
Redes neurais em trading: Segmentação guiada

Introdução
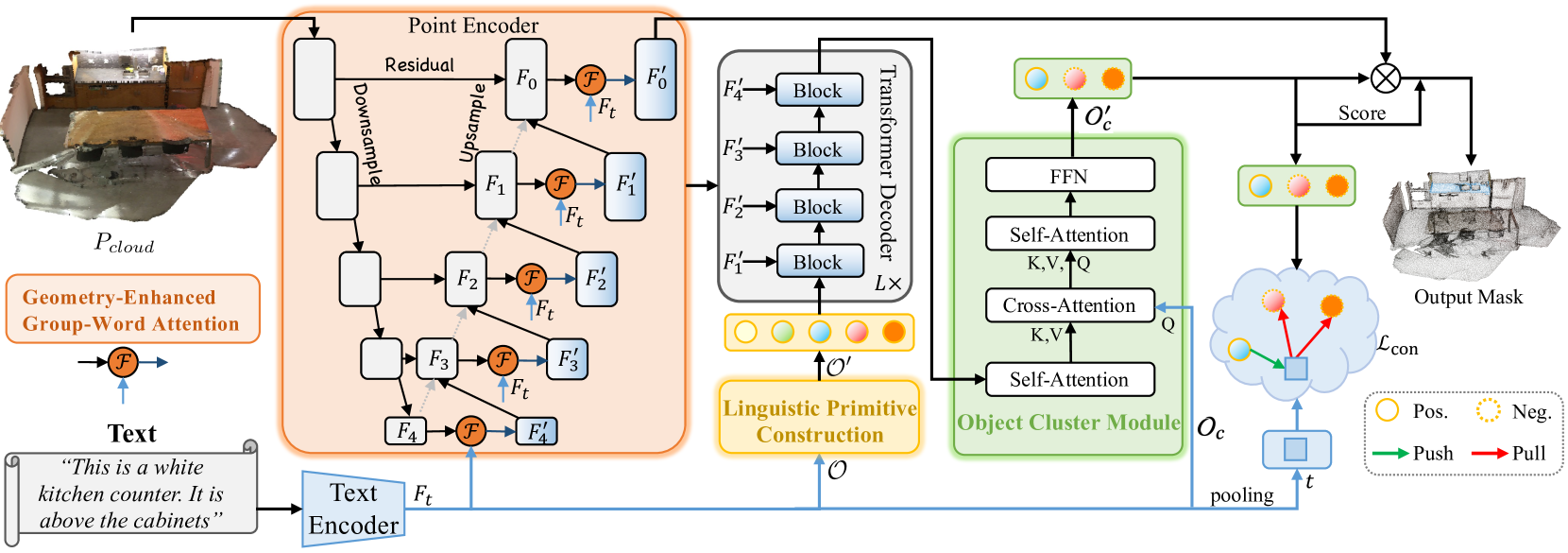
A tarefa de segmentação guiada envolve identificar uma área dentro de uma nuvem de pontos com base em uma descrição do objeto-alvo feita em linguagem natural. Durante sua execução, o modelo realiza uma análise detalhada de dependências semânticas complexas e granulares, construindo uma máscara pontual do objeto-alvo. Para resolver essa tarefa, o trabalho "RefMask3D: Language-Guided Transformer for 3D Referring Segmentation" apresentou um framework eficiente e abrangente, que utiliza amplamente a informação linguística. O método proposto RefMask3D melhora os algoritmos de interação multimodal e compreensão.
Os autores do método propõem o uso de camadas iniciais de codificação de características para extrair um contexto multimodal mais rico. Para isso, eles introduzem o módulo Geometry-Enhanced Group-Word Attention, no qual a atenção cruzada entre a descrição do objeto em linguagem natural e os grupos locais de pontos (subnuvens) é realizada em cada etapa da codificação de suas características. Essa integração não só reduz o ruído gerado pela correlação direta entre pontos e palavras — comum devido à natureza esparsa e irregular das nuvens de pontos —, como também aproveita as relações geométricas internas e a estrutura fina da nuvem de pontos. Dessa forma, a capacidade do modelo de interagir com os dados linguísticos e geométricos é significativamente aprimorada.
Além disso, os autores do método adicionam um token de "fundo" treinável, que evita o entrelaçamento de funções linguísticas irrelevantes com as características do grupo local. Essa abordagem garante que os objetos pontuais sejam enriquecidos com informações semânticas linguísticas, mantendo uma percepção contínua e dependente do contexto sobre a linguagem pertinente dentro de cada grupo ou objeto analisado na nuvem de pontos.
Ao combinarem recursos de visão computacional e análise de linguagem natural, os autores do método desenvolveram uma estratégia eficaz de identificação do objeto-alvo no decodificador, chamada Linguistic Primitives Construction (LPC). Foi proposta a inicialização de um conjunto diverso de primitivos, cada um representando diferentes atributos semânticos, como forma, cor, tamanho, relações, localização etc. Ao interagir com a informação linguística específica, esses primitivos adquirem os atributos correspondentes.
O uso de primitivos semanticamente enriquecidos no decodificador intensifica o foco do modelo na diversidade semântica da nuvem de pontos, melhorando significativamente sua capacidade de localizar e identificar o objeto-alvo com precisão.
Para coletar informações completas e gerar incorporações dos objetos, os autores do framework RefMask3D propuseram o módulo de cluster de objetos (Object Cluster Module — OCM). Os primitivos linguísticos são projetados para destacar partes específicas da nuvem de pontos correlacionadas com seus atributos semânticos. No entanto, o objetivo final é identificar o objeto-alvo com base na descrição fornecida. Isso exige uma compreensão integral da linguagem. Essa tarefa é resolvida por meio da introdução do OCM. Nesse módulo, as relações entre os primitivos linguísticos são analisadas, a fim de identificar características comuns e diferenças nas áreas principais. Com base nessas informações, são iniciadas consultas baseadas em linguagem natural. Isso permite capturar os traços comuns revelados, que formam a incorporação final, essencial para a identificação do objeto-alvo.
O módulo de cluster de objetos proposto ajuda significativamente o modelo a aprofundar sua compreensão integrada das informações linguísticas e visuais.
1. O algoritmo RefMask3D
O método RefMask3D gera uma máscara pontual do objeto-alvo com base na análise da cena original da nuvem de pontos e na descrição textual das características desejadas. A cena analisada consiste em um total de N pontos, cada um contendo informações sobre as coordenadas 3D P e uma função auxiliar F, que descreve cor, forma e outras características.
Inicialmente, é utilizado um Codificador textual, que gera as incorporações da descrição textual Ft. Em seguida, as características pontuais são extraídas por meio de um codificador de pontos, que estabelece uma interação profunda entre a forma observada e a descrição textual com o auxílio do módulo Geometry-Enhanced Group-Word Attention. O codificador de pontos funciona como um backbone, semelhante ao 3D U-Net.
O construtor de primitivos linguísticos cria os primitivos 𝒪′ para representar diferentes atributos semânticos por meio de sinais linguísticos informativos, ampliando a capacidade do modelo de localizar e identificar com precisão os alvos ao interagir com informações linguísticas específicas.
Os primitivos linguísticos 𝒪′, os objetos pontuais multiescalares {𝑭1′,𝑭2′,𝑭3′,𝑭4′} e as funções linguísticas 𝑭t compõem os dados de entrada para um Decodificador cross-modal de quatro camadas, baseado na arquitetura Transformer.
Os primitivos linguísticos, enriquecidos por meio do Decodificador, e as consultas de objeto 𝒪c são alimentados no módulo de cluster de objetos para análise das inter-relações entre os primitivos linguísticos, com o objetivo de unificar sua compreensão e identificar características comuns.
