
Neuronale Netze im Handel: Praktische Ergebnisse der Methode TEMPO

Einführung
Im vorherigen Artikel haben wir uns mit den theoretischen Aspekten der Methode TEMPO vertraut gemacht, die einen originellen Ansatz zur Verwendung vorab trainierter Sprachmodelle zur Lösung von Problemen der Zeitreihenprognose vorschlägt. Hier ist eine kurze Zusammenfassung der wichtigsten Neuerungen des vorgeschlagenen Algorithmus.
TEMPO basiert auf der Verwendung eines vortrainierten Sprachmodells. Insbesondere verwenden die Autoren der Methode in ihren Experimenten vortrainiertes GPT-2. Die Grundidee des Ansatzes besteht darin, die im Vortraining erworbenen Kenntnisse des Modells zur Prognose von Zeitreihen zu nutzen. Hier lohnt es sich natürlich, nicht offensichtliche Parallelen zwischen Sprache und Zeitreihe zu ziehen. Im Wesentlichen ist unsere Sprache eine Zeitreihe von Lauten, die mithilfe von Buchstaben aufgezeichnet werden. Unterschiedliche Betonungen werden durch Satzzeichen vermittelt.
Das Long Language Model (LLM), beispielsweise GPT-2, wurde an einem großen Datensatz (oft in mehreren Sprachen) vortrainiert und lernte eine große Anzahl verschiedener Abhängigkeiten in der zeitlichen Abfolge von Wörtern, die wir in der Zeitreihenprognose verwenden möchten. Allerdings unterscheiden sich die Buchstaben- und Wortfolgen deutlich von den analysierten Zeitreihendaten. Wir haben immer gesagt, dass es für die ordnungsgemäße Funktion jedes Modells sehr wichtig ist, die Datenverteilung in den Trainings- und Testdatensätzen beizubehalten. Dies betrifft auch die während des Betriebs des Modells analysierten Daten. Kein Sprachmodell funktioniert mit dem Text, den wir in seiner Reinform gewohnt sind. Zunächst durchläuft er die Einbettungsphase (Kodierungsphase), in der der Text in einen bestimmten numerischen Code umgewandelt wird (versteckter Zustand). Das Modell verarbeitet dann diese codierten Daten und generiert in der Ausgabephase Wahrscheinlichkeiten für nachfolgende Buchstaben und Satzzeichen. Die wahrscheinlichsten Symbole werden dann verwendet, um einen für Menschen lesbaren Text zu erstellen.
TEMPO macht sich diese Eigenschaft zunutze. Während des Trainingsprozesses eines Zeitreihenprognosemodells werden die Parameter des Sprachmodells „eingefroren“, während die Transformationsparameter der Originaldaten in mit dem Modell kompatible Einbettungen optimiert werden. Die Autoren von TEMPO schlagen einen umfassenden Ansatz vor, um den Zugriff des Modells auf nützliche Informationen zu maximieren. Zunächst wird die analysierte Zeitreihe in ihre grundlegenden Komponenten, wie Trend, Saisonalität und der Rest, zerlegt. Jede Komponente wird dann segmentiert und in Einbettungen umgewandelt, die das Sprachmodell interpretieren kann. Um das Modell zusätzlich in die gewünschte Richtung zu lenken (z. B. Trend- oder Saisonalitätsanalyse), führen die Autoren ein System von „Soft Prompts“ ein.
Insgesamt verbessert dieser Ansatz die Interpretierbarkeit des Modells und ermöglicht ein besseres Verständnis dafür, wie verschiedene Komponenten die Vorhersage zukünftiger Werte beeinflussen.
Die originale Visualisierung wird unten angezeigt.
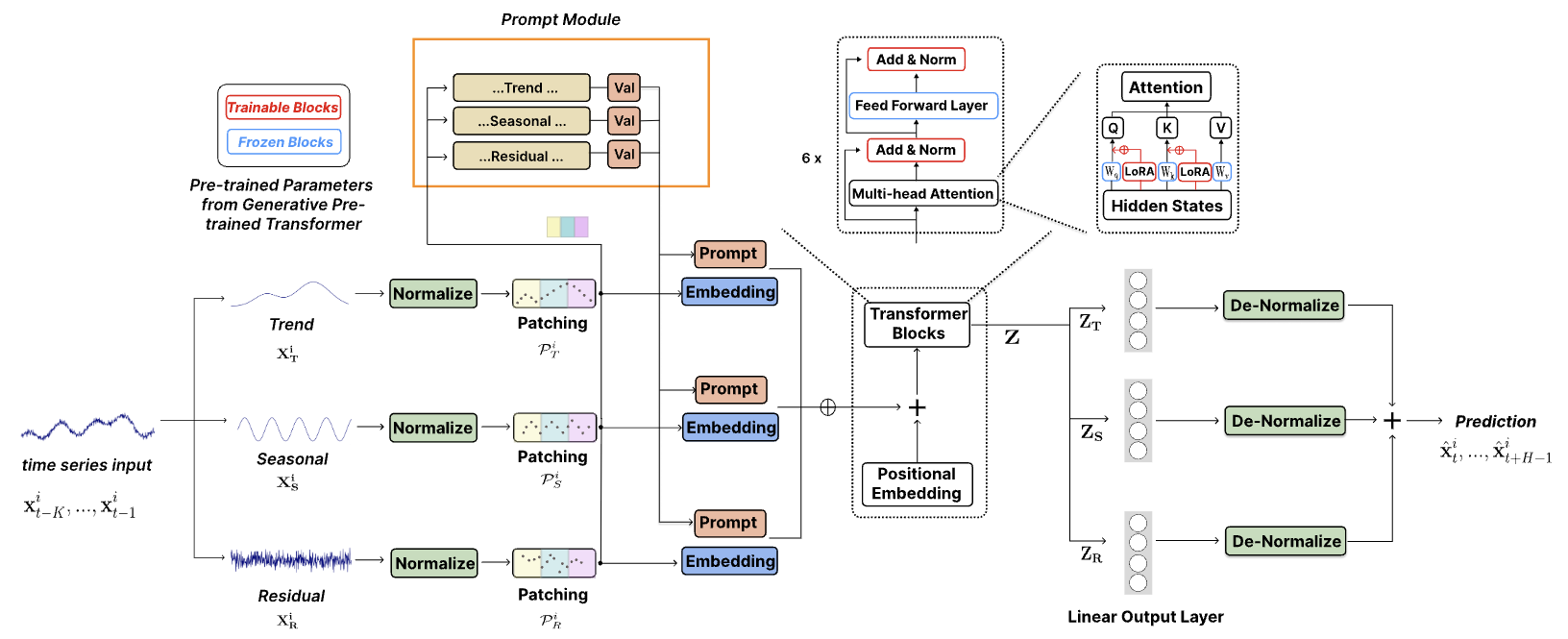
1. Die Architektur des Modells
Die vorgeschlagene Modellarchitektur ist recht komplex und umfasst mehrere Zweige und parallele Datenströme, die am Ausgang aggregiert werden. Die Implementierung eines solchen Algorithmus in unseren vorhandenen linearen Modellrahmen war mit erheblichen Herausforderungen verbunden. Um dieses Problem zu lösen, haben wir einen integrierten Ansatz entwickelt, der den gesamten Algorithmus in einem einzigen Modul zusammenfasst und so effektiv als einschichtige Implementierung funktioniert. Dieser Ansatz begrenzt zwar die Möglichkeiten der Nutzer, mit unterschiedlichen Modellkomplexitäten zu experimentieren, etwas (da die strukturelle Flexibilität des Moduls durch die Parameter der Methode Init in unserer Klasse CNeuronTEMPOOCL eingeschränkt wird), vereinfacht jedoch auch den Prozess der Erstellung neuer Modelle erheblich. Nutzer müssen sich nicht mit den komplizierten Details der Architektur befassen. Stattdessen müssen sie nur einige Schlüsselparameter angeben, um eine robuste und ausgereifte Modellarchitektur zu erstellen. Unserer Ansicht nach ist dieser Kompromiss für die Mehrheit der Nutzer praktischer.
Darüber hinaus ist ein wichtiger Aspekt zu berücksichtigen: Die Autoren von TEMPO haben ihre Experimente mit einem vortrainierten Sprachmodell von GPT-2 durchgeführt. Bei der Implementierung in Python können solche Modelle über Bibliotheken wie Hugging Face aufgerufen werden. In unserer Implementierung verwenden wir jedoch kein vortrainiertes Sprachmodell. Stattdessen ersetzen wir es durch einen Block Kreuzaufmerksamkeit, der zusammen mit dem Hauptmodell trainiert wird.
TEMPO ist als Zeitreihen-Prognosemodell positioniert. Folglich integrieren wir, wie in ähnlichen Fällen, die vorgeschlagenen Techniken in unser Modell des Encoders der Umgebungszustände (Environmental State Encoder). Die Architektur dieses Modells wird in der Methode CreateEncoderDescriptions definiert.
Innerhalb der Parameter dieser Methode übergeben wir einen Zeiger auf ein dynamisches Array, in dem die Architekturparameter der neuronalen Schichten im generierten Modell gespeichert werden.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Im Hauptteil der Methode prüfen wir die Relevanz des empfangenen Zeigers und erstellen ggf. eine neue Instanz des Objekts.
Anschließend folgt eine Beschreibung des Modells. Zunächst spezifizieren wir eine vollständig verbundene Schicht zur Aufzeichnung der Eingabedaten. Die Größe der erstellten Schicht muss mit der Größe des Eingabedatentensors übereinstimmen.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Zur Erinnerung: Das Modell erhält einen Tensor aus Roheingabedaten in seiner ursprünglichen Form, genau wie er vom Terminal abgerufen wurde. In allen unseren vorherigen Modellen bestand der nächste Schritt darin, eine Batch-Normalisierungsschicht anzuwenden, um eine vorläufige Datenverarbeitung durchzuführen und die Werte auf einen vergleichbaren Maßstab zu bringen.
In diesem Fall haben wir jedoch die Batch-Normalisierungsschicht bewusst ausgeschlossen. Überraschenderweise ergibt sich diese Entscheidung aus der Architektur der Methode TEMPO selbst. Wie in der obigen Visualisierung dargestellt, werden die Rohdaten sofort an den Zerlegungsblock weitergeleitet, wo die analysierte Zeitreihe in ihre drei grundlegenden Komponenten zerlegt wird: Trend, Saisonalität und Residuen. Diese Zerlegung erfolgt unabhängig für jede univariate Zeitreihe, also für jeden analysierten Parameter der multimodalen Zeitreihe. Die Vergleichbarkeit der Werte innerhalb jeder univariaten Reihe ist aufgrund der Art der Daten von Natur aus gewährleistet.
Zunächst wird die Trendkomponente aus den Rohdaten extrahiert. In unserer Implementierung erreichen wir dies durch eine stückweise lineare Darstellung der Zeitreihe. Wie Sie wissen, ermöglicht der Algorithmus dieser Methode die Extraktion vergleichbarer Segmente unabhängig von der Skalierung und Verschiebung der Rohdatenverteilung, die normalerweise während der Normalisierung auftreten würde.
Als Nächstes subtrahieren wir die Trendkomponente von den Originaldaten und bestimmen die saisonale Komponente. Dies wird mithilfe der diskreten Fourier-Transformation erreicht, die das Signal in sein Frequenzspektrum zerlegt, sodass wir die signifikantesten periodischen Abhängigkeiten basierend auf der Amplitude identifizieren können. Wie die Trendextraktion ist auch die Frequenzzerlegung unempfindlich gegenüber Datenskalierung und -verschiebung.
Schließlich wird die Restkomponente ermittelt, indem die beiden zuvor extrahierten Komponenten von den Originaldaten abgezogen werden.
An diesem Punkt wird deutlich, dass eine vorläufige Datennormalisierung aus Sicht des Modelldesigns keinen zusätzlichen Nutzen bringt. Darüber hinaus würde die Anwendung einer Normalisierung in dieser Phase einen zusätzlichen Rechenaufwand verursachen, der an sich unerwünscht ist.
Betrachten wir nun die nächste Phase. Die Autoren der TEMPO-Methode führen eine Normalisierung der extrahierten Komponenten ein, die für nachfolgende Operationen mit multimodalen Daten eindeutig von wesentlicher Bedeutung ist. Dies wirft eine Frage auf: Könnten wir den Normalisierungsansatz ändern? Könnten wir insbesondere die Roheingabedaten vor der Zerlegung normalisieren und dann die Normalisierung der einzelnen Komponenten weglassen? Schließlich ist das Rohdatenvolumen dreimal kleiner als die kombinierte Größe der extrahierten Komponenten. Meiner Ansicht nach lautet die Antwort wahrscheinlich „Nein“.
Zur Veranschaulichung betrachten wir ein abstraktes Zeitreihendiagramm und heben die wichtigsten Trends hervor. Es ist offensichtlich, dass die Trendkomponente den Großteil der Informationen umfasst.
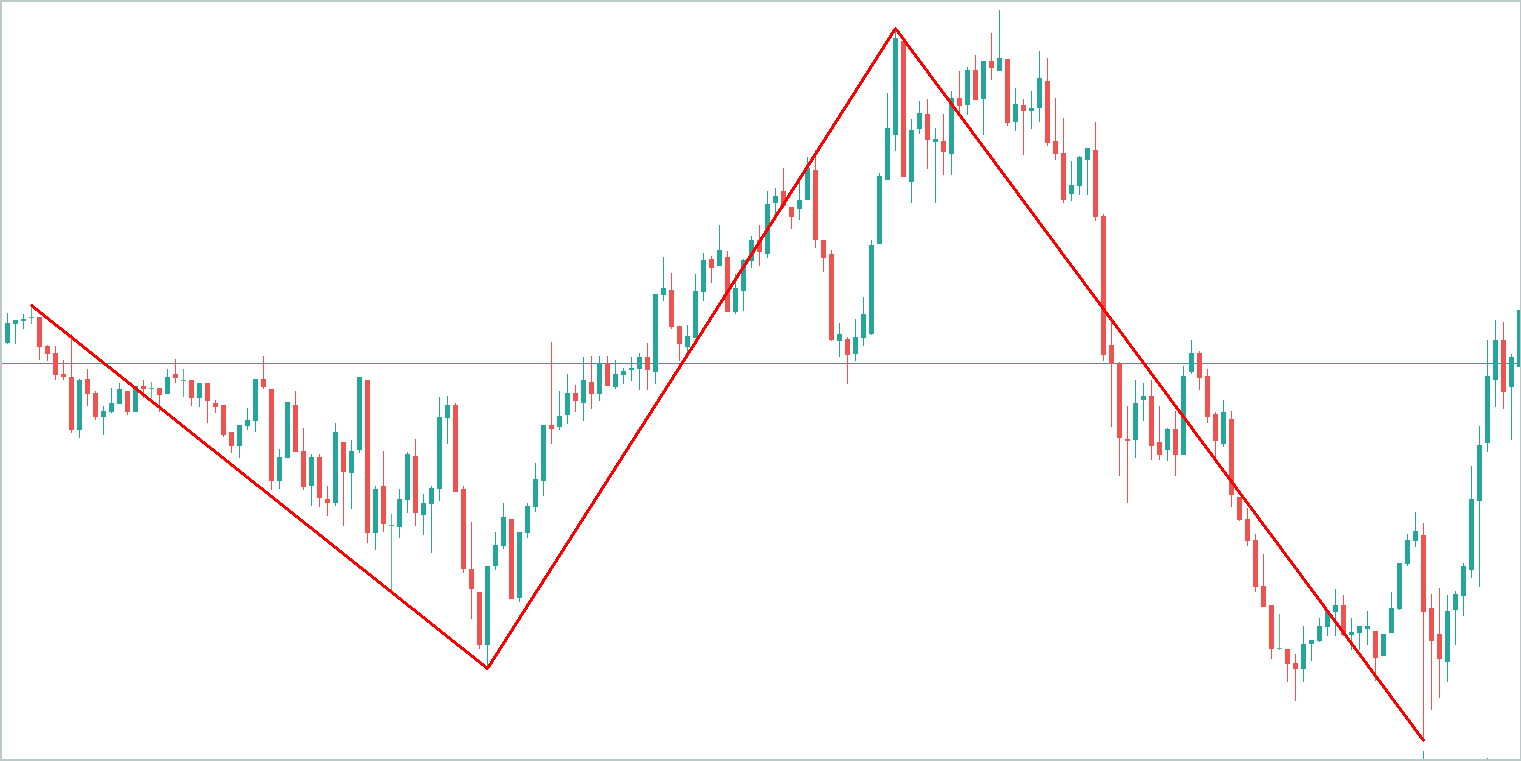
Die saisonale Komponente besteht aus wellenförmigen Schwankungen um die Trendlinie mit deutlich geringerer Amplitude als der Trend selbst.
Die Restkomponente, die andere Variationen darstellt, weist eine noch geringere Amplitude auf und spiegelt in erster Linie Rauschen wider. Dieses Rauschen kann jedoch nicht ignoriert werden, da es externe Einflüsse wie Nachrichtenereignisse und andere unberücksichtigte Faktoren erfasst, die einen nicht-systematischen Charakter aufweisen.
Durch die Normalisierung der Rohdaten vor der Zerlegung würde das Problem der Vergleichbarkeit zwischen einzelnen univariaten Reihen gelöst. Das Problem der Vergleichbarkeit zwischen den extrahierten Komponenten selbst würde dadurch jedoch nicht gelöst. Aus Gründen der Modellstabilität ist es daher vorzuziehen, die Normalisierung nach der Zerlegung auf Komponentenebene anzuwenden.
Aus diesem Grund schließen wir die Batch-Normalisierungsschicht für Roheingabedaten aus. Stattdessen führen wir unseren neuen Methodenblock TEMPO direkt nach der Eingabedatenschicht ein.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTEMPOOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = NForecast;
Wir legen die Größe der analysierten multimodalen Sequenz, die Anzahl der darin enthaltenen Einheitszeitreihen und den Planungshorizont mithilfe zuvor festgelegter Konstanten fest.
Als Teil des Experiments bei der Vorbereitung dieses Artikels habe ich 4 Aufmerksamkeitsköpfe angegeben.
descr.window_out = 4;
Ich habe auch 4 verschachtelte Schichten im Aufmerksamkeitsblock festgelegt.
descr.layers = 4;
Hier möchte ich Sie daran erinnern, dass diese Parameter in zwei verschachtelten Aufmerksamkeitsblöcken verwendet werden:
- der Frequenzbereichs-Aufmerksamkeitsblock zur Erkennung von Abhängigkeiten zwischen den Frequenzmerkmalen einzelner Einheitssequenzen und
- der Cross-Attention-Block zum Erkennen von Abhängigkeiten in einer Abfolge von Zeitreihen.
Als Nächstes geben wir die Normalisierungs-Batchgröße und die Methode zur Modelloptimierung an.
descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
An diesem Punkt kann das Modell als vollständig betrachtet werden, da wir am Ausgang des Blocks CNeuronTEMPOOCL die gewünschten Prognosewerte der analysierten Zeitreihe erhalten. Aber wir werden noch den letzten Schliff hinzufügen – eine Frequenzanpassungsschicht für die Prognosezeitreihe, CNeuronFreDFOCL.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Als Ergebnis erhalten wir eine kurze und prägnante Modellarchitektur in Form von 3 neuronalen Schichten. Dahinter verbirgt sich jedoch ein komplexer, integrierter Algorithmus. Schließlich wissen wir, was sich unter der „Spitze des Eisbergs“, CNeuronTEMPOOCL, verbirgt: 24 verschachtelte Schichten, von denen 12 trainierbare Parameter enthalten. Darüber hinaus sind zwei dieser verschachtelten Schichten Aufmerksamkeitseinheiten, für die wir die Erstellung einer vierschichtigen Architektur der Selbstaufmerksamkeit mit jeweils 4 Aufmerksamkeitsköpfen spezifiziert haben. Dies macht unser Modell wirklich komplex und tiefgreifend.
Wir werden die erhaltenen Prognosewerte der bevorstehenden Preisbewegung verwenden, um die Verhaltensrichtlinie des Akteurs zu trainieren. Hier haben wir die Architekturen aus den vorherigen Artikeln weitgehend beibehalten, aber aufgrund der Komplexität des Environment State Encoders und der zu erwartenden steigenden Kosten für dessen Training habe ich beschlossen, die Anzahl der verschachtelten Schichten in den Blöcken der Kreuzaufmerksamkeit der Modelle von Akteur und Kritiker (Actor & Critic) zu reduzieren. Zur Erinnerung: Die Architektur dieser Modelle wird in der Methode CreateDescriptions beschrieben, in deren Parametern wir Zeiger auf 2 dynamische Arrays übergeben. Daher schreiben wir die Beschreibung der Architektur unserer Modelle in diese Arrays.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Im Hauptteil der Methode prüfen wir die Relevanz der erhaltenen Zeiger und erstellen gegebenenfalls neue Instanzen von Objekten.
Zuerst beschreiben wir die Architektur des Akteurs, in die wir den Tensor eingeben, der den Status des Kontos beschreibt.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass es hier um den Kontostand geht und nicht um die Umgebung. Unter dem Begriff „Umgebungszustand“ (state of environment) verstehen wir die Parameter der Preisbewegungsdynamik und die analysierten Indikatoren. In den „Kontostand“ (state of the account) fließen der aktuelle Wert des Kontoguthabens, das Volumen und die Richtung der offenen Positionen sowie der darauf aufgelaufene Gewinn oder Verlust ein.
Wir transformieren die am Eingang des Modells erhaltenen Informationen mithilfe einer grundlegenden, vollständig verbundenen Schicht in einen verborgenen Zustand.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Als Nächstes verwenden wir einen Kreuzaufmerksamkeits-Block, in dem wir den aktuellen Kontostand mit dem vorhergesagten Wert der bevorstehenden Preisbewegung vergleichen, den wir vom Environment State Encoder erhalten.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } { int temp[] = {4, 2}; ArrayCopy(descr.heads, temp); } descr.layers = 4; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Hierbei ist es wichtig, sich auf einen zentralen Aspekt zu konzentrieren: den Unterraum der Datenwerte, die vom State Score Encoder abgerufen werden. Obwohl wir zuvor schon denselben Ansatz verfolgt hatten, gab es damals keinen Anlass zu Bedenken. Also, was hat sich geändert?
Wie heißt es so schön: „Der Teufel steckt im Detail.“ Zuvor haben wir eine Batch-Normalisierungsschicht am Eingang des Environmental State Encoders verwendet, um Rohdaten in ein vergleichbares Format zu bringen. Bei der Ausgabe des Modells haben wir die Schicht CNeuronRevINDenormOCL angewendet, um diese Transformation umzukehren und die Daten in ihrem ursprünglichen Unterraum wiederherzustellen. Für den Akteur und den Kritiker haben wir mit der versteckten Darstellung der Vorhersagewerte in einer vergleichbaren Form gearbeitet, bevor wir Verschiebungs- und Skalierungsoperationen wieder auf die ursprünglichen Datenunterräume angewendet haben. Dadurch wurde sichergestellt, dass die nachfolgenden Analysen auf konsistenten und interpretierbaren Daten basierten, was die Verarbeitung durch das Modell erleichterte.
Im Fall von CNeuronTEMPOOCL haben wir jedoch bewusst auf die vorläufige Normalisierung der Eingabedaten verzichtet, wie zuvor besprochen. Als Ergebnis gibt das Modell nun nicht normalisierte, prognostizierte Preisbewegungen aus, was die Aufgaben des Akteurs und Kritikers erschweren und folglich ihre Wirksamkeit verringern kann. Eine mögliche Lösung besteht darin, die vorhergesagten Zeitreihenwerte vor ihrer anschließenden Verwendung zu normalisieren. Der einfachste Weg, dies zu erreichen, wäre die Einführung eines kleinen Vorverarbeitungsmodells mit einer einzigen Normalisierungsschicht. Diesen Schritt haben wir allerdings nicht umgesetzt.
Darüber hinaus möchte ich Sie daran erinnern, dass wir anstelle der einfachen Summierung der drei Prognosekomponenten (Trend, Saisonalität und der Rest) bei der Ausgabe des Blocks CNeuronTEMPOOCL eine Faltungsschicht ohne Aktivierungsfunktion verwendet haben. Dadurch wird die einfache Summierung durch eine gewichtete Summierung der erhaltenen Daten ersetzt.
if(!cSum.Init(0, 24, OpenCL, 3, 3, 1, iVariables, iForecast, optimization, iBatch)) return false; cSum.SetActivationFunction(None);
Durch die Begrenzung des Maximalwerts der Modellparameter auf kleiner als 1 können wir offensichtlich große Werte bei der Modellausgabe ausschließen.
#define MAX_WEIGHT 1.0e-3f
Natürlich schränkt dieser Ansatz die Genauigkeit unseres Environmental State Encoders von Natur aus ein. Denn wie können wir tatsächliche Indikatorwerte wie den RSI (der zwischen 0 und 100 liegt) mit vorhergesagten Ergebnissen in Einklang bringen, deren absolute Werte unter 1 liegen? In solchen Fällen besteht bei Verwendung von MSE als Verlustfunktion eine hohe Wahrscheinlichkeit, dass die vorhergesagten Werte das maximal mögliche Niveau erreichen. Um dies zu beheben, haben wir den Frequenzausrichtungsblock CNeuronFreDFOCL am Ausgang des Environmental State Encoders eingeführt. Dieser Block reagiert weniger empfindlich auf die Skalierung der Daten und ermöglicht es dem Modell, die Struktur bevorstehender Preisbewegungen zu erlernen, was in diesem Zusammenhang wichtiger ist als absolute Werte.
Mir ist bewusst, dass die vorgeschlagene Lösung nicht unmittelbar intuitiv ist und möglicherweise etwas schwierig zu verstehen ist. Die Wirksamkeit wird jedoch letztlich anhand der praktischen Ergebnisse unserer Modelle bewertet.
Kehren wir nun zur Architektur unseres Akteurs zurück: Nach dem Kreuzaufmerksamkeits-Attention-Block verwenden wir zur Entscheidungsfindung ein Perzeptron, das aus drei vollständig verbundenen Schichten besteht.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
An seiner Ausgabe fügen wir der Richtlinie unseres Akteurs Stochastik hinzu.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Anschließend passen wir die Frequenzeigenschaften der gewählten Lösung an.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die Architektur des Kritikers wiederholt fast vollständig die oben vorgestellte Architektur des Akteurs. Es gibt nur geringfügige Unterschiede. Insbesondere speisen wir den Input des Modells nicht mit dem Kontostand, sondern mit dem Aktionstensor des Akteurs.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Bei der Ausgabe des Modells verwenden wir keine Stochastik und erhalten so eine klare Bewertung der vorgeschlagenen Maßnahmen.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Eine vollständige Beschreibung der architektonischen Lösungen aller verwendeten Modelle finden Sie in der Anlage.
2. Modelltraining
Wie aus der Architekturbeschreibung der trainierten Modelle oben hervorgeht, hat die Implementierung der Methode von TEMPO weder die Struktur der Originaldaten noch die Ergebnisse der trainierten Modelle verändert. Daher können wir für das anfängliche Modelltraining bedenkenlos zuvor gesammelte Trainingsdatensätze verwenden. Darüber hinaus können wir mit der Datenerfassung, dem Trainieren von Modellen und der Aktualisierung des Trainingsdatensatzes fortfahren, indem wir die zuvor entwickelten Programme zur Umgebungsinteraktion und zum Modelltraining verwenden.
Für die Interaktion mit der Umgebung und das Sammeln von Trainingsdaten verwenden wir zwei Programme:
- „...\Experts\TEMPO\ResearchRealORL.mq5“ — sammelt Daten basierend auf einem historischen Satz realer Trades. Die Methodik wird im zitierten Artikel ausführlich beschrieben.
- „...\Experts\TEMPO\Research.mq5“ — Expert Advisor, der in erster Linie dazu dient, die Leistung einer vorab trainierten Richtlinie zu analysieren und den Trainingsdatensatz innerhalb der aktuellen Richtlinienumgebung zu aktualisieren. Dies ermöglicht eine Feinabstimmung der Richtlinie des Akteurs auf der Grundlage von echtem Belohnungsfeedback. Dieser EA kann jedoch auch verwendet werden, um einen ersten Trainingsdatensatz basierend auf der mit zufälligen Parametern initialisierten Verhaltensrichtlinie des Akteurs zu sammeln.
