
Redes neurais em trading: Resultados práticos do método TEMPO

Introdução
No artigo anterior, abordamos os aspectos teóricos do método TEMPO, que oferece uma abordagem original para o uso de modelos linguísticos pré-treinados na resolução de problemas de previsão de séries temporais. Aqui, relembrarei brevemente as principais inovações do algoritmo proposto.
O método TEMPO utiliza um modelo linguístico pré-treinado. Em particular, os autores do método utilizam o GPT-2 pré-treinado em seus experimentos. A ideia principal do método consiste em utilizar os conhecimentos adquiridos pelo modelo durante o pré-treinamento para prever séries temporais. Neste ponto, é importante destacar as não tão óbvias semelhanças entre a linguagem e as séries temporais. Afinal, essencialmente, nossa fala é uma série temporal de sons registrados por meio de letras. Já diferentes entonações são marcadas por sinais de pontuação.
Outro ponto importante é que um modelo linguístico extenso (Long Language Model — LLM), como o GPT-2, foi pré-treinado em um grande conjunto de dados (geralmente em vários idiomas) e aprendeu diversas dependências em sequências temporais de palavras, que gostaríamos de usar na previsão de séries temporais. Porém, as sequências de letras e palavras diferem bastante dos dados analisados em séries temporais. E sempre destacamos que, para a operação correta de qualquer modelo, é fundamental que a distribuição dos dados nos conjuntos de treinamento e teste seja consistente. Especialmente os dados analisados durante a utilização prática do modelo. É necessário lembrar que qualquer modelo linguístico não trabalha com o texto em sua forma pura. Primeiro, ele passa por uma etapa de incorporação, na qual o texto que conhecemos é transformado em um código numérico (estado oculto). Esse é o formato com o qual o modelo trabalha. A saída do modelo gera probabilidades para o uso subsequente de letras e sinais de pontuação. Os símbolos com maior probabilidade formam o texto legível.
Os autores do método TEMPO aproveitaram essa característica. Durante o treinamento do modelo de previsão de séries temporais, eles "congelam" os parâmetros do modelo linguístico e otimizam os parâmetros de transformação dos dados brutos em incorporações compreensíveis para o modelo utilizado. Aqui, os autores do método TEMPO propõem uma abordagem abrangente, que permite fornecer ao modelo o máximo de informações úteis. Primeiro, a série temporal analisada é decomposta em seus componentes: tendência, sazonalidade etc. Em seguida, cada componente é segmentado e transformado em incorporações compreensíveis pelo modelo linguístico. Para direcionar o modelo linguístico no caminho desejado (análise de tendências ou sazonalidade), os autores desenvolveram um sistema de "indicações suaves".
Em geral, essa abordagem torna o modelo altamente interpretável e permite avaliar a influência de cada componente no resultado da previsão dos valores subsequentes.
A seguir, é apresentada a visualização autoral do método.
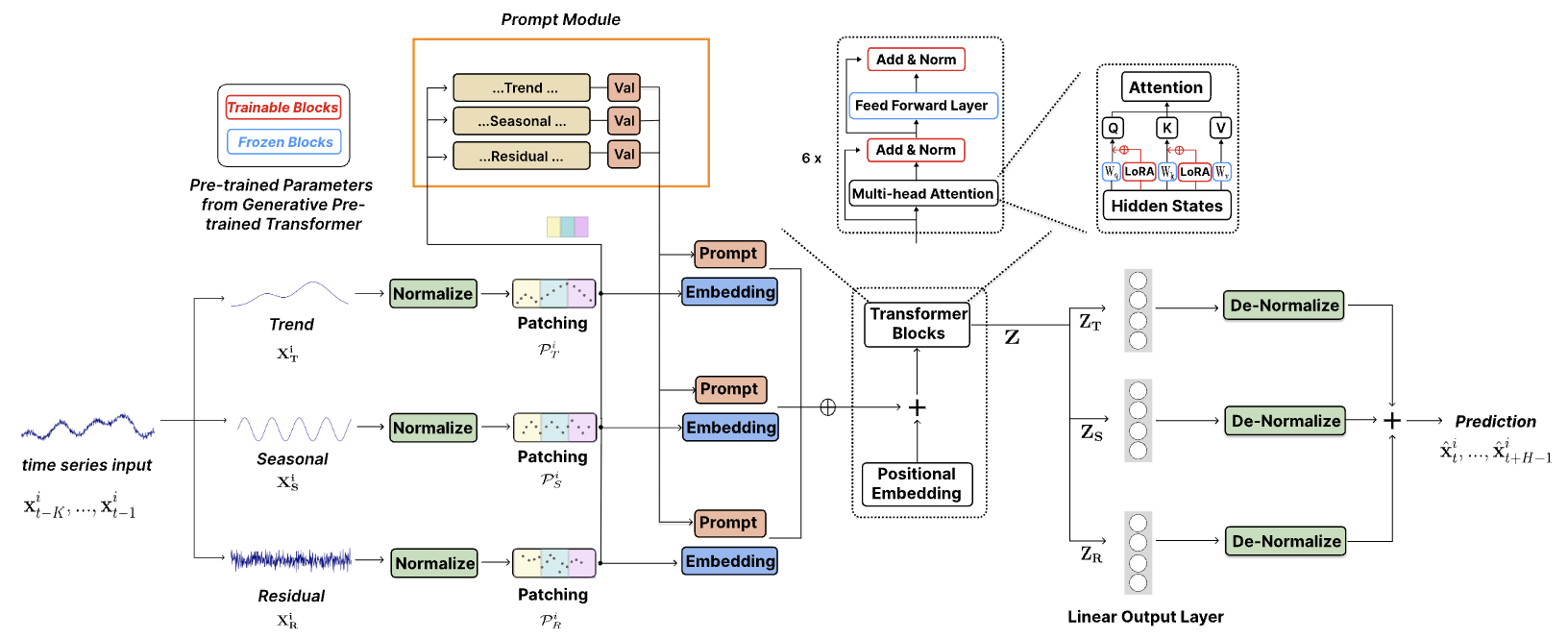
1. Arquitetura dos modelos
A arquitetura do modelo proposto é bastante complexa. Ela contém várias ramificações e fluxos de dados paralelos, que são somados na saída. Esse tipo de algoritmo é difícil de implementar na estrutura do nosso modelo linear. Por isso, realizamos um extenso trabalho para implementá-lo em um único bloco, que atua como uma única camada do nosso modelo. Essa implementação limita as possibilidades do usuário de experimentar modelos com diferentes níveis de complexidade. Afinal, a variação na estrutura do módulo está restrita aos parâmetros do método Init, criado por nossa classe CNeuronTEMPOOCL. Porém, há outro lado dessa abordagem: simplificamos ao máximo o processo de criação de um novo modelo. O usuário não precisa se aprofundar em todas as nuances da arquitetura do método apresentado. Ele só precisa especificar alguns parâmetros para construir uma arquitetura complexa e poderosa. A meu ver, essa é a opção mais viável para a maioria dos usuários.
E, claro, vale destacar outro ponto bastante importante. Em seus experimentos, os autores do método utilizaram o modelo linguístico GPT-2 pré-treinado. Na implementação em Python, é possível encontrar esses modelos, por exemplo, na biblioteca titleHugging Facetitle. Entretanto, esse modelo não está disponível na nossa versão de implementação. Por isso, substituímos esse bloco por um mecanismo de atenção cruzada e o treinamos juntamente com o modelo.
O método TEMPO é posicionado pelos autores como um modelo para previsão de séries temporais. Assim, assim como fizemos em casos semelhantes anteriormente, incorporamos as abordagens propostas ao nosso modelo de Codificador do estado do ambiente. A arquitetura deste modelo está apresentada no método CreateEncoderDescriptions.
Nos parâmetros do referido método, passamos um ponteiro para um array dinâmico, cujos elementos conterão os parâmetros arquitetônicos das camadas neurais do modelo criado.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
No corpo do método, verificamos a validade do ponteiro recebido e, se necessário, criamos uma nova instância do objeto.
Em seguida, descrevemos o modelo. Inicialmente, especificamos uma camada totalmente conectada para registrar os dados brutos. O tamanho da camada criada deve corresponder ao tamanho do tensor dos dados brutos.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
No modelo, passamos um tensor de dados brutos não processados, exatamente como os recebemos do terminal. Em todos os nossos modelos anteriores, utilizávamos uma camada de normalização em lote, na qual os dados passavam por um processamento inicial para serem trazidos a um formato comparável.
No entanto, neste caso, excluímos a camada de normalização em lote. E, curiosamente, a razão para isso foi a arquitetura do método TEMPO. Como é possível observar na visualização do método apresentada acima, os dados brutos são diretamente enviados ao bloco de decomposição. Nesse bloco, a série temporal analisada é decomposta em três componentes principais: tendência, sazonalidade e outros aspectos. A decomposição em componentes é realizada de forma independente para cada série temporal individual, ou seja, o parâmetro analisado em uma série temporal multimodal. A comparabilidade dos valores dentro de uma série individual é garantida pela natureza dos dados.
Primeiramente, a componente de tendência é extraída dos dados brutos. Em nossa implementação, essa operação é realizada utilizando o método de representação linear segmentada da série temporal. Como você sabe, o algoritmo desse método permite extrair segmentos comparáveis, independentemente da escala e do deslocamento na distribuição dos dados brutos, o que normalmente não ocorre no processo de normalização.
Em seguida, subtraímos a componente de tendência dos dados brutos e determinamos a componente de sazonalidade. Para isso, utilizamos a Transformada Discreta de Fourier para decompor o sinal em um espectro de frequências, no qual é possível identificar as dependências periódicas mais significativas por meio das amplitudes das frequências. A decomposição em frequências também não é afetada pela escala ou pelo deslocamento dos dados brutos.
Por fim, para determinar a terceira componente, basta subtrair das informações brutas as duas componentes encontradas anteriormente.
Acredito que isso fique evidente: do ponto de vista da lógica de construção do modelo, a normalização preliminar dos dados não nos traria vantagens adicionais. Por outro lado, a normalização dos dados exigiria recursos computacionais adicionais, o que, por si só, já seria indesejável.
Agora, observe mais de perto. Os autores do método introduzem a normalização das componentes destacadas, o que é obviamente importante para operações subsequentes com dados multimodais. É possível alterar o ponto de normalização dos dados? É possível realizar a normalização dos dados brutos antes da divisão em componentes e eliminar a normalização posterior das componentes individuais? Afinal, o volume dos dados brutos é três vezes menor do que o volume total das três componentes. Minha opinião é que isso é mais "não" do que "sim".
Por exemplo, vamos considerar um gráfico abstrato e identificar nele as principais tendências. É evidente que a componente de tendência "absorverá" a maior parte das informações.
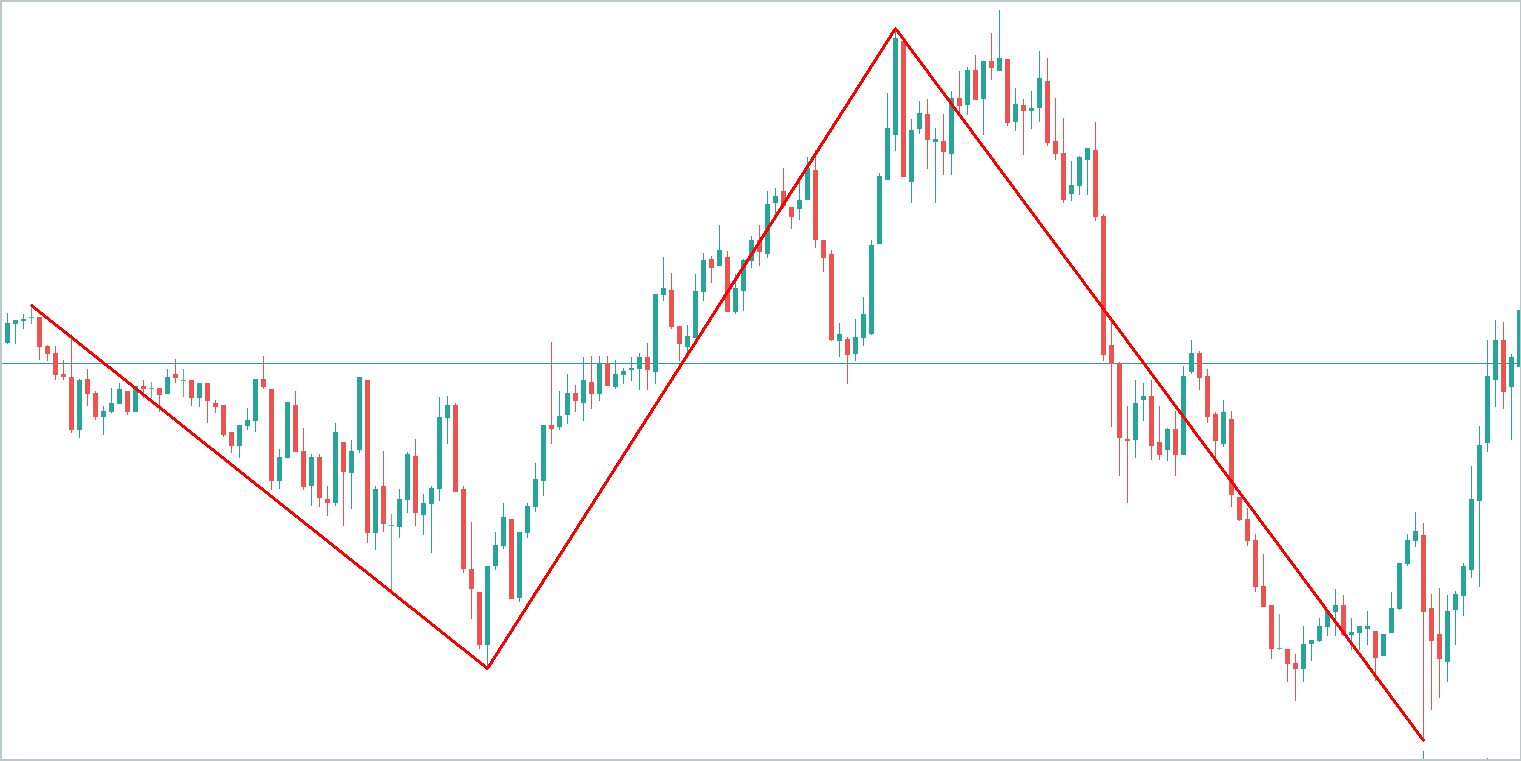
A componente sazonal representa oscilações ondulatórias em torno da linha de tendência. A amplitude de seus valores será significativamente menor que a da componente de tendência.
A terceira componente, que engloba outros valores, terá uma amplitude ainda menor, composta em grande parte por ruídos. Contudo, esses ruídos não podem ser ignorados, pois refletem o impacto de fatores externos, como notícias e outros elementos não sistemáticos.
A normalização dos dados iniciais antes de dividir os sinais em componentes permitirá resolver a questão da comparabilidade dos dados de séries individuais separadas. Porém, ela não resolve o problema da comparabilidade dos dados de componentes individuais extraídas do sinal analisado. Portanto, para garantir a estabilidade do modelo, é preferível normalizar posteriormente os dados das componentes individuais.
Com base nesses argumentos, optamos por excluir a camada de normalização em lote dos dados brutos. Imediatamente após a camada de dados brutos, posicionamos nosso novo bloco do método TEMPO.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTEMPOOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = NForecast;
Especificamos o tamanho da sequência multimodal a ser analisada, o número de séries temporais individuais nela e o horizonte de planejamento por meio de constantes previamente definidas.
Nos experimentos realizados para este artigo, especifiquei 4 cabeças de atenção.
descr.window_out = 4;
E 4 camadas aninhadas no bloco de atenção.
descr.layers = 4;
Aqui, quero lembrar que esses parâmetros são usados nos dois blocos de atenção aninhados:
- O bloco de atenção na área de frequências, utilizado para identificar dependências entre as características de frequência de séries individuais separadas;
- O bloco de cross-attention para identificar dependências na sequência de séries temporais.
Em seguida, especificamos o tamanho do lote para normalização e o método de otimização do modelo.
descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Com isso, poderíamos considerar o modelo concluído, já que, na saída do bloco CNeuronTEMPOOCL, obtemos os valores previstos desejados da série temporal analisada. No entanto, adicionaremos o toque final na forma de uma camada de alinhamento das características de frequência da série temporal prevista, denominada CNeuronFreDFOCL.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Como resultado, obtemos uma arquitetura concisa e direta do modelo, composta por três camadas neurais. No entanto, por trás dessa simplicidade aparente, há um algoritmo complexo e detalhado. Sabemos que, sob a superfície do iceberg do CNeuronTEMPOOCL, estão 24 camadas aninhadas, das quais 12 possuem parâmetros treináveis. Além disso, duas dessas camadas aninhadas são blocos de atenção, para os quais definimos uma arquitetura de Self-Attention com quatro camadas e quatro cabeças de atenção em cada uma. Isso torna nosso modelo verdadeiramente profundo e complexo.
Os valores previstos do movimento de preços futuros que obtemos serão utilizados para treinar a política de comportamento do Ator. Aqui, preservamos em grande parte as arquiteturas descritas em artigos anteriores, mas, devido à complexidade do Codificador do estado do ambiente e ao aumento esperado no custo do treinamento, decidimos reduzir o número de camadas aninhadas nos blocos de atenção cruzada das redes do Ator e do Crítico. Lembro que a descrição da arquitetura dessas redes é apresentada no método CreateDescriptions, onde são passados ponteiros para dois arrays dinâmicos. Nesses arrays, registramos a descrição da arquitetura dos modelos.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
No corpo do método, verificamos a validade dos ponteiros recebidos e, se necessário, criamos novas instâncias dos objetos.
rimeiro, descrevemos a arquitetura do Ator, para a qual passamos como entrada um tensor que descreve o estado da conta.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Note que aqui estamos falando especificamente da situação da conta, e não do estado do ambiente. O termo "estado do ambiente" refere-se aos parâmetros da dinâmica do movimento dos preços e dos indicadores analisados. Já o termo "estado da conta" abrange o valor atual do saldo, o volume e a direção das posições abertas, bem como o lucro ou prejuízo acumulado nelas.
As informações recebidas como entrada no modelo são transformadas em um estado oculto por meio de uma camada totalmente conectada básica.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, utilizamos um bloco de cross-attention, no qual comparamos o estado atual da conta com o valor previsto do movimento de preços futuros, obtido a partir do Codificador do estado do ambiente.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } { int temp[] = {4, 2}; ArrayCopy(descr.heads, temp); } descr.layers = 4; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Aqui, é importante destacar um detalhe: o subespaço dos valores recebidos do Codificador do estado da conta. Sim, utilizamos exatamente a mesma abordagem anteriormente, e isso não nos preocupou naquela ocasião. O que mudou?
O "diabo está nos detalhes". Anteriormente, utilizávamos uma camada de normalização em lote na entrada do Codificador do estado do ambiente para padronizar os dados brutos. Na saída do modelo, utilizávamos a camada CNeuronRevINDenormOCL para realizar a operação inversa, ou seja, retornar os dados ao subespaço original. Para os objetivos do Ator e do Crítico, trabalhávamos com o valor oculto das previsões em um formato comparável antes das operações de deslocamento e escalonamento para os subespaços dos dados brutos. Dessa maneira, obtínhamos dados comparáveis para análise subsequente, com os quais o modelo estava acostumado a trabalhar.
No caso do CNeuronTEMPOOCL, optamos por não realizar a normalização preliminar dos dados brutos, conforme discutido anteriormente. Contudo, na saída do modelo, espera-se obter valores não normalizados do movimento de preços previsto, o que pode complicar o trabalho do Ator e do Crítico. Como consequência, a eficácia pode ser reduzida. Uma solução possível seria a normalização preliminar dos valores previstos da série temporal antes de seu uso subsequente. A forma mais simples de fazer isso seria criar um pequeno modelo adicional de pré-processamento de dados com uma única camada de normalização. Entretanto, não adotamos essa abordagem.
Gostaria de lembrar que, na saída do bloco CNeuronTEMPOOCL, em vez de simplesmente somar os valores previstos das três componentes (tendência, sazonalidade e outros), utilizamos uma camada convolucional sem função de ativação, que substitui a soma simples por uma soma ponderada dos dados obtidos.
if(!cSum.Init(0, 24, OpenCL, 3, 3, 1, iVariables, iForecast, optimization, iBatch)) return false; cSum.SetActivationFunction(None);
Além disso, a limitação dos valores máximos dos parâmetros do modelo para menos de 1 nos permite excluir valores excessivamente altos na saída do modelo.
#define MAX_WEIGHT 1.0e-3f
Claro, esse método limita intencionalmente a precisão do nosso Codificador do estado do ambiente. Afinal, como comparar, por exemplo, os valores reais do indicador RSI (cujo intervalo varia de 0 a 100) com os resultados previstos, cujos valores absolutos são menores que 1? Nesse caso, ao utilizar o MSE como função de perda, há uma grande probabilidade de obter valores previstos próximos do máximo possível. Por isso, adicionamos à saída do Codificador do estado do ambiente o bloco de alinhamento de frequências CNeuronFreDFOCL, que é menos sensível ao escalonamento dos dados. Isso permitirá que o modelo aprenda a estrutura do movimento futuro dos preços, que é mais importante do que os valores absolutos.
Aqui, devo admitir que a solução proposta não é evidente e, até certo ponto, pode ser difícil de compreender. Avaliaremos sua eficácia com base nos resultados práticos obtidos por nossos modelos.
Voltando à arquitetura do nosso Ator, após o bloco de cross-attention, usamos um perceptron com três camadas totalmente conectadas para a tomada de decisão.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Na saída, adicionamos um elemento de aleatoriedade à política do nosso Ator.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Também ajustamos as características de frequência da decisão tomada.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A arquitetura do Crítico é quase idêntica à arquitetura do Ator apresentada acima. Há apenas pequenas diferenças. Em particular, em vez de fornecer o estado da conta como entrada, passamos o tensor das ações do Ator.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Na saída do modelo, não utilizamos estocasticidade, fornecendo uma avaliação clara das ações propostas.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
O código completo da solução arquitetônica de todos os modelos utilizados está disponível no anexo.
2. Treinamento dos modelo
Como pode ser observado na descrição apresentada acima sobre a solução arquitetônica dos modelos treináveis, a implementação das abordagens do método TEMPO não alterou a estrutura dos dados brutos ou dos resultados das previsões dos modelos. Assim, podemos utilizar sem restrições as amostras de treinamento coletadas anteriormente para o treinamento inicial dos modelos. Além disso, podemos continuar coletando dados para as amostras de treinamento, treinar os modelos e atualizar as amostras utilizando os programas já desenvolvidos para interação com o ambiente e treinamento de modelos.
Lembro que, para a interação com o ambiente e a coleta de dados para as amostras de treinamento, utilizamos dois programas:
- "...\Experts\TEMPO\ResearchRealORL.mq5" — utilizado para coletar dados com base no histórico de transações reais. O método é descrito em detalhes no artigo mencionado no link.
- "...\Experts\TEMPO\Research.mq5" — este EA é principalmente destinado a analisar a eficácia de uma política previamente treinada e atualizar os dados da amostra de treinamento com base no ambiente da política atual. Isso permite, posteriormente, ajustar de forma mais precisa a política do Ator com base em recompensas reais por suas ações. No entanto, esse EA também pode ser usado para coletar o conjunto inicial de dados de treinamento com base em uma política de comportamento do Ator inicializada com parâmetros aleatórios.
Independentemente de já termos ou não dados coletados previamente de interações com o ambiente, podemos executar no testador de estratégias do MetaTrader 5 qualquer um dos EAs mencionados acima para criar uma nova amostra de treinamento ou atualizar uma existente.
Os dados coletados para a amostra de treinamento são inicialmente usados para treinar o modelo do Codificador do estado do ambiente, focado na previsão do movimento de preços subsequente. Para isso, executamos em tempo real no MetaTrader 5 o EA "...\Experts\TEMPO\StudyEncoder.mq5".
Nesse contexto, é importante destacar que, durante o treinamento, o Codificador do estado do ambiente trabalha apenas com os parâmetros da dinâmica do movimento de preços e os indicadores analisados, que não são influenciados pelas ações do Agente. Portanto, todas as passagens pela amostra de treinamento em um mesmo intervalo histórico são idênticas para o modelo. Assim, durante o treinamento do Codificador, a atualização da amostra de treinamento não fornecerá informações adicionais. Por conseguinte, devemos ter paciência e treinar o modelo até obter os resultados desejados.
Mais uma vez, gostaria de lembrar que, devido às particularidades da nossa solução arquitetônica, discutidas anteriormente, nesta etapa não esperamos valores baixos de erro. No entanto, buscamos alcançar os resultados possíveis mínimos. Encerramos o processo de treinamento do modelo quando o erro de previsão se estabiliza em um intervalo estreito.
Na segunda etapa, realizamos o treinamento iterativo das redes do Ator e do Crítico. Nesta fase, utilizamos o EA "...\Experts\TEMPO\Study.mq5", que também é executado em tempo real. Desta vez, "congelamos" os parâmetros do Codificador do estado do ambiente e treinamos dois modelos em paralelo (Ator e Crítico).
Com base nos dados da amostra de treinamento, o Crítico aprende a função de recompensa do ambiente, relacionando o estado previsto do ambiente e as ações do Agente na amostra de treinamento para prever a recompensa do ambiente. Essa etapa segue os princípios do aprendizado supervisionado, pois as recompensas reais pelas ações realizadas estão salvas na amostra de treinamento.
Depois, o Ator, com base nas "orientações" fornecidas pelo Crítico, otimiza sua política para maximizar o retorno total.
Esse processo é iterativo, pois, durante o treinamento, o subespaço de ações do Ator se desloca. Portanto, é necessário atualizar a amostra de treinamento para obter recompensas reais no novo subespaço. Isso permite que o Crítico ajuste a função de recompensa e forneça uma avaliação mais precisa das ações do Ator. Por sua vez, isso possibilita que o Ator ajuste sua política na direção correta.
Para atualizar a amostra de treinamento, repetimos o processo de otimização lenta com o EA "...\Experts\TEMPO\Research.mq5".
Nesta etapa, pode surgir a questão sobre a utilidade de treinar o Codificador do estado da conta separadamente dos outros modelos. Por um lado, o Codificador do estado da conta, previamente treinado, nos fornece a previsão mais provável do movimento subsequente do mercado, funcionando como um filtro digital que reduz o ruído presente nos dados brutos. Ao mesmo tempo, utilizamos um horizonte de planejamento significativamente inferior à profundidade do histórico analisado. Assim, o Codificador também comprime os dados para análise posterior. Isso, em geral, potencialmente melhora a eficiência do Ator e do Crítico.
Por outro lado, até que ponto precisamos de uma previsão precisa do movimento futuro dos preços? Afinal, como já dissemos várias vezes, o mais importante para nós é a interpretação clara do estado atual, que permite escolher a ação ideal para o Agente com máxima precisão. Para responder a essa pergunta, criamos outro EA de treinamento de modelos: "...\Experts\TEMPO\Study2.mq5". Este programa foi desenvolvido com base no EA "...\Experts\TEMPO\Study.mq5", e, por isso, analisaremos apenas o método de treinamento direto dos modelos, chamado Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false;
No corpo do método, começamos gerando um vetor de probabilidades de escolha de trajetórias a partir do buffer de reprodução de experiência, com base na rentabilidade total dos ciclos. Em seguida, inicializamos as variáveis locais necessárias.
Com isso, concluímos o trabalho preparatório e organizamos o ciclo de treinamento direto dos modelos.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum() == 0) { iter --; continue; }
No corpo do ciclo, amostramos uma trajetória do buffer de reprodução de experiência e selecionamos aleatoriamente um estado do ambiente dentro dela.
Transferimos a descrição do estado selecionado do ambiente, retirada da amostra de treinamento, para o buffer de dados e realizamos a propagação no Codificador do estado do ambiente.
bState.AssignArray(state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Depois, recuperamos do buffer de reprodução de experiência as ações do Agente realizadas no estado selecionado durante a interação com o ambiente e avaliamos essas ações com o Crítico.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite(); Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Note que no buffer de reprodução de experiência há uma avaliação factual dessas ações, o que nos permite ajustar a função de recompensa aprendida pelo Crítico para minimizar o erro. Para isso, extraímos do buffer a recompensa real obtida e realizamos a propagação reversa no Crítico.e reprodução de experiência. Simultaneamente, ajustamos os parâmetros do Codificador do estado do ambiente para destacar os pontos dos dados brutos que impactam a eficácia da política do Ator. Na segunda etapa do treinamento da política do Ator, pediremos ao Crítico que indique a direção para ajustar as ações do Agente, visando aumentar a rentabilidade ou reduzir perdas em 1%. Para isso, utilizamos a avaliação atual das ações do Ator e a aprimoramos em 1%. O resultado obtido será usado como referência para a propagação reversa no Crítico. Lembro que, nesta etapa, o processo de treinamento do Crítico foi desativado. Portanto, durante a propagação reversa, os parâmetros do Crítico não serão ajustados. No entanto, o Ator receberá o gradiente do erro, o que permitirá ajustes em seus parâmetros para melhorar a eficiência de sua política. Depois disso, apenas informamos o usuário sobre o progresso do treinamento dos modelos e passamos para a próxima iteração do ciclo. Ao finalizar o processo de treinamento, limpamos o campo de comentários no gráfico do instrumento. Registramos no log do terminal os resultados do treinamento dos modelos e iniciamos o processo de encerramento do programa. O código completo deste EA, assim como de todos os programas utilizados na preparação deste artigo, está disponível no anexo. 3. Teste Após concluir o trabalho, chegamos ao momento culminante: a avaliação prática dos resultados dos modelos treinados. Lembro que os modelos foram treinados com dados históricos de todo o ano de 2023 para o instrumento EURUSD no intervalo de tempo H1. Os parâmetros de todos os indicadores analisados foram utilizados com seus valores padrão. O teste dos modelos treinados foi realizado com dados históricos de janeiro de 2024, mantendo todos os outros parâmetros inalterados.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Nesta etapa, adicionamos também a propagação reversa no Codificador do estado do ambiente para destacar pontos de referência nos dados, permitindo que o modelo faça avaliações mais precisas das ações.
O próximo passo é ajustar a política do Ator. Primeiro, a partir do buffer de reprodução de experiência, preparamos uma descrição do estado da conta correspondente ao estado do ambiente selecionado anteriormente.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Em seguida, realizamos a propagação do Ator para gerar um vetor de ações com base na política atual.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Depois disso, desativamos o modo de treinamento do Crítico e avaliamos as ações geradas pelo Ator.
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A política do Ator será ajustada em duas etapas. Primeiro, verificaremos a eficácia da trajetória atual. Se, durante a interação com o ambiente, a trajetória resultar em lucro, ajustamos a política do Ator de modo a executar as ações armazenadas no buffer de experiência.
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Simultaneamente, ajustamos os parâmetros do Codificador do estado do ambiente para destacar os pontos dos dados brutos que impactam a eficácia da política do Ator.
Na segunda etapa do treinamento da política do ATOR, pediremos ao CRÍTICO que indique a direção para ajustar as ações do Agente, visando aumentar a rentabilidade ou reduzir perdas em 1%. Para isso, utilizamos a avaliação atual das ações do Ator e a aprimoramos em 1%.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
O resultado obtido será usado como referência para a propagação reversa no Crítico. Lembro que, nesta etapa, o processo de treinamento do Crítico foi desativado. Portanto, durante a propagação reversa, os parâmetros do Crítico não serão ajustados. No entanto, o Ator receberá o gradiente do erro, o que permitirá ajustes em seus parâmetros para melhorar a eficiência de sua política.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Depois disso, apenas informamos o usuário sobre o progresso do treinamento dos modelos e passamos para a próxima iteração do ciclo.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Ao finalizar o processo de treinamento, limpamos o campo de comentários no gráfico do instrumento.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Registramos no log do terminal os resultados do treinamento dos modelos e iniciamos o processo de encerramento do programa.
O código completo deste EA, assim como de todos os programas utilizados na preparação deste artigo, está disponível no anexo.
3. Teste
Após concluir o trabalho, chegamos ao momento culminante: a avaliação prática dos resultados dos modelos treinados.
Lembro que os modelos foram treinados com dados históricos de todo o ano de 2023 para o instrumento EURUSD no intervalo de tempo H1. Os parâmetros de todos os indicadores analisados foram utilizados com seus valores padrão.
O teste dos modelos treinados foi realizado com dados históricos de janeiro de 2024, mantendo todos os outros parâmetros inalterados. Dessa forma, foi possível atingir uma aproximação máxima das condições de uso real dos modelos.
Na primeira etapa, treinamos o modelo do Codificador do estado do ambiente. Abaixo, apresentamos o gráfico de visualização do movimento de preços real e previsto para as próximas 24 horas, com uma nova previsão a cada passo. Isso corresponde ao movimento das próximas 24 horas no intervalo de tempo H1, o mesmo utilizado para análise.
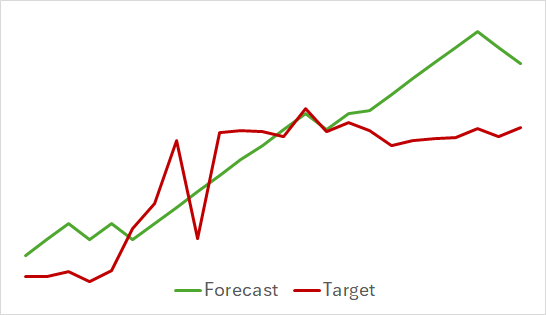
No gráfico apresentado, é possível observar que o movimento previsto captou, de forma geral, a direção principal do movimento futuro. É possível notar até coincidências em termos de tempo e direção de alguns extremos locais. Porém, o gráfico do movimento previsto é mais suave e se assemelha a linhas de tendência traçadas sobre o movimento de preços do instrumento.
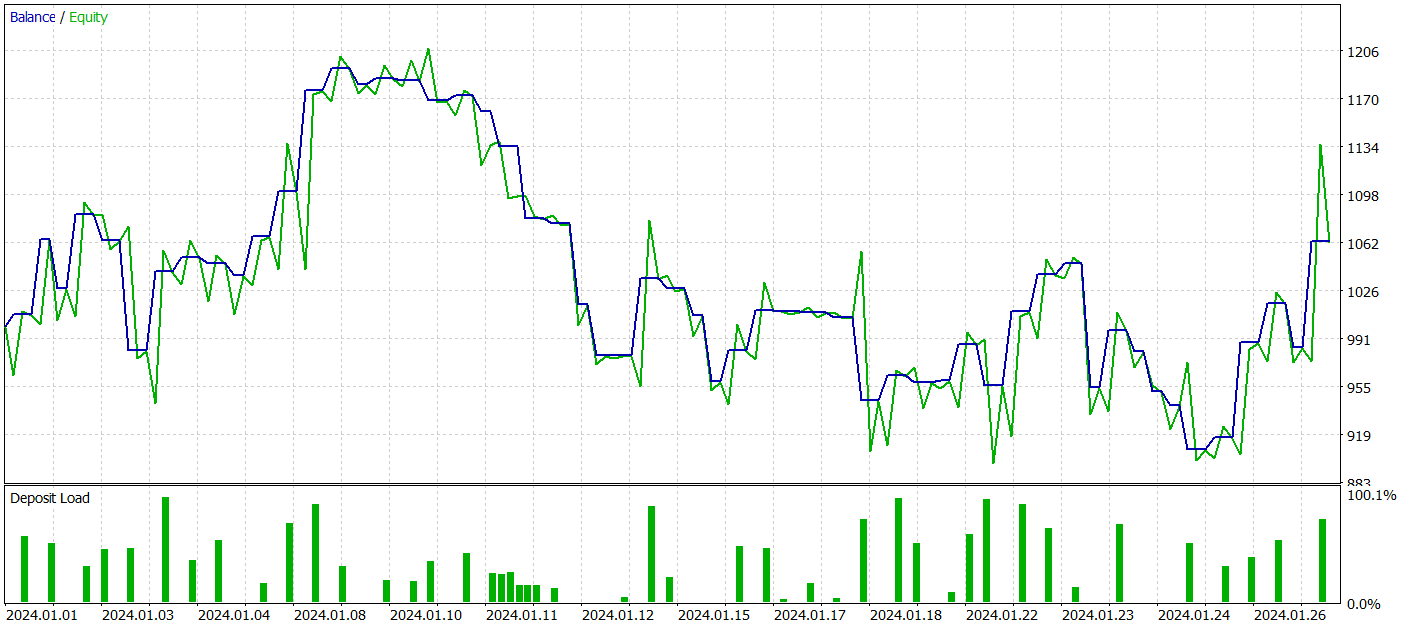
Na segunda etapa, treinamos os modelos do Ator e do Crítico. Não nos concentraremos na qualidade da avaliação das ações pelo Crítico, pois sua principal função é orientar o treinamento da política do Ator na direção correta. Vamos examinar a rentabilidade da política aprendida pelo Ator no intervalo de tempo de teste. Abaixo, estão apresentados os resultados das ações do Ator no testador de estratégias.
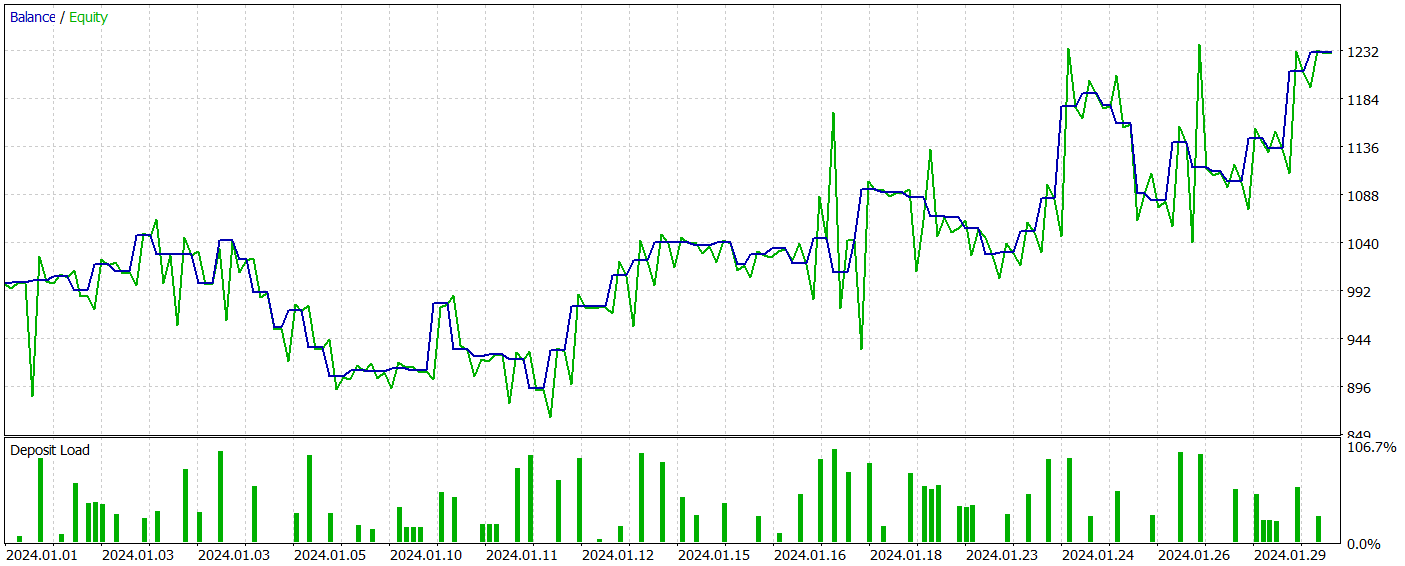
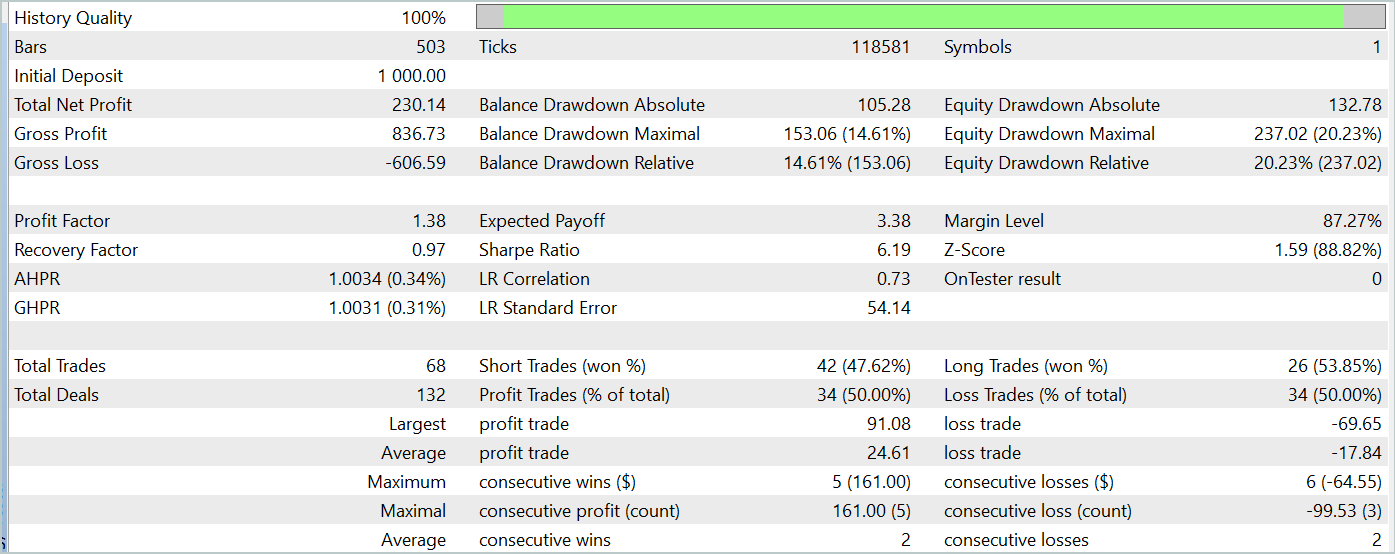
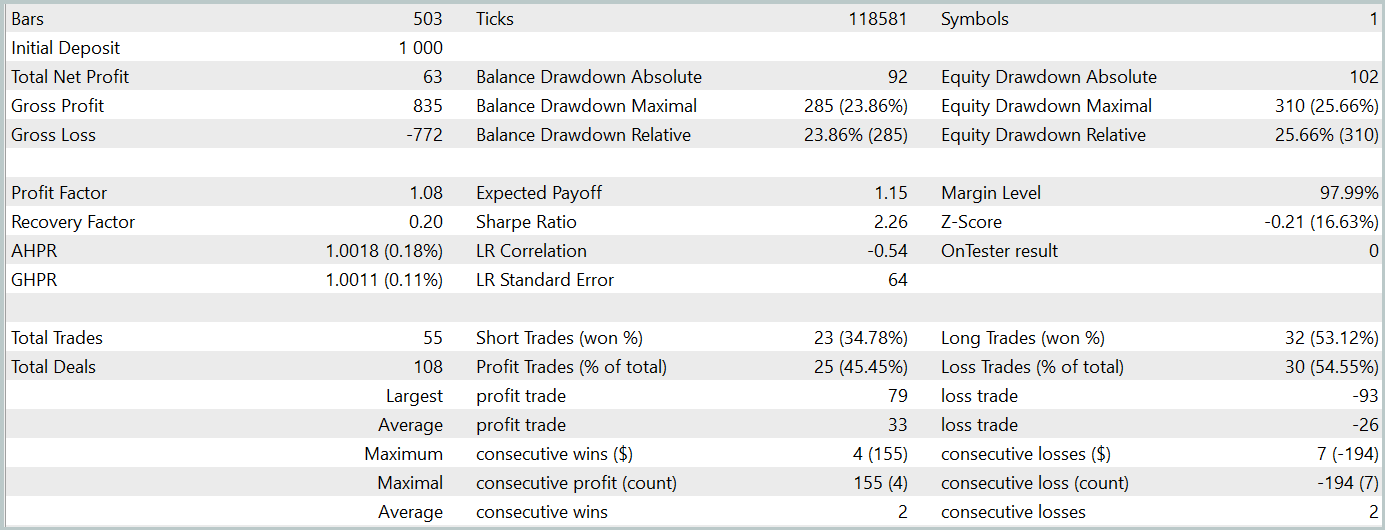
Durante o período de teste (janeiro de 2024), o Ator realizou 68 transações, das quais metade foi encerrada com lucro. Graças ao fato de o lucro máximo e o lucro médio por transação terem superado os respectivos valores negativos (-69,85 e -17,84, em comparação com 91,08 e 24,61, respectivamente), o modelo alcançou uma rentabilidade de 23%.
No entanto, no gráfico do saldo, é possível observar picos significativos no patrimônio, tanto acima quanto abaixo da linha de saldo. A primeira impressão é de "prolongamento de perdas" e saídas tardias de posições. Contudo, ao notar que, nesses momentos, a utilização do depósito está próxima de 100%, surge a suspeita de riscos excessivos. Esse ponto é reforçado pela retração máxima no patrimônio, que ultrapassou 20%.
Como etapa seguinte, realizamos um treinamento adicional da política do Ator, ajustando os parâmetros do Codificador do estado do ambiente. É importante destacar que esse treinamento adicional foi realizado sem atualizar a amostra de treinamento, ou seja, a base de dados não foi alterada. Contudo, esse treinamento teve um impacto negativo. A eficiência do modelo diminuiu: o número de transações realizadas foi reduzido, a proporção de operações lucrativas caiu para 45%, a rentabilidade geral do modelo diminuiu e a retração do patrimônio ultrapassou 25%.
Vale notar que também houve mudanças na qualidade das previsões das trajetórias futuras do movimento dos preços.
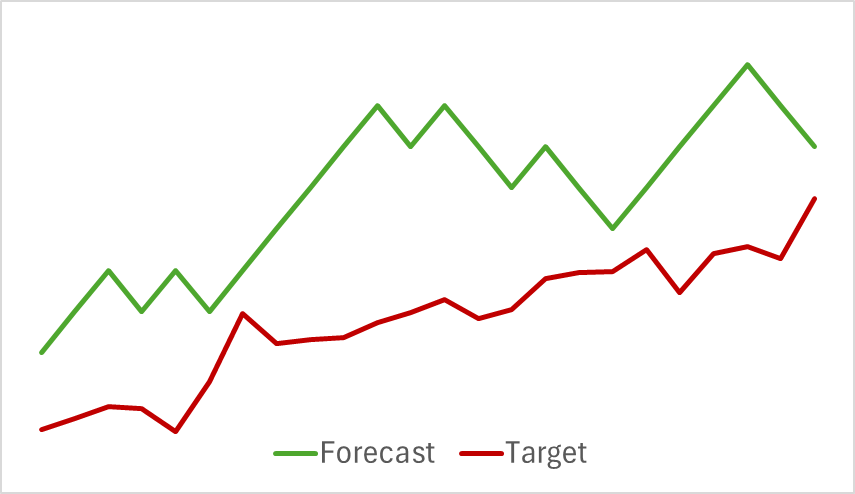
Minha opinião é que, ao começar a otimizar os parâmetros do Codificador do estado do ambiente para os objetivos do Ator e do Crítico, adicionamos ruído à saída do Codificador. Durante o treinamento para a previsão do movimento futuro, havia uma correspondência clara entre os dados brutos e os resultados. O modelo aprendia e generalizava essas relações. Contudo, o gradiente de erro recebido do Ator e do Crítico introduz um ruído contraditório quando o modelo tenta minimizar seu erro com base nos dados brutos fornecidos pelo Codificador do estado do ambiente. Como resultado, o Codificador deixa de desempenhar seu papel como filtro dos dados brutos, o que leva a uma redução na eficiência dos modelos em todos os aspectos.
Considerações finais
Exploramos um método interessante e complexo de previsão de séries temporais, o TEMPO, no qual os autores propõem o uso de modelos linguísticos pré-treinados para resolver problemas de previsão de séries temporais. O algoritmo implementa uma nova abordagem na decomposição de séries temporais, melhorando a eficiência na representação dos dados brutos durante o treinamento.
Realizamos um trabalho significativo na implementação das abordagens propostas utilizando os recursos do MQL5. E, apesar de não termos à disposição um modelo linguístico pré-treinado, os experimentos resultaram em descobertas bastante interessantes.
De maneira geral, as abordagens propostas podem ser aplicadas na construção de modelos de trading reais. No entanto, é importante estar preparado para o fato de que o treinamento de modelos que utilizam a arquitetura Transformer exige a coleta prévia de grandes volumes de dados e pode demandar muitos recursos durante o processo de aprendizado.
Referências
- TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de Modelos |
| 4 | StudyEncoder.mq5 | Expert Advisor | EA para treinamento do Codificador |
| 5 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
| 9 | Estudo2.mq5 | Expert Advisor | EA para treinamento de modelos do Ator e do Crítico com ajuste de parâmetros do Codificador |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/15469
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Atitude em relação aos usuários
Claramente
Somente para aqueles que acham que o autor deve algo a ele.....
O golpista também não deve nada a ninguém.
Mas as pessoas caem no golpe por algum motivo.
Se os artigos não contiverem gatilhos e motivações flagrantes como "...o modelo é capaz de gerar lucro", então está tudo bem. Nossos problemas.
E quando informações não testadas são manipuladas, isso não é realmente problema nosso.
Considerando que o primeiro usuário foi banido por criticar, eu também vou acabar de vez. Você pode contra-argumentar com contra-argumentos, eu deixarei melhor sem resposta.
...Se os artigos não contivessem gatilhos e motivação flagrante como "...o modelo é capaz de gerar lucros", tudo bem. Nossos problemas.
E quando eles manipulam informações não testadas - não são realmente nossos problemas....
Em um artigo de Dmitry nos comentários, pedi a ele que escrevesse um artigo especificamente sobre o treinamento de seus Expert Advisors. Ele poderia pegar qualquer um de seus modelos de qualquer artigo e explicar completamente no artigo como ele o ensina. Do zero até o resultado, em detalhes, com todas as nuances. O que observar, em que sequência ele ensina, quantas vezes, em que equipamento, o que ele faz se não aprender, que erros ele observa. Aqui está o máximo de detalhes possível sobre o treinamento no estilo "para manequins". Mas Dmitry, por algum motivo, ignorou ou não notou essa solicitação e não escreveu esse artigo até agora. Acredito que muitas pessoas ficarão gratas a ele por isso.
Dmitry, escreva um artigo desse tipo, por favor.
Há um livro de Dmitry - Conheça o livro "Neural Networks in Algorithm Trading in MQL5 "