Ciência de Dados e Aprendizado de Máquina (Parte 02): Regressão Logística

Ao contrário da Regressão Linear que nós discutimos na parte 01, A Regressão Logística é um método de classificação baseado em regressão linear.
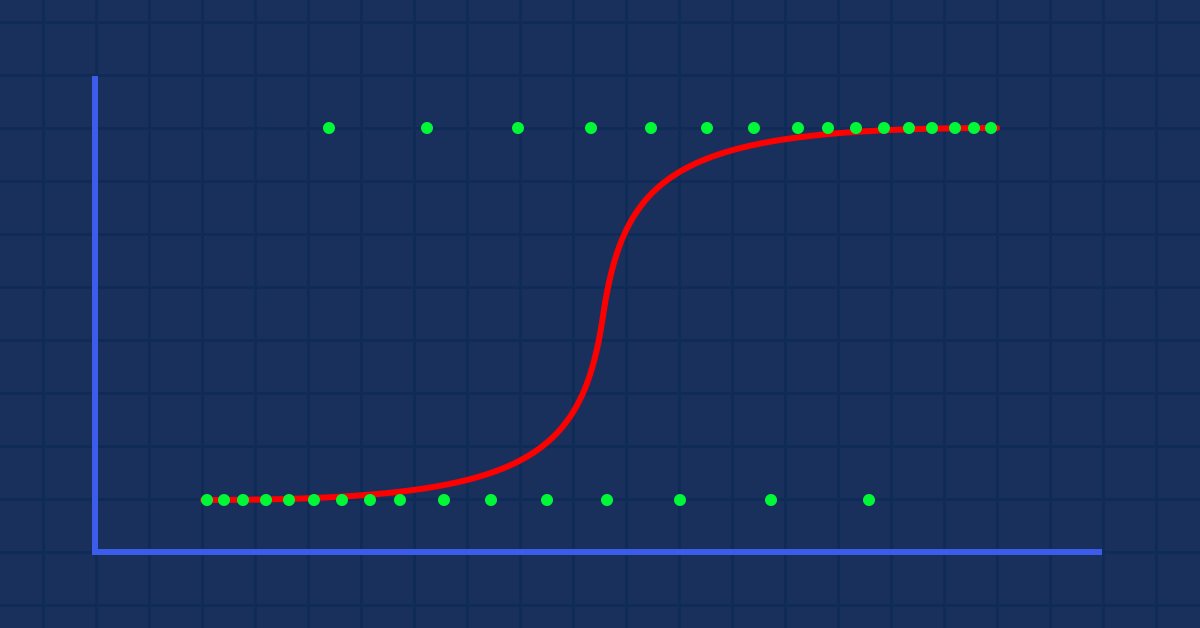
Teoria: Suponha que nós desenhamos um gráfico da probabilidade de alguém ser obeso versus seu peso.
Neste caso, nós não podemos usar um modelo linear, usaremos outra técnica para transformar essa linha em uma curva em "S" conhecida como Sigmoide.
Como a regressão logística produz resultados em um formato binário que é usado para prever o resultado da variável dependente categórica, o resultado deve ser discreto/categórico, como:
- 0 ou 1
- Sim ou não
- Verdadeiro ou Falso
- Alto ou Baixo
- Compra ou Venda
Em nossa biblioteca que vamos criar, nós vamos ignorar outros valores discretos. Nosso foco será no binário somente (0,1).
Como nossos valores de y devem estar entre 0 e 1, nossa linha deve ser cortada em 0 e 1. Isso pode ser obtido através da fórmula:

O que nos dará este gráfico

O modelo Linear é passado para uma função logística (sigmoide/p) =1/1+e^t onde t é o modelo linear cujo resultado possui valores entre 0 e 1. Isso representa a probabilidade de um ponto de dado pertencer a uma classe.
Em vez de usar y de um modelo linear como dependente, sua função é exibida como "p" para caracterizar como dependente
p = 1/1+e^-(c+m1x1+m2x2+....+mnxn), no caso de múltiplos valores
Como dito anteriormente, a curva sigmoide visa converter valores infinitos em uma saída no formato binário (0 ou 1). Mas e se eu tiver um ponto de dados localizado em 0.8, como se pode decidir que o valor é zero ou um? É aqui que os valores do limiar entram em jogo.

O limiar indica a probabilidade de ganhar ou perder, ele está localizado em 0.5 (centro de 0 e 1).
Qualquer valor maior ou igual a 0.5 será arredondado para um, portanto, considerado vencedor, enquanto qualquer valor abaixo de 0.5 será arredondado para 0, portanto, considerado perdedor neste ponto, está hora de vermos a diferença entre a regressão linear e logística.
Regressão Linear vs Logística
| Linear | Regressão Logística |
|---|---|
| Variável contínua | Variável categórica |
| Resolve problemas de regressão | Resolve problemas de classificação |
| O modelo tem uma equação da reta | O modelo tem uma equação logística |
Antes de mergulharmos na parte de codificação e nos algoritmos para classificar os dados, várias etapas podem nos ajudar a entender os dados e facilitar a construção do nosso modelo:
- Coleta e análise de dados
- Limpeza dos dados
- Verificação da Precisão
01: Coleta e Análise de dados
Nesta seção, nós vamos escrever muito código em python para visualizar os nossos dados. Vamos começar importando as bibliotecas que vamos usar para extrair e visualizar os dados no Jupyter notebook.
Para a construção de nossa biblioteca, nós vamos usar os dados do Titanic, para quem não está familiarizado, são os dados sobre o acidente do navio Titanic que afundou no Oceano Atlântico do Norte em 15 de abril de 1912 após colidir com um iceberg, Wikipédia. Todos os códigos em python e o conjunto de dados podem ser encontrados no meu GitHub, cujo link se encontra no final do artigo.

As colunas representam
survival - Sobrevivente (0 = No; 1 = Yes)
class - Classe do passageiro (1 = 1st; 2 = 2nd; 3 = 3rd)
name - Nome
sex - Sexo
age - Idade
sibsp - Número de Irmãos/Cônjuges a Bordo
parch - Número de Pais/Filhos a Bordo
ticket - Número do bilhete
fare - Tarifa do Passageiro
cabin - Cabine
embarked - Porto de Embarcação (C = Cherbourg; Q = Queenstown; S = Southampton)
Agora que nós temos os nossos dados coletados e armazenados na variável titanic_data, vamos começar a visualizar os dados em colunas, começando com a coluna de sobrevivência.
sns.countplot(x="Survived", data = titanic_data)
saída

Isso nos diz que a minoria dos passageiros sobreviveu ao acidente, cerca de metade dos passageiros que estavam no navio sobreviveram ao acidente.
Vamos visualizar o número de sobreviventes de acordo com o sexo
sns.countplot(x='Survived', hue='Sex', data=titanic_data)

Eu não sei o que aconteceu com os homens naquele dia, mas as mulheres sobreviveram mais que o dobro do número de homens
Vamos visualizar o número de sobreviventes de acordo com os grupos da classe
sns.countplot(x='Survived', hue='Pclass', data=titanic_data)

Vamos traçar o histograma das faixas etárias dos passageiros que estavam no navio, aqui nós não podemos usar o gráficos de contagem para visualizar os nossos dados, pois há muitos valores diferentes de idade em nosso conjunto de dados que não estão organizados.
titanic_data['Age'].plot.hist()Saída:

Por último, vamos visualizar o histograma da tarifa cobrada no navio
titanic_data['Fare'].plot.hist(bins=30, figsize=(10,10))

É isso para a visualização dos dados, embora tenhamos visualizado apenas 5 de 12 colunas porque essas são as colunas importantes, agora vamos limpar nossos dados.
02: Limpeza dos Dados
Aqui, nós limpamos os nossos dados removendo os valores NaN (ausentes) enquanto evitamos/removemos colunas desnecessárias no conjunto de dados.
Usando a regressão logística, você precisa ter valores do tipo double e integer e evitar valores do tipo string não significativos, neste caso, nós ignoraremos as seguintes colunas:
- A coluna Name (não tem informações significativas)
- A coluna Ticket (não faz sentido para a sobrevivência do acidente)
- A coluna Cabin (tem muitos valores ausentes, as primeiras 5 linhas mostram isso)
- A coluna Embarked (acho que ela é irrelevante)
Para fazer isso, eu vou abrir o arquivo CSV no WPS office e remover manualmente as colunas, você pode usar qualquer programa de planilha de sua escolha.
Após remover as colunas usando uma planilha vamos visualizar os novos dados.
new_data = pd.read_csv(r'C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\892B47EBC091D6EF95E3961284A76097\MQL5\Files\titanic.csv') new_data.head(5)
Saída:

Agora nós limpamos os dados, embora ainda tenhamos valores ausentes na coluna age, sem mencionar que temos os valores do tipo string na coluna sex. Vamos corrigir o problema com um pouco de código. Vamos criar um codificador de rótulos para converter a string male e female em 0 e 1, respectivamente.
void CLogisticRegression::LabelEncoder(string &src[],int &EncodeTo[],string members="male,female") { string MembersArray[]; ushort separator = StringGetCharacter(m_delimiter,0); StringSplit(members,separator,MembersArray); //convert members list to an array ArrayResize(EncodeTo,ArraySize(src)); //make the EncodeTo array same size as the source array int binary=0; for(int i=0;i<ArraySize(MembersArray);i++) // loop the members array { string val = MembersArray[i]; binary = i; //binary to assign to a member int label_counter = 0; for (int j=0; j<ArraySize(src); j++) { string source_val = src[j]; if (val == source_val) { EncodeTo[j] = binary; label_counter++; } } Print(MembersArray[binary]," total =",label_counter," Encoded To = ",binary); } }
Para obter a matriz de origem nomeada como src[] eu também programei uma função para obter os dados de uma coluna específica em um arquivo CSV e a coloquei na matriz MembersArray[] de valores do tipo string, confira:
void CLogisticRegression::GetDatatoArray(int from_column_number, string &toArr[]) { int handle = FileOpen(m_filename,FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI,m_delimiter); int counter=0; if (handle == INVALID_HANDLE) Print(__FUNCTION__," Invalid csv handle err=",GetLastError()); else { int column = 0, rows=0; while (!FileIsEnding(handle)) { string data = FileReadString(handle); column++; //--- if (column==from_column_number) //if column in the loop is the same as the desired column { if (rows>=1) //Avoid the first column which contains the column's header { counter++; ArrayResize(toArr,counter); toArr[counter-1]=data; } } //--- if (FileIsLineEnding(handle)) { rows++; column=0; } } } FileClose(handle); }
Dentro de nosso testscript.mq5, veja como chamar corretamente as funções e inicializar a biblioteca:
#include "LogisticRegressionLib.mqh"; CLogisticRegression Logreg; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Logreg.Init("titanic.csv",","); string Sex[]; int SexEncoded[]; Logreg.GetDatatoArray(4,Sex); Logreg.LabelEncoder(Sex,SexEncoded,"male,female"); ArrayPrint(SexEncoded); }
Exibição da saída, após a execução do script com sucesso,
male total =577 Encoded To = 0
female total =314 Encoded To = 1
[ 0] 0 1 1 1 0 0 0 0 1 1 1 1 0 0 1 1 0 0 1 1 0 0 1 0 1 1 0 0 1 0 0 1 1 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1 0 1 0 0 1 1 0 0 1 0 1 0 0 1 0 0 0 0 1 0 1 0 0 1 0 0 0
[ 75] 0 0 0 0 1 0 0 1 0 1 1 0 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 1 0 1 1 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 1 0 0 0 0 1 0 0
... ... ... ...
... ... ... ...
[750] 1 0 0 0 1 0 0 0 0 1 0 0 0 1 0 1 0 1 0 0 0 0 1 0 1 0 0 1 0 1 1 1 0 0 0 0 1 0 0 0 0 0 1 0 0 0 1 1 0 1 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 0 1 0 0 0 1 0 0 1 0
[825] 0 0 0 0 1 1 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 1 1 1 1 1 0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 0 1 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0
Antes de codificar os seus valores preste atenção ao members="male,female" em seu argumento da função, o primeiro valor a aparecer em sua string será codificado como0; como você pode ver, a coluna de homens aparece primeiro, portanto, todos os homens serão codificados para 0, as mulheres serão codificadas para 1. Esta função não está restrita a dois valores, porém, você pode codificar o quanto quiser, desde que a string faça algum sentido para os seus dados.
Valores Ausentes
Se você prestar atenção na coluna Age, notará que há valores ausentes, os valores ausentes podem ser principalmente por um motivo... a morte. Em nosso conjunto de dados é impossível identificar a idade de um indivíduo, você pode identificar essas lacunas olhando para o conjunto de dados que pode ser demorado, especialmente em grandes conjuntos de dados, já que também estamos usando a pandas para visualizar nossos dados. Vamos descobrir as linhas que faltam em todas as colunas
titanic_data.isnull().sum()
A saída será:
PassengerId 0
Survived 0
Pclass 0
Sex 0
Age 177
SibSp 0
Parch 0
Fare 0
dtype: int64
De 891, 177 linhas em nossa coluna Age têm valores ausentes (NAN).
Agora, nós vamos substituir os valores ausentes em nossa coluna pela média de todos os valores.
void CLogisticRegression::FixMissingValues(double &Arr[]) { int counter=0; double mean=0, total=0; for (int i=0; i<ArraySize(Arr); i++) //first step is to find the mean of the non zero values { if (Arr[i]!=0) { counter++; total += Arr[i]; } } mean = total/counter; //all the values divided by their total number Print("mean ",MathRound(mean)," before Arr"); ArrayPrint(Arr); for (int i=0; i<ArraySize(Arr); i++) { if (Arr[i]==0) { Arr[i] = MathRound(mean); //replace zero values in array } } Print("After Arr"); ArrayPrint(Arr); }
Esta função encontra a média de todos os valores diferentes de zero e substitui todos os valores de zero na matriz pelo valor médio.
A saída após a execução bem-sucedida da função. Como podemos ver, todos os valores iguais a zero foram substituídos por 30.0 que era a idade média dos passageiros do Titanic.
mean 30.0 before Arr
[ 0] 22.0 38.0 26.0 35.0 35.0 0.0 54.0 2.0 27.0 14.0 4.0 58.0 20.0 39.0 14.0 55.0 2.0 0.0 31.0 0.0 35.0 34.0 15.0 28.0 8.0 38.0 0.0 19.0 0.0 0.0
… … … … … … … … …
[840] 20.0 16.0 30.0 34.5 17.0 42.0 0.0 35.0 28.0 0.0 4.0 74.0 9.0 16.0 44.0 18.0 45.0 51.0 24.0 0.0 41.0 21.0 48.0 0.0 24.0 42.0 27.0 31.0 0.0 4.0
[870] 26.0 47.0 33.0 47.0 28.0 15.0 20.0 19.0 0.0 56.0 25.0 33.0 22.0 28.0 25.0 39.0 27.0 19.0 0.0 26.0 32.0
After Arr
[ 0] 22.0 38.0 26.0 35.0 35.0 30.0 54.0 2.0 27.0 14.0 4.0 58.0 20.0 39.0 14.0 55.0 2.0 30.0 31.0 30.0 35.0 34.0 15.0 28.0 8.0 38.0 30.0 19.0 30.0 30.0
… … … … … … … … …
[840] 20.0 16.0 30.0 34.5 17.0 42.0 30.0 35.0 28.0 30.0 4.0 74.0 9.0 16.0 44.0 18.0 45.0 51.0 24.0 30.0 41.0 21.0 48.0 30.0 24.0 42.0 27.0 31.0 30.0 4.0
[870] 26.0 47.0 33.0 47.0 28.0 15.0 20.0 19.0 30.0 56.0 25.0 33.0 22.0 28.0 25.0 39.0 27.0 19.0 30.0 26.0 32.0
Construindo o Modelo de Regressão Logística
Primeiro, vamos construir nossa regressão logística onde nós teremos uma variável independente e uma variável dependente. Em seguida, nós escalaremos para um modelo de solução completo para o nosso problema.
Vamos construir o modelo em duas variáveis Sobreviventes vs Idade, vamos descobrir quais eram as chances de uma pessoa sobreviver com base em sua idade.
Até agora, nós sabemos que no fundo de um modelo logístico existe um modelo linear. Vamos começar codificando as funções que tornam possível um modelo linear.
Coefficient_of_X() e y_intercept(), essas funções não são novas, nós as construímos no primeiro artigo desta série, considere lê-lo para obter mais informações sobre essas funções e a regressão linear em geral.
double CLogisticRegression::y_intercept() { // c = y - mx return (y_mean-coefficient_of_X()*x_mean); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CLogisticRegression::coefficient_of_X() { double m=0; //--- { double x__x=0, y__y=0; double numerator=0, denominator=0; for (int i=0; i<ArraySize(m_xvalues); i++) { x__x = m_xvalues[i] - x_mean; //right side of the numerator (x-side) y__y = m_yvalues[i] - y_mean; //left side of the numerator (y-side) numerator += x__x * y__y; //summation of the product two sides of the numerator denominator += MathPow(x__x,2); } m = numerator/denominator; } return (m); }
Agora, vamos programar o modelo logístico a partir da fórmula.

Observe que z também é referido como a log-odds porque o inverso do sigmoide afirma que z pode ser definido como o logaritmo da probabilidade do rótulo 1 (por exemplo, "Sobrevivente") dividido pela probabilidade do rótulo 0 (por exemplo, "não sobreviveu"):

Neste caso y = mx+c (lembre-se do modelo linear).
Transformando isso em código, o resultado será,
double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1);
Preste atenção ao que foi feito aqui no valor de z a fórmula é log(y/1-y), mas o código é escrito como log(y_)-log(1-y_); Lembre-se das Leis dos Logaritmos na matemática!! A divisão de logaritmos com a mesma base resulta na subtração dos expoentes, leia aqui.
Este é basicamente o nosso modelo quando a fórmula é programada, mas há muita coisa acontecendo dentro de nossa função LogisticRegression(), aqui está tudo o que está dentro da função:
double CLogisticRegression::LogisticRegression(double &x[],double &y[],int& Predicted[],double train_size_split = 0.7) { int arrsize = ArraySize(x); //the input array size double p_hat =0; //store the probability //--- int train_size = (int)MathCeil(arrsize*train_size_split); int test_size = (int)MathFloor(arrsize*(1-train_size_split)); ArrayCopy(m_xvalues,x,0,0,train_size); ArrayCopy(m_yvalues,y,0,0,train_size); //--- y_mean = mean(m_yvalues); x_mean = mean(m_xvalues); // Training our model in the background double c = y_intercept(), m = coefficient_of_X(); //--- Here comes the logistic regression model int TrainPredicted[]; double sigmoid = 0; ArrayResize(TrainPredicted,train_size); //resize the array to match the train size Print("Training starting..., train size=",train_size); for (int i=0; i<train_size; i++) { double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1); double odds_ratio = p_hat/(1-p_hat); TrainPredicted[i] = (int) round(p_hat); //round the values to give us the actual 0 or 1 if (m_debug) PrintFormat("%d Age =%.2f survival_Predicted =%d ",i,m_xvalues[i],TrainPredicted[i]); } //--- Testing our model if (train_size_split<1.0) //if there is room for testing { ArrayRemove(m_xvalues,0,train_size); //clear our array ArrayRemove(m_yvalues,0,train_size); //clear our array from train data ArrayCopy(m_xvalues,x,0,train_size,test_size); //new values of x, starts from where the training ended ArrayCopy(m_yvalues,y,0,train_size,test_size); //new values of y, starts from where the testing ended Print("start testing...., test size=",test_size); ArrayResize(Predicted,test_size); //resize the array to match the test size for (int i=0; i<test_size; i++) { double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1); double odds_ratio = p_hat/(1-p_hat); TrainPredicted[i] = (int) round(p_hat); //round the values to give us the actual 0 or 1 if (m_debug) PrintFormat("%d Age =%.2f survival_Predicted =%d , Original survival=%.1f ",i,m_xvalues[i],Predicted[i],m_yvalues[i]); } }
Agora, vamos treinar e testar nosso modelo em nosso TestScript.mq5
double Age[]; Logreg.GetDatatoArray(5,Age); Logreg.FixMissingValues(Age); double y_survival[]; int Predicted[]; Logreg.GetDatatoArray(2,y_survival); Logreg.LogisticRegression(Age,y_survival,Predicted);
A saída de uma execução bem-sucedida do script será:
Training starting..., train size=624
0 Age =22.00 survival_Predicted =0
1 Age =38.00 survival_Predicted =0
... .... ....
622 Age =20.00 survival_Predicted =0
623 Age =21.00 survival_Predicted =0
start testing...., test size=267
0 Age =21.00 survival_Predicted =0
1 Age =61.00 survival_Predicted =1
.... .... ....
265 Age =26.00 survival_Predicted =0
266 Age =32.00 survival_Predicted =0
Excelente. Nosso modelo está funcionando agora nós podemos pelo menos obter os resultados dele, mas o modelo está fazendo boas previsões?
Nós precisamos verificar a sua precisão.
A Matriz de Confusão

Como todos nós sabemos, todo modelo bom ou ruim pode fazer previsões, eu criei um arquivo CSV para as previsões que o nosso modelo fez ao lado dos valores originais dos dados de teste dos passageiros sobreviventes: novamente, 1 significa que sobreviveue 0 significa que não sobreviveu.
Aqui estão umas 10 colunas:
| Original | Previsto | |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 2 | 0 | 1 |
| 3 | 1 | 0 |
| 4 | 0 | 0 |
| 5 | 0 | 0 |
| 6 | 1 | 1 |
| 7 | 0 | 1 |
| 8 | 1 | 0 |
| 9 | 0 | 0 |
Calculamos a matriz de confusão usando:
- TP - Verdadeiro Positivo
- TN - Verdadeiro Negativo
- FP - Falso Positivo
- FN - Falso Negativo
Agora, quais são esses valores?
TP(Verdadeiro Positivo)
É quando o valor Original é Positivo (1) e seu modelo também prevê Positivo (1)
TN(Verdadeiro Negativo)
É quando o valor Original é Negativo (0) e seu modelo também prevê Negativo (0)
FP(Falso Positivo)
É quando o valor original é Negativo (0), mas seu modelo prevê um valor positivo (1)
FN(Falso Negativo)
É quando o valor original é Positivo (1), mas seu modelo prevê um valor negativo (0)
Agora que você conhece os valores vamos calcular a matriz de confusão para a amostra acima como exemplo
| Original | Previsto | TP/TN/FP/FN | |
|---|---|---|---|
| 0 | 0 | 0 | TN |
| 1 | 0 | 1 | FP |
| 2 | 0 | 1 | FP |
| 3 | 1 | 0 | FN |
| 4 | 0 | 0 | TN |
| 5 | 0 | 0 | TN |
| 6 | 1 | 1 | TP |
| 7 | 0 | 1 | FP |
| 8 | 1 | 0 | FN |
| 9 | 0 | 0 | TN |
A matriz de confusão pode ser usada para calcular a precisão do nosso modelo usando esta fórmula.
Da nossa tabela:
- TN = 4
- TP = 1
- FN = 2
- FP = 3

Precisão = 1 + 5 / 4 + 1 + 2 + 3
Precisão = 0.5
Neste caso, nossa precisão é de 50%.( 0.5*100% convertendo em porcentagem)
Agora, já entendemos como funciona a matriz de confusão 1X1. É hora de convertê-la em código e analisar a precisão do nosso modelo em todo o conjunto de dados
void CLogisticRegression::ConfusionMatrix(double &y[], int &Predicted_y[], double& accuracy) { int TP=0, TN=0, FP=0, FN=0; for (int i=0; i<ArraySize(y); i++) { if ((int)y[i]==Predicted_y[i] && Predicted_y[i]==1) TP++; if ((int)y[i]==Predicted_y[i] && Predicted_y[i]==0) TN++; if (Predicted_y[i]==1 && (int)y[i]==0) FP++; if (Predicted_y[i]==0 && (int)y[i]==1) FN++; } Print("Confusion Matrix \n ","[ ",TN," ",FP," ]","\n"," [ ",FN," ",TP," ] "); accuracy = (double)(TN+TP) / (double)(TP+TN+FP+FN); }
Agora vamos voltar para a nossa função principal em nossa classe conhecida como LogisticRegression(), desta vez nós vamos transformá-lo em uma função do tipo double que retorna a precisão do modelo, também vou reduzir o número do método Print(), mas vou adicioná-los a uma instrução if, pois não queremos imprimir os valores todas as vezes, a menos que queiramos depurar a nossa classe. Todas as alterações estão destacadas em azul:
double CLogisticRegression::LogisticRegression(double &x[],double &y[],int& Predicted[],double train_size_split = 0.7) { double accuracy =0; //Accuracy of our Train/Testmodel int arrsize = ArraySize(x); //the input array size double p_hat =0; //store the probability //--- int train_size = (int)MathCeil(arrsize*train_size_split); int test_size = (int)MathFloor(arrsize*(1-train_size_split)); ArrayCopy(m_xvalues,x,0,0,train_size); ArrayCopy(m_yvalues,y,0,0,train_size); //--- y_mean = mean(m_yvalues); x_mean = mean(m_xvalues); // Training our model in the background double c = y_intercept(), m = coefficient_of_X(); //--- Here comes the logistic regression model int TrainPredicted[]; double sigmoid = 0; ArrayResize(TrainPredicted,train_size); //resize the array to match the train size Print("Training starting..., train size=",train_size); for (int i=0; i<train_size; i++) { double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1); TrainPredicted[i] = (int) round(p_hat); //round the values to give us the actual 0 or 1 if (m_debug) PrintFormat("%d Age =%.2f survival_Predicted =%d ",i,m_xvalues[i],TrainPredicted[i]); } ConfusionMatrix(m_yvalues,TrainPredicted,accuracy); //be careful not to confuse the train predict values arrays printf("Train Model Accuracy =%.5f",accuracy); //--- Testing our model if (train_size_split<1.0) //if there is room for testing { ArrayRemove(m_xvalues,0,train_size); //clear our array ArrayRemove(m_yvalues,0,train_size); //clear our array from train data ArrayCopy(m_xvalues,x,0,train_size,test_size); //new values of x, starts from where the training ended ArrayCopy(m_yvalues,y,0,train_size,test_size); //new values of y, starts from where the testing ended Print("start testing...., test size=",test_size); ArrayResize(Predicted,test_size); //resize the array to match the test size for (int i=0; i<test_size; i++) { double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1); TrainPredicted[i] = (int) round(p_hat); //round the values to give us the actual 0 or 1 if (m_debug) PrintFormat("%d Age =%.2f survival_Predicted =%d , Original survival=%.1f ",i,m_xvalues[i],Predicted[i],m_yvalues[i]); } ConfusionMatrix(m_yvalues,Predicted,accuracy); printf("Testing Model Accuracy =%.5f",accuracy); } return (accuracy); //Lastly, the testing Accuracy will be returned }
A execução bem-sucedida do script produzirá o seguinte:
Training starting..., train size=624
Confusion Matrix
[ 378 0 ]
[ 246 0 ]
Train Model Accuracy =0.60577
start testing...., test size=267
Confusion Matrix
[ 171 0 ]
[ 96 0 ]
Testing Model Accuracy =0.64045
Viva! Agora nós somos capazes de identificar a qualidade do nosso modelo por meio de números, embora a precisão de 64.045% nos dados de teste não seja boa o suficiente para usar o modelo para fazer previsões (na minha opinião) pelo menos por enquanto, temos uma biblioteca que pode nos ajudar a classificar os dados usando a regressão logística.
Seguimos com algumas explicações sobre a função principal:
double CLogisticRegression::LogisticRegression(double &x[],double &y[],int& Predicted[],double train_size_split = 0.7)
A entrada train_size_split é para dividir os dados de treinamento e de teste por padrão, a divisão é 0.7, o que significa que 70% dos dados serão para treinamento, enquanto os 30% restantes serão para fins de teste, a matriz de referência Predicted[] retornará os dados previstos do teste.
Entropia Cruzada Binária, também conhecido como Função de Perda
Assim como o Erro Quadrático Médio é a função de erro para a regressão linear, a Entropia Cruzada Binária é a função de perda para a regressão logística.
Teoria:
Vamos ver como ela funciona em dois casos de uso para a regressão logística, ou seja: quando a saída real é 0 e 1
01: Quando o valor de saída real é 1
Considere o modelo para duas amostras de entrada p1 = 0.4 e p2 = 0.6. Espera-se que p1 seja penalizado mais do que p2 porque está longe de 1 em relação a p1.
Do ponto de vista matemático, o logaritmo negativo de um número pequeno é um número grande e vice-versa.
Para penalizar as entradas, nós usaremos a fórmula
penalização = -log(p)
Nestes dois casos
- Penalização = -log(0.4)=0.4 i.e. the penalty on p1 is 0.4
- Penalização = -log(0.6)=0.2 i.e. the penalty on p2 is 0.2
02: Quando o valor de saída real é 0
Considere a saída do modelo para as duas amostras de entrada, p1 = 0.4 e p2 = 0.6 (igual ao caso anterior). Espera-se que p2 seja penalizado mais do que p1 porque ele está longe de 0, mas lembre-se que a saída do modelo logístico é a probabilidade de uma amostra ser positiva. uma amostra sendo negativa, isso é fácil. Segue a fórmula
Probabilidade de uma amostra ser negativa = 1-probabilidade de uma amostra ser positiva
Então, para encontrar a penalidade neste caso, a fórmula da penalidade será
penalização = -log(1-p)
Nestes dois casos
- penalização = -log(1-p) = -log(1-0.4) =0.2 i.e. a penalização é de 0.2
- penalização = -log(1-p) = -log(1-0.6) =0.4 i.e. a penalização é de 0.4
A penalidade em p2 é maior que em p1 (funciona como o esperado), legal!
Agora, a penalidade para uma única amostra de entrada cuja saída do modelo é p e o verdadeiro valor de saída é y pode ser calculada da seguinte forma.
se a amostra de entrada é positiva y=1:
penalização = -log(p)
senão:
penalização = -log(1-p)
Uma equação de uma única linha equivalente à instrução de bloco if-else acima pode ser escrita como
penalização = -( y*log(p) + (1-y)*log(1-p) )
onde
y = valores reais em nosso conjunto de dados
p = probabilidade bruta prevista do modelo (antes do arredondamento)
Vamos provar que esta equação é equivalente à declaração if-else acima
01: quando os valores de saída y = 1
penalização = -( 1*log(p) + (1-1)*log(1-p) ) = -log(p) portanto provado
02: quando o valor de saída y = 0
penalização = -( 0*log(p) + (1-0)* log(1-p) ) = log(1-p) portanto provado
Finalmente, a função de perda de log para N amostras de entrada se parece com

A perda logarítmica é um indicativo de quão próxima a probabilidade de previsão está do valor real/verdadeiro correspondente (0 ou 1 no caso da classificação binária). Quanto mais a probabilidade prevista divergir do valor real, maior será o valor da perda logarítmica.
Funções de custo, como perda logarítmica e muitas outras, podem ser usadas como uma métrica de quão bom é o modelo, mas o seu maior uso é ao otimizar o modelo para obter os melhores parâmetros usando o gradiente descendente ou outros algoritmos de otimização (discutiremos nas séries posteriores, fique atento).
Se você pode medi-lo, você pode melhorá-lo. Esse é o objetivo principal das funções de custo.
do nosso conjunto de dados de teste e treinamento, parece que a nossa perda logarítmica está entre 0.64 - 0.68, o que não é o ideal (a grosso modo).
conjunto de dados de treinamento
Logloss =0.6858006105398738
conjunto de dados de teste
Logloss =0.6599503403665642
Aqui está como nós podemos converter a nossa função de perda logarítmica em código
double CLogisticRegression::LogLoss(double &rawpredicted[]) { double log_loss =0; double penalty=0; for (int i=0; i<ArraySize(rawpredicted); i++ ) { penalty += -((m_yvalues[i]*log(rawpredicted[i])) + (1-m_yvalues[i]) * log(1-rawpredicted[i])); //sum all the penalties if (m_debug) printf("penalty =%.5f",penalty); } log_loss = penalty/ArraySize(rawpredicted); //all the penalties divided by their total number Print("Logloss =",log_loss); return(log_loss); }
Para obter a saída prevista bruta, nós precisamos voltar ao teste principal, treinar em loops e armazenar os dados na matriz de previsão bruta logo antes do processo de arredondamento das probabilidades.
Desafio da Regressão Logística Dinâmica Múltipla
O maior desafio que eu enfrentei ao construir as bibliotecas de regressão linear e logística em ambos os artigos, este e o anterior, foram as várias funções de regressão dinâmica, nas quais poderíamos usá-las para várias colunas de dados sem precisar codificar as coisas para todos os dados adicionados a nosso modelo, no artigo anterior eu codifiquei duas funções com o mesmo nome, a única diferença entre elas era o número de dados com que cada modelo podia trabalhar, uma conseguia trabalhar com duas variáveis independentes e a outra com quatro respectivamente:
void MultipleRegressionMain(double& predicted_y[],double& Y[],double& A[],double& B[]); void MultipleRegressionMain(double& predicted_y[],double& Y[],double& A[],double& B[],double& C[],double& D[]);
Mas, esse método é inconveniente e parece uma maneira prematura de codificar as coisas e viola as