Unabhängig davon, ob wir bereits Daten zur Umgebungsinteraktion gesammelt haben, können wir jeden der oben genannten Expert Advisors im MetaTrader 5-Strategietester starten, um einen neuen Trainingsdatensatz zu erstellen oder einen vorhandenen zu aktualisieren.
Die gesammelten Trainingsdaten werden zunächst verwendet, um den Environmental State Encoder zu trainieren, zukünftige Preisbewegungen vorherzusagen. Dazu führen wir den EA „...\Experts\TEMPO\StudyEncoder.mq5“ im Echtzeitmodus in MetaTrader 5 aus.
Es ist wichtig zu beachten, dass der Environmental State Encoder während des Trainings ausschließlich mit Preisdynamiken und analysierten Indikatoren arbeitet, die nicht von den Aktionen des Agenten beeinflusst werden. Daher bleiben alle Trainingsdatensatzdurchläufe im selben historischen Segment für das Modell identisch. Folglich liefert die Aktualisierung des Trainingsdatensatzes während des Encoder-Trainings keine zusätzlichen Informationen. Daher müssen wir geduldig sein und das Modell trainieren, bis wir zufriedenstellende Ergebnisse erzielen.
Ich möchte noch einmal betonen, dass wir aufgrund der Besonderheiten unseres Architekturansatzes, wie bereits zuvor erläutert, zum jetzigen Zeitpunkt keine „niedrigen“ Fehlerwerte erwarten. Unser Ziel ist es jedoch weiterhin, den Fehler so weit wie möglich zu minimieren und den Trainingsprozess zu stoppen, wenn sich der Vorhersagefehler in einem engen Bereich stabilisiert.
Die zweite Phase umfasst ein iteratives Training der Akteur- und Kritikermodelle. In dieser Phase verwenden wir den EA „...\Experts\TEMPO\Study.mq5“, der ebenfalls im Echtzeitmodus ausgeführt wird. Dieses Mal „frieren“ wir die Parameter des Environmental State Encoders ein und trainieren die beiden Modelle (Akteur und Kritiker) parallel.
Der Kritiker lernt durch die Belohnungsfunktion der Umgebung aus dem Trainingsdatensatz, indem er den vorhergesagten Umgebungszustand und die Aktionen des Agenten aus dem Trainingsdatensatz abbildet, um die erwartete Belohnung zu schätzen. Diese Phase folgt den Prinzipien des überwachten Lernens, da die tatsächlichen Belohnungen für die ausgeführten Aktionen im Trainingsdatensatz gespeichert werden.
Der Akteur optimiert dann seine Strategie auf Grundlage des Feedbacks des Kritikers mit dem Ziel, die Gesamtrentabilität zu maximieren.
Dieser Prozess ist iterativ, da sich der Aktionsunterraum des Akteurs während des Trainings verschiebt. Um die Relevanz aufrechtzuerhalten, müssen wir den Trainingsdatensatz aktualisieren, um echte Belohnungen im neu angepassten Aktionsunterraum zu erfassen. Dadurch kann der Kritiker die Belohnungsfunktion verfeinern und eine genauere Bewertung der Aktionen des Akteurs vornehmen, wodurch er die politischen Anpassungen in die gewünschte Richtung lenkt.
Um den Trainingsdatensatz zu aktualisieren, führen wir den langsamen Optimierungsprozess des EA „...\Experts\TEMPO\Research.mq5“ erneut aus.
An diesem Punkt könnte man die Notwendigkeit in Frage stellen, den State Score Encoder getrennt von den anderen Modellen zu trainieren. Einerseits liefert ein vortrainierter State Score Encoder die wahrscheinlichsten Marktbewegungen und fungiert effektiv als digitaler Filter, der das Rauschen in den Rohdaten reduziert. Darüber hinaus verwenden wir einen Planungshorizont, der deutlich kürzer ist als die Tiefe der analysierten Historie. Dies bedeutet, dass der Encoder auch Daten für die anschließende Analyse komprimiert und so möglicherweise die Effizienz der Modelle von Akteur und Kritiker verbessert.
Andererseits: Brauchen wir wirklich eine Prognose künftiger Preisbewegungen? Wir haben zuvor betont, dass es mehr auf eine klare Interpretation des aktuellen Zustands ankommt, die es dem Agenten ermöglicht, die optimale Aktion mit maximaler Genauigkeit auszuwählen. Um diese Frage zu untersuchen, haben wir einen weiteren Trainings-EA entwickelt: „...\Experts\TEMPO\Study2.mq5“. Dieses Programm basiert auf „...\Experts\TEMPO\Study.mq5“. Daher konzentrieren wir uns ausschließlich auf die direkte Modelltrainingsmethode: Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false;
Im Hauptteil der Methode generieren wir zunächst einen Vektor von Wahrscheinlichkeiten für die Auswahl von Flugbahnen aus dem Erfahrungswiedergabepuffer basierend auf der Gesamtrentabilität der Pässe. Danach initialisieren wir die notwendigen lokalen Variablen.
An diesem Punkt schließen wir die Vorarbeiten ab und organisieren die Modelltrainingsschleife.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum() == 0) { iter --; continue; }
Im Schleifenkörper entnehmen wir eine Trajektorie aus dem Erfahrungswiedergabepuffer und wählen zufällig einen Umgebungszustand darauf aus.
Wir übertragen die Beschreibung des ausgewählten Umgebungszustands aus der Trainingsprobe in den Datenpuffer und führen einen Vorwärtsdurchgang des Environmental State Encoders durch.
bState.AssignArray(state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Anschließend entnehmen wir dem Experience-Replay-Buffer die im ausgewählten Zustand bei der Interaktion mit der Umgebung ausgeführten Aktionen des Agenten und führen deren Bewertung durch den Kritiker durch.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite(); Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Beachten Sie, dass der Erfahrungswiedergabepuffer die tatsächliche Auswertung dieser Aktionen enthält und wir die vom Kritiker erlernte Belohnungsfunktion anpassen können, um Fehler zu minimieren. Dazu extrahieren wir die tatsächlich erhaltene Belohnung aus dem Erfahrungswiedergabepuffer und führen den Rückwärtsdurchgang des Kritikers durch.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
In diesem Schritt fügen wir einen Referenzpunkte des Environment State Encoders hinzu, um die Aufmerksamkeit des Modells auf Referenzpunkte zu lenken und so genauere Aktionsschätzungen zu ermöglichen.
Der nächste Schritt besteht darin, die Richtlinie des Akteurs anzupassen. Zunächst erstellen wir aus dem Experience-Replay-Buffer eine Beschreibung des Kontostatus, die dem zuvor ausgewählten Umgebungsstatus entspricht.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Wir führen den Vorwärtsdurchgang des Akteurs aus, um einen Aktionsvektor zu generieren, der die aktuelle Richtlinie berücksichtigt.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Danach deaktivieren wir den Trainingsmodus für den Kritiker und bewerten die vom Akteur generierten Aktionen.
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Wir passen die Akteurspolitik in zwei Schritten an. Zunächst prüfen wir die Wirksamkeit des aktuellen Durchgangs. Wenn sich dieser Durchgang im Prozess der Interaktion mit der Umgebung als profitabel erweist, passen wir die Aktionsrichtlinie des Akteurs an die im Erfahrungswiedergabepuffer gespeicherten Aktionen an.
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Gleichzeitig passen wir auch die Parameter des Encoders des Umgebungszustands an, um Datenpunkte zu identifizieren, die die Wirksamkeit der Politik des Akteurs beeinflussen.
In der zweiten Phase des Trainings zur Akteurspolitik bieten wir dem Kritiker an, die Richtung der Anpassung der Aktionen des Akteurs anzugeben, um die Rentabilität zu steigern bzw. die Unrentabilität um 1 % zu senken. Dazu nehmen wir die aktuelle Bewertung der Aktionen des Akteurs und verbessern diese um 1 %.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
Wir verwenden das erhaltene Ergebnis als Referenz für den Rückwärtsdurchgang des Kritikers. Zur Erinnerung: Zu diesem Zeitpunkt haben wir den Lernprozess des Kritikers deaktiviert. Daher werden die Parameter beim Durchführen eines Rückwärtsdurchgang nicht angepasst. Der Akteur erhält jedoch einen Fehlergradienten. Und wir werden in der Lage sein, die Parameter des Akteurs anzupassen, um die Wirksamkeit seiner Politik zu erhöhen.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Als Nächstes müssen wir den Nutzer nur noch über den Fortschritt des Modelltrainings informieren und mit der nächsten Iteration der Schleife fortfahren.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Sobald der Trainingsprozess abgeschlossen ist, löschen wir das Kommentarfeld in der Symboltabelle.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Wir geben die Ergebnisse des Modelltrainings in das Terminalprotokoll aus und initialisieren den EA-Beendigungsprozess.
Der vollständige Code für diesen Expert Advisor sowie alle Programme, die bei der Erstellung dieses Artikels verwendet wurden, sind im Anhang verfügbar.
3. Tests
Nach Abschluss der Entwicklungs- und Trainingsphasen haben wir die entscheidende Phase erreicht: die praktische Evaluierung unserer trainierten Modelle.
Die Modelle wurden anhand historischer Daten für das EURUSD-Instrument über das gesamte Jahr 2023 im H1-Zeitraum trainiert. Alle Indikatorparameter wurden auf ihre Standardwerte gesetzt.
Die Tests der trainierten Modelle wurden anhand historischer Daten vom Januar 2024 durchgeführt, wobei alle anderen Parameter unverändert blieben. Dieser Ansatz gewährleistet eine größtmögliche Annäherung an reale Betriebsbedingungen.
In der ersten Phase haben wir das Modell des Encoders des Umgebungszustands trainiert. Unten sehen Sie eine Visualisierung der tatsächlichen und prognostizierten Preisbewegungen über einen Zeitraum von 24 Stunden mit einer Prognoseschrittweite von einer Stunde, was dem folgenden Tag im H1-Zeitraum entspricht. Für die Analyse wurde derselbe Zeitraum verwendet.

Aus dem dargestellten Diagramm können wir ersehen, dass die erstellte Prognose im Allgemeinen die Hauptrichtung der bevorstehenden Bewegung erfasst hat. Es gelang sogar, sich zeitlich und richtungsweise an bestimmte lokale Extrema anzupassen. Der prognostizierte Preisverlauf erscheint jedoch gleichmäßiger und ähnelt Trendlinien, die über das Preisdiagramm des Instruments gezeichnet werden.
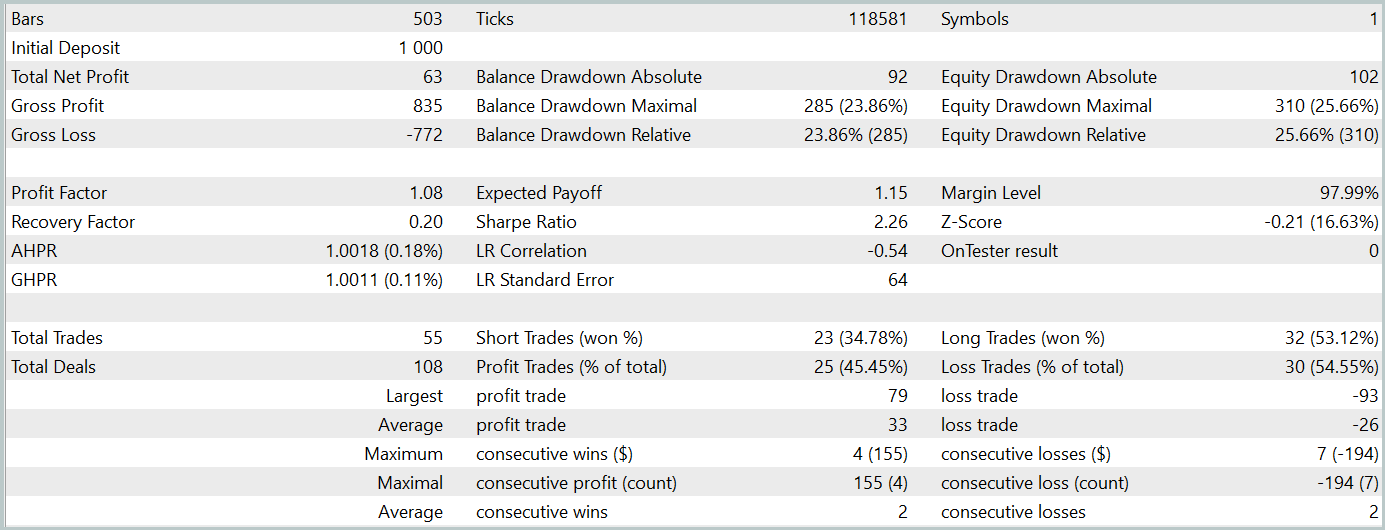
In der zweiten Phase haben wir die Modelle Akteur und Kritiker trainiert. Wir werden die Genauigkeit der Handlungseinschätzungen des Kritikers nicht beurteilen. Denn seine Hauptaufgabe besteht darin, die Akteurspolitik in die richtige Richtung zu lenken. Stattdessen konzentrieren wir uns auf die Rentabilität der vom Akteur während des Testzeitraums erlernten Strategie. Die Leistung des Akteurs im Strategietester wird unten dargestellt.
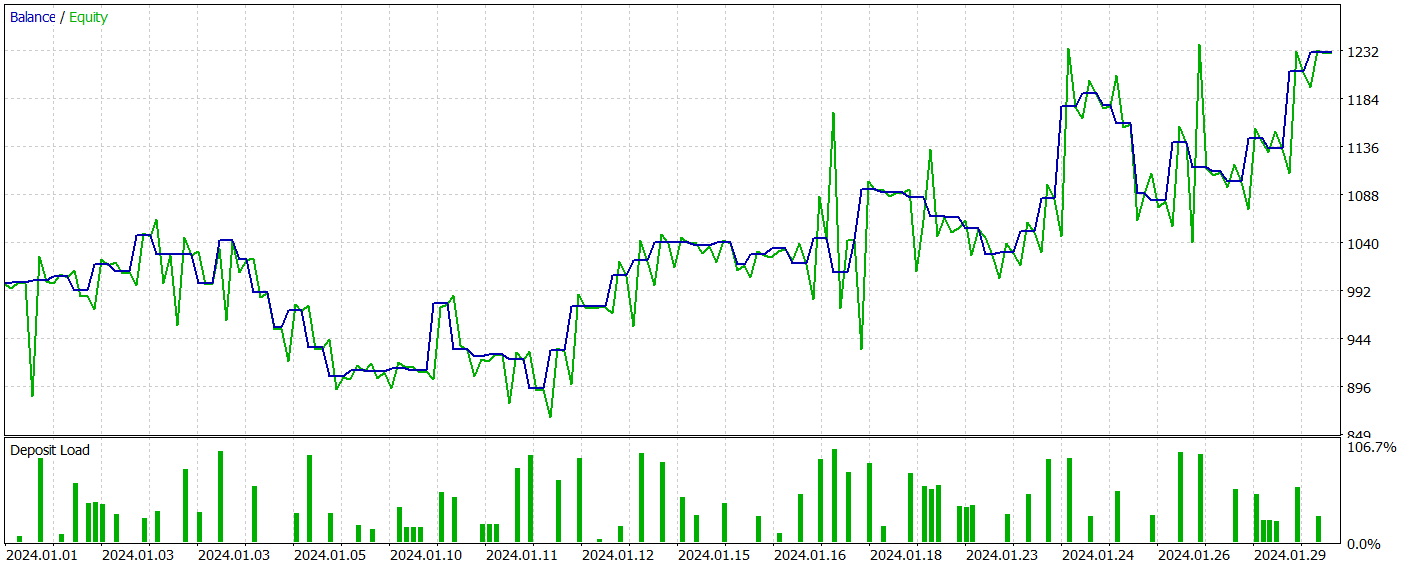
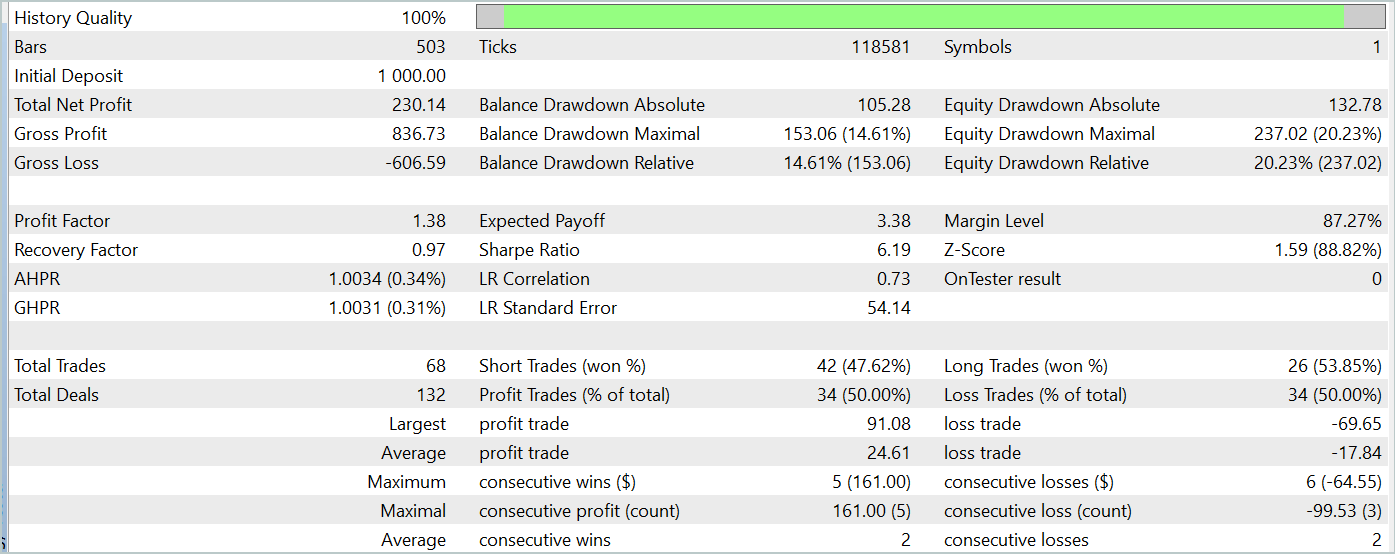
Während des Testzeitraums (Januar 2024) führte der Akteur 68 Handelsgeschäfte aus, von denen die Hälfte mit Gewinn abgeschlossen wurde. Noch wichtiger ist, dass sowohl die maximalen als auch die durchschnittlichen gewinnbringenden Handelsgeschäfte die entsprechenden mit Verlust übertrafen (91,08 und 24,61 gegenüber -69,85 und -17,84), was zu einem Gesamtgewinn von 23 % führte.
Allerdings weist der Kapitalkurve oberhalb und unterhalb der Saldenlinie deutliche Schwankungen auf. Dies weckt zunächst die Sorge, dass es zu einem „Festhalten an Verlusten“ und einem verzögerten Ausstieg aus Positionen kommt. Auffällig ist, dass in diesen Momenten die Einlagenbelastung 100 % erreicht, was auf eine übermäßige Risikoexposition schließen lässt. Dies wird durch den maximalen Drawdown von über 20 % bestätigt.
Als Nächstes haben wir ein zusätzliches Training der Akteursrichtlinie mit Anpassungen an den Parametern des Encoders der Umgebungszustände durchgeführt. Es ist wichtig hervorzuheben, dass diese Feinabstimmung ohne Aktualisierung des Trainingsdatensatzes durchgeführt wurde. Mit anderen Worten: Die Trainingsbasis blieb unverändert. Dieser Vorgang hatte jedoch negative Auswirkungen. Die Leistung des Modells verschlechterte sich: Die Anzahl der Transaktionen nahm ab, der Prozentsatz profitabler Transaktionen sank auf 45 %, die Gesamtrentabilität nahm ab und der Kapital-Drawdown überstieg 25 %.
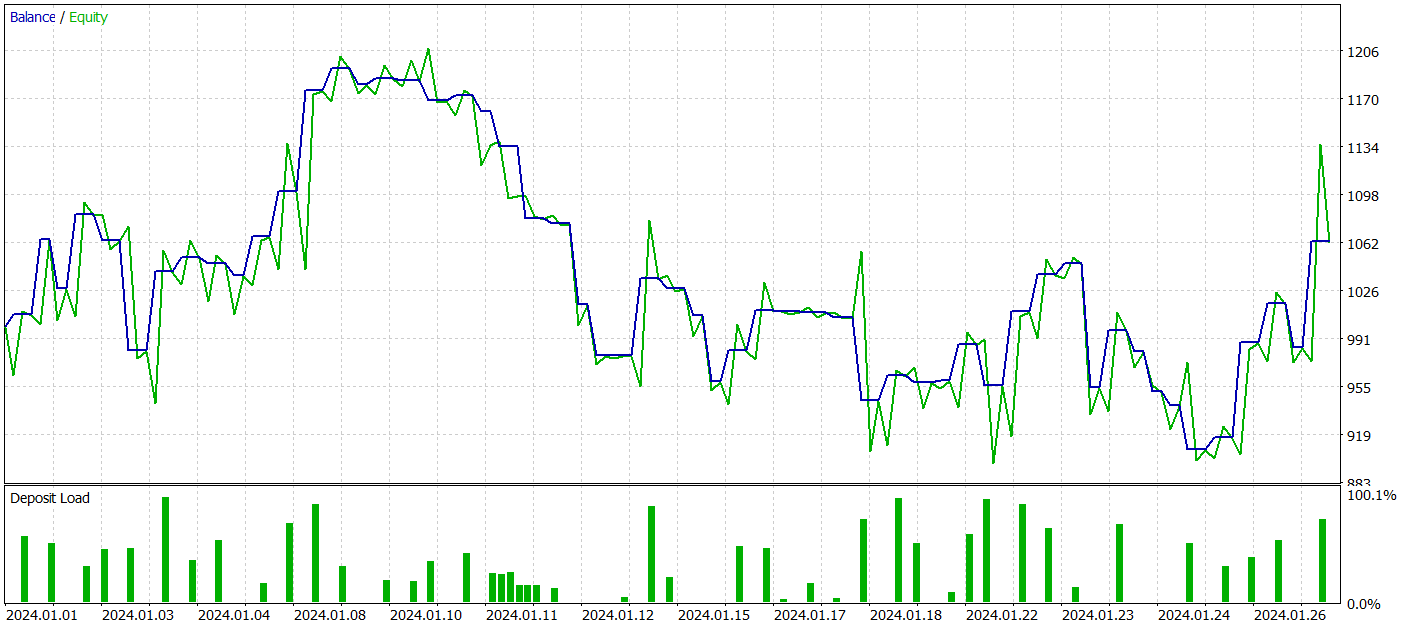
Interessanterweise änderte sich auch die Genauigkeit der vorhergesagten Preisbewegungsverläufe.
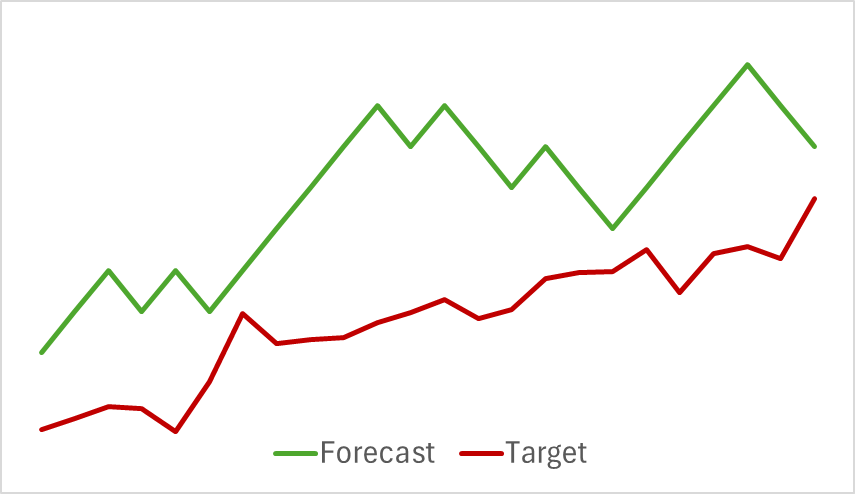
Meiner Ansicht nach führen wir zusätzliches Rauschen am Ausgang des Encoders ein, wenn wir beginnen, die Parameter des Encoders der Umgebungszustände zu optimieren, um sie an die Ziele des Akteurs und Kritikers anzupassen. Während der anfänglichen Trainingsphase stellte das Vorhersagemodell eine klare Übereinstimmung zwischen den Eingabedaten und den Ergebnissen fest, sodass es Muster effektiv erlernen und verallgemeinern konnte. Der vom Akteur und Kritiker empfangene Fehlergradient führt jedoch zu widersprüchlichem Rauschen, da das Modell versucht, seinen Fehler basierend auf den vom Encoder des Umgebungszustands bereitgestellten Daten zu minimieren. Dies führt dazu, dass der Encoder seine Funktion als Filter für Rohdaten verliert und die Effektivität aller Modelle abnimmt.
Schlussfolgerung
Wir haben eine innovative und komplexe Methode zur Zeitreihenprognose untersucht, TEMPO, bei der die Autoren vorgeschlagen haben, für Aufgaben zur Zeitreihenvorhersage vorab trainierte Sprachmodelle zu verwenden. Der vorgeschlagene Algorithmus führt einen neuartigen Ansatz zur Zeitreihenzerlegung ein und verbessert die Effizienz des Lernens von Datendarstellungen.
Wir haben umfangreiche Arbeit geleistet, um diese Ansätze in MQL5 zu implementieren. Obwohl wir keinen Zugriff auf ein vortrainiertes Sprachmodell hatten, lieferten unsere Experimente faszinierende Ergebnisse.
Insgesamt lassen sich die vorgeschlagenen Methoden auf die Entwicklung realer Handelsmodelle anwenden. Dabei muss jedoch berücksichtigt werden, dass das Trainieren von Modellen auf Basis von Transformer-Architekturen das Sammeln erheblicher Datenmengen erfordert und rechenintensiv sein kann.
Referenzen
- TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
- Weitere Artikel aus dieser Serie
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modelltraining EA |
| 4 | StudyEncoder.mq5 | Expert Advisor | Trainings-EA des Encoders |
| 5 | Test.mq5 | Expert Advisor | Trainings-EA für das Model |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek |
| 9 | Study2.mq5 | Expert Advisor | Expert Advisor zum Trainieren von Actor- und Critic-Modellen mit Encoder-Parameteranpassungen |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/15469
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Haltung gegenüber den Nutzern
Eindeutig
Nur für diejenigen, die denken, dass der Autor ihm etwas schuldet.....
Der Betrüger schuldet auch niemandem etwas.
Aber die Leute fallen aus irgendeinem Grund auf ihn herein.
Wenn die Artikel keine Auslöser und unverhohlene Motivation wie "...das Modell ist in der Lage, Gewinn zu generieren" enthielten, dann ist das in Ordnung. Unsere Probleme.
Und wenn ungeprüfte Informationen manipuliert werden, ist das nicht wirklich unser Problem.
In Anbetracht der Tatsache, dass der erste User wegen Kritik gesperrt wurde, werde ich auch endgültig Schluss machen. Sie können mit Gegenargumenten parieren, ich lasse es besser ohne Antwort.
...Wenn die Artikel keine Auslöser und unverhohlenen Begründungen wie "...das Modell ist in der Lage, Gewinne zu erwirtschaften" enthalten würden, dann wäre es in Ordnung. Unsere Probleme.
Und wenn sie ungeprüfte Informationen manipulieren - dann ist das nicht wirklich unser Problem....
Unter einem Artikel von Dmitry in den Kommentaren habe ich ihn gebeten, einen Artikel speziell über die Ausbildung seiner Expert Advisors zu schreiben. Er könnte jedes seiner Modelle aus einem beliebigen Artikel nehmen und in dem Artikel vollständig erklären, wie er es lehrt. Von Null bis zum Ergebnis, im Detail, mit allen Nuancen. Worauf ist zu achten, in welcher Reihenfolge lehrt er, wie oft, auf welchem Gerät, was er tut, wenn er nicht lernt, welche Fehler er anschaut. Hier ist so viel Detail wie möglich über das Training im Stil von "für Dummies". Aber Dmitry hat aus irgendeinem Grund diese Anfrage ignoriert oder nicht bemerkt und hat bis jetzt keinen solchen Artikel geschrieben. Ich denke, viele Leute werden ihm dafür dankbar sein.
Dmitry schreibe bitte einen solchen Artikel.
Es gibt ein Buch von Dmitry - Treffen Sie das Buch "Neural Networks in Algorithm Trading in MQL5 ".