
Do básico ao intermediário: Estruturas (VI)

Introdução
No artigo anterior Do básico ao intermediário: Estruturas (V), foi mostrado e explicado, como poderíamos criar templates de estruturas simples. Isto para conseguirmos sobrecarregar uma estrutura para outros tipos de dados, sem precisar programar novamente todo um contexto estrutural. Apesar de que a princípio, aquele artigo, ser um tanto quanto complicado de ser entendido. Tentei explicar as coisas de forma a tornar o artigo o mais simples e prático possível. Isto para que todos consigam acompanhar e estudar os temas de maneira a realmente conseguir utilizar os conceitos mostrados e adotados em cada um dos artigos.
Pois bem, apesar de tudo, aquilo que foi visto naquele artigo, é a parte fácil de um conjunto de conceitos e informações. Que visam principalmente colocar debaixo de um guarda-chuva, uma ampla e vasta gama de atividades possíveis e passiveis de serem feitas por um programador realmente qualificado.
O que iremos começar a ver agora, e irei mostrar isto aos poucos, tem como objetivo, literalmente ampliar a aplicação do que foi visto no artigo anterior. Sendo portanto, e isto de maneira literal, tema de muitos cursos, voltados a programação avançada e temas como análise de dados e afins. Assim, não espere ver tudo em um único artigo. Seria necessário um conjunto enorme de artigos, apenas para abordar de maneira adequada este tema. E isto, sem nem ao menos entrarmos no que seria a programação orientada em objetos.
E por que estou frisando isto? O motivo, é que vejo muita gente doida para aprender a utilizar classes e coisas do tipo. Porém, estas mesmas pessoas, não tem uma base ou conceitos básicos para poder compreender a magnitude do que seria a programação orientada em objetos. E tais conceitos somente nascem e surgem, quando você, meu caro leitor, consegue por compreender adequadamente o que seria uma programação estrutural. E para entender isto, é preciso, de fato dedicar muito tempo em estudos e na solução de problemas reais. Coisa que só vem com o tempo e experiência.
Porém, estes artigos visam justamente acelerar um pouco esta fase de aprendizagem. Assim, o que iria demorar anos, passa a ser feito em questão de meses ou até semanas, dependendo do seu empenho e perfil. E acredite, ter um perfil de programador, é extremamente necessário, para que você consiga assimilar as coisas de maneira bem rápida. Sem isto, você até conseguirá aprender a criar diversas coisas. Mas infelizmente irá chegar um ponto no qual você não conseguirá mais avançar. Meu objetivo, com estes artigos, é justamente este. Mostrar a você, que não importa o fato de você ter ou não o perfil correto. Com calma, paciência e bastante dedicação e estudo. Qualquer um pode vir a se tornar um bom programador.
Então vamos começar, um novo tópico para rever o que foi feito no artigo anterior e também entender alguns pormenores que talvez tenham passado batido. Pois isto é muito importante para entender, algumas coisas que veremos muito em breve.
Pensando em problemas do dia a dia
Uma das coisas mais simples que existe, é o de procurar um contato em uma agenda de contatos. Isto é sem dúvida, uma tarefa muito simples e básica. Assim como procurar sinônimos de palavras em um dicionário de sinônimos. Ou quem sabe, procurar o significado de uma palavra em um dicionário. Estas são coisas, que uma criança consegue aprender, já que é muito simples de ensinar como proceder. Porém, você já parou para pensar em como seria, se você não soubesse como encontrar um contato em uma agenda? Ou como encontrar um número de telefone em uma lista telefônica? Ou até mesmo, como seu navegador de internet, consegue rapidamente encontrar um site requisitado? Pois bem, todos estes problemas, tem como base, o mesmo tipo de conceito primordial. Estruturas.
No entanto, apesar do conceito ser o mesmo, o tipo de informação contida ali, pode variar imensamente. Por exemplo: Em uma agenda de contatos, você pode ter um nome e um endereço, ou número de telefone. Mas em um dicionário, teremos uma palavra seguida de seu significado. Tudo isto, pode ser organizado de uma maneira muito simples e prática. Porém, implementar um código, que consiga lidar com diferentes tipos de estrutura, sem que seja necessário efetuar enormes modificações. Isto sim, é algo realmente notável. Existem formas de se fazer isto. Mas não vamos chegar tão longe, já que não seria de fato necessário. Visto que o objetivo aqui, é mostrar como as coisas podem ser implementadas, fazendo uso de conceitos simples.