O módulo de fusão de modalidades é inserido sobre os backbones de visão computacional ou do modelo linguístico. Os autores do método integram a fusão multimodal diretamente no Codificador de pontos. A fusão de funções cross-modais em estágios iniciais aumenta a eficiência do processo de combinação. O mecanismo Geometry-Enhanced Group-Word Attention processa de forma inovadora grupos locais de pontos (subnuvens) com vizinhança geométrica. Essa abordagem não apenas reduz o ruído causado por correlações diretas entre características dos pontos e palavras, mas também aproveita as relações geométricas inerentes nas nuvens de pontos, fortalecendo a capacidade do modelo de integrar com precisão a informação linguística e a estrutura 3D.
No mecanismo de atenção cross-modal tradicional (vanilla), é comum surgir o problema de lidar com situações em que não há palavras associadas a um determinado ponto. Para resolver esse problema, os autores do método propõem a introdução de tokens treináveis da função de fundo. Essa estratégia permite que os pontos sem informações textuais correspondentes se concentrem na incorporação geral do token de fundo, reduzindo a distorção potencial causada por textos desconectados no objeto pontual.
A inclusão de objetos pontuais sem correspondência com elementos linguísticos para representar o objeto de fundo reduz o impacto de elementos irrelevantes. Com isso, obtemos características dos pontos que representam atributos linguísticos refinados, relacionados aos centróides locais, sem interferência de palavras inadequadas. A incorporação de fundo é um parâmetro treinável, projetado para capturar a distribuição geral do conjunto de dados e representar a informação original com eficácia. Essa incorporação é utilizada exclusivamente durante o cálculo da atenção. Com o uso da incorporação de fundo, os autores promovem interações cross-modais mais precisas, que não sofrem interferência negativa de palavras irrelevantes.
As abordagens existentes normalmente utilizam consultas com coordenadas dos centróides, extraídas da nuvem de pontos original. No entanto, a principal limitação dessa abordagem é o descaso com a informação linguística, que é essencial para uma segmentação precisa. O uso de amostras apenas dos pontos mais distantes frequentemente resulta em previsões que se desviam dos objetos-alvo, especialmente em cenas esparsas, dificultando a convergência ou levando à perda de objetos. Isso se torna especialmente problemático quando os pontos escolhidos não representam corretamente o objeto-alvo ou quando todos estão associados a uma única palavra. Para resolver essa questão, os autores do framework propõem a construção de primitivos linguísticos que incorporem conteúdo semântico, capacitando diferentes primitivos linguísticos a localizar objetos associados a propriedades semânticas específicas.
Os primitivos treináveis são inicializados a partir de amostras extraídas de diferentes distribuições gaussianas. Cada um representa uma propriedade semântica distinta. Parte-se do princípio de que esses primitivos abrangem diferentes aspectos semânticos, como forma, cor, tamanho, material, relações e localização. Cada primitivo agrega traços linguísticos específicos e extrai as informações correspondentes. Os primitivos linguísticos são destinados a expressar padrões semânticos. A inserção desses primitivos no decodificador Transformer permite destacar a diversidade da informação linguística, o que favorece a identificação precisa dos objetos-alvo em etapas posteriores.
Cada primitivo linguístico foca em diferentes padrões semânticos dentro da nuvem de pontos analisada, que se correlacionam com seus atributos linguísticos. No entanto, o objetivo final, conforme definido pelo texto de entrada, é identificar um único objeto-alvo. Isso exige uma análise abrangente e uma compreensão profunda da descrição textual do objeto de interesse. Para alcançar esse objetivo, os autores do método utilizam o módulo de cluster de objetos, que possibilita a análise das dependências entre os primitivos linguísticos, identificando características comuns e diferenças em suas áreas principais. Isso contribui para uma compreensão mais aprofundada das descrições dos objetos apresentadas. Os autores do método utilizam o mecanismo Self-Attention para extrair características comuns a partir dos primitivos linguísticos. Durante o processo de decodificação, são introduzidas consultas de objeto, tratadas como Query, enquanto as características comuns, enriquecidas pelos primitivos linguísticos, são utilizadas como Key-Value. Essa configuração permite que o decodificador agregue os insights linguísticos dos primitivos às consultas dos objetos, identificando e agrupando de forma eficaz as consultas do objeto designado em 𝒪c′, atingindo assim a identificação precisa do objeto.
Embora o módulo de cluster de objetos proposto auxilie na identificação dos objetos-alvo, ele não elimina ambiguidades que surgem em outras implementações. Essas ambiguidades podem levar a falsos positivos na fase de inferência. Os autores do RefMask3D utilizam aprendizado contrastivo para distinguir o token alvo dos demais. Isso é alcançado maximizando a similaridade entre o token alvo e a expressão correspondente, enquanto se minimiza a similaridade com pares não-alvo (negativos).
A visualização do método apresentada pelos autores está ilustrada em RefMask3D abaixo.
2. Implementação com MQL5
Após a análise dos aspectos teóricos do método RefMask3D, passamos à parte prática do nosso artigo. Nela, implementamos nossa visão das abordagens propostas utilizando MQL5.
Na descrição apresentada acima, os autores do método RefMask3D dividiram o algoritmo complexo em vários blocos funcionais. E penso que será bastante lógico construirmos nossas implementações em forma de módulos correspondentes.
2.1 Geometry-Enhanced Group-Word Attention
Vamos começar construindo o Codificador de pontos, no qual os autores do método integraram o módulo Geometry-Enhanced Group-Word Attention. O algoritmo deste módulo será implementado em uma nova classe CNeuronGEGWA. Conforme mencionado na descrição teórica do método RefMask3D, o Codificador de pontos é construído com uma estrutura de backbone semelhante ao U-Net. Por isso, escolhemos como classe pai a CNeuronUShapeAttention, que fornecerá à nossa classe o funcional básico. A estrutura da nova classe está apresentada abaixo.
class CNeuronGEGWA : public CNeuronUShapeAttention { protected: CNeuronBaseOCL cResidual; CNeuronMLCrossAttentionMLKV cCrossAttention; CBufferFloat cTemp; bool bAddNeckGradient; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronGEGWA(void) : bAddNeckGradient(false) {}; ~CNeuronGEGWA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronGEGWA; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CNeuronBaseOCL* GetInsideLayer(const int layer) const; virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; } };
Vale destacar que a maior parte das variáveis e objetos que nos permitirão estruturar o backbone U-Net, é herdada da classe pai. No entanto, adicionamos objetos para construir a atenção cross-modal.
Todos os objetos são declarados como estáticos, o que nos permite deixar os métodos construtor e destrutor da classe vazios. A inicialização de todos os objetos herdados e adicionados é feita no método Init. Como você sabe, os parâmetros desse método recebem constantes que oferecem uma compreensão clara da arquitetura necessária para o objeto a ser criado.
bool CNeuronGEGWA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
No corpo do método, chamamos imediatamente o método de mesmo nome da camada totalmente conectada base CNeuronBaseOCL, que é o ancestral inicial de todos os nossos objetos de camadas neurais.
Note que, neste caso, estamos chamando o método da classe base, e não da classe pai direta. Isso se deve a certas particularidades da arquitetura que utilizamos na construção do backbone U-Net. Em especial, ao construir o "pescoço", usamos a criação recursiva de objetos. E aqui precisamos utilizar objetos de outra classe.
Em seguida, inicializamos os objetos de atenção primária e de escalonamento.
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2*window, window, (units_count + 1) / 2, optimization, iBatch)) return false;
Em seguida, implementamos o algoritmo de criação do "pescoço". O tipo do objeto do "pescoço" depende do seu tamanho. De modo geral, criamos um objeto semelhante ao atual. apenas reduzindo em "1" o tamanho interno do "pescoço".
if(inside_bloks > 0) { CNeuronGEGWA *temp = new CNeuronGEGWA(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, (units_count + 1) / 2, window_kv, heads_kv, units_count_kv, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
Para a última camada, utilizamos o bloco de atenção cruzada.
else { CNeuronMLCrossAttentionMLKV *temp = new CNeuronMLCrossAttentionMLKV(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, window_kv, heads_kv, (units_count + 1) / 2, units_count_kv, layers, 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
Depois, inicializamos o módulo de reatenção e o de redimensionamento inverso.
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, (units_count + 1) / 2, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, window, window, 2*window, (units_count + 1) / 2, optimization, iBatch)) return false;
Na sequência, adicionamos uma camada de conexão residual e o módulo de atenção cruzada multimodal.
if(!cResidual.Init(0, 5, OpenCL, Neurons(), optimization, iBatch)) return false; if(!cCrossAttention.Init(0, 6, OpenCL, window, window_key, heads, window_kv, heads_kv, units_count, units_count_kv, layers, 1, optimization, iBatch)) return false;
Também inicializamos um buffer auxiliar para armazenamento temporário de dados.
if(!cTemp.BufferInit(MathMax(cCrossAttention.GetSecondBufferSize(), cAttention[0].Neurons()), 0) || !cTemp.BufferCreate(OpenCL)) return false;
E, ao final do método de inicialização, organizamos a substituição dos ponteiros para os buffers de dados, a fim de minimizar as operações de cópia de informações.
if(Gradient != cCrossAttention.getGradient()) { if(!SetGradient(cCrossAttention.getGradient(), true)) return false; } if(cResidual.getGradient() != cMergeSplit[1].getGradient()) { if(!cResidual.SetGradient(cMergeSplit[1].getGradient(), true)) return false; } if(Output != cCrossAttention.getOutput()) { if(!SetOutput(cCrossAttention.getOutput(), true)) return false; } //--- return true; }
E retornamos à função chamadora o resultado lógico da execução das operações do método.
Concluída a inicialização do novo objeto, passamos à construção do algoritmo de propagação para frente, implementado no método feedForward. Ao contrário da classe pai, nosso novo objeto exige duas fontes de dados. Por isso, o método herdado, que trabalha com uma única fonte de dados, foi sobrescrito com uma "função tampão" negativa. E o novo método foi escrito, por assim dizer, "do zero".
Nos parâmetros do método, recebemos ponteiros para dois objetos de dados de entrada. No entanto, neste caso, não realizamos verificações sobre nenhum deles.
bool CNeuronGEGWA::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
Primeiro, passamos o ponteiro de uma das fontes de dados para o método de mesmo nome da camada interna de atenção primária. A verificação do ponteiro já está organizada dentro desse método. Só precisamos verificar o resultado lógico da execução das operações do método chamado. Em seguida, escalamos os resultados do bloco de atenção.
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
Para o "pescoço", passamos os dados escalonados e o ponteiro para o objeto da segunda fonte de dados.
if(!cNeck.FeedForward(cMergeSplit[0].AsObject(), SecondInput)) return false;
O resultado obtido é processado por um segundo bloco de atenção e então realizamos o redimensionamento inverso dos dados.
if(!cAttention[1].FeedForward(cNeck)) return false; if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
Depois, adicionamos as conexões residuais e realizamos a análise das dependências cross-modais.
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), cResidual.getOutput(), 1, false)) return false; if(!cCrossAttention.FeedForward(cResidual.AsObject(), SecondInput)) return false; //--- return true; }
Antes de começarmos a trabalhar nos métodos de propagação reversa, precisamos discutir um ponto. Observe o trecho extraído da visualização do método RefMask3D apresentada pelos autores.

O fato é que, no Decodificador, ocorre a atenção cross-modal entre os primitivos treináveis e os resultados intermediários do nosso Codificador de pontos. Essa operação, que à primeira vista parece simples, implica em um fluxo correspondente de gradientes de erro. Naturalmente, será necessário organizar as interfaces apropriadas. Mas não é difícil perceber que, ao distribuir os gradientes de erro através do nosso bloco geral RefMask3D, primeiro calcularemos os gradientes do Decodificador e só depois os do Codificador de pontos. E, com o modelo clássico de implementação dos métodos de propagação de gradientes de erro, simplesmente perderíamos os dados vindos do Decodificador. No entanto, entendemos que esse uso do bloco representa um caso específico. Por isso, no método calcInputGradients consideramos dois modos de operação: com exclusão dos gradientes previamente salvos (algoritmo clássico) e sem exclusão (caso específico). Para isso, adicionamos uma variável interna de controle chamada bAddNeckGradient e um método para sua modificação chamado AddNeckGradient.
virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; }
Mas voltemos ao algoritmo de propagação reversa. Nos parâmetros do método calcInputGradients, recebemos ponteiros para 3 objetos e uma constante da função de ativação do segundo conjunto de dados.
bool CNeuronGEGWA::calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!prevLayer) return false;
No corpo do método, verificamos apenas a validade do ponteiro para a primeira fonte de dados. As verificações dos demais ponteiros são realizadas dentro dos métodos de distribuição de gradientes de erro das camadas internas.
Graças à substituição de ponteiros para os buffers de dados, organizada anteriormente, o algoritmo de distribuição dos gradientes de erro começa a partir da camada interna de atenção cross-modal.
if(!cResidual.calcHiddenGradients(cCrossAttention.AsObject(), SecondInput, SecondGradient, SecondActivation)) return false;
Depois disso, realizamos o redimensionamento dos gradientes de erro.
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
A seguir, estruturamos um ramal no algoritmo, dependendo da necessidade de preservar o gradiente de erro previamente acumulado. Caso seja necessário preservar, fazemos a substituição do buffer de gradientes de erro no "pescoço" por um buffer de gradientes semelhante, proveniente da primeira camada de redimensionamento de dados. Aqui exploramos o fato de que os tamanhos dos tensores de saída dessa camada de redimensionamento e do "pescoço" são iguais. E o gradiente de erro para essa camada será propagado posteriormente. Portanto, nesse caso, o uso é seguro.
if(bAddNeckGradient) { CBufferFloat *temp = cNeck.getGradient(); if(!cNeck.SetGradient(cMergeSplit[0].getGradient(), false)) return false;
Em seguida, obtemos o gradiente de erro no nível do "pescoço" pelo método clássico. Somamos os resultados de ambos os fluxos de informação e retornamos os ponteiros para os objetos.
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false; if(!SumAndNormilize(cNeck.getGradient(), temp, temp, 1, false, 0, 0, 0, 1)) return false; if(!cNeck.SetGradient(temp, false)) return false; }
No caso em que o gradiente de erro previamente acumulado não é relevante para nós, simplesmente calculamos o gradiente de erro usando os métodos padrão.
else if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
A seguir, propagamos o gradiente de erro através do objeto "pescoço". Aqui usamos o método clássico. apenas o gradiente de erro da segunda fonte de dados é armazenado no buffer temporário, já que mais adiante precisaremos somar os valores obtidos tanto do módulo de atenção cross-modal do objeto atual quanto do "pescoço".
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject(), SecondInput, GetPointer(cTemp), SecondActivation)) return false; if(!SumAndNormilize(SecondGradient, GetPointer(cTemp), SecondGradient, 1, false, 0, 0, 0, 1)) return false;
Depois, propagamos o gradiente de erro até o nível da primeira fonte de dados de entrada.
if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
Passamos o gradiente de erro das conexões residuais pela derivada da função de ativação e somamos as informações de ambos os fluxos.
if(!DeActivation(prevLayer.getOutput(), GetPointer(cTemp), cMergeSplit[1].getGradient(), prevLayer.Activation())) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getGradient(), 1, false)) return false; //--- return true; }
O método de atualização dos parâmetros do modelo updateInputWeights é bastante simples. Aqui apenas chamamos os métodos de mesmo nome das camadas internas que contêm parâmetros treináveis. Por isso, sugiro deixar esse trecho para estudo independente. Lembro que o código completo desta classe e de todos os seus métodos está disponível no anexo.
E algumas palavras sobre a criação da interface de acesso aos objetos do "pescoço". Para implementar essa funcionalidade, foi criado o método GetInsideLayer, no qual passamos como parâmetro o índice da camada desejada.
CNeuronBaseOCL* CNeuronGEGWA::GetInsideLayer(const int layer) const { if(layer < 0) return NULL;
A obtenção de um índice negativo é interpretada como um erro, e o método retorna um ponteiro NULL. Um valor igual a zero indica que estamos acessando a camada atual. Sendo assim, o método retornará um ponteiro para o objeto "pescoço".
if(layer == 0) return cNeck;
Caso contrário, o pescoço deve ser um objeto da classe correspondente, e chamamos recursivamente esse método, reduzindo o índice da camada desejada em 1.
if(!cNeck || cNeck.Type() != Type()) return NULL; //--- CNeuronGEGWA* temp = cNeck; return temp.GetInsideLayer(layer - 1); }
2.2 Linguistic Primitives Construction
Na próxima etapa, criamos o objeto do módulo de geração de primitivos Linguistic Primitives Construction na classe CNeuronLPC. A visualização do método fornecida pelos autores está apresentada abaixo.
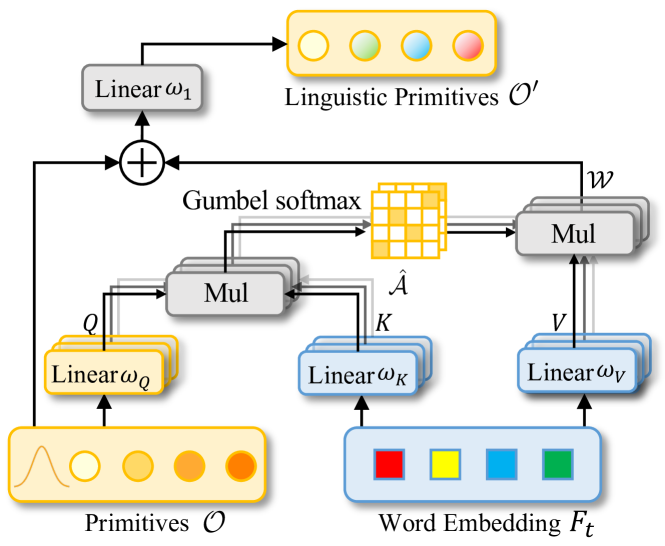
Nela, é fácil perceber a semelhança com o bloco clássico de atenção cruzada, o que motivou a escolha da classe base. Neste caso, utilizamos o objeto de atenção cruzada CNeuronMLCrossAttentionMLKV. A estrutura da nova classe está apresentada abaixo.
class CNeuronLPC : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cPrimitives; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronLPC(void) {}; ~CNeuronLPC(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronLPC; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Vale observar que, se no caso anterior adicionávamos fontes de dados de entrada para os processos de propagação para frente e reversa, aqui é o contrário. Apesar de o módulo de atenção cruzada exigir duas fontes de dados, nesta implementação usaremos apenas uma. Isso porque a geração da segunda fonte de dados (os primitivos) é realizada internamente por este próprio objeto.
Para gerar os primitivos treináveis, criamos dois objetos internos de camadas totalmente conectadas. Ambos os objetos são declarados como estáticos, o que permite deixar o construtor e o destrutor da classe "vazios". A inicialização dos objetos declarados e herdados é realizada no método Init.
bool CNeuronLPC::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, window, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
Nos parâmetros desse método, como de costume, recebemos constantes que permitem determinar com clareza a arquitetura do objeto a ser criado. E no corpo do método, imediatamente chamamos o método de mesmo nome da classe base, que já realiza a verificação dos parâmetros recebidos e a inicialização dos objetos herdados.
Note que utilizamos os parâmetros dos primitivos gerados como informações da fonte primária de dados.
Em seguida, geramos uma camada totalmente conectada unitária, composta por apenas um elemento.
if(!cOne.Init(window * units_count, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false;
E então inicializamos a camada de geração de primitivos.
if(!cPrimitives.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false; //--- return true; }
Observe que, neste caso, não utilizamos a camada de codificação posicional. Afinal, pela lógica dos autores do método, alguns primitivos são responsáveis pela posição do objeto, enquanto outros acumulam seus atributos.
O método de propagação para frente feedForward deste módulo também é simples. Nos parâmetros do método, recebemos um ponteiro para o objeto de dados de entrada e imediatamente verificamos a validade desse ponteiro. O que, devo dizer, não é muito comum nos métodos recentes de propagação para frente.
bool CNeuronLPC::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Estamos cada vez mais acostumados a ver esse tipo de verificação sendo feito pelos métodos dos objetos internos. No entanto, neste caso, os dados recebidos do programa externo serão usados como contexto. Isso significa que, ao chamarmos os métodos dos objetos internos, teremos que acessar os objetos aninhados da nossa fonte de dados. Portanto, somos obrigados a verificar o ponteiro recebido.
Em seguida, geramos o tensor de características.
if(bTrain && !cPrimitives.FeedForward(cOne.AsObject())) return false;
E aqui vale dizer que, para reduzir o tempo de decisão, essa operação será realizada apenas durante o processo de treinamento do modelo. No modo de operação, o tensor de primitivos permanece estático, e não há necessidade de gerá-lo a cada iteração.
As operações da propagação para frente são finalizadas com a chamada ao método de mesmo nome da classe pai. A esse método passamos o tensor de primitivos como fonte primária de dados e as informações recebidas do programa externo como contexto.
if(!CNeuronMLCrossAttentionMLKV::feedForward(cPrimitives.AsObject(), NeuronOCL.getOutput())) return false; //--- return true; }
No método de propagação reversa calcInputGradients, seguimos as operações em estrita conformidade com o algoritmo de propagação direta, apenas em ordem inversa.
bool CNeuronLPC::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Aqui também verificamos primeiro o ponteiro recebido para o objeto de dados de entrada. Em seguida, chamamos o método de mesmo nome da classe pai, com a distribuição do gradiente de erro entre os primitivos e o contexto de entrada.
if(!CNeuronMLCrossAttentionMLKV::calcInputGradients(cPrimitives.AsObject(), NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) return false;
Depois disso, adicionamos o gradiente de erro relacionado à diversificação dos primitivos.
if(!DiversityLoss(cPrimitives.AsObject(), iUnits, iWindow, true)) return false; //--- return true; }
A propagação do gradiente de erro até o nível da camada unitária não traz valor prático, por isso omitimos essa operação. E o algoritmo do método de atualização dos parâmetros fica como sugestão para estudo independente. O código completo desta classe e de todos os seus métodos está disponível no anexo.
O próximo bloco no fluxo do algoritmo RefMask3D é o bloco do decodificador Transformer do tipo vanilla, no qual está implementado o algoritmo de atenção cruzada multimodal entre a nuvem de pontos e os primitivos treináveis. Esse funcional já pode ser coberto com os recursos que já possuímos. Portanto, não nos preocuparemos com a criação de um novo bloco.
E o próximo módulo que precisamos implementar é o módulo de cluster de objetos. O algoritmo desse módulo será implementado na classe CNeuronOCM. Trata-se de um módulo bastante complexo. Ele combina dois blocos de Self-Attention para os primitivos e funções semânticas, complementados por um bloco de atenção cruzada. A estrutura da nova classe está apresentada abaixo.
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); };
Acredito que você já tenha percebido que os métodos desta classe possuem algoritmos bastante complexos. Sua descrição exige explicações adicionais. No entanto, o formato deste artigo é relativamente limitado. Por isso, com o objetivo de apresentar de forma completa e clara os algoritmos implementados, proponho continuar a análise da implementação em um próximo artigo. Nele também serão apresentados os resultados dos testes das modelos utilizando os métodos propostos com dados reais.
Considerações finais
Neste artigo, apresentamos o método RefMask3D, desenvolvido para análise de interações multimodais complexas e compreensão de características. O método analisado pode representar uma inovação relevante na área de negociação. Ao utilizar dados multidimensionais, ele consegue levar em conta padrões atuais e históricos dos dados de mercado. O RefMask3D emprega uma série de mecanismos para focar nas características essenciais, minimizando o impacto do ruído e de dados irrelevantes.
Na parte prática do artigo, iniciamos a implementação das abordagens propostas com o uso de MQL5 e estruturamos os objetos de dois dos módulos apresentados. No entanto, o volume de trabalho realizado ultrapassa os limites de um único artigo. Assim, o trabalho iniciado será continuado.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos com método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA de treinamento de Modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste de modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código para OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16038
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso