
取引におけるニューラルネットワーク:TEMPO法の実践結果

はじめに
前回の記事では、事前訓練済みの言語モデルを使用して時系列予測問題を解決する独自のアプローチを提案するTEMPO法の理論的側面について説明しました。ここで、提案されたアルゴリズムの主な革新について簡単に振り返ってみましょう。
TEMPO法は、事前に訓練された言語モデルの使用に基づいて構築されています。特に、この手法の著者は、実験で事前訓練済みのGPT-2を使用しています。このアプローチの主なアイデアは、予備訓練中に得られたモデルの知識を使用して時系列を予測することにあります。もちろん、ここで、スピーチと時系列の間に、明らかではない類似点を描くことは価値があります。本質的に、スピーチとは文字を使用して記録された音の時系列です。句読点によって異なるイントネーションが伝えられます。
GPT-2などの大規模言語モデル(LLM)は、大規模なデータセット(多くの場合、複数の言語)で事前訓練され、時系列予測に使用したい単語の時間的シーケンスにおける多数の異なる依存関係を学習しました。しかし、文字や単語の順序は、分析対象の時系列データとは大きく異なります。私たちは常に、あらゆるモデルを正しく動作させるためには、訓練データセットとテストデータセット内のデータの分布を維持することが非常に重要であると述べてきました。これは、モデルの操作中に分析されるデータにも関係します。どのような言語モデルも、私たちが慣れ親しんでいる純粋な形式のテキストでは機能しません。まず、埋め込み(エンコード)段階を経て、テキストが特定の数値コード(非表示状態)に変換されます。次に、モデルはこのエンコードされたデータに対して動作し、出力段階で後続の文字と句読点の確率を生成します。最も可能性の高い銘柄を使用して、人間が読めるテキストが構築されます。
TEMPO法はこの特性を活用します。時系列予測モデルの訓練プロセス中、言語モデルのパラメータは「固定」され、モデルと互換性のある埋め込みへの元のデータの変換パラメータが最適化されます。TEMPO法の著者は、モデルが有用な情報に最大限にアクセスできるようにするための包括的なアプローチを提案しています。まず、分析された時系列は、トレンド、季節性などの基本的な要素に分解されます。次に、各成分はセグメント化され、言語モデルが解釈できる埋め込みに変換されます。モデルを望ましい方向(トレンドや季節性の分析など)にさらに導くために、著者らは「ソフトプロンプト」のシステムを導入しています。
全体として、このアプローチによりモデルの解釈可能性が向上し、さまざまな成分が将来の値の予測にどのように影響するかをよりよく理解できるようになります。
この手法のオリジナルの視覚化を以下に示します。
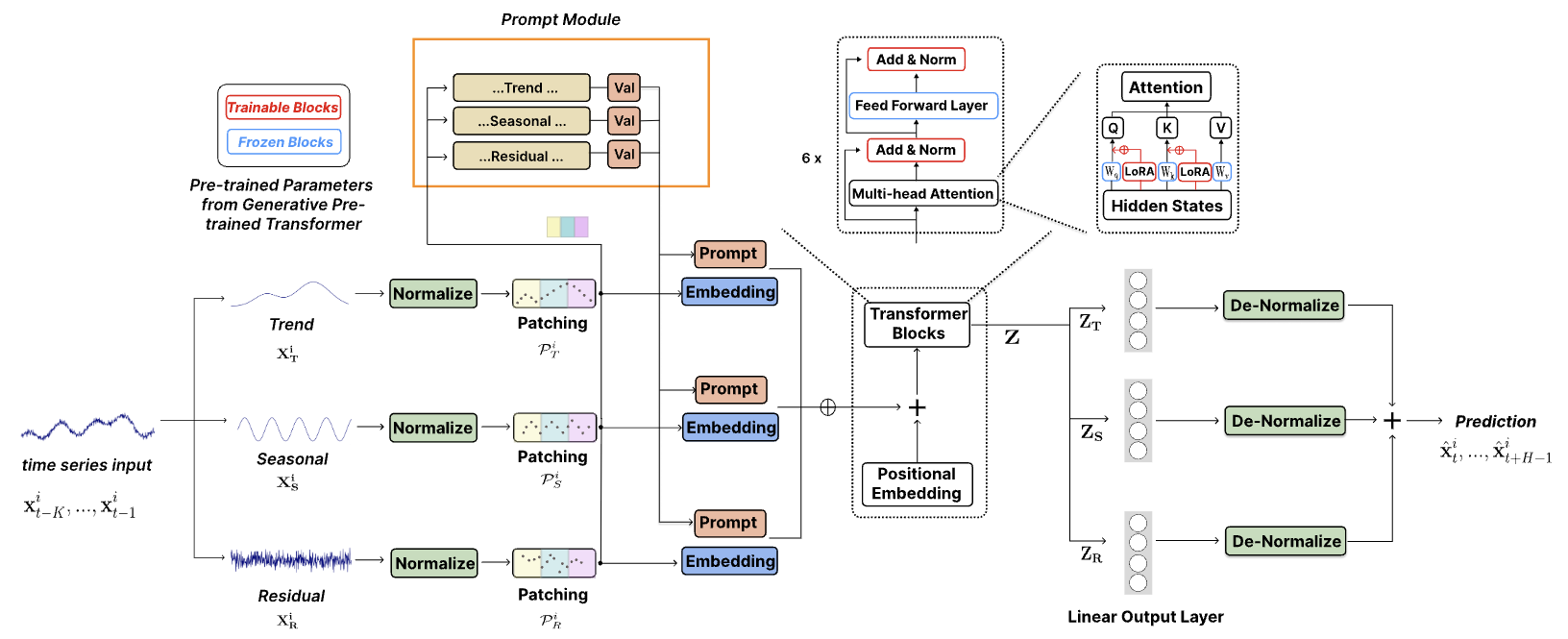
1.モデルアーキテクチャ
提案されたモデルアーキテクチャは非常に複雑で、出力で集約される複数のブランチと並列データストリームが組み込まれています。このようなアルゴリズムを既存の線形モデルフレームワーク内に実装することには、大きな課題がありました。これに対処するために、私たちはアルゴリズム全体を単一のモジュール内にカプセル化し、実質的に単一層実装として機能する統合アプローチを開発しました。このアプローチでは、モジュールの構造的柔軟性がCNeuronTEMPOOCLクラスのInitメソッドのパラメータによって制約されるため、ユーザーがさまざまなモデルの複雑さを試す能力が多少制限されますが、新しいモデルを構築するプロセスも大幅に簡素化されます。ユーザーは、アーキテクチャの複雑な詳細を詳しく調べる必要はありません。代わりに、堅牢で洗練されたモデルアーキテクチャを構築するために、いくつかの重要なパラメータを指定するだけで済みます。私たちの見解では、このトレードオフは大多数のユーザーにとってより現実的です。
さらに、考慮すべき重要な点の1つは、TEMPO法の作成者が、事前に訓練されたGPT-2言語モデルを使用して実験を実施したことです。これをPythonで実装する場合、このようなモデルにはHuggingFaceなどのライブラリを介してアクセスできます。ただし、私たちの実装では、事前訓練済みの言語モデルは使用しません。代わりに、メインモデルと一緒に訓練されるクロスアテンションブロックに置き換えます。
TEMPO法は時系列予測モデルとして位置付けられます。したがって、同様のケースと同様に、提案された手法を環境状態エンコーダーモデルに統合します。このモデルのアーキテクチャは、CreateEncoderDescriptionsメソッドで定義されます。
