
取引におけるニューラルネットワーク:制御されたセグメンテーション(最終部)

はじめに
前回の記事では、点群データに対するマルチモーダルな相互作用を包括的に解析し、その特徴を理解するために設計されたRefMask3D法について紹介しました。RefMask3Dは、以下の複数のモジュールで構成された総合的なフレームワークです。
- Geometry-Enhanced Group-Word Attentionモジュールを統合した点エンコーダ(point encoder):このモジュールでは、特徴量エンコーディングの各段階において、オブジェクトの自然言語による記述と局所的な点群グループ(部分点群)との間でクロスモーダルアテンションを実行します。著者らが提案したブロック構造により、点と単語の直接的な相関に起因するノイズの影響が軽減され、内部の幾何学的関係が洗練された点群構造に変換されます。これにより、モデルの言語情報と幾何情報の両方に対する処理能力が大幅に向上します。
- 言語モデル:ターゲットオブジェクトに関するテキスト記述を、モデルが識別処理に使用するトークン構造へと変換します。
- 言語プリミティブ構築(LPC: Linguistic Primitives Construction):形状、色、サイズ、関係、位置などの意味的属性を表現するために設計された、学習可能な言語プリミティブのセットです。特定の言語入力と連携することで、これらのプリミティブはそれぞれ対応する属性を獲得します。
- Transformerベースのデコーダ:点群内の多様な意味情報に対する注目度を強化し、ターゲットオブジェクトをより正確に特定・識別する能力を高めます。
- オブジェクトクラスタモジュール(OCM: Object Cluster Module):点群全体から統合的な情報を収集し、オブジェクトの埋め込み表現を生成します。
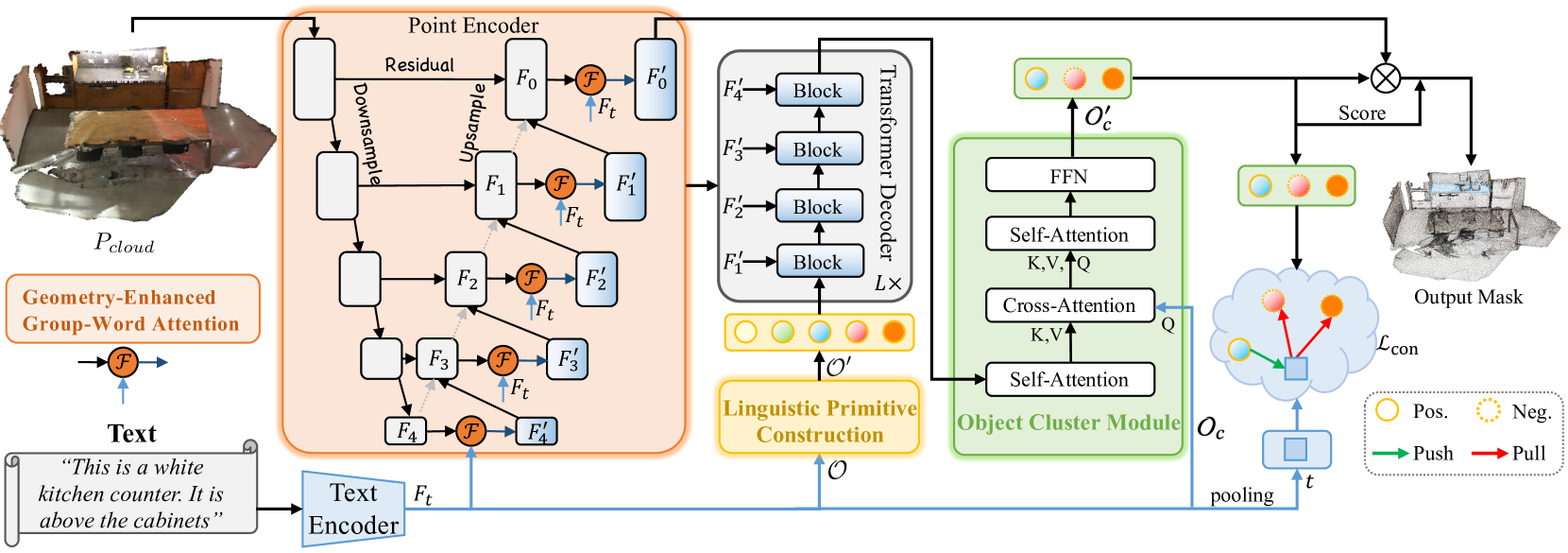
前回の記事では、フレームワークの実装の大部分がすでに完了していました。具体的には、それぞれのクラス内に、Geometry-Enhanced Group-Word Attentionモジュールと言語プリミティブ構築モジュールを実装しました。また、デコーダ機能については、既存のクロスアテンションブロックの実装を活用することで対応可能であることも確認しました。前回は、オブジェクトクラスタモジュールのアルゴリズム開発に取り組んでいるところで終了しました。今回は、そこから作業を再開していきます。
1. オブジェクトクラスタモジュールの実装
前述のように、オブジェクトクラスタモジュールは、点群全体から包括的な情報を集約し、オブジェクトの埋め込み表現を生成するように設計されています。本モジュールのオリジナルの可視化図を以下に示します。
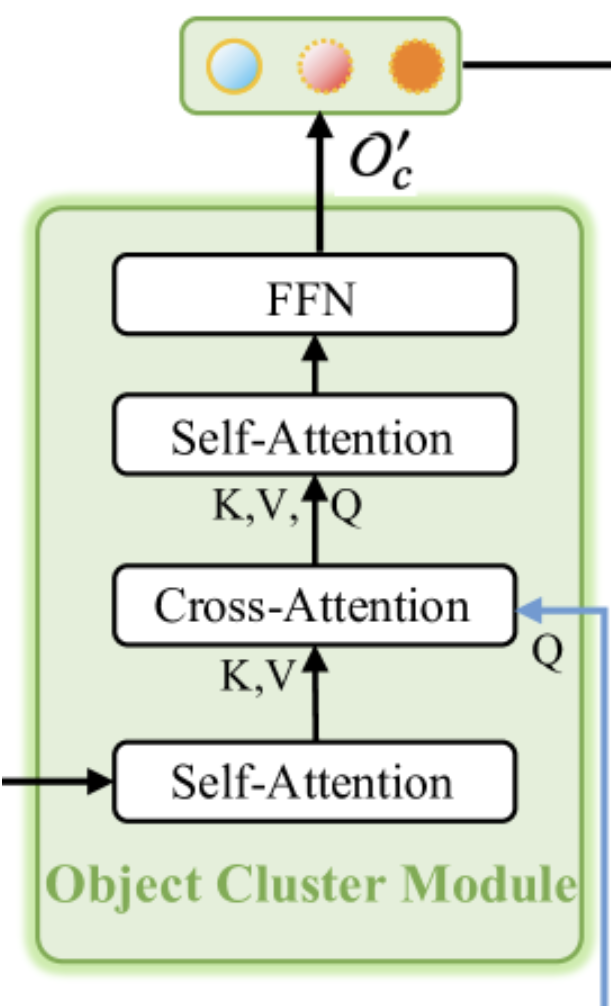
可視化からわかるように、オブジェクトクラスタモジュールは、2つの自己アテンションブロック、それらの間に配置された1つのクロスアテンションブロック、および出力部にあるFFNブロック(完全接続MLPとして実装)で構成されています。このアーキテクチャは、いくつかの異なる解釈を呼び起こすかもしれません。一方では、クロスアテンションの後に自己アテンションブロックを追加した通常のTransformerデコーダのようにも見えます。ただし、本モジュールにおけるクロスアテンションブロックの機能が変更されている点には注意が必要です。この文脈では、SPFormer法が連想されます。このような解釈においては、最初の自己アテンションブロックは点群表現の特徴量抽出モジュールとして機能していると捉えられます。
とはいえ、本モジュールのアーキテクチャは、FeedForwardブロックを省略したエンコーダと、クロスアテンションブロックと自己アテンションブロックを再構成したデコーダで構成される、バニラTransformerのコンパクト版とも見ることができます。この構造により、本モジュールはRefMask3Dフレームワーク全体における高度で不可欠な構成要素となっており、著者らの実験結果によってその重要性が確認されています。オブジェクトクラスタモジュールを組み込むことで、モデルの性能は1.57%向上します。
このモジュールは2つの入力を受け取ります。まず、点群に関する情報が付加されたプリミティブ埋め込みを含むデコーダ出力が、最初の自己アテンションブロックを通過し、続くクロスアテンションブロックに対するコンテキストとして機能します。一方で、クロスアテンションブロックの主要な情報源は、ターゲットオブジェクトのテキスト記述の埋め込みです。これらの埋め込みは、クロスアテンションブロックのQueryコンポーネントを構成するために使用されます。クロスアテンションブロックの出力は、2番目の自己アテンションとFeedForwardに入力されます。
上記のアルゴリズムはCNeuronOCMクラスに実装されており、その構造の概要は以下のとおりです。
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); //--- virtual uint GetPrimitiveWindow(void) const { return iPrimWindow; } virtual uint GetContextWindow(void) const { return iContWindow; } };
ニューラル層のコア機能は、親クラスとして使用される全結合のCNeuronBaseOCLから継承されます。
これまでに示した新しいクラスの構造には、よく知られたオーバーライドメソッドのセットに加え、いくつかの内部オブジェクトや変数の宣言が確認できます。これらの機能については、メソッドの実装過程で詳しく見ていくことにします。現時点で重要なのは、すべての内部オブジェクトが静的として宣言されているという点です。これにより、クラスのコンストラクタおよびデストラクタは空のままにしておくことができます。これらの宣言済みおよび継承された内部オブジェクトの初期化は、Initメソッド内でおこなわれます。ご存知のとおり、このメソッドのパラメータでは、構築されるオブジェクトのアーキテクチャを一意に解釈できる定数のセットを受け取ります。
bool CNeuronOCM::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, cont_window * cont_units, optimization_type, batch)) return false;
メソッド本体では、まず親クラスの同名メソッドを呼び出します。このメソッドには、受け取ったパラメータの最低限の検証や、継承されたオブジェクトの初期化のアルゴリズムが既に実装されています。親メソッドの実行が成功したかどうかは、返されるブール値を確認して判断します。
親クラスのメソッドが正常に実行された後、受け取った定数の値をクラス内の内部変数に格納します。
iPrimWindow = prim_window; iPrimUnits = prim_units; iPrimHeads = prim_heads; iContWindow = cont_window; iContUnits = cont_units; iContHeads = cont_heads; iWindowKey = window_key;
次に、内部オブジェクトに関連付けられた動的配列をクリアします。
cQuery.Clear(); cKey.Clear(); cValue.Clear(); cMHAttentionOut.Clear(); cAttentionOut.Clear(); cResidual.Clear(); cFeedForward.Clear();
次に、内部ブロックの構成要素の初期化に進みます。前述のアルゴリズムによると、最初に初期化されるのは、プリミティブ間の依存関係を解析する役割を持つ自己アテンションブロックです。
ここで、このモジュールへの入力が、デコーダ内で解析された点群に関する情報で強化されたプリミティブで構成されていることを改めて思い出してください。したがって、この自己アテンションブロックの役割は、与えられた点群に関連するプリミティブを特定することにあります。
まず、Query、Key、Valueの生成用オブジェクトを作成します。これら3つのエンティティの生成には、同一のパラメータを持つ畳み込み層を用います。初期化された各オブジェクトへのポインタは、それぞれの生成対象に対応した名前の動的配列に格納されます。
CNeuronBaseOCL *neuron = NULL; CNeuronConvOCL *conv = NULL; //--- Primitives Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 0, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 1, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 2, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
次に、マルチヘッドアテンションの出力を記録するための全結合層を追加します。
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, iPrimHeads * iWindowKey * iPrimUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
畳み込み層を使用して、マルチヘッドアテンションの結果を元のデータテンソルのサイズにスケーリングします。
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 4, OpenCL, iPrimHeads * iWindowKey, iPrimHeads * iWindowKey, iPrimWindow, iPrimUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
自己アテンションブロックの最後には、全結合の残差接続層があります。
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
上記で示したアテンションブロックのオブジェクト構造は汎用的であり、自己アテンションブロックとクロスアテンションブロックの両方に使用できます。したがって、次に実装するクロスアテンションブロックのアルゴリズムでも同様のオブジェクトを作成し、それらのポインタを同じ動的配列に追加します。唯一の違いは、Query、Key、Valueエンティティを生成する際のデータソースにあります。Queryエンティティの生成時には、コンテキスト情報を入力として使用します。
//--- Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 6, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false;
KeyとValueエンティティを生成するには、前の自己アテンションブロックからの出力を使用します。ここでは、学習可能なプリミティブと同じテンソルサイズがあります。
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 7, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 8, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
次に、マルチヘッドアテンション結果の層を追加します。
//--- Multi-Heads Cross-Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 9, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
畳み込みスケーリング層も追加します。
//--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 10, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
クロスアテンションブロックは、残差接続層によって完了します。
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 11, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
次のステップでは、コンテキストの依存関係を解析するための追加の自己アテンションブロックを作成します。再び、対応するアテンション関連オブジェクトを作成し、これら新たに生成したオブジェクトへのポインタを、先に使った動的配列に追加します。ただし今回は、すべてのエンティティがクロスアテンションブロックの出力に基づいて生成されるため、入力テンソルの次元は解析対象のコンテキストに対応したものとなります。
//--- Context Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 12, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 13, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 14, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
マルチヘッドアテンションの結果の層を追加します。
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 15, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
これに畳み込みスケーリング層が続きます。
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 16, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
最後は、やはり残差接続層です。
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 17, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
