
Data Science e ML (Parte 30): O Casal Poderoso para Prever o Mercado de Ações, Redes Neurais Convolucionais (CNNs) e Redes Neurais Recorrentes (RNNs)

Conteúdo:
- Introdução
- Compreendendo RNNs e CNNs
- A sinergia entre CNNs e RNNs
- Extração de características com CNNs
- Modelagem temporal com RNNs
- Treinamento e obtenção de previsões
- Uma combinação de CNN e LSTM
- Uma combinação de CNN e GRU
- Conclusão
Introdução
Nos artigos anteriores, vimos o quão poderosas são tanto as Redes Neurais Convolucionais (CNNs) quanto as Redes Neurais Recorrentes (RNNs) e como podem ser empregadas para ajudar a superar o mercado, fornecendo sinais de negociação valiosos.
Neste, vamos tentar combinar duas das técnicas mais poderosas, CNN e RNN, e observar seu impacto preditivo no mercado de ações. Mas, antes disso, vamos entender brevemente do que se tratam CNN e RNN.
Entendendo as Redes Neurais Recorrentes (RNNs) e as Redes Neurais Convolucionais (CNNs)
Redes Neurais Convolucionais (CNNs) são projetadas para reconhecer padrões e características nos dados. Apesar de terem sido originalmente desenvolvidas para tarefas de reconhecimento de imagens, também se saem bem em dados tabulares especificamente preparados para previsão de séries temporais.
Como dito nos artigos anteriores, elas operam aplicando filtros aos dados de entrada e, em seguida, extraem características de alto nível que podem ser úteis para a predição. Em dados de mercado acionário, essas características incluem tendências, efeitos sazonais e anomalias.

Arquitetura de CNN
Aproveitando a natureza hierárquica das CNNs, podemos revelar camadas de representações dos dados, cada uma fornecendo insights sobre diferentes aspectos do mercado.
Redes Neurais Recorrentes (RNNs) são redes neurais artificiais projetadas para reconhecer padrões em sequências de dados, como séries temporais, linguagens ou vídeos.
Ao contrário das redes neurais tradicionais, que assumem que as entradas são independentes entre si, as RNNs conseguem detectar e compreender padrões a partir de uma sequência de dados (informações).
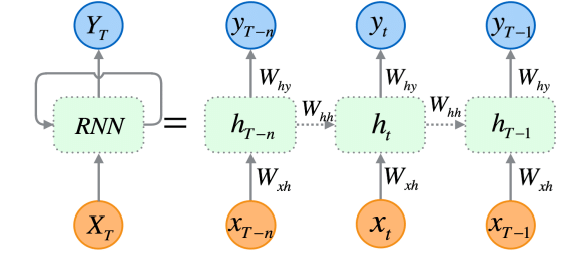
As RNNs são projetadas explicitamente para dados sequenciais. Sua arquitetura lhes permite manter uma memória das entradas anteriores, o que as torna muito adequadas para a previsão de séries temporais, pois são capazes de entender dependências temporais nos dados — algo crucial para fazer previsões precisas no mercado de ações.
Como expliquei na parte 25 desta série de artigos, existem três tipos específicos de RNNs (comumente usados), que incluem a RNN simples (vanilla), a Long Short-Term Memory (LSTM) e a Gated Recurrent Unit (GRU).
Como as CNNs se destacam em extrair e detectar características dos dados, as RNNs são excepcionais em interpretar essas características ao longo do tempo. A ideia é simples: combinar as duas e ver se conseguimos construir um modelo poderoso e robusto, capaz de fazer melhores previsões no mercado de ações.
A sinergia entre CNNs e RNNs
Para integrar as duas, vamos criar os modelos em três etapas.
- Extração de características com CNNs
- Modelagem temporal com RNNs
- Treinamento e Obtenção das Predições
Vamos passar por cada etapa e construir esse modelo robusto composto por RNN e LSTM.
01: Extração de Características com CNNs
Esta primeira etapa envolve alimentar os dados de série temporal em um modelo CNN; o modelo processa os dados, identificando padrões significativos e extraindo características relevantes.
Usando o conjunto de dados das ações da Tesla, que consiste em valores de Abertura, Máxima, Mínima e Fechamento. Vamos começar preparando os dados em um formato 3D de série temporal, aceitável por CNNs e RNNs.
Vamos criar a variável-alvo para um problema de classificação.
Código Python
target_var = [] open_price = new_df["Open"] close_price = new_df["Close"] for i in range(len(open_price)): if close_price[i] > open_price[i]: # Closing price is greater than opening price target_var.append(1) # buy signal else: target_var.append(0) # sell signal
Normalizamos os dados usando o StandardScaler para torná-los robustos para fins de ML.
X = new_df.iloc[:, :-1] y = target_var # Scalling the data scaler = StandardScaler() X = scaler.fit_transform(X) # Train-test split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) print(f"x_train = {X_train.shape} - x_test = {X_test.shape}\n\ny_train = {len(y_train)} - y_test = {len(y_test)}")
Saída:
x_train = (799, 3) - x_test = (200, 3) y_train = 799 - y_test = 200
Podemos então preparar os dados em formato de séries temporais.
# creating the sequence
X_train, y_train = create_sequences(X_train, y_train, time_step)
X_test, y_test = create_sequences(X_test, y_test, time_step) Como este é um problema de classificação, codificamos em one-hot a variável-alvo.
from tensorflow.keras.utils import to_categorical
y_train_encoded = to_categorical(y_train)
y_test_encoded = to_categorical(y_test)
print(f"One hot encoded\n\ny_train {y_train_encoded.shape}\ny_test {y_test_encoded.shape}") Saída:
One hot encoded y_train (794, 2) y_test (195, 2)
A extração de características é realizada pelo próprio modelo CNN. Vamos fornecer ao modelo os dados brutos que acabamos de preparar.
model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2))
02: Modelagem Temporal com RNNs
As características extraídas na etapa anterior são então passadas para o modelo RNN. O modelo processa essas características considerando a ordem temporal e as dependências presentes nos dados.
Diferentemente da arquitetura de CNN que usamos na parte 27 desta série de artigos, onde utilizamos camadas de rede neural totalmente conectadas (Fully Connected) logo após a camada Flatten. Desta vez, substituímos essas camadas tradicionais de Rede Neural (NN) por camadas de Rede Neural Recorrente (RNN).
Sem esquecer de remover a “camada Flatten” mostrada na imagem da arquitetura de CNN.
Removemos a camada Flatten na arquitetura da CNN porque ela é normalmente usada para converter uma entrada 3D em uma saída 2D, enquanto as RNNs (RNN, LSTM e GRU) esperam uma entrada 3D no formato (tamanho do lote, passos de tempo, características).
model.add(MaxPooling1D(pool_size=2)) model.add(SimpleRNN(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # Softmax for binary classification (1 buy, 0 sell signal)
03: Treinamento e Obtenção das Predições
Por fim, podemos prosseguir para treinar o modelo que construímos nas duas etapas anteriores; depois, validamos, medimos seu desempenho e então obtemos as previsões.
Código Python
model.summary()
# Compile the model
optimizer = Adam(learning_rate=0.0001)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
history = model.fit(X_train, y_train_encoded, epochs=1000, batch_size=16, validation_split=0.2, callbacks=[early_stopping])
plt.figure(figsize=(7.5, 6))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.legend()
plt.savefig("training loss curve-rnn-cnn-clf.png")
plt.show()
# Evaluating the Trained Model
y_pred = model.predict(X_test)
classes_in_y = np.unique(y)
y_pred_binary = classes_in_y[np.argmax(y_pred, axis=1)]
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix RNN + CNN.png") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary))
Saída:
Após avaliar o modelo após 14 épocas, o modelo apresentou 54% de acurácia nos dados de teste.

7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step Classification Report precision recall f1-score support 0 0.70 0.40 0.51 117 1 0.45 0.74 0.56 78 accuracy 0.54 195 macro avg 0.58 0.57 0.54 195 weighted avg 0.60 0.54 0.53 195
Vale mencionar que o treinamento do modelo final levou algum tempo quando mais camadas foram adicionadas; isso se deve à natureza complexa dos dois modelos que combinamos.
Após o treinamento, precisei salvar o modelo final no formato ONNX.
Código Python
onnx_file_name = "rnn+cnn.TSLA.D1.onnx" spec = (tf.TensorSpec((None, time_step, X_train.shape[2]), tf.float16, name="input"),) model.output_names = ['outputs'] onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13) # Save the ONNX model to a file with open(onnx_file_name, "wb") as f: f.write(onnx_model.SerializeToString())
Sem esquecer de salvar também os parâmetros do scaler de padronização.
# Save the mean and scale parameters to binary files scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin") scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
Abri o modelo ONNX salvo no Netron; é enorme.

Semelhante à forma como implantamos a Rede Neural Convolucional (CNN) antes, podemos usar a mesma biblioteca para nos ajudar na tarefa de ler esse modelo massivo com facilidade no MQL5.
#include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler; //from preprocessing.mqh
Mas, antes disso, precisamos adicionar o modelo ONNX e os parâmetros do scaler de padronização ao nosso Expert Advisor como recursos.
#resource "\\Files\\rnn+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[]
A primeira coisa que precisamos fazer dentro da função OnInit é inicializar ambos (o scaler de padronização e o modelo de CNN).
int OnInit() { //--- if (!cnn.Init(onnx_model)) //Initialize the Convolutional neural network return INIT_FAILED; scaler = new StandardizationScaler(standardization_mean, standardization_std); //Initialize the saved scaler by populating it with values ... ... return (INIT_SUCCEEDED); }
Para obter as previsões, precisamos normalizar os dados de entrada usando esse scaler pré-carregado; em seguida, aplicamos os dados normalizados ao modelo de CNN e obtemos o sinal previsto e as probabilidades.
if (NewBar()) //Trade at the opening of a new candle { CopyRates(Symbol(), PERIOD_D1, 1, time_step, rates); for (ulong i=0; i<x_data.Rows(); i++) { x_data[i][0] = rates[i].open; x_data[i][1] = rates[i].high; x_data[i][2] = rates[i].low; } //--- x_data = scaler.transform(x_data); //Normalize the data int signal = cnn.predict_bin(x_data, classes_in_data_); //getting a trading signal from the RNN model vector probabilities = cnn.predict_proba(x_data); //probability for each class Comment("Probability = ",probabilities,"\nSignal = ",signal);
Abaixo está como o comentário aparece no gráfico.

O vetor de probabilidades depende das classes presentes na variável-alvo dos seus dados de treinamento. Nos dados de treinamento, preparamos a variável-alvo para indicar 0 para um sinal de venda e 1 para um sinal de compra. Os identificadores ou números das classes devem estar em ordem crescente.
input int time_step = 5; input int magic_number = 24092024; input int slippage = 100; MqlRates rates[]; matrix x_data(time_step, 3); //3 columns for open, high and low vector classes_in_data_ = {0, 1}; //unique target variables as they are in the target variable in your training data int OldNumBars = 0; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //---
A matriz chamada x_data é a responsável pelo armazenamento temporário das variáveis independentes (features) do mercado. Essa matriz é redimensionada para 3 colunas, já que treinamos o modelo com 3 features (Abertura, Máxima e Mínima), e para um número de linhas igual ao valor do passo de tempo (time step).
O valor do passo de tempo deve ser semelhante ao utilizado na criação dos dados de treinamento sequenciais
Podemos montar uma estratégia simples com base nos sinais fornecidos pelo modelo que construímos.
double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { ClosePos(POSITION_TYPE_SELL); //close sell trades when the signal is buy if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions { if (!m_trade.Buy(min_lot, Symbol(), ticks.ask, 0 , 0)) //Open a buy trade printf("Failed to open a buy position err=%d",GetLastError()); } } else if (signal==0) //Bearish signal { ClosePos(POSITION_TYPE_BUY); //close all buy trades when the signal is sell if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions { if (!m_trade.Sell(min_lot, Symbol(), ticks.bid, 0 , 0)) //open a sell trade printf("Failed to open a sell position err=%d",GetLastError()); } } else //There was an error return;
Agora que temos o modelo carregado e pronto para gerar previsões, executei um teste de 2020.01.01 a 2024.09.01. Abaixo está a imagem com a configuração completa do testador.
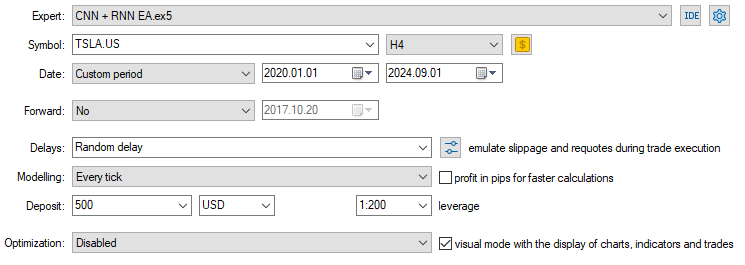
Observe que apliquei o EA em um gráfico de 4 horas, em vez do timeframe Diário a partir do qual os dados da ação da Tesla foram coletados. Isso porque programamos a estratégia e os modelos para entrarem em ação no instante em que uma nova vela é aberta, mas a vela diária normalmente abre quando o mercado está fechado, fazendo com que o EA perca operações até o dia seguinte.
Ao aplicar o EA a um timeframe menor (4 horas, neste caso), garantimos o monitoramento contínuo do mercado a cada 4 horas e a execução de algumas atividades de negociação.
Isso não afeta os dados fornecidos ao EA, pois aplicamos a função CopyRates no timeframe diário (as decisões de negociação ainda dependem do gráfico diário).
Abaixo está o resultado do Testador.
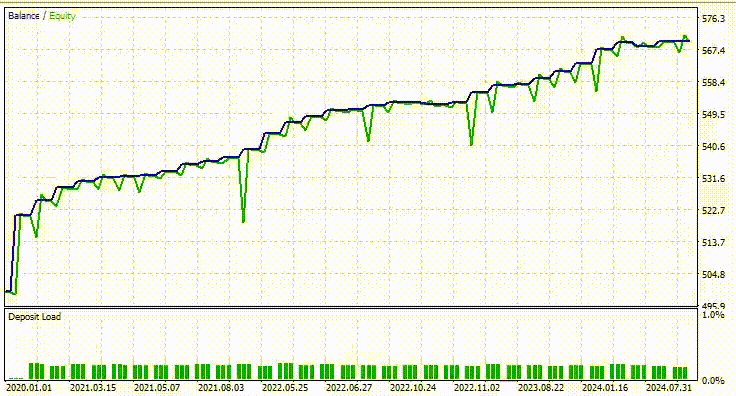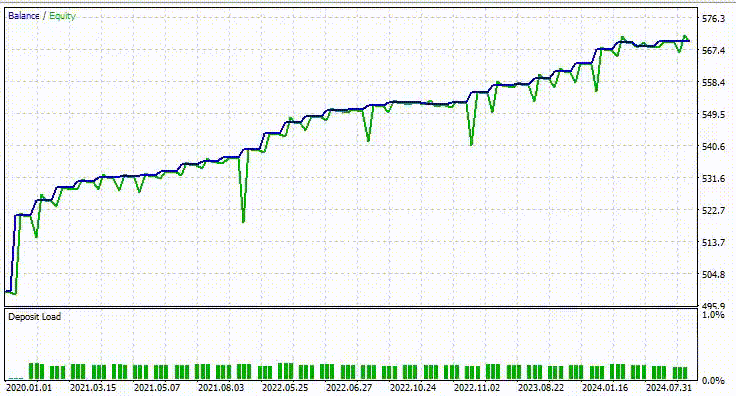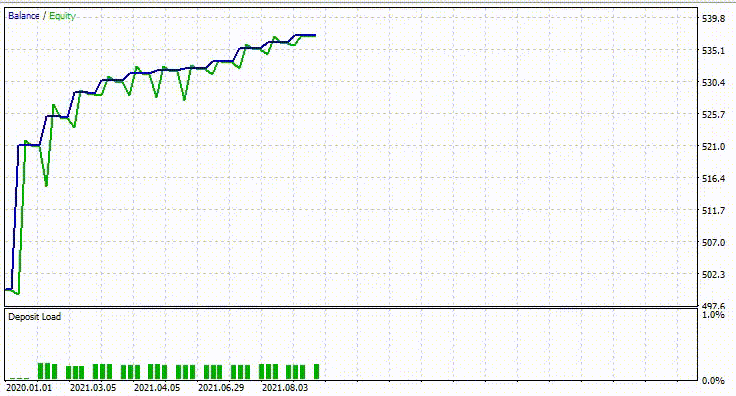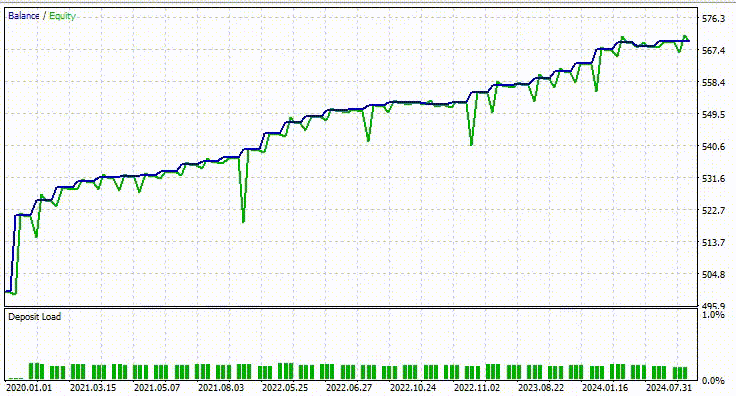
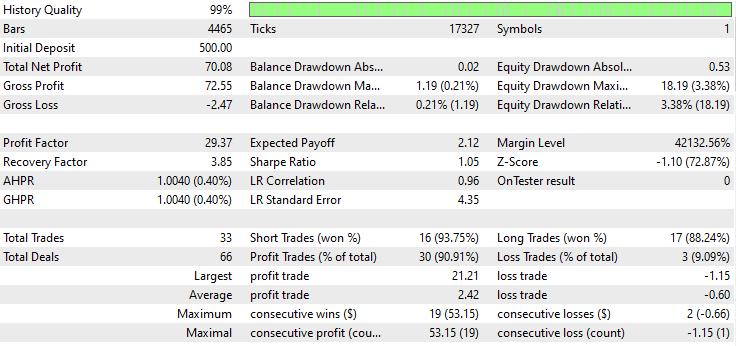
Impressionante! O EA produziu 90% de trades lucrativos. O modelo de IA era apenas uma RNN simples.
Agora vamos ver como LSTM e GRU se saem no mesmo mercado.
Uma combinação de Rede Neural Convolucional (CNN) e Long Short-Term Memory (LSTM)
Ao contrário da RNN simples, que tem dificuldade em entender padrões em sequências longas de dados ou informações, a LSTM consegue compreender relações e padrões em sequências longas.
As LSTMs costumam ser mais eficientes e precisas do que RNNs simples. Vamos criar um modelo de CNN com LSTM e, em seguida, observar como ele se comporta na ação da Tesla.
Código Python
from tensorflow.keras.layers import LSTM # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(LSTM(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
Como todas as RNNs podem ser implementadas da mesma forma, precisei fazer apenas uma alteração no bloco de código usado para criar uma RNN simples.
Após treinar e validar o modelo, sua acurácia foi de 53% nos dados de teste.
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 36ms/step Classification Report precision recall f1-score support 0 0.67 0.44 0.53 117 1 0.45 0.68 0.54 78 accuracy 0.53 195 macro avg 0.56 0.56 0.53 195 weighted avg 0.58 0.53 0.53 195
Na linguagem de programação MQL5, podemos usar a mesma biblioteca que utilizamos no EA de RNN simples.
#resource "\\Files\\lstm+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
O restante do código é mantido igual ao do EA de CNN + RNN.
Usei as mesmas configurações do Testador de antes; abaixo estava o resultado.
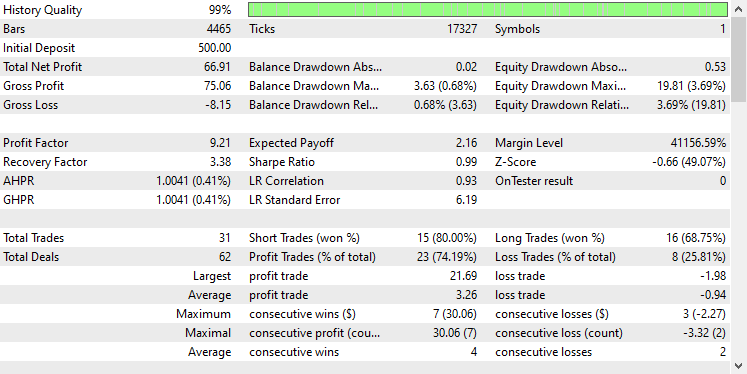
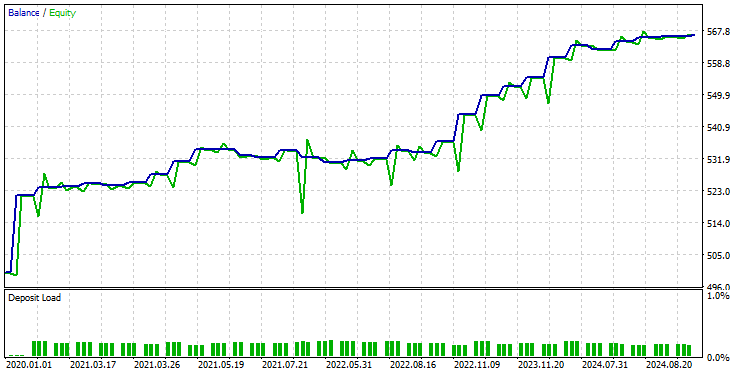
Desta vez, a acurácia geral dos trades é de aproximadamente 74%. É menor do que a que obtivemos no modelo anterior, mas ainda assim excelente!
Uma combinação de Rede Neural Convolucional (CNN) e Gated Recurrent Unit (GRU)
Assim como a LSTM, os modelos GRU também são capazes de entender as relações entre longas sequências de informações e dados, apesar de terem uma abordagem mais minimalista em comparação à do modelo LSTM.
Podemos implementá-lo da mesma forma que outros modelos RNN; apenas fazemos a alteração no tipo de modelo no código de construção da arquitetura da CNN.
from tensorflow.keras.layers import GRU # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(GRU(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
Após treinar e validar o modelo, ele atingiu uma acurácia semelhante à da LSTM: 53% de acurácia nos dados de teste.
7/7 ━━━━━━━━━━━━━━━━━━━━ 1s 41ms/step Classification Report precision recall f1-score support 0 0.69 0.39 0.50 117 1 0.45 0.73 0.55 78 accuracy 0.53 195 macro avg 0.57 0.56 0.53 195 weighted avg 0.59 0.53 0.52 195
Carregamos o modelo GRU em formato ONNX e seus parâmetros do scaler em arquivos binários.
#resource "\\Files\\gru+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
Novamente, o restante do código é o mesmo usado no EA de RNN simples.
Depois de testar o modelo no Testador usando as mesmas configurações, abaixo estava o resultado.
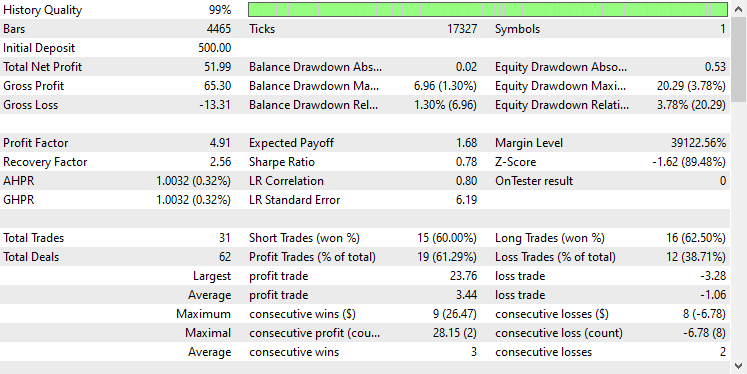
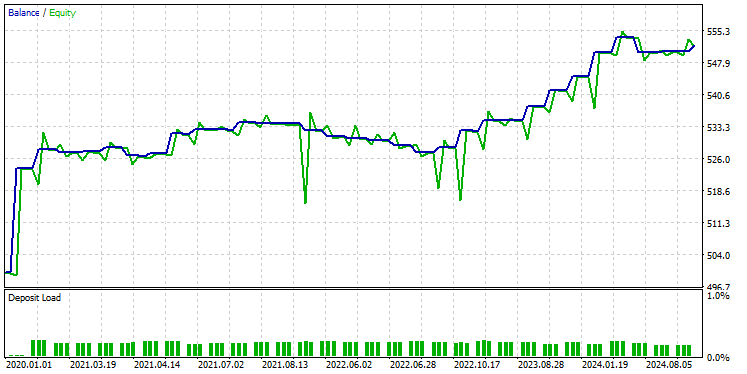
O modelo GRU apresentou uma acurácia de aproximadamente 61% — não tão boa quanto a dos dois modelos anteriores, mas ainda assim uma acurácia decente.
Considerações Finais
A integração de Redes Neurais Convolucionais (CNNs) com Redes Neurais Recorrentes (RNNs) pode ser uma abordagem poderosa para previsão no mercado de ações, oferecendo o potencial de revelar padrões ocultos e dependências temporais nos dados. No entanto, essa combinação é relativamente incomum e traz alguns desafios. Um dos principais riscos é o overfitting, especialmente ao aplicar modelos tão sofisticados a problemas relativamente simples. O overfitting pode fazer o modelo ter bom desempenho nos dados de treinamento, mas falhar em generalizar para novos dados.
Além disso, a complexidade de combinar CNNs e RNNs gera custos computacionais significativos, principalmente se você decidir escalar o modelo adicionando mais camadas densas ou aumentando o número de neurônios. É essencial equilibrar cuidadosamente a complexidade do modelo com os recursos disponíveis e o problema em questão.,
Até mais.
Acompanhe o desenvolvimento dos modelos de machine learning e muito mais discutido nesta série de artigos neste repositório do GitHub.
Tabela de Anexos
Nome do Arquivo | Tipo de arquivo | Descrição e Uso |
|---|---|---|
Experts\CNN + GRU EA.mq5 Experts\CNN + LSTM EA.mq5 Experts\CNN + RNN EA.mq5 | Expert Advisors | Robô de negociação para carregar os modelos ONNX e testar a estratégia de trading no MetaTrader 5. |
ConvNet.mqh preprocessing.mqh | Arquivos de inclusão |
|
Files\ *.onnx | Modelos ONNX | Modelos de machine learning discutidos neste artigo em formato ONNX |
| Files\*.bin | Arquivos binários | Arquivos binários para carregar os parâmetros do scaler de Padronização para cada modelo |
Jupyter Notebook\cnns-rnns.ipynb | python/Jupyter notebook | Todo o código Python discutido neste artigo pode ser encontrado dentro deste notebook. |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/15585
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.


- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso