
Redes neurais em trading: Segmentação guiada (Conclusão)

Introdução
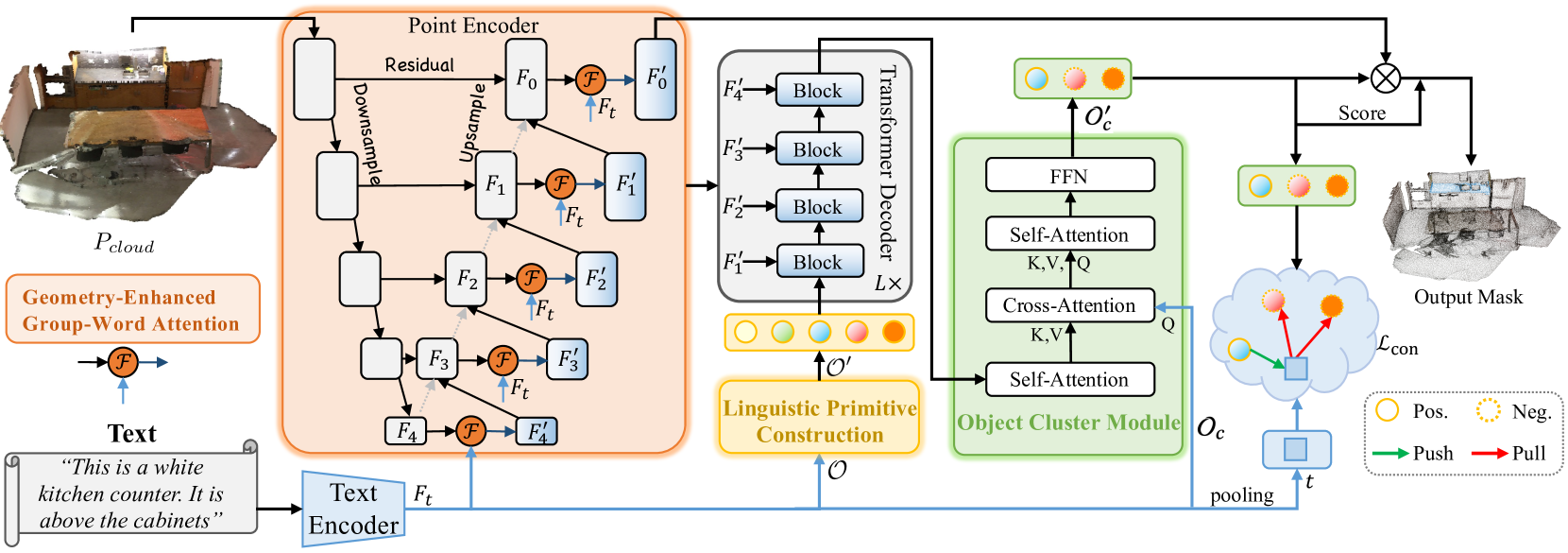
No artigo anterior, apresentamos o método RefMask3D, criado para análise detalhada da interação multimodal e compreensão das características da nuvem de pontos analisada. RefMask3D é um framework completo, que inclui diversos módulos:
- Um codificador de pontos com módulo embutido Geometry-Enhanced Group-Word Attention. Nele, é realizada atenção cruzada entre a descrição do objeto em linguagem natural e grupos locais de pontos (subnuvens) em cada etapa de codificação das características. A arquitetura do bloco proposta pelos autores do método reduz o impacto do ruído típico da correlação direta entre pontos e palavras, transformando as relações geométricas internas em uma estrutura refinada da nuvem de pontos. Isso melhora significativamente a capacidade do modelo de interagir com dados linguísticos e geométricos.
- O modelo linguístico converte a descrição textual recebida do objeto-alvo em uma estrutura de tokens que o modelo utiliza para identificá-lo.
- Um conjunto de primitivas linguísticas treináveis (Linguistic Primitives Construction — LPC) é usado para representar diversos atributos semânticos, como forma, cor, tamanho, relações, localização etc. Ao interagir com determinada informação linguística, essas primitivas adquirem os atributos correspondentes.
- O decodificador com arquitetura Transformer aumenta o foco do modelo sobre a variedade semântica da nuvem de pontos, melhorando bastante a capacidade de localizar e identificar o objeto-alvo com precisão.
- O módulo de agrupamento de objetos (Object Cluster Module — OCM) é responsável por reunir informações completas e gerar as incorporações dos objetos.
No artigo anterior, concluímos uma parte significativa da implementação do framework proposto. Especificamente, implementamos os algoritmos dos módulos Geometry-Enhanced Group-Word Attention e Linguistic Primitives Construction em suas respectivas classes. Também discutimos que a funcionalidade do Decodificador pode ser atendida por meio de implementações existentes de diferentes variações de blocos de atenção cruzada. A construção dos algoritmos do módulo de agrupamento de objetos foi o ponto em que paramos. É a partir desse ponto que daremos continuidade ao trabalho.
1. Implementação do módulo de agrupamento de objetos
Como mencionado anteriormente, o módulo de agrupamento de objetos tem a função de reunir informações completas e gerar incorporações dos objetos. A visualização original do módulo é mostrada abaixo.
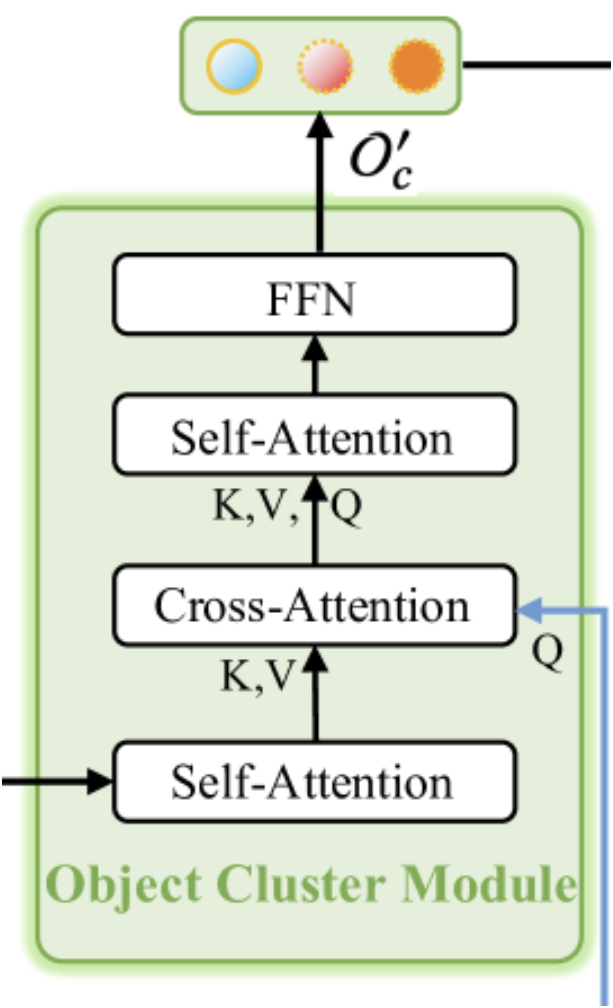
Como pode ser observado na visualização apresentada, o módulo de agrupamento de objetos é composto por dois blocos Self-Attention, um bloco de Cross-Attention entre eles e um bloco FFN na saída, que é um MLP totalmente conectado. Essa arquitetura pode evocar diferentes associações. Por um lado, ela lembra um decodificador Transformer "vanilla" com um bloco extra de Self-Attention após o Cross-Attention. No entanto, é importante notar a funcionalidade modificada do bloco de atenção cruzada. E isso nos remete ao método SPFormer. Nessa interpretação, o primeiro bloco Self-Attention desempenha a função de extração de características dos pontos.
Ainda assim, na solução arquitetônica apresentada, pode-se ver uma versão miniaturizada do Transformer "vanilla". Aqui temos uma cópia "reduzida" do codificador, sem o bloco FeedForward, e um decodificador com os blocos Cross-Attention e Self-Attention trocados de lugar. Isso, sem dúvida, torna esse módulo complexo e importante dentro do framework geral RefMask3D, como demonstrado pelos experimentos realizados pelos autores do método. A introdução do módulo de agrupamento de objetos permite aumentar a eficiência do modelo em 1,57%.
O módulo de agrupamento de objetos recebe dados de 2 fontes. Primeiro, os resultados do Decodificador, que são as incorporações dos primitivos enriquecidas com informações da nuvem de pontos analisada, passam pelo primeiro bloco Self-Attention e servem como contexto para o bloco de atenção cruzada que vem a seguir. A principal fonte de informação para o bloco de atenção cruzada são as incorporações da descrição textual do objeto-alvo. É com base nelas que são formadas as entidades Query do bloco de atenção cruzada. Em seguida, os resultados do bloco Cross-Attention são enviados para o segundo Self-Attention e para o FeedForward.
O algoritmo descrito acima será implementado na classe CNeuronOCM, cuja estrutura é apresentada a seguir.
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); //--- virtual uint GetPrimitiveWindow(void) const { return iPrimWindow; } virtual uint GetContextWindow(void) const { return iContWindow; } };
A funcionalidade básica da camada neural será herdada da classe totalmente conectada CNeuronBaseOCL, que utilizaremos como classe base.
Na estrutura apresentada acima, podemos ver um conjunto de métodos sobrescrevíveis já conhecidos, além de uma série de objetos e variáveis internas declarados. Exploraremos suas funcionalidades ao longo da implementação dos métodos da classe. Por ora, vale destacar que todos os objetos internos foram declarados como estáticos. Isso significa que podemos deixar o construtor e o destrutor da classe em branco. A inicialização de todos os objetos internos declarados e herdados é feita no método Init. Como você já sabe, os parâmetros desse método contêm um conjunto de constantes que nos permite interpretar de forma inequívoca a arquitetura do objeto que estamos criando.
bool CNeuronOCM::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, cont_window * cont_units, optimization_type, batch)) return false;
No corpo do método, como de costume, chamamos o método com o mesmo nome da classe base, onde já estão implementados os algoritmos de controle mínimo necessário dos parâmetros recebidos, assim como a inicialização dos objetos herdados. A execução das operações do método da classe base é controlada com base no valor lógico retornado.
Após a execução bem-sucedida das operações do método da classe base, salvamos os valores das constantes recebidas nas variáveis internas da nossa classe.
iPrimWindow = prim_window; iPrimUnits = prim_units; iPrimHeads = prim_heads; iContWindow = cont_window; iContUnits = cont_units; iContHeads = cont_heads; iWindowKey = window_key;
E limpamos os arrays dinâmicos dos objetos internos.
cQuery.Clear(); cKey.Clear(); cValue.Clear(); cMHAttentionOut.Clear(); cAttentionOut.Clear(); cResidual.Clear(); cFeedForward.Clear();
Em seguida, passamos à inicialização dos blocos internos. Conforme o algoritmo descrito anteriormente, o primeiro é o bloco Self-Attention para análise de dependências entre os primitivos.
Aqui, vale lembrar que, na entrada do módulo, recebemos primitivos enriquecidos com informações sobre a nuvem de pontos analisada, provenientes do Decodificador. Portanto, a função deste bloco é identificar os primitivos relevantes para a nuvem de pontos em questão.
Primeiro, criamos os objetos geradores das entidades Query, Key e Value. Para gerar todas essas entidades, usamos camadas convolucionais com parâmetros idênticos. Os ponteiros para os objetos inicializados são adicionados aos arrays dinâmicos, nomeados de forma correspondente às entidades geradas.
CNeuronBaseOCL *neuron = NULL; CNeuronConvOCL *conv = NULL; //--- Primitives Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 0, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 1, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 2, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Depois, adicionamos uma camada totalmente conectada para registrar os resultados da atenção multicanais.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, iPrimHeads * iWindowKey * iPrimUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
E usamos uma camada convolucional para redimensionar os resultados da atenção multicanais ao tamanho do tensor dos dados de entrada.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 4, OpenCL, iPrimHeads * iWindowKey, iPrimHeads * iWindowKey, iPrimWindow, iPrimUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
Por fim, o bloco Self-Attention se encerra com uma camada totalmente conectada de conexões residuais.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
É fácil perceber que a estrutura apresentada acima dos objetos do bloco de atenção é universal. Ela pode ser usada tanto para o bloco Self-Attention quanto para o Cross-Attention. Creio que está claro que, para implementar o algoritmo do próximo bloco Cross-Attention, criaremos objetos idênticos e adicionaremos os ponteiros aos mesmos arrays dinâmicos. A única diferença está nas fontes de dados para a formação das entidades Query, Key e Value. Ao formar a entidade Query, utilizamos a informação de contexto como dados de entrada.
//--- Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 6, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false;
Enquanto as entidades Key e Value são formadas a partir dos resultados do bloco anterior Self-Attention. Aqui temos um tensor com dimensão idêntica à dos primitivos treináveis.
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 7, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 8, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Em seguida, adicionamos a camada de resultados da atenção multicanais.
//--- Multi-Heads Cross-Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 9, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Adicionamos a camada convolucional de redimensionamento.
//--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 10, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
E o bloco Cross-Attention se encerra com a camada de conexões residuais.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 11, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Na próxima etapa, criamos mais um bloco Self-Attention. Desta vez, para análise de dependências contextuais. Novamente repetimos a criação de objetos equivalentes do bloco de atenção, adicionando os ponteiros dos objetos criados nos mesmos arrays dinâmicos. Mas agora todas as entidades são formadas com base nos resultados do bloco de atenção cruzada. Portanto, o tensor de entrada tem as dimensões do contexto analisado.
//--- Context Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 12, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 13, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 14, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Adicionamos a camada de resultados da atenção multicanais.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 15, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Logo após, vem a camada convolucional de redimensionamento.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 16, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
E para finalizar o bloco, assim como antes, usamos uma camada de conexões residuais.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 17, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Agora nos resta adicionar os objetos do bloco FeedForward. De forma análoga ao Transformer "vanilla", usamos aqui duas camadas convolucionais com a função de ativação LReLU entre elas.
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 18, OpenCL, iContWindow, iContWindow, 4 * iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false; conv.SetActivationFunction(LReLU); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 19, OpenCL, 4*iContWindow, 4*iContWindow, iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false;
Como camada de conexão residual neste caso, vamos usar buffers da nossa classe, herdados da classe base. Contudo, faremos uma substituição dos ponteiros para os buffers de gradientes de erro com o objetivo de reduzir operações de cópia de dados.
if(!SetGradient(conv.getGradient())) return false; //--- SetOpenCL(OpenCL); //--- return true; }
E ao final do método, retornaremos um valor lógico indicando o sucesso das operações à função chamadora.
Vale notar que não criamos objetos de buffers de dados para armazenar os coeficientes de atenção. Esses buffers só serão criados no contexto do OpenCL. E sua criação está separada em um método à parte chamado CreateBuffers, que convido você a analisar por conta própria no anexo.
Após finalizarmos o método de inicialização do objeto, passamos à construção dos algoritmos de propagação para frente. Esses algoritmos são implementados no método feedForward. E aqui vale destacar que nos afastamos um pouco do formato usual dos métodos de propagação direta usados anteriormente. Se nos trabalhos anteriores utilizávamos um ponteiro para o objeto da camada neural como primeira fonte de dados e um ponteiro para o buffer de dados como segunda, neste caso estamos usando objetos da camada neural em ambos os casos. No entanto, nesta etapa, essa implementação é possível apenas para os objetos internos usados na construção dos algoritmos do objeto de camada neural superior. E isso nos atende perfeitamente.
bool CNeuronOCM::feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context) { CNeuronBaseOCL *neuron = NULL, *q = cQuery[0], *k = cKey[0], *v = cValue[0];
No corpo do método, criaremos algumas variáveis locais para armazenar temporariamente ponteiros para objetos das camadas neurais. Em seguida, já atribuímos a elas os ponteiros dos objetos de formação de entidades para o primeiro bloco de atenção. Depois, verificamos a validade dos ponteiros para os objetos e geramos as entidades necessárias a partir do tensor de primitivos recebido do programa externo.
if(!q || !k || !v) return false; if(!q.FeedForward(Primitives) || !k.FeedForward(Primitives) || !v.FeedForward(Primitives) ) return false;
As entidades geradas são então passadas ao bloco de atenção multicanais para análise das dependências.
if(!AttentionOut(q, k, v, cScores[0], cMHAttentionOut[0], iPrimUnits, iPrimHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Os resultados obtidos são redimensionados e somados com os dados de entrada correspondentes. Após isso, normalizamos os resultados.
neuron = cAttentionOut[0]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[0]) ) return false; v = cResidual[0]; if(!v || !SumAndNormilize(Primitives.getOutput(), neuron.getOutput(), v.getOutput(), iPrimWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
Na entrada do primeiro bloco Self-Attention, alimentamos com primitivos enriquecidos com informações sobre a nuvem de pontos analisada. E, dentro do bloco, adicionamos dependências internas. Com isso, queremos destacar de forma contrastante os primitivos relevantes à cena analisada. De fato, essa etapa pode ser comparada à tarefa de segmentação da nuvem de pontos. Mas, neste caso, nosso objetivo é encontrar o objeto-alvo descrito em uma expressão textual. Por isso, avançamos para a próxima etapa de atenção cruzada. Nela, comparamos as incorporações da descrição do objeto-alvo com os primitivos presentes na nuvem de pontos analisada. Para isso, utilizamos em nossos arrays os objetos de camada neural responsáveis pela formação das entidades de atenção cruzada. Verificamos a validade dos ponteiros obtidos. E geramos as entidades necessárias.
//--- Cross-Attention q = cQuery[1]; k = cKey[1]; v = cValue[1]; if(!q || !k || !v) return false; if(!q.FeedForward(Context) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
Lembrando que Query é gerado a partir das incorporações da descrição do objeto-alvo. Já os dados de entrada para gerar Key e Value são os resultados do bloco anterior Self-Attention. Em seguida, aplicamos o mecanismo de atenção multicanais.
if(!AttentionOut(q, k, v, cScores[1], cMHAttentionOut[1], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Depois, redimensionamos os resultados obtidos e os complementamos com conexões residuais.
neuron = cAttentionOut[1]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[1]) ) return false; v = cResidual[1]; if(!v || !SumAndNormilize(Context.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
É importante destacar que usamos o tensor do contexto original como conexão residual. Os resultados da soma entre os dois tensores são normalizados elemento por elemento dentro da sequência.
Na saída do bloco Cross-Attention, esperamos obter incorporações da descrição do objeto-alvo enriquecidas com informações da nuvem de pontos analisada. Em outras palavras, queremos "realçar" as incorporações da descrição do objeto-alvo que são relevantes para a cena em questão.
Observe que, nesse ponto, ainda não realizamos um mapeamento direto entre a nuvem de pontos analisada e a descrição do objeto-alvo. Contudo, nas etapas anteriores do framework RefMask3D, realizamos a identificação de primitivos na nuvem de pontos original. E no bloco de atenção cruzada, extraímos da descrição do objeto-alvo os primitivos encontrados nessa nuvem de pontos. Em seguida, vamos compor o "quadro completo", enriquecendo essas incorporações selecionadas com conexões mútuas no próximo bloco Self-Attention.
Assim como antes, extraímos dos arrays dinâmicos internos os próximos layers de formação de entidades e verificamos a validade dos ponteiros obtidos.
//--- Context Self-Attention q = cQuery[2]; k = cKey[2]; v = cValue[2]; if(!q || !k || !v) return false;
Depois disso, geramos as entidades Query, Key e Value. Neste caso, os dados de entrada para a geração de todas as entidades são os resultados do bloco anterior de atenção cruzada.
if(!q.FeedForward(neuron) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
Também utilizamos o algoritmo de atenção multicanais para detectar interdependências na sequência de dados analisada.
if(!AttentionOut(q, k, v, cScores[2], cMHAttentionOut[2], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Os resultados obtidos são redimensionados e somados com as conexões residuais, seguidos pela normalização dos dados.
q = cAttentionOut[1]; if(!q || !q.FeedForward(cMHAttentionOut[2]) ) return false; v = cResidual[2]; if(!v || !SumAndNormilize(q.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
Em seguida, passamos pelo bloco FeedForward o tensor do contexto enriquecido. Aos resultados obtidos, adicionamos as conexões residuais e normalizamos os dados. Os valores resultantes são gravados no buffer de resultados da nossa classe CNeuronOCM. Este objeto foi herdado da classe base.
//--- Feed Forward q = cFeedForward[0]; k = cFeedForward[1]; if(!q || !k || !q.FeedForward(neuron) || !k.FeedForward(q) || !SumAndNormilize(neuron.getOutput(), k.getOutput(), Output, iContWindow, true, 0, 0, 0, 1) ) return false; //--- return true; }
Ao finalizar a execução do método de propagação para frente, resta apenas retornar à função chamadora o resultado lógico das operações realizadas.
Após concluir a construção dos métodos de propagação para frente, passamos à organização dos processos de propagação reversa. Como de costume, dividimos a funcionalidade da propagação reversa em duas etapas: distribuição dos gradientes de erro entre todos os elementos de acordo com sua influência no resultado geral do modelo e otimização dos parâmetros treináveis. Para cada etapa, construiremos seu respectivo método: calcInputGradients e updateInputWeights. O primeiro inverte completamente as operações da propagação para frente. No segundo, apenas chamamos sequencialmente os métodos de mesmo nome dos objetos internos que contêm parâmetros treináveis. Recomendo que você consulte diretamente os algoritmos desses métodos. O código completo desta classe e de todos os seus métodos está disponível no anexo.
2. Construção do framework RefMask3D
Realizamos um extenso trabalho de implementação dos módulos individuais do framework RefMask3D e agora precisamos reunir tudo em um único objeto, integrando os blocos individuais em uma estrutura bem organizada. Para essa tarefa, criaremos uma nova classe CNeuronRefMask, cuja estrutura é apresentada a seguir.
class CNeuronRefMask : public CNeuronBaseOCL { protected: CNeuronGEGWA cGEGWA; CLayer cContentEncoder; CLayer cBackGround; CNeuronLPC cLPC; CLayer cDecoder; CNeuronOCM cOCM; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronRefMask(void) {}; ~CNeuronRefMask(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRefMask; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Na estrutura acima apresentada, é fácil identificar os objetos dos módulos que implementamos. Mas, junto a eles, também estão presentes objetos de arrays dinâmicos, cuja funcionalidade será explorada durante a implementação dos métodos da nova classe.
Todos os objetos internos foram declarados como estáticos, o que nos permite manter o construtor e o destrutor da classe "vazios". Já a inicialização de todos os objetos declarados e herdados é feita no método Init.
Como você sabe, nos parâmetros desse método recebemos constantes que permitem identificar de forma inequívoca a arquitetura do objeto sendo criado. No entanto, a presença de muitos objetos internos complexos leva a uma forte variabilidade na arquitetura do objeto. Como consequência, isso aumenta a quantidade de parâmetros necessários para descrever essas configurações arquitetônicas. Na minha visão, o excesso de parâmetros apenas torna mais difícil trabalhar com a classe. Por isso, foi tomada a decisão de unificar os parâmetros dos objetos internos, o que permitiu reduzir significativamente o número de parâmetros externos. A ideia é manter, nos parâmetros do método de inicialização, apenas as constantes que definem os dados de entrada e os resultados. E, sempre que possível, reutilizar esses mesmos parâmetros para os objetos internos. Por exemplo, o tamanho da janela de um elemento da sequência é especificado apenas para os dados de entrada. No entanto, esse mesmo parâmetro será utilizado tanto na geração das incorporações dos primitivos treináveis quanto como dimensão da incorporação do contexto. Assim, para construir os tensores de primitivos e de contexto, basta indicar os respectivos tamanhos das sequências.
bool CNeuronRefMask::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * content_units, optimization_type, batch)) return false;
Como de costume, a primeira operação dentro do método é chamar o método de mesmo nome da classe base, onde já está implementado o controle mínimo necessário sobre os parâmetros recebidos e a inicialização dos objetos herdados. Após isso, seguimos com a inicialização dos objetos declarados. E, aqui, começamos inicializando o codificador da nuvem de pontos, representado pelo módulo Geometry-Enhanced Group-Word Attention que criamos anteriormente.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.Init(0, 0, OpenCL, window, window_key, heads, units_count, window, heads, (content_units + 3), 2, layers, optimization, iBatch)) return false; cGEGWA.AddNeckGradient(true);
É importante observar dois pontos aqui. Primeiro, ao indicar o tamanho da sequência de contexto, adicionamos 3 elementos ao tamanho da incorporação da descrição do objeto-alvo. Naturalmente, como nas implementações anteriores, não utilizaremos uma descrição textual explícita do objeto-alvo. Em vez disso, geraremos alguns tokens a partir do vetor de descrição do estado atual da conta e das posições abertas. Essa escolha segue a mesma lógica usada antes: a criação de vários tokens diferentes descrevendo o mesmo estado da conta nos permite realizar uma análise abrangente da situação atual do mercado. Contudo, não descartamos a presença de ruído e valores atípicos nos dados de entrada. Para mitigar sua influência, adicionamos 3 tokens treináveis adicionais para absorver os valores irrelevantes. Essencialmente, trata-se do token de “fundo” proposto pelos autores do framework RefMask3D.
O segundo ponto é que, no nosso codificador de pontos, usamos blocos de atenção com duas camadas em todas as etapas. E o parâmetro dos layers internos layers, recebido do programa externo, indica o número de incorporações da "garganta" do nosso U-formado módulo.
Além disso, ativamos a funcionalidade de somar os gradientes de erro para os objetos da "garganta".
A seguir, temos o codificador de contexto. Para esse módulo, não criamos um bloco separado. Ainda assim, você já está familiarizado com sua arquitetura. Ela reproduz integralmente o codificador da expressão refinadora do método 3D-GRES. Primeiro, criamos uma camada totalmente conectada para registrar o vetor de descrição do estado atual da conta.
//--- Content Encoder cContentEncoder.Clear(); cContentEncoder.SetOpenCL(OpenCL); CNeuronBaseOCL *neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * content_units, 1, OpenCL, content_size, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Em seguida, adicionamos uma camada totalmente conectada para gerar a quantidade definida de incorporações no tamanho exigido.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 2, OpenCL, window * content_units, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Neste ponto, incluímos ainda outra camada, onde registramos o tensor concatenado do contexto com os tokens "de fundo".
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, window * (content_units + 3), optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
O próximo passo é criar o modelo de geração do tensor de tokens de fundo treináveis. Aqui também usamos um MLP com duas camadas. A primeira camada é estática e contém o valor "1". A segunda gera o tensor no tamanho necessário com base em parâmetros treináveis.
//--- Background cBackGround.Clear(); cBackGround.SetOpenCL(OpenCL); neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * 3, 4, OpenCL, content_size, optimization, iBatch) || !cBackGround.Add(neuron) ) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, window * 3, optimization, iBatch) || !cBackGround.Add(neuron) ) return false;
Depois, adicionamos o módulo de primitivos linguísticos.
//--- Linguistic Primitive Construction if(!cLPC.Init(0, 6, OpenCL, window, window_key, heads, heads, primitive_units, content_units, 2, 1, optimization, iBatch)) return false;
E, na sequência, vem o decodificador. Aqui, fizemos um pequeno desvio da estrutura proposta pelos autores do método, substituindo as camadas do decodificador Transformer "vanilla" pelos objetos do módulo de agrupamento de objetos que criamos anteriormente. Já discutimos acima as semelhanças e diferenças na arquitetura desses módulos. E esperamos que essa abordagem permita aumentar um pouco mais a eficiência do modelo que estamos construindo.
Também vale ressaltar que, conforme a estrutura proposta pelos autores do framework RefMask3D, cada camada do decodificador realiza a análise de dependências com uma camada específica do codificador de pontos em forma de U. Para implementar essa abordagem, criamos um laço que extrai sequencialmente os objetos correspondentes.
//--- Decoder cDecoder.Clear(); cDecoder.SetOpenCL(OpenCL); CNeuronOCM *ocm = new CNeuronOCM(); if(!ocm || !ocm.Init(0, 7, OpenCL, window, window_key, units_count, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; for(uint i = 0; i < layers; i++) { neuron = cGEGWA.GetInsideLayer(i); ocm = new CNeuronOCM(); if(!ocm || !neuron || !ocm.Init(0, i + 8, OpenCL, window, window_key, neuron.Neurons() / window, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; }
Agora, nos resta inicializar o módulo de agrupamento de objetos.
//--- Object Cluster Module if(!cOCM.Init(0, layers + 8, OpenCL, window, window_key, primitive_units, heads, window, content_units, heads, optimization, iBatch)) return false;
E faremos a substituição dos ponteiros dos buffers de dados, o que nos permitirá reduzir a quantidade de operações de cópia de valores.
if(!SetOutput(cOCM.getOutput()) || !SetGradient(cOCM.getGradient()) ) return false; //--- return true; }
Por fim, no encerramento do método, retornamos à função chamadora o resultado lógico da execução das operações. Com isso, concluímos a construção do método de inicialização do objeto da classe e passamos à organização dos algoritmos de propagação para frente, que implementaremos no método feedForward. Nos parâmetros desse método, recebemos ponteiros para dois objetos de dados de entrada. O primeiro é um ponteiro para um objeto da camada neural, e o segundo é um buffer de dados. Esse é o esquema para o qual temos interfaces organizadas dentro do nosso modelo base.
bool CNeuronRefMask::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
No corpo do método, verificamos a validade do ponteiro recebido como segunda fonte de dados de entrada e, se necessário, fazemos a substituição do ponteiro para o buffer de resultados na primeira camada do codificador de contexto.
//--- Context Encoder CNeuronBaseOCL *context = cContentEncoder[0]; if(context.getOutput() != SecondInput) { if(!context.SetOutput(SecondInput, true)) return false; }
Em seguida, geramos a incorporação (embedding) do contexto com base nos dados fornecidos.
int content_total = cContentEncoder.Total(); for(int i = 1; i < content_total - 1; i++) { context = cContentEncoder[i]; if(!context || !context.FeedForward(cContentEncoder[i - 1]) ) return false; }
Vale destacar que as operações de propagação para frente começam justamente pela geração da incorporação do contexto. Afinal, o codificador de pontos utiliza essa informação como segunda fonte de dados de entrada.
Depois, geramos o tensor dos tokens de fundo.
//--- Background Encoder CNeuronBaseOCL *background = NULL; if(bTrain) { for(int i = 1; i < cBackGround.Total(); i++) { background = cBackGround[i]; if(!background || !background.FeedForward(cBackGround[i - 1]) ) return false; } } else { background = cBackGround[cBackGround.Total() - 1]; if(!background) return false; }
E o concatenamos com o tensor de incorporação do contexto.
CNeuronBaseOCL *neuron = cContentEncoder[content_total - 1]; if(!neuron || !Concat(context.getOutput(), background.getOutput(), neuron.getOutput(), context.Neurons(), background.Neurons(), 1)) return false;
O tensor concatenado, junto com o ponteiro da primeira fonte de dados de entrada fornecido pelo programa externo, é então passado para o nosso codificador de pontos.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.FeedForward(NeuronOCL, neuron.getOutput())) return false;
Além disso, a incorporação do contexto também é passada ao módulo de geração de primitivos linguísticos. Mas, nesse caso, utilizamos o tensor sem os tokens de fundo.
//--- Linguistic Primitive Construction if(!cLPC.FeedForward(context)) return false;
É importante notar que os tokens de fundo são usados exclusivamente no codificador de pontos, com a finalidade de filtrar ruído e valores atípicos.
Neste ponto, já formamos os tensores das incorporações dos primitivos linguísticos e da nuvem de pontos original. O próximo passo é associá-los em nosso decodificador, que nos ajudará a identificar os primitivos linguísticos presentes na cena analisada. Primeiro, associamos os resultados do codificador de pontos com os nossos primitivos.
//--- Decoder CNeuronOCM *decoder = cDecoder[0]; if(!decoder.feedForward(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
Depois, enriquecemos as incorporações dos primitivos linguísticos com os resultados intermediários do codificador de pontos. Para isso, criamos um laço no qual extraímos sequencialmente as camadas subsequentes do decodificador e os respectivos objetos do codificador de pontos, realizando a associação dos dados.
for(int i = 1; i < cDecoder.Total(); i++) { decoder = cDecoder[i]; if(!decoder.feedForward(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; }
Os resultados do decodificador são passados pelo módulo de agrupamento de objetos.
//--- Object Cluster Module if(!cOCM.feedForward(decoder, context)) return false; //--- return true; }
Por fim, encerramos o método de propagação para frente, retornando à função chamadora o resultado lógico da execução das operações.
É importante dizer que o algoritmo implementado não é uma cópia integral do framework original RefMask3D. No algoritmo dos autores, há ainda uma multiplicação dos resultados do codificador de pontos pela saída do módulo de agrupamento de objetos, com a adição de uma "cabeça" para determinar a probabilidade de associação de cada ponto a um determinado objeto. E o motivo dessa “redução” no algoritmo está nas diferenças entre os objetivos das tarefas. Não temos a necessidade de destacar visualmente objetos individuais na cena analisada. Para tomarmos decisões sobre a execução de operações de trading, basta termos conhecimento da presença dos padrões buscados e seus parâmetros. Por isso, optamos por implementar o framework proposto nesta forma. E os resultados do seu funcionamento serão analisados pelo modelo do Ator.
Seguimos adiante. Após a implementação dos algoritmos de propagação para frente, passamos à construção dos métodos responsáveis pelos processos de propagação reversa. E, neste caso, vale fazer algumas observações sobre o método de distribuição dos gradientes de erro calcInputGradients. Como sempre, nele invertemos completamente as operações realizadas durante a propagação para frente. Mas é importante destacar que, no processo da propagação direta, geramos uma série de entidades que exercem influência fundamental sobre a eficácia do modelo. Entre elas, podemos citar os primitivos treináveis, as incorporações do contexto e os tokens de fundo. Naturalmente, queremos gerar a maior diversidade possível dessas entidades, com o objetivo de cobrir o máximo possível do espaço da cena observada da situação de mercado. E, embora já tenhamos implementado essa funcionalidade no módulo de geração de primitivos linguísticos, ainda precisamos criá-la para as demais entidades. Por isso, proponho que dediquemos alguns minutos à análise do algoritmo utilizado para construir o método de distribuição do gradiente de erro.
bool CNeuronRefMask::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!NeuronOCL || !SecondGradient) return false;
Nos parâmetros do método, recebemos ponteiros para 3 objetos: uma camada neural e dois buffers de dados. Como você sabe, o objeto da camada neural contém os buffers dos resultados e dos gradientes de erro da primeira fonte. Já para a segunda fonte de dados, recebemos buffers separados com os dados originais e os respectivos gradientes de erro. Também está presente aqui um ponteiro para a função de ativação aplicada à segunda fonte de dados.
No corpo do método, começamos verificando a validade dos ponteiros recebidos para a primeira fonte de dados e para o gradiente de erro da segunda. A ausência de um ponteiro válido para o buffer de dados da segunda fonte não é um problema crítico, pois o ponteiro validado foi armazenado durante a execução da propagação direta.
Em seguida, se necessário, realizamos a substituição do buffer de gradientes de erro no nosso objeto interno correspondente à segunda fonte de dados.
CNeuronBaseOCL *neuron = cContentEncoder[0]; if(!neuron) return false; if(neuron.getGradient() != SecondGradient) { if(!neuron.SetGradient(SecondGradient)) return false; neuron.SetActivationFunction(SecondActivation); }
Com isso, encerramos a etapa preparatória e passamos às operações efetivas de distribuição do gradiente de erro.
