 | VirtualChartOrder.mqh | 1.01 | Classe para a posição gráfica virtual | Parte 18 |
| 30 | VirtualFactory.mqh | 1.04 | Classe de fábrica para objetos | Parte 16 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | Classe de EA para reprodução do histórico de transações | Parte 16 |
| 32 | VirtualInterface.mqh | 1.00 | Classe para interface gráfica do EA | Parte 4 |
| 33 | VirtualOrder.mqh | 1.07 | Classe para ordens e posições virtuais | Parte 19 |
| 34 | VirtualReceiver.mqh | 1.03 | Classe para converter volumes abertos em posições de mercado (receptor) | Parte 12 |
| 35 | VirtualRiskManager.mqh | 1.02 | Classe para gerenciamento de risco (gerente de risco) | Parte 15 |
| 36 | VirtualStrategy.mqh | 1.05 | Classe de estratégia de trading com posições virtuais | Parte 15 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | Classe para grupo de estratégias de trading ou grupos de estratégias | Parte 11 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | Classe de receptor simbólico | Parte 3 |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16134
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Oi Yuriy
Usei o Google Translate para chegar à Parte 20. Pesquise "Google Translate" no Google e coloque-o em uma nova guia no navegador. Ele colocará um ícone na barra de pesquisa, na extremidade direita. Carregue a página em seu idioma nativo e pressione o ícone para selecionar o idioma do artigo e o idioma a ser traduzido para ele. Presto, estou na parte 20! Ele não faz um trabalho perfeito, mas a tradução é 99% útil.
Carreguei seu Archive Source no Excel e adicionei algumas colunas para classificar e organizar o conteúdo. Além de classificar no Excel, a planilha pode ser importada diretamente para um banco de dados do OutLook
Estou tendo problemas para identificar o artigo inicial para estabelecer o banco de dados SQL. Tentei executar o Volume Simples Estágio 1 e obtive uma linha plana, o que me indica que provavelmente preciso voltar atrás e criar outro banco de dados SQL. Seria extremamente útil ter uma tabela com a ordem de execução dos programas necessários para obter um sistema funcional. Talvez você possa adicioná-la à tabela Archive Source.
Outra pequena solicitação é usar a opção <> para incluir especificações de arquivo em vez de "". Estou mantendo seu sistema separado em meus diretórios Experts e Include, #include <!!!! MultiCurrency\VirtualAdvisor.mqh>, portanto, essa alteração facilitará a adição da especificação do subdiretório/.
Obrigado por sua contribuição
CapeCoddah
Olá.
Sobre o preenchimento inicial do banco de dados com informações sobre o projeto, etapas, trabalhos e tarefas, você pode ver nas partes 13, 18 e 19. Esse não é o tópico principal, portanto, as informações de que você precisa estarão em algum lugar mais próximo do final dos artigos. Por exemplo, na parte 18:
Ou na parte 19:
Ou você pode aguardar o próximo artigo, que será dedicado, entre outras coisas, à questão do preenchimento inicial do banco de dados com a ajuda de um script auxiliar.
A mudança para o uso da pasta include para armazenar os arquivos da biblioteca está nos planos, mas ainda não chegou a esse ponto.
Muito obrigado
Oi Yuriy,
Você já enviou o próximo artigo ou sabe quando ele será publicado?