Ciência de Dados e Aprendizado de Máquina (Parte 07): Regressão Polinomial

Índice:
- Introdução
- Revisão de polinômios
- Ordem dos polinômios
- Regressão polinomial
- Quando você deve usá-lo?
- Critério de Informação Bayesiano
- Encontrando os coeficientes do modelo
- Encontrando o melhor modelo
- Dimensionamento de recursos
- Prós e contras da regressão polinomial
- Pensamentos finais
Introdução
Ainda não terminamos com os modelos de regressão, voltamos a eles por um segundo. Como eu disse no primeiro artigo desta série a regressão linear básica serve de base para muitos modelos de aprendizado de máquina e hoje nós vamos discutir algo um pouco diferente da regressão linear, conhecida como regressão polinomial. O aprendizado de máquina mudou muito nosso mundo de várias maneiras, temos métodos diferentes para aprender os dados de treinamento para problemas de classificação e regressão, como regressão linear, regressão logística, máquina de vetores de suporte, regressão polinomial e muitas outras técnicas, alguns métodos paramétricos como regressão polinomial e máquinas de vetores de suporte se destacam por serem versáteis.
Eles criam limites simples para problemas simples e limites não lineares para problemas complexos

Revisão de polinômios
Um polinômio é qualquer expressão matemática que se pareça com isso;
Equação polinomial 01:
Temos nossos dados x, que são elevados a uma potência, assim como alguns coeficientes que são levados para dimensionar os nossos dados.
aqui está outro exemplo de regressão polinomial;
![]() Equação polinomial 02
Equação polinomial 02
5 corresponde a ao -7 corresponde a a1, 4 corresponde a a2, e11.3 corresponde a a3.
No polinômio, você não precisa necessariamente ter todos os termos x aqui, vamos ver esta equação;
![]() Equação polinomial 03
Equação polinomial 03
Você pode pensar nisso como a escrita
![]()
Ordem dos Polinômios
Existe outro conceito em polinômios chamado de ordem. A ordem do polinômio é denotada por n. Ele é o coeficiente mais alto na expressão matemática por exemplo:
- A equação polinomial 01 acima, é uma regressão polinomial de enésima ordem
- A equação polinomial 02 acima, é uma regressão polinomial de terceira ordem/grau
- A equação polinomial 03 acima, também é uma regressão polinomial de terceira ordem/grau
Algumas pessoas ficam confusas porque na segunda equação nós temos 3 variáveis multiplicadas por x e seus coeficientes estão em ordem crescente 1,2,3 enquanto na segunda equação nós temos apenas duas variáveis. Bem, a ordem do polinômio é determinada principalmente pelo maior coeficiente na expressão.
Regressão polinomial
A regressão polinomial é um dos algoritmos de aprendizado de máquina usados para fazer previsões, ouvi dizer que era amplamente usado para prever a taxa de propagação do COVID-19 e outras doenças infecciosas, vamos ver do que esse algoritmo é composto;Olhando para um modelo de regressão linear simples.

notou algo?
Esta regressão linear simples nada mais é do que uma regressão polinomial de primeira ordem, dependendo da regressão polinomial a ordem em que podemos adicionar variáveis a ela, por exemplo, uma regressão polinomial de segunda ordem ficaria assim;


O que aconteceu com as linearidades?
Eu não disse nos artigos anteriores que a regressão é toda sobre o modelo linear? Como nós podemos ajustar essa regressão polinomial às linearidades quando temos esses coeficientes de termos quadráticos.
Tudo se resume ao que precisa ser linear e o que pode ser não linear. Os coeficientes/Betas são todos lineares, são apenas os próprios dados que são elevados a potências mais altas.

Quando se deve usar a regressão polinomial?
Todos nós sabemos que o modelo linear básico não é bom para ajustar os dados ligeiramente complexos (não lineares) ou descobrir relacionamentos complexos no conjunto de dados. A regressão polinomial está aqui para resolver esse problema. Imagine tentar prever o preço da NASDAQ usando o preço das ações da APPLE, sendo a Apple um dos maiores influenciadores por trás do preço da NASDAQ, seu relacionamento ainda não é linear, então o modelo linear pode não ser capaz de ajustar nosso conjunto de dados ao ponto em que podemos confiar nele para a tomada de decisões preditivas futuras. Vamos ver como fica o gráfico desses dois símbolos no mesmo eixo criando um gráfico de dispersão para apresentar os valores dos preços.
Abaixo está a função para criar um gráfico de dispersão na plataforma, graças a CGraphics (Eu nunca soube que tal coisa era possível até o momento em que estava escrevendo este artigo)
bool ScatterPlot( string obj_name, vector &x, vector &y, string legend, string x_axis_label = "x-axis", string y_axis_label = "y-axis", color clr = clrDodgerBlue, bool points_fill = true ) { if (!graph.Create(0,obj_name,0,30,70,440,320)) { printf("Failed to Create graphical object on the Main chart Err = %d",GetLastError()); return(false); } ChartSetInteger(0,CHART_SHOW,ChartShow); double x_arr[], y_arr[]; pol_reg.vectortoArray(x,x_arr); pol_reg.vectortoArray(y,y_arr); CCurve *curve = graph.CurveAdd(x_arr,y_arr,clr,CURVE_POINTS); curve.PointsSize(10); curve.PointsFill(points_fill); curve.Name(legend); graph.XAxis().Name(x_axis_label); graph.XAxis().NameSize(10); graph.YAxis().Name(y_axis_label); graph.YAxis().NameSize(10); graph.FontSet("Lucida Console",10); graph.CurvePlotAll(); graph.Update(); delete(curve); return(true); }
string plot_name = "x vs y"; ObjectDelete(0,plot_name); ScatterPlot(plot_name,x_v,y_v,X_symbol,X_symbol,Y_symol,clrOrange);
Saída:
Você não pode negar o fato de que o modelo linear não funcionará bem nesse tipo de problema, então vamos tentar a regressão polinomial. Isso agora, isso levanta a questão de qual ordem se deve usar para fazer um modelo polinomial?
Gráfico da Nasdaq x Apple
Observando a expressão do modelo;

Como temos apenas uma variável independente, nós podemos trazê-la para qualquer potência que quisermos. Novamente, como sabemos a que potência devemos elevar essa variável independente, em outras palavras, como sabemos qual ordem o polinômio deve ter? Para entender isso, vamos primeiro entender algo chamado de Critério de informação Bayesiano denotado como BIC.
Critério de Informação Bayesiano
sua fórmula é dada abaixo,
BIC = n log(SSE) + k log (n)
n = número de pontos de dados
k = número de parâmetros
Mas antes de descobrirmos o melhor modelo, vamos criar uma regressão polinomial básica e ver o que a faz funcionar, a partir daí podemos prosseguir para encontrar a melhor ordem.
Encontrar os coeficientes do modelo.
Da equação,

Vamos resolver esta tarefa de regressão polinomial de segundo grau encontrando os valores de b0, b1 e b2.
Nós usamos o seguinte sistema de equações,

n = número de pontos de dados
Para calcular os valores, vamos usar este conjunto de dados simples.
| X | y |
|---|---|
| 3 | 2.5 |
| 4 | 3.2 |
| 5 | 3.8 |
| 6 | 6.5 |
| 7 | 11.5 |
Agora temos um conjunto de equações simultâneas para o nosso problema e o conjunto de dados simples para construir as coisas, você pode facilmente inserir os valores e encontrar os coeficientes em uma calculadora científica, Microsoft Excel ou algo que você preferir. Você irá obter os valores;
- b0 = 12.4285714
- b1= -5.5128571
- b2 = 0.7642857
Mas isso não é a nossa área aqui na MQL5, vamos descobrir como obter este resultado no Meta Editor a partir do conjunto da equação simultânea acima, vamos transformá-la na forma de matriz, agora ela se torna
 Figura da matriz polinomial
Figura da matriz polinomial
O resultado dessa multiplicação nos leva de volta à equação simultânea. então você sabe que estamos matematicamente corretos,
Agora vamos escrever algum código;
Classe de regressão polinomial:
class CPolynomialRegression { private: ulong m_degree; //depends on independent vars int n; //number of samples in the dataset vector x; vector y; matrix PolyNomialsXMatrix; //x matrix matrix PolynomialsYMatrix; //y matrix matrix Betas; double Betas_A[]; //coefficients of the model stored in Array void Poly_model(vector &Predictions,ulong degree); public: CPolynomialRegression(vector& x_vector,vector &y_vector,int degree=2); ~CPolynomialRegression(void); double RSS(vector &Pred); //sum of squared residuals void BIC(ulong k, vector &bic,int &best_degree); //Bayessian information Criterion void PolynomialRegressionfx(ulong degree, vector &Pred); double r_squared(vector &y,vector &y_predicted); void matrixtoArray(matrix &mat, double &Array[]); void vectortoArray(vector &v, double &Arr[]); void MinMaxScaler(vector &v); };
Nossa classe é basicamente simples e ela não possui código complicado de ler, a princípio caso alguma alteração seja feita, o código será atualizado nos arquivos anexados abaixo pois eu estou escrevendo este código no momento em que eu também estou escrevendo este post.
Da nossa expressão matricial na figura da imagem da matriz polinomial acima, nós podemos ver que temos muitos somatórios em cada ponto de dados elevado em seu próprio expoente, pois esse cálculo é solicitado para quase todos os elementos em nossa primeira matriz no lado direito do sinal de igual, abaixo está um código curto de exemplo sobre como fazê-lo.
vector c; vector x_pow; for (ulong i=0; i<PolynomialsYMatrix.Rows(); i++) for (ulong j=0; j<PolynomialsYMatrix.Cols(); j++) { if (i+j == 0) PolynomialsYMatrix[i][j] = y.Sum(); else { x_pow = MathPow(x,i); c = y*x_pow; //x vector elements are raised to the power i then the resulting vector is //Then multiplied to the vector of y values the output is stored in a vector c PolynomialsYMatrix[i][j] = c.Sum(); //Finally the sum of all the elements in a vector c is stored in the matrix of polynomials } }
Olhando para a Matrix no lado direito da Figura da imagem da matriz polinomial acima você também notará que temos a função Σxy e Σxy^2 agora esta é uma abordagem um pouco diferente, então vamos também ver o código de como fazer isso
double pow = 0; ZeroMemory(x_pow); for (ulong i=0,index = 0; i<PolyNomialsXMatrix.Rows(); i++) for (ulong j=0; j<PolyNomialsXMatrix.Cols(); j++, index++) { pow = (double)i+j; //The power corresponds to the access index of rows and cols i+j if (pow == 0) PolyNomialsXMatrix[i][j] = n; else { x_pow = MathPow(x,pow); //x_pow is a vector to store the x vector raised to a certain power PolyNomialsXMatrix[i][j] = x_pow.Sum(); //find the sum of the power vector } }
Agora que nós temos essas somas de linhas de códigos que provam ser de muita importância para a regressão polinomial, vamos prosseguir criando a Matrix que carregará esses valores assim como a segunda matriz da imagem da figura de matriz polinomial.
Começando com a matriz do lado esquerdo do sinal de igual.

ulong order_size = degree+1; PolyNomialsXMatrix.Resize(order_size,order_size); PolynomialsYMatrix.Resize(order_size,1); vector c; vector x_pow; for (ulong i=0; i<PolynomialsYMatrix.Rows(); i++) for (ulong j=0; j<PolynomialsYMatrix.Cols(); j++) { if (i+j == 0) PolynomialsYMatrix[i][j] = y.Sum(); else { x_pow = MathPow(x,i); c = y*x_pow; PolynomialsYMatrix[i][j] = c.Sum(); } } if (debug) Print("Polynomials y vector \n",PolynomialsYMatrix);
Apenas olhando como os elementos dentro da matriz foram organizados, nós sabemos que o primeiro elemento é apenas aquele que não é multiplicado pelos valores de x, todo o resto é multiplicado pelos valores de x elevados pelo índice de onde eles estão posicionados na matriz.
Mudando a matriz no ponto focal da equação
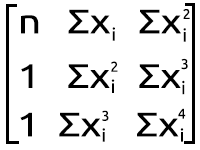
Minha primeira observação é que o tamanho do array Matrix é igual ao tamanho ao quadrado da matriz/ Matrix Y no lado esquerdo que acabamos de calcular anteriormente, também a potência à qual os itens x são elevados é baseada em onde o elemento está posicionado na matriz olhando para as linhas e colunas. Como esta matriz é quadrada, temos que construir fazendo um loop em suas colunas duas vezes de dois loops respectivos, veja o código abaixo.
ulong order_size = degree+1; PolyNomialsXMatrix.Resize(order_size,order_size); PolynomialsYMatrix.Resize(order_size,1); vector x_pow; //--- PolyNomialsXMatrix.Resize(order_size, order_size); double pow = 0; ZeroMemory(x_pow); //x_pow.Copy(x); for (ulong i=0,index = 0; i<PolyNomialsXMatrix.Rows(); i++) for (ulong j=0; j<PolyNomialsXMatrix.Cols(); j++, index++) { pow = (double)i+j; if (pow == 0) PolyNomialsXMatrix[i][j] = n; else { x_pow = MathPow(x,pow); PolyNomialsXMatrix[i][j] = x_pow.Sum(); } } //--- if (debug) Print("Polynomial x matrix\n",PolyNomialsXMatrix);
Abaixo está a saída dos trechos de código acima.
CS 0 02:10:15.429 polynomialReg test (#SP500,D1) Polynomials y vector CS 0 02:10:15.429 polynomialReg test (#SP500,D1) [[27.5] CS 0 02:10:15.429 polynomialReg test (#SP500,D1) [158.8] CS 0 02:10:15.429 polynomialReg test (#SP500,D1) [966.2]] CS 0 02:10:15.429 polynomialReg test (#SP500,D1) Polynomial x matrix CS 0 02:10:15.429 polynomialReg test (#SP500,D1) [[5,25,135] CS 0 02:10:15.429 polynomialReg test (#SP500,D1) [25,135,775] CS 0 02:10:15.429 polynomialReg test (#SP500,D1) [135,775,4659]]
Magnífico!!, Agora, é aqui que as coisas ficam complicadas. Para encontrar os valores da matriz desconhecida de valores Beta, temos que olhar para alguma matemática das matrizes.
Encontrando os valores desconhecidos da matriz multiplicada:

Seguimos o mesmo procedimento para as nossas matrizes que acabamos de obter os seus valores acima.

O processo de encontrar a inversa de uma matriz é relativamente simples e leva duas, senão uma linha de código usando a biblioteca padrão na matriz.
PolyNomialsXMatrix = PolyNomialsXMatrix.Inv();/ /encontra o inverso da matriz e atribui à matriz original Finalmente, para encontrar os coeficientes do modelo temos que multiplicar a matriz inversa pela matriz com os valores de y somados.
Betas = PolyNomialsXMatrix.MatMul(PolynomialsYMatrix);
Agora, é hora de imprimirmos a Matriz de Betas para ver o que ganhamos com esse processo;
CS 0 02:10:15.429 polynomialReg test (#SP500,D1) Betas CS 0 02:10:15.429 polynomialReg test (#SP500,D1) [[12.42857142857065] CS 0 02:10:15.429 polynomialReg test (#SP500,D1) [-5.512857142857115] CS 0 02:10:15.429 polynomialReg test (#SP500,D1) [0.7642857142856911]]
Ótimo, exatamente o que estávamos procurando. Agora que nós temos os coeficientes da regressão polinomial de 2º grau, vamos continuar construindo o modelo sobre eles.
void CPolynomialRegression::Poly_model(vector &Predictions, ulong degree) { ulong order_size = degree+1; Predictions.Resize(n); matrixtoArray(Betas,Betas_A); for (ulong i=0; i<(ulong)n; i++) { double sum = 0; for (ulong j=0; j<order_size; j++) { if (j == 0) sum += Betas_A[j]; else sum += Betas_A[j] * MathPow(x[i],j); } Predictions[i] = sum; } }
Por mais simples que o código do modelo possa parecer, ele pode lidar com quantos graus você quiser, pelo menos por enquanto. Vamos plotar as previsões do modelo no mesmo eixo dos valores x e y
ObjectDelete(0,plot_name); plot_name = "x vs y"; ScatterCurvePlots(plot_name,x_v,y_v,Predictions,"Predictions","x","y",clrDeepPink);
bool ScatterCurvePlots( string obj_name, vector &x, vector &y, vector &curveVector, string legend, string x_axis_label = "x-axis", string y_axis_label = "y-axis", color clr = clrDodgerBlue, bool points_fill = true ) { if (!graph.Create(0,obj_name,0,30,70,440,320)) { printf("Failed to Create graphical object on the Main chart Err = %d",GetLastError()); return(false); } ChartSetInteger(0,CHART_SHOW,ChartShow); //--- additional curves double x_arr[], y_arr[]; pol_reg.vectortoArray(x,x_arr); pol_reg.vectortoArray(y,y_arr); double curveArray[]; //curve matrix array pol_reg.vectortoArray(curveVector,curveArray); graph.CurveAdd(x_arr,y_arr,clrBlack,CURVE_POINTS,y_axis_label); graph.CurveAdd(x_arr,curveArray,clr,CURVE_POINTS_AND_LINES,legend); //--- graph.XAxis().Name(x_axis_label); graph.XAxis().NameSize(10); graph.YAxis().Name(y_axis_label); graph.YAxis().NameSize(10); graph.FontSet("Lucida Console",10); graph.CurvePlotAll(); graph.Update(); return(true); }
Saída:

É inegável que o modelo polinomial foi capaz de ajustar bem nossos dados e pode superar um modelo linear no ajuste dos dados neste caso.
Encontrando o Melhor Grau Polinomial
Como dito anteriormente que o Critério de Informação Bayesiano é o algoritmo que usamos para encontrar o melhor modelo. Vamos converter a fórmula em código. De acordo com o BIC o modelo com o menor valor de BIC é o melhor modelo porque ele é aquele com a menor soma de resíduos/erros.
void CPolynomialRegression::BIC(ulong k, vector &bic,int &best_degree) { vector Pred; bic.Resize(k-2); best_degree = 0; for (ulong i=2, counter = 0; i<k; i++) { PolynomialRegressionfx(i,Pred); bic[counter] = ( n * log(RSS(Pred)) ) + (i * log(n)); counter++; } //--- bool positive = false; for (ulong i=0; i<bic.Size(); i++) if (bic[i] > 0) { positive = true; break; } double low_bic = DBL_MAX; if (positive == true) for (ulong i=0; i<bic.Size(); i++) { if (bic[i] < low_bic && bic[i] > 0) low_bic = bic[i]; } else low_bic = bic.Min(); //bic[ best_degree = ArrayMinimum(bic) ]; printf("Best Polynomial Degree(s) is = %d with BIC = %.5f",best_degree = best_degree+2,low_bic); }
A partir do código a função RSS é Soma Residual dos Quadrados. Esta função encontra a soma dos resíduos quadrados.
double CPolynomialRegression::RSS(vector &Pred) { if (Pred.Size() != y.Size()) Print(__FUNCTION__," Predictions Array and Y matrix doesn't have the same size"); double sum =0; for (int i=0; i<(int)y.Size(); i++) sum += MathPow(y[i] - Pred[i],2); return(sum); }
Agora deixe-me executar esta função para encontrar o melhor polinômio entre os 10 graus.
vector bic_; //A vector to store the model BIC values for visualization purposes only int best_order; //A variable to store the best model order pol_reg.BIC(polynomia_degrees,bic_,best_order);
Abaixo está a saída quando plotada na plataforma;
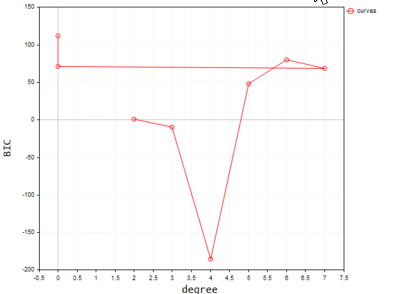
De acordo com o nosso código, o melhor modelo tem grau polinomial igual a 2. É inegável que o modelo com grau 2 é o melhor para este conjunto de dados simples.
2022.09.22 20:58:21.540 polynomialReg test (#NQ100,D1) Best Polynomial Degree(s) is = 2 with BIC = 0.93358
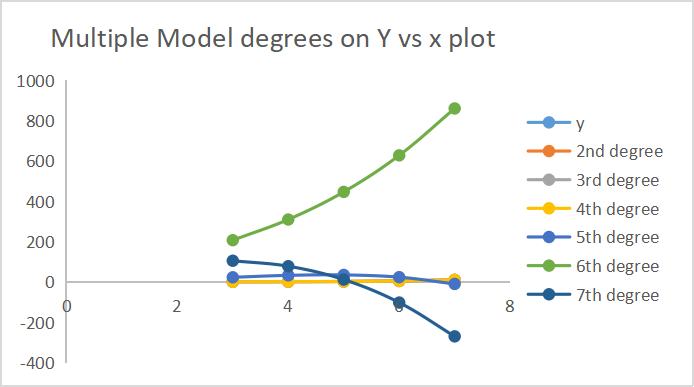
Abaixo está a saída de como cada modelo fez as previsões.

7 das saídas de grau são plotadas no mesmo eixo.
O dimensionamento de recursos é essencial
Como na regressão polinomial nós temos apenas uma variável independente que podemos elevar a qualquer potência, nós queremos escalar o recurso em primeiro lugar, torna-se muito importante porque se sua variável independente tiver recursos no intervalo de 100-1000 no segundo grau desses recursos variará entre 10000 - 1000000 no terceiro grau eles vão variar entre 10^6 - 10^9. OMG, isso é muito.
Existem muitas maneiras e algoritmos para dimensionar o conjunto de dados, mas vamos usar a função Min-max scaler para dimensionar os vetores. Lembre-se de que esse processo deve ser feito antes de qualquer manipulação no conjunto de dados. Abaixo está o código da função que será usada para dimensionar os vetores do conjunto de dados.
void MinMaxScaler(vector &v) { //Normalizing vector using Min-max scaler double min, max, mean; min = v.Min(); max = v.Max(); mean = v.Mean(); for (int i=0; i<(int)v.Size(); i++) v[i] = (v[i] - min) / (max - min); }
Agora temos tudo o que nós precisamos, é hora de construir o modelo nos dados do mercado ao vivo, consultando o Gráfico Nasdaq x Apple de cima. Para poder obter os resultados, existem algumas etapas que nós precisamos seguir.
Extração de dados de preços de mercado e dimensionamento.
if (!SymbolSelect(X_symbol,true)) printf("%s not found on Market watch Err = %d",X_symbol,GetLastError()); if (!SymbolSelect(Y_symol,true)) printf("%s not found on Market watch Err = %d",Y_symol,GetLastError()); matrix rates(bars, 2); vector price_close; //--- vector x_v, y_v; price_close.CopyRates(X_symbol,PERIOD_H1,COPY_RATES_CLOSE,1,bars); //extracting prices rates.Col(price_close,0); x_v.Copy(price_close); //--- price_close.CopyRates(Y_symol,PERIOD_H1,COPY_RATES_CLOSE,1,bars); y_v.Copy(price_close); rates.Col(price_close,1); //--- MinMaxScaler(x_v); //scalling all the close prices MinMaxScaler(y_v); //scalling all the close prices //---
Abaixo está a saída apresentada em um gráfico de dispersão;

02: Encontrando o Melhor Modelo Usando a Função Bic
//--- FINDING BEST MODEL USING BIC vector bic_; //A vector to store the model BIC values for visualization purposes only int best_order; //A variable to store the best model order pol_reg.BIC(polynomia_degrees,bic_,best_order); ulong bic_cols = polynomia_degrees-2; //2 is the first in the polynomial order //--- Plot BIc vs model degrees vector x_bic; x_bic.Resize(bic_cols); for (ulong i=2,counter =0; i<bic_cols; i++) { x_bic[counter] = (double)i; counter++; } ObjectDelete(0,plot_name); plot_name = "curves"; ScatterCurvePlots(plot_name,x_bic,y_v,bic_,"curves","degree","BIC",clrBlue); Sleep(10000);
Abaixo está a saída,

Por último
Agora sabemos que a melhor ordem do modelo é igual a 2. Vamos fazer um modelo com 2 graus e usá-lo para prever os valores e, finalmente, plotamos os valores no gráfico.
vector Predictions; pol_reg.PolynomialRegressionfx(best_order,Predictions); //Create model with the best order then use it to predict ObjectDelete(0,plot_name); plot_name = "Actual vs predictions"; ScatterCurvePlots(plot_name,x_v,y_v,Predictions,string(best_order)+"degree Predictons",X_symbol,Y_symol,clrDeepPink);
O gráfico resultante é mostrado abaixo,

Verificando a precisão do modelo
Apesar de encontrar o melhor grau para o modelo, ainda precisamos saber como esse modelo é capaz de entender o relacionamento em nosso conjunto de dados, verificando sua precisão preditiva.
Print("Model Accuracy = ",DoubleToString(pol_reg.r_squared(y,Predictions)*100,2),"%");
Saída,
2022.09.30 16:19:31.735 polynomialReg test (#SP500,D1) Model Accuracy = 2.36%
Más notícias para nós, temos o modelo ruim entre os piores modelos. Agora, antes de decidir usar uma regressão polinomial para resolver uma tarefa específica, lembre-se de que a regressão polinomial tem um modelo linear como base, portanto, sempre tenha os dados correlacionados. Não precisa ser linear correlacionado, mas cerca de 50% de correlação pode ser ideal, olhando para trás em nosso conjunto de dados NASDAQ vs APPLE e verificando sua correlação, obtive um coeficiente de correlação de menos de 1%. Esta é provavelmente a razão pela qual não conseguimos obter um bom modelo deste conjunto de dados.
Print("correlation coefficient ",x_v.CorrCoef(y_v));
Para demonstrar bem este ponto, vamos tentar o script em diferentes instrumentos de forex.
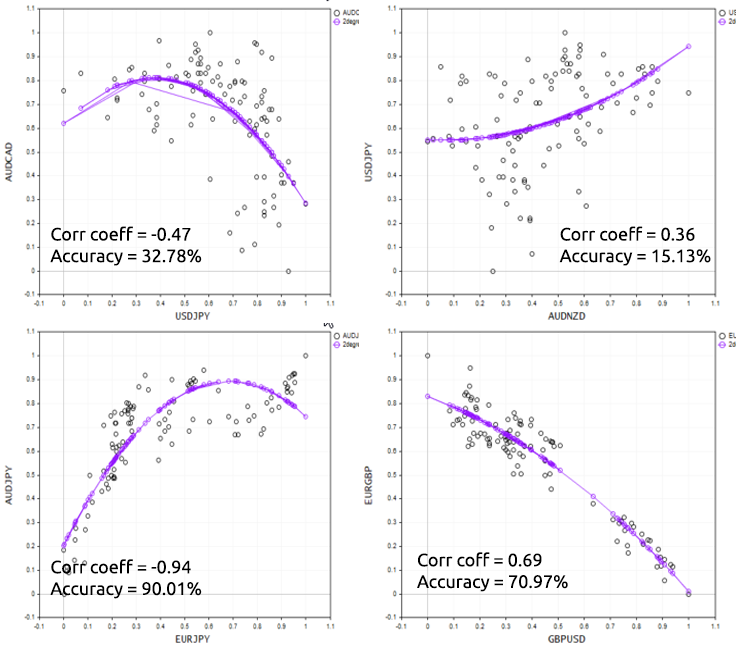
Prós e contras da regressão polinomial
Vantagens:
- Você pode modelar uma relação não linear entre as variáveis
- Há uma ampla gama de funções que você pode usar para ajustar
- Bom para fins exploratórios; Você pode testar diferentes ordens/graus polinomiais para ver qual funciona melhor para o conjunto de dados que você possui
- Ele é simples de desenvolver e interpretar os resultados, porém poderoso
Desvantagens:
- Outliers podem atrapalhar seriamente os resultados
- Os modelos de regressão polinomial são propensos a overfitting (dúvida sobre isso)
- Como consequência do overfitting, o modelo pode não funcionar com os dados externos
Pensamentos finais
A regressão polinomial é uma técnica útil de aprendizado de máquina em muitos casos, pois a relação entre uma variável independente e variáveis dependentes não devem ser linear, ela oferece mais liberdade ao trabalhar com diferentes conjuntos de dados e ajuda a preencher a lacuna que o modelo linear não pode, esta técnica é uma escolha melhor quando o modelo linear está subajustando (underfitting) os dados. Dito isto, é crucial que você fique ciente do overfitting porque, como esse modelo paramétrico é muito flexível, ele pode ter um desempenho muito ruim nos dados não treinados/dados de teste, eu diria para escolher as ordens de modelo mais baixas e dê ao modelo espaço para erros.
Obrigado por ler.
Mais informações sobre matrizes em forma de array, leia >> Matrizes e Vetores
Leitura adicional | Livros | Referências
- Neural Networks for Pattern Recognition (Advanced Texts in Econometrics)
- Neural Networks: Tricks of the Trade (Lecture Notes in Computer Science, 7700)
- Deep Learning (Adaptive Computation and Machine Learning series)
Referência dos artigos:
- Ciência de Dados e Aprendizado de Máquina (Parte 01): Regressão Linear
- Ciência de Dados e Aprendizado de Máquina (Parte 02): Regressão Logística
- Ciência de Dados e Aprendizado de Máquina (Parte 03): Regressões Matriciais
- Ciência de Dados e Aprendizado de Máquina (Parte 06): Gradiente Descendente
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/11477
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Perceptron Multicamadas e o Algoritmo Backpropagation (Parte 3): Integrando ao Testador de estratégias - Visão Geral (I)
Perceptron Multicamadas e o Algoritmo Backpropagation (Parte 3): Integrando ao Testador de estratégias - Visão Geral (I)
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso