
Neural Networks in Trading: Controlled Segmentation (Final Part)

Introduction
In the previous article, we explored the RefMask3D method, designed to perform a comprehensive analysis of multimodal interactions and understand the features of the point cloud under consideration. RefMask3D is a comprehensive framework that includes several modules:
- A point encoder with an integrated Geometry-Enhanced Group-Word Attention module. This module performs cross-modal attention between the natural language description of the object and local point groups (sub-clouds) at each stage of feature encoding. The block architecture proposed by the authors reduces the impact of noise inherent in direct correlations between points and words, while transforming internal geometric relationships into a refined point cloud structure. This significantly enhances the model's ability to interact with both linguistic and geometric data.
- A language model that transforms the textual description of the target object into a token structure used by the model to identify the object.
- A set of trainable linguistic primitives (Linguistic Primitives Construction — LPC), designed to represent various semantic attributes such as shape, color, size, relations, location, etc. When interacting with specific linguistic input, these primitives acquire the corresponding attributes.
- A Transformer-based decoder that enhances the model's focus on diverse semantic information within the point cloud, thereby significantly improving its ability to accurately localize and identify the target object.
- An Object Cluster Module — OCM gathers holistic information and generates object embeddings.
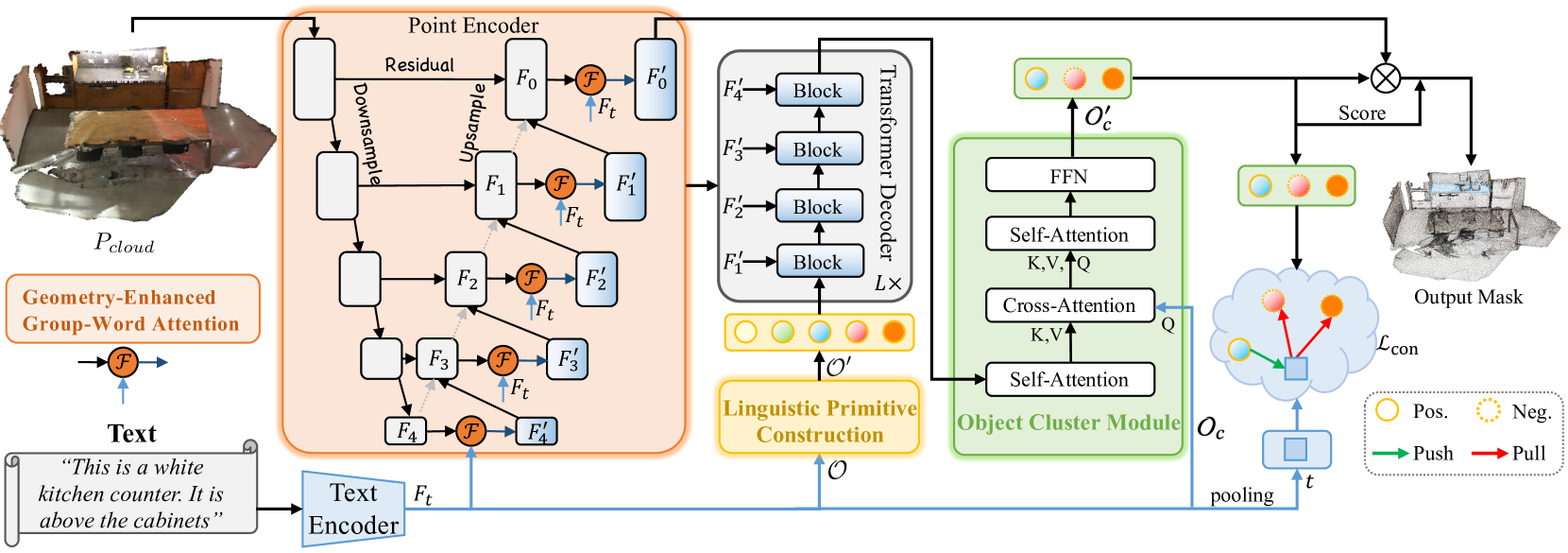
In the previous article, we had already completed a significant portion of the framework's implementation. Specifically, we implemented the Geometry-Enhanced Group-Word Attention and Linguistic Primitives Construction modules within their respective classes. We also noted that the decoder functionality could be covered using existing implementations of various cross-attention blocks. We left off at the development of the algorithms for the Object Cluster Module. This is where we will continue our work.
1. Implementation of the Object Cluster Module
As mentioned earlier, the Object Cluster Module is designed to aggregate holistic information and generate object embeddings. The original visualization of the module is provided below.
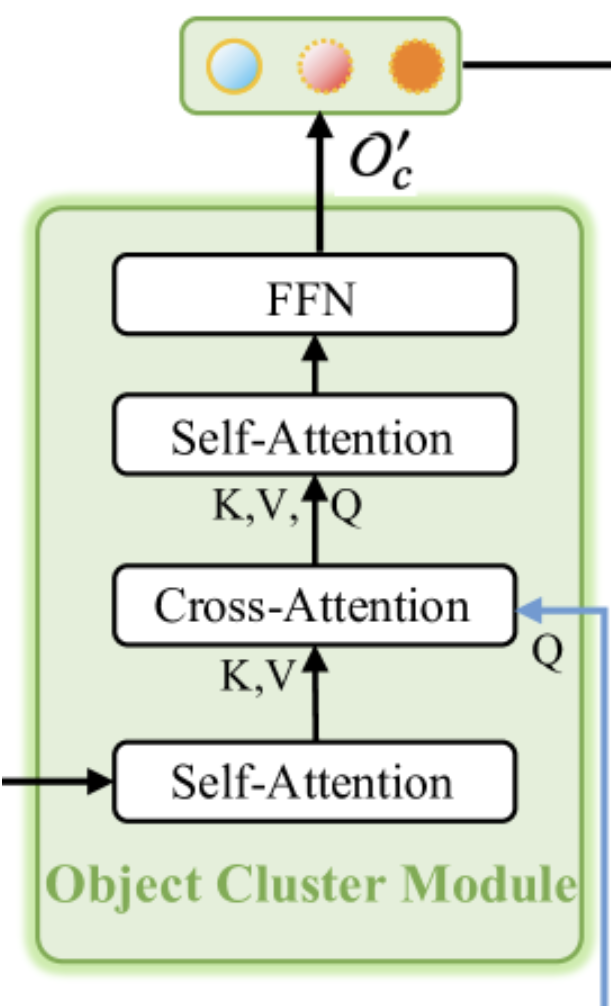
As can be seen from the visualization, the Object Cluster Module consists of two Self-Attention block, one Cross-Attention block positioned between them, and an FFN block at the output, implemented as a fully connected MLP. This architecture may evoke different associations. On one hand, it resembles a vanilla Transformer decoder with an additional Self-Attention block placed after the Cross-Attention. However, attention should be paid to the modified functionality of the Cross-Attention block. In this context, the SPFormer method comes to mind. Under such an interpretation, the first Self-Attention block serves as a feature extraction module for point representations.
That said, the presented architectural solution may also be viewed as a compact version of a vanilla Transformer. It features a "trimmed" encoder, omitting the FeedForward block, and a decoder with rearranged Cross-Attention and Self-Attention blocks. This structure undoubtedly makes the module a complex and integral component of the overall RefMask3D framework, its importance confirmed by experimental results provided by the authors. Incorporating the Object Cluster Module improves model performance by 1.57%.
The module receives input from two sources. First, the output from the Decoder, which includes primitive embeddings enriched with information about the analyzed point cloud, passes through the initial Self-Attention block, serving as context for the subsequent Cross-Attention block. The primary information source for the Cross-Attention block is the embedding of the target object's textual description. These embeddings are used to form the Query components of the Cross-Attention block. The output of the Cross-Attention block is input into the second Self-Attention and FeedForward.
The algorithm described above is implemented in the CNeuronOCM class, the structure of which is outlined below.
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); //--- virtual uint GetPrimitiveWindow(void) const { return iPrimWindow; } virtual uint GetContextWindow(void) const { return iContWindow; } };
The core functionality of the neural layer will be inherited from the fully connected CNeuronBaseOCL, which we will use as the parent class.
In the previously presented structure of the new class, we can observe a familiar set of overridden methods, along with a number of declared internal objects and variables. We will explore their functionality in detail during the method implementation process. For now, it is important to note that all internal objects have been declared as static. This means we can leave the class constructor and destructor empty. The initialization of these declared and inherited internal objects is performed in the Init method. As you know, in the parameters of the specified method, we receive a set of constants that allow us to unambiguously interpret the architecture of the created object.
bool CNeuronOCM::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, cont_window * cont_units, optimization_type, batch)) return false;
In the body of the method, we begin by calling the method of the same name from the parent class. This method already implements the algorithms for the minimal required validation of the received parameters and the initialization of inherited objects. We monitor the success of the parent method's execution by checking the boolean value it returns.
Upon successful execution of the parent class method, we proceed to store the values of the received constants in the internal variables of our class.
iPrimWindow = prim_window; iPrimUnits = prim_units; iPrimHeads = prim_heads; iContWindow = cont_window; iContUnits = cont_units; iContHeads = cont_heads; iWindowKey = window_key;
Next, we clear the dynamic arrays associated with internal objects.
cQuery.Clear(); cKey.Clear(); cValue.Clear(); cMHAttentionOut.Clear(); cAttentionOut.Clear(); cResidual.Clear(); cFeedForward.Clear();
We then move on to initializing the components of the internal blocks. According to the previously described algorithm, the first block to be initialized is the Self-Attention block responsible for analyzing the dependencies between primitives.
At this point, it is worth recalling that the input to this module consists of primitives that, within the Decoder, were enriched with information about the analyzed point cloud. Therefore, the task of this Self-Attention block is to identify the primitives that are relevant to the given point cloud.
We begin by creating the Query, Key, and Value generator objects. For the generation of all three entities, we utilize convolutional layers with identical parameters. The pointers to these initialized objects are added to dynamic arrays named in accordance with the generated entities.
CNeuronBaseOCL *neuron = NULL; CNeuronConvOCL *conv = NULL; //--- Primitives Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 0, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 1, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 2, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Next, we add a fully connected layer to record the output of multi-headed attention.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, iPrimHeads * iWindowKey * iPrimUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
We use a convolutional layer to scale the results of multi-headed attention to the size of the original data tensor.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 4, OpenCL, iPrimHeads * iWindowKey, iPrimHeads * iWindowKey, iPrimWindow, iPrimUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
The last one in the Self-Attention block is the fully connected residual connection layer.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
You can see that the structure of the attention block objects presented above is universal. It can be used for both Self-Attention and Cross-Attention block. Therefore, to implement the algorithm of the subsequent Cross-Attention block, we will create similar objects and add pointers to them into the same dynamic arrays. The only difference is in the data sources for generating Query, Key, and Value entities. When generating the Query entity, we use context information as input.