No antigo anterior, mostrei como lidar com um tipo de código estrutural muito simples. Onde dentro da própria estrutura, teríamos dados discretos sendo utilizados para objetivos diversos. Porém, aquele tipo de solução, não se adequa a problemas de natureza mais ampla. Para que você consiga entender isto, vamos criar um código muito simples e fácil de entender. Este pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. }; 26. //+------------------------------------------------------------------+ 27. #define PrintX(X) Print(#X, " => ", X) 28. //+------------------------------------------------------------------+ 29. void OnStart(void) 30. { 31. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 32. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 33. 34. st_Data <double> Info_1; 35. st_Data <uint> Info_2; 36. 37. Info_1.Set(H); 38. Info_2.Set(K); 39. 40. PrintX(Info_1.Get(Info_2.Get(3))); 41. } 42. //+------------------------------------------------------------------+
Código 01
Este código 01 pode ser muito engraçado e interessante. Dependendo da forma como você venha a analisar ele, antes mesmo de entender o que quero explicar. Já que nele criamos uma relação desconexa entre duas entidades. Mas vamos com calma. Já que o conceito a ser entendido, é de fato algo que nos ajuda a entender como problemas do dia a dia, podem ser modelados. Isto de modo a nos permitir fazer uso de uma programação estrutural muito simples e relativamente bem abrangente.
O que estamos tentando fazer neste código 01, é uma tentativa de criar, via programação estrutural, uma ligação entre os elementos do array K e os elementos do array H. Naturalmente, poderíamos criar a mesma coisa de forma convencional. Porém criando as coisas de maneira estrutural, você logo irá notar, o quanto é mais simples expandir as coisas, para outros tipos de problemas. Sem ao menos precisarmos mexer no código já criado.
Se você vem praticando e estudando o conteúdo dos artigos. Sabe perfeitamente bem, que tipo de resultado será gerado por este código. E mais ainda. Você sabe por que este código consegue gerar o resultado que é gerado. E tudo isto, apenas olhando para este código 01. Porém para aqueles que ainda não alcançaram este nível de excelência. Vamos mostrar para eles o resultado impresso no terminal do MetaTrader 5. Este pode ser visto na imagem logo abaixo.

Imagem 01
Pergunta: Porque a linha 40, está mostrando este valor na imagem 01? Resposta: Porque estamos usando um elemento presente no array K para indexar um elemento no array H. Porém não é bem isto que queríamos fazer. Mas, ok, a ideia de fato é ligar um valor do array K para saber o valor no array H. No entanto, a ligação não aconteceu como previsto.
Para tornar claro, qual seria a ideia aqui, é preciso que você entenda o seguinte meu caro leitor. O array K seria como uma chave, onde cada um dos valores seria um índice para podermos acessar, ou conhecer o valor no array H. No entanto, este array K está fora de ordem. E isto foi feito de maneira proposital para que você entenda porque nem sempre a solução nasce de imediato.
Para que você entenda como esta relação irá se dar, vamos modificar o código 01, para o código 02.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. uint NumberOfElements(void) 26. { 27. return Values.Size(); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. void OnStart(void) 33. { 34. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 35. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 36. 37. st_Data <double> Info_1; 38. st_Data <uint> Info_2; 39. 40. Info_1.Set(H); 41. Info_2.Set(K); 42. 43. for (uint c = 0; c < Info_2.NumberOfElements(); c++) 44. PrintFormat("Index [%d] => [%.2f]", Info_2.Get(c), Info_1.Get(c)); 45. } 46. //+------------------------------------------------------------------+
Código 02
Ok, talvez agora neste código 02, as coisas fiquem mais claras. Já que na linha 43, estamos fazendo uso de um laço a fim de varrer todos os elementos presentes. E ao mesmo tempo, mostrar como um array estaria correlacionado com o outro array. No caso, quando executarmos este código 02, teremos o que é visto na imagem logo abaixo.
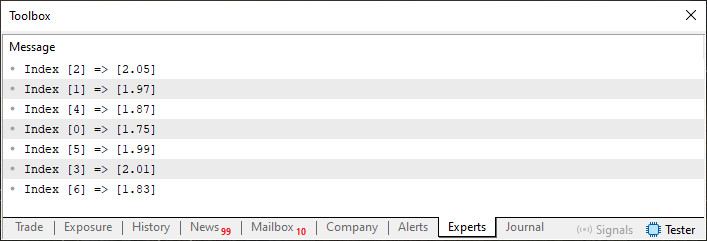
Imagem 02
Muito bem, agora podemos voltar na questão do código 01. Já que com base nesta imagem 02, sabemos que dado um índice, declarado no array K. Temos um valor correspondente no array H. Então quando no código 01, estivéssemos pedindo para saber qual seria o valor do terceiro índice. Não estaríamos de fato nos referindo ao valor mostrado na imagem 01. Isto porque se ignorarmos o fato dos arrays estarem fora de ordem, o terceiro índice, no array K, seria de fato o zero. Porém, ao pedirmos para que o valor correspondente nos fosse mostrado. Não estaríamos apontando para o índice correto no array H. Sei que isto pode parecer confuso. Mas você logo irá entender onde quero chegar.
Então tudo bem, o primeiro problema que temos é o fato de que os arrays estão desordenados. E para uma pesquisa de fato eficiente, precisamos que eles estejam ordenados. Lembrando que a relação mostrada na imagem 02 deverá ser mantida. Já que um array servirá como fonte de busca e o outro como fonte de resposta.
Muitos iniciantes ao ouvirem tais coisas, já pensam logo em uma solução. Sendo a mais óbvia, utilização da função ArraySort para organizar os arrays, ou a ArrayBsearch para pesquisar no array. De qualquer maneira, precisamos modificar o código 01, para conseguir nosso objetivo. Assim surge o código que é visto logo na sequência.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. T Search(const uint index) 26. { 27. return ArrayBsearch(Values, index); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. #define PrintX(X) Print(#X, " => ", X) 33. //+------------------------------------------------------------------+ 34. void OnStart(void) 35. { 36. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 37. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 38. 39. st_Data <double> Info_1; 40. st_Data <uint> Info_2; 41. 42. Info_1.Set(H); 43. Info_2.Set(K); 44. 45. PrintX(Info_1.Get(Info_2.Search(3))); 46. } 47. //+------------------------------------------------------------------+
Código 03
Ao executarmos este código 03, temos finalmente a ligação correta, e pretendida. Isto acaba gerando o que é visto logo abaixo, como resposta.

Imagem 03
Observe meu caro leitor, que o valor que o valor que está sendo dada como resposta de fato corresponde ao índice procurado dentro do que seria a nossa lista, por assim dizer. Isto olhando a correspondência entre o array K e o array H, que é mostrado na imagem 02. Porém existem formas mais simples de se fazer este mesmo tipo de ligação. Onde podemos trabalhar de maneira mais adequada, mantendo de fato uma relação mais estreita entre o array K e o array H.
Uma destas formas seria a utilização de arrays multidimensionais. No entanto, arrays multidimensionais não são muito adequados para trabalhar com tipos diferentes de informações. Sendo necessário fazermos uso de uma outra maneira de criar este tipo de ligação. Lembrando que a ideia é criar um código que esteja contido dentro do que seria uma estrutura.
Sendo assim, precisamos dar um passo para trás, para depois dar dois para frente. Isto a fim de tornar a compreensão da solução mais simples. Então para separar as coisas vamos a um novo tópico.
Estruturas de estruturas
Uma das coisas que costuma confundir muito iniciante, é quando passamos a usar conceitos que foram vistos até agora de modo individualizado, m um formato conjugado. Sei que pode parecer estranho dizer isto. Já que basicamente, o conceito se manterá intacto. No entanto, quando unimos conceitos e os aplicamos de maneira mais profunda. Novas possibilidades surgem e algumas podem ser bastante confusas no primeiro momento.
Para explicar isto, vamos modificar o código 03 visto no tópico anterior, de modo a podermos gerar algo que seja simples de entender. E ao mesmo tempo nos permita direcionar e explicação para algo que seria o nosso objetivo primário. Ou seja, criar um tipo de ligação entre um conjunto de valores e outro conjunto de valores completamente distinto.
Para isto, vamos usar o código implementado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. struct st_Reg 07. { 08. double h_value; 09. uint k_value; 10. }Values[]; 11. }; 12. //+------------------------------------------------------------------+ 13. bool Set(st_Data &dst, const uint &arg1[], const double &arg2[]) 14. { 15. if (arg1.Size() != arg2.Size()) 16. return false; 17. 18. ArrayResize(dst.Values, arg1.Size()); 19. for (uint c = 0; c < arg1.Size(); c++) 20. { 21. dst.Values[c].k_value = arg1[c]; 22. dst.Values[c].h_value = arg2[c]; 23. } 24. 25. return true; 26. } 27. //+------------------------------------------------------------------+ 28. string Get(const st_Data &src, const uint index) 29. { 30. for (uint c = 0; c < src.Values.Size(); c++) 31. if (src.Values[c].k_value == index) 32. return DoubleToString(src.Values[c].h_value, 2); 33. 34. return "-nan"; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 43. 44. st_Data info; 45. 46. Set(info, K, H); 47. PrintX(Get(info, 3)); 48. } 49. //+------------------------------------------------------------------+
Código 04
Muito bem, antes de começarmos a de fato explicar e a entrar nos detalhes do que este código 04 está fazendo. Preciso que você, meu caro leitor, entenda o seguinte: O que estamos vendo aqui, neste código 04 é somente uma das formas de se implementar algo, com um objetivo previamente definido.
De maneira alguma você deve encarar isto que será explicado, como sendo a única forma de se fazer as coisas. Pois existem outras formas, podendo ser mais simples ou mais complicadas. Sendo que uma delas envolve o uso de arrays multidimensionais. Isto tomando como base, o que já foi explicado e mostrado até este momento.
Mas existe uma forma ainda melhor de se fazer a mesma coisa. Porém isto será visto futuramente. Pois bem, dito isto, vamos entender o que este código 04 está fazendo. Para começar, vamos ver o resultado da execução. Isto pode ser observado na imagem logo abaixo.

Imagem 04
Hum, interessante este resultado, não é mesmo meu caro leitor? Isto por que, a princípio você pode estar pensando o seguinte: Quando a linha 47 é executada, estamos fazendo algo muito parecido com o que foi visto no código 01. No entanto, olhando a função Get, presente na linha 28 deste código 04, podemos perceber que o valor de index, está sendo procurado dentro do que seria o conjunto de elementos do array K.
Mas, e é este o ponto chave, e de real interesse aqui. Quando a linha 31 obtiver sucesso, não iremos retornar o índice do elemento, presente no array K, mas sim o valor no mesmo índice no array H. Com isto criamos a nossa ligação. Agora preste atenção no seguinte fato, aqui, como o número de elementos é pequeno, não precisamos nos preocupar com o tempo de execução do código.
Porém, em uma situação normal e real, esta estrutura, que está sendo criada na linha quatro, iria de fato ser ordenada de alguma maneira. Isto para que durante a pesquisa, que estamos fazendo na linha 28, o tempo de execução fosse o menor possível.
Então, com isto uma nova ideia começa a surgir. Como poderíamos criar um código mais próximo do que seria um código real? Bem, meu caro leitor, para isto precisamos fazer com que esta estrutura, venha a ter um contexto próprio. E é neste ponto que começa o que em ciência da computação é chamado de análise de dados.
Quando aplicamos análise de dados em nossos códigos, precisamos estruturar o mesmo de alguma forma. Sendo que não existe uma forma perfeita para todos os casos. Alguns casos irão exigir uma determinada maneira de implementar o código. Enquanto outros exigirão uma maneira bem diferente. Assim sendo, cada problema exige um nível de conhecimento adequado para se obter o melhor resultado, com o menor tempo de CPU.
Bem, neste momento, você já deve estar pensando: Então vamos começar a estudar análise de dados? Ainda não, meu caro leitor. Temos algumas outras coisas para serem vistas antes disto. Se bem, que poderíamos começar a fazer isto em breve. Mas, este não é o caso. O detalhe é: Tendo entendido que agora temos uma ligação entre o conjunto de elementos presentes no array K, com o conjunto de elementos presentes no array H. Podemos começar a pensar em uma forma, que seja a mais simples possível, de tornar a estrutura da linha quatro, em uma estrutura contextual. Onde, a própria estrutura, irá conter os mecanismos necessários para manter, gerir e garantir que esta ligação entre os elementos se mantenha adequadamente estabelecidas.
Para conseguir isto, vamos primeiro utilizar o próprio código 04, a fim de construir esta modelagem necessária. Ou seja, ainda não iremos generalizar o mecanismo. Isto a fim de que o compilador possa criar o que seria a sobrecarga de tipos. Para tornar as coisas realidade, o novo código já modificado é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. struct st_Reg 10. { 11. double h_value; 12. uint k_value; 13. }Values[]; 14. //+----------------+ 15. public: 16. //+----------------+ 17. bool Set(const uint &arg1[], const double &arg2[]) 18. { 19. if (arg1.Size() != arg2.Size()) 20. return false; 21. 22. ArrayResize(Values, arg1.Size()); 23. for (uint c = 0; c < arg1.Size(); c++) 24. { 25. Values[c].k_value = arg1[c]; 26. Values[c].h_value = arg2[c]; 27. } 28. 29. return true; 30. } 31. //+----------------+ 32. string Get(const uint index) 33. { 34. for (uint c = 0; c < Values.Size(); c++) 35. if (Values[c].k_value == index) 36. return DoubleToString(Values[c].h_value, 2); 37. 38. return "-nan"; 39. } 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. #define PrintX(X) Print(#X, " => ", X) 44. //+------------------------------------------------------------------+ 45. void OnStart(void) 46. { 47. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 48. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 49. 50. st_Data info; 51. 52. info.Set(K, H); 53. PrintX(info.Get(3)); 54. } 55. //+------------------------------------------------------------------+
Código 05
Agora preste atenção, meu caro leitor. Isto para que você não venha a perder o fio da meada. Quando este código 05 vier a ser executado. Iremos ver no terminal do MetaTrader 5, a mesma informação base vista na imagem 04. Porém com uma pequena diferença como pode ser observado logo abaixo.

Imagem 05
No entanto, diferente do que era o código 04, este código 05, já é um código construído de forma estrutural. No entanto, devido as declarações de tipo, feitas nas linhas 11 e 12, estamos presos a um tipo específico de dado que pode ser usado aqui. Mas suponhamos que você queira, ou necessite criar um sistema diferente. Onde ao invés de criar uma ligação de valores numéricos, você queira criar uma ligação de valores de texto. Basicamente strings no lugar de valores como estão sendo feitos no código 05. Como poderíamos fazer isto, mudando o mínimo possível o código 05?
Bem, é neste ponto em que a coisa fica confusa, se você estiver caindo de paraquedas neste artigo. Já que em artigos anteriores foi explicado alguns destalhes que não irei comentar novamente aqui. Porém, irei mostrar como você poderia generalizar a estrutura declarada na linha quatro a fim de que o compilador, venha a criar a sobrecarga necessária de tipo. Conseguindo desta maneira cobrir casos, que aparentemente não seria possível.
Para facilitar, vamos começar, generalizando apenas e somente um tipo base. No caso o tipo definido na linha 11. Assim o novo código pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. struct st_Reg 11. { 12. T h_value; 13. uint k_value; 14. }Values[]; 15. //+----------------+ 16. string ConvertToString(T arg) 17. { 18. if ((typename(T) == "double") || (typename(T) == "float")) return DoubleToString(arg, 2); 19. if (typename(T) == "string") return arg; 20. 21. return IntegerToString(arg); 22. } 23. //+----------------+ 24. public: 25. //+----------------+ 26. bool Set(const uint &arg1[], const T &arg2[]) 27. { 28. if (arg1.Size() != arg2.Size()) 29. return false; 30. 31. ArrayResize(Values, arg1.Size()); 32. for (uint c = 0; c < arg1.Size(); c++) 33. { 34. Values[c].k_value = arg1[c]; 35. Values[c].h_value = arg2[c]; 36. } 37. 38. return true; 39. } 40. //+----------------+ 41. string Get(const uint index) 42. { 43. for (uint c = 0; c < Values.Size(); c++) 44. if (Values[c].k_value == index) 45. return ConvertToString(Values[c].h_value); 46. 47. return "-nan"; 48. } 49. //+----------------+ 50. }; 51. //+------------------------------------------------------------------+ 52. #define PrintX(X) Print(#X, " => ", X) 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 57. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 58. 59. st_Data <double> info; 60. 61. info.Set(K, H); 62. PrintX(info.Get(3)); 63. } 64. //+------------------------------------------------------------------+
Código 06
Ok, agora a coisa realmente ficou divertida, com a construção deste código 06. Isto porque, neste código 06, podemos começar a generalizar a estrutura para que o compilador, possa fazer a sobrecarga quando for necessário. Com isto, poderemos trabalhar com tipos diferentes de dados, a fim de construir algum tipo de mecanismo de pesquisa. No entanto, quando você for tentar compilar este código 06, irá perceber que diferente dos códigos anteriores, aqui teremos um tipo de mensagem diferente.
Esta pode ser vista logo abaixo.

Imagem 06
Não sei se você se recorda, meu caro leitor, de que houve um momento em que mencionei, o fato de que, existem situações em que as mensagens do compilador podem ser ignoradas. E que em outros não podemos ignorar tais mensagens. Pois bem, este é um típico exemplo de um momento em que podemos ignorar o que o compilador está nos alertando. Isto porque, estas mensagens só existem pelo fato de que o compilador, NÃO CONSEGUIU entender o que estamos fazendo nas linhas 19 e 21. E que estas linhas somente serão executadas em casos muito específicos. Assim como a própria linha 18. Existe uma forma de evitar que estas mensagens sejam disparadas. Mas irei mostrar isto em outro momento. Muito provavelmente no próximo artigo. Já que estamos chegando ao final deste artigo daqui.
Ok, então como agora estamos generalizando um dos valores, precisamos dizer ao compilador que tipo de informação estará sendo utilizada. Isto para que ele consiga criar o código adequado, para aquele tipo de dado que estaremos utilizando. Para fazer isto, usamos a linha 59 a fim de declarar a variável que irá nos dar acesso a estrutura. Agora devido ao fato de que, o tipo base declarado na linha 56 é do tipo double. Precisamos usar um tipo compatível, ou idêntico, na declaração da linha 59. Caso contrário, teremos problemas quando formos pesquisar na estrutura de dados.
Mas como assim? Não entendi está parte. Até consigo entender o motivo da declaração da linha 59. Isto por conta justamente da declaração feita na estrutura. Porém, não entendi, por que preciso declarar um tipo adequado, com o tipo usando na linha 56. Se estamos criando algo genérico? Para mim isto não faz muito sentido.
Bem meu caro leitor, como isto é um pouco complicado de explicar. Vou dedicar o restante do artigo a explicar este motivo. Ficando assim uma boa parte da explicação para ser dada no próximo artigo.
Quero que você observe o fato de que começamos o artigo usando um código muito parecido como o que é visto em código 06. No entanto, quando isto foi feito, o resultado de certa maneira era previamente conhecido. Já que não estávamos preocupados em converter ou retornar o tipo adequado de dado.
Agora pense no seguinte fato. No código 01, o tipo de dado que seria retornado, iria depender do tipo de dado armazenado. Porém, e é aqui onde a coisa muda de figura. Neste código 06, iremos sempre ter um tipo de dado que será retornado a nós. Isto independentemente do tipo de dado armazenado. No caso, estaremos armazenando dados do tipo double. Entretanto, o retorno SEMPRE será do tipo string.
O simples fato de isto estar sendo feito, acaba por assim dizer, confundindo o próprio sistema. Já que a conversão não seria esperada, pelo programador que estiver utilizando a estrutura que estamos definindo. Mas você pode pensar: Como assim? Claro que ele irá saber. Isto nem sempre é verdade, meu caro leitor, visto que podemos criar bibliotecas de código, e as utilizar em diversos momentos. E quando falo de biblioteca de código, não estou me referindo a questão de você acumular um monte de códigos fonte.
Tais bibliotecas, normalmente são formadas por código executável. Tipo o que acontece com as famosas DLLs. Nelas não sabemos exatamente como o código interno funciona. Apenas temos uma noção disto, já que passamos valores a DLL e ela nos retorna um resultado. Saber o tipo de dado que estamos repassando a estrutura é importante, já que pode ser que venhamos a precisar converter eles no tipo original. Visto que o retorno, neste caso sempre será uma string.
Certo. Mas será que não podemos deixar as coisas de forma totalmente generalizada? Isto é, ao invés de converter os dados para o tipo string, se os mantivermos no seu tipo original. Não teríamos este tipo de problema mencionado a pouco. Estou certo? Sim, você está certo quanto a isto meu amigo leitor. Porém lembre-se de que aqui, o objetivo é ser didático. E não o de produzir um código que possa ser utilizado na prática, em uma situação real.
Porém, todavia e, entretanto, como quero lhe dar a oportunidade de parar por uns instantes, e de pensar sobre certas coisas. Para isto, vamos modificar o código 06, de modo que apenas o fragmento mostrado abaixo, venha a ser mudado no código visto acima. E pelo simples fato de isto ter sido feito, temos uma situação completamente diferente sendo desenhada e implementada aqui. Veja abaixo o fragmento que foi modificado.
. . . 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const string T = "possible loss of data due to type conversion"; 57. const uint K[] = {2, 1, 4, 0, 7, 5, 3, 6}; 58. 59. st_Data <string> info; 60. string H[]; 61. 62. StringSplit(T, ' ', H); 63. info.Set(K, H); 64. PrintX(info.Get(3)); 65. } 66. //+------------------------------------------------------------------+
Código 07
E não precisa se preocupar, no anexo, você terá acesso a estes códigos, na íntegra. Isto para que você possa experimentar e praticar, cada detalhe que está sendo mostrado aqui. De qualquer forma, quero que você pare e pense sobre o que estamos fazendo aqui, ao mudarmos o código 06 para este fragmento mostrado no código 07. Já que o simples fato de termos mudado o tipo de informação que estará na estrutura, nos permitirá construir coisas aparentemente pouco prováveis, ou que muitos considerariam difíceis de serem feitas.
Uma dica para lhe ajudar a pensar a respeito do que está sendo feito. Dependendo da forma como a informação venha a ser criada e colocada na variável da linha 60, neste código 07. Podemos criar o que seria um código capaz de ser executado em qualquer idioma. Desde é claro venhamos a implementar e colocar de maneira adequada as informações na variável da linha 60.
Procure pensar em como isto poderia ser feito, e como isto afetaria toda uma geração de futuros códigos que você possa vir a construir.
Considerações finais
Este artigo, que ao meu entender é um artigo onde exploramos de maneira mais profunda certas bases da programação. Vimos como podemos começar a implementar o que seria uma base de código genérico. Isto a fim de reduzir nosso trabalho em programar as coisas e fazer um melhor uso dos potenciais oferecidos pela própria linguagem de programação. No caso o MQL5. O que estou mostrando, ou tentando explicar aqui, é algo que demorei um bom tempo para compreender.
Porém, isto foi devido ao fato de que as coisas estavam sendo criadas enquanto eu as estava estudando. Hoje, vemos praticamente todos disserem que programação orientada em objetos é o máximo. E sim, ela realmente é muito boa e util. Mas porquê? De nada adianta você ver um código de uma classe, usar ou até mesmo conseguir modificar aquele código. Sem ao menos entender por que aquilo funciona. E para entender, e aprender de verdade, é preciso primeiro entender como as linguagens de programação chegaram naquele nível. Por que a programação orientada em objetos foi criada. E por que ela é usada de forma tão extensiva.
Entender isto, será algo que você somente conseguirá fazer, praticando e experimentado. Isto ao usar códigos, que tem princípios somente comentados em programação orientada em objetos. Porém que de fato, não estão sendo criados como os métodos e possibilidades que somente a programação orientada em objetos nos proporciona. De fato, tais princípios, nasceram no que hoje, quase ninguém fala ou comenta. Que é justamente a programação estrutural. Que é justamente o tema que estamos começando a explorar aqui.
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso