
Ciência de dados e aprendizado de máquina (Parte 31): Aplicação de modelos CatBoost no trading

"CatBoost é uma biblioteca de gradient boosting que se destaca pelo processamento eficiente e escalável de características categóricas, proporcionando um aumento significativo de performance para várias tarefas práticas."
— Anthony Goldbloom.
O que é CatBoost?
CatBoost é uma biblioteca de código aberto que implementa algoritmos de gradient boosting sobre árvores de decisão. Foi desenvolvida especialmente para resolver tarefas relacionadas ao processamento de características categóricas e dados em problemas de aprendizado de máquina.
Desenvolvida pela empresa Yandex, a biblioteca foi disponibilizada como código aberto em 2017 (saiba mais).
Embora o CatBoost tenha surgido relativamente recentemente em comparação com outros métodos de aprendizado de máquina, como regressão linear ou SVM, a biblioteca rapidamente ganhou popularidade e se tornou um dos modelos mais usados em competições do Kaggle.
O CatBoost atraiu muita atenção por sua capacidade de processar automaticamente características categóricas em conjuntos de dados, algo bastante desafiador para muitos algoritmos de aprendizado de máquina.
- Os modelos CatBoost geralmente oferecem melhor desempenho em comparação com outros, exigindo um esforço mínimo. Mesmo com parâmetros e configurações padrão, esses modelos demonstram excelente precisão.
- Diferentemente das redes neurais, que exigem conhecimento aprofundado da área, o CatBoost é mais simples de implementar.

Este material assume que você já tem conhecimento básico sobre aprendizado de máquina, árvores de decisão, XGBoost, LightGBM e ONNX.
Como o CatBoost funciona?
O CatBoost é baseado no algoritmo de gradient boosting, o que o torna semelhante aos métodos Light Gradient Machine (LightGBM) e Extreme Gradient Boosting (XGBoost). Seu princípio de funcionamento está na construção sequencial de vários modelos baseados em árvores de decisão, onde cada novo modelo tenta corrigir os erros do anterior.
A previsão final é uma soma ponderada das previsões de todos os modelos envolvidos no processo.
O objetivo das árvores de decisão com gradient boosting é minimizar a função de perda. Para isso, é adicionada uma nova árvore ao modelo, que compensa os erros da anterior.
Processamento de características categóricas
Como mencionado no início do artigo, o CatBoost lida com características categóricas sem a necessidade de codificação manual, como one-hot ou label encoding, geralmente exigidas por outros modelos de aprendizado de máquina. Isso é possível graças ao mecanismo incorporado de codificação baseada no alvo (target-based encoding), que codifica as características categóricas utilizando informações da variável-alvo.
A essência disso é que, para cada valor único da característica categórica, é calculada a distribuição condicional da variável alvo.
Outra característica importante do CatBoost é o uso do chamado boosting ordenado (ordered boosting) para o cálculo das estatísticas das características categóricas. Nesse caso, a codificação de cada objeto de dados se baseia apenas nas informações obtidas dos objetos anteriores.
Essa abordagem ajuda a evitar perda de dados e sobreajuste.
Uso de estruturas simétricas de árvores de decisão
Ao contrário do LightGBM e do XGBoost, que utilizam árvores assimétricas, o CatBoost emprega árvores de decisão simétricas na construção dos modelos. Em uma árvore simétrica, ambos os ramos em cada divisão são formados de forma simétrica, usando a mesma regra de divisão. Essa abordagem oferece várias vantagens:
- Aprendizado mais rápido devido às divisões simétricas;
- Uso eficiente da memória graças à estrutura simplificada da árvore;
- As árvores simétricas são mais estáveis frente a pequenas variações nos dados.
Comparação entre CatBoost, XGBoost e LightGBM
Vamos entender como o CatBoost se diferencia de outras árvores de decisão com gradient boosting. Abaixo está uma tabela comparativa que ajudará a entender melhor qual opção é mais adequada para cada situação.
Características | CatBoost | LightGBM | XGBoost |
|---|---|---|---|
Processamento de características categóricas | Detecção automática e boosting ordenado para tratar variáveis categóricas. | Requer codificação prévia (por exemplo, one-hot encoding, label encoding etc.) | Requer codificação prévia (por exemplo, one-hot encoding, label encoding etc.) |
Estrutura da árvore de decisão | Árvores de decisão simétricas, que são balanceadas e crescem de forma uniforme. Oferecem previsões mais rápidas e menor risco de sobreajuste. | Crescimento por folhas (estrutura assimétrica), foca nas folhas com maior perda. Resulta em árvores profundas e desequilibradas, que podem ter mais precisão, mas aumentam o risco de sobreajuste. | Crescimento por níveis (estrutura assimétrica), onde a árvore cresce com base na melhor divisão para cada nó. Gera árvores flexíveis, porém com previsões mais lentas e risco potencial de sobreajuste. |
Precisão do modelo | Boa precisão ao trabalhar com conjuntos de dados com muitas variáveis categóricas, graças ao boosting ordenado e menor risco de sobreajuste em dados pequenos. | Oferecem boa precisão, especialmente para grandes conjuntos de dados e de alta dimensionalidade, sendo aplicados para melhorar desempenho em áreas com alta margem de erro. | Garantem boa precisão na maioria dos conjuntos de dados, mas geralmente perdem para o CatBoost em conjuntos categóricos e para o LightGBM em conjuntos muito grandes, devido a uma estratégia de crescimento de árvore menos agressiva. |
Velocidade e precisão no treinamento | Normalmente treinam mais devagar que o LightGBM, mas são mais eficientes em conjuntos pequenos e médios, especialmente ao lidar com características categóricas. | Geralmente o mais rápido entre os três métodos, especialmente ao trabalhar com grandes volumes de dados, graças ao crescimento por folhas, mais eficiente em dados multidimensionais. | O mais lento dos três. Eficiente para trabalhar com grandes volumes de dados. |
Implantação do modelo CatBoost
Antes de começarmos a trabalhar diretamente com o CatBoost, vamos definir o cenário da tarefa. Vamos gerar uma previsão de sinais de trading (compra/venda) com base nos dados Open, High, Low, Close, além de algumas características categóricas: data atual, dia da semana (de segunda a domingo), dia do ano (de 1 a 365) e mês (de janeiro a dezembro).
Os valores OHLC (abertura, máxima, mínima, fechamento) são características contínuas, enquanto os demais são categóricos. O script de coleta desses dados está anexado ao artigo.
Vamos começar importando o modelo CatBoost.
Instalação
Comando de terminal
pip install catboost
Importação.
Código Python
import numpy as np import pandas as pd import catboost from catboost import CatBoostClassifier from sklearn.pipeline import Pipeline from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report import seaborn as sns import matplotlib.pyplot as plt sns.set_style("darkgrid")
Para entender os dados, vamos visualizá-los.
df = pd.read_csv("/kaggle/input/ohlc-eurusd/EURUSD.OHLC.PERIOD_D1.csv")
df.head()Saída
| Open | High | Low | Close | Day | DayofWeek | DayofYear | Month | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 | 21.0 | 3.0 | 264.0 | 9.0 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 | 22.0 | 4.0 | 265.0 | 9.0 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 | 23.0 | 5.0 | 266.0 | 9.0 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 | 26.0 | 1.0 | 269.0 | 9.0 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 | 27.0 | 2.0 | 270.0 | 9.0 |
Durante a coleta dos dados no script em MQL5, obtive os valores de DayofWeek (de segunda a domingo) e Month (de janeiro a dezembro) como inteiros, e não como strings. Isso ocorreu porque os dados eram armazenados em uma matriz, e não é possível adicionar strings nela. Embora essas características sejam naturalmente categóricas. No formato atual, elas não são reconhecidas como categóricas, portanto vamos convertê-las de volta para dados categóricos e observar como o CatBoost lida com elas.
Preparar a variável alvo.
Código Python
new_df = df.copy() # Create a copy of the original DataFrame # we Shift the 'Close' and 'open' columns by one row to ge the future close and open price values, then we add these new columns to the dataset new_df["target_close"] = df["Close"].shift(-1) new_df["target_open"] = df["Open"].shift(-1) new_df = new_df.dropna() # Drop the rows with NaN values resulting from the shift operation open_values = new_df["target_open"] close_values = new_df["target_close"] target = [] for i in range(len(open_values)): if close_values[i] > open_values[i]: target.append(1) # buy signal else: target.append(0) # sell signal new_df["signal"] = target # we create the signal column and add the target variable we just prepared print(new_df.shape) new_df.head()
Saída
| Open | High | Low | Close | Day | DayofWeek | DayofYear | Month | target_close | target_open | signal | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 | 21.0 | 3.0 | 264.0 | 9.0 | 1.09399 | 1.09678 | 0 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 | 22.0 | 4.0 | 265.0 | 9.0 | 1.09805 | 1.09701 | 1 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 | 23.0 | 5.0 | 266.0 | 9.0 | 1.09742 | 1.09639 | 1 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 | 26.0 | 1.0 | 269.0 | 9.0 | 1.09757 | 1.10302 | 0 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 | 27.0 | 2.0 | 270.0 | 9.0 | 1.10297 | 1.10431 | 0 |
Então, entendemos os sinais que podemos prever. Agora vamos dividir os dados em conjuntos de treino e teste.
X = new_df.drop(columns = ["target_close", "target_open", "signal"]) # we drop future values y = new_df["signal"] # trading signals are the target variables we wanna predict X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42)
Definimos a lista de características categóricas do nosso conjunto de dados.
categorical_features = ["Day","DayofWeek", "DayofYear", "Month"]
Depois podemos usar essa lista para converter as características categóricas para o formato string, como geralmente são representadas as variáveis categóricas.
X_train[categorical_features] = X_train[categorical_features].astype(str) X_test[categorical_features] = X_test[categorical_features].astype(str) X_train.info() # we print the data types now
Saída
<class 'pandas.core.frame.DataFrame'> Index: 6999 entries, 9068 to 7270 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Open 6999 non-null float64 1 High 6999 non-null float64 2 Low 6999 non-null float64 3 Close 6999 non-null float64 4 Day 6999 non-null object 5 DayofWeek 6999 non-null object 6 DayofYear 6999 non-null object 7 Month 6999 non-null object dtypes: float64(4), object(4) memory usage: 492.1+ KB
Obtivemos variáveis categóricas com o tipo de dados object, que para nós isso é string. Se tentarmos aplicar esses dados em outro modelo de aprendizado de máquina (que não seja o CatBoost), vamos obter erros, pois o tipo object não é aceito em conjuntos de treinamento típicos para aprendizado de máquina.
Treinamento do modelo CatBoost
Antes de chamar o método fit para treinar o modelo CatBoost, vamos entender os parâmetros do modelo.
Parâmetro | Descrição |
|---|---|
Iterations | Número de iterações para construir as árvores de decisão. Um número maior geralmente melhora o desempenho, mas também aumenta o risco de sobreajuste. |
learning_rate | Controla a contribuição de cada árvore na previsão final. Valores menores exigem mais iterações para convergir, mas frequentemente resultam em modelos de maior qualidade. |
depth | Profundidade máxima das árvores. Árvores mais profundas conseguem capturar padrões mais complexos nos dados, mas tendem ao sobreajuste. |
cat_features | Lista de índices categóricos. Embora o CatBoost consiga identificar automaticamente os dados categóricos, é boa prática informar explicitamente quais são esses atributos. Isso ajuda o modelo a interpretar corretamente os dados categóricos do ponto de vista humano, já que os métodos automáticos podem falhar ocasionalmente. |
l2_leaf_reg | Coeficiente de regularização L2. Ajuda a combater o sobreajuste aplicando uma penalidade sobre os pesos elevados dos nós folha. |
border_count | Número de divisões para cada característica categórica. Quanto maior esse valor, melhor tende a ser a qualidade do modelo, mas o custo computacional também aumenta. |
eval_metric | Métrica de avaliação usada durante o treinamento. Permite monitorar o desempenho do modelo de forma eficiente. |
early_stopping_rounds | Se houver dados de validação, o treinamento será interrompido se não houver melhoria na precisão após o número definido de iterações. Esse parâmetro ajuda a reduzir o risco de sobreajuste e pode encurtar significativamente o tempo de treinamento. |
Vamos definir um dicionário com esses parâmetros.
params = dict( iterations=100, learning_rate=0.01, depth=10, l2_leaf_reg=5, bagging_temperature=1, border_count=64, # Number of splits for categorical features eval_metric='Logloss', random_seed=42, # Seed for reproducibility verbose=1, # Verbosity level # early_stopping_rounds=10 # Early stopping for validation )
Finalmente, podemos criar o modelo CatBoost dentro de um pipeline do Sklearn, e, em seguida, chamar o método fit para realizar o treinamento. Nos parâmetros do método, passaremos os dados de validação e a lista de características categóricas.
pipe = Pipeline([ ("catboost", CatBoostClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test), catboost__cat_features=categorical_features)
Resultados
90: learn: 0.6880592 test: 0.6936112 best: 0.6931239 (3) total: 523ms remaining: 51.7ms 91: learn: 0.6880397 test: 0.6936100 best: 0.6931239 (3) total: 529ms remaining: 46ms 92: learn: 0.6880350 test: 0.6936051 best: 0.6931239 (3) total: 532ms remaining: 40ms 93: learn: 0.6880280 test: 0.6936103 best: 0.6931239 (3) total: 535ms remaining: 34.1ms 94: learn: 0.6879448 test: 0.6936110 best: 0.6931239 (3) total: 541ms remaining: 28.5ms 95: learn: 0.6878328 test: 0.6936387 best: 0.6931239 (3) total: 547ms remaining: 22.8ms 96: learn: 0.6877888 test: 0.6936473 best: 0.6931239 (3) total: 553ms remaining: 17.1ms 97: learn: 0.6877408 test: 0.6936508 best: 0.6931239 (3) total: 559ms remaining: 11.4ms 98: learn: 0.6876611 test: 0.6936708 best: 0.6931239 (3) total: 565ms remaining: 5.71ms 99: learn: 0.6876230 test: 0.6936898 best: 0.6931239 (3) total: 571ms remaining: 0us bestTest = 0.6931239281 bestIteration = 3 Shrink model to first 4 iterations.
Avaliação do modelo
Para avaliar a performance do modelo, utilizaremos as métricas do Sklearn.
# Make predicitons on training and testing sets y_train_pred = pipe.predict(X_train) y_test_pred = pipe.predict(X_test) # Training set evaluation print("Training Set Classification Report:") print(classification_report(y_train, y_train_pred)) # Testing set evaluation print("\nTesting Set Classification Report:") print(classification_report(y_test, y_test_pred))
Resultados
Training Set Classification Report: precision recall f1-score support 0 0.55 0.44 0.49 3483 1 0.54 0.64 0.58 3516 accuracy 0.54 6999 macro avg 0.54 0.54 0.54 6999 weighted avg 0.54 0.54 0.54 6999 Testing Set Classification Report: precision recall f1-score support 0 0.53 0.41 0.46 1547 1 0.49 0.61 0.54 1453 accuracy 0.51 3000 macro avg 0.51 0.51 0.50 3000 weighted avg 0.51 0.51 0.50 3000
Como resultado, obtivemos um modelo com desempenho mediano. Notei que, ao remover a lista de características categóricas, a precisão do modelo no conjunto de treino aumentou para 60%, mas no conjunto de teste permaneceu no mesmo nível.
pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test))
Saída
91: learn: 0.6844878 test: 0.6933503 best: 0.6930500 (30) total: 395ms remaining: 34.3ms 92: learn: 0.6844035 test: 0.6933539 best: 0.6930500 (30) total: 399ms remaining: 30ms 93: learn: 0.6843241 test: 0.6933791 best: 0.6930500 (30) total: 404ms remaining: 25.8ms 94: learn: 0.6842277 test: 0.6933732 best: 0.6930500 (30) total: 408ms remaining: 21.5ms 95: learn: 0.6841427 test: 0.6933758 best: 0.6930500 (30) total: 412ms remaining: 17.2ms 96: learn: 0.6840422 test: 0.6933796 best: 0.6930500 (30) total: 416ms remaining: 12.9ms 97: learn: 0.6839896 test: 0.6933825 best: 0.6930500 (30) total: 420ms remaining: 8.58ms 98: learn: 0.6839040 test: 0.6934062 best: 0.6930500 (30) total: 425ms remaining: 4.29ms 99: learn: 0.6838397 test: 0.6934259 best: 0.6930500 (30) total: 429ms remaining: 0us bestTest = 0.6930499562 bestIteration = 30 Shrink model to first 31 iterations.
Training Set Classification Report: precision recall f1-score support 0 0.61 0.53 0.57 3483 1 0.59 0.67 0.63 3516 accuracy 0.60 6999 macro avg 0.60 0.60 0.60 6999 weighted avg 0.60 0.60 0.60 6999
Para entender melhor o funcionamento do modelo, vamos construir o gráfico de importância das características.
# Extract the trained CatBoostClassifier from the pipeline
catboost_model = pipe.named_steps['catboost']
# Get feature importances
feature_importances = catboost_model.get_feature_importance()
feature_im_df = pd.DataFrame({
"feature": X.columns,
"importance": feature_importances
})
feature_im_df = feature_im_df.sort_values(by="importance", ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(data = feature_im_df, x='importance', y='feature', palette="viridis")
plt.title("CatBoost feature importance")
plt.xlabel("Importance")
plt.ylabel("feature")
plt.show()Saída
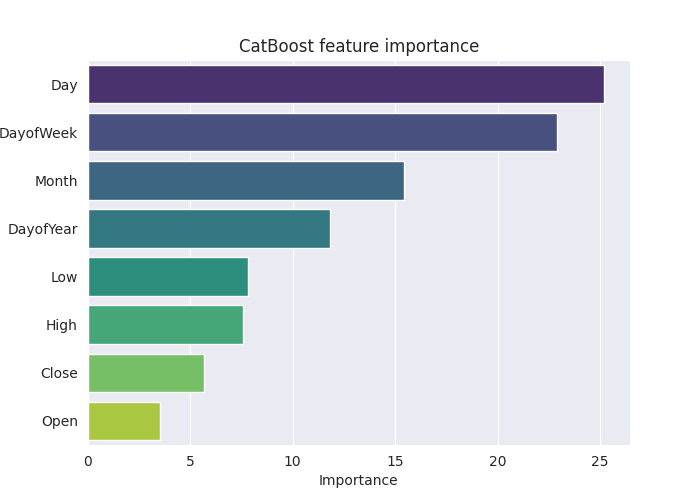
O gráfico de importância dos atributos acima ilustra claramente como o modelo tomou suas decisões. Parece que o CatBoost considerou as variáveis categóricas mais relevantes para a previsão final do que as variáveis contínuas.
Salvando o modelo CatBoost em ONNX
Para utilizar o modelo na plataforma MetaTrader 5, é necessário salvá-lo no formato ONNX. No entanto, salvar um modelo CatBoost pode ser um pouco mais trabalhoso do que com Sklearn ou Keras, que oferecem métodos de conversão mais diretos.
Mas tudo é perfeitamente possível se você seguir as instruções da documentação oficial. Não foi necessário mergulhar nos detalhes do código.
from onnx.helper import get_attribute_value import onnxruntime as rt from skl2onnx import convert_sklearn, update_registered_converter from skl2onnx.common.shape_calculator import ( calculate_linear_classifier_output_shapes, ) # noqa from skl2onnx.common.data_types import ( FloatTensorType, Int64TensorType, guess_tensor_type, ) from skl2onnx._parse import _apply_zipmap, _get_sklearn_operator_name from catboost import CatBoostClassifier from catboost.utils import convert_to_onnx_object def skl2onnx_parser_castboost_classifier(scope, model, inputs, custom_parsers=None): options = scope.get_options(model, dict(zipmap=True)) no_zipmap = isinstance(options["zipmap"], bool) and not options["zipmap"] alias = _get_sklearn_operator_name(type(model)) this_operator = scope.declare_local_operator(alias, model) this_operator.inputs = inputs label_variable = scope.declare_local_variable("label", Int64TensorType()) prob_dtype = guess_tensor_type(inputs[0].type) probability_tensor_variable = scope.declare_local_variable( "probabilities", prob_dtype ) this_operator.outputs.append(label_variable) this_operator.outputs.append(probability_tensor_variable) probability_tensor = this_operator.outputs if no_zipmap: return probability_tensor return _apply_zipmap( options["zipmap"], scope, model, inputs[0].type, probability_tensor ) def skl2onnx_convert_catboost(scope, operator, container): """ CatBoost returns an ONNX graph with a single node. This function adds it to the main graph. """ onx = convert_to_onnx_object(operator.raw_operator) opsets = {d.domain: d.version for d in onx.opset_import} if "" in opsets and opsets[""] >= container.target_opset: raise RuntimeError("CatBoost uses an opset more recent than the target one.") if len(onx.graph.initializer) > 0 or len(onx.graph.sparse_initializer) > 0: raise NotImplementedError( "CatBoost returns a model initializers. This option is not implemented yet." ) if ( len(onx.graph.node) not in (1, 2) or not onx.graph.node[0].op_type.startswith("TreeEnsemble") or (len(onx.graph.node) == 2 and onx.graph.node[1].op_type != "ZipMap") ): types = ", ".join(map(lambda n: n.op_type, onx.graph.node)) raise NotImplementedError( f"CatBoost returns {len(onx.graph.node)} != 1 (types={types}). " f"This option is not implemented yet." ) node = onx.graph.node[0] atts = {} for att in node.attribute: atts[att.name] = get_attribute_value(att) container.add_node( node.op_type, [operator.inputs[0].full_name], [operator.outputs[0].full_name, operator.outputs[1].full_name], op_domain=node.domain, op_version=opsets.get(node.domain, None), **atts, ) update_registered_converter( CatBoostClassifier, "CatBoostCatBoostClassifier", calculate_linear_classifier_output_shapes, skl2onnx_convert_catboost, parser=skl2onnx_parser_castboost_classifier, options={"nocl": [True, False], "zipmap": [True, False, "columns"]}, )
Abaixo está o código final para conversão do modelo e salvamento no arquivo .onnx.
model_onnx = convert_sklearn( pipe, "pipeline_catboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("CatBoost.EURUSD.OHLC.D1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Ao visualizar no Netron, a estrutura do modelo aparece da mesma forma que nos modelos do XGBoost e LightGBM.

Isso faz sentido, já que o CatBoost também é baseado em árvores de decisão com gradient boosting. Em essência, eles compartilham estruturas semelhantes.
Quando tentei converter um modelo CatBoost, integrado ao pipeline, para o formato ONNX com características categóricas, encontrei um erro:
CatBoostError: catboost/libs/model/model_export/model_exporter.cpp:96: ONNX-ML format export does yet not support categorical features
As características categóricas precisam ser representadas no formato float64 (double), como nos dados originalmente coletados no MetaTrader 5. Isso resolveu o problema. Assim, podemos usar o modelo no MQL5 sem preocupação de que valores double ou float sejam confundidos com inteiros.
categorical_features = ["Day","DayofWeek", "DayofYear", "Month"] # Remove these two lines of code operations # X_train[categorical_features] = X_train[categorical_features].astype(str) # X_test[categorical_features] = X_test[categorical_features].astype(str) X_train.info() # we print the data types now
Apesar dessa alteração, a precisão do modelo CatBoost permaneceu no mesmo nível, pois ele é capaz de trabalhar com conjuntos de dados de diferentes naturezas.
Criação de um robô de trading com CatBoost
Vamos começar incorporando o modelo ONNX no nosso EA na forma de recurso.
Código MQL5
#resource "\\Files\\CatBoost.EURUSD.OHLC.D1.onnx" as uchar catboost_onnx[]
We import the library for loading the CatBoost model.
#include <MALE5\Gradient Boosted Decision Trees(GBDTs)\CatBoost\CatBoost.mqh>
CCatBoost cat_boost;
É necessário coletar os dados da mesma maneira como fizemos durante o treinamento. Isso será feito dentro da função OnTick.
void OnTick() { ... ... ... if (CopyRates(Symbol(), timeframe, 1, 1, rates) < 0) //Copy information from the previous bar { printf("Failed to obtain OHLC price values error = ",GetLastError()); return; } MqlDateTime time_struct; string time = (string)datetime(rates[0].time); //converting the date from seconds to datetime then to string TimeToStruct((datetime)StringToTime(time), time_struct); //converting the time in string format to date then assigning it to a structure vector x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close, time_struct.day, time_struct.day_of_week, time_struct.day_of_year, time_struct.mon}; //input features from the previously closed bar ... ... ... }
Depois disso, podemos obter o sinal e o vetor de probabilidade. Vamos definir dois sinais: um sinal de baixa de classe 0 e um sinal de alta de classe 1.
vector proba = cat_boost.predict_proba(x); //predict the probability between the classes long signal = cat_boost.predict_bin(x); //predict the trading signal class Comment("Predicted Probability = ", proba,"\nSignal = ",signal);
Resta agora implementar no EA a estratégia de trading com base nas previsões obtidas pelo modelo.
Vamos usar a estratégia mais simples: quando o modelo prevê um sinal de alta, abrimos uma ordem de compra e, se houver uma ordem de venda aberta, fechamos essa venda. Quando houver sinal de baixa, faremos o inverso, isto é, vendemos e fechamos a compra.
void OnTick() { //--- if (!NewBar()) return; //--- Trade at the opening of each bar if (CopyRates(Symbol(), timeframe, 1, 1, rates) < 0) //Copy information from the previous bar { printf("Failed to obtain OHLC price values error = ",GetLastError()); return; } MqlDateTime time_struct; string time = (string)datetime(rates[0].time); //converting the date from seconds to datetime then to string TimeToStruct((datetime)StringToTime(time), time_struct); //converting the time in string format to date then assigning it to a structure vector x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close, time_struct.day, time_struct.day_of_week, time_struct.day_of_year, time_struct.mon}; //input features from the previously closed bar vector proba = cat_boost.predict_proba(x); //predict the probability between the classes long signal = cat_boost.predict_bin(x); //predict the trading signal class Comment("Predicted Probability = ", proba,"\nSignal = ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(min_lot, Symbol(), ticks.ask, 0, 0); //Open a buy trade ClosePosition(POSITION_TYPE_SELL); //close the opposite trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(min_lot, Symbol(), ticks.bid, 0, 0); //open a sell trade ClosePosition(POSITION_TYPE_BUY); //close the opposite trade } }
Testamos a estratégia no testador entre 01.01.2021 e 08.10.2024 no timeframe de 4 horas. O teste foi realizado apenas com preços de abertura. Abaixo está o resultado.
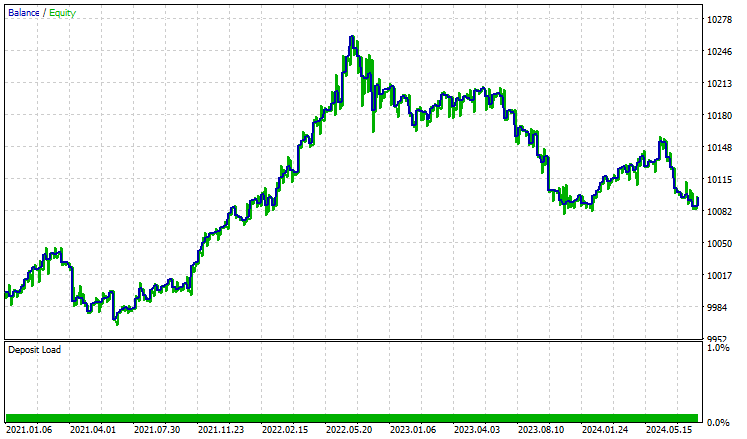
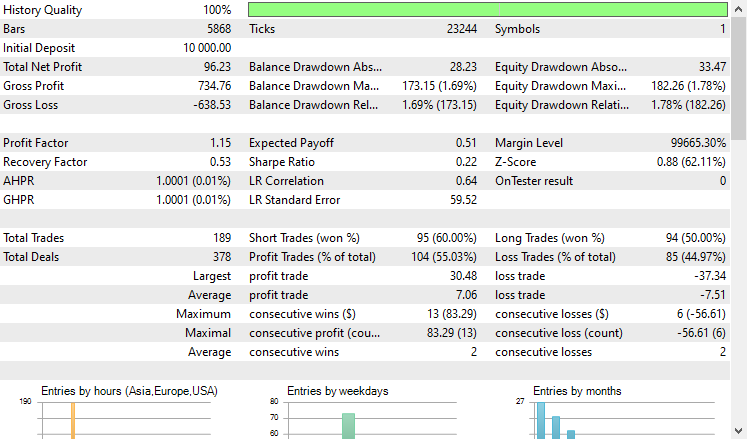
O EA obteve resultados respeitáveis, pois 55% das operações foram lucrativas, resultando em um lucro líquido total de 96 dólares americanos. Um bom resultado, considerando o conjunto de dados simples, o modelo básico e o volume mínimo de operações.
Considerações finais
CatBoost e outros modelos de gradient boosting com árvores de decisão são bastante adequados para uso em ambientes com recursos computacionais limitados. Também são uma ótima escolha quando se precisa de um modelo que "simplesmente funcione". Ou ainda, quando se quer evitar tarefas pouco atrativas como seleção de atributos e ajuste fino de modelos, frequentemente necessárias em outros métodos de aprendizado de máquina.
Apesar da simplicidade e da baixa barreira de entrada, esses modelos continuam entre as ferramentas mais eficazes aplicáveis a uma variedade de problemas reais.
Com os melhores cumprimentos.
Você pode acompanhar a evolução deste modelo de aprendizado de máquina e muito mais desta série de artigos no meu repositório no GitHub.
Tabela de anexos
Nome do arquivo | Tipo de arquivo | Descrição e uso |
|---|---|---|
Experts\CatBoost EA.mq5 | Expert | Robô de trading para carregar o modelo CatBoost em ONNX e testar a estratégia de trading resultante no MetaTrader 5. |
Include\CatBoost.mqh | Arquivo Include |
|
Files\CatBoost.EURUSD.OHLC.D1.onnx | Modelo ONNX | Modelo CatBoost treinado no formato ONNX. |
| Scripts\CollectData.mq5 | Script MQL5 | Script para coleta de dados de treinamento. |
Jupyter Notebook\CatBoost-4-trading.ipynb | Python/Jupyter notebook | O notebook contém todo o código em Python discutido neste artigo. |
Fontes e links
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/16017
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Corpo em Connexus (Parte 4): Adicionando suporte ao corpo de requisições HTTP
Corpo em Connexus (Parte 4): Adicionando suporte ao corpo de requisições HTTP
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
E há também o problema de exportar o modelo do classificador para o ONNX
Observação
O rótulo é inferido incorretamente para a classificação binária. Esse é um bug conhecido na implementação do onnxruntime. Ignore o valor desse parâmetro no caso de classificação binária.
Tenho uma pequena dúvida ou preocupação que gostaria de compartilhar.
Acredito que o problema subjacente possa estar relacionado ao que está descrito aqui:
https://catboost.ai/docs/en/concepts/apply-onnx-ml
Especificidades:
No momento, só há suporte para modelos treinados em conjuntos de dados sem recursos categóricos.
No Jupyter Notebook catboost-4-trading.ipynb que baixei, o código de ajuste do pipeline está escrito como:
pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test))
Parece que o parâmetro"catboost__cat_features=categorical_features" foi omitido, portanto, o modelo pode ter sido treinado sem especificar recursos categóricos.
Isso pode explicar por que o modelo pode ser salvo como ONNX sem nenhum problema.
Se esse for o caso, talvez o método nativo do CatBoost"save_model" possa ser usado diretamente, assim:
model = pipe.named_steps['catboost']
model_filename = "CatBoost.EURUSD.OHLC.D1.onnx"
model.save_model(model_filename, format='onnx')
Espero que essa observação possa ser útil.