
Redes neurais de maneira fácil (Parte 57): Stochastic Marginal Actor-Critic (SMAC)

Introdução
Quanto construímos um sistema de negociação automatizado, desenvolvemos algoritmos para uma tomada de decisão consistente. Os métodos de aprendizado por reforço procuram lidar com essas tarefas. Um dos principais problemas do aprendizado por reforço é o processo de exploração, quando o Agente aprende a interagir com o ambiente. Neste contexto, o princípio da máxima entropia é comumente usado para motivar o Agente a realizar ações com o mais alto grau de aleatoriedade. Entretanto, na prática, esses algoritmos treinam Agentes simples que só aprendem mudanças locais em torno de uma única ação. Isso se deve à necessidade de calcular a entropia da política do Agente e usá-la como parte do objetivo do aprendizado.
Paralelamente, um enfoque relativamente simples para aumentar a expressividade da política do Ator consiste em usar variáveis latentes, que oferecem ao Agente seu próprio procedimento de inferência para modelar a estocasticidade nas observações, no ambiente e nas recompensas desconhecidas.
A introdução de variáveis latentes na política do Agente permite abranger uma variedade maior de cenários compatíveis com o histórico de observações. É importante notar aqui que as políticas com variáveis latentes não admitem uma expressão simples para determinar sua entropia. A estimativa ingênua da entropia pode acarretar falhas catastróficas na otimização da política. Além disso, as atualizações estocásticas com alta variação para maximizar a entropia não distinguem imediatamente entre efeitos aleatórios locais e exploração multimodal.
Uma das soluções para essas limitações das políticas com variáveis latentes foi proposta no artigo "Latent State Marginalization as a Low-cost Approach for Improving Exploration". Nele, os autores propõem um algoritmo de otimização de política simples, mas eficaz, que é capaz de proporcionar uma exploração mais eficiente e estável tanto em ambientes totalmente observáveis quanto em ambientes parcialmente observáveis.
As principais contribuições do artigo mencionado podem ser resumidas nas seguintes teses:
- Motivação para o uso de políticas com variáveis latentes para melhorar a exploração e a estabilidade em condições de observabilidade parcial.
- São propostos vários métodos de estimativa estocástica, focados na eficiência da exploração e na redução da variância.
- A aplicação de abordagens ao método Ator-Crítico leva à criação do algoritmo Stochastic Marginal Actor-Critic (SMAC).
1. Algoritmo SMAC
Os autores do algoritmo "Stochastic Marginal Actor-Critic" sugerem o uso de variáveis latentes para construir a política distribuída do Ator. Este é um método simples e eficaz para aumentar a flexibilidade dos modelos e da política de ações do Agente. Esta abordagem requer mudanças mínimas para ser implementada em algoritmos existentes que usam políticas estocásticas de comportamento do Agente.
A política com variáveis latentes pode ser expressa da seguinte forma:
![]()
onde st é a variável latente, dependente da observação atual.
A introdução da variável latente q(st|xt) geralmente aumenta a expressividade da política do Ator. Isso permite que a política capture um espectro mais amplo de ações ótimas. O que pode ser particularmente útil no estágio inicial de exploração, quando há falta de informações sobre recompensas futuras.
Para a parametrização do modelo estocástico, os autores do método sugerem o uso de distribuições gaussianas fatorizadas tanto para a política do Ator π(at|st), quanto para a função das variáveis latentes q(st|xt). Isso leva a uma política computacionalmente eficiente em relação a variáveis latentes: a amostragem e a estimativa de densidade permanecem com baixo custo. Além disso, isso nos permite aplicar as abordagens propostas para construir modelos com base em algoritmos existentes com políticas estocásticas e uma distribuição gaussiana única. Simplesmente adicionamos um novo nó estocástico st.
Note que, devido à suposição do processo de Markov, π(at|st) depende apenas do estado latente atual, embora o algoritmo proposto possa ser facilmente estendido para situações não-markovianas. No entanto, graças à recorrência, observamos a marginalização sobre o histórico oculto completo. Afinal, o estado latente atual st, e, logo, a política π(at|st), é o resultado de uma série de transições do estado inicial sob a influência de ações realizadas pelo Agente.
![]()
Os métodos propostos para lidar com variáveis latentes não dependem do que q afeta.
A presença de variáveis latentes torna o treinamento com máxima entropia bastante complexo. Isso porque requer uma avaliação precisa do componente de entropia. E a entropia de um modelo com variáveis latentes é extremamente difícil de avaliar devido à dificuldade na marginalização. Além disso, o uso de variáveis latentes acarreta um aumento na variância do gradiente. E também, as variáveis latentes podem ser usadas na função Q para melhor agregação da incerteza.
Em cada um desses casos, os autores do Stochastic Marginal Actor-Critic formularam métodos bastante coerentes para tratar com variáveis latentes. Assim, o resultado final é bastante simples e acrescenta uma sobrecarga mínima de recursos adicionais em comparação com as políticas sem variáveis latentes.
Por sua vez, o uso de variáveis latentes torna a entropia (ou entropia marginal) inutilizável devido à dificuldade em encontrar o logaritmo da probabilidade.
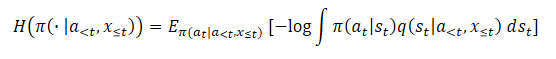
A aplicação de um estimador ingênuo tem como resultado a maximização do limite superior da função de entropia máxima desejada. Isso leva à maximização do erro. E isso estimula a distribuição variacional a ser o mais distante possível da verdadeira estimativa a posteriori q(st|a<t,x≤t). Além disso, esse erro não é limitado e pode se tornar arbitrariamente grande, não tendo um impacto real na verdadeira entropia que queremos maximizar, o que leva a sérios problemas de instabilidade numérica.
No artigo dos autores são mostrados os resultados de um experimento preliminar, no qual tal abordagem para a estimativa da entropia durante a otimização da política levou a valores extremamente altos, superestimando significativamente a verdadeira entropia e resultando em políticas que não foram aprendidas. Abaixo está uma visualização desse artigo.
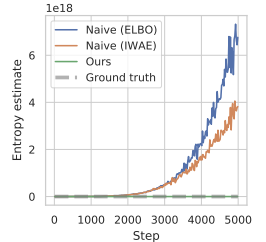
Para superar o problema mencionado de superestimação, os autores do método propõem construir um estimador do limite inferior da entropia marginal.
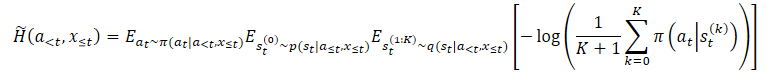
onde p(st|a≤t,x≤t) é a distribuição a posteriori desconhecida da política.
No entanto, podemos facilmente escolher primeiro st⁰, e então escolher at dado st⁰. Isso leva a um estimador aninhado, no qual na verdade escolhemos K+1 vezes de q(st|a<t,x≤t). Para a escolha da ação, usamos apenas a primeira variável latente st⁰. E todas as outras variáveis latentes são usadas para estimar a entropia marginal.
Observe que isso não é equivalente a substituir a expectativa dentro do logaritmo por amostras independentes. O estimador proposto aumenta monotonicamente com K, o que, no limite, torna-se um estimador não viesado da entropia marginal.
Os métodos mencionados podem ser aplicados a algoritmos gerais de maximização de entropia. No entanto, os autores do método criaram um algoritmo específico, que foi nomeado "Stochastic Marginal Actor-Critic" (SMAC). O SMAC é caracterizado pelo uso de uma política do Ator com variáveis latentes e pela maximização do limite inferior da função objetivo da entropia marginal.
O algoritmo segue o estilo comum de Ator-Crítico e usa um buffer de reprodução de experiência para armazenar os dados, que servem de base para a atualização dos parâmetros do Ator e do Crítico.
O Crítico é treinado por meio da minimização do erro:
![]()
onde:
(x, a, r, x') — do buffer de reprodução de experiência D,
a' — ação do Ator de acordo com a política π(·|x'),
Q ̅ — representa a função objetivo do Crítico,
H ̃ — estimativa da entropia da política.
Assim, estimamos a entropia da política com variáveis latentes.
Além disso, o Ator é atualizado minimizando o erro:
![]()
Observe que, ao atualizar o crítico, usamos a estimativa da entropia da política do Ator no estado seguinte. E ao atualizar a política do Ator - no estado atual.
No geral, o SMAC não difere muito do SAC ingênuo em termos de detalhes algorítmicos dos métodos de aprendizado por reforço, mas obtém melhorias principalmente devido ao comportamento de exploração estruturado. Isso é alcançado por meio da modelagem de variáveis latentes.
2. Implementação no MQL5
Já apresentada a parte teórica do método autoral Stochastic Marginal Actor-Critic, na parte prática deste artigo, implementaremos o algoritmo proposto usando MQL5. No entanto, não repetiremos completamente o algoritmo SMAC do autor. O artigo do autor afirma que os métodos propostos podem ser usados em quase todos os algoritmos de aprendizado por reforço. Aproveitaremos essa oportunidade e implementaremos os métodos propostos na nossa implementação do algoritmo NNM, que analisamos no artigo anterior.
E as primeiras mudanças serão feitas na arquitetura dos modelos. Como pode ser observado nas fórmulas apresentadas acima, a base do algoritmo SMAC é composta por três modelos:
- q — o modelo de representação do estado latente;
- π — o Ator;
- Q — o Crítico.
Acho que os dois últimos modelos não geram dúvidas. O primeiro modelo, o estado latente, representa um Codificador com um nó estocástico na saída. Neste caso, tanto o Ator quanto o Crítico como dados de entrada usam os resultados do trabalho desse Codificador. Será apropriado lembrar aqui o Codificador do autocodificador variacional.
Os trabalhos que temos permitem não separar o Codificador em um modelo à parte, mas mantê-lo, como antes, dentro da arquitetura do modelo do Ator. Assim, para implementar o algoritmo proposto, precisaremos fazer alterações na arquitetura do Ator. Especificamente, adicionar um nó estocástico na saída do bloco de pré-processamento de dados (Codificador).
A arquitetura dos modelos é especificada no método CreateDescriptions. Essencialmente, fazemos ajustes mínimos na arquitetura do Ator. Mantemos o bloco de pré-processamento de dados inalterado. Os dados históricos relativos ao movimento de preços e aos indicadores são alimentados em uma camada neural totalmente conectada. Depois, eles passam por um processamento inicial em uma camada de normalização em lote.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Depois, os dados normalizados passam por duas camadas convolucionais sucessivas, nas quais tentamos extrair alguns padrões da estrutura de dados.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; int prev_wout = descr.window_out = HistoryBars / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
E marginalizamos o estado do ambiente com duas camadas totalmente conectadas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Então, combinamos os dados obtidos com informações sobre o estado da conta. E aqui fazemos a primeira mudança na arquitetura do modelo. Antes do bloco estocástico, precisamos criar uma camada com o dobro do tamanho da representação latente: precisamos de indicadores de distribuição na forma de médias e variâncias. Portanto, especificamos o tamanho da camada de concatenação como o dobro da representação latente. E depois adicionamos a camada de estado latente do autocodificador variacional. É com essa camada que criamos o nó estocástico.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Observe que aumentamos o tamanho do nosso bloco de pré-processamento de dados (Codificador). E isso precisará ser considerado ao gerar a transferência de dados entre os modelos.
Deixamos o bloco de tomada de decisão do Ator inalterado. Ele contém três camadas totalmente conectadas e uma camada de estado latente do autocodificador variacional, que cria a estocasticidade do comportamento do Ator.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Agora, vamos falar sobre a arquitetura do Crítico. À primeira vista, nas sugestões dos autores do método SMAC, não há requisitos para a arquitetura do Crítico. E poderíamos muito bem deixá-la sem alterações. Mas lembre-se de que estamos usando uma função de recompensa decomposta. E surge a questão: onde incluir a entropia do nó estocástico adicionado? Poderíamos adicioná-la a qualquer um dos elementos de recompensa existentes. Mas, no contexto da decomposição da função de recompensa, faz mais sentido adicionar outro elemento na saída do Crítico. Por isso, aumentamos a constante do número de elementos de recompensa.
#define NRewards 5 //Number of rewards
No mais, a arquitetura do modelo do Crítico permaneceu sem alterações.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Para a implementação do algoritmo SMAC, especificamos todos os modelos necessários. No entanto, estamos implementando os métodos propostos no algoritmo NNM. Assim, mantemos todos os modelos previamente utilizados com o objetivo de preservar a funcionalidade completa do algoritmo. O modelo do Codificador Convolucional Aleatório é transferido sem mudanças. E não vamos nos deter nele. Você pode se familiarizar com ele em anexo. Lá também são apresentados todos os programas usados neste artigo.
E vamos voltar imediatamente à questão da transferência de dados entre os modelos. Para o Crítico acessar o estado latente do Ator, usamos o identificador da camada de estado latente, que está especificado na constante LatentLayer. Por isso, para redirecionar o Crítico para a camada neural apropriada de acordo com a mudança na arquitetura do Ator, basta alterar o valor dessa constante. Nenhuma outra correção no código do programa é necessária neste contexto.
#define LatentLayer 7
Agora, vamos discutir a questão do uso de algoritmos para calcular a componente de entropia na função de recompensa. Os autores do método apresentaram sua visão sobre a questão descrita na parte teórica. No entanto, estamos expandindo nossa implementação do método NNM, no qual usamos a norma nuclear como a componente de entropia do Ator. Para manter a comparabilidade dos valores dos diferentes elementos da função de recompensa, é lógico usar uma abordagem semelhante para o Codificador.
Os autores do método SMAC sugerem usar K+1 amostras do Codificador para estimar a entropia do estado latente. Claramente, para um estado ambiental específico durante o treinamento do Codificador, chegaremos a algum valor médio bastante rapidamente. E, no curso da otimização adicional dos parâmetros do Codificador, buscaremos reduzir o valor da variância para maximizar a separação dos estados individuais. Com a redução da variância para o limite de "0", a entropia também tenderá a "0". Obteremos o mesmo efeito ao usar a norma nuclear?
Para responder a esta pergunta, podemos mergulhar nas fórmulas matemáticas. Ou podemos verificar na prática. Claro, não vamos agora criar e treinar um modelo por um longo tempo para verificar a viabilidade de usar a norma nuclear. Faremos isso de uma maneira muito mais simples e rápida. Vamos criar um pequeno script em Python.
Primeiro, importaremos duas bibliotecas: numpy e matplotlib. Usaremos a primeira para cálculos e a segunda para visualização dos resultados.
# Импорт библиотек import numpy as np import matplotlib.pyplot as plt
Para criar amostras, precisaremos de estatísticas de distribuições: médias e as variâncias correspondentes. Durante o treinamento, elas serão geradas pelo modelo. Valores aleatórios são suficientes para testar a abordagem.
mean = np.random.normal(size=[1,10]) std = np.random.rand(1,10)
Note que qualquer número pode ser usado como médias. E nós os geramos a partir de uma distribuição normal. Mas as variâncias devem ser apenas positivas, e nós as geramos no intervalo (0, 1].
Analogamente ao nó estocástico, usaremos o truque de reparametrização da distribuição. Para isso, geraremos uma matriz de valores aleatórios de uma distribuição normal.
data = np.random.normal(size=[20,10])
E prepararemos um vetor para registrar nossas recompensas internas.
reward=np.zeros([20])
A ideia é a seguinte: é necessário verificar como os recompensas internas se comportam ao usar a norma nuclear com a redução da variância e outras condições iguais.
Para reduzir a variância, criaremos um vetor de coeficientes redutores.
scl = [2**(-k/2.0) for k in range(20)]
Em seguida, criamos um laço no qual usaremos o truque de reparametrização da distribuição para nossos dados aleatórios com médias constantes e variância decrescente. Com base nos dados obtidos, calcularemos a recompensa interna usando a norma nuclear. E armazenaremos os resultados obtidos no vetor de recompensas preparado.
for idx, k in enumerate(scl): new_data=mean+data*(std*k) _,S,_=np.linalg.svd(new_data) reward[idx]=S.sum()/(np.sqrt(new_data*new_data).sum()*max(new_data.shape))
Visualizaremos os resultados do script.
# Отрисовка результатов
plt.plot(scl,reward)
plt.gca().invert_xaxis()
plt.ylabel('Reward')
plt.xlabel('STD multiplier')
plt.xscale('log',base=2)
plt.savefig("graph.png")
plt.show() 
Os resultados obtidos demonstram claramente a redução da recompensa interna ao usar a norma nuclear com a redução da variância da distribuição, sob outras condições iguais. Isso significa que podemos confiantemente usar a norma nuclear também para avaliar a entropia do estado latente.
Voltamos à nossa implementação do algoritmo usando MQL5. E agora podemos prosseguir com a implementação da avaliação da entropia do estado latente. Primeiramente, precisamos definir o número de estados latentes para amostragem. Esse indicador será definido pela constante SamplLatentStates.
#define SamplLatentStates 32
A próxima questão é: realmente precisamos realizar uma passagem completa para frente no modelo do Codificador (no nosso caso, o Ator) para amostrar cada estado latente?
É bastante óbvio que, sem mudança nos dados de entrada e nos parâmetros do modelo, o desempenho de todas as camadas neurais serão idênticos a cada passagem subsequente. A única diferença está nos resultados do nó estocástico. Consequentemente, para cada estado específico, precisamos de apenas uma propagação do modelo do Ator. Em seguida, usaremos o truque de reparametrização da distribuição e amostraremos a quantidade necessária de estados latentes. Acredito que a ideia esteja clara e podemos prosseguir para a implementação.
Primeiro, geramos uma matriz de valores aleatórios da distribuição normal com média "0" e variância "1". Esses parâmetros de distribuição são os mais convenientes para reparametrização.
float EntropyLatentState(CNet &net) { //--- random values double random[]; Math::MathRandomNormal(0,1,LatentCount * SamplLatentStates,random); matrix<float> states; states.Assign(random); states.Reshape(SamplLatentStates,LatentCount);
Em seguida, carregaremos da nossa modelo do Ator os parâmetros de distribuição aprendidos, que são armazenados na penúltima camada do Codificador. É importante notar que nosso modelo tem um buffer de dados no qual são armazenados sequencialmente primeiro todas as médias da distribuição aprendida e, após elas, todas as variâncias. No entanto, para realizar operações matriciais, precisaremos não de um vetor, mas de duas matrizes com valores duplicados nas linhas. E aqui faremos um pequeno truque. Primeiro, criamos uma grande matriz com o número necessário de linhas e o dobro do número de colunas, preenchida com valores zero. Na primeira linha, registramos os dados do buffer com os parâmetros das distribuições. E então usaremos a função de soma cumulativa de valores da matriz pelas colunas.
O truque é que todas as linhas, exceto a primeira, estão preenchidas com zeros. E, como resultado da operação de soma cumulativa, simplesmente copiaremos os dados da primeira linha para todas as seguintes.
Agora, simplesmente dividimos a matriz em duas iguais verticalmente e obtemos um array de matrizes split. Nesse array, a matriz de médias tem índice 0. E a matriz de variâncias tem índice 1.
//--- get means and std vector<float> temp; matrix<float> stats = matrix<float>::Zeros(SamplLatentStates,2 * LatentCount); net.GetLayerOutput(LatentLayer - 1,temp); stats.Row(temp,0); stats=stats.CumSum(0); matrix<float> split[]; stats.Vsplit(2,split);
Agora, nós realizamos de forma bastante simples a reparametrização de valores aleatórios de uma distribuição normal. E obtemos a quantidade desejada de amostras.
//--- calculate latent values states = states * split[1] + split[0];
Na parte inferior da matriz, adicionamos uma linha com os valores atuais do Codificador, que foram utilizados pelo Ator e pelos Críticos como dados de entrada durante a propagação.
//--- add current latent value net.GetLayerOutput(LatentLayer,temp); states.Resize(SamplLatentStates + 1,LatentCount); states.Row(temp,SamplLatentStates);
Nesta etapa, todos os dados para o cálculo da norma nuclear estão prontos. E realizamos o cálculo do componente de entropia da função de recompensa. O resultado obtido é retornado ao programa chamador.
//--- calculate entropy states.SVD(split[0],split[1],temp); float result = temp.Sum() / (MathSqrt(MathPow(states,2.0f).Sum() * MathMax(SamplLatentStates + 1,LatentCount))); //--- return result; }
Pode-se dizer que o trabalho preparatório está concluído. E passamos a trabalhar no EA de interação com o ambiente e treinamento de modelos.
Desde já dizemos que os EA de interação com o ambiente (Research.mq5 e Test.mq5) permaneceram inalterados e não vamos focar neles agora. No anexo você pode encontrar o código completo dos programas mencionados, bem como de todos os outros utilizados neste artigo.
Agora, passamos para o EA de treinamento de modelos e focamos no método de treinamento Train. No início do método, determinaremos o tamanho total do buffer de reprodução de experiência.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Em seguida, realizaremos a codificação de todos os exemplos existentes no buffer de reprodução de experiência usando um codificador convolucional aleatório. Este processo é completamente retirado da implementação anterior.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); next.Assign(Buffer[tr].States[st + 1].rewards); rewards.Row(temp - next * DiscFactor,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão da codificação de todos os exemplos do buffer de reprodução de experiência, removeremos as linhas extras das matrizes.
if(state != total_states)
{
rewards.Resize(state,NRewards);
state_embedding.Reshape(state,state_embedding.Cols());
total_states = state;
}
Segue-se o bloco de treinamento direto dos modelos. Aqui, inicializamos variáveis locais e criamos um ciclo para o treinamento dos modelos. O número de iterações do ciclo é definido pela variável externa Iterations.
vector<float> rewards1, rewards2; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
No corpo do ciclo, amostramos uma trajetória e um estado específico do ambiente para a iteração atual de atualização dos parâmetros dos modelos.
Depois, verificamos o valor limiar para o uso de modelos alvo. E, se necessário, carregamos os dados do estado subsequente nos buffers de dados correspondentes.
target_reward = vector<float>::Zeros(NRewards); reward.Assign(Buffer[tr].States[i].rewards); //--- Target TargetState.AssignArray(Buffer[tr].States[i + 1].state); if(iter >= StartTargetIter) { float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
Os dados preparados são utilizados para a execução da propagação do Ator e de dois modelos alvo Críticos.
if(!Actor.feedForward(GetPointer(TargetState), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Com base nos resultados da propagação dos modelos alvo, preparamos um vetor do valor do estado subsequente. E adicionamos obrigatoriamente ao vetor obtido uma estimativa de entropia do estado latente de acordo com o algoritmo SMAC.
TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; for(ulong r = 0; r < target_reward.Size(); r++) target_reward -= Buffer[tr].States[i + 1].rewards[r]; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
Após a preparação do vetor do valor do estado subsequente, passamos a trabalhar com o estado selecionado do ambiente. E preenchemos os buffers necessários com os dados de entrada correspondentes.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Em seguida, realizamos a propagação do Ator para gerar o estado latente do ambiente.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Na etapa de atualização dos parâmetros dos Críticos, usamos apenas o estado latente. As ações do Ator são retiradas do buffer de reprodução de experiências. E chamamos a propagação de ambos os Críticos.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A atualização dos parâmetros dos Críticos é realizada levando em conta a recompensa real do ambiente, ajustada pela política atual do Ator. Os parâmetros de influência da política atualizada do Ator já estão considerados no vetor do valor do estado subsequente do ambiente.
Lembro que utilizamos uma função de recompensa decomposta e, para a otimização dos gradientes, aplicamos o método CAGrad. Isso resulta na obtenção de diferentes vetores de valores de referência para cada Crítico. Primeiramente, preparamos o vetor de valores de referência e realizamos a retropropagação do primeiro Crítico.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(reward + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Depois, repetimos as operações para o segundo Crítico.
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(reward + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Note que, após a atualização dos parâmetros de cada Crítico, realizamos a retropropagação para atualizar os parâmetros do Codificador. E não esquecemos de monitorar a execução de operações em cada etapa.
Após a atualização dos parâmetros dos Críticos, passamos a trabalhar na otimização do modelo do Ator. E para definir o gradiente de erro no nível do Ator, usaremos o Crítico com o menor erro médio móvel de previsão do valor das ações do Ator. Tal abordagem potencialmente nos dará uma avaliação mais precisa das ações geradas pela política do Ator. E, como consequência, uma distribuição mais correta do gradiente de erro.
//--- Policy study CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
A propagação do Ator já foi realizada anteriormente. E agora formaremos o estado subsequente previsto do ambiente. Precisamente, o previsto. Pois no buffer de reprodução de experiências existem dados históricos de movimento de preços e indicadores. Estes não dependem das ações do Ator e nós os utilizamos com confiança. No entanto, o estado da conta depende diretamente das operações de negociação realizadas pelo Ator. E as ações dentro da política atual do Ator podem diferir das armazenadas no buffer de reprodução de experiências. Nesta fase, nos cabe formar o vetor previsto de descrição do estado da conta. Para nossa comodidade, essa funcionalidade já foi implementada no método ForecastAccount, que examinamos no artigo anterior. E agora basta apenas chamá-lo com a passagem dos dados de entrada corretos.
Actor.getResults(rewards1); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,rewards1,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetState.AddArray(forecast);
Agora que temos todos os dados necessários, realizamos a propagação do Crítico selecionado e do Codificador Convolutivo Aleatório para formar a incorporação do estado subsequente previsto.
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Convolution.feedForward(GetPointer(TargetState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Com base nos dados obtidos, formamos o vetor de valores de referência da função de recompensa para a atualização dos parâmetros do Ator. E ajustamos sempre o gradiente de erro usando o método CAGrad.
next.Assign(Buffer[tr].States[i + 1].rewards); Convolution.getResults(rewards1); target_reward += KNNReward(KNN,rewards1,state_embedding,rewards) + next * DiscFactor; if(forecast[3] == 0.0f && forecast[4] == 0.0f) target_reward[2] -= (Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance); critic.getResults(reward); reward += CAGrad(target_reward - reward);
Após isso, desativamos o modo de atualização dos parâmetros do Crítico e realizamos sua retropropagação. E em seguida efetuamos a completa retropropagação do Ator.
Result.AssignArray(reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
É essencial monitorar a execução das operações. E após a execução bem-sucedida da retropropagação de ambos os modelos, retornamos o Crítico para o modo de treinamento.
Nesta etapa, atualizamos os parâmetros de ambos os Críticos e do Ator. Resta apenas atualizar os parâmetros dos modelos alvo dos Críticos. Aqui, usamos a atualização suave dos parâmetros dos modelos com o coeficiente Tau, que é definido nos parâmetros externos do Expert Advisor.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau);
E ao finalizar as operações no corpo do ciclo de treinamento dos modelos, informamos o usuário sobre o progresso do treinamento e passamos para a próxima iteração do ciclo.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após a conclusão bem-sucedida de todas as iterações do ciclo de treinamento dos modelos, limpamos o campo de comentários no gráfico. Exibimos os resultados do treinamento no log e iniciamos a conclusão do trabalho do Expert Advisor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Creio que você tenha notado que, no processo de treinamento do Ator, pulamos o cálculo do componente de entropia do estado latente, que é previsto pelo método SMAC. Na verdade, não optamos por dividir o processo de formação do vetor de recompensas em partes separadas. Na construção do algoritmo NNM, este processo foi colocado em um método separado, KNNReward. Foi justamente neste método que fizemos as correções necessárias.
Como anteriormente, no corpo do método, primeiro verificamos a correspondência entre os tamanhos da incorporação do estado previsto e na matriz de incorporações de estados do ambiente do buffer de reprodução de experiências.
vector<float> KNNReward(ulong k, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards ) { if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return vector<float>::Zeros(0); }
Após passar com sucesso pelo bloco de controles, procedemos com a inicialização das variáveis locais necessárias.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); k = MathMin(k,states); ulong rew_size = rewards.Cols(); vector<float> distance = vector<float>::Zeros(states); matrix<float> k_rewards = matrix<float>::Zeros(k,rew_size); matrix<float> k_embeding = matrix<float>::Zeros(k + 1,size); matrix<float> U,V; vector<float> S;
Com isso, concluímos a etapa de trabalho preparatório e passamos diretamente para as operações de cálculo. Primeiro, determinamos a distância entre o estado previsto e os exemplos reais do buffer de reprodução de experiências.
for(ulong i = 0; i < size; i++) distance+=MathPow(state_embedding.Col(i) - embedding[i],2.0f); distance = MathSqrt(distance);
Identificamos os k-vizinhos mais próximos e preenchemos a matriz de incorporações. E também transferimos as recompensas correspondentes para uma matriz previamente preparada. Simultaneamente, ajustamos o vetor de recompensas por um coeficiente inversamente proporcional à distância entre os vetores de estado. O coeficiente mencionado determinará a influência das recompensas do buffer de reprodução de experiências no resultado da ação escolhida pelo Ator de acordo com a política de comportamento atualizada.
for(ulong i = 0; i < k; i++) { ulong pos = distance.ArgMin(); k_rewards.Row(rewards.Row(pos) * (1 - MathLog(distance[pos] + 1)),i); k_embeding.Row(state_embedding.Row(pos),i); distance[pos] = FLT_MAX; }
Na matriz de incorporações, adicionamos como última linha a incorporação do estado previsto do ambiente.
k_embeding.Row(embedding,k);
E encontramos o vetor de valores singulares da matriz de incorporações obtida. Esta operação é facilmente realizada utilizando operações matriciais embutidas.
k_embeding.SVD(U,V,S);
Formamos o vetor de recompensas como o valor médio das recompensas correspondentes dos k-vizinhos mais próximos, ajustados pelo coeficiente de participação.
vector<float> result = k_rewards.Mean(0);
Os dois últimos elementos do vetor de recompensas são preenchidos com a componente de entropia, utilizando a norma nuclear da política do Ator e o estado latente, respectivamente.
result[rew_size - 2] = S.Sum() / (MathSqrt(MathPow(k_embeding,2.0f).Sum() * MathMax(k + 1,size))); result[rew_size - 1] = EntropyLatentState(Actor); //--- return (result); }
O vetor de recompensas formado é retornado ao programa chamador. Todos os demais métodos do EA são transferidos sem alterações.
Com isso, concluímos o trabalho com o EA de treinamento de modelos. No anexo você pode se familiarizar independentemente com o código completo dele, assim como de todos os programas usados no artigo. E agora passamos para a etapa de testes do trabalho realizado.
3. Testes
Na parte prática deste artigo, realizamos um trabalho sério na implementação do método Stochastic Marginal Actor-Critic no EA do algoritmo NNM anteriormente elaborado. E agora, movemo-nos para a fase de testes do trabalho realizado. Como sempre, o treinamento e os testes dos modelos são realizados com dados históricos do EURUSD com timeframe H1. Os parâmetros de todos os indicadores são usados por padrão.
Já é setembro lá fora. E eu aumentei o período de treinamento para 7 meses de 2023. O teste do desempenho do modelo será realizado com dados históricos de agosto de 2023.
Ao criar o EA de treinamento "...\NNM\Study.mq5", falamos sobre as peculiaridades do método NNM e o problema da falta de estados gerados no buffer de reprodução de experiência. Então decidimos reduzir o número de iterações de um único ciclo de treinamento. E agora vamos aderir às mesmas abordagens para o processo de treinamento dos modelos.
De forma análoga ao processo de treinamento usado no artigo anterior, não reduzimos o buffer de reprodução de experiência de modo geral. Mas, paralelamente, estaremos preenchendo o buffer de reprodução de experiência gradualmente. Na primeira iteração, lançamos o EA de coleta de dados de treinamento fazendo 100 passagens. No intervalo histórico especificado, isso já nos dá quase 360K estados para o treinamento dos modelos.
Após a primeira iteração de treinamento dos modelos, complementamos a base de exemplos com mais 50 passagens. Assim, preenchemos gradualmente o buffer de reprodução de experiência com novos estados, que correspondem às ações do Ator dentro da política de treinamento.
Repetimos o treinamento dos modelos e a coleta de exemplos adicionais várias vezes até alcançar o resultado desejado do treinamento da política do Ator.
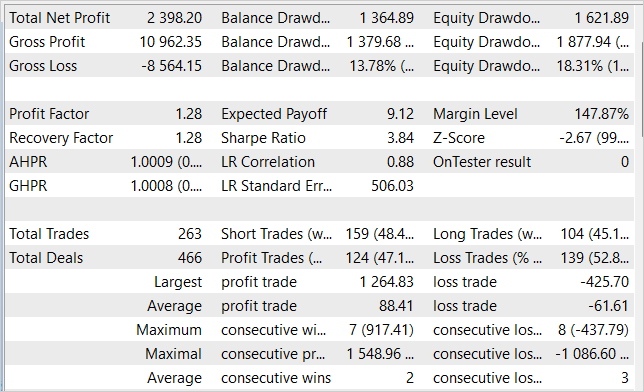
Durante o treinamento dos modelos, conseguimos obter uma política do Ator capaz de gerar lucro na amostra de treinamento e generalizar o conhecimento adquirido para estados sucessivos do ambiente. Assim, no testador de estratégias, o modelo que treinamos conseguiu gerar um lucro de 23,98% em 1 mês, seguindo a amostra de treinamento. Durante o período de teste, o modelo realizou 263 operações de negociação, 47% delas foram fechadas com lucro. A máxima lucratividade em uma única operação é quase três vezes superior à máxima operação perdedora. E o lucro médio por operação é 44% maior que a perda média. Tudo isso, em conjunto, permitiu alcançar um fator de lucro de 1,28. Ao mesmo tempo, no gráfico da linha de saldo, observamos uma clara tendência de crescimento.

Considerações finais
Neste artigo, iniciamo-nos no método Stochastic Marginal Actor-Critic, que representa uma abordagem inovadora para resolver problemas de treinamento com reforço. Baseando-se no princípio da máxima entropia, o SMAC permite ao agente explorar o ambiente de forma mais eficaz e treinar de maneira mais estável, o que é alcançado pela introdução de um nó estocástico adicional de variáveis latentes.
O uso de variáveis latentes na política do Agente permite aumentar significativamente sua expressividade e capacidade de modelar a estocasticidade nas observações e recompensas.
Entretanto, existem algumas dificuldades notreinamento da política com variáveis latentes. E os autores do método propõem soluções que permitem lidar com essas dificuldades.
Na parte prática do artigo, nós integramos com sucesso o SMAC na arquitetura do método NNM, criando um método de otimização de política simples e eficaz, o que é confirmado pelos resultados dos testes. Conseguimos treinar uma política do Ator capaz de gerar um retorno de até 24% ao mês.
Considerando esses resultados, o método SMAC representa uma solução eficaz para resolver problemas práticos.
No entanto, quero salientar que todos os programas apresentados no artigo foram criados apenas para demonstrar o método e não são adequados para operar em contas reais. Eles requerem ajustes adicionais e otimização de funcionalidades.
Lembro que os mercados financeiros são uma forma de investimento de alto risco. E todos os riscos de operações realizadas por você ou por meios eletrônicos que você utiliza são de sua total responsabilidade.
Referências
- Latent State Marginalization as a Low-cost Approach for Improving Exploration
- Redes neurais de maneira fácil (Parte 56): Utilização da norma nuclear para estimular a pesquisa
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | Study.mq5 | EA | EA de treinamento do agente |
| 3 | Test.mq5 | EA | EA para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criar redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13290
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Cada passagem do EA de teste gera resultados drasticamente diferentes, como se o modelo fosse diferente de todos os anteriores. É óbvio que o modelo evolui a cada passagem do teste, mas o comportamento desse EA dificilmente é uma evolução, então o que está por trás disso?
Aqui estão algumas imagens:
Esse modelo usa a política estocástica do Ator. Portanto, no início do estudo, podemos ver acordos aleatórios em cada passagem. Coletamos essas passagens e reiniciamos o estudo do modelo. E repetimos esse processo algumas vezes. Enquanto o Ator encontra uma boa política de ações.
Vamos colocar a questão de outra forma. Depois de coletar amostras (pesquisa) e processá-las (estudo), executamos o script de teste. Em várias execuções consecutivas, sem nenhuma pesquisa ou estudo, os resultados obtidos são completamente diferentes.
O script de teste carrega um modelo treinado na sub-rotina OnInit (linha 99). Aqui alimentamos o EA com um modelo que não deve ser alterado durante o processamento do teste. Ele deve ser estável, pelo que entendi. Então, os resultados finais não devem mudar.
Nesse meio tempo, não realizamos nenhum treinamento de modelo. Apenas a coleta de mais amostras é realizada pelo teste.
A aleatoriedade é observada no módulo Research e possivelmente no Study durante a otimização de uma política.
O Actor é chamado na linha 240 para calcular os resultados de feedforward. Se ele não for inicializado aleatoriamente no momento da criação, acredito que esse seja o caso, ele não deve se comportar de forma aleatória.
Você encontrou algum equívoco no raciocínio acima?
Vamos colocar a questão de outra forma. Depois de coletar amostras (pesquisa) e processá-las (estudo), executamos o script de teste. Em várias execuções consecutivas, sem nenhuma pesquisa ou estudo, os resultados obtidos são completamente diferentes.
O script de teste carrega um modelo treinado na sub-rotina OnInit (linha 99). Aqui alimentamos o EA com um modelo que não deve ser alterado durante o processamento do teste. Ele deve ser estável, pelo que entendi. Então, os resultados finais não devem mudar.
Nesse meio tempo, não realizamos nenhum treinamento de modelo. Apenas a coleta de mais amostras é realizada pelo teste.
A aleatoriedade é observada no módulo Research (Pesquisa) e possivelmente no Study (Estudo) durante a otimização de uma política.
O Actor é chamado na linha 240 para calcular os resultados de feedforward. Se ele não for inicializado aleatoriamente no momento da criação, acredito que esse seja o caso, ele não deve se comportar de forma aleatória.
Você encontrou algum equívoco no raciocínio acima?
O Actor usa política estocástica. Nós a implementamos pelo VAE.
A camada CNeuronVAEOCL usa os dados da camada anterior como média e STD da distribuição gaussiana e faz uma amostra da mesma ação a partir dessa distribuição. No início, colocamos no modelo pesos aleatórios. Assim, ele gera médias e DSTs aleatórios. No final, temos ações aleatórias em cada passagem do teste do modelo. No momento do estudo, o modelo encontrará algumas médias para cada estado e o STD tende a zero.