このメソッドのパラメータ内で、生成されたモデルのニューラル層のアーキテクチャパラメータが格納される動的配列へのポインタを渡します。
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
メソッド本体では、受信したポインタの関連性をチェックし、必要に応じてオブジェクトの新しいインスタンスを作成します。
続いてモデルの説明が続きます。まず、入力データを記録するための全結合層を指定します。作成された層のサイズは、入力データテンソルのサイズと一致する必要があります。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
念のため、モデルは端末から取得されたとおりの元の形式で生の入力データのテンソルを受け取ります。これまでのすべてのモデルでは、次のステップではバッチ正規化層を適用して予備的なデータ処理を実行し、値を比較可能なスケールにしていました。
ただし、この場合は、バッチ正規化層を意図的に除外しています。驚くべきことに、この決定はTEMPO法自体のアーキテクチャに由来しています。上記の視覚化に示されているように、生データはすぐに分解ブロックに送られ、分析された時系列はトレンド、季節性、残差という3つの基本成分に分解されます。この分解は、単変量時系列ごとに、つまり、多峰性時系列の分析されたパラメータごとに独立しておこなわれます。各単変量系列内の値の比較可能性は、データの性質によって本質的に保証されます。
まず、生データからトレンド成分を抽出します。私たちの実装では、時系列の区分線形表現を使用してこれを実現します。ご存知のとおり、この方法のアルゴリズムにより、正規化中に通常発生する生データ分布のスケーリングやシフトに関係なく、比較可能なセグメントを抽出できます。
次に、元のデータからトレンド成分を差し引いて季節成分を決定します。これは離散フーリエ変換を使用して実現されます。離散フーリエ変換は信号を周波数スペクトルに分解し、振幅に基づいて最も重要な周期的な依存関係を識別できるようにします。トレンド抽出と同様に、頻度分解もデータのスケーリングやシフトの影響を受けません。
最後に、元のデータから以前に抽出された2つの成分を減算することで、残差成分が得られます。
この時点で、モデル設計の観点から、予備的なデータ正規化によって追加の利点が得られないことが明らかになります。さらに、この段階で正規化を適用すると、余分な計算オーバーヘッドが発生し、それ自体が望ましくありません。
さて、次の段階を考えてみましょう。TEMPO法の著者は、抽出された成分の正規化を導入しています。これは、マルチモーダルデータを使用した後続の操作に明らかに不可欠です。次のような疑問が生じます。正規化アプローチを変更することはできるでしょうか。具体的には、分解前に生の入力データを正規化し、個々の成分の正規化を省略することは可能でしょうか。結局のところ、生のデータの量は、抽出された成分の合計サイズよりも3倍小さくなります。私の見解では、答えはおそらく「できない」です。
説明のために、抽象的な時系列グラフを取り上げて、その主なトレンドを強調してみましょう。トレンド成分が情報の大部分を包含していることは明らかです。
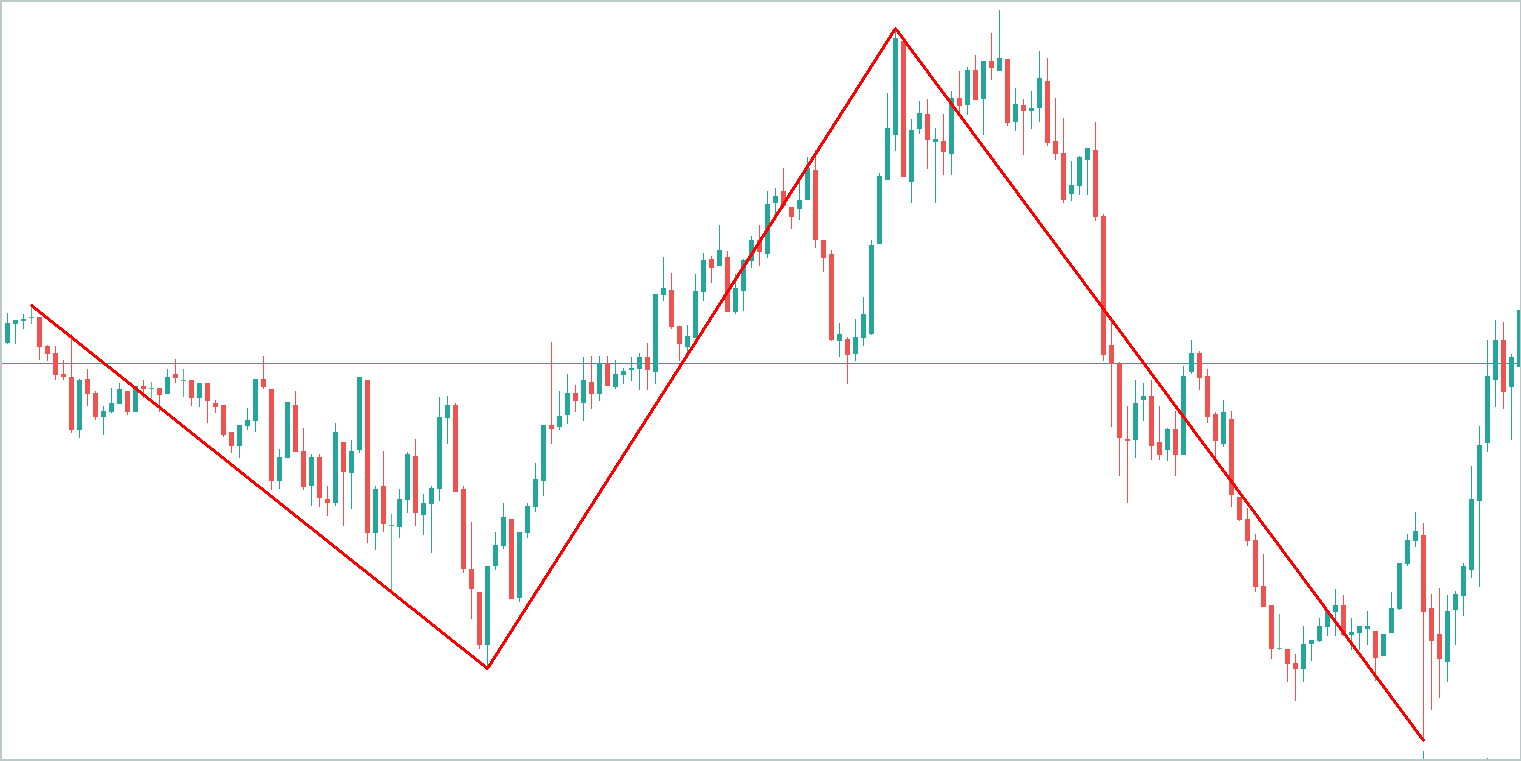
季節的要素はトレンドラインの周りの波のような変動で構成され、その振幅はトレンド自体よりも大幅に低くなります。
その他の変動を表す残差成分の振幅はさらに低く、主にノイズを反映しています。ただし、このノイズは、ニュースイベントや非体系的な性質を示すその他の説明できない要因などの外部の影響を捉えているため、無視することはできません。
分解前に生データを正規化することで、個々の単変量系列間の比較可能性の問題に対処できます。しかし、抽出された成分自体の比較可能性の問題は解決されません。したがって、モデルの安定性のためには、分解後に成分レベルで正規化を適用することが望ましいです。
この理由に基づいて、生の入力データに対してバッチ正規化層を除外します。代わりに、入力データ層の直後に新しいTEMPO法ブロックを導入します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTEMPOOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = NForecast;
分析されたマルチモーダルシーケンスのサイズ、その中のユニタリ時系列の数、および計画期間を、以前に指定した定数を使用して指定します。
この記事を準備する際の実験の一環として、4つのアテンションヘッドを指定しました。
descr.window_out = 4;
また、アテンションブロックに4つのネストされた層を設定しました。
descr.layers = 4;
ここで、これらのパラメータが2つのネストされた注意ブロックで使用されることに注意してください。
- 個々の単位シーケンスの周波数特性間の依存関係を識別するために使用される周波数領域アテンションブロック
- 時系列のシーケンス内の依存関係を検出するためのクロスアテンションブロック
次に、正規化バッチサイズとモデルの最適化方法を指定します。
descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
この時点で、CNeuronTEMPOOCLブロックの出力で、分析された時系列の目的の予測値が得られるため、モデルは完了したと見なすことができます。しかし、最後の仕上げとして、予測時系列CNeuronFreDFOCLの周波数マッチング層を追加します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
その結果、3つのニューラル層からなる短く簡潔なモデルアーキテクチャが得られます。しかし、その下には複雑に統合されたアルゴリズムが存在します。結局のところ、私たちは「氷山の一角」であるCNeuronTEMPOOCLの下にあるものを知っています。24個のネストされた層が隠されており、そのうち12個には訓練可能なパラメータが含まれています。さらに、これらのネストされた層のうち2つはアテンションユニットであり、それぞれに4つのアテンションヘッドを持つ4層の自己アテンションアーキテクチャの作成を指定しました。これにより、私たちのモデルは実に複雑かつ奥深いものになります。
得られた今後の価格変動の予測値を使用して、Actorの行動方策を訓練します。ここでは、前回の記事のアーキテクチャをほぼそのまま維持していますが、環境状態エンコーダーの複雑さと、それを訓練するためのコストの増加が予想されるため、ActorモデルとCriticモデルのクロスアテンションブロック内のネストされた層の数を減らすことにしました。念のため、これらのモデルのアーキテクチャの説明はCreateDescriptionsメソッドで示されており、そのパラメータで2つの動的配列へのポインタを渡します。したがって、モデルのアーキテクチャの説明をこれらの配列に書き込みます。
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
メソッド本体では、受け取ったポインタの妥当性を確認し、必要であればオブジェクトの新しいインスタンスを生成します。
まず、口座の状態を記述するテンソルを入力するActorアーキテクチャについて説明します。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
ここでは環境ではなく口座の状態について説明していることに注意してください。「環境の状態」という用語は、価格変動ダイナミクスと分析された指標のパラメータを意味します。「口座の状態」には、口座残高の現在の値、オープンポジションの量と方向、およびそれらに蓄積された利益または損失が含まれます。
基本的な完全接続層を使用して、モデルの入力時に受信した情報を隠し状態に変換します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次に、クロスアテンションブロックを使用して、現在の口座状態と、環境状態エンコーダーから取得した今後の価格変動の予測値を比較します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } { int temp[] = {4, 2}; ArrayCopy(descr.heads, temp); } descr.layers = 4; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
ここでは、1つの重要な側面、つまり状態スコアエンコーダーから取得されたデータ値のサブスペースに焦点を当てることが重要です。以前にも同じアプローチを採用しましたが、当時は何も懸念はありませんでした。それで、何が変わったのでしょうか?
よく言われるように、「悪魔は細部に宿る」のです。以前は、EnvironmentalStateEncoderの入力でバッチ正規化層を使用して、生データを比較可能な形式に変換していました。モデルの出力では、CNeuronRevINDenormOCL層を適用してこの変換を元に戻し、データを元のサブスペースに復元しました。ActorとCriticについては、シフト操作とスケーリング操作を元のデータサブスペースに適用する前に、比較可能な形式で予測値の隠し表現を操作しました。これにより、その後の分析は一貫性があり解釈可能なデータに依存するようになり、モデルによる処理が容易になりました。
ただし、CNeuronTEMPOOCLの場合、前述したように、入力データの予備的な正規化を意図的に省略しました。その結果、モデルは正規化されていない予測価格変動を出力するようになり、ActorとCriticのタスクが複雑になり、その結果、その有効性が低下する可能性があります。考えられる解決策の1つは、予測された時系列値を後で使用する前に正規化することです。これを実現する最も簡単な方法は、単一の正規化層を持つ小さな前処理モデルを導入することです。ただし、この手順は実装しませんでした。
さらに、CNeuronTEMPOOCLブロックの出力で3つの予測成分(トレンド、季節性など)を単純に合計するのではなく、活性化関数のない畳み込み層を使用したことにも留意してください。これにより、単純な合計が、取得されたデータの加重合計に置き換えられます。
if(!cSum.Init(0, 24, OpenCL, 3, 3, 1, iVariables, iForecast, optimization, iBatch)) return false; cSum.SetActivationFunction(None);
モデルパラメータの最大値を1未満に制限すると、モデル出力で明らかに大きな値を除外できます。
#define MAX_WEIGHT 1.0e-3f
もちろん、このアプローチは本質的に環境状態エンコーダーの精度を制限します。結局のところ、RSI(0~100の範囲)などの実際の指標値を、絶対値が1未満の予測結果とどのように一致させることができるのでしょうか。このような場合、損失関数としてMSEを使用すると、予測値が最大レベルに達する可能性が高くなります。この問題に対処するために、環境状態エンコーダーの出力にCNeuronFreDFOCL周波数アライメントブロックを導入しました。このブロックはデータのスケーリングにあまり影響されず、モデルが今後の価格変動の構造を学習できるようにします。このコンテキストでは、価格変動の構造は絶対値よりも重要です。
提案された解決策はすぐには直感的に理解できるものではなく、理解するのが多少難しいかもしれないことを承知しています。ただし、その有効性は最終的には当社のモデルの実際の結果に基づいて評価されることになります。
さて、Actorのアーキテクチャに戻りましょう。クロスアテンションブロックに続いて、意思決定のために3つの完全に接続された層で構成されたパーセプトロンを採用します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
その出力では、Actorの方策に確率性を追加します。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次に、採用したソリューションの周波数特性を調整します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Criticのアーキテクチャは、上で示したActorアーキテクチャをほぼ完全に繰り返します。わずかな違いがあるだけです。特に、口座の状態ではなく、Actorの行動テンソルをモデルの入力として入力します。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
モデルの出力では確率性は使用せず、提案された行動の明確な評価を提供します。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
使用された全モデルアーキテクチャソリューションの詳細については、添付ファイルをご覧ください。
2.モデル訓練
上記の訓練済みモデルのアーキテクチャの説明からわかるように、TEMPO法の実装によって、元のデータの構造や訓練済みモデルの結果は変更されていません。したがって、以前に収集した訓練データセットを、初期のモデル訓練に自信を持って使用できます。さらに、環境インタラクションとモデル訓練用に以前に開発されたプログラムを使用して、データの収集、モデルの訓練、訓練データセットの更新を継続できます。
環境と対話し、訓練データを収集するために、次の2つのプログラムを使用します。
- ...\Experts\TEMPO\ResearchRealORL.mq5:実際の取引の履歴セットに基づいてデータを収集します。方法論については、参照記事で詳しく説明されています。
- ...\Experts\TEMPO\Research.mq5:事前に訓練された方策のパフォーマンスを分析し、現在の方策環境内で訓練データセットを更新するために主に設計されたEAです。これにより、実際の報酬フィードバックに基づいてActorの方策を微調整できるようになります。ただし、このEAは、ランダムパラメータで初期化されたActorの動作方策に基づいて初期訓練データセットを収集するためにも使用できます。
環境相互作用データがすでに収集されているかどうかに関係なく、MetaTrader 5ストラテジーテスターで上記のいずれかのエキスパートアドバイザー(EA)を起動して、新しい訓練データセットを作成したり、既存のデータセットを更新したりできます。
収集された訓練データは、まず環境状態エンコーダーを訓練して将来の価格変動を予測するために使用されます。このため、MetaTrader 5でリアルタイムモードで...\Experts\TEMPO\StudyEncoder.mq5 EAを実行します。
訓練中、環境状態エンコーダーはエージェントの行動の影響を受けない価格動向と分析された指標のみに基づいて動作することに注意することが重要です。したがって、同じ履歴セグメント上のすべての訓練データセットパスは、モデルに対して同一のままになります。したがって、エンコーダーの訓練中に訓練データセットを更新しても、追加情報は提供されません。したがって、満足のいく結果が得られるまで、忍耐強くモデルを訓練する必要があります。
もう一度強調しておきたいのは、前述のとおり、当社のアーキテクチャアプローチの特性により、現段階では「低い」誤差値は期待できないということです。ただし、予測誤差が狭い範囲内で安定したら訓練プロセスを停止し、誤差を可能な限り最小限に抑えることを目指しています。
2番目の段階では、ActorモデルとCriticモデルの反復的な訓練がおこなわれます。この段階では、リアルタイムモードで実行される...\Experts\TEMPO\Study.mq5 EAを使用します。今回は、EnvironmentalStateEncoderパラメータを「フリーズ」し、2つのモデル(ActorとCritic)を並行して訓練します。
Criticは訓練データセットから環境の報酬関数を学習し、予測された環境状態と訓練データセットからのエージェントの行動をマッピングして、予想される報酬を推定します。この段階では、実行された行動に対する実際の報酬が訓練データセットに保存されるため、教師あり学習の原則に従います。
次に、ActorはCriticからのフィードバックに基づいて方策を最適化し、全体的な収益性を最大化することを目指します。
このプロセスは、訓練中にActorの行動サブスペースが変化するため、反復されます。関連性を維持するには、新しく調整された行動サブスペースで実際の報酬をキャプチャするように訓練データセットを更新する必要があります。これにより、Criticは報酬関数を改良し、Actorの行動をより正確に評価して、方策調整を望ましい方向に導くことができます。
訓練データセットを更新するには、...\Experts\TEMPO\Research.mq5 EAの低速最適化プロセスを再実行します。
この段階では、状態スコアエンコーダーを他のモデルとは別に訓練する必要性について疑問が生じるかもしれません。一方では、事前に訓練された状態スコアエンコーダーは、最も可能性の高い市場の動きを提供し、生データ内のノイズを減らすデジタルフィルターとして効果的に機能します。さらに、分析された履歴の深さよりも大幅に短い計画期間を使用します。つまり、エンコーダーは後続の分析のためにデータも圧縮し、ActorモデルとCriticモデルの効率が向上する可能性があります。
一方で、将来の価格変動の予測は本当に必要でしょうか。以前、より重要なのは現在の状態を明確に解釈し、エージェントが最大限の精度で最適な行動を選択できるようにすることであると強調しました。この疑問を探るために、別の訓練EA ...\Experts\TEMPO\Study2.mq5を開発しました。このプログラムは、...\Experts\TEMPO\Study.mq5に基づいています。したがって、ここでは直接的なモデル訓練方法のみに焦点を当てます。訓練します。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false;
メソッドの本体では、まず、パスの総収益性に基づいて、経験再生バッファから軌道を選択する確率のベクトルを生成します。その後、必要なローカル変数を初期化します。
この時点で準備作業が完了し、モデル訓練ループが整理されます。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum() == 0) { iter --; continue; }
ループ本体では、経験再生バッファから 1 つの軌跡をサンプリングし、その上の環境状態をランダムに選択します。
選択された環境状態の説明を訓練サンプルからデータバッファに転送し、環境状態エンコーダーのフィードフォワードパスを実行します。
bState.AssignArray(state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次に、環境と対話するときに選択された状態で実行されたエージェントの行動を経験再生バッファから取得し、Criticによって評価を実行します。
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite(); Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
経験再生バッファにはこれらの行動の実際の評価が含まれており、誤差を最小限に抑えるためにCriticによって学習された報酬関数を調整できることに注意してください。これをおこなうには、経験再生バッファから実際に受け取った報酬を抽出し、 Criticのバックプロパゲーション パスを実行します。
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
このステップでは、環境状態エンコーダーのバックプロパゲーションパスを追加して、モデルの注意を参照ポイントに向け、より正確な行動推定を可能にします。
次のステップは、Actorの方策を調整することです。まず、経験再生バッファから、以前に選択した環境の状態に対応する口座状態の説明を準備します。
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
現在の方策を考慮して行動ベクトルを生成するために、Actorのフィードフォワードパスを実行します。
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
その後、Criticの訓練モードを無効にして、Actorによって生成された行動を評価します。
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Actorの方策を2段階で調整します。まず、現在のパスの有効性を確認します。環境とのインタラクションの過程で、このパスが有益であることが判明した場合、経験再生バッファに保存されている行動に合わせてActorの行動方策を調整します。
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
同時に、環境状態エンコーダーのパラメータを調整して、Actor方策の有効性に影響を与えるデータポイントを特定します。
Actor方策訓練の第2段階では、エージェントの行動を調整して収益性を1%向上/非収益性を1%削減する方向を示すCriticを提供します。これをおこなうには、Actorの行動の現在の評価を取得し、それを1%向上させます。
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
得られた結果をCritic のバックプロパゲーション パスの参照として使用します。念のためお知らせしますが、この段階ではCriticの学習プロセスは無効になっています。したがって、バックプロパゲーションパスを実行する場合、そのパラメータは調整されません。しかし、Actorは誤差勾配を受け取ります。そして、方策の有効性を高めるために、Actorのパラメータを調整できるようになります。
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次に、モデルの訓練の進行状況をユーザーに通知し、ループの次のイテレーションに進みます。
if(GetTickCount() - ticks > 500) { double percent = double(iter + i) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
訓練プロセスが完了したら、銘柄チャートのコメントフィールドをクリアし、
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
モデルの訓練結果をターミナルログに出力し、EA終了プロセスを初期化します。
このEAの完全なコードと、この記事の作成に使用されたすべてのプログラムは、添付ファイルで入手できます。
3.テスト
開発と訓練の段階を完了した後、訓練済みモデルの実際の評価という重要な段階に到達しました。
モデルは、2023年全体のH1時間枠におけるEURUSD商品の履歴データに基づいて訓練されました。すべてのインジケーターパラメータはデフォルト値に設定されました。
訓練済みモデルのテストは、他のすべてのパラメータを変更せずに、2024年1月からの履歴データで実施されました。このアプローチにより、実際の動作条件に可能な限り近い近似値を実現できます。
最初の段階では、EnvironmentalStateEncoderモデルを訓練しました。以下は、H1時間枠の翌日に相当する24時間にわたる実際の価格変動と予測価格変動を1時間ごとに視覚化したものです。分析には同じ時間枠が使用されました。

提示されたチャートから、生成された予測が今後の動きの主な方向性を概ね捉えていることがわかります。タイミングと方向の両方において、特定の局所的極値に合わせることさえできました。ただし、予測される価格の軌道はより滑らかで、金融商品の価格チャートに描かれたトレンドラインに似ています。
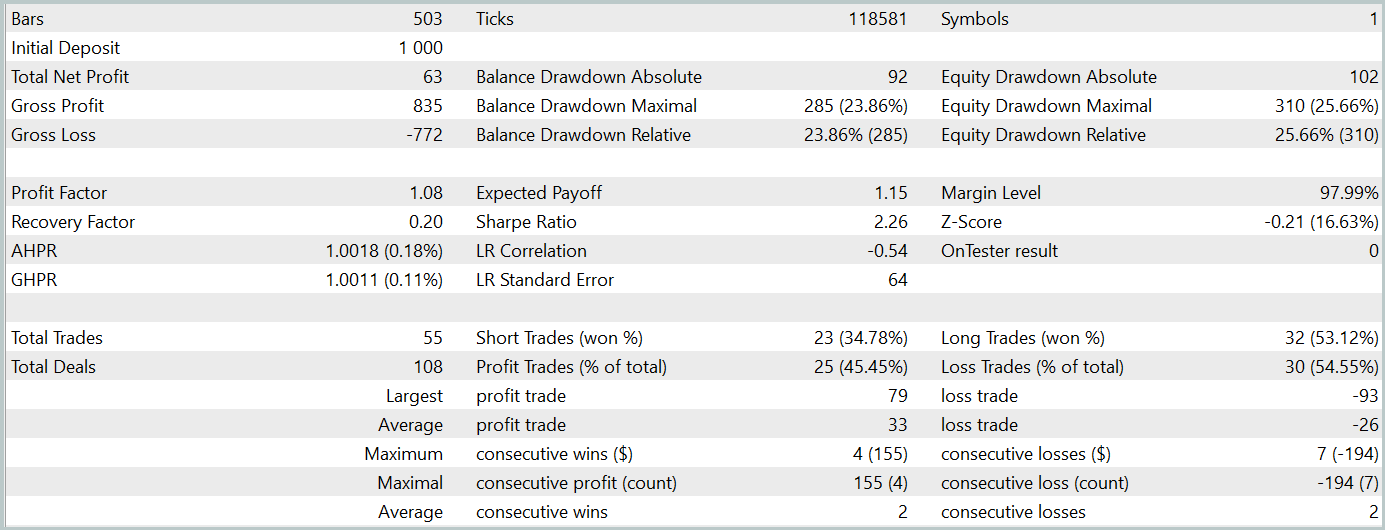
第2段階では、ActorモデルとCriticモデルを訓練しました。Criticの行動評価の正確性については評価しません。その主なタスクは、Actor方策の訓練を正しい方向に導くことです。代わりに、テスト期間中のActorの学習した方策の収益性に焦点を当てます。戦略テスターにおけるActorのパフォーマンスを以下に示します。
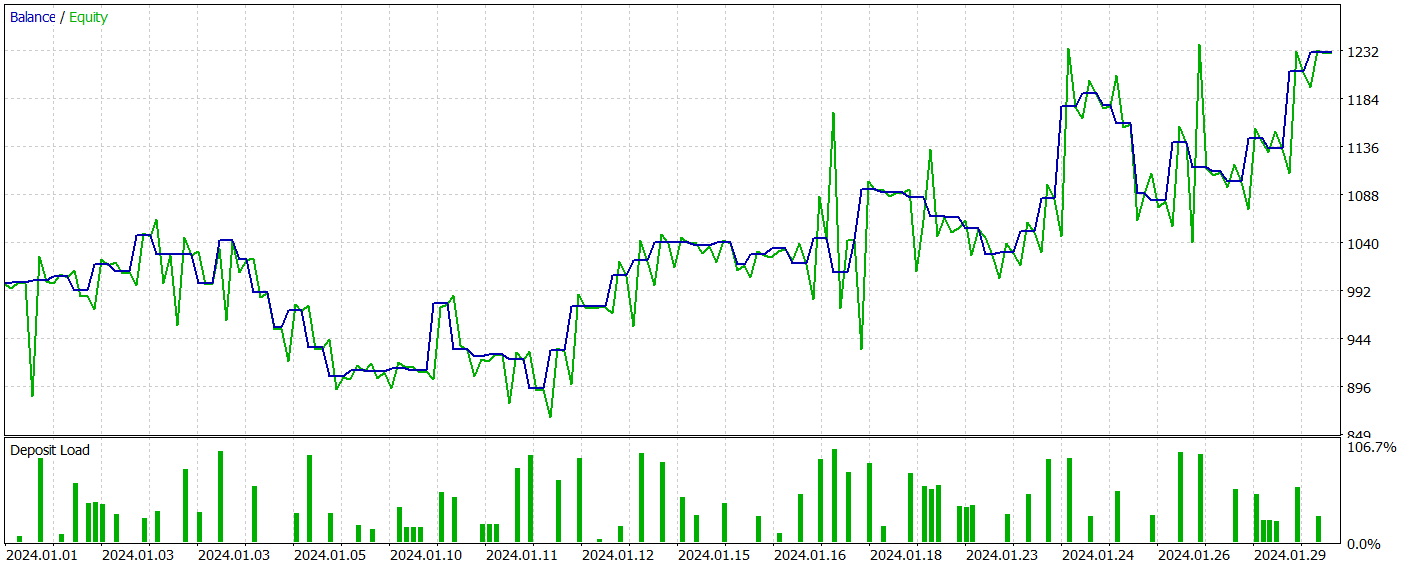
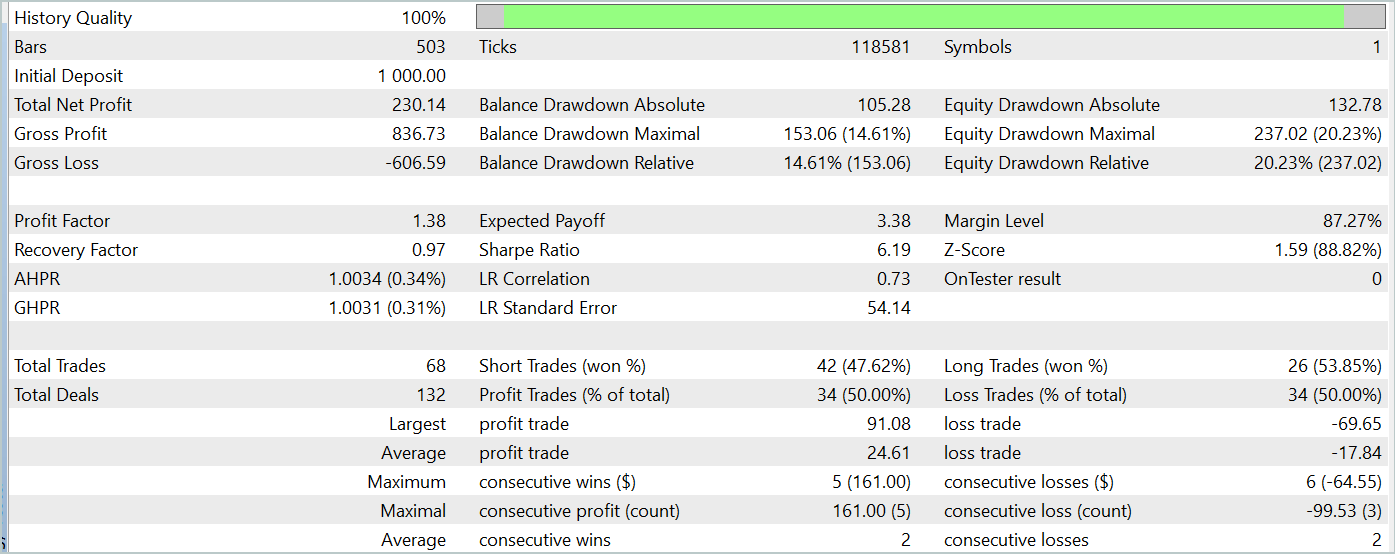
テスト期間中(2024年1月)、アクターは68件の取引を実行し、その半分は利益で終了しました。さらに重要なのは、最大の利益を上げた取引と平均の利益を上げた取引の両方が、損失を出した取引を上回ったことです(それぞれ91.08と24.61対-69.85と-17.84)。その結果、全体の利益は23%になりました。
しかし、エクイティチャートではバランスラインの上下に大きな変動が見られます。これにより、当初は「損失の保持」とポジションの終了の遅れに関する懸念が生じます。特に、これらの瞬間に預金負荷は100%に近づき、過度のリスクにさらされていることを示唆しています。これは、最大ドローダウンが20%を超えていることからもさらに裏付けられます。
次に、環境状態エンコーダーのパラメータを調整して、Actor方策の追加訓練を実行しました。この微調整は訓練データセットを更新せずにおこなわれたことを強調することが重要です。つまり、訓練の基盤は変更されていないということです。しかし、このプロセスはマイナスの効果をもたらしました。モデルのパフォーマンスは低下しました。取引数が減少し、収益性の高い取引の割合が45%に低下し、全体的な収益性が低下し、エクイティドローダウンが25%を超えました。
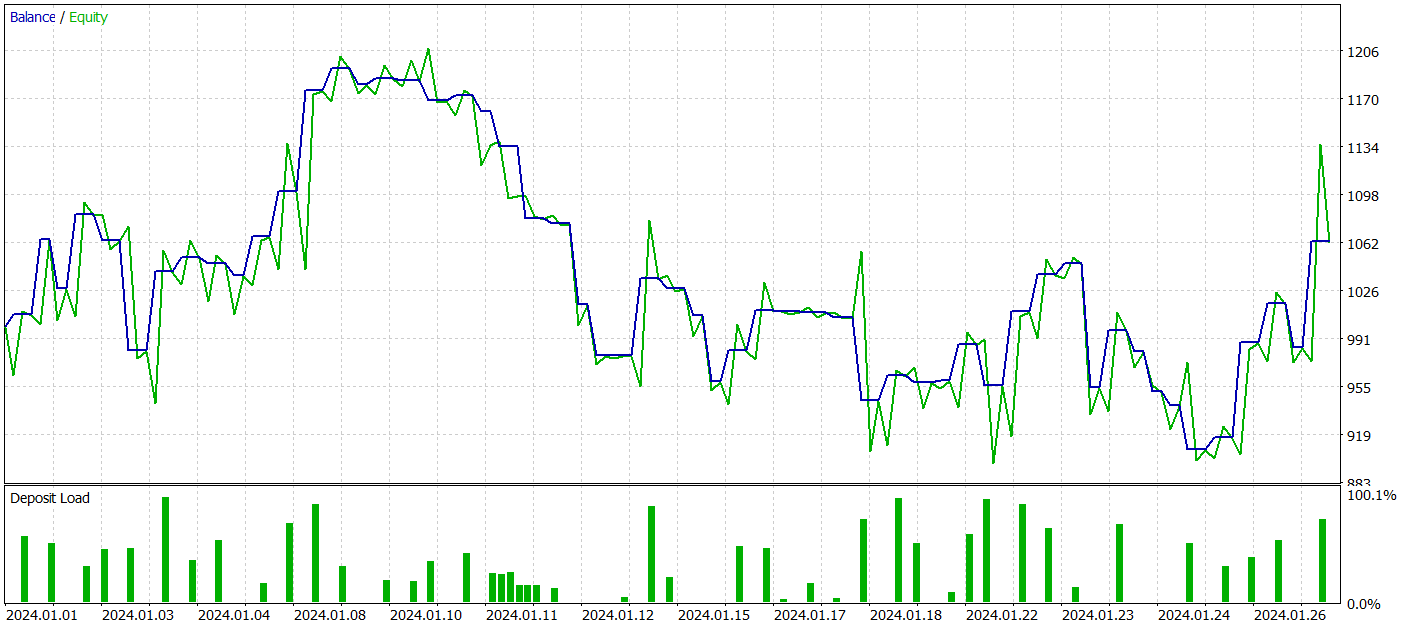
興味深いことに、予測される価格変動軌道の精度も変化しました。
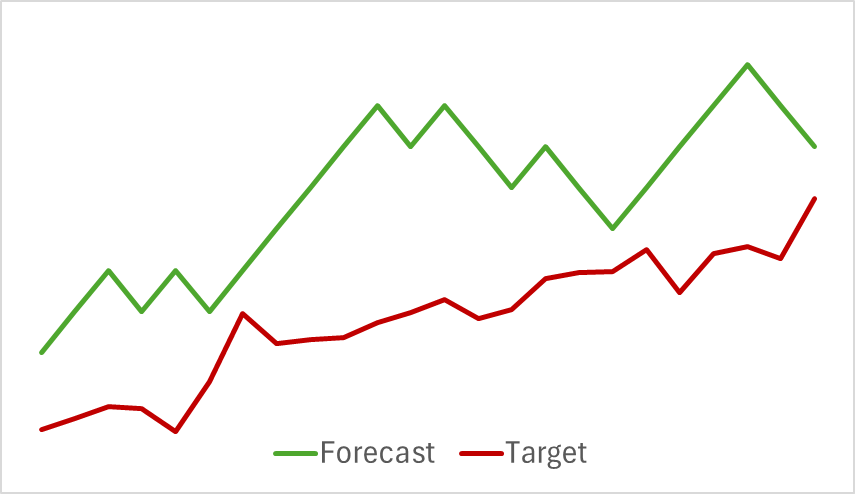
私の見解では、ActorとCriticの目標に合わせて環境状態エンコーダーのパラメータを最適化し始めると、エンコーダーの出力に追加のノイズが導入されることになります。初期の訓練段階では、予測モデルは入力データと結果の間に明確な対応関係があり、パターンを効果的に学習して一般化できました。ただし、モデルがEnvironmentalStateEncoderによって提供されるデータに基づいて誤差を最小化しようとすると、ActorとCriticから受信した誤差勾配によって矛盾するノイズが発生します。その結果、エンコーダーは生データのフィルターとして機能しなくなり、すべてのモデルの有効性が低下します。
結論
時系列予測のための革新的かつ複雑な手法であるTEMPOを調査しました。このアプローチでは、事前に訓練された言語モデルを時系列予測タスクに適用することを提案しています。提案されたアルゴリズムは、時系列分解に新たなアプローチを導入し、データ表現の学習効率を向上させることができます。
また、これらのアプローチをMQL5に実装するために広範な作業をおこないました。事前に訓練された言語モデルにアクセスできなかったにもかかわらず、実験の結果、興味深い成果を得ることができました。
全体として、提案された手法は実際の取引モデルの開発に適用可能であることが確認されました。ただし、Transformerアーキテクチャに基づくモデルの訓練には大量のデータ収集が必要であり、そのため計算コストが高くなる可能性があることを認識することが重要です。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダー訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
| 9 | Study2.mq5 | EA | エンコーダパラメータ調整によるActorおよびCriticモデルの訓練のためのEA |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15469
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ユーザーに対する姿勢
明確に
作者に借りがあると思っている人たちだけに......。
でも、なぜかみんな引っかかる。
「...このモデルは利益を生み出すことができる」みたいなトリガーやあからさまな動機が記事になければ、それでいいのだ。
、未検証の情報が操作されたとしても、それは我々の問題ではない。
最初のユーザーが批判で追放されたことを考えると、私もいい加減終わりにしよう。反論があれば反論すればいい。
......記事に「......このモデルは利益を生み出すことができる」といったトリガーやあからさまな動機が含まれていなければ、それでいいのだ。
、未検証の情報を操作するのであれば、それは我々の問題ではない。
コメント欄のドミトリーの記事の下で、私は彼にエキスパートアドバイザーのトレーニングについて特別に記事を書く ように頼んだ。ドミトリーは、どの記事からどのモデルを取り出して、どのようにそれを教えるかを記事で完全に説明することができる。ゼロから結果まで、詳細に、すべてのニュアンスで。何を見るべきか、どのような順序で教えるか、何回教えるか、どのような機材で教えるか、学べない場合はどうするか、どのような間違いを見るか。ここには、"for dummies "のスタイルでトレーニングについてできるだけ詳しく書かれている。しかし、ドミトリーはなぜかこの要望を無視したのか、あるいは気づかなかったのか、今までそのような記事を書いていない。多くの人が彼に感謝すると思う。
ドミトリー、そのような記事を書いてください。
ドミトリーによる本がある -"MQL5におけるアルゴリズム取引におけるニューラルネットワーク"を紹介しよう。