Graças à substituição de ponteiros dos buffers de dados, realizada durante a inicialização do objeto, o gradiente de erro vindo da camada seguinte é gravado diretamente no buffer do módulo de agrupamento de objetos. Assim, eliminamos operações desnecessárias de cópia de dados e iniciamos a distribuição do gradiente de erro diretamente pelo objeto OCM.
//--- Object Cluster Module CNeuronBaseOCL *context = cContentEncoder[cContentEncoder.Total() - 2]; if(!cOCM.calcInputGradients(cDecoder[cDecoder.Total() - 1], context)) return false;
É importante observar que, neste caso, transmitimos o gradiente ao último layer do decodificador e ao penúltimo layer do codificador de contexto. Isso porque o último layer do codificador de contexto contém o tensor concatenado da incorporação do contexto com os tokens de fundo, e esse tensor só é utilizado no codificador de pontos.
Na etapa seguinte, propagamos o gradiente de erro através do decodificador. Para isso, criamos um laço reverso que percorre os layers do decodificador.
//--- Decoder CNeuronOCM *decoder = NULL; for(int i = cDecoder.Total() - 1; i > 0; i--) { decoder = cDecoder[i]; if(!decoder.calcInputGradients(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; } decoder = cDecoder[0]; if(!decoder.calcInputGradients(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
Vale lembrar que, durante a distribuição do gradiente de erro, também o transmitimos para as camadas internas do codificador de pontos. Foi justamente para armazenar esses valores que implementamos anteriormente o algoritmo de soma dos gradientes de erro nos objetos da "garganta".
A segunda fonte de dados do decodificador é o módulo de geração de primitivos LPC. O gradiente de erro recebido por esse módulo será propagado até o módulo interno de geração de primitivos e até a incorporação do contexto sem os tokens de fundo. No entanto, esse último buffer já contém dados de operações anteriores. Por isso, substituímos temporariamente o ponteiro do buffer de gradientes da incorporação do contexto por um buffer não utilizado, herdado da classe base. Só então chamamos o método de distribuição do gradiente de erro do módulo LPC. Em seguida, somamos os valores dos dois buffers de dados.
//--- Linguistic Primitive Construction CBufferFloat *context_grad = context.getGradient(); if(!context.SetGradient(PrevOutput, false)) return false; if(!cLPC.FeedForward(context) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) ) return false;
Depois disso, propagamos o gradiente de erro através do codificador de pontos. E agora, distribuímos o gradiente entre a primeira fonte de dados de entrada e a incorporação do contexto com os tokens de fundo.
//--- Geometry-Enhaced Group-Word Attention neuron = cContentEncoder[cContentEncoder.Total() - 1]; if(!neuron || !NeuronOCL.calcHiddenGradients((CObject*)GetPointer(cGEGWA), neuron.getOutput(), neuron.getGradient(), (ENUM_ACTIVATION)neuron.Activation())) return false;
Aqui, é fundamental observar que precisamos realizar uma diversificação conjunta dos tokens de contexto e dos de fundo. Afinal, não é difícil perceber que esses dois tipos de token pertencem ao mesmo subespaço. Além disso, mais do que diversificar, também é necessário estabelecer uma diferenciação clara entre essas entidades. Por isso, primeiro adicionamos o erro de diversificação ao tensor concatenado de contexto e fundo.
if(!DiversityLoss(neuron, cOCM.GetContextWindow(), neuron.Neurons() / cOCM.GetContextWindow(), true)) return false; CNeuronBaseOCL *background = cBackGround[cBackGround.Total() - 1]; if(!background || !DeConcat(context.getGradient(), background.getGradient(), neuron.getGradient(), context.Neurons(), background.Neurons(), 1) || !DeActivation(context.getOutput(), context.getGradient(), context.getGradient(), context.Activation()) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) || !context.SetGradient(context_grad, false) ) return false;
Depois, distribuímos o gradiente de erro obtido entre os buffers correspondentes a essas entidades. Corrigimos o gradiente do contexto com a derivada da função de ativação e somamos os valores ao que já havia sido acumulado. Em seguida, restauramos o ponteiro para o buffer de dados correspondente. A partir daqui, podemos propagar o gradiente de erro até o nível da segunda fonte de dados.
//--- Context Encoder for(int i = cContentEncoder.Total() - 3; i >= 0; i--) { context = cContentEncoder[i]; if(!context || !context.calcHiddenGradients(cContentEncoder[i + 1]) ) return false; }
Lembrando que o ponteiro para o buffer de gradientes de erro já foi armazenado no objeto correspondente da camada neural interna. Portanto, a operação de cópia entre buffers de dados torna-se desnecessária.
Neste ponto, já distribuímos o gradiente de erro para ambas as fontes de dados de entrada e para praticamente todos os objetos internos. "Praticamente" porque ainda nos resta propagá-lo através do modelo de geração dos tokens de fundo. Ajustamos o gradiente de erro obtido anteriormente com a derivada da função de ativação e geramos um laço reverso para percorrer as camadas do MLP.
//--- Background if(!DeActivation(background.getOutput(), background.getGradient(), background.getGradient(), background.Activation())) return false; for(int i = cBackGround.Total() - 2; i > 0; i--) { background = cBackGround[i]; if(!background || !background.calcHiddenGradients(cBackGround[i + 1]) ) return false; } //--- return true; }
E, ao final do método de distribuição do gradiente de erro, retornamos à função chamadora o resultado lógico da execução das operações.
Com isso, encerramos a análise dos algoritmos de implementação do framework RefMask3D. O código completo de todas as classes apresentadas e seus respectivos métodos está disponível no anexo. Lá também você encontrará a arquitetura dos modelos treináveis e de todos os programas utilizados na elaboração deste artigo.
Na arquitetura dos modelos treináveis, realizamos apenas pequenas modificações pontuais, consistindo na alteração de uma camada do Codificador da descrição do estado do ambiente. Já os programas de interação com o ambiente e de treinamento dos modelos foram reaproveitados dos trabalhos anteriores, sem nenhuma alteração. Por esse motivo, não nos deteremos na análise desses programas, e passamos diretamente à parte final do nosso artigo — o treinamento dos modelos e a avaliação dos resultados.
3. Testes
Como mencionado anteriormente, as alterações realizadas na arquitetura dos modelos não afetaram a estrutura dos dados de entrada e de saída. Sendo assim, para o treinamento inicial dos modelos, pudemos utilizar a mesma base de dados de treinamento já reunida anteriormente. Vale lembrar que usamos dados históricos reais do ativo EURUSD ao longo de todo o ano de 2023, no timeframe H1. Os parâmetros de todos os indicadores analisados foram mantidos com seus valores padrão.
O treinamento dos modelos é realizado offline. No entanto, para manter a base de dados de treinamento atualizada, realizamos atualizações periódicas da amostra de treinamento, adicionando interações com base na política atual do Ator. As iterações entre treinamento dos modelos e atualização da base de dados são repetidas até que se atinja o desempenho desejado.
Durante a preparação deste artigo, obtivemos uma política bastante interessante do Ator. Os resultados de seu teste com dados históricos de janeiro de 2024 são apresentados abaixo.
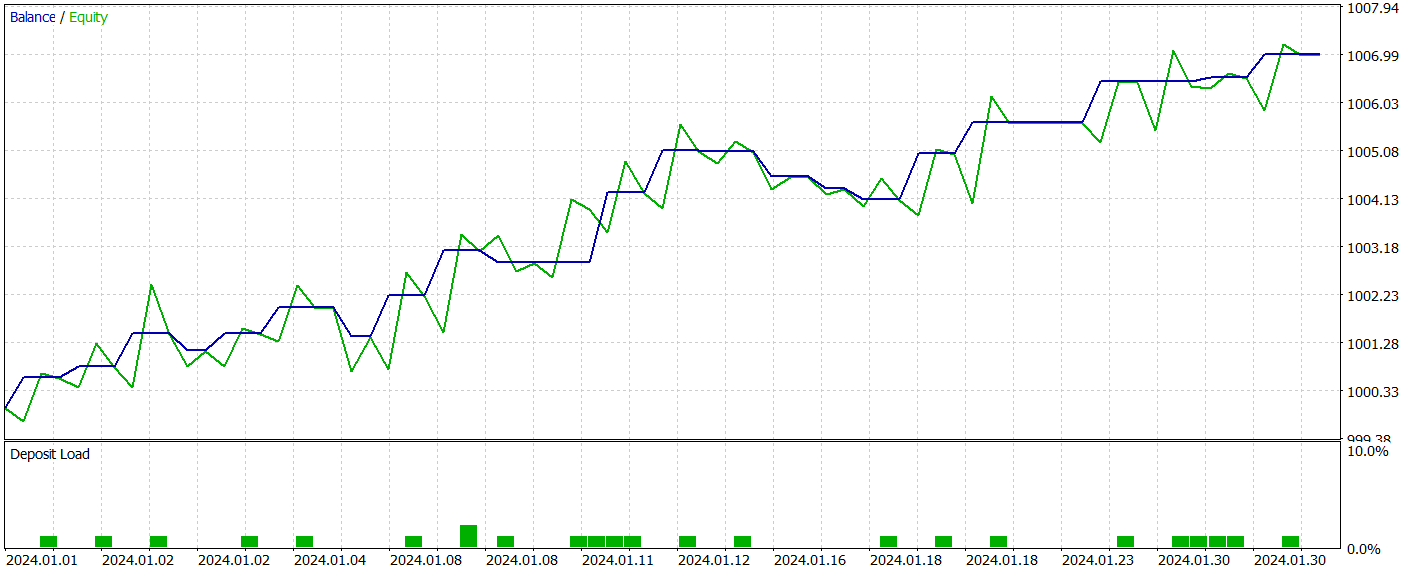

Percebe-se facilmente que o período de teste não faz parte da base de dados utilizada no treinamento. Essa abordagem de teste cria condições muito próximas do uso real do modelo.
Durante o período de teste, o modelo realizou 21 operações de trading, das quais 14 foram encerradas com lucro, o que representa mais de 66%. Vale destacar que a proporção de operações lucrativas supera a de perdas, tanto nas posições vendidas quanto nas compradas. Além disso, o lucro médio por operação vencedora foi duas vezes maior do que a perda média por operação perdedora. Um resultado similar é observado no caso da maior operação lucrativa, cuja rentabilidade se aproxima de três vezes o valor da maior operação com prejuízo. Ao mesmo tempo, o gráfico de balanço apresenta uma tendência claramente positiva.
Claro, a quantidade reduzida de operações de trading realizadas não permite tirar conclusões definitivas sobre a eficácia do modelo em uma perspectiva de longo prazo. Ainda assim, a abordagem proposta demonstra claramente ter potencial e merece ser investigada mais a fundo.
Considerações finais
Ao longo dos dois últimos artigos, realizamos um extenso trabalho de implementação dos métodos propostos pelos autores do RefMask3D utilizando os recursos da linguagem MQL5. É verdade que a versão apresentada difere um pouco do framework original. No entanto, os resultados obtidos demonstram o potencial da abordagem adotada.
Contudo, chamo sua atenção para o fato de que todos os programas apresentados neste artigo têm caráter demonstrativo e não estão prontos para uso em condições reais de mercado.
#Referências
#Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento dos Modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Código-fonte da biblioteca OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16057
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Olá, Dmitry. Recebi esse erro durante o treinamento:
O que isso significa?
A propósito, ao compilar, esses dois avisos aparecem:
Os arquivos do artigo não foram alterados.
Excelente artigo. Vou fazer o download e tentar usá-lo neste fim de semana. Há duas coisas que o relatório de backtest não mostra: o par de moedas usado e o período de tempo. Você poderia fornecer essas informações ou fazer referência a um artigo anterior que as tenha identificado? Acabei de encontrar as respostas. É EURUSD e H1
Viktor, tive o mesmo erro de memorando sobre o comportamento obsoleto. No meu caso, eu estava desenvolvendo uma classe e, inadvertidamente, chamei uma função visível que não tinha um parâmetro, mas a classe continha os parâmetros corretos. Adicionar o parâmetro resolveu meu problema. O programa foi executado corretamente usando o comportamento obsoleto, e é por isso que é um erro de memorando.