次に、FeedForwardブロックオブジェクトを追加する必要があります。バニラTransformerと同様に、このブロックでは2つの畳み込み層を使用し、その間にLReLU活性化関数を挟んでいます。
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 18, OpenCL, iContWindow, iContWindow, 4 * iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false; conv.SetActivationFunction(LReLU); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 19, OpenCL, 4*iContWindow, 4*iContWindow, iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false;
この場合、親クラスから継承したクラスバッファを残差接続層として使用します。ただし、データのコピー操作を削減するために、誤差の勾配バッファへのポインタの置換を整理します。
if(!SetGradient(conv.getGradient())) return false; //--- SetOpenCL(OpenCL); //--- return true; }
メソッドの最後で、操作の成功を示すブール値を呼び出し元のプログラムに返します。
重要な点として、アテンション係数を格納するためのデータバッファオブジェクトは作成していません。これらのバッファはOpenCLコンテキスト内でのみインスタンス化されます。その作成は別のメソッドCreateBuffersに移されているため、添付ファイルで確認することをお勧めします。
オブジェクトの初期化メソッドを完了した後、順方向パスのアルゴリズム実装に進みます。これらはfeedForwardメソッドで定義されています。ここで、従来の実装で用いていたフォワードパスの構造から少し逸脱している点に注目してください。通常はニューラル層オブジェクトへのポインタを主要な入力として渡し、データバッファへのポインタを二次的な入力として渡しますが、本ケースでは両方ともニューラル層オブジェクトを使用します。ただし、現段階ではこの実装は、高レベルニューラル層オブジェクトのアルゴリズム構築に用いられる内部コンポーネントに限って適用されており、現時点の目的には問題ありません。
bool CNeuronOCM::feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context) { CNeuronBaseOCL *neuron = NULL, *q = cQuery[0], *k = cKey[0], *v = cValue[0];
メソッドの本体では、まずいくつかのローカル変数を宣言し、ニューラル層オブジェクトへのポインタを一時的に格納します。これらの変数には直ちに、最初のアテンションブロック用のエンティティ生成コンポーネントへのポインタが代入されます。次に、ポインタの有効性を検証し、外部プログラムから受け取ったプリミティブのテンソルから必要なエンティティを生成します。
if(!q || !k || !v) return false; if(!q.FeedForward(Primitives) || !k.FeedForward(Primitives) || !v.FeedForward(Primitives) ) return false;
得られたエンティティをマルチヘッドアテンションブロックに渡し、依存関係の解析をおこないます。
if(!AttentionOut(q, k, v, cScores[0], cMHAttentionOut[0], iPrimUnits, iPrimHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
得られた結果にスケーリングをおこない、対応する入力データと加算します。その後、結果を正規化します。
neuron = cAttentionOut[0]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[0]) ) return false; v = cResidual[0]; if(!v || !SumAndNormilize(Primitives.getOutput(), neuron.getOutput(), v.getOutput(), iPrimWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
最初の自己アテンションブロックへの入力として、分析対象の点群に関する情報が付加されたプリミティブを与えました。このブロック内でさらに内部依存関係を導入しました。その目的は、解析中のシーンに最も関連するプリミティブを際立たせることにあります。実質的に、この段階は点群に対するセグメンテーション処理に相当します。ただし、本ケースではテキストで記述されたターゲットオブジェクトを特定することが目的です。そこで、次の段階であるクロスアテンションへ進みます。ここでは、ターゲットオブジェクトのテキスト記述の埋め込みを、分析された点群のプリミティブと対応付けます。そのために、オブジェクト配列からクロスアテンション用のエンティティを生成するニューラル層を取得し、ポインタの有効性を確認した上で、必要なエンティティを生成します。
//--- Cross-Attention q = cQuery[1]; k = cKey[1]; v = cValue[1]; if(!q || !k || !v) return false; if(!q.FeedForward(Context) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
念のためご説明すると、Queryエンティティはターゲットオブジェクトのテキスト記述の埋め込みから生成されます。一方、KeyおよびValueエンティティは、前段の自己アテンションブロックの出力から生成されます。次に、マルチヘッドアテンションの仕組みを用います。
if(!AttentionOut(q, k, v, cScores[1], cMHAttentionOut[1], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
次に、得られた結果のスケーリングをおこない、残差接続で補完します。
neuron = cAttentionOut[1]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[1]) ) return false; v = cResidual[1]; if(!v || !SumAndNormilize(Context.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
残差接続として元のコンテキストテンソルを使用している点に注意が必要です。2つのテンソルを足し合わせた結果は、各シーケンス要素ごとに正規化されます。
クロスアテンションブロックの出力としては、分析された点群の情報によって強化されたターゲットオブジェクトの説明の埋め込みが得られることが期待されます。つまり、分析対象のシーンに関連性の高いターゲットオブジェクトの説明の埋め込みを「強調」することが目的です。
なお、この段階で分析された点群とターゲットオブジェクトの説明の直接比較はおこないません。しかし、RefMask3Dフレームワークの前段階で、元の点群からプリミティブはすでに抽出済みです。クロスアテンションブロックでは、ターゲットオブジェクトの説明に含まれるプリミティブのうち、点群に存在するものを特定します。その後、続く自己アテンションブロックにおける相互作用を通じて、選択された埋め込みをより充実させ、一貫した情報表現を構築します。
前回と同様に、内部の動的配列から次のエンティティ生成層を取得し、取得したポインタの有効性を確認します。
//--- Context Self-Attention q = cQuery[2]; k = cKey[2]; v = cValue[2]; if(!q || !k || !v) return false;
その後、Query、Key、Valueエンティティを生成します。この場合、すべてのエンティティを生成するための入力データは、前のクロスアテンションブロックの出力です。
if(!q.FeedForward(neuron) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
また、分析対象のデータシーケンス内の相互依存関係を検出するために、マルチヘッドアテンションアルゴリズムを使用します。
if(!AttentionOut(q, k, v, cScores[2], cMHAttentionOut[2], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
得られた結果にスケーリングをおこない、残差接続を加えた後、データを正規化します。
q = cAttentionOut[1]; if(!q || !q.FeedForward(cMHAttentionOut[2]) ) return false; v = cResidual[2]; if(!v || !SumAndNormilize(q.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
そして、強化されたコンテキストテンソルをFeedForwardブロックに通します。得られた結果に残差接続を加え、データを正規化します。最終的な値は、親クラスから継承したCNeuronOCMクラスの結果バッファに書き込みます。
//--- Feed Forward q = cFeedForward[0]; k = cFeedForward[1]; if(!q || !k || !q.FeedForward(neuron) || !k.FeedForward(q) || !SumAndNormilize(neuron.getOutput(), k.getOutput(), Output, iContWindow, true, 0, 0, 0, 1) ) return false; //--- return true; }
フィードフォワードパスメソッドの最後では、処理結果を示すブール値を呼び出し元プログラムに返すだけです。
フィードフォワードパスの実装が完了したら、次にバックプロパゲーションパスの処理を整理します。通常どおり、バックワードパスの処理は2段階に分かれます。1つ目は、誤差の勾配を各構成要素へ、その寄与度に応じて分配する処理、2つ目は、学習可能なパラメータの最適化です。この2つの処理に対応して、それぞれ専用のメソッドを実装します。前者にはcalcInputGradients、後者にはupdateInputWeightsを使用します。calcInputGradientsメソッドでは、フィードフォワードパスで実行された操作を逆方向にたどる処理をおこないます。一方、updateInputWeightsメソッドでは、学習可能なパラメータを保持する内部オブジェクトに対して、同名のメソッドを順に呼び出していくだけです。これらの各メソッドの詳細なアルゴリズムについては、ぜひご自身で確認してみてください。このクラスとそのすべてのメソッドの完全なコードは添付ファイルに含まれています。
2. RefMask3Dフレームワークの構築
RefMask3Dフレームワークの各モジュールの実装作業が一通り完了したので、次はいよいよそれらを統合し、全体を一貫したアーキテクチャとしてまとめ上げる段階に入ります。この作業をおこなうために、新たにCNeuronRefMaskというクラスを作成します。その構造は以下の通りです。
class CNeuronRefMask : public CNeuronBaseOCL { protected: CNeuronGEGWA cGEGWA; CLayer cContentEncoder; CLayer cBackGround; CNeuronLPC cLPC; CLayer cDecoder; CNeuronOCM cOCM; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronRefMask(void) {}; ~CNeuronRefMask(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRefMask; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
上記の構造を見ると、これまでに実装してきたモジュールを容易に識別できます。それらに加えて、新たに登場するのが動的配列オブジェクトです。これらの機能については、新クラスのメソッド実装フェーズで詳しく見ていきます。
すべてのオブジェクトは静的に宣言されているため、クラスのコンストラクタとデストラクタは「空」のままで問題ありません。これらの宣言済みおよび継承されたオブジェクトの初期化は、Initメソッド内でおこなわれます。
ご存じのとおり、このメソッドのパラメータには、生成対象のオブジェクト構造を明確に特定するための定数が含まれます。しかし、内部オブジェクトの数や構成が複雑であるため、アーキテクチャのバリエーションが非常に多くなります。これにより、記述すべきパラメータも増加しがちです。ただし、パラメータ数が多すぎるとクラスの使用が煩雑になるため、私たちは内部オブジェクトのパラメータを統一し、外部からの入力数を大幅に削減する方針を取りました。つまり、初期化メソッドには、入力および出力データのパラメータを定義するための定数のみを残すことにします。内部オブジェクトは、可能な限り外部から与えられたデータパラメータを再利用します。たとえば、1つのシーケンス要素に対するウィンドウサイズは入力データにのみ指定されますが、この値は学習可能なプリミティブの埋め込み生成や、コンテキストの埋め込みサイズとしても使い回されます。したがって、プリミティブおよびコンテキストのシーケンス長を定義するだけで、必要なテンソル構築には十分です。
bool CNeuronRefMask::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * content_units, optimization_type, batch)) return false;
メソッド内で最初におこなう操作は、これまでと同様、親クラスに定義された同名のメソッドを呼び出すことです。この親クラスメソッドには、受け取ったパラメータに対する最低限の検証処理や、継承されたオブジェクトの初期化ロジックがすでに含まれています。その処理が完了した後、宣言済みオブジェクトの初期化に進みます。まず最初に初期化するのは、点エンコーダです。これには、以前に実装したモジュール「Geometry-Enhanced Group-Word Attention」を使用します。
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.Init(0, 0, OpenCL, window, window_key, heads, units_count, window, heads, (content_units + 3), 2, layers, optimization, iBatch)) return false; cGEGWA.AddNeckGradient(true);
次の2点に注意してください。まず、コンテキストのシーケンス長を指定する際には、ターゲットオブジェクトの記述に対応する埋め込みサイズに3つの要素を追加しています。これは、以前の実装と同様、ターゲットオブジェクトに関するテキストによる説明を直接使用せず、現在の口座状態およびポジションを表すベクトルから複数のトークンを生成するというアプローチに基づいています。この理由は明確です。1つの口座状態ベクトルから複数の異なるトークンを生成することで、市況をより包括的に把握することが可能になるためです。しかしながら、この入力データにはノイズや外れ値が含まれている可能性があることも考慮しなければなりません。そこで、そうした無関係な情報を吸収するために、学習可能な3つの追加トークンを導入します。これは、RefMask3Dフレームワークの論文で提案されている「背景(background)」トークンのアイデアに基づいています。
私たちの点エンコーダでは、各ステージにおいて2層のアテンションブロックを用いています。また、外部プログラムから渡されるlayersパラメータは、U字型モジュールの「ネック部分」に含まれる埋め込み層の数を指定しています。
さらに、ネックモジュールに対して勾配の合算機能を有効化しています。
続いてコンテキストエンコーダに進みます。このモジュールに対しては個別のクラスは定義していませんが、既にご存じのとおり、そのアーキテクチャは3D-GRES法において表現を精緻化するエンコーダと完全に同じ構成です。処理は、まず現在の口座状態を表すベクトルを保持する全結合層の作成から始まります。
//--- Content Encoder cContentEncoder.Clear(); cContentEncoder.SetOpenCL(OpenCL); CNeuronBaseOCL *neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * content_units, 1, OpenCL, content_size, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
続いて、指定された数の埋め込みベクトルを所定のサイズで生成するために、全結合層を追加します。
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 2, OpenCL, window * content_units, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
ここでは、コンテキストと背景トークンを連結したテンソルを書き込むための別の層を追加します。
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, window * (content_units + 3), optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
次のステップでは、学習可能な背景トークンのテンソルを生成するモデルを作成します。ここでも2層のMLPを使用します。最初の層は静的で、「1」を含みます。2番目の層は、学習可能なパラメータに基づいて、必要なサイズのテンソルを生成します。
//--- Background cBackGround.Clear(); cBackGround.SetOpenCL(OpenCL); neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * 3, 4, OpenCL, content_size, optimization, iBatch) || !cBackGround.Add(neuron) ) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, window * 3, optimization, iBatch) || !cBackGround.Add(neuron) ) return false;
次に、言語プリミティブモジュールを追加します。
//--- Linguistic Primitive Construction if(!cLPC.Init(0, 6, OpenCL, window, window_key, heads, heads, primitive_units, content_units, 2, 1, optimization, iBatch)) return false;
この後に続くのがデコーダです。ここでは、元の手法の著者が提案したアーキテクチャから少し逸脱し、バニラTransformerデコーダ層を、以前に開発したオブジェクトクラスタモジュールに置き換えました。これらのモジュール間の類似点と相違点についてはすでに説明済みです。このアプローチにより、モデル全体の効率がさらに向上することを期待しています。
また、RefMask3Dフレームワークの著者が提案した構造によれば、各デコーダ層はU字型の点群エンコーダの対応する層と依存関係の解析をおこなうことにも注目すべきです。このアプローチを実現するために、対応するオブジェクトを順番に抽出するループを構成します。
//--- Decoder cDecoder.Clear(); cDecoder.SetOpenCL(OpenCL); CNeuronOCM *ocm = new CNeuronOCM(); if(!ocm || !ocm.Init(0, 7, OpenCL, window, window_key, units_count, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; for(uint i = 0; i < layers; i++) { neuron = cGEGWA.GetInsideLayer(i); ocm = new CNeuronOCM(); if(!ocm || !neuron || !ocm.Init(0, i + 8, OpenCL, window, window_key, neuron.Neurons() / window, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; }
ここで、オブジェクトクラスタモジュールを初期化する必要があります。
//--- Object Cluster Module if(!cOCM.Init(0, layers + 8, OpenCL, window, window_key, primitive_units, heads, window, content_units, heads, optimization, iBatch)) return false;
次に、データバッファへのポインタを差し替えます。これにより、コピー操作の回数を削減できます。
if(!SetOutput(cOCM.getOutput()) || !SetGradient(cOCM.getGradient()) ) return false; //--- return true; }
メソッドの最後に、操作の成功を示すブール値を呼び出し元のプログラムに返します。これでクラスオブジェクトの初期化メソッドの構築が完了し、次にfeedForwardメソッドで実装するフィードフォワードパスのアルゴリズムの構成へ進むことができます。このメソッドのパラメータとして、元データの2つのオブジェクトへのポインタを受け取ります。1つ目はニューラル層オブジェクトへのポインタ、2つ目はデータバッファへのポインタです。これは、基底モデル内でインターフェイスを整理するために採用しているスキームです。
bool CNeuronRefMask::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
メソッドの本体では、受け取った2番目の初期データソースへのポインタの有効性を確認し、必要に応じて、コンテキストエンコーダの最初の層の結果バッファへのポインタに差し替えます。
//--- Context Encoder CNeuronBaseOCL *context = cContentEncoder[0]; if(context.getOutput() != SecondInput) { if(!context.SetOutput(SecondInput, true)) return false; }
その後、提供されたデータに基づいてコンテキスト埋め込みを生成します。
int content_total = cContentEncoder.Total(); for(int i = 1; i < content_total - 1; i++) { context = cContentEncoder[i]; if(!context || !context.FeedForward(cContentEncoder[i - 1]) ) return false; }
フィードフォワードパス操作はコンテキスト埋め込みの生成から始まることに注意してください。点エンコーダは、この情報を初期データの2番目のソースとして使用します。
次に、背景トークンのテンソルを生成します。
//--- Background Encoder CNeuronBaseOCL *background = NULL; if(bTrain) { for(int i = 1; i < cBackGround.Total(); i++) { background = cBackGround[i]; if(!background || !background.FeedForward(cBackGround[i - 1]) ) return false; } } else { background = cBackGround[cBackGround.Total() - 1]; if(!background) return false; }
そしてそれをコンテキスト埋め込みテンソルと連結します。
CNeuronBaseOCL *neuron = cContentEncoder[content_total - 1]; if(!neuron || !Concat(context.getOutput(), background.getOutput(), neuron.getOutput(), context.Neurons(), background.Neurons(), 1)) return false;
次に、結合されたテンソルと、外部プログラムから受け取った最初の初期データソースへのポインタを一緒に、点エンコーダに渡します。
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.FeedForward(NeuronOCL, neuron.getOutput())) return false;
さらに、コンテキスト埋め込みを言語プリミティブ生成モジュールに渡します。この場合のみ、背景トークンのないテンソルを使用します。
//--- Linguistic Primitive Construction if(!cLPC.FeedForward(context)) return false;
背景トークンは点エンコーダ内でのみ使用され、ノイズや外れ値を除去するためのフィルターとして機能することを特に指摘しておくべきでしょう。
この段階で、言語プリミティブと元の点群の埋め込みテンソルがすでに形成されています。次のステップは、これらをデコーダ内で照合し、解析対象のシーンに固有の言語プリミティブを特定することです。ここではまず、点エンコーダの結果をプリミティブにマッピングします。
//--- Decoder CNeuronOCM *decoder = cDecoder[0]; if(!decoder.feedForward(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
次に、言語プリミティブの埋め込みを点エンコーダの中間結果で強化します。そのためにループを作成し、デコーダの各層と対応する点エンコーダのオブジェクトを順次取り出し、データの比較をおこないます。
for(int i = 1; i < cDecoder.Total(); i++) { decoder = cDecoder[i]; if(!decoder.feedForward(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; }
デコーダの結果をオブジェクトクラスタモジュールに渡します。
//--- Object Cluster Module if(!cOCM.feedForward(decoder, context)) return false; //--- return true; }
この後、操作の論理結果を呼び出し元に返してフィードフォワードメソッドの実行を完了します。
なお、今回実装したアルゴリズムは、元のRefMask3Dフレームワークの完全な再現ではありません。元のフレームワークでは、点エンコーダの出力にオブジェクトクラスタモジュールの出力を乗算し、各点が特定オブジェクトに割り当てられる確率を算出するヘッドも存在します。しかし、このアルゴリズムの「剪定」は解決しようとしているタスクの違いによるものです。私たちは、分析対象のシーン内の個々のオブジェクトを視覚的にセグメント化する必要はありません。取引の判断を下すには、望ましいパターンの存在とそのパラメータを把握できれば十分だからです。したがって、このような形でフレームワークを実装しました。その動作結果はActorモデルによって分析されます。
続いて、フィードフォワード処理の実装後はバックプロパゲーションのメソッド開発へ進みます。ここでは誤差勾配分布を担当するcalcInputGradientsメソッドに注目しましょう。通常通り、このメソッドはフィードフォワードの処理を完全に逆におこないます。ただし重要なのは、フィードフォワード中にモデルの性能に重要な役割を持つ学習可能プリミティブ、コンテキスト埋め込み、背景トークンなど様々なエンティティを生成している点です。これらのエンティティは、観察対象となる市場シーンの表現空間をできるだけ広くカバーすることが求められています。言語プリミティブ生成モジュールではこの機能は既に実装済みですが、他のエンティティに関してはまだ開発が必要です。したがって、これから誤差勾配分布メソッドの構築アルゴリズムをじっくり確認していくことをお勧めします。
bool CNeuronRefMask::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!NeuronOCL || !SecondGradient) return false;
このメソッドは3つのパラメータを受け取ります。1つのニューラル層オブジェクトへのポインタと、2つのデータバッファへのポインタです。ご存知の通り、ニューラル層オブジェクトには第一のデータソースの結果バッファと誤差勾配バッファが含まれています。一方、第二のデータソースに対しては、入力データ用と対応する誤差勾配用の別々のバッファが渡されます。さらに、第二のデータソースの活性化関数へのポインタも提供されます。
メソッドの本体では、まず第一のデータソースのポインタと、第二のデータソースの誤差勾配ポインタの有効性を検証します。第二のデータソースの入力データバッファへの有効なポインタが存在しない場合でも問題ありません。なぜなら、フィードフォワードパスの過程で検証済みのポインタが保持されているためです。
必要に応じて、内部オブジェクト内の第二のデータソースの誤差勾配バッファを差し替えます。
CNeuronBaseOCL *neuron = cContentEncoder[0]; if(!neuron) return false; if(neuron.getGradient() != SecondGradient) { if(!neuron.SetGradient(SecondGradient)) return false; neuron.SetActivationFunction(SecondActivation); }
これで準備作業は完了し、実際の誤差勾配分配処理に進みます。
オブジェクト初期化時におこなったポインタの差し替えにより、後続層から受け取った誤差勾配はオブジェクトクラスタモジュールのバッファに直接書き込まれます。これにより不必要なデータコピーを避けつつ、OCMオブジェクトを通じた誤差勾配の分配処理を開始します。
//--- Object Cluster Module CNeuronBaseOCL *context = cContentEncoder[cContentEncoder.Total() - 2]; if(!cOCM.calcInputGradients(cDecoder[cDecoder.Total() - 1], context)) return false;
この場合、勾配はデコーダの最終層と、コンテキストエンコーダの最終層の1つ手前の層に渡されることに注意してください。理由は、コンテキストエンコーダの最終層にはコンテキスト埋め込みと背景トークンを連結したテンソルが含まれており、これは点エンコーダのみが使用するということです。
次に、誤差の勾配をデコーダに伝播させます。そのために、デコーダ層を逆順に反復処理するループを構成します。
//--- Decoder CNeuronOCM *decoder = NULL; for(int i = cDecoder.Total() - 1; i > 0; i--) { decoder = cDecoder[i]; if(!decoder.calcInputGradients(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; } decoder = cDecoder[0]; if(!decoder.calcInputGradients(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
誤差勾配の分配処理中に、勾配を点エンコーダの内部層へ伝播させることに注意してください。これらの値を保持するために、以前にネックオブジェクトの誤差勾配合算法を実装してあります。
デコーダの第二のデータソースは、LPCプリミティブ生成モジュールです。ここで得られた誤差の勾配は、内部のプリミティブ生成モジュールと背景トークンを含まないコンテキスト埋め込みに分配されます。ただし、後者のバッファはすでに前段階の処理結果を保持しているため、一時的に親クラスから継承した未使用のバッファでコンテキスト埋め込みの勾配バッファポインタを差し替えます。その後にLPCモジュールの誤差勾配分配メソッドを呼び出し、最後に2つのデータバッファの値を合算します。
//--- Linguistic Primitive Construction CBufferFloat *context_grad = context.getGradient(); if(!context.SetGradient(PrevOutput, false)) return false; if(!cLPC.FeedForward(context) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) ) return false;
次に、誤差勾配を点エンコーダーへ伝播させます。この際、誤差勾配は元の第一データソースと、背景トークンを含むコンテキスト埋め込みの間で分配されます。
//--- Geometry-Enhaced Group-Word Attention neuron = cContentEncoder[cContentEncoder.Total() - 1]; if(!neuron || !NeuronOCL.calcHiddenGradients((CObject*)GetPointer(cGEGWA), neuron.getOutput(), neuron.getGradient(), (ENUM_ACTIVATION)neuron.Activation())) return false;
重要な点は、コンテキストトークンと背景トークンの両方を同時に多様化させる必要があるということです。ご覧のとおり、背景トークンとコンテキストは同じ部分空間に属しています。さらに、コンテキストと背景トークンの多様化に加えて、これらのエンティティ間に明確な区別を設ける必要があります。したがって、まずコンテキストと背景を連結したテンソルに多様化誤差を加えます。
if(!DiversityLoss(neuron, cOCM.GetContextWindow(), neuron.Neurons() / cOCM.GetContextWindow(), true)) return false; CNeuronBaseOCL *background = cBackGround[cBackGround.Total() - 1]; if(!background || !DeConcat(context.getGradient(), background.getGradient(), neuron.getGradient(), context.Neurons(), background.Neurons(), 1) || !DeActivation(context.getOutput(), context.getGradient(), context.getGradient(), context.Activation()) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) || !context.SetGradient(context_grad, false) ) return false;
次に、得られた誤差の勾配をこれらのエンティティの対応するバッファに分配します。コンテキスト勾配には活性化関数の導関数を適用して調整し、その結果を以前に蓄積された値に加算します。その後、適切なデータバッファへのポインタを復元します。ここから先は、誤差勾配を第二のデータソースへ伝播させることが可能です。
//--- Context Encoder for(int i = cContentEncoder.Total() - 3; i >= 0; i--) { context = cContentEncoder[i]; if(!context || !context.calcHiddenGradients(cContentEncoder[i + 1]) ) return false; }
誤差勾配バッファへのポインタは、対応する内部ニューラル層オブジェクト内にすでに保存されているため、バッファ間で明示的にデータをコピーする必要はありません。
この時点で、誤差勾配は両方のデータソースおよびほとんどの内部コンポーネントに伝播されています。「ほとんど」というのは、最後のステップとして背景トークン生成モデルへの誤差勾配の分配が残っているためです。以前に得られた勾配に活性化関数の導関数を適用して調整し、MLP層に対して逆方向のループを開始します。
//--- Background if(!DeActivation(background.getOutput(), background.getGradient(), background.getGradient(), background.Activation())) return false; for(int i = cBackGround.Total() - 2; i > 0; i--) { background = cBackGround[i]; if(!background || !background.calcHiddenGradients(cBackGround[i + 1]) ) return false; } //--- return true; }
そして最後に、勾配分布メソッドの終了時に、操作の成功を示す論理値を呼び出し元プログラムに返します。
これで、RefMask3Dフレームワークの実装アルゴリズムについての説明は終わりです。紹介されているすべてのクラスとそのメソッドの完全なソースコードは添付ファイルに含まれています。同じ添付ファイルには、学習済みモデルのアーキテクチャや、本記事の準備に使用したすべてのプログラムも収録されています。
モデルのアーキテクチャにはわずかな調整のみが加えられており、具体的には環境状態を記述するエンコーダ内の1つの層が変更されています。インタラクションおよび学習プログラムは以前の作業から変更なく引き継がれているため、ここでは再度取り上げず、代わりに記事の最後の部分、すなわちモデルの学習と性能評価に進みます。
3.テスト
前述のとおり、モデルアーキテクチャに加えた変更は、入力データの構造や出力結果に影響を及ぼしていません。つまり、以前に収集した学習用データセットを、初期段階のモデル学習に再利用することが可能です。なお、使用しているのは2023年通年のEURUSDに関する実際の履歴データ(H1時間足)であり、すべてのインジケーターのパラメータはデフォルト値のままとしています。
モデルの学習はオフラインでおこなわれますが、学習データセットの有効性を維持するために、現在のActor方策に基づいて新たなエピソードを追加し、定期的に更新をおこないます。こうしたモデルの再学習とデータセットの更新は、目標とするパフォーマンスに達するまで繰り返されます。
なお、この記事の準備にあたっては、非常に興味深いActor方策を新たに開発しました。その方策を用いて、2024年1月の履歴データに対するテストを実施した結果を以下に示します。
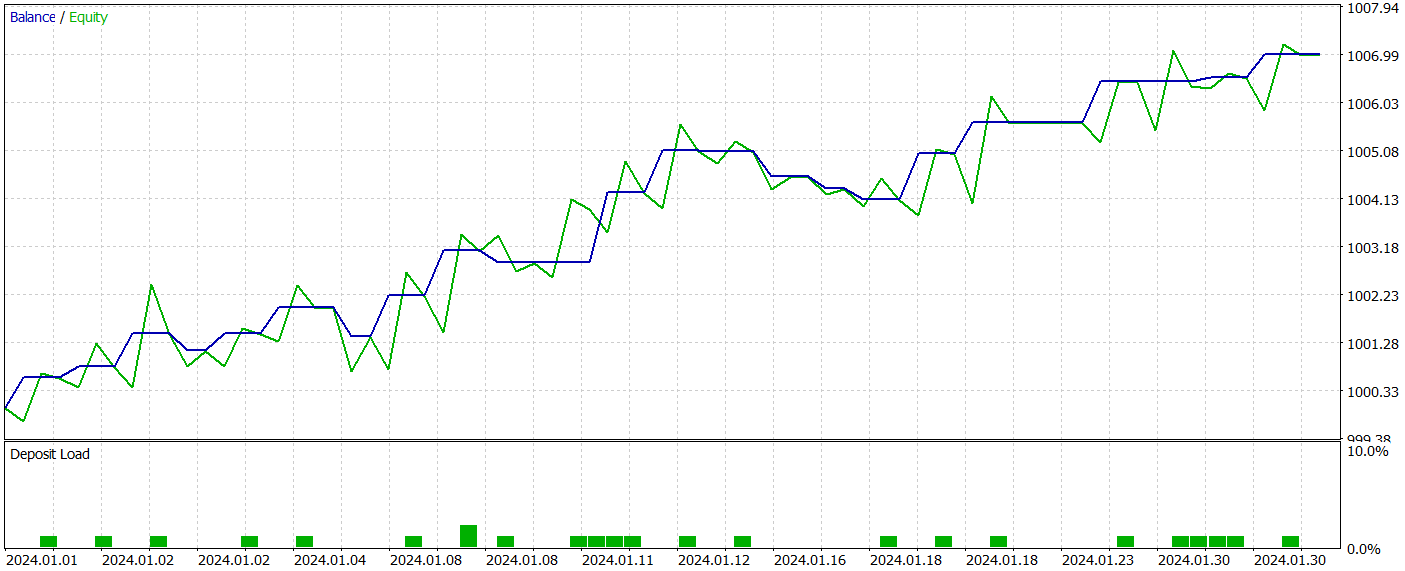
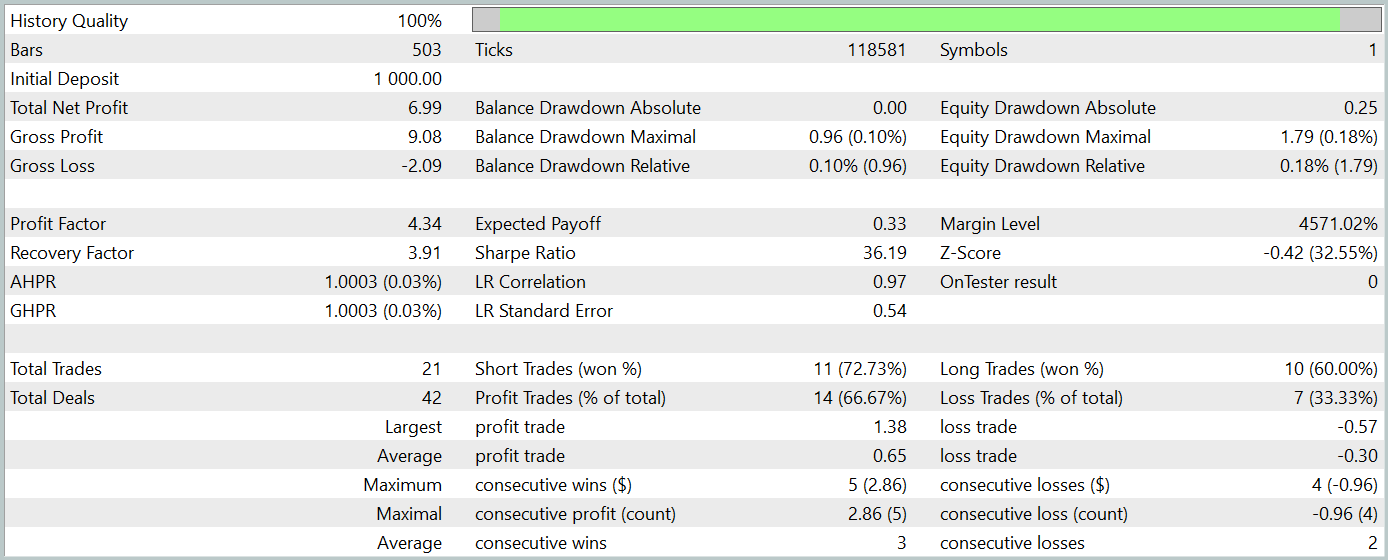
テスト期間中のデータは学習データセットには含まれていません。このようなテスト手法により、実運用におけるモデルの使用状況を可能な限り現実に近い形で再現することができます。
テスト期間中、モデルは21件の取引を実行し、そのうち14件が利益を生みました。勝率は66%を超えており、ショートポジションとロングポジションのいずれにおいても、勝ちトレードの割合が負けトレードを上回っています。さらに、1回あたりの平均利益は、1回あたりの平均損失の2倍に達しており、勝ちトレードの最大利益は最大損失の約3倍となっています。バランスチャートにおいても、明確な上昇トレンドが確認されました。
もちろん、取引数が限られているため、本モデルの長期的な有効性について確固たる結論を下すには時期尚早です。しかしながら、提案手法は十分な可能性を示しており、今後さらなる検討と発展に値すると考えられます。
結論
過去2回にわたる記事では、RefMask3Dフレームワークで提案された手法をMQL5で実装するための包括的な作業をおこなってきました。もちろん、私たちの実装は元のフレームワークとは一部異なる点がありますが、それでも得られた結果はこのアプローチの有効性と将来性を十分に示しています。
ただし、ここで紹介したすべてのプログラムはあくまでデモンストレーションを目的としたものであり、現時点では実際の取引環境での使用には適していないことを強調しておく必要があります。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16057
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ドミトリー、こんにちは。トレーニング中にこのエラーが出ました:
どういう意味ですか?
ちなみに、コンパイル時に2つの警告が表示されます:
記事のファイルは変更されていません。
素晴らしい記事です。 週末にダウンロードして使ってみようと思っています。バックテストレポートで 表示されないものが2つあります。 使用されている通貨ペアと時間枠です。 この情報を提供していただくか、それを特定した過去の記事を参照していただけますか? 答えを見つけました。 EURUSDとH1です。
Viktorさん、私もDeprecated behaviorで同じメモエラーになったことがあります。私の場合、クラスを開発していて、うっかりパラメータが足りない可視関数を呼び出してしまいましたが、クラスには正しいパラメータが含まれていました。パラメータを追加することで問題は解決しました。プロブラムはDeprecated behaviorを使用して正しく実行されたため、メモエラーになったのです。