
Neuronale Netze leicht gemacht (Teil 57): Stochastic Marginal Actor-Critic (SMAC)

Einführung
Beim Aufbau eines automatisierten Handelssystems entwickeln wir Algorithmen für die sequentielle Entscheidungsfindung. Die Methoden des Verstärkungslernens sind genau auf die Lösung solcher Probleme ausgerichtet. Eines der Hauptprobleme beim Verstärkungslernen ist der Erkundungsprozess, wenn der Agent lernt, mit seiner Umgebung zu interagieren. In diesem Zusammenhang wird häufig das Prinzip der maximalen Entropie angewandt, das den Agenten dazu motiviert, Handlungen mit dem größtmöglichen Grad an Zufälligkeit auszuführen. In der Praxis trainieren solche Algorithmen jedoch einfache Agenten, die nur lokale Veränderungen um eine einzelne Aktion herum lernen. Der Grund dafür ist die Notwendigkeit, die Entropie der Agentenpolitik zu berechnen und sie als Teil des Trainingsziels zu verwenden.
Gleichzeitig besteht ein relativ einfacher Ansatz zur Erhöhung der Aussagekraft der Politik eines Akteurs (Actor) in der Verwendung latenter Variablen, die dem Akteur ein eigenes Inferenzverfahren zur Modellierung der Stochastizität von Beobachtungen, der Umgebung und unbekannter Belohnungen zur Verfügung stellen.
Durch die Einführung latenter Variablen in die Politik des Agenten können vielfältigere Szenarien abgedeckt werden, die mit historischen Beobachtungen vereinbar sind. Hier ist anzumerken, dass Politiken mit latenten Variablen keinen einfachen Ausdruck zur Bestimmung ihrer Entropie zulassen. Eine naive Entropieschätzung kann bei der Optimierung von Richtlinien zu katastrophalen Fehlern führen. Außerdem unterscheiden stochastische Aktualisierungen mit hoher Varianz zur Entropiemaximierung nicht ohne weiteres zwischen lokalen Zufallseffekten und multimodaler Exploration.
Eine der Möglichkeiten zur Behebung dieser Unzulänglichkeiten der Politik für latente Variablen wurde in dem Artikel „Latent State Marginalization as a Low-cost Approach for Improving Exploration“ (Latente Zustands-Marginalization als kosteneffizienter Ansatz zur Verbesserung der Erkundung). Die Autoren schlagen einen einfachen, aber effektiven Algorithmus zur Optimierung von Richtlinien vor, der eine effizientere und robustere Erkundung sowohl in vollständig beobachtbaren als auch in teilweise beobachtbaren Umgebungen ermöglicht.
Die wichtigsten Beiträge dieses Artikels lassen sich kurz mit den folgenden Thesen zusammenfassen:
- Motivation für die Verwendung von Strategien mit latenten Variablen zur Verbesserung der Exploration und der Robustheit unter den Bedingungen der teilweisen Beobachtbarkeit.
- Es werden mehrere stochastische Schätzverfahren vorgeschlagen, die sich auf die Effizienz der Studie und die Verringerung der Varianz konzentrieren.
- Die Anwendung von Ansätzen auf die Actor-Critic-Methode führt zur Entwicklung des Algorithmus Stochastic Marginal Actor-Critic (SMAC).
1. SMAC-Algorithmus
Die Autoren des Algorithmus „Stochastic Marginal Actor-Critic“ schlagen vor, latente Variablen zu verwenden, um eine verteilte Akteurspolitik zu entwickeln. Dies ist ein einfacher und effizienter Weg, um die Flexibilität der Aktionsmodelle und Richtlinien des Agenten zu erhöhen. Dieser Ansatz erfordert nur minimale Änderungen an bestehenden Algorithmen, die stochastische Agentenverhaltensregeln verwenden.
Eine Politik mit latenten Variablen kann wie folgt ausgedrückt werden:
![]()
wobei st eine latente Variable ist, die von der aktuellen Beobachtung abhängt.
Die Einführung der latenten Variable q(st|xt) erhöht in der Regel die Aussagekraft der Politik des Akteurs. Dadurch kann die Politik ein breiteres Spektrum an optimalen Maßnahmen erfassen. Dies kann besonders in der Anfangsphase der Forschung nützlich sein, wenn noch keine Informationen über künftige Belohnungen vorliegen.
Zur Parametrisierung des stochastischen Modells schlagen die Autoren der Methode vor, faktorisierte Gaußsche Verteilungen sowohl für die Politik des Akteurs π(at|st) und für die Funktion der latenten Variablen q(st|xt) zu verwenden. Dies führt zu einer rechnerisch effizienten Politik für latente Variablen, da Stichprobenziehung und Dichteschätzung kostengünstig bleiben. Darüber hinaus können wir die vorgeschlagenen Ansätze auf Modelle anwenden, die auf bestehenden Algorithmen mit stochastischen Strategien und einer einzigen Gaußverteilung basieren. Wir fügen einfach einen neuen stochastischen Knoten hinzu.
Bitte beachten Sie, dass aufgrund des Markov-Prozesses π(at|st) nur vom aktuellen latenten Zustand abhängt, obwohl der vorgeschlagene Algorithmus leicht auf Nicht-Markov-Situationen erweitert werden kann. Dank der Rekursion beobachten wir jedoch eine Marginalisierung gemäß der vollständigen verborgenen Geschichte, da der aktuelle latente Zustand st, wie auch die Poslitik π(at|st) eine Folge einer Reihe von Übergängen vom Ausgangszustand unter dem Einfluss der vom Agenten durchgeführten Aktionen sind.
![]()
Gleichzeitig sind die vorgeschlagenen Ansätze zur Verarbeitung latenter Variablen nicht davon abhängig, was q bewirkt.
Das Vorhandensein latenter Variablen macht das Maximum-Entropie-Training recht schwierig. Schließlich erfordert dies eine genaue Bewertung der Entropiekomponente. Die Entropie eines latenten Variablenmodells ist aufgrund der Schwierigkeit der Marginalisierung äußerst schwierig zu schätzen. Darüber hinaus erhöht die Verwendung latenter Variablen die Varianz des Gradienten. Außerdem können latente Variablen in der Q-Funktion zur besseren Aggregation der Unsicherheit verwendet werden.
Für jeden dieser Fälle leiten die Autoren von Stochastic Marginal Actor-Critic vernünftige Methoden für den Umgang mit latenten Variablen ab. Das Endergebnis ist recht einfach und verursacht nur minimale zusätzliche Ressourcenkosten im Vergleich zu Strategien ohne latente Variablen.
Die Verwendung latenter Variablen wiederum macht die Entropie (oder Grenzentropie) aufgrund der Unlösbarkeit des Wahrscheinlichkeitslogarithmus unbrauchbar.
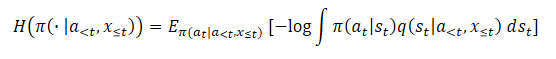
Die Verwendung eines naiven Schätzers führt zur Maximierung der oberen Schranke der objektiven maximalen Entropiefunktion und damit zur Maximierung des Fehlers. Dies führt dazu, dass die Variationsverteilung so weit wie möglich von der wahren posterioren Schätzung q(st|a<t,x≤t) entfernt ist. Außerdem ist dieser Fehler nicht begrenzt und kann beliebig groß werden, ohne dass sich dies auf die tatsächliche Entropie auswirkt, die wir maximieren wollen, was zu ernsthaften Problemen mit der numerischen Instabilität führt.
Der Artikel zeigt die Ergebnisse eines vorläufigen Experiments, bei dem dieser Ansatz zur Schätzung der Entropie während der Optimierung von Richtlinien zu extrem hohen Werten führte, die die wahre Entropie deutlich überschätzten und zu untrainierten Richtlinien führten. Nachfolgend finden Sie eine Visualisierung aus dem genannten Artikel.
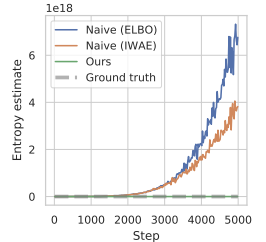
Um das Problem der Überschätzung zu lösen, schlagen die Autoren der Methode vor, einen Schätzer für die untere Grenze der Grenzentropie zu konstruieren.
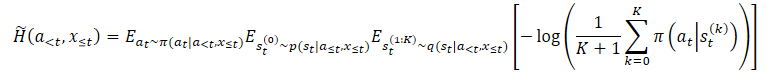
wobei p(st|a≤t,x≤t) die unbekannte posteriore Verteilung der Politik ist.
Wir können jedoch daraus einfach st⁰ auswählen und dann ein t wählen, wenn st⁰. Daraus ergibt sich ein verschachtelter Evaluator, bei dem wir tatsächlich K+1 Mal aus q(st|a<t,x≤t) auswählen. Um die Aktion auszuwählen, verwenden wir nur die erste latente Variable st⁰. Alle anderen latenten Variablen werden zur Schätzung der marginalen Entropie verwendet.
Dies ist nicht gleichbedeutend mit dem Ersetzen des Erwartungswerts im Logarithmus durch unabhängige Stichproben. Der vorgeschlagene Schätzer nimmt monoton mit K zu und wird im Grenzfall zu einem unverzerrten Grenzentropieschätzer.
Die oben genannten Methoden können auf allgemeine Algorithmen zur Entropiemaximierung angewendet werden. Die Autoren der Methode haben jedoch einen speziellen Algorithmus namens Stochastic Marginal Actor-Critic (SMAC) entwickelt. SMAC zeichnet sich durch die Verwendung einer Akteurspolitik mit latenten Variablen und die Maximierung der unteren Grenze der Zielfunktion der marginalen Entropie aus.
Der Algorithmus folgt dem allgemein anerkannten Stil von Akteur (Actor) und Kritiker (Critic) und verwendet den Erfahrungswiedergabepuffer, um Daten zu speichern, auf deren Grundlage die Parameter sowohl des Akteurs als auch des Kritikers aktualisiert werden.
Der Kritiker lernt, indem er den Fehler minimiert:
![]()
wobei:
(x, a, r, x') — aus dem Wiedergabepuffer D,
a' — Aktion des Akteurs gemäß der Poltik π(·|x'),
Q ̅ — Die Zielfunktion des Kritikers,
H ̃ — Schätzung der politischen Entropie.
Darüber hinaus schätzen wir die Politikentropie mit latenten Variablen.
Außerdem wird der Akteur durch Minimierung des Fehlers aktualisiert:
![]()
Beachten Sie, dass wir bei der Aktualisierung des Kritikers die Entropieschätzung der Politik des Akteurs im nachfolgenden Zustand verwenden, während wir bei der Aktualisierung der Politik des Akteurs — im aktuellen Zustand — die Entropieschätzung verwenden.
Insgesamt ist SMAC in Bezug auf die algorithmischen Details der Reinforcement-Learning-Methoden im Wesentlichen identisch mit naivem SAC, erzielt aber Verbesserungen vor allem durch strukturiertes Explorationsverhalten. Dies wird durch die Modellierung latenter Variablen erreicht.
2. Implementierung mit MQL5
Dies sind die theoretischen Berechnungen der Methode des Autors von Stochastic Marginal Actor-Critic. Im praktischen Teil dieses Artikels werden wir den vorgeschlagenen Algorithmus mit MQL5 implementieren. Die einzige Ausnahme ist, dass wir den ursprünglichen SMAC-Algorithmus nicht vollständig wiederholen werden. Der genannte Artikel befasst sich mit der Möglichkeit, die vorgeschlagenen Methoden in fast allen Algorithmen des verstärkten Lernens einzusetzen. Wir werden diese Gelegenheit nutzen und die vorgeschlagenen Methoden in unsere Implementierung des NNM-Algorithmus einbauen, den wir im vorherigen Artikel besprochen haben.
Die ersten Änderungen werden an der Architektur der Modelle vorgenommen. Wie aus den oben dargestellten Gleichungen hervorgeht, basiert der SMAC-Algorithmus auf drei Modellen:
- q — Modell zur Darstellung des latenten Zustands;
- π — Akteur;
- Q — Kritiker.
Ich denke, die letzten beiden Modelle werfen keine Fragen auf. Das erste latente Zustandsmodell ist ein Encoder mit einem stochastischen Knoten am Ausgang. Sowohl der Akteur als auch der Kritiker verwenden die Ergebnisse der Encoder-Operation als Quelldaten. Hier wäre es angebracht, an den Variations-Auto-Encoder zu erinnern.
Unsere bisherigen Entwicklungen erlauben es uns, den Encoder nicht in ein separates Modell zu verschieben, sondern ihn wie bisher in der Architektur des Akteursmodells zu belassen. Um den vorgeschlagenen Algorithmus zu implementieren, müssen wir daher Änderungen an der Architektur des Akteurs vornehmen. Wir müssen nämlich einen stochastischen Knoten am Ausgang des Datenvorverarbeitungsblocks (Encoder) hinzufügen.
Die Architektur der Modelle wird in der Methode CreateDescriptions festgelegt. Im Wesentlichen nehmen wir nur minimale Änderungen an der Architektur des Akteurs vor, während wir den Datenvorverarbeitungsblock unverändert lassen. Historische Daten von Kursbewegungen und Indikatoren werden in eine vollständig verknüpfte neuronale Schicht eingespeist. Anschließend werden sie in der neuronalen Schicht der Stapelnormalisierung einer Erstverarbeitung unterzogen.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die normalisierten Daten werden dann durch zwei aufeinander folgende Faltungsschichten geleitet, in denen wir versuchen, bestimmte Muster aus der Datenstruktur zu extrahieren.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; int prev_wout = descr.window_out = HistoryBars / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wir marginalisieren den Zustand der Umgebung mit zwei vollständig verbundenen Schichten.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Anschließend kombinieren wir die erhaltenen Daten mit Informationen über den Kontostatus. Hier nehmen wir die erste Änderung an der Modellarchitektur vor. Vor dem stochastischen Block müssen wir eine Schicht erstellen, die doppelt so groß ist wie die latente Repräsentation: Wir benötigen Verteilungsmaße in Form von Mittelwerten und Varianzen. Daher legen wir die Größe der Verkettungsschicht auf das Doppelte der Größe der latenten Repräsentation fest. Es folgt die Schicht des latenten Zustands des Variations-Autocodierers. Mit dieser Schicht erstellen wir einen stochastischen Knoten.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass wir die Größe unserer Datenvorverarbeitungseinheit (Encoder) erhöht haben. Dies müssen wir bei der Datenübertragung zwischen den Modellen berücksichtigen.
Ich habe den Entscheidungsblock des Akteurs unverändert gelassen. Es enthält drei voll verknüpfte Schichten und eine latente Zustandsschicht eines Variations-Autocodierers, der das stochastische Verhalten des Akteurs erzeugt.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Werfen wir nun einen Blick auf die Architektur der Kritiker. Auf den ersten Blick enthalten die Vorschläge der Autoren der SMAC-Methode keine Anforderungen an die Architektur des Kritikers. Wir könnten sie einfach unverändert lassen. Wie Sie sich vielleicht erinnern, verwenden wir eine aufgeteilte (decomposed) Belohnungsfunktion. Es stellt sich die Frage: Wo soll die Entropie des hinzugefügten stochastischen Knotens angesetzt werden? Wir könnten sie zu jedem der bestehenden Belohnungselemente hinzufügen. Im Zusammenhang mit der Aufteilung der Belohnungsfunktion ist es jedoch logischer, ein weiteres Element am Ausgang des Kritikers hinzuzufügen. Deshalb erhöhen wir die Konstante der Anzahl der Belohnungselemente.
#define NRewards 5 //Number of rewards
Ansonsten ist die Architektur des Kritiker-Modells unverändert geblieben.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Wir haben alle notwendigen Modelle für die Implementierung des SMAC-Algorithmus spezifiziert. Vergessen Sie jedoch nicht, dass wir die vorgeschlagenen Methoden in den NNM-Algorithmus implementieren. Daher behalten wir alle bisher verwendeten Modelle bei, um die volle Funktionalität des Algorithmus zu erhalten. Das Modell des Random Convolutional Encoders wird ohne Änderungen übernommen. Ich will mich nicht damit aufhalten. Sie finden sie in der Anlage. Alle in diesem Artikel verwendeten Programme werden dort ebenfalls vorgestellt.
Kommen wir noch einmal auf die Frage der Datenübertragung zwischen den Modellen zurück. Damit sich der Kritiker auf den latenten Zustand des Akteurs beziehen kann, verwenden wir die ID der in der Konstante LatentLayer angegebenen latenten Zustandsschicht. Um den Kritiker entsprechend der veränderten Architektur des Akteurs auf die gewünschte neuronale Schicht umzuleiten, müssen wir also nur den Wert der angegebenen Konstante ändern. Weitere Anpassungen des Programmcodes sind in diesem Zusammenhang nicht erforderlich.
#define LatentLayer 7
Lassen Sie uns nun über die Verwendung von Algorithmen zur Berechnung der Entropiekomponente in der Belohnungsfunktion sprechen. Die Autoren der Methode haben ihre Sichtweise des im theoretischen Teil vorgestellten Themas dargelegt. Wir erweitern jedoch unsere Implementierung der NNM-Methode, bei der wir die Kernnorm als Entropiekomponente des Akteurs verwendet haben. Um die Werte der verschiedenen Elemente der Belohnungsfunktion vergleichbar zu machen, ist es logisch, einen ähnlichen Ansatz für den Encoder zu verwenden.
Die Autoren der SMAC-Methode schlagen vor, die K+1 Encoder-Stichprobe zu verwenden, um die Entropie des latenten Zustands zu schätzen. Es liegt auf der Hand, dass wir für einen einzelnen Zustand der Umgebung während des Encoder-Trainings recht schnell zu einem Durchschnittswert kommen. Im Zuge der weiteren Optimierung der Encoder-Parameter werden wir uns bemühen, den Varianzwert zu reduzieren, um die Trennung der einzelnen Zustände zu maximieren. Da die Streuung im Grenzbereich zu „0“ abnimmt, tendiert auch die Entropie gegen „0“. Erzielen wir die gleiche Wirkung, wenn wir die Kernel-Norm verwenden?
Um diese Frage zu beantworten, können wir uns in mathematische Gleichungen vertiefen oder auf die Praxis zurückgreifen. Natürlich werden wir jetzt noch lange kein Modell erstellen und trainieren, um die Möglichkeit der Verwendung der Kernel-Norm zu testen. Wir werden es viel einfacher und schneller machen. Lassen Sie uns ein kleines Python-Skript erstellen.
Zunächst importieren wir zwei Bibliotheken: numpy und matplotlib. Die erste wird für Berechnungen verwendet, die zweite für die Visualisierung der Ergebnisse.
# Import libraries import numpy as np import matplotlib.pyplot as plt
Um Stichproben zu erstellen, benötigen wir statistische Indikatoren für Verteilungen: Durchschnittswerte und entsprechende Varianzen. Sie werden vom Modell während des Trainings erzeugt. Wir brauchen nur Zufallswerte, um den Ansatz zu testen.
mean = np.random.normal(size=[1,10]) std = np.random.rand(1,10)
Bitte beachten Sie, dass alle Zahlen als Durchschnittswerte verwendet werden können. Wir generieren sie aus einer Normalverteilung. Die Varianzen können jedoch nur positiv sein, und wir erzeugen sie im Bereich (0, 1).
Wir werden den Trick der Umparametrisierung der Verteilung ähnlich wie beim stochastischen Knoten anwenden. Zu diesem Zweck wird eine Matrix von Zufallswerten aus der Normalverteilung erstellt.
data = np.random.normal(size=[20,10])
Wir werden einen Vektor zur Erfassung unserer internen Belohnungen erstellen.
reward=np.zeros([20])
Die Idee ist folgende: Wir müssen testen, wie sich intrinsische Belohnungen unter Verwendung der Kernnorm bei reduzierter Varianz und unter sonst gleichen Bedingungen verhalten.
Um die Varianz zu reduzieren, wird ein Vektor von Reduktionsfaktoren erstellt.
scl = [2**(-k/2.0) for k in range(20)]
Als Nächstes erstellen wir eine Schleife, in der wir den Trick der Neuparametrisierung der Verteilung auf unsere Zufallsdaten mit konstantem Mittelwert und abnehmender Varianz anwenden werden. Auf der Grundlage der gewonnenen Daten berechnen wir die interne Belohnung mit Hilfe der Kernel-Norm. Speichern Sie die Ergebnisse im vorbereiteten Belohnungs-Vektor.
for idx, k in enumerate(scl): new_data=mean+data*(std*k) _,S,_=np.linalg.svd(new_data) reward[idx]=S.sum()/(np.sqrt(new_data*new_data).sum()*max(new_data.shape))
Visualisieren wir die Skriptergebnisse.
# Draw results
plt.plot(scl,reward)
plt.gca().invert_xaxis()
plt.ylabel('Reward')
plt.xlabel('STD multiplier')
plt.xscale('log',base=2)
plt.savefig("graph.png")
plt.show() 
Die erzielten Ergebnisse zeigen deutlich, dass die interne Belohnung bei Verwendung der Kernel-Norm geringer ausfällt und die Varianz der Verteilung bei ansonsten gleichen Bedingungen abnimmt. Dies bedeutet, dass wir die Kernel-Norm sicher zur Schätzung der Entropie des latenten Zustands verwenden können.
Kommen wir zurück zu unserer Implementierung des Algorithmus mit MQL5. Jetzt können wir mit der Umsetzung der Schätzung der latenten Zustandsentropie beginnen. Zunächst müssen wir die Anzahl der latenten Zustände bestimmen, die in die Stichprobe aufgenommen werden sollen. Wir werden diesen Indikator durch die Konstante SamplLatentStates definieren.
#define SamplLatentStates 32
Die nächste Frage lautet: Müssen wir wirklich einen vollständigen Vorwärtsdurchlauf durch das Kodierer-Modell (in unserem Fall Akteur) durchführen, um jeden latenten Zustand zu erfassen?
Es liegt auf der Hand, dass ohne Änderung der Ausgangsdaten und Modellparameter die Ergebnisse aller neuronalen Schichten bei jedem weiteren Durchlauf identisch sind. Der einzige Unterschied liegt in den Ergebnissen des stochastischen Knotens. Daher genügt uns ein direkter Durchlauf des Akteursmodells für jeden einzelnen Zustand. Als Nächstes wenden wir den Trick der Umparametrisierung der Verteilung an und nehmen die Anzahl der benötigten verborgenen Zustände. Ich denke, die Idee ist klar, und wir machen uns an die Umsetzung.
Zunächst wird eine Matrix von Zufallswerten aus einer Normalverteilung mit Mittelwert „0“ und Varianz „1“ erstellt. Solche Verteilungsindikatoren sind für die Umparametrisierung am besten geeignet.
float EntropyLatentState(CNet &net) { //--- random values double random[]; Math::MathRandomNormal(0,1,LatentCount * SamplLatentStates,random); matrix<float> states; states.Assign(random); states.Reshape(SamplLatentStates,LatentCount);
Anschließend laden wir die trainierten Verteilungsparameter aus unserem Akteursmodell, die in der vorletzten Encoder-Schicht gespeichert sind. Hier ist anzumerken, dass unser Modell einen Datenpuffer vorsieht, in dem nacheinander alle Mittelwerte der gelernten Verteilung gespeichert werden, gefolgt von allen Varianzen. Für die Durchführung von Matrixoperationen benötigen wir jedoch nicht einen Vektor, sondern zwei Matrizen mit doppelten Werten in den Zeilen. Hier werden wir einen kleinen Trick anwenden. Zunächst erstellen wir eine große Matrix mit der erforderlichen Anzahl von Zeilen und der doppelten Anzahl von Spalten, die mit Nullwerten gefüllt sind. In der ersten Zeile schreiben wir Daten aus dem Datenpuffer mit Verteilungsparametern. Dann werden wir die Funktion der kumulativen Summierung der Matrixwerte nach Spalten verwenden.
Der Trick besteht darin, dass alle Zeichenfolgen außer der ersten mit Nullen gefüllt werden. Bei der Durchführung der kumulativen Summenoperation werden die Daten der ersten Zeile einfach in alle nachfolgenden Zeilen kopiert.
Jetzt teilen wir die Matrix einfach vertikal in zwei gleiche auf und erhalten das Array der geteilten Matrizen. Sie enthält die Matrix der Durchschnittswerte mit dem Index 0. Die Varianzmatrix hat den Index 1.
//--- get means and std vector<float> temp; matrix<float> stats = matrix<float>::Zeros(SamplLatentStates,2 * LatentCount); net.GetLayerOutput(LatentLayer - 1,temp); stats.Row(temp,0); stats=stats.CumSum(0); matrix<float> split[]; stats.Vsplit(2,split);
Jetzt können wir ganz einfach Zufallswerte aus einer Normalverteilung neu parametrisieren und erhalten die Anzahl der benötigten Stichproben.
//--- calculate latent values states = states * split[1] + split[0];
Am unteren Ende der Matrix fügen wir eine Zeichenkette mit den aktuellen Encoder-Werten ein, die von den Akteuren und Kritikern während des Vorwärtsdurchlaufs als Eingabedaten verwendet werden.
//--- add current latent value net.GetLayerOutput(LatentLayer,temp); states.Resize(SamplLatentStates + 1,LatentCount); states.Row(temp,SamplLatentStates);
In diesem Stadium haben wir alle Daten, um die Kernel-Norm zu berechnen. Wir berechnen die Entropiekomponente der Belohnungsfunktion. Das Ergebnis wird an das aufrufende Programm zurückgegeben.
//--- calculate entropy states.SVD(split[0],split[1],temp); float result = temp.Sum() / (MathSqrt(MathPow(states,2.0f).Sum() * MathMax(SamplLatentStates + 1,LatentCount))); //--- return result; }
Die vorbereitenden Arbeiten sind abgeschlossen. Kommen wir nun zur Arbeit an EAs für die Interaktion mit der Umgebung und an Trainingsmodellen.
Die EAs für die Interaktion mit der Umgebung (Research.mq5 und Test.mq5) sind unverändert geblieben, und wir werden jetzt nicht näher auf sie eingehen. Der vollständige Code aller in diesem Artikel verwendeten Programme ist im Anhang verfügbar.
Gehen wir nun zum Modelltraining EA über und konzentrieren uns auf die Trainingsmethode Train. Zu Beginn der Methode wird die Gesamtgröße des Wiedergabepuffers für das Erlebnis bestimmt.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Dann werden wir alle vorhandenen Beispiele aus dem Erfahrungswiedergabepuffer mit einem zufälligen Faltungscodierer codieren. Dieser Prozess wurde vollständig von der vorherigen Implementierung übernommen.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); next.Assign(Buffer[tr].States[st + 1].rewards); rewards.Row(temp - next * DiscFactor,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
Nach Abschluss der Codierung aller Beispiele aus dem Erfahrungswiedergabepuffer entfernen wir die zusätzlichen Zeilen aus den Matrizen.
if(state != total_states)
{
rewards.Resize(state,NRewards);
state_embedding.Reshape(state,state_embedding.Cols());
total_states = state;
}
Als Nächstes folgt der Block des direkten Modelltrainings. Hier initialisieren wir lokale Variablen und erstellen eine Modell-Trainingsschleife. Die Anzahl der Iterationen der Schleife wird durch die externe Variable Iterations bestimmt.
vector<float> rewards1, rewards2; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Im Hauptteil der Schleife werden die Trajektorie und ein separater Zustand der Umgebung für die aktuelle Iteration der Aktualisierung der Modellparameter erfasst.
Anschließend prüfen wir den Schwellenwert für die Verwendung der Zielmodelle. Falls erforderlich, laden wir die nachfolgenden Zustandsdaten in die entsprechenden Datenpuffer.
target_reward = vector<float>::Zeros(NRewards); reward.Assign(Buffer[tr].States[i].rewards); //--- Target TargetState.AssignArray(Buffer[tr].States[i + 1].state); if(iter >= StartTargetIter) { float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
Die vorbereiteten Daten werden verwendet, um einen Vorwärtsdurchlauf der Zielmodelle des Akteurs und der beiden Kritiker durchzuführen.
if(!Actor.feedForward(GetPointer(TargetState), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Auf der Grundlage der Ergebnisse eines direkten Durchlaufs durch die Zielmodelle wird ein Vektor des nachfolgenden Zustandswertes erstellt. Außerdem wird eine Entropieschätzung des latenten Zustands nach dem SMAC-Algorithmus hinzugefügt.
TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; for(ulong r = 0; r < target_reward.Size(); r++) target_reward -= Buffer[tr].States[i + 1].rewards[r]; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
Nach der Vorbereitung des Kostenvektors des Folgezustands gehen wir zur Arbeit mit dem ausgewählten Umgebungszustand über und füllen die notwendigen Puffer mit den entsprechenden Quelldaten.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Dann führen wir einen Vorwärtsdurchlauf des Akteurs durch, um den latenten Zustand der Umgebung zu erzeugen.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
In der Phase der Aktualisierung der Parameter des Kritikers verwenden wir nur den latenten Zustand. Wir nehmen die Aktionen des Akteurs aus dem Erfahrungswiedergabepuffer und rufen den Vorwärtsdurchgang beider Kritiker auf.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Die Parameter der Kritiker werden unter Berücksichtigung der tatsächlichen Belohnung durch die Umgebung aktualisiert und an die aktuelle Politik des Akteurs angepasst. Die Wirkungsparameter der aktualisierten Politik des Akteurs sind bereits im Vektor der Kosten für den späteren Zustand der Umgebung berücksichtigt.
Ich möchte Sie daran erinnern, dass wir eine zerlegte Belohnungsfunktion anwenden und die Methode CAGrad verwenden, um die Gradienten zu optimieren. Daraus ergeben sich unterschiedliche Vektoren von Referenzwerten für jeden Kritiker. Zunächst bereiten wir einen Vektor von Referenzwerten vor und führen einen Rückwärtsdurchlauf durch den ersten Kritiker durch.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(reward + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Dann wiederholen wir die Vorgänge für den zweiten Kritiker.
