Ciência de Dados e Aprendizado de Máquina (Parte 01): Regressão Linear

Introdução
A tentação de formar teorias prematuras sobre dados insuficientes é a ruína de nossa profissão.
"Sherlock Holmes"
Ciência de Dados
É um campo interdisciplinar que usa métodos, processos, algoritmos e sistemas científicos para extrair conhecimento e "insights" de dados ruidosos, estruturados e não estruturados e aplicar esse conhecimento e insights acionáveis de dados em uma ampla variedade de domínios de aplicações.
Um cientista de dados é alguém que cria códigos de programação e o combina com conhecimento estatístico para criar "insights" a partir dos dados.
O que esperar desta série de artigos?
- Teoria (como nas equações matemáticas): A teoria é mais importante na ciência de dados. Você precisa conhecer os algoritmos em profundidade e como um modelo se comporta e por que ele se comporta de uma determinada maneira, entender isso é muito mais difícil do que codificar o próprio algoritmo.
- Exemplos práticos em MQL5 e Python.
Regressão linear
É um modelo preditivo que é usado para encontrar a relação linear entre uma variável dependente e uma ou mais variáveis independentes.
A regressão linear é um dos principais algoritmos usados por muitos algoritmos, como:
- A regressão logística que é um modelo baseado em regressão linear
- Support Vector Machine, este famoso algoritmo em ciência de dados é baseado em um modelo linear
O que é um Modelo
Um modelo nada mais é que um sufixo.
Teoria
Toda reta que passa pelo gráfico tem uma equação
De onde tiramos essa equação?
Suponha que você tenha dois conjuntos de dados com os mesmos valores de x e y:
| x | y |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
Se traçarmos os valores no gráfico, obteremos o seguinte:
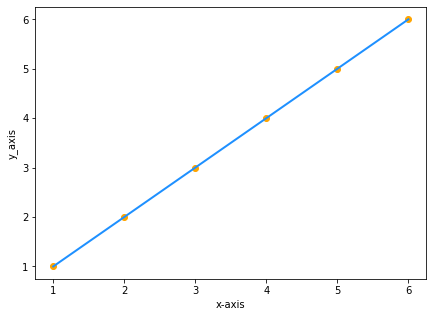
Como y é igual a x, a equação da nossa reta será y=x certo? ERRADO
no entanto,
y = x é matematicamente igual a y = 1x, isso é bem diferente em ciência de dados, a fórmula para a linha será y=1x, onde 1 é o ângulo formado entre a linha e o eixo x, também conhecido como a inclinação da reta
mas,
inclinação da reta = mudança em y /mudança em x = m(referido como m)
Nossa fórmula agora será y = mx.
Finalmente, nós precisamos adicionar uma constante à nossa equação, que é um valor de y quando x era zero em outras palavras, é o valor de y quando a linha cruza o eixo y
Finalmente,
nossa equação será y = mx + c (Isso não passa de um modelo em ciência de dados)
onde c é a interceptação em y
Regressão Linear Simples
A Regressão Linear Simples tem uma variável dependente e uma variável independente. Aqui, nós estamos tentando entender a relação entre duas variáveis, por exemplo, como o preço de uma ação muda com a mudança de uma média móvel simples.
Dados Complicados
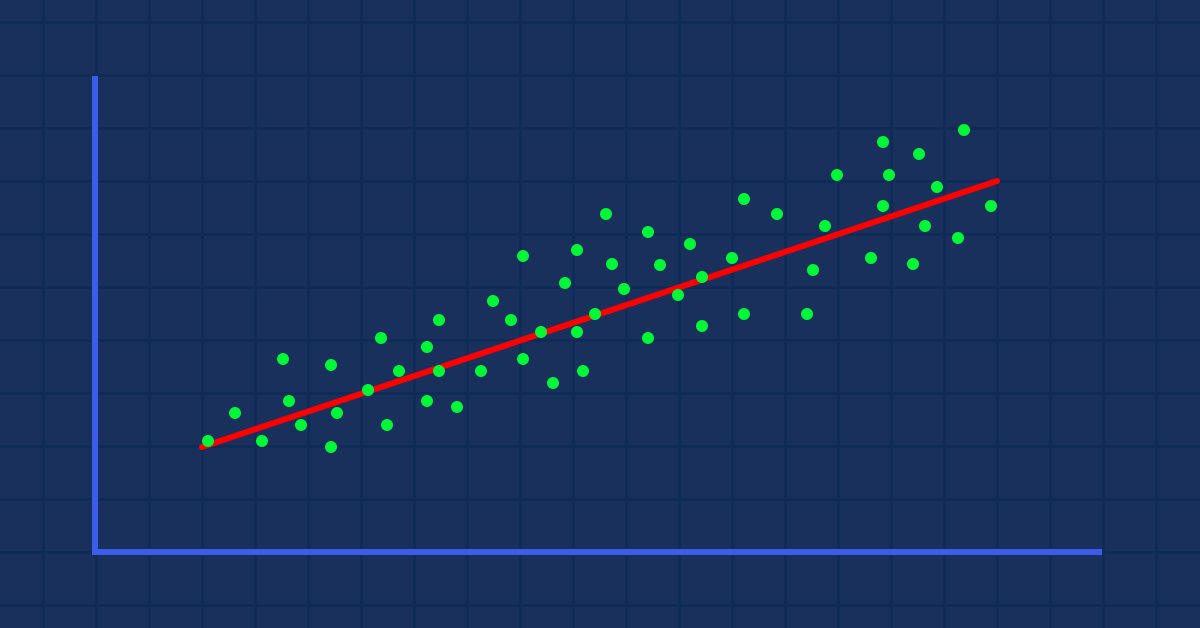
Suponha que nós temos valores dispersos e aleatórios de um indicador quando comparados ao preço da ação (algo que acontece na vida real).
")
Nesse caso, nosso Indicador/variável independente pode não ser um bom preditor do preço de nossa ação/variável dependente.
O primeiro filtro que você precisa aplicar no seu conjunto de dados é descartar todas as colunas que não se correlacionam fortemente com o seu objetivo, pois você não construirá seu modelo linear com elas.
Construir um modelo linear com dados relacionados não lineares é um grande erro fundamental; tome cuidado!
A relação pode ser inversa ou reversa, mas tem que ser forte e como estamos procurando relações lineares, é isso que você quer encontrar.

Então, como nós medimos a força entre a variável independente e o objetivo? Nós usamos uma métrica conhecida como o coeficiente de correlação.
Coeficiente de Correlação
Vamos codificar um script para criar um conjunto de dados a ser usado como exemplo principal para este artigo. Vamos encontrar os Preditores da NASDAQ.
input ENUM_TIMEFRAMES timeframe = PERIOD_H1; input int maperiod = 50; input int rsiperiod = 13; int total_data = 744; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string file_name = "NASDAQ_DATA.csv"; string nasdaq_symbol = "#NQ100", s_p500_symbol ="#SP500"; //--- int handle = FileOpen(file_name,FILE_CSV|FILE_READ|FILE_WRITE,","); if (handle == INVALID_HANDLE) { Print("data to work with is nowhere to be found Err=",GetLastError()); } //--- MqlRates nasdaq[]; ArraySetAsSeries(nasdaq,true); CopyRates(nasdaq_symbol,timeframe,1,total_data,nasdaq); //--- MqlRates s_p[]; ArraySetAsSeries(s_p,true); CopyRates(s_p500_symbol,timeframe,1,total_data,s_p); //--- Moving Average Data int ma_handle = iMA(nasdaq_symbol,timeframe,maperiod,0,MODE_SMA,PRICE_CLOSE); double ma_values[]; ArraySetAsSeries(ma_values,true); CopyBuffer(ma_handle,0,1,total_data,ma_values); //--- Rsi values data int rsi_handle = iRSI(nasdaq_symbol,timeframe,rsiperiod,PRICE_CLOSE); double rsi_values[]; ArraySetAsSeries(rsi_values,true); CopyBuffer(rsi_handle,0,1,total_data,rsi_values); //--- if (handle>0) { FileWrite(handle,"S&P500","NASDAQ","50SMA","13RSI"); for (int i=0; i<total_data; i++) { string str1 = DoubleToString(s_p[i].close,Digits()); string str2 = DoubleToString(nasdaq[i].close,Digits()); string str3 = DoubleToString(ma_values[i],Digits()); string str4 = DoubleToString(rsi_values[i],Digits()); FileWrite(handle,str1,str2,str3,str4); } } FileClose(handle); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+
No script, nós reunimos o preço de fechamento da NASDAQ, valores de RSI de 13 períodos, S&P 500 e média móvel de 50 períodos. Após uma coleta bem sucedida dos dados para um arquivo CSV, vamos visualizar os dados em python no Jupyter notebook da anaconda, para aqueles que não possuem o anaconda instalado em sua máquina, você pode executar seu código python de ciência de dados usado neste artigo no google colab.
Antes de poder abrir um arquivo CSV que foi criado por nosso script de teste, você precisa convertê-lo em codificação UTF-8 para que ele possa ser lido em python. Abra o arquivo CSV com o bloco de notas então salve-o codificando como UTF-8. Será bom copiar o arquivo no diretório externo para que ele seja lido separadamente em python quando você vincular a esse diretório, vamos ler o arquivo CSV usando o pandas e armazená-lo na variável de dados.


A saída é a seguinte:

A partir da apresentação visual dos dados, nós já podemos ver que há uma relação muito forte entre a NASDAQ e o S&P 500, e há uma forte relação entre a NASDAQ e sua média móvel de 50 períodos. Como dito anteriormente, sempre que os dados estão espalhados por todo o gráfico, a variável independente pode não ser um bom preditor do objetivo quando se trata de encontrar relações lineares, mas vamos ver o que os números falam sobre a sua correlação e tirar uma conclusão sobre os números em vez de nossa olhos, para descobrir como as variáveis se correlacionam, usaremos a métrica conhecida como coeficiente de correlação.
Coeficiente de correlação
É usado para medir a força entre a variável independente e o objetivo.
Existem vários tipos de coeficientes de correlação, mas nós usaremos este mais popular para a regressão linear que também é conhecido como coeficiente de correlação de Pearson (R) que varia entre -1 e +1.
Correlação de valores extremos possíveis de -1 e +1 indica uma relação linear negativa perfeita e linear positiva perfeita, respectivamente, entre x e y considerando que, uma correlação igual a 0 (zero) indica a ausência de correlação linear.
A fórmula do coeficiente de correlação/coeficiente de Pearson (R).

Eu criei a linearRegressionLib.mqh, vamos codificar a função corrcoef() dentro da nossa biblioteca principal.
Vamos começar com a função da média para os valores, mean é a soma de todos os dados dividido pelo número total de elementos.
double CSimpleLinearRegression::mean(double &data[]) { double x_y__bar=0; for (int i=0; i<ArraySize(data); i++) { x_y__bar += data[i]; // all values summation } x_y__bar = x_y__bar/ArraySize(data); //total value after summation divided by total number of elements return(x_y__bar); }Agora vamos codificar a correlação de Pearson
double CSimpleLinearRegression::corrcoef(double &x[],double &y[]) { double r=0; double numerator =0, denominator =0; double x__x =0, y__y=0; for(int i=0; i<ArraySize(x); i++) { numerator += (x[i]-mean(x))*(y[i]-mean(y)); x__x += MathPow((x[i]-mean(x)),2); //summation of x values minus it's mean squared y__y += MathPow((y[i]-mean(y)),2); //summation of y values minus it's mean squared } denominator = MathSqrt(x__x)*MathSqrt(y__y); //left x side of the equation squared times right side of the equation squared r = numerator/denominator; return(r); }
Para exibir o resultado em nosso TestSript.mq5
Print("Correlation Coefficient NASDAQ vs S&P 500 = ",lr.corrcoef(s_p,y_nasdaq)); Print("Correlation Coefficient NASDAQ vs 50SMA = ",lr.corrcoef(ma,y_nasdaq)); Print("Correlation Coefficient NASDAQ Vs rsi = ",lr.corrcoef(rsi,y_nasdaq));
a saída será
Correlation Coefficient NASDAQ vs S&P 500 = 0.9807093773142763
Correlation Coefficient NASDAQ vs 50SMA = 0.8746579124626006
Correlation Coefficient NASDAQ Vs rsi = 0.24245225451004537
Como você pode ver, a NASDAQ e o S&P500 têm uma correlação muito forte de todas as outras colunas de dados (porque seu coeficiente de correlação é muito próximo de 1), então nós temos que descartar outras colunas fracas ao prosseguir com a construção de nosso modelo de regressão linear simples.
Agora nós temos duas colunas de dados sobre as quais nós vamos construir o nosso modelo, vamos continuar construindo nosso modelo.
O coeficiente de X
O coeficiente de x, também conhecido como slope(m), é por definição a razão entre a variação de Y e a variação de X ou, em outras palavras, a inclinação da reta
Formula:
inclinação = Variação em Y / Variação em X
Lembre-se da Álgebra, que a inclinação da reta é o,m da fórmula
Y = M X + C
A fórmula para encontrar a inclinação da Regressão Linear m é,
Agora que nós vimos a fórmula, vamos codificar a inclinação da reta em nosso modelo.

double CSimpleLinearRegression::coefficient_of_X() { double m=0; double x_mean=mean(x_values); double y_mean=mean(y_values);; //--- { double x__x=0, y__y=0; double numerator=0, denominator=0; for (int i=0; i<(ArraySize(x_values)+ArraySize(y_values))/2; i++) { x__x = x_values[i] - x_mean; //right side of the numerator (x-side) y__y = y_values[i] - y_mean; //left side of the numerator (y-side) numerator += x__x * y__y; //summation of the product two sides of the numerator denominator += MathPow(x__x,2); } m = numerator/denominator; } return (m); }
Preste atenção para as matrizes y_values e x_values, estas são matrizes que foram iniciadas e copiadas dentro da função Init(), dentro da classe CSimpleLinearRegression.
Aqui está a função CSimpleLinearRegression::Init():
void CSimpleLinearRegression::Init(double& x[], double& y[]) { ArrayCopy(x_values,x); ArrayCopy(y_values,y); //--- if (ArraySize(x_values)!=ArraySize(y_values)) Print(" Two of your Arrays seems to vary In Size, This could lead to inaccurate calculations ",__FUNCTION__); int columns=0, columns_total=0; int rows=0; fileopen(); while (!FileIsEnding(m_handle)) { string data = FileReadString(m_handle); if (rows==0) { columns_total++; } columns++; if (FileIsLineEnding(m_handle)) { rows++; columns=0; } } m_rows = rows; m_columns = columns; FileClose(m_handle); //--- }
Nós já fizemos a codificação do Coeficiente de X agora vamos passar para a próxima parte.
Interceptação em Y
Como dito anteriormente, a interceptação em Y é o valor de y quando o valor de x for igual a zero, ou o valor de y quando a linha corta o eixo y.

Encontrando a interceptação em Y
Da equação
Y = M X + C
Tomando MX para o lado esquerdo da equação e invertendo a equação do lado esquerdo para a direita, a equação final para a interseção com x será
C = Y - M X
aqui,
Y = média de todos os valores de y
x = média de todos os valores de x
Agora, vamos codificar a função para encontrar a interceptação em y
double CSimpleLinearRegression::y_intercept() { // c = y - mx return (mean(y_values)-coefficient_of_X()*mean(x_values)); }
Terminamos com a interceptação em y, vamos construir nosso modelo de regressão linear exibiindo-o em nossa função principal LinearRegressionMain()
void CSimpleLinearRegression::LinearRegressionMain(double &predict_y[]) { double slope = coefficient_of_X(); double constant_y_intercept= y_intercept(); Print("The Linear Regression Model is "," Y =",DoubleToString(slope,2),"x+",DoubleToString(constant_y_intercept,2)); ArrayResize(predict_y,ArraySize(y_values)); for (int i=0; i<ArraySize(x_values); i++) predict_y[i] = coefficient_of_X()*x_values[i]+y_intercept(); //--- }
Nós também estamos usando o nosso modelo para obter os valores previstos de y, talvez, isso será útil no futuro, ao continuarmos a construir nosso modelo e a analisar sua precisão.
Vamos chamar a função na função Onstart() dentro do nosso TestScript.mq5.
lr.LinearRegressionMain(y_nasdaq_predicted);
A saída será
2022.03.03 10:41:35.888 TestScript (#SP500,H1) The Linear Regression Model is Y =4.35241x+-4818.54986
void CSimpleLinearRegression::GetDataToArray(double &array[],string file_name,string delimiter,int column_number) { m_filename = file_name; m_delimiter = delimiter; int column=0, columns_total=0; int rows=0; fileopen(); while (!FileIsEnding(m_handle)) { string data = FileReadString(m_handle); if (rows==0) { columns_total++; } column++; //Get data by each Column if (column==column_number) //if we are on the specific column that we want { ArrayResize(array,rows+1); if (rows==0) { if ((double(data))!=0) //Just in case the first line of our CSV column has a name of the column { array[rows]= NormalizeDouble((double)data,Digits()); } else { ArrayRemove(array,0,1); } } else { array[rows-1]= StringToDouble(data); } //Print("column ",column," "," Value ",(double)data); } //--- if (FileIsLineEnding(m_handle)) { rows++; column=0; } } FileClose(m_handle); }
Dentro da Função void fileopen()
void CSimpleLinearRegression::fileopen(void) { m_handle = FileOpen(m_filename,FILE_READ|FILE_WRITE|FILE_CSV,m_delimiter); if (m_handle==INVALID_HANDLE) { Print("Data to work with is nowhere to be found, Error = ",GetLastError()," ", __FUNCTION__); } //--- }
Agora dentro do nosso TestScript, a primeira coisa que temos que fazer é declarar duas matrizes
double s_p[]; //Array for storing S&P 500 values double y_nasdaq[]; //Array for storing NASDAQ values
A próxima coisa que nós temos que fazer é passar essas matrizes para obter sua referência da nossa função void GetDataToArray()
lr.GetDataToArray(s_p,file_name,",",1); lr.GetDataToArray(y_nasdaq,file_name,",",2);
Preste atenção aos números das colunas, pois nossos argumentos da função se parecem com isso na seção pública de nossa classe
void GetDataToArray(double& array[],string filename, string delimiter, int column_number);
Certifique-se de se referir ao número da coluna correta. Como você pode ver, é assim que as colunas são organizadas em nosso arquivo CSV
S&P500,NASDAQ,50SMA,13RSI 4377.5,14168.6,14121.1,59.3 4351.3,14053.2,14118.1,48.0 4342.6,14079.3,14117.0,50.9 4321.2,14038.1,14115.6,46.1 4331.8,14092.9,14114.6,52.5 4336.1,14110.2,14111.8,54.7 4331.5,14101.4,14109.4,53.8 4336.4,14096.8,14104.7,53.3 .....
Depois de chamar a função GetDataToArray(), é hora de chamar a função Init(), pois não faz sentido inicializar a biblioteca sem ter os dados devidamente coletados e armazenados em suas matrizes. Seue abaixo a chamada da função de maneira correta,
void OnStart() { string file_name = "NASDAQ_DATA.csv"; double s_p[]; double y_nasdaq[]; double y_nasdaq_predicted[]; lr.GetDataToArray(s_p,file_name,",",1); //Data is taken from the first column and gets stored in the s_p Array lr.GetDataToArray(y_nasdaq,file_name,",",2); //Data is taken from the second column and gets stored in the y_nasdaq Array //--- lr.Init(s_p,y_nasdaq); { lr.LinearRegressionMain(y_nasdaq_predicted); Print("slope of a line ",lr.coefficient_of_X()); } }
Agora que nós temos os valores previstos armazenados na matriz y_nasdaq_predicted Vamos visualizar a variável dependente (NASDAQ), a variável independente (S&P500) e as previsões na mesma curva.
Executamos o seguinte código no Jupyter notebook

A referência completa do código em python está anexada no final do artigo.
Depois de executar com sucesso o trecho de código acima, você verá o gráfico a seguir

Agora, nós temos o nosso modelo e outras coisas acontecendo em nossa biblioteca, e quanto à Precisão do nosso modelo? Nosso modelo é bom o suficiente para significar alguma coisa ou ser usado em qualquer coisa?
Para entender o quão bom nosso modelo é em prever a variável objetivo, nós usamos uma métrica conhecida como coeficiente de determinação referido como R-quadrado.
R-Quadrado
Esta é a proposição de variância total de y que foi explicada pelo modelo.
Para encontrar o r-quadrado, nós precisamos entender o erro na previsão. O erro na previsão é a diferença entre o valor atual/real de y e o valor previsto de y.

matematicamente,
Erro = Y real - Y previsto
A fórmula do R-quadrado é
Rsquared = 1 - (Soma total dos erros ao quadrado / Soma total dos resíduos ao quadrado)

Por que erros quadrados?
- Os erros podem ser positivos ou negativos (acima ou abaixo da linha) nós os elevamos ao quadrado para mantê-los positivos
- Os valores negativos podem diminuir o erro
- Nós também elevamos os erros ao quadrado para penalizar erros grandes para que possamos obter o melhor ajuste possível
Zero significa que o modelo não é capaz de explicar qualquer variação de y indicando que o modelo é o pior possível, o valor igual a Um indica que o modelo é capaz de explicar toda a variância de y em seu conjunto de dados (esse modelo não existe).
Você pode se referir à saída r-quadrado como a porcentagem de quão bom seu modelo é, um valor igual a zero significa zero precisão percentual e um valor igual a um significa que seu modelo é 100% preciso.
Agora vamos codificar o R-quadrado.
double CSimpleLinearRegression::r_squared() { double error=0; double numerator =0, denominator=0; double y_mean = mean(y_values); //--- if (ArraySize(m_ypredicted)==0) Print("The Predicted values Array seems to have no values, Call the main Simple Linear Regression Funtion before any use of this function = ",__FUNCTION__); else { for (int i=0; i<ArraySize(y_values); i++) { numerator += MathPow((y_values[i]-m_ypredicted[i]),2); denominator += MathPow((y_values[i]-y_mean),2); } error = 1 - (numerator/denominator); } return(error); }
Lembre-se que, dentro da nossa função LinearRegressionMain onde nós armazenamos os valores previstos na matriz previsto_a[], que foi passado por referência, temos que copiar essa matriz para uma matriz de variável global que foi declarado na seção privada de nossa classe.
private: int m_handle; string m_filename; string m_delimiter; double m_ypredicted[]; double x_values[]; double y_values[];
no final a nossa função LinearRegressionMain eu adicionei a linha para copiar essa matriz para uma matriz de variável global m_ypredicted[].
//At the end of the function LinearRegressionMain(double &predict_y[]) I added the following line, // Copy the predicted values to m_ypredicted[], to be Accessed inside the library ArrayCopy(m_ypredicted,predict_y);
Agora vamos imprimir o valor de R-quadrado dentro do nosso TestScript
Print(" R_SQUARED = ",lr.r_squared());
A saída será:
2022.03.03 10:40:53.413 TestScript (#SP500,H1) R_SQUARED = 0.9590906984145334
Isso é para a regressão linear simples, agora vamos ver como seria para uma regressão linear múltipla.
Regressão Linear Múltipla
A regressão linear múltipla tem uma variável independente e mais de uma variável dependente.
A fórmula para o modelo de regressão linear múltipla é a seguinte
É assim que a nossa biblioteca ficará depois de codificar as seções privada e pública de nossa classe.
class CMultipleLinearRegression: public CSimpleLinearRegression { private: int m_independent_vars; public: CMultipleLinearRegression(void); ~CMultipleLinearRegression(void); double coefficient_of_X(double& x_arr[],double& y_arr[]); void MultipleRegressionMain(double& predicted_y[],double& Y[],double& A[],double& B[]); double y_interceptforMultiple(double& Y[],double& A[],double& B[]); void MultipleRegressionMain(double& predicted_y[],double& Y[],double& A[],double& B[],double& C[],double& D[]); double y_interceptforMultiple(double& Y[],double& A[],double& B[],double& C[],double& D[]); };
Como nós lidaremos com vários valores, esta é a parte em que nós jogaremos com muitas matrizes de referência de argumentos de funções, eu não consegui encontrar um caminho mais curto de implementação.
Para criar o modelo de Regressão linear para duas variáveis dependentes, nós usaremos esta função.
void CMultipleLinearRegression::MultipleRegressionMain(double &predicted_y[],double &Y[],double &A[],double &B[]) { // Multiple regression formula = y = M1X1+M2X2+M3X3+...+C double constant_y_intercept=y_interceptforMultiple(Y,A,B); double slope1 = coefficient_of_X(A,Y); double slope2 = coefficient_of_X(B,Y); Print("Multiple Regression Model is ","Y="+DoubleToString(slope1,2)+"A+"+DoubleToString(slope2,2)+"B+"+ DoubleToString(constant_y_intercept,2)); int ArrSize = (ArraySize(A)+ArraySize(B))/2; ArrayResize(predicted_y,ArrSize); for (int i=0; i<ArrSize; i++) predicted_y[i] = slope1*A[i]+slope2*B[i]+constant_y_intercept; }
A interceptação em Y para esta instância será baseada no número de colunas de dados que nós decidimos trabalhar. Depois de derivar a fórmula da regressão linear múltipla, a fórmula final será:
C = Y - M1 X1 - M2 X2
É assim que ele fica depois de codificá-lo
double CMultipleLinearRegression::y_interceptforMultiple(double &Y[],double &A[],double &B[]) { //formula c=Y-M1X1-M2X2; return(mean(Y)-coefficient_of_X(A,Y)*mean(A)-coefficient_of_X(B,Y)*mean(B)); }
No caso de três variáveis, era apenas uma questão de codificar a função novamente e adicionar outra variável.
void CMultipleLinearRegression::MultipleRegressionMain(double &predicted_y[],double &Y[],double &A[],double &B[],double &C[],double &D[]) { double constant_y_intercept = y_interceptforMultiple(Y,A,B,C,D); double slope1 = coefficient_of_X(A,Y); double slope2 = coefficient_of_X(B,Y); double slope3 = coefficient_of_X(C,Y); double slope4 = coefficient_of_X(D,Y); //--- Print("Multiple Regression Model is ","Y="+DoubleToString(slope1,2),"A+"+DoubleToString(slope2,2)+"B+"+ DoubleToString(slope3,2)+"C"+DoubleToString(slope4,2)+"D"+DoubleToString(constant_y_intercept,2)); //--- int ArrSize = (ArraySize(A)+ArraySize(B))/2; ArrayResize(predicted_y,ArrSize); for (int i=0; i<ArrSize; i++) predicted_y[i] = slope1*A[i]+slope2*B[i]+slope3*C[i]+slope4*D[i]+constant_y_intercept; }
A interceptação da constante/Y para nossa regressão linear múltipla foi como eu disse que seria anteriormente.
double CMultipleLinearRegression::y_interceptforMultiple(double &Y[],double &A[],double &B[],double &C[],double &D[]) { return (mean(Y)-coefficient_of_X(A,Y)*mean(A)-coefficient_of_X(B,Y)*mean(B)-coefficient_of_X(C,Y)*mean(C)-coefficient_of_X(D,Y)*mean(D)); }
Suposições da Regressão Linear
O modelo de Regressão Linear é baseado em um conjunto de suposições, se o conjunto de dados subjacente não atender a essas suposições, os dados podem ter que ser transformados ou um modelo linear pode não ser um bom ajuste.
- Suposição de linearidade, assume uma relação linear entre a variável dependente/alvo e as variáveis independentes/preditoras
- Suposição de normalidade da distribuição de erros
- Os erros devem ser normalmente distribuídos junto com o modelo
- Um gráfico de dispersão entre os valores reais e os valores previstos deve mostrar os dados distribuídos igualmente pelo modelo
Vantagens de um modelo de Regressão Linear
Simples de implementar e mais fácil de interpretar as saídas e os coeficientes.
Desvantagens
- Assume uma relação linear entre as variáveis dependentes e independentes, ou seja, assume que existe uma relação linear entre elas
- "Outliers" têm um enorme efeito na regressão
- A Regressão Linear assume independência entre os atributos
- A Regressão Linear olha para uma relação entre a média da variável dependente e a variável independente
- Assim como a média não é uma descrição completa de uma única variável, a regressão linear não é uma descrição completa das relações entre as variáveis.
- Os limites são lineares
Pensamentos finais
Eu acho que os algoritmos de regressão linear podem ser muito úteis ao criar estratégias de negociação com base na correlação de pares e outras coisas como indicadores, embora nossa biblioteca não esteja nem perto de uma biblioteca finalizada, eu não incluí o treinamento e teste do nosso modelo e melhorias adicionais dos resultados, essa parte estará no próximo artigo, fique atento, eu tenho o código em python em meu repositório do Github aqui, qualquer contribuição para a biblioteca será apreciada, também se sinta à vontade para compartilhar sua opinião na seção de discussão do artigo.
Vejo você em breve
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/10459
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Desenvolvendo um EA de negociação do zero (Parte 22): Um novo sistema de ordens (V)
Desenvolvendo um EA de negociação do zero (Parte 22): Um novo sistema de ordens (V)
 Como desenvolver um sistema de negociação baseado no indicador RSI
Como desenvolver um sistema de negociação baseado no indicador RSI
 Como desenvolver um sistema de negociação baseado no indicador CCI
Como desenvolver um sistema de negociação baseado no indicador CCI
 Desenvolvendo um EA de negociação do zero (Parte 21): Um novo sistema de ordens (IV)
Desenvolvendo um EA de negociação do zero (Parte 21): Um novo sistema de ordens (IV)
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
What is a Model
Um modelo nada mais é do que um sufixo.
Um sufixo? Não entendo o que isso significa.
Antes de abrir um arquivo CSV criado pelo nosso script de teste, você precisa convertê-lo em codificação UTF-8 para que ele possa ser lido pelo python.
Por que isso acontece? Basta criar um arquivo de dados UTF-8 diretamente do MQL.
A elipse vermelha foi adicionada por mim. Isso está errado, esse ponto não é um "y-intercept" e suas coordenadas não são (0,-5).
Um sufixo? Não entendo o que isso significa.
Por que isso acontece? Basta criar um arquivo de dados UTF-8 diretamente do MQL.
Elipse vermelha adicionada por mim. Isso está errado, esse ponto não é um "y-intercept" e suas coordenadas não são (0,-5).
Com a palavra sufixo, estou me referindo a uma notação matemática, como y=mx+c, que é um modelo.
Sim, entendi, cometi um erro na imagem, o outro ponto deveria ser (-5,0) e não é um "y-intercept".
Olá, obrigado pelo artigo conciso sobre regressão linear e seus potenciais.
A fórmula do coeficiente de Peasson tem falhas no denominador.
Olá, talvez esteja lá, mas eu não o encontrei, mas onde está o arquivo NASDAQ.csv usado no artigo?