
Redes neuronales: así de sencillo (Parte 57): Stochastic Marginal Actor-Critic (SMAC)

Introducción
Al construir un sistema comercial automatizado, desarrollamos algoritmos para la toma de decisiones secuenciales. Los métodos de aprendizaje por refuerzo tienen por objeto resolver este tipo de problemas. Uno de los retos clave en el aprendizaje por refuerzo es el proceso de exploración, en el que el Agente aprende a interactuar con el entorno. En este contexto, el principio de máxima entropía se usa a menudo para motivar al Agente a realizar acciones con el mayor grado de aleatoriedad. Sin embargo, en la práctica, dichos algoritmos entrenan Agentes simples que solo aprenden cambios locales en torno a una única acción. Esto se debe a la necesidad de calcular la entropía de la política del Agente y usarla como parte del objetivo del entrenamiento.
Al mismo tiempo, un enfoque relativamente sencillo para aumentar la expresividad de la política del Agente sería utilizar variables latentes que proporcionen al Agente su propio procedimiento de inferencia para modelar la estocasticidad en las observaciones, el entorno y las recompensas desconocidas.
La introducción de variables latentes en la política del Agente permitirá abarcar una mayor variedad de escenarios compatibles con la historia de observaciones. Aquí cabe señalar que las políticas con variables latentes no admitirán una expresión sencilla para definir su entropía. Una estimación ingenua de la entropía puede provocar fallos catastróficos en la optimización de las políticas. Además, las actualizaciones estocásticas con alta varianza para maximizar la entropía no distinguen de inmediato entre efectos aleatorios locales y exploración multimodal.
Una de las soluciones a estas deficiencias de las políticas de variables latentes se ofreció en el artículo "Latent State Marginalization as a Low-cost Approach for Improving Exploration". En él, los autores proponen un algoritmo de optimización de políticas sencillo pero eficaz que puede posibilitar una exploración más eficiente y robusta tanto en entornos totalmente observados como parcialmente observados.
Las principales aportaciones de este artículo pueden resumirse en las tesis siguientes:
- Motivación del uso de políticas de variable latente para mejorar la exploración y en condiciones de observabilidad parcial.
- Se ofrecen varios métodos de estimación estocástica, centrados en la eficacia de la exploración y la reducción de la varianza.
- La aplicación de los enfoques Actor-Crítico conduce al algoritmo Stochastic Marginal Actor-Critic (SMAC)
1. Algoritmo SMAC
Los autores del algoritmo Stochastic Marginal Actor-Critic (SMAC) proponen utilizar variables latentes para construir una política de Actor distribuida. Se trata de una forma simple y eficaz de aumentar la flexibilidad de los modelos y las políticas de acciones del Agente. Este enfoque requiere cambios mínimos para implementarlo en los algoritmos existentes que usan políticas estocásticas de comportamiento de los agentes.
Una política con variables latentes puede expresarse de la forma siguiente:
![]()
donde st es una variable latente que depende de la observación actual.
La introducción de una variable latente q(st|xt) suele aumentar la expresividad de la política del Actor. Esto permite a la política captar una gama más amplia de acciones óptimas, lo que puede resultar especialmente útil en las primeras fases de una exploración, cuando se carece de información sobre las recompensas futuras.
Para parametrizar el modelo estocástico, los autores del método proponen utilizar distribuciones gaussianas factorizadas tanto para la política del Actor π(at|st), como para la función de variables latentes q(st|xt), lo cual conduce a una política computacionalmente eficiente con variables latentes: el muestreo y la estimación de la densidad seguirán siendo poco costosos. Además, nos permitirá aplicar los enfoques propuestos para construir modelos basados en algoritmos existentes con políticas estocásticas y una única distribución gaussiana. Simplemente añadiremos un nuevo nodo estocástico st.
Nótese que, debido a la suposición de un proceso de Markov π(at|st) solo dependerá del estado latente actual, aunque el algoritmo propuesto sea fácilmente extensible a situaciones no Markovianas. Sin embargo, gracias a la recurrencia, observaremos la marginación por la historia oculta completa. De hecho, el estado latente actual st, por consiguiente, la política π(at|st) también será la consecuencia de una serie de transiciones desde el estado inicial bajo la influencia de las acciones realizadas por el Agente.
![]()
Además, los enfoques propuestos para tratar las variables latentes son independientes de aquello en lo que q influye.
La presencia de variables latentes hace que el entrenamiento de la entropía máxima resulte todo un reto. Después de todo, esto requiere una estimación precisa del componente de entropía, y la entropía de un modelo con variables latentes resulta extremadamente difícil de estimar debido a la dificultad de la marginación. Además, el uso de variables latentes provoca un aumento de la varianza del gradiente, y también pueden utilizarse variables latentes en la función Q para una mejor agregación de la incertidumbre.
En cada uno de estos casos, los autores del SMAC derivan métodos razonables para manejar las variables latentes. El resultado final es bastante sencillo y añade una sobrecarga mínima de recursos adicionales en comparación con las políticas sin variables latentes.
A su vez, el uso de variables latentes inutiliza la entropía (o la entropía marginal) debido a la dificultad de hallar el logaritmo de probabilidad.
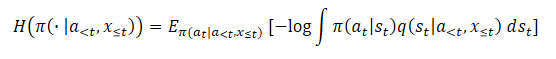
Si se aplica el estimador ingenuo, se maximizará el límite superior del objetivo de máxima entropía funcional, lo que lleva a maximizar el error, y esto favorece que la distribución variacional se aleje lo máximo posible de la verdadera estimación posterior q(st|a<t,x≤t). Además, este error no tiene límite y podría llegar a ser aleatoriamente grande sin afectar verdaderamente a la entropía real que queremos maximizar, lo que provoca graves problemas de inestabilidad numérica.
El artículo de los autores muestra los resultados de un experimento preliminar en el que este enfoque para la estimación de la entropía durante la optimización de políticas condujo a valores extremadamente grandes, sobrestimando significativamente la verdadera entropía y conduciendo a políticas que no aprendían. A continuación le mostramos una visualización del artículo de los autores.
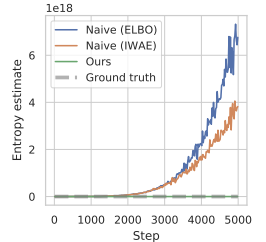
Para superar el problema de sobreestimación anterior, los autores del método proponen construir un estimador del límite inferior de la entropía marginal.
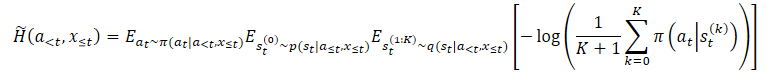
donde p(st|a≤t,x≤t) es la distribución a posteriori desconocida de la política.
No obstante, podemos elegir fácilmente de ella primero st⁰, y luego seleccionar at con la condición de que st⁰. Esto conduce a un estimador anidado en el que en realidad elegimos K+1 veces de q(st|a<t,x≤t). solo utilizaremos la primera variable latente para seleccionar una acción st⁰. Y todas las demás variables latentes se utilizarán para estimar la entropía marginal.
Nótese que esto no equivale a sustituir la esperanza dentro del logaritmo por muestras independientes. El estimador propuesto aumentará monotónicamente con K, que en el límite se convertirá en un estimador no desplazado de entropía marginal.
Los métodos anteriores pueden aplicarse a algoritmos generales de maximización de la entropía, pero los autores del método crean un algoritmo específico llamado "Stochastic Marginal Actor-Critic" (SMAC). El SMAC se caracteriza por utilizar una política Actor con variables latentes y maximizar el límite inferior de la función objetivo de entropía marginal.
El algoritmo sigue un estilo común Actor-Crítico y usa un búfer de reproducción de experiencias para almacenar los datos a partir de los cuales se actualizan los parámetros del Actor y el Crítico.
El crítico aprende minimizando el error:
![]()
donde:
(x, a, r, x') — del búfer de reproducción de experiencias D,
a' — acción del Actor de acuerdo con la política π(·|x'),
Q ̅ — indica la función objetivo del Crítico,
H ̃ — estimación de la entropía de la política.
Al hacerlo, estimaremos la entropía de la política con variables latentes.
Además, el Actor se actualizará minimizando el error:
![]()
Nótese que al actualizar el Crítico, utilizaremos la estimación de entropía de la política del Actor en el estado subsiguiente, mientras que al actualizar la política del Actor, utilizaremos el actual.
En general, el SMAC no difiere mucho del SAC ingenuo en cuanto a los detalles algorítmicos de los métodos de aprendizaje por refuerzo, pero obtiene mejoras debido principalmente al comportamiento estructurado de la exploración. Esto se consigue gracias a la modelación de variables latentes.
2. Implementación usando MQL5
Arriba se encuentran los cálculos teóricos del método Stochastic Marginal Actor-Critic. En la parte práctica de este artículo, implementaremos el algoritmo propuesto usando herramientas MQL5, solo que no replicaremos completamente el algoritmo SMAC del autor. El artículo de los autores afirma que los métodos propuestos pueden utilizarse en casi todos los algoritmos de aprendizaje por refuerzo. Aprovecharemos esta oportunidad para aplicar los métodos propuestos en nuestra implementación del algoritmo NNM, que hemos analizado en el artículo anterior.
Y los primeros cambios se producirán en la arquitectura de los modelos. Como podemos ver en las fórmulas presentadas anteriormente, tres modelos constituyen la base del algoritmo SMAC:
- q — modelo de representación del estado latente;
- π — Actor;
- P — Crítico.
Creo que los dos últimos modelos no son cuestionables. El primer modelo de estado latente, sin embargo, supone un codificador con un nodo estocástico en la salida. En este caso, además, tanto el Actor como el Crítico utilizarán como datos de origen los resultados de este Codificador. Aquí será pertinente recordar el Codificador del Autocodificador Variacional.
Nuestra experiencia nos permite no poner el Codificador en un modelo aparte, sino dejarlo, como antes, dentro de la arquitectura del modelo del Actor. Por lo tanto, para implementar el algoritmo propuesto, deberemos modificar la arquitectura del Actor. Es decir, añadiremos un nodo estocástico a la salida de la unidad de preprocesamiento de datos (Codificador).