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(reward + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Beachten Sie, dass wir nach der Aktualisierung der Parameter jedes Kritiker einen umgekehrten Durchlauf durchführen, um die Encoder-Parameter zu aktualisieren. Vergessen Sie auch nicht, den Prozess in jeder Phase zu kontrollieren.
Nach der Aktualisierung der Kritiker-Parameter gehen wir zur Optimierung des Akteursmodells über. Um den Fehlergradienten auf der Akteursebene zu bestimmen, verwenden wir Kritiker mit dem minimalen gleitenden Durchschnittsfehler bei der Vorhersage der Kosten von Akteurshandlungen. Mit diesem Ansatz erhalten wir möglicherweise eine genauere Schätzung der Aktionen, die durch die Politik des Akteurs ausgelöst werden, und folglich eine korrektere Verteilung des Fehlergradienten.
//--- Policy study CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
Wir haben die Vorwärtsdurchgänge des Akteurs bereits früher durchgeführt. Nun werden wir einen vorausschauenden Folgezustand der Umgebung formulieren. „Vorausschauend“ ist hier das Schlüsselwort. Schließlich enthält der Erfahrungswiedergabepuffer historische Daten über Kursbewegungen und Indikatoren. Sie hängen nicht von den Aktionen des Akteurs ab, sodass wir sie sicher verwenden können. Der Stand des Kontos hängt jedoch direkt von den Handelsgeschäften ab, die der Akteur durchführt. Die Aktionen in der aktuellen Richtlinie des Akteurs können sich von denen unterscheiden, die im Puffer für die Wiedergabe von Erfahrungen gespeichert sind. In diesem Stadium müssen wir einen Prognosevektor bilden, der den Zustand des Kontos beschreibt. Der Einfachheit halber wurde diese Funktionalität bereits in der Methode ForecastAccount implementiert, die im vorherigen Artikel behandelt wurde. Jetzt müssen wir sie nur noch mit der Übermittlung der richtigen Ausgangsdaten aufrufen.
Actor.getResults(rewards1); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,rewards1,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetState.AddArray(forecast);
Da wir nun alle erforderlichen Daten haben, führen wir einen Vorwärtsdurchlauf des ausgewählten Kritiker und des Random Convolutional Encoders durch, um die Einbettung des prädiktiven Folgezustands zu erzeugen.
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Convolution.feedForward(GetPointer(TargetState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Auf der Grundlage der gewonnenen Daten bilden wir einen Vektor von Referenzwerten der Belohnungsfunktion, um die Parameter des Akteurs zu aktualisieren. Außerdem stellen wir sicher, dass der Fehlergradient mit der Methode CAGrad korrigiert wird.
next.Assign(Buffer[tr].States[i + 1].rewards); Convolution.getResults(rewards1); target_reward += KNNReward(KNN,rewards1,state_embedding,rewards) + next * DiscFactor; if(forecast[3] == 0.0f && forecast[4] == 0.0f) target_reward[2] -= (Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance); critic.getResults(reward); reward += CAGrad(target_reward - reward);
Danach deaktivieren wir den Aktualisierungsmodus des Kritiker-Parameters und führen seinen Rückwärtsdurchlauf durch, gefolgt von einem vollständigen Rückwärtsdurchlauf des Akteurs.
Result.AssignArray(reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
Achten Sie darauf, den gesamten Prozess zu überwachen. Nach erfolgreichem Abschluss des umgekehrten Durchlaufs der beiden Modelle schalten wir den Kritiker wieder in den Trainingsmodus.
In diesem Stadium haben wir die Parameter für Kritiker und Akteur aktualisiert. Wir müssen lediglich die Parameter der Zielmodelle der Kritiker aktualisieren. Hier verwenden wir eine sanfte Aktualisierung der Modellparameter, wobei das Tau-Verhältnis in den externen EA-Parametern festgelegt wird.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau);
Am Ende der Operationen im Hauptteil des Modelltrainingszyklus informieren wir den Nutzer über den Fortschritt des Trainingsprozesses und fahren mit der nächsten Iteration der Schleife fort.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nachdem alle Iterationen des Modelltrainingszyklus erfolgreich abgeschlossen wurden, wird das Kommentarfeld im Chart gelöscht. Anzeige der Trainingsergebnisse im Journal und Einleitung der Beendigung des EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Sie haben vielleicht bemerkt, dass ich die Berechnung der Entropiekomponente des latenten Zustands, die von der SMAC-Methode beim Training des Akteurs bereitgestellt wird, übersprungen habe. Ich habe mich dafür entschieden, den Belohnungsvektor nicht in einzelne Teile zu zerlegen. Bei der Entwicklung des NNM-Algorithmus wurde dieser Prozess in eine separate Methode KNNReward verlagert. Mit dieser Methode habe ich die notwendigen Anpassungen vorgenommen.
Wie zuvor überprüfen wir zunächst die Übereinstimmung der Größen der prädiktiven Zustandseinbettung im Hauptteil der Methode und in der Matrix der Umgebungszustandseinbettungen aus dem Erfahrungswiedergabepuffer.
vector<float> KNNReward(ulong k, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards ) { if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return vector<float>::Zeros(0); }
Nach erfolgreicher Übergabe des Kontrollblocks initialisieren wir die erforderlichen lokalen Variablen.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); k = MathMin(k,states); ulong rew_size = rewards.Cols(); vector<float> distance = vector<float>::Zeros(states); matrix<float> k_rewards = matrix<float>::Zeros(k,rew_size); matrix<float> k_embeding = matrix<float>::Zeros(k + 1,size); matrix<float> U,V; vector<float> S;
Damit sind die vorbereitenden Arbeiten abgeschlossen und wir können direkt zu den Berechnungen übergehen. Zunächst bestimmen wir den Abstand zwischen dem vorhergesagten Zustand und den tatsächlichen Beispielen aus dem Erfahrungswiedergabepuffer.
for(ulong i = 0; i < size; i++) distance+=MathPow(state_embedding.Col(i) - embedding[i],2.0f); distance = MathSqrt(distance);
Definieren wir die k-ächsten Nachbarn und füllen die Einbettungsmatrix aus. Außerdem übertragen wir die entsprechenden Belohnungen in eine vorbereitete Matrix. Gleichzeitig passen wir den Belohnungsvektor in einem Verhältnis an, das umgekehrt zum Abstand zwischen den Zustandsvektoren ist. Das angegebene Verhältnis bestimmt den Einfluss der Belohnungen aus dem Erfahrungswiedergabepuffer auf das Ergebnis der ausgewählten Aktion des Akteurs in Übereinstimmung mit der aktualisierten Verhaltensrichtlinie.
for(ulong i = 0; i < k; i++) { ulong pos = distance.ArgMin(); k_rewards.Row(rewards.Row(pos) * (1 - MathLog(distance[pos] + 1)),i); k_embeding.Row(state_embedding.Row(pos),i); distance[pos] = FLT_MAX; }
Wir fügen die Einbettung des prädiktiven Zustands der Umgebung zur Einbettungsmatrix in der letzten Zeichenkette hinzu.
k_embeding.Row(embedding,k);
Ermittelung des Vektors der Singulärwerte der resultierenden Einbettungsmatrix. Diese Operation lässt sich leicht mit den integrierten Matrixoperationen durchführen.
k_embeding.SVD(U,V,S);
Wir bilden den Belohnungsvektor als den Durchschnitt der entsprechenden Belohnungen der k-ächsten Nachbarn, bereinigt um die Beteiligungsquote.
vector<float> result = k_rewards.Mean(0);
Die letzten beiden Elemente des Belohnungsvektors füllen wir mit der Entropiekomponente unter Verwendung der Kernel-Norm der Actor-Politik bzw. des latenten Zustands.
result[rew_size - 2] = S.Sum() / (MathSqrt(MathPow(k_embeding,2.0f).Sum() * MathMax(k + 1,size))); result[rew_size - 1] = EntropyLatentState(Actor); //--- return (result); }
Der erzeugte Belohnungsvektor wird an das aufrufende Programm zurückgegeben. Alle anderen EA-Methoden wurden ohne Änderungen übernommen.
Damit ist unsere Arbeit mit dem Modelltraining EA abgeschlossen. Der vollständige Code aller in diesem Artikel verwendeten Programme ist im Anhang verfügbar. Es ist Zeit für einen Test.
3. Test
Im praktischen Teil dieses Artikels haben wir viel Arbeit in die Implementierung der Stochastic Marginal Actor-Critic-Methode in den bereits implementierten NNM-Algorithmus EA gesteckt. Jetzt gehen wir zur Phase der Prüfung der geleisteten Arbeit über. Wie immer werden die Modelle auf EURUSD H1 trainiert und getestet. Die Parameter aller Indikatoren werden standardmäßig verwendet.
Es ist bereits September, also habe ich die Ausbildungszeit auf 7 Monate im Jahr 2023 verlängert. Wir werden das Modell anhand historischer Daten für August 2023 testen.
Ich habe bereits die Eigenschaften der NNM-Methode und das Fehlen von generierten Zuständen im Erfahrungswiedergabepuffer bei der Erstellung des Trainings-EA „...\NNM\Study.mq5“ erwähnt. Dann beschlossen wir, die Anzahl der Iterationen eines Trainingszyklus zu reduzieren. Wir werden die gleichen Ansätze wie bei den Ausbildungsmodellen beibehalten.
Ähnlich wie beim Trainingsprozess im vorigen Artikel reduzieren wir den Erfahrungswiedergabepuffer nicht als Ganzes. Aber gleichzeitig werden wir den Erfahrungswiedergabepuffer nach und nach füllen. In der ersten Iteration starten wir die Trainingsdatenerfassung EA für 100 Durchgänge. Bei dem angegebenen historischen Intervall ergibt dies bereits fast 360K Zustände für das Training von Modellen.
Nach der ersten Iteration des Modelltrainings ergänzen wir die Beispieldatenbank um weitere 50 Durchläufe. So füllen wir den Erfahrungswiedergabepuffer nach und nach mit neuen Zuständen, die den Handlungen des Akteurs im Rahmen der trainierten Politik entsprechen.
Wir wiederholen den Prozess des Trainings von Modellen und des Sammelns zusätzlicher Beispiele mehrere Male, bis das gewünschte Ergebnis des Trainings der Akteurspolitik erreicht ist.
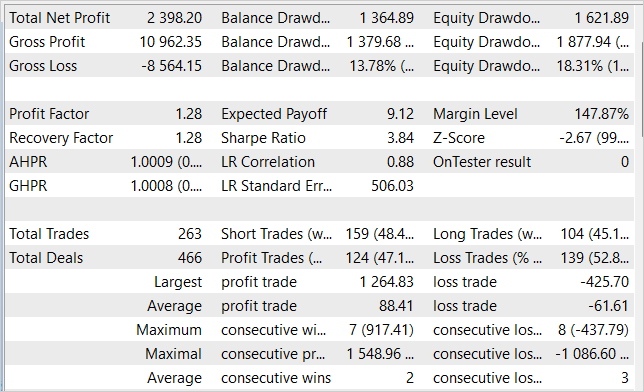
Während des Trainings der Modelle ist es uns gelungen, eine Akteurspolitik zu entwickeln, die in der Lage ist, aus der Trainingsstichprobe Gewinn zu erzielen und das erworbene Wissen für nachfolgende Umgebungszustände zu verallgemeinern. Im Strategietester konnte das von uns trainierte Modell beispielsweise innerhalb eines Monats nach der Trainingsstichprobe einen Gewinn von 23,98 % erzielen. Während des Testzeitraums führte das Modell 263 Handelsgeschäfte durch, von denen 47 % mit Gewinn abgeschlossen wurden. Der maximale Gewinn pro Handel ist fast dreimal so hoch wie der maximale Verlust pro Handel. Der durchschnittliche Gewinn pro Handel ist 44 % höher als der durchschnittliche Verlust. All dies zusammen ermöglichte es uns, einen Gewinnfaktor von 1,28 zu erhalten. Das Diagramm zeigt einen klaren Aufwärtstrend in der Saldenkurve.

Schlussfolgerung
Der Artikel befasst sich mit der Methode Stochastic Marginal Actor-Critic, die einen innovativen Ansatz zur Lösung von Verstärkungslernproblemen bietet. Basierend auf dem Prinzip der maximalen Entropie ermöglicht SMAC dem Agenten, die Umgebung effizienter zu erkunden und robuster zu lernen, was durch die Einführung eines zusätzlichen stochastischen latenten Variablenknotens erreicht wird.
Die Verwendung latenter Variablen in der Politik des Agenten erhöht die Aussagekraft und die Fähigkeit zur Modellierung von Stochastizität in Beobachtungen und Belohnungen erheblich.
Es gibt jedoch einige Schwierigkeiten bei Ausbildungsstrategien mit latenten Variablen. Die Autoren der Methode bieten Lösungen für die Bewältigung dieser Schwierigkeiten an.
Im praktischen Teil haben wir erfolgreich SMAC in die Architektur der NNM-Methode integriert und damit eine einfache und effektive Methode zur Optimierung von Richtlinien geschaffen, was durch Testergebnisse bestätigt wurde. Wir waren in der Lage, die Politik des Akteurs zu trainieren, die in der Lage ist, Renditen von bis zu 24 % pro Monat zu erzielen.
In Anbetracht dieser Ergebnisse ist die SMAC-Methode eine effektive Lösung für praktische Probleme.
Beachten Sie jedoch, dass alle in diesem Artikel vorgestellten Programme nur zur Demonstration der Methode erstellt wurden und nicht für die Arbeit mit echten Konten geeignet sind. Sie erfordern eine zusätzliche Konfiguration und Optimierung der Funktionalität.
Ich möchte Sie daran erinnern, dass die Finanzmärkte eine hochriskante Anlageform sind. Alle Risiken, die sich aus den von Ihnen oder Ihren elektronischen Handelsinstrumenten durchgeführten Transaktionen ergeben, liegen vollständig in Ihrer Verantwortung.
Links
- Latent State Marginalization as a Low-cost Approach for Improving Exploration
- Neuronale Netze leicht gemacht (Teil 56): Die Nuklearnorm als Antrieb für die Forschung nutzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Trainings-EA des Agenten |
| 3 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 6 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13290
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Jeder Durchlauf des Test EA erzeugt drastisch unterschiedliche Ergebnisse, als ob das Modell sich von allen vorherigen unterscheiden würde. Es ist offensichtlich, dass sich das Modell bei jedem einzelnen Durchlauf von Test weiterentwickelt, aber das Verhalten dieses EA ist kaum eine Weiterentwicklung.
Hier sind einige Bilder:
Dieses Modell verwendet die stochastische Politik des Akteurs. Zu Beginn der Studie können wir also bei jedem Durchgang zufällige Geschäfte sehen. Wir sammeln diese Durchgänge und beginnen erneut mit der Untersuchung des Modells. Und wiederholen diesen Prozess einige Male. Während der Akteur eine gute Politik der Aktionen findet.
Lassen Sie uns die Frage anders formulieren. Nachdem wir Proben gesammelt (Forschung) und verarbeitet (Studie) haben, führen wir das Testskript aus. In mehreren konskutiven Durchläufen, ohne Research oder Study, sind die Ergebnisse völlig unterschiedlich.
Das Testskript lädt ein trainiertes Modell im Unterprogramm OnInit (Zeile 99). Hier füttern wir den EA mit einem Modell, das sich während der Testverarbeitung nicht ändern sollte. Es sollte stabil sein, soweit ich das verstehe. Dann sollten sich auch die Endergebnisse nicht ändern.
In der Zwischenzeit führen wir kein Modelltraining durch. Durch den Test werden lediglich mehr Stichproben gesammelt.
Die Zufälligkeit wird eher im Modul Research und möglicherweise in der Study bei der Optimierung einer Strategie beobachtet.
Actor wird in Zeile 240 aufgerufen, um Feedforward-Ergebnisse zu berechnen. Wenn er bei der Erstellung nicht zufällig initialisiert wird, was meiner Meinung nach der Fall ist, sollte er sich nicht zufällig verhalten.
Finden Sie in der obigen Argumentation ein Missverständnis?
Lassen Sie uns die Frage anders formulieren. Nachdem wir Proben gesammelt (Forschung) und verarbeitet (Studie) haben, führen wir das Testskript aus. In mehreren konskutiven Durchläufen, ohne Forschung oder Studie, sind die Ergebnisse völlig unterschiedlich.
Das Testskript lädt ein trainiertes Modell in der Unterroutine OnInit (Zeile 99). Hier füttern wir den EA mit einem Modell, das sich während der Testverarbeitung nicht ändern sollte. Es sollte stabil sein, soweit ich das verstehe. Dann sollten sich auch die Endergebnisse nicht ändern.
In der Zwischenzeit führen wir kein Modelltraining durch. Der Test sammelt lediglich weitere Stichproben.
Die Zufälligkeit wird eher im Modul Forschung und möglicherweise in der Studie bei der Optimierung einer Strategie beobachtet.
Actor wird in Zeile 240 aufgerufen, um Feedforward-Ergebnisse zu berechnen. Wenn er bei der Erstellung nicht zufällig initialisiert wird, was meiner Meinung nach der Fall ist, sollte er sich nicht zufällig verhalten.
Finden Sie in der obigen Argumentation ein Missverständnis?
Der Akteur verwendet eine stochastische Politik. Wir implementieren sie mit VAE.
Die Schicht CNeuronVAEOCL verwendet die Daten der vorherigen Schicht als Mittelwert und STD der Gauß-Verteilung und entnimmt dieser Verteilung die gleiche Aktion. Zu Beginn setzen wir im Modell zufällige Gewichte ein. So werden zufällige Mittelwerte und STDs erzeugt. Am Ende haben wir zufällige Aktionen bei jedem Durchgang des Modelltests. Zum Zeitpunkt der Untersuchung wird das Modell einige Mittelwerte für jeden Zustand finden und die STD tendiert gegen Null.