
ニューラルネットワークが簡単に(第57回):Stochastic Marginal Actor-Critic (SMAC)

はじめに
自動売買システムを構築する際には、逐次的な意思決定のためのアルゴリズムを開発します。強化学習法は、まさにそのような問題を解決することを目的としています。強化学習における重要な問題の1つは、エージェントが環境との相互作用を学習する際の探索プロセスです。この文脈では、最大エントロピーの原則がしばしば使用され、エージェントは最大のランダム性の程度で行動をとるように動機付けられます。しかし、実際には、このようなアルゴリズムは、単一行動の周りの局所的な変化のみを学習する単純なエージェントを訓練します。これは、エージェント方策のエントロピーを計算し、訓練目標の一部として使用する必要があるためです。
同時に、Actorの方策の表現力を高める比較的簡単なアプローチは、潜在変数を使用することです。潜在変数は、観測、環境、および未知の報酬における確率的特性をモデル化するための独自の推論手順をエージェントに提供します。
エージェントの方策に潜在変数を導入することで、過去の観測結果と互換性のある、より多様なシナリオをカバーすることができます。ここで注意しなければならないのは、潜在変数を持つ方策は、そのエントロピーを決定する単純な式を許さないということです。素朴なエントロピー推定は、方策の最適化において壊滅的な失敗につながる可能性があります。また、エントロピー最大化のための高分散確率更新では、局所的ランダム効果とマルチモーダル探索を容易に区別できません。
このような潜在変数方策の欠点を解決する選択肢のひとつが「Latent State Marginalization as a Low-cost Approach for Improving Exploration」で提案されています。著者らは、完全に観測可能な環境と部分的に観測可能な環境の両方において、より効率的でロバストな探索をおこなうことができる、シンプルかつ効果的な方策最適化アルゴリズムを提案しています。
本稿の主な貢献は、以下のテーゼによって簡潔にまとまります。
- 部分的な観測可能性の条件下で探索性と頑健性を向上させるために潜在変数方策を使用する動機
- 研究効率と分散の低減に焦点を当てたいくつかの確率的推定法の提案
- Actor-Critic法へのアプローチの適用による、Stochastic Marginal Actor-Critic (SMAC)アルゴリズムの誕生
1.SMACアルゴリズム
Stochastic Marginal Actor-Criticアルゴリズムの著者は、分散Actor方策を構築するために潜在変数を使用することを提案しています。これは、エージェントの行動モデルと方策の柔軟性を高めるシンプルで効率的な方法です。このアプローチは、確率論的エージェントの行動方策を使用する既存のアルゴリズムに実装するための最小限の変更を必要とします。
潜在変数方策は次のように表すことができます。
![]()
ここでstは、現在のオブザベーションに依存する潜在変数です。
q(st|xt)潜在変数の導入は、通常Actorの方策の表現力を高めます。これによって、方策はより幅広い最適な行動を捉えることができます。これは、将来の報酬に関する情報が不足している研究の初期段階において、特に有用です。
確率モデルをパラメータ化するために、この手法の著者はπ(at|st)Actor方策とq(st|xt)潜在変数関数の両方に因数分解されたガウス分布を使用することを提案しています。この結果、サンプリングと密度推定が安価なままであるため、計算効率のよい潜在変数方策が実現します。さらに、確率的方策と単一のガウス分布を持つ既存のアルゴリズムに基づくモデルを構築するために、提案されたアプローチを適用することができます。新しいst確率的ノードを追加するだけです。
Markovの仮定過程により、π(at|st)は現在の潜在状態にのみ依存するが、提案アルゴリズムは非Markov状況に容易に拡張できることに注意してください。ただし、再帰のおかげで、現在の潜在状態st状態と、π(at|st)方策は、エージェントによってとられた行動の影響下での初期状態からの一連の遷移の結果であるため、完全な隠れた履歴に従って周辺化が観察されます。
![]()
同時に、潜在変数を処理するための提案されたアプローチは、qが何に影響するかには依存しません。
潜在変数が存在すると、最大エントロピーの訓練はかなり難しくなります。結局のところ、これにはエントロピー成分を正確に評価する必要があります。潜在変数モデルのエントロピーの推定は、周辺化が困難なため非常に難しくなります。さらに、潜在変数の使用は勾配の分散を増加させます。また、潜在変数をQ関数に使用することで、不確実性をより適切に集約することができます。
これらの各ケースにおいて、Marginal Actor-Criticの著者たちは、潜在変数を扱うための合理的な方法を導き出しています。最終的な結果は非常にシンプルで、潜在変数なしの方策と比較して、追加的なリソースコストは最小限に抑えられています。
また、潜在変数を使用すると、確率対数の解が得られないため、エントロピー(または限界エントロピー)が使えなくなります。
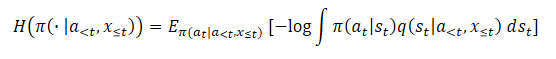
素朴な推定器を使用すると、目的の最大エントロピー関数の上限が最大になり、誤差が最大になります。これは、変動分布がq(st|a<t,x≦t)真の事後推定値からできるだけ離れるように促すものです。さらに、この誤差は有界ではなく、実際に最大化したい真のエントロピーに影響を与えることなく、恣意的に大きくなる可能性があり、数値的不安定性という深刻な問題につながります。
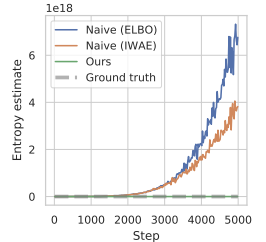
この記事は予備実験の結果を示しています。この方策最適化の際にエントロピーを推定するアプローチでは、値が極端に大きくなり、真のエントロピーを著しく過大評価し、訓練されていない方策につながります。以下はその記事からのビジュアル化です。
過大評価の問題を克服するために、この方法の著者は限界エントロピーの下界の推定器を構築することを提案しています。
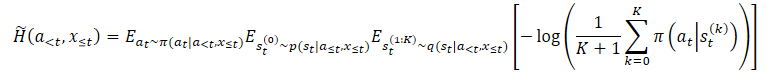
ここでp(st|a≦t,x≦t)は方策の未知の事後分布です。
しかし、そこからst⁰を選択し、st⁰の場合はtを選択できます。この結果、ネストされた評価器となり、q(st|a<t,x≤t)から実際にK+1回を選ぶことになります。 行動を選択するには、最初のst⁰の潜在変数のみを使用します。他のすべての潜在変数は、限界エントロピーの推定に使用されます。
これは、対数内の期待値を独立標本で置き換えることと同じではないことに注意してください。提案する推定量はKとともに単調増加し、極限では不偏の限界エントロピー推定量となります。
上記の方法は、一般的なエントロピー最大化アルゴリズムに適用できます。しかし、この方法の著者は、Stochastic Marginal Actor-Critic (SMAC)と呼ばれる特定のアルゴリズムを作成しました。SMACの特徴は、潜在変数を持つActor方策を使用し、限界エントロピー目的関数の下限を最大化することです。
このアルゴリズムは、一般的に認められているActorとCriticのスタイルに従い、データを保存するために経験再生バッファを使用し、それに基づいてActorとCriticの両方のパラメータが更新されます。
Criticは誤差を最小化することによって学習します。
![]()
ここで
(x, a, r, x') : D再生バッファから
a':π(·|x')方策に従ったActorの行動
Q̅:Criticの目標関数
H̃:方策エントロピー推定
さらに、潜在変数を用いて方策エントロピーを推定します。
さらに、誤差を最小化することでActorが更新されます。
![]()
Criticを更新するときは、次の状態におけるActorの方策のエントロピー推定値を使用し、Actorの方策を更新するときは、現在の状態におけるエントロピー推定値を使用することに注意してください。
全体として、SMACは強化学習法のアルゴリズムの詳細という点では、基本的にナイーブなSACと同じですが、主に構造化された探索行動によって改善されています。これは潜在変数モデリングによって達成されます。
2.MQL5を使用した実装
上記は著者のStochastic Marginal Actor-Critic法の理論計算です。本稿の実践編では、MQL5を用いて提案アルゴリズムを実装します。唯一の例外は、オリジナルのSMACアルゴリズムを完全に繰り返さないことです。本稿では、提案された手法をほとんどすべての強化学習アルゴリズムに使用できる可能性を検討しています。この機会を利用し、前回の記事で説明したNNMアルゴリズムの実装に、提案された方法を実装する予定です。
最初の変更は、モデルのアーキテクチャに加えます。上に示した式を見ればわかるように、SMACアルゴリズムは3つのモデルに基づいています。
- q:潜在状態を表すモデル
- π:Actor
- Q:Critic
最後の2つのモデルは何の疑問も抱かせないと思います。最初の潜在状態モデルは、出力に確率的ノードを持つエンコーダーです。ActorもCriticも、エンコーダーの操作結果をソースデータとして使用します。 ここで、変分オートエンコーダを思い出すのが適切でしょう。
私たちのこれまでの開発によって、エンコーダーを別のモデルに移すことはなく、以前と同じようにActorモデルのアーキテクチャの中に残すことができるようになりました。したがって、提案アルゴリズムを実装するためには、Actorのアーキテクチャに変更を加えなければなりません。すなわち、データの前処理ブロック(エンコーダー)の出力に確率的ノードを追加する必要があります。
モデルのアーキテクチャは、CreateDescriptionsメソッドで指定します。基本的には、Actorのアーキテクチャに最小限の変更を加えるだけで、データの前処理ブロックは変更しません。値動きと指標の履歴データは、全結合層に供給されます。その後、ニューラル層で一括正規化の一次処理を受けます。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
正規化されたデータは、次に2つの連続した畳み込み層に通され、データ構造から特定のパターンを抽出しようとします。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; int prev_wout = descr.window_out = HistoryBars / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
2つの全結合層を使って、環境の状態を周辺化します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次に、受信したデータを口座状況に関する情報と組み合わせます。ここで、モデルアーキテクチャに最初の変更を加えます。確率ブロックの前に、潜在表現の2倍の大きさの層を作る必要があります。したがって、連結層のサイズを潜在表現のサイズの2倍に指定します。続いて、変分オートエンコーダの潜在状態の層が続きます。この層でストキャスティックノードを作ります。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
データ前処理ユニット(エンコーダ)のサイズが大きくなっていることに注意してください。モデル間のデータ転送を手配する際には、この点を考慮しなければなりません。
Actorの意思決定ブロックは変えずにおきました。これは3つの全結合層と変分オートエンコーダの潜在状態層を含み、Actorの確率的挙動を作り出します。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
では、Criticのアーキテクチャーを見てみましょう。一見したところ、SMAC法の著者の提案には、Criticのアーキテクチャに関する要件は含まれていません。そのままにしておくことも簡単です。覚えていらっしゃるかもしれませんが、ここでは報酬関数を分解して使用します。問題は、追加された確率的ノードのエントロピーをどこに割り当てるべきか、ということです。既存の報酬要素に追加することもできますが、報酬関数の分解の文脈では、Criticの出力にもうひとつ要素を加える方が論理的です。そこで、報酬要素の数の定数を増やします。
#define NRewards 5 //Number of rewards
それ以外は、Criticのモデルのアーキテクチャは変わっていません。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
SMACアルゴリズムを実装するために必要なすべてのモデルを指定しました。ただし、提案した方法をNNMアルゴリズムに実装していることを忘れてはなりません。したがって、アルゴリズムの完全な機能を維持するために、以前に使用されたすべてのモデルを保持します。ランダム畳み込みエンコーダーのモデルはそのまま引き継がれます。そのことにこだわるつもりはありません。添付ファイルをご覧ください。この記事で使用されているすべてのプログラムもそこで紹介されています。
モデル間のデータ転送の問題に戻りましょう。CriticにActorの潜在状態を参照させるために、LatentLayer定数で指定された潜在状態の層のIDを使用します。したがって、Actorのアーキテクチャの変更に応じてCriticを目的のニューラル層にリダイレクトするには、指定された定数の値を変更するだけでよくなります。この文脈では、プログラムコードを調整する必要はありません。
#define LatentLayer 7
ここで、報酬関数のエントロピー成分を計算するアルゴリズムについて見てみましょう。この方法の著者は、理論的な部分で提示された問題に対するビジョンを提示しましたが、私たちはNNM法の実装を拡張し、核ノルムをActorのエントロピー成分として用いました。報酬関数のさまざまな要素の値を比較できるようにするには、エンコーダーにも同様のアプローチを用いるのが論理的です。
SMAC法の著者は、潜在状態のエントロピーを推定するためにK+1エンコーダサンプルを使用することを提案しています。エンコーダーの訓練プロセスにおいて、環境の1つの状態に対して、ある平均値に非常に早く到達することは明らかです。エンコーダーのパラメータをさらに最適化する過程で、分散値を小さくして個々の状態の分離を最大化するよう努力します。極限で分散が0になるにつれて、エントロピーも0になります。カーネルノルムを使っても同じ効果が得られるのでしょうか。
この質問に答えるためには、数学の方程式を掘り下げても、練習を参考にしてもいいでしょう。もちろん、カーネルノルムを使用する可能性をテストするために、これから長い間モデルを作成して訓練することはありません。それをより簡単に、より速くします。小さなPythonスクリプトを作ってみましょう。
まず、numpyとmatplotlibの2つのライブラリをインポートしましょう。前者を計算に、後者を結果の視覚化に使用します。
# Import libraries import numpy as np import matplotlib.pyplot as plt
サンプルを作成するには、分布の統計的指標、すなわち平均値と対応する分散が必要です。これらは訓練中にモデルによって生成されます。アプローチをテストするために必要なのはランダムな値だけです。
mean = np.random.normal(size=[1,10]) std = np.random.rand(1,10)
どの数字も平均値として使用できることにご注意ください。正規分布から生成します。ただし、分散は正の値しかとれないので、(0,1)の範囲で生成します。
ストキャスティックノードと同様に、分布の再パラメータ化のトリックを使用します。そのために、正規分布からランダムな値の行列を生成します。
data = np.random.normal(size=[20,10])
社内の報酬を記録するためのベクトルを用意します。
reward=np.zeros([20])
つまり、分散が減少し、他の条件が等しい場合に、核ノルムを用いて内発的報酬がどのように振る舞うかをテストする必要があります。
分散を減らすために、削減因子のベクトルを作成します。
scl = [2**(-k/2.0) for k in range(20)]
次に、平均が一定で分散が減少するランダムデータに対して、分布の再パラメータ化のトリックを使用するループを作成します。得られたデータをもとに、カーネルノルムを用いて内部報酬を計算します。得られた結果を、用意した報酬ベクトルに保存します。
for idx, k in enumerate(scl): new_data=mean+data*(std*k) _,S,_=np.linalg.svd(new_data) reward[idx]=S.sum()/(np.sqrt(new_data*new_data).sum()*max(new_data.shape))
スクリプトの結果を視覚化します。
# Draw results
plt.plot(scl,reward)
plt.gca().invert_xaxis()
plt.ylabel('Reward')
plt.xlabel('STD multiplier')
plt.xscale('log',base=2)
plt.savefig("graph.png")
plt.show() 
得られた結果は、カーネルノルムを用いると、分布の分散が減少し、内部報酬が減少することを明確に示しています。つまり、潜在状態のエントロピーを推定するためにカーネルノルムを安全に使うことができます。
MQL5を使ったアルゴリズムの実装に戻りましょう。これで潜在状態エントロピーの推定を実行し始めることができます。まず、サンプリングする潜在状態の数を決定する必要があります。この指標をSamplLatentStates定数で定義します。
#define SamplLatentStates 32
次の疑問は、各潜在状態をサンプリングするために、エンコーダー(この場合はActor)モデルをフルフォワードパスする必要が本当にあるのか、ということです。
初期データとモデルパラメータを変更しなければ、すべてのニューラル層の結果は、後続のパスごとに同じになることは明らかです。唯一の違いは、ストキャスティックノードの結果にあります。従って、Actorモデルを各状態に対して1回直接パスすれば十分です。次に、分布の再パラメータ化のトリックを使い、必要な隠れ状態の数をサンプリングします。アイデアは明確なので、実装に進みます。
まず、平均が0、分散が1の正規分布からランダムな値の行列を生成します。このような分布指標は、再パラメータ化に最も便利です。
float EntropyLatentState(CNet &net) { //--- random values double random[]; Math::MathRandomNormal(0,1,LatentCount * SamplLatentStates,random); matrix<float> states; states.Assign(random); states.Reshape(SamplLatentStates,LatentCount);
次に、Actorモデルから学習された分布パラメータをロードします。この分布パラメータは、最後尾のエンコーダー層に格納されています。ここで注意すべきは、モデルは1つのデータバッファを提供し、そこに学習された分布のすべての平均値が順次格納され、その後にすべての分散が格納されるということです。しかし、行列演算をおこなうには、1つのベクトルではなく、行に沿って値を重複させた2つの行列が必要になります。ここでちょっとしたトリックを使います。まず、必要な行数とその2倍の列数を持つ、ゼロ値で埋め尽くされた大きな行列を1つ作成します。最初の行では、データバッファからデータを分布パラメータとともに書き込みます。次に、行列の値を列ごとに累積和する機能を使います。
トリックは、最初の文字列を除くすべての文字列がゼロで埋められていることです。累積和演算を実行した結果、最初の行から後続の行すべてにデータをコピーするだけになります。
あとは行列を縦に2等分して、分割行列の配列を得ればよくなります。インデックス0を持つ平均値の行列が格納されます。分散行列のインデックスは1です。
//--- get means and std vector<float> temp; matrix<float> stats = matrix<float>::Zeros(SamplLatentStates,2 * LatentCount); net.GetLayerOutput(LatentLayer - 1,temp); stats.Row(temp,0); stats=stats.CumSum(0); matrix<float> split[]; stats.Vsplit(2,split);
これで、正規分布からランダムな値をパラメータ化し直すだけで、必要なサンプル数を得ることができます。
//--- calculate latent values states = states * split[1] + split[0];
行列の下部には、フォワードパスの入力データとしてActorとCriticが使用する現在のエンコーダー値を文字列で追加します。
//--- add current latent value net.GetLayerOutput(LatentLayer,temp); states.Resize(SamplLatentStates + 1,LatentCount); states.Row(temp,SamplLatentStates);
この段階で、カーネルノルムを計算するためのすべてのデータが揃いました。報酬関数のエントロピー成分を計算します。結果は呼び出し側プログラムに返されます。
//--- calculate entropy states.SVD(split[0],split[1],temp); float result = temp.Sum() / (MathSqrt(MathPow(states,2.0f).Sum() * MathMax(SamplLatentStates + 1,LatentCount))); //--- return result; }
準備作業は完了です。環境との相互作用のためのEAと訓練モデルの作成に移りましょう。
環境との相互作用のためのEA(Research.mq5とTest.mq5)は変更されていないので、ここでは触れません。記事で使用したすべてのプログラムの完全なコードは、添付ファイルでご覧いただけます。
モデル訓練EAに移り、Train訓練メソッドに焦点を当てましょう。メソッドの最初に、経験値再生バッファの全体的なサイズを決定します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
次に、ランダム畳み込みエンコーダを使って、経験再生バッファからすべての既存の例をエンコードします。このプロセスは、以前の実装から完全に移行されました。
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); next.Assign(Buffer[tr].States[st + 1].rewards); rewards.Row(temp - next * DiscFactor,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
経験再生バッファからすべての例をエンコードし終えたら、行列から余分な行を削除します。
if(state != total_states)
{
rewards.Resize(state,NRewards);
state_embedding.Reshape(state,state_embedding.Cols());
total_states = state;
}
次に、直接的なモデル訓練のブロックに入ります。ここではローカル変数を初期化し、モデル学習ループを作成します。ループの反復回数は、外部変数Iterationsによって決定されます。
vector<float> rewards1, rewards2; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
ループの本体では、モデルパラメータを更新する現在の反復のために、軌跡と環境の別の状態をサンプリングします。
そして、対象モデルを使用するための閾値を確認します。必要であれば、その後の状態データを適切なデータバッファに読み込みます。
target_reward = vector<float>::Zeros(NRewards); reward.Assign(Buffer[tr].States[i].rewards); //--- Target TargetState.AssignArray(Buffer[tr].States[i + 1].state); if(iter >= StartTargetIter) { float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
準備されたデータは、Actorと2つのターゲットCriticモデルのフォワードパスを実行するために使用されます。
if(!Actor.feedForward(GetPointer(TargetState), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
対象モデルを直接通過した結果に基づいて、その後の状態値のベクトルを用意します。さらに、SMACアルゴリズムに従って潜在状態のエントロピー推定を加えます。
TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; for(ulong r = 0; r < target_reward.Size(); r++) target_reward -= Buffer[tr].States[i + 1].rewards[r]; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
後続の状態のコストベクトルを準備した後、選択された環境状態での作業に移り、対応するソースデータで必要なバッファを埋めます。
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
次に、環境の潜在状態を生成するために、Actorのフォワードパスを実行します。
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Criticsのパラメータを更新する段階では、潜在状態のみを使用します。Actorの行動をプレイバックバッファから取り出し、両Criticのフォワードパスを呼び出します。
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Criticのパラメータは、現在のActorの方策に合わせて調整された環境からの実際の報酬を考慮して更新されます。Actorが更新した方策の影響パラメータは、その後の環境状態に対するコストのベクトルにすでに考慮されています。
報酬関数を分解して適用し、CAGradメソッドで勾配を最適化することを思い出してください。この結果、各Criticの基準値のベクトルが異なることになります。まず、参照値のベクトルを用意し、最初のCriticをリバースパスします。
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(reward + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
次に、2つ目のCriticに対してこの操作を繰り返します。
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(reward + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
各Criticのパラメータを更新した後、エンコーダーのパラメータを更新するためにリバースパスを実行することに注意してください。また、各段階でプロセスを管理することも忘れてはなりません。
Criticsのパラメータを更新した後、Actorモデルの最適化に移ります。Actorレベルでの誤差勾配を決定するために、Actorの行動コストを予測する移動平均誤差が最小となるCriticを使用します。このアプローチは、Actor方策によって生成される行動をより正確に推定し、その結果、誤差勾配の分布をより正しくする可能性があります。
//--- Policy study CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
Actorの前方通過はすでに実行済みです。ここで、環境のその後の状態を予測する定式化をおこないます。ここでのキーワードは「予測」です。結局のところ、経験再生バッファには、値動きや指標に関する過去のデータが含まれています。Actorの行動に依存しないので、安心して使えます。しかし、口座の状態は、Actorがおこなった取引操作に直接依存します。Actorの現在の方策内の行動は、経験再生バッファに保存されているものと異なる場合があります。この段階で、口座の状態を表す予測ベクトルを形成しなければなりません。便宜上、この機能は前回の記事で検討したForecastAccountメソッドにすでに実装されています。あとは正しい初期データを送信して呼び出すだけです。
Actor.getResults(rewards1); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,rewards1,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetState.AddArray(forecast);
必要なデータがすべて揃ったので、選択されたCriticとランダム畳み込みエンコーダーのフォワードパスを実行し、予測される後続状態の埋め込みを生成します。
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Convolution.feedForward(GetPointer(TargetState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
得られたデータに基づいて、報酬関数の参照値のベクトルを形成し、Actorのパラメータを更新します。また、CAGradメソッドを用いて誤差勾配を補正します。
next.Assign(Buffer[tr].States[i + 1].rewards); Convolution.getResults(rewards1); target_reward += KNNReward(KNN,rewards1,state_embedding,rewards) + next * DiscFactor; if(forecast[3] == 0.0f && forecast[4] == 0.0f) target_reward[2] -= (Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance); critic.getResults(reward); reward += CAGrad(target_reward - reward);
その後、Criticのパラメータ更新モードを無効にし、そのリバースパスを行い、Actorのフルリバースパスをおこないます。
Result.AssignArray(reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
必ず全過程を監視してください。両モデルのリバースパスを成功させた後、Criticを訓練モードに戻します。
現段階では、CriticとActorの両方のパラメータを更新しました。残るは、Criticのターゲットモデルのパラメータを更新することです。ここでは、外部EAパラメータにTau比を設定したモデルパラメータのソフト更新を使用します。
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau);
モデル訓練サイクルの本体での操作が終わると、訓練プロセスの進行状況をユーザーに通知し、ループの次の反復に移ります。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
モデル訓練サイクルのすべての反復が成功したら、チャートのコメントフィールドを消去します。訓練結果をジャーナルに表示し、EAを終了します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
お気づきかもしれませんが、Actorの訓練中にSMAC法が提供する潜在状態のエントロピー成分の計算をスキップしました。報酬のベクトルは分割しないことにしました。NNMアルゴリズムを構築する際、このプロセスは別のKNNRewardメソッドに移されました。このメソッドで必要な調整をおこないました。
前回と同様に、まず、メソッド本体の予測状態埋め込みと、経験再生バッファからの環境状態埋め込み行列のサイズの対応を確認します。
vector<float> KNNReward(ulong k, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards ) { if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return vector<float>::Zeros(0); }
コントロールブロックの受け渡しに成功したら、必要なローカル変数を初期化します。
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); k = MathMin(k,states); ulong rew_size = rewards.Cols(); vector<float> distance = vector<float>::Zeros(states); matrix<float> k_rewards = matrix<float>::Zeros(k,rew_size); matrix<float> k_embeding = matrix<float>::Zeros(k + 1,size); matrix<float> U,V; vector<float> S;
これで準備作業は終了し、直接計算作業に移ります。まず、予測された状態から実際の例までの距離を経験再現バッファから求めます。
for(ulong i = 0; i < size; i++) distance+=MathPow(state_embedding.Col(i) - embedding[i],2.0f); distance = MathSqrt(distance);
k最近傍を定義し、埋め込み行列を埋めます。さらに、対応する報酬をあらかじめ用意した行列に移します。同時に、状態ベクトル間の距離に逆比例する比率で報酬ベクトルを調整します。指定された比率は、更新された行動方策に従って、選択されたActorの行動の結果に対する経験再生バッファからの報酬の影響を決定します。
for(ulong i = 0; i < k; i++) { ulong pos = distance.ArgMin(); k_rewards.Row(rewards.Row(pos) * (1 - MathLog(distance[pos] + 1)),i); k_embeding.Row(state_embedding.Row(pos),i); distance[pos] = FLT_MAX; }
最後の文字列の埋め込み行列に、環境の予測状態の埋め込みを追加します。
k_embeding.Row(embedding,k);
得られた埋め込み行列の特異値のベクトルを求めます。この操作は、組み込みの行列演算を使って簡単に実行できます。
k_embeding.SVD(U,V,S);
報酬ベクトルは、参加率で調整されたk近傍の対応する報酬の平均として形成されます。
vector<float> result = k_rewards.Mean(0);
報酬ベクトルの最後の2つの要素を、それぞれActor方策と潜在状態のカーネルノルムを用いたエントロピー成分で埋めます。
result[rew_size - 2] = S.Sum() / (MathSqrt(MathPow(k_embeding,2.0f).Sum() * MathMax(k + 1,size))); result[rew_size - 1] = EntropyLatentState(Actor); //--- return (result); }
生成された報酬ベクトルは、呼び出し元のプログラムに返されます。その他のEA方式はすべて変更なく移管されました。
これで、モデル訓練EAに関する我々の作業は終了です。記事で使用したすべてのプログラムの完全なコードは、添付ファイルでご覧いただけます。テストの時間です。
3.検証
この記事の実用的な部分では、以前に実装されたNNMアルゴリズムEAにStochastic Marginal Actor-Critic法を実装することに多大な労力を費やしました。次に、出来上がった仕事をテストする段階に移ります。いつものように、モデルはEURUSDH1で訓練され、テストされています。 すべての指標のパラメータがデフォルトで使用されます。
もう9月なので、訓練期間を2023年の7月まで増やしました。2023年8月の履歴データを用いてモデルをテストします。
学習用EA「......\NNM\Study.mq5」を作成する際に、NNM法の特徴や経験値再生バッファに生成状態がないことについては既に述べました。そこで、訓練サイクルの反復回数を減らすことにしました。訓練モデルに関しても、同じアプローチを堅持します。
前回の記事で使用した訓練プロセスと同様に、全体として経験再生バッファを減らすことはしませんが、同時に、経験値再生バッファを徐々に埋めていきます。最初の反復では、訓練データ収集EAを100パス起動します。指定された履歴間隔では、すでにモデルの訓練用にほぼ360Kの状態が得られています。
モデル訓練の最初の反復の後、さらに50パスで例のデータベースを補足します。こうして、訓練された方策の枠組みの中で、Actorの行動に対応する新しい状態で経験再生バッファを徐々に満たしていきます。
Actor方策の学習という望ましい結果が得られるまで、モデルの学習と追加的な例収集のプロセスを何度か繰り返します。
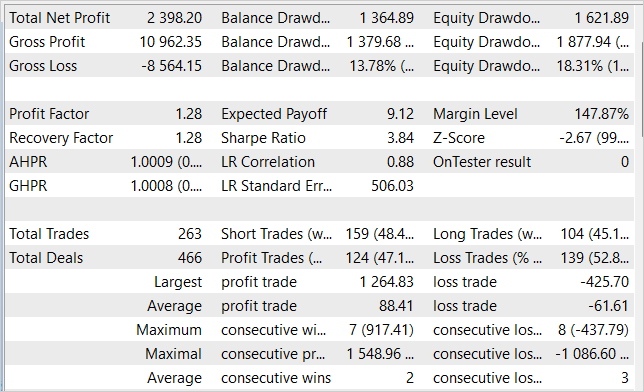
モデルを訓練しながら、訓練サンプルで利益を生み出し、獲得した知識をその後の環境状態に対して汎化することができるActor方策を得ることに成功しあました。例えば、ストラテジーテスターでは、学習させたモデルは、学習サンプルの後、1ヶ月以内に23.98%の利益を生み出すことができました。テスト期間中、このモデルは263回の取引を行い、そのうちの47%は利益で決済されました。取引ごとの最大利益は、最大損失取引のほぼ3倍です。取引ごとの平均利益は平均損失より44%高い。この結果、プロフィットファクターは1.28となりました。グラフでは、バランスラインが明確に上昇傾向にあることがわかります。

結論
本稿では、強化学習問題を解くための革新的なアプローチを提供するStochastic Marginal Actor-Critic法について考察しました。最大エントロピーの原理に基づき、SMACを使用すると、エージェントは環境をより効率的に探索し、より堅牢に学習できます。これは、追加の確率的潜在変数ノードを導入することによって実現されます。
エージェントの方策に潜在変数を使用することで、その表現力と、オブザベーションと報酬における確率性をモデル化する能力が大幅に向上します。
しかし、、潜在変数を用いた訓練方策にはいくつかの困難さがあります。この方法の著者は、こうした困難に対処するための解決策を提示しています。
実用的な部分では、テスト結果によって検証されるように、NNMメソッドアーキテクチャにSMACを統合し、シンプルで効果的な方策最適化メソッドを作成することに成功しました。毎月最大24%のリターンを生み出すことができるActor方策を訓練することができました。
これらの結果を考慮すると、SMAC法は実用的な問題を解決するための効果的なソリューションです。
ただし、この記事で紹介されているプログラムはすべて、その方法を実証するためだけに作成されたものであり、実際の口座で使用するには適していないことに留意してください。さらに機能の設定と最適化が必要になります。
金融市場はハイリスクな投資であることを忘れないでください。ご自分またはご自分の電子取引ツールによっておこなわれた取引によるすべてのリスクは、すべてご自分の責任となります。
リンク
- Latent State Marginalization as a Low-cost Approach for Improving Exploration
- ニューラルネットワークが簡単に(第56回):核の規範を研究の推進力に
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 5 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 6 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13290
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
テストEAを通過するたびに、まるでモデルが以前のものすべてと異なるかのように、劇的に異なる結果が生成される。テストEAを通過するたびにモデルが進化するのは明らかですが、このEAの挙動は進化とは言い難いものです。
ここにいくつかの写真があります:
このモデルはアクターの確率的政治を使用している。そのため、研究の初期には、すべてのパスでランダムな取引を見ることができる。このパスを集め、モデルの研究を再開する。このプロセスを何度か繰り返す。アクターが良い政治的行動を見つける間に。
別の言い方をしよう。サンプルを収集(研究)し、それを処理(研究)した後、テストスクリプトを実行します。ResearchもStudyも行わず、何度か連続して実行すると、得られる結果は全く異なる。
テストスクリプトは OnInit サブルーチン(99 行目)で学習済みモデルをロードします。ここでは、テスト処理中に変化してはならないモデルを EA に与えます。私が理解する限り、それは安定しているはずです。そうすれば、最終的な結果は変わらないはずです。
その間、モデルのトレーニングは行いません。より多くのサンプルを集めることだけがテストによって行われる。
ランダム性はむしろResearchモジュールで観察され、場合によってはStudyモジュールでポリシーの最適化中に観察される。
アクターは、フィードフォワード結果を計算するために240行目で起動される。作成時にランダムに初期化されていないのであれば、ランダムに動作することはないはずです。
上記の推論に誤りはありませんか?
別の言い方をしよう。サンプルを収集(研究)し、それを処理(研究)した後、テストスクリプトを実行します。調査も研究もしていない状態で、何度か連続して実行すると、得られる結果はまったく異なるものになる。
テストスクリプトは OnInit サブルーチン(99 行目)で学習済みモデルをロードします。ここでは、テスト処理中に変化してはならないモデルを EA に与えます。私が理解する限り、それは安定しているはずです。そのため、最終的な結果は変化しないはずです。
その間、モデルのトレーニングは行いません。テストでは、サンプルの収集のみを行います。
ランダム性は、むしろリサーチ・モジュールで観察され、場合によっては、ポリシーの最適化中にスタディで観察される。
アクターは、フィードフォワード結果を計算するために240行目で起動される。もし生成時にランダムに初期化されていないのであれば、ランダムに動作することはないはずです。
上記の推論に誤りはありませんか?
アクターは確率的ポリシーを使っています。VAEで 実装しています。
レイヤCNeuronVAEOCLは前のレイヤのデータをガウス分布の平均と標準偏差として使用し、この分布から同じアクションをサンプリングする。最初にモデルにランダムな重みを入れる。そのため、ランダムな平均と標準偏差が生成される。最終的に、モデルテストのすべてのパスで、ランダムなアクションを持つ。学習時に、モデルはすべての状態についていくつかの平均を見つけ、STDはゼロになる傾向がある。