La arquitectura de los modelos se especificará en el método CreateDescriptions. En esencia, estamos realizando modificaciones mínimas en la arquitectura del Actor. Dejaremos el bloque de preprocesamiento de datos sin cambios. Los movimientos históricos de los precios y los datos de los indicadores se introducirán en una capa neuronal totalmente conectada. A continuación, se someterán a un tratamiento inicial en la capa neuronal de normalización de lotes.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Después los datos normalizados pasarán por dos capas de convolucionales sucesivas en las que intentaremos extraer algunos patrones de la estructura de datos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; int prev_wout = descr.window_out = HistoryBars / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y marginaremos el estado del entorno con dos capas totalmente conectadas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Luego combinaremos los datos obtenidos con la información de la cuenta. Y aquí realizaremos el primer cambio en la arquitectura del modelo. Antes del bloque estocástico, necesitaremos crear una capa del doble del tamaño de la representación latente: necesitaremos medidas de la distribución en forma de valores medios y varianza. Por ello, especificaremos que el tamaño de la capa de concatenación sea el doble del tamaño de la representación latente, y después añadiremos la capa de estado latente del autocodificador variacional. Precisamente con esta capa crearemos el nodo estocástico.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Obsérvese que hemos aumentado el tamaño de nuestro bloque de preprocesamiento de datos (codificador), y esto hay que tenerlo en cuenta a la hora de organizar la transferencia de datos entre modelos.
Dejaremos el bloque de decisión del Actor sin cambios. Este contendrá tres capas totalmente conectadas y una capa de estado latente del autocodificador variacional, que creará la estocasticidad del comportamiento del Actor.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A continuación, hablaremos de la arquitectura del Crítico. A primera vista, no hay requisitos para la arquitectura del Crítico en las propuestas de los autores del método SMAC, y podríamos dejarlo sin cambios. No obstante, deberemos recordar que estamos utilizando una función de recompensa descompuesta, y nos surge la pregunta: ¿dónde atribuir la entropía del nodo estocástico añadido? Podríamos añadirla a cualquiera de los elementos de recompensa disponibles. Pero en el contexto de la descomposición de la función de recompensa, sería más lógico añadir otro elemento a la salida del Crítico. Por lo tanto, aumentaremos la constante del número de elementos de recompensa.
#define NRewards 5 //Number of rewards
Por lo demás, la arquitectura del modelo del Crítico permanecerá inalterada.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Para aplicar el algoritmo SMAC, hemos especificado todos los modelos necesarios, pero estamos implementando los métodos propuestos en el algoritmo NNM. Por lo tanto, dejaremos todos los modelos utilizados anteriormente en su lugar con el fin de preservar la funcionalidad completa del algoritmo. El modelo del Codificador convolucional aleatorio se mantiene sin cambios, y no insistiremos en ello. Podrá leerlo usted mismo en el archivo adjunto. Allí también verá todos los programas utilizados en este artículo.
Vamos a regresar directamente al tema de la transferencia de datos entre modelos. Para que el Crítico se refiera al estado latente del Actor, utilizaremos el identificador de la capa de estado latente que se especificará en la constante LatentLayer. Por lo tanto, para redirigir el Crítico a la capa neuronal correcta según el cambio en la arquitectura del Actor solo necesitaremos cambiar el valor de la constante especificada. En este contexto, no será necesario introducir ningún otro ajuste en el código del programa.
#define LatentLayer 7
Ahora analizaremos la cuestión del uso de algoritmos para calcular el componente de entropía en la función de recompensa. Los autores del método ofrecieron su visión de la cuestión, que se presenta en la parte teórica. Sin embargo, ampliaremos nuestra aplicación del método NNM, en el que utilizaremos la norma nuclear como componente de entropía de Actor. Para que los valores de los distintos elementos de la función de recompensa sean comparables, lo lógico sería utilizar un enfoque similar también para el Codificador.
Los autores del método SMAC proponen usar K+1 muestras del Codificador para estimar la entropía del estado latente. Obviamente, para una única condición del entorno en el proceso de entrenamiento del Codificador, llegaremos a algún valor medio con bastante rapidez, y durante la optimización posterior de los parámetros del Codificador, intentaremos reducir el valor de la varianza para maximizar la separación de los estados individuales. A medida que la varianza disminuye en el límite hacia "0", la entropía también tenderá hacia "0". ¿Obtendremos el mismo efecto con la norma nuclear?
Para responder a esta pregunta, podemos ahondar en fórmulas matemáticas, o bien podemos ponerlo a prueba. Por supuesto, ahora no vamos a construir y entrenar un modelo durante mucho tiempo para probar la viabilidad de la norma nuclear: haremos algo mucho más fácil y rápido. Vamos a crear un pequeño script en Python.
En primer lugar, importaremos dos bibliotecas: numpy y matplotlib. Utilizaremos la primera para los cálculos y la segunda para visualizar los resultados.
# Import libraries import numpy as np import matplotlib.pyplot as plt
Para crear las muestras, necesitaremos medidas estadísticas de las distribuciones: los valores medios y la varianza correspondiente. Estos serán generados por el modelo durante el entrenamiento. Para probar el enfoque, solo necesitaremos valores aleatorios.
mean = np.random.normal(size=[1,10]) std = np.random.rand(1,10)
Tenga en cuenta que podemos utilizar cualquier número como promedio. Y los generaremos a partir de una distribución normal. Pero las varianzas solo pueden ser positivas, y las generaremos en el intervalo (0, 1].
De forma similar al nodo estocástico, usaremos el truco de reparametrización de la distribución. Para ello, generaremos una matriz de valores aleatorios partiendo de una distribución normal,
data = np.random.normal(size=[20,10])
y prepararemos un vector para registrar nuestras recompensas interiores.
reward=np.zeros([20])
La idea es la siguiente: necesitaremos probar cómo se comportarán las recompensas intrínsecas utilizando la norma nuclear cuando se reduce la varianza y otras condiciones por el estilo.
Para reducir la varianza, crearemos un vector de coeficientes decrecientes.
scl = [2**(-k/2.0) for k in range(20)]
A continuación, crearemos un ciclo en el que utilizaremos el truco de reparametrización de la distribución para nuestros datos aleatorios con una media constante y una varianza decreciente. Partiendo de los datos obtenidos, calcularemos la recompensa intrínseca utilizando la norma nuclear, y almacenaremos los resultados en el vector de recompensas preparado.
for idx, k in enumerate(scl): new_data=mean+data*(std*k) _,S,_=np.linalg.svd(new_data) reward[idx]=S.sum()/(np.sqrt(new_data*new_data).sum()*max(new_data.shape))
A continuación, veremos los resultados del funcionamiento del script.
# Draw results
plt.plot(scl,reward)
plt.gca().invert_xaxis()
plt.ylabel('Reward')
plt.xlabel('STD multiplier')
plt.xscale('log',base=2)
plt.savefig("graph.png")
plt.show() 
Los resultados demuestran claramente la reducción de la recompensa intrínseca usando la norma nuclear cuando disminuye la varianza de la distribución, en igualdad de condiciones. Y, por tanto, podemos usar con seguridad la norma nuclear para estimar también la entropía del estado latente.
Volvamos a nuestra implementación del algoritmo usando MQL5. Ahora podemos proceder a aplicar la estimación de la entropía de estado latente. En primer lugar, deberemos determinar el número de estados latentes que vamos a muestrear. Luego definiremos este indicador usando la constante SamplLatentStates.
#define SamplLatentStates 32
La siguiente pregunta es: ¿realmente necesitamos realizar una pasada completa del modelo codificador (en nuestro caso Actor) para muestrear cada estado latente?
Resulta bastante obvio que sin cambiar los datos iniciales y los parámetros del modelo, los resultados de todas las capas neuronales serán idénticos en cada pasada posterior. La única diferencia residirá en los resultados del nodo estocástico. Por ello, para cada estado individual, solo necesitaremos una pasada directa del modelo Actor, y luego utilizaremos el truco de reparametrización de la distribución y muestrearemos el número de estados ocultos que queramos. Creo que la idea queda clara, así que pasaremos a la aplicación.
En primer lugar, generaremos una matriz de valores aleatorios a partir de una distribución normal con un valor medio "0" y una varianza "1". Estos índices de distribución son los más convenientes para la reparametrización.
float EntropyLatentState(CNet &net) { //--- random values double random[]; Math::MathRandomNormal(0,1,LatentCount * SamplLatentStates,random); matrix<float> states; states.Assign(random); states.Reshape(SamplLatentStates,LatentCount);
A continuación, cargaremos desde nuestro modelo de Actor los parámetros de distribución aprendidos: estos se almacenarán en la penúltima capa del Codificador. Aquí debemos señalar que nuestro modelo ofrece un único búfer de datos que almacenará secuencialmente primero todos los valores medios de la distribución aprendida seguidos de toda la varianza. Excepto que para realizar operaciones matriciales no necesitamos un vector, sino dos matrices con valores duplicados en las filas, y ahí es donde vamos a complicarnos un poco. Primero crearemos una gran matriz con el número necesario de filas y el doble de columnas, rellenada con valores cero. En la primera línea escribiremos los datos del búfer de datos con los parámetros de las distribuciones, y luego utilizaremos la función de suma acumulativa de valores de la matriz por columnas.
El truco está en que todas las filas salvo la primera se rellenarán con ceros, y como resultado de la operación de suma acumulativa, simplemente copiaremos los datos de la primera fila a todas las filas siguientes.
Ahora simplemente dividiremos la matriz en dos iguales verticalmente y obtendremos un array de matrices split. En ella, la matriz de valores medios tendrá el índice 0, mientras que la matriz de varianza tendrá el índice 1.
//--- get means and std vector<float> temp; matrix<float> stats = matrix<float>::Zeros(SamplLatentStates,2 * LatentCount); net.GetLayerOutput(LatentLayer - 1,temp); stats.Row(temp,0); stats=stats.CumSum(0); matrix<float> split[]; stats.Vsplit(2,split);
Ahora realizaremos una reparametrización bastante simple de valores aleatorios de una distribución normal, y obtendremos el número de muestras que necesitamos.
//--- calculate latent values states = states * split[1] + split[0];
En la parte inferior de la matriz, añadiremos una fila con los valores actuales del Codificador que han sido utilizados por el Actor y los Críticos como entradas en la pasada directa.
//--- add current latent value net.GetLayerOutput(LatentLayer,temp); states.Resize(SamplLatentStates + 1,LatentCount); states.Row(temp,SamplLatentStates);
En esta fase tendremos todos los datos listos para calcular la norma nuclear, y realizaremos el cálculo del componente de entropía de la función de recompensa. El resultado se retornará al programa que realiza la llamada.
//--- calculate entropy states.SVD(split[0],split[1],temp); float result = temp.Sum() / (MathSqrt(MathPow(states,2.0f).Sum() * MathMax(SamplLatentStates + 1,LatentCount))); //--- return result; }
Podemos decir que el trabajo preparatorio ha concluido. Ahora pasaremos a trabajar con los asesores de interacción con el entorno y el entrenamiento de modelos.
Diremos directamente que los asesores de interacción con el entorno (Research.mq5 y Test.mq5) han permanecido inalterados, así que no nos detendremos en ellos ahora. Podrá ver el código completo de estos programas, así como de todos los demás utilizados en este artículo, en el archivo adjunto.
Ahora pasaremos al asesor de entrenamiento de modelos y nos centraremos en el método de entrenamiento Train. Al principio del método, determinaremos el tamaño total del búfer de repetición de experiencia.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Y, luego realizaremos la codificación de todos los ejemplos existentes del búfer de reproducción de experiencias utilizando un codificador convolucional aleatorio. Este proceso será totalmente heredado de la aplicación anterior.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); next.Assign(Buffer[tr].States[st + 1].rewards); rewards.Row(temp - next * DiscFactor,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
Una vez que hayamos terminado de codificar todos los ejemplos del búfer de reproducción de experiencias, eliminaremos las filas sobrantes de las matrices.
if(state != total_states)
{
rewards.Resize(state,NRewards);
state_embedding.Reshape(state,state_embedding.Cols());
total_states = state;
}
Luego vendrá el bloque de entrenamiento directo del modelo. Aquí inicializaremos las variables locales y crearemos un ciclo de entrenamiento del modelo. El número de iteraciones del ciclo vendrá determinado por la variable externa Iterations.
vector<float> rewards1, rewards2; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
En el cuerpo del ciclo, muestrearemos la trayectoria y un estado del entorno independiente para la iteración actual de las actualizaciones de los parámetros del modelo.
A continuación, comprobaremos el valor umbral de utilización de los modelos objetivo. Y, si fuera necesario, cargaremos los datos de estado posteriores en los búferes de datos correspondientes.
target_reward = vector<float>::Zeros(NRewards); reward.Assign(Buffer[tr].States[i].rewards); //--- Target TargetState.AssignArray(Buffer[tr].States[i + 1].state); if(iter >= StartTargetIter) { float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
Los datos preparados se utilizarán para aplicar la pasada directa del Actor y los dos modelos objetivo de los Críticos.
if(!Actor.feedForward(GetPointer(TargetState), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Basándonos en los resultados de la pasada directa de los modelos objetivo, prepararemos el vector de valores del estado posterior. Y nos aseguraremos de añadir al vector resultante la estimación de la entropía del estado latente según el algoritmo SMAC.
TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; for(ulong r = 0; r < target_reward.Size(); r++) target_reward -= Buffer[tr].States[i + 1].rewards[r]; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
Una vez preparado el vector de costes del estado posterior, comenzaremos a trabajar con el estado del entorno seleccionado. Y rellenaremos los búferes necesarios con los datos de origen correspondientes.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
A continuación, realizaremos una pasada directa del Actor para generar un estado del entorno latente.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
En la fase de actualización de los parámetros del Crítico, solo utilizaremos el estado latente. Tomaremos las acciones del Actor del búfer de repetición de experiencias, y llamaremos la pasada directa de ambos Críticos.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Los parámetros de los Críticos se actualizarán para reflejar la recompensa real del entorno, ajustada a la política actual del Actor. Los parámetros de influencia de la política del Actor actualizada ya los hemos considerado en el vector de valores del estado del entorno posterior.
Recordemos que estamos utilizando una función de recompensa descompuesta y que se aplicará el método CAGrad. Esto dará lugar a diferentes vectores de valores de referencia para cada Crítico. En primer lugar, prepararemos un vector de valores de referencia y realizaremos una pasada inversa del primer Crítico.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(reward + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A continuación, repetiremos las operaciones para el segundo Crítico.
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(reward + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Tenga en cuenta que tras actualizar los parámetros de cada Crítico, realizaremos una pasada inversa para actualizar los parámetros del Codificador. Y no nos olvidaremos de supervisar el proceso de las operaciones en cada fase.
Tras actualizar los parámetros del Crítico, comenzaremos a trabajar en la optimización del modelo del Actor. Y para determinar el gradiente de error a nivel del Actor, utilizaremos el Crítico con el error medio móvil mínimo de predicción del coste de acción del Actor. Este enfoque nos ofrecerá potencialmente una evaluación más precisa de las acciones generadas por la política del Actor. Y, como consecuencia, una distribución más correcta del gradiente de error.
//--- Policy study CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
Ya hemos realizado anteriormente la pasada directa del Actor. Ahora formaremos una predicción del estado posterior del entorno. Concretamente predictivo. Después de todo, tenemos datos históricos del movimiento de los precios e indicadores en el búfer de repetición de experiencias. Estos resultan independientes de las acciones del Actor y podemos utilizarlos tranquilamente, pero el estado de la cuenta dependerá directamente de las operaciones comerciales realizadas por el Actor. Y las acciones en el marco de las políticas actuales del Actor pueden diferir de las almacenadas en el búfer de reproducción de experiencias. En esta fase, deberemos generar un vector predictivo de la descripción del estado de la cuenta. Para nuestra comodidad, esta funcionalidad ya está implementada en el método ForecastAccount, del que hablamos en el artículo anterior. Y ahora todo lo que deberemos hacer es llamarla transmitiendo los datos iniciales correctos.
Actor.getResults(rewards1); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,rewards1,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetState.AddArray(forecast);
Ahora que tenemos todos los datos necesarios, realizaremos una pasada directa del Crítico seleccionado y el Codificador Convolucional Aleatorio para formar una incorporación del estado posterior predicho.
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Convolution.feedForward(GetPointer(TargetState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A partir de los datos obtenidos, generaremos un vector de valores de referencia de la función de recompensa para actualizar los parámetros del Actor, y nos aseguraremos de corregir el gradiente de error usando la técnica CAGrad.
next.Assign(Buffer[tr].States[i + 1].rewards); Convolution.getResults(rewards1); target_reward += KNNReward(KNN,rewards1,state_embedding,rewards) + next * DiscFactor; if(forecast[3] == 0.0f && forecast[4] == 0.0f) target_reward[2] -= (Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance); critic.getResults(reward); reward += CAGrad(target_reward - reward);
A continuación, desactivaremos el modo de actualización de parámetros del Crítico y realizaremos su pasada inversa. Y a continuación, realizaremos una pasada inversa completa del Actor.
Result.AssignArray(reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
Asegúrese de supervisar el proceso de las operaciones. Y tras realizar con éxito la pasada inversa de ambos modelos, devolveremos el Crítico al modo de entrenamiento.
En este punto hemos actualizado los parámetros tanto del Crítico como del Actor. Todo lo que deberemos hacer es actualizar los parámetros de los modelos objetivo del Crítico. Aquí utilizaremos la actualización suave de los parámetros del modelo con el coeficiente Tau, que se establecerá en los parámetros externos del asesor.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau);
Y al final de las operaciones en el cuerpo del ciclo de entrenamiento del modelo, informaremos al usuario sobre el progreso del proceso de entrenamiento y pasaremos a la siguiente iteración del ciclo.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Una vez completadas con éxito todas las iteraciones del ciclo de entrenamiento del modelo, borraremos el campo de comentarios del gráfico. Luego enviaremos los resultados del entrenamiento al registro e inicializaremos el proceso de finalización del Asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Supongo que se habrá dado cuenta de que en el proceso de entrenamiento de Actor, nos hemos saltado el cálculo del componente de entropía del estado latente que proporciona el método SMAC. La cuestión es que no hemos dividido el proceso de entrenamiento del vector de recompensa en partes separadas. Al construir el algoritmo NNM, este proceso se ha incluido en un método KNNReward separado. Precisamente en este método hemos introducido los ajustes necesarios.
Al igual que antes, en el cuerpo del método, primero comprobaremos la correspondencia entre los tamaños de incorporación del estado predicho y en la matriz de incorporaciones de los estados del entorno del búfer de reproducción de experiencias.
vector<float> KNNReward(ulong k, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards ) { if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return vector<float>::Zeros(0); }
Tras pasar con éxito el bloque de control, inicializaremos las variables locales necesarias.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); k = MathMin(k,states); ulong rew_size = rewards.Cols(); vector<float> distance = vector<float>::Zeros(states); matrix<float> k_rewards = matrix<float>::Zeros(k,rew_size); matrix<float> k_embeding = matrix<float>::Zeros(k + 1,size); matrix<float> U,V; vector<float> S;
Con esto finalizaremos la fase preparatoria y pasaremos directamente a las operaciones de cálculo. Primero determinaremos la distancia entre el estado predicho y los ejemplos reales del búfer de reproducción de experiencias
for(ulong i = 0; i < size; i++) distance+=MathPow(state_embedding.Col(i) - embedding[i],2.0f); distance = MathSqrt(distance);
Después determinaremos los k vecinos más próximos y rellenaremos la matriz de incorporaciones. Y también transferiremos las recompensas correspondientes a una matriz preparada de antemano. Simultáneamente, ajustaremos el vector de recompensas según un factor inverso a la distancia entre los vectores de estado. El coeficiente indicado determinará la influencia de las recompensas del búfer de reproducción de experiencias sobre el resultado de la acción seleccionada por el Actor según la política de comportamiento actualizada.
for(ulong i = 0; i < k; i++) { ulong pos = distance.ArgMin(); k_rewards.Row(rewards.Row(pos) * (1 - MathLog(distance[pos] + 1)),i); k_embeding.Row(state_embedding.Row(pos),i); distance[pos] = FLT_MAX; }
En la matriz de incorporaciones, añadiremos la incorporación del estado del entorno previsto como última fila.
k_embeding.Row(embedding,k);
Y hallaremos el vector de valores singulares de la matriz de incorporaciones obtenida. Esta operación se realizará fácilmente utilizando las operaciones matriciales incorporadas.
k_embeding.SVD(U,V,S);
Luego formaremos el vector de recompensas como la media de las recompensas correspondientes de los k vecinos más próximos, ajustada por el coeficiente de participación,
vector<float> result = k_rewards.Mean(0);
pero rellenaremos los dos últimos elementos del vector de recompensas con el componente de entropía utilizando la norma nuclear del Actor de la política y el estado latente, respectivamente.
result[rew_size - 2] = S.Sum() / (MathSqrt(MathPow(k_embeding,2.0f).Sum() * MathMax(k + 1,size))); result[rew_size - 1] = EntropyLatentState(Actor); //--- return (result); }
Luego retornaremos el vector de recompensas generado al programa que ha realizado la llamada. Todos los demás métodos del asesor se mantendrán sin cambios.
Con esto daremos por concluido nuestro trabajo con el asesor de entrenamiento de modelos. Su código completo, así como todos los programas usados en este artículo, se encuentran en el archivo adjunto. Ahora pasaremos a la fase de comprobación del trabajo realizado.
3. Simulación
En la parte práctica de este artículo hemos trabajado seriamente en la implementación del método Stochastic Marginal Actor-Critic en el asesor del algoritmo NNM previamente implementado. Y ahora pasaremos a la fase de comprobación del trabajo realizado. Como siempre, el entrenamiento y las pruebas de los modelos se realizarán usando los datos históricos de EURUSD, con el marco temporal H1. Los parámetros de todos los indicadores se utilizarán por defecto.
Ya estamos a septiembre, y el periodo de entrenamiento ha aumentado a 7 meses en 2023. Ahora comprobaremos el rendimiento del modelo con los datos históricos de agosto de 2023.
Al crear el asesor de entrenamiento "...\NNM\Study.mq5", hablamos de las peculiaridades del método NNM y del problema que supone la ausencia de estados generados en el búfer de reproducción de experiencias. Debido a ello, hemos decidido reducir el número de iteraciones en el ciclo de entrenamiento. Y ahora seguiremos los mismos planteamientos para el proceso de entrenamiento del modelo.
Al igual que en el proceso de entrenamiento utilizado en el artículo anterior, no reduciremos el búfer de reproducción de experiencias en general. Pero al mismo tiempo, iremos rellenando gradualmente el búfer de reproducción de experiencias. En la primera iteración, ejecutaremos el asesor de recopilación de datos de entrenamiento durante 100 ejecuciones. Con el intervalo histórico especificado, esto ya nos da casi 360 000 estados para el entrenamiento del modelo.
Tras la primera iteración de entrenamiento del modelo, aumentaremos la base de ejemplos con otras 50 ejecuciones. De este modo, rellenaremos gradualmente el búfer de reproducción de experiencias con nuevos estados que se corresponderán con las acciones del Actor dentro de la política entrenada.
Repetiremos el proceso de entrenamiento de los modelos y de recogida de ejemplos adicionales varias veces hasta alcanzar el resultado deseado del entrenamiento de la política del Actor.
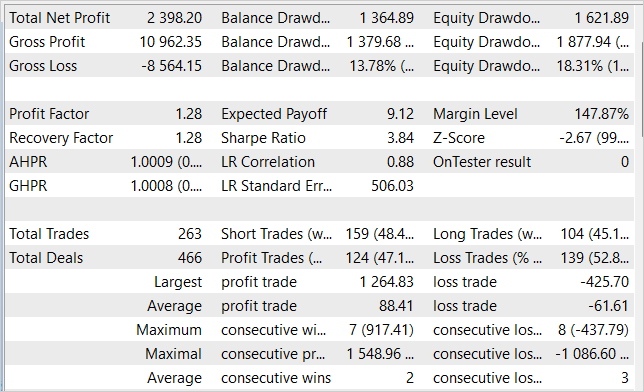
Durante el entrenamiento de los modelos, hemos podido obtener una política del Actor capaz de generar beneficios sobre la muestra de entrenamiento y generalizar el conocimiento aprendido a estados posteriores del entorno. Así, en el simulador de estrategias, nuestro modelo entrenado ha sido capaz de generar una rentabilidad del 23,98% en el mes siguiente a la muestra de entrenamiento. Durante el periodo de prueba, el modelo ha realizado 263 operaciones, el 47% de las cuales se han cerrado con beneficios. El beneficio máximo por operación ha sido casi 3 veces superior a la operación perdedora máxima, mientras que el beneficio medio por operación ha sido un 44% superior a la pérdida media. Todo ello se ha combinado para producir un factor de beneficio de 1,28. Al mismo tiempo, vemos una clara tendencia al alza en el gráfico de la línea de balance.

Conclusión
En este trabajo, hemos introducido el método Stochastic Marginal Actor-Critic, que supone un enfoque innovador para resolver problemas de aprendizaje por refuerzo. Basándose en el principio de máxima entropía, el SMAC permite al agente explorar el entorno de forma más eficiente y aprender de forma más sólida, lo cual se logra introduciendo un nodo estocástico adicional de variables latentes.
El uso de variables latentes en la política del Agente aumenta enormemente su expresividad y su capacidad para modelar la estocasticidad en las observaciones y las recompensas.
No obstante, existen algunas dificultades en el entrenamiento de la política con las variables latentes, y los autores del método ofrecen soluciones para hacer frente a estas dificultades.
En la parte práctica del artículo, hemos integrado con éxito el SMAC en la arquitectura del método NNM, creando un método sencillo y eficaz para optimizar las políticas, como demuestran los resultados de las pruebas. Asimismo, hemos sido capaces de formar una política del Actor capaz de generar rendimientos de hasta el 24% mensual.
A la vista de estos resultados, el método SMAC supone una solución eficaz para resolver problemas prácticos.
No obstante, me gustaría llamar su atención sobre el hecho de que todos los programas presentados en el artículo se han creado solo para demostrar el método y no resultan adecuados para trabajar con cuentas reales, pues requieren la realización de configuraciones adicionales y la optimización de la funcionalidad.
Permítanme recordarles que los mercados financieros son un tipo de inversión de alto riesgo, por lo que usted correrá con la responsabilidad íntegra por todos los riesgos derivados de las transacciones que usted realice o de los fondos electrónicos que utilice.
Enlaces
- Latent State Marginalization as a Low-cost Approach for Improving Exploration
- Redes neuronales: así de sencillo (Parte 56): Utilizamos la norma nuclear para incentivar la exploración
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13290
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Cada pasada del EA Test genera resultados drásticamente diferentes como si el modelo fuera diferente a todos los anteriores. Es obvio que el modelo evoluciona en cada pasada de Test pero el comportamiento de este EA no es una evolución, ¿qué hay detrás?
He aquí algunas imágenes:
Este modelo utiliza la política estocástica del Actor. Así que al principio del estudio podemos ver tratos aleatorios en cada pase. Recogemos estos pases y reiniciamos el estudio del modelo. Y repetimos este proceso algunas veces. Mientras el Actor encuentra una buena politica de acciones.
Planteemos la pregunta de otro modo. Una vez recogidas las muestras (Investigación) y procesadas (Estudio), ejecutamos el script de prueba. En varias ejecuciones conscutivas, sin ninguna Investigación o Estudio, los resultados obtenidos son completamente diferentes.
El script de prueba carga un modelo entrenado en la subrutina OnInit (línea 99). Aquí alimentamos el EA con un modelo que no debe cambiar durante el procesamiento de la Prueba. Debería ser estable, según tengo entendido. Entonces, los resultados finales no deberían cambiar.
Mientras tanto, no realizamos ningún entrenamiento del modelo. La prueba se limita a recoger más muestras.
La aleatoriedad se observa más bien en el módulo Investigación y posiblemente en el Estudio mientras se optimiza una política.
El Actor es invocado en la línea 240 para calcular los resultados feedforward. Si no se inicializa aleatoriamente en el momento de la creación, creo que este es el caso, no debería comportarse aleatoriamente.
¿Encuentras algún error en el razonamiento anterior?
Planteemos la pregunta de otro modo. Una vez recogidas las muestras (Investigación) y procesadas (Estudio), ejecutamos el script de prueba. En varias ejecuciones conscutivas, sin Investigación ni Estudio, los resultados obtenidos son completamente diferentes.
El script de prueba carga un modelo entrenado en la subrutina OnInit (línea 99). Aquí alimentamos el EA con un modelo que no debe cambiar durante el procesamiento de la Prueba. Debería ser estable, según tengo entendido. Entonces, los resultados finales no deberían cambiar.
Mientras tanto, no realizamos ningún entrenamiento del modelo. La Prueba sólo recoge más muestras.
La aleatoriedad se observa más bien en el módulo Investigación y posiblemente en el Estudio mientras se optimiza una política.
El Actor es invocado en la línea 240 para calcular los resultados feedforward. Si no se inicializa aleatoriamente en el momento de la creación, creo que este es el caso, no debería comportarse aleatoriamente.
¿Encuentras algún error en el razonamiento anterior?
El Actor utiliza una política estocástica. La implementamos mediante VAE.
La capa CNeuronVAEOCL utiliza los datos de la capa anterior como media y STD de la distribución Gaussiana y muestrea la misma acción de esta distribución. Al principio ponemos en el modelo pesos aleatorios. Así se generan medias y STD aleatorias. Al final tenemos acciones aleatorias en cada paso de la prueba del modelo. En el momento del estudio el modelo encontrará algunas medias para cada estado y STD tiende a cero.