//--- Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 6, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false;
To generate Key and Value entities, we use the output from the previous Self-Attention block. Here we have a tensor size identical to the learnable primitives.
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 7, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 8, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Then we add a layer of multi-headed attention results.
//--- Multi-Heads Cross-Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 9, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Add a convolutional scaling layer.
//--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 10, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
The Cross-Attention block is completed by a residual connection layer.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 11, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
In the next step, we create an additional Self-Attention block. This one will be used for analyzing contextual dependencies. Once again, we repeat the process of creating the corresponding attention-related objects, adding pointers to these newly created objects into the same dynamic arrays used previously. However, in this case, all entities are generated based on the output of the Cross-Attention block. Consequently, the input tensor now has the dimensionality of the analyzed context.
//--- Context Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 12, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 13, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 14, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
We add a layer of multi-headed attention results.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 15, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
This is followed by a convolutional scaling layer.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 16, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
Again, the last one is the residual connection layer.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 17, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Now we need to add FeedForward block objects. Similar to vanilla Transformer, in this block we use 2 convolutional layers with an LReLU activation function between them.
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 18, OpenCL, iContWindow, iContWindow, 4 * iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false; conv.SetActivationFunction(LReLU); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 19, OpenCL, 4*iContWindow, 4*iContWindow, iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false;
In this case, we will use our class buffers inherited from the parent class as a residual connection layer. However, we organize the substitution of pointers to error gradient buffers in order to reduce data copy operations.
if(!SetGradient(conv.getGradient())) return false; //--- SetOpenCL(OpenCL); //--- return true; }
At the end of the method, we return a boolean value indicating the success of the operations to the calling program.
It's important to note that we have not created data buffer objects for storing attention coefficients. These buffers will be instantiated exclusively within the OpenCL context. Their creation has been moved to a separate method CreateBuffers, which I encourage you to review independently in the provided attachment.
After completing the initialization method for the object, we move on to implementing the forward-pass algorithms. They are defined in the feedForward method. Here, it's worth noting a slight deviation from the usual structure of forward-pass methods used in our previous implementations. While we typically passed a pointer to a neural layer object as the primary input and a data buffer pointer as the secondary, in this case, we use neural layer objects for both inputs. However, at this stage, such an implementation is only applicable to internal components used in building the algorithms of the higher-level neural layer object. This is perfectly acceptable for our current purposes.
bool CNeuronOCM::feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context) { CNeuronBaseOCL *neuron = NULL, *q = cQuery[0], *k = cKey[0], *v = cValue[0];
In the body of the method, we first declare several local variables to temporarily store pointers to neural layer objects. These variables are immediately assigned pointers to the entity-generation components for the first attention block. Then, we verify the validity of the pointers and generate the necessary entities from the tensor of primitives received from the external program.
if(!q || !k || !v) return false; if(!q.FeedForward(Primitives) || !k.FeedForward(Primitives) || !v.FeedForward(Primitives) ) return false;
We pass the obtained entities to the multi-headed attention block for dependency analysis.
if(!AttentionOut(q, k, v, cScores[0], cMHAttentionOut[0], iPrimUnits, iPrimHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
We scale the obtained results and sum them with the corresponding input data. After that we normalize the results.
neuron = cAttentionOut[0]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[0]) ) return false; v = cResidual[0]; if(!v || !SumAndNormilize(Primitives.getOutput(), neuron.getOutput(), v.getOutput(), iPrimWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
As input to the first Self-Attention block, we provided the primitives enriched with information about the analyzed point cloud. In the block, we further introduced internal dependencies. The goal of this step is to emphasize, in contrast, those primitives that are most relevant to the analyzed scene. In essence, this stage is comparable to performing a segmentation task on the point cloud. However, in our case, the objective is to locate the target object described by a textual expression. Therefore, we proceed to the next stage - Cross-Attention. Here we align the embeddings of the target object's textual description with the primitives associated with the analyzed point cloud. To achieve this, we retrieve from our object arrays the neural layers responsible for generating Cross-Attention entities. We verify the validity of the obtained pointers. And we generate the required entities.
//--- Cross-Attention q = cQuery[1]; k = cKey[1]; v = cValue[1]; if(!q || !k || !v) return false; if(!q.FeedForward(Context) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
Let me remind you that the Query entity is generated from the target object description embeddings. Key and Value entities are generated from the output of the previous Self-Attention block. Next, we will use the mechanism of multi-headed attention.
if(!AttentionOut(q, k, v, cScores[1], cMHAttentionOut[1], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Then, we scale the obtained results and supplement them with residual connections.
neuron = cAttentionOut[1]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[1]) ) return false; v = cResidual[1]; if(!v || !SumAndNormilize(Context.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
It is important to note that we use the original context tensor as a residual connection. The results of summing the two tensors are normalized across individual sequence elements.
At the output of the Cross-Attention block, we expect to obtain embeddings of the target object's description enriched with information from the analyzed point cloud. In other words, our goal is to "highlight" those embeddings of the target object description that are relevant to the scene under analysis.
Note that we do not perform a direct comparison between the analyzed point cloud and the target object description at this stage. However, in previous stages of the RefMask3D framework, we have already extracted primitives from the original point cloud. In the Cross-Attention block, we identify from the target object's description those primitives that were found in the point cloud. We then proceed to construct a "coherent picture" by enriching the selected embeddings through mutual interactions in the subsequent Self-Attention block.
As before, we retrieve the next entity-generation layers from the internal dynamic arrays and validate the obtained pointers.
//--- Context Self-Attention q = cQuery[2]; k = cKey[2]; v = cValue[2]; if(!q || !k || !v) return false;
After that, we generate Query, Key, and Value entities. In this case, the input data for generating all entities is the output of the previous cross-attention block.
if(!q.FeedForward(neuron) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
We also use the multi-headed attention algorithm to detect interdependencies in the analyzed data sequence.
if(!AttentionOut(q, k, v, cScores[2], cMHAttentionOut[2], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
We scale the obtained results and add residual connections with subsequent data normalization.
q = cAttentionOut[1]; if(!q || !q.FeedForward(cMHAttentionOut[2]) ) return false; v = cResidual[2]; if(!v || !SumAndNormilize(q.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
And then we need to propagate enriched context tensor through the FeedForward block. We add residual relationships to the obtained results and normalize the data. We write the obtained values into the results buffer of our CNeuronOCM class. This object was inherited from a parent class.
//--- Feed Forward q = cFeedForward[0]; k = cFeedForward[1]; if(!q || !k || !q.FeedForward(neuron) || !k.FeedForward(q) || !SumAndNormilize(neuron.getOutput(), k.getOutput(), Output, iContWindow, true, 0, 0, 0, 1) ) return false; //--- return true; }
At the conclusion of the feed-forward pass method, we just need to return the Boolean result of the operations back to the calling program.
Once the implementation of the feed-forward pass methods is complete, we proceed to organize the processes of the backpropagation pass. As usual, the functionality of the backward pass is divided into two stages: distribution of the error gradients to all elements according to their influence on the overall model performance, and optimization of the learnable parameters. Accordingly, we will construct a dedicated method for each stage: calcInputGradients and updateInputWeights. The first method fully inverts the operations of the feed-forward pass. In the second, we simply sequentially invoke the methods of the same name in the internal objects containing trainable parameters. I encourage you to explore the algorithms for these methods independently. The complete code of this class and all its methods is included in the attached files.
2. Constructing the RefMask3D Framework
We have completed substantial work on implementing the individual modules of the RefMask3D framework, and now it is time to assemble everything into a unified object, integrating the separate blocks into a well-structured architecture. To perform this task, we will create a new class CNeuronRefMask whose structure is presented below.
class CNeuronRefMask : public CNeuronBaseOCL { protected: CNeuronGEGWA cGEGWA; CLayer cContentEncoder; CLayer cBackGround; CNeuronLPC cLPC; CLayer cDecoder; CNeuronOCM cOCM; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronRefMask(void) {}; ~CNeuronRefMask(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRefMask; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
In the structure presented above, it is easy to recognize the modules we have previously implemented. However, alongside them are also dynamic array objects, whose functionality we will explore during the method implementation phase of the new class.
All objects are declared statically, allowing us to leave the class constructor and destructor "empty". The initialization of these declared and inherited objects is performed in the Init method.
As you know, the parameters of this method provide constants that allow us to clearly identify the architecture of the object being created. However, the complexity and quantity of internal objects result in high architectural variability. This in turn increases the number of descriptive parameters required. In our view, an excessive number of parameters would only complicate the use of the class. Therefore, we opted to unify the parameters of the internal objects, significantly reducing the number of external inputs. This means that the initialization method should retain only constants that define the parameters of the input and output data. Where possible, the internal objects will reuse the external data parameters. For instance, the window size for a single sequence element is specified only for the input data. But the same parameter is also used for generating embeddings of the learnable primitives and as the embedding size for context. As such, defining the sequence lengths for the primitives and context is sufficient for tensor construction.
bool CNeuronRefMask::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * content_units, optimization_type, batch)) return false;
The first operation inside the method, as usual, is to call the parent class method of the same name, which already contains the minimal validation logic for the received parameters and initialization of inherited objects. After this, we proceed with initializing the declared objects. We begin by initializing the point cloud encoder using the previously implemented module: Geometry-Enhanced Group-Word Attention.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.Init(0, 0, OpenCL, window, window_key, heads, units_count, window, heads, (content_units + 3), 2, layers, optimization, iBatch)) return false; cGEGWA.AddNeckGradient(true);
Please pay attention to the following two moments. First, when specifying the sequence length of the context, we add 3 elements to the embedding size of the target object description. As in the previous implementation, we will not provide a textual description of the target object. Instead, we will generate a series of tokens from the vector that describes the current account state and open positions. The rationale is the same: generating multiple distinct tokens from a single account state description allows for a more comprehensive analysis of the current market situation. However, we acknowledge that the input data may contain noise and outliers. To mitigate their influence, we introduce three additional learnable tokens to accumulate irrelevant values. Essentially, this is a type of "background" token, as proposed by the authors of the RefMask3D framework.
Our point encoder utilizes two-layer attention blocks at every stage. The layers parameter, received from the external program, specifies the number of embeddings within our U-shaped module's "neck".
In addition, we enable the gradient summation functionality for the neck modules.
Following this, we proceed to the context encoder. Ф separate block was not created for this module. However, you are already familiar with its architecture. It fully replicates the encoder for refining expressions in the 3D-GRES method. The process begins by creating a fully connected layer that stores the vector representing the current account state.
//--- Content Encoder cContentEncoder.Clear(); cContentEncoder.SetOpenCL(OpenCL); CNeuronBaseOCL *neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * content_units, 1, OpenCL, content_size, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
And then we add a fully connected layer to generate a given number of embeddings of the required size.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 2, OpenCL, window * content_units, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Here we add another layer, into which we will write the concatenated tensor of context and "background" tokens.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, window * (content_units + 3), optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
The next step is to create a model for generating a tensor of learnable background tokens. Here we also use a two-layer MLP. Its first layer is static and contains "1". The second layer generates a tensor of the required size based on the learnable parameters.
//--- Background cBackGround.Clear(); cBackGround.SetOpenCL(OpenCL); neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * 3, 4, OpenCL, content_size, optimization, iBatch) || !cBackGround.Add(neuron) ) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, window * 3, optimization, iBatch) || !cBackGround.Add(neuron) ) return false;
Then we add the linguistic primitives module.
//--- Linguistic Primitive Construction if(!cLPC.Init(0, 6, OpenCL, window, window_key, heads, heads, primitive_units, content_units, 2, 1, optimization, iBatch)) return false;
This is followed by a decoder. Here, we made a slight deviation from the architecture proposed by the authors of the original method: we replaced the vanilla Transformer decoder layers with the previously developed Object Cluster module. We have already discussed the similarities and differences between these modules earlier. And we hope that this approach will further improve the efficiency of the resulting model.
It is also worth noting that, according to the structure proposed by the authors of the RefMask3D framework, each decoder layer performs dependency analysis with a corresponding layer of the U-shaped point encoder. To implement this approach, we organize a loop that sequentially extracts the appropriate objects.
//--- Decoder cDecoder.Clear(); cDecoder.SetOpenCL(OpenCL); CNeuronOCM *ocm = new CNeuronOCM(); if(!ocm || !ocm.Init(0, 7, OpenCL, window, window_key, units_count, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; for(uint i = 0; i < layers; i++) { neuron = cGEGWA.GetInsideLayer(i); ocm = new CNeuronOCM(); if(!ocm || !neuron || !ocm.Init(0, i + 8, OpenCL, window, window_key, neuron.Neurons() / window, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; }
We now just need to initialize the object cluster module.
//--- Object Cluster Module if(!cOCM.Init(0, layers + 8, OpenCL, window, window_key, primitive_units, heads, window, content_units, heads, optimization, iBatch)) return false;
Then we substitute pointers to data buffers, which allows us to reduce the number of copying operations.
if(!SetOutput(cOCM.getOutput()) || !SetGradient(cOCM.getGradient()) ) return false; //--- return true; }
At the end of the method, we return a boolean value indicating the success of the operations to the calling program. This completes the construction of the class object initialization method and we can move on to organizing the feed-forward pass algorithms that we implement in the feedForward method. In the parameters of this method, we receive pointers to two objects of the original data. The first one is represented as a pointer to a neural layer object, and the second one is a data buffer. This is the scheme for which we have organized interfaces within our base model.
bool CNeuronRefMask::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
In the body of the method, we check the relevance of the received pointer to the second source of the initial data and, if necessary, substitute the pointer with the result buffer in the first layer of the Context Encoder.
//--- Context Encoder CNeuronBaseOCL *context = cContentEncoder[0]; if(context.getOutput() != SecondInput) { if(!context.SetOutput(SecondInput, true)) return false; }
After that we generate context embedding based on the provided data.
int content_total = cContentEncoder.Total(); for(int i = 1; i < content_total - 1; i++) { context = cContentEncoder[i]; if(!context || !context.FeedForward(cContentEncoder[i - 1]) ) return false; }
Note that feed-forward pass operations start with the generation of the context embedding. T%he point encoder uses this information as a second source of initial data.
Next, we generate a tensor of background tokens.
//--- Background Encoder CNeuronBaseOCL *background = NULL; if(bTrain) { for(int i = 1; i < cBackGround.Total(); i++) { background = cBackGround[i]; if(!background || !background.FeedForward(cBackGround[i - 1]) ) return false; } } else { background = cBackGround[cBackGround.Total() - 1]; if(!background) return false; }
And we concatenate it with the context embedding tensor.
CNeuronBaseOCL *neuron = cContentEncoder[content_total - 1]; if(!neuron || !Concat(context.getOutput(), background.getOutput(), neuron.getOutput(), context.Neurons(), background.Neurons(), 1)) return false;
Next, we transfer the concatenated tensor together with the pointer to the first source of initial data received from an external program to our point encoder.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.FeedForward(NeuronOCL, neuron.getOutput())) return false;
In addition, we pass the context embedding to the linguistic primitives generation module. Only in this case we use a tensor without background tokens.
//--- Linguistic Primitive Construction if(!cLPC.FeedForward(context)) return false;
It should probably be noted that background tokens are only used in the point encoder to filter out noise and outliers.
At this stage, we have already formed the tensors of embeddings of linguistic primitives and the original point cloud. The next step is to match them in our decoder, which will help to identify linguistic primitives inherent in the analyzed scene. Here we first map the results of the point encoder to our primitives.
//--- Decoder CNeuronOCM *decoder = cDecoder[0]; if(!decoder.feedForward(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
Then we enrich the embeddings of linguistic primitives with intermediate results of the point encoder. To do this, we create a loop, in which we will sequentially extract subsequent layers of the decoder and the corresponding objects of the point encoder with subsequent data comparison.
for(int i = 1; i < cDecoder.Total(); i++) { decoder = cDecoder[i]; if(!decoder.feedForward(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; }
We pass the decoder results through the object cluster module.
//--- Object Cluster Module if(!cOCM.feedForward(decoder, context)) return false; //--- return true; }
After this, we complete the execution of the feed-forward method by returning the logical result of the operations to the calling program.
It is worth mentioning that the implemented algorithm is not an exact replica of the original RefMask3D framework. In the original algorithm, there is an additional multiplication of the point encoder's outputs by the output of the object cluster module, along with a head that determines the probability of assigning points to specific objects. The reason for this "pruning" of the algorithm lies in the difference in tasks being solved. We do not require visual segmentation of individual objects within the analyzed scene. To make a decision about making a trading operation, it is enough to know about the presence of the desired patterns and their parameters. Therefore, we decided to implement the proposed framework in this form. Its operation results will be analyzed by the Actor model.
Let's move forward. After implementing the feed-forward algorithms, we proceed to develop the methods for the backpropagation process. Here, a few words should be said about the error gradient distribution method calcInputGradients. As usual, this method fully inverts the feed-forward operations. However, it is important to note that during the feed-forward pass, we generate a range of entities that play a crucial role in the model’s effectiveness. These include trainable primitives, context embeddings, and background tokens. Naturally, we want to generate as diverse a set of these entities as possible, aiming to cover the broadest space of the observed market scene. While we have already implemented this functionality within the linguistic primitives generation module, it still needs to be developed for the other entities. Therefore, I suggest spending a few minutes reviewing the algorithm used to build the error gradient distribution method.
bool CNeuronRefMask::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!NeuronOCL || !SecondGradient) return false;
The method receives three parameters: pointers to one neural layer object and two data buffers. As you know, the neural layer object contains buffers for the first source's results and error gradients. For the second data source, however, we receive separate buffers for the input data and corresponding error gradients. Additionally, a pointer to the activation function for the second data source is provided.
Within the method body, we immediately verify the validity of the pointers for the first data source and the error gradient of the second. The absence of a valid pointer to the second source's input data buffer is not critical, as the verified pointer was preserved during the feed-forward pass.
If necessary, we then replace the error gradient buffer within our internal object for the second data source.
CNeuronBaseOCL *neuron = cContentEncoder[0]; if(!neuron) return false; if(neuron.getGradient() != SecondGradient) { if(!neuron.SetGradient(SecondGradient)) return false; neuron.SetActivationFunction(SecondActivation); }
This completes the preparatory work, and we proceed to the actual error gradient distribution operations.
Thanks to the pointer substitution performed during object initialization, the error gradient received from the subsequent layer is written directly into the object cluster module's buffer. Thus, avoiding unnecessary data copying, we start the operations by distributing the error gradient through the OCM object.
//--- Object Cluster Module CNeuronBaseOCL *context = cContentEncoder[cContentEncoder.Total() - 2]; if(!cOCM.calcInputGradients(cDecoder[cDecoder.Total() - 1], context)) return false;
Note that in this case, we pass the gradient to the last decoder layer and the penultimate context encoder layer. The reason is that the last context encoder layer contains a concatenated tensor of the context embeddings and background tokens, which is used only by the point encoder.
Next, we propagate the error gradient through the decoder. To achieve this, we organize a reverse loop iterating over the decoder layers.
//--- Decoder CNeuronOCM *decoder = NULL; for(int i = cDecoder.Total() - 1; i > 0; i--) { decoder = cDecoder[i]; if(!decoder.calcInputGradients(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; } decoder = cDecoder[0]; if(!decoder.calcInputGradients(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
Please note that during the error gradient distribution process, we propagate the gradient to the internal layers of the point encoder. It is precisely to preserve these values that we previously implemented the error gradient summation algorithm for the neck objects.
The second data source for the Decoder is the LPC primitive generation module. The error gradient obtained here will be distributed to the internal primitive generation module and the context embedding without background tokens. However, the latter buffer already contains data from previous operations. Therefore, we temporarily replace the context embedding gradient buffer pointer with an unused buffer inherited from the parent class. Only then do we call the LPC module's error gradient distribution method. Afterward, we sum the values of the two data buffers.
//--- Linguistic Primitive Construction CBufferFloat *context_grad = context.getGradient(); if(!context.SetGradient(PrevOutput, false)) return false; if(!cLPC.FeedForward(context) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) ) return false;
Next, we propagate the error gradient through the point encoder. This time, we distribute the error gradient between the first source of original data and the context embedding with background tokens.
//--- Geometry-Enhaced Group-Word Attention neuron = cContentEncoder[cContentEncoder.Total() - 1]; if(!neuron || !NeuronOCL.calcHiddenGradients((CObject*)GetPointer(cGEGWA), neuron.getOutput(), neuron.getGradient(), (ENUM_ACTIVATION)neuron.Activation())) return false;
It is important to note that we must jointly diversify both the context and background tokens. As you can see, background tokens and the context belong to the same subspace. Moreover, in addition to diversifying the context and background tokens, we must establish a clear distinction between these entities. Therefore, we first add a diversification error to the concatenated tensor of context and background.
if(!DiversityLoss(neuron, cOCM.GetContextWindow(), neuron.Neurons() / cOCM.GetContextWindow(), true)) return false; CNeuronBaseOCL *background = cBackGround[cBackGround.Total() - 1]; if(!background || !DeConcat(context.getGradient(), background.getGradient(), neuron.getGradient(), context.Neurons(), background.Neurons(), 1) || !DeActivation(context.getOutput(), context.getGradient(), context.getGradient(), context.Activation()) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) || !context.SetGradient(context_grad, false) ) return false;
Next, we distribute the resulting error gradient across the corresponding buffers of these entities. We adjust the context gradient by applying the derivative of the activation function and add the resulting values to those previously accumulated. After that, we restore the pointer to the appropriate data buffer. From this point, we can propagate the error gradient down to the second data source.
//--- Context Encoder for(int i = cContentEncoder.Total() - 3; i >= 0; i--) { context = cContentEncoder[i]; if(!context || !context.calcHiddenGradients(cContentEncoder[i + 1]) ) return false; }
Recall that the pointer to the error gradient buffer has already been saved within the corresponding internal neural layer object. As a result, explicitly copying data between buffers becomes redundant.
At this stage, we have propagated the error gradient to both data sources and almost all internal components. "Almost" - because the final step is to distribute the error gradient through the background token generation model. We adjust the previously obtained gradient using the derivative of the activation function and initiate a reverse-iteration loop over the MLP layers.
//--- Background if(!DeActivation(background.getOutput(), background.getGradient(), background.getGradient(), background.Activation())) return false; for(int i = cBackGround.Total() - 2; i > 0; i--) { background = cBackGround[i]; if(!background || !background.calcHiddenGradients(cBackGround[i + 1]) ) return false; } //--- return true; }
And finally, at the end of the gradient distribution method, we return a logical result to the calling program, indicating the success of the operation.
With this, we conclude our discussion of the RefMask3D framework implementation algorithms. You can find the complete source code for all presented classes and their methods in the attachment. The same attachment also includes the architectures of the trained models and all the programs used during the preparation of this article.
Only minor adjustments were made to the model architectures, specifically modifying a single layer in the encoder responsible for describing the environment state. The interaction and training programs were carried over from previous work without any changes. Therefore, we will not revisit them here and instead proceed to the final part of our article - training the models and evaluating their performance.
3. Testing
As previously mentioned, changes to the model architecture did not affect the structure of the input data or the output results. This means we can reuse the previously collected training dataset for initial model training. Recall that we use real historical data of the EURUSD instrument for the entire year of 2023 on the H1 timeframe. All indicator parameters were set to their default values.
Model training is performed offline. However, to maintain the training dataset relevance, we periodically update it by adding new episodes based on the current Actor policy. Model training and dataset updates are repeated until the desired performance is achieved.
During the preparation of this article, we developed a rather interesting Actor policy. The results of its testing on historical data from January 2024 are presented below.
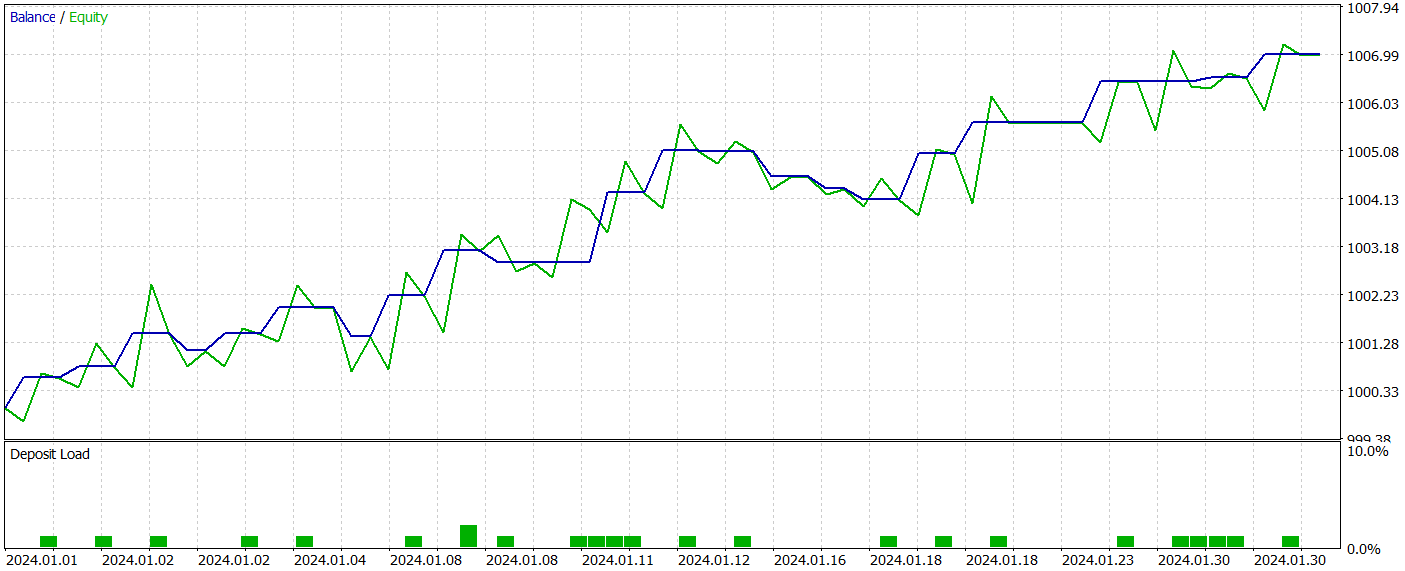
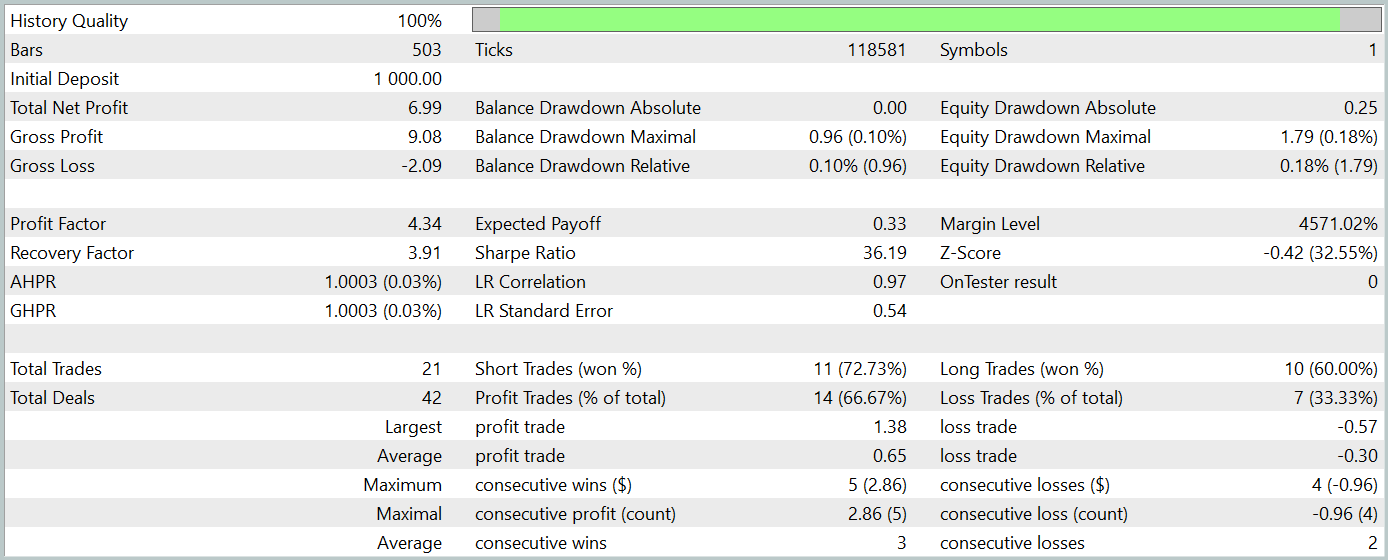
The test period was not included in the training dataset. This testing approach simulates real-world model usage as closely as possible.
During the test period, the model executed 21 trades, 14 of which were profitable, which amounted to more than 66%. Notably, the proportion of profitable trades exceeded losing ones in both short and long positions. Moreover, the average profit per winning trade was twice the average loss per losing trade. The maximum profit trade was nearly three times greater than the largest loss. The balance chart shows a clearly defined upward trend.
Of course, the limited number of trades does not allow us to draw firm conclusions about the model’s long-term effectiveness. However, the proposed approach clearly shows promise and warrants further exploration.
Conclusion
Over the past two articles, we have done extensive work implementing the methods proposed in the RefMask3D framework using MQL5. Naturally, our implementation differs slightly from the original framework. Nevertheless, the results obtained demonstrate the potential of this approach.
However, I must emphasize that all programs presented in this article are for demonstration purposes only and are not yet suitable for real-world trading conditions.
References
- RefMask3D: Language-Guided Transformer for 3D Referring Segmentation
- Other articles from this series
Programs used in the article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA for collecting examples |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA for collecting examples using the Real-ORL method |
| 3 | Study.mq5 | Expert Advisor | Model training EA |
| 4 | Test.mq5 | Expert Advisor | Model testing EA |
| 5 | Trajectory.mqh | Class library | System state description structure |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Library | OpenCL program code library |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/16057
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Dmitry hello. I got this error during training:
What does it mean?
By the way, when compiling these 2 warnings appear:
The files from the article are unchanged.
Excellent Article. I am going to download it and try using it this weekend. There are two things the backtest report does not show. The currency pair used and the time frame. Can you please provide this information or reference a previous article which identified it? I just found the answers. Its EURUSD and H1
Viktor, I have had the same memo error on Deprecated behavior. In my case, I was developing a class and inadvertently called a visible function that was missing a parameter but the class contained the correct parameters. Adding the parameter solved my problem. the probram ran correctly using the deprecated behavior which is why it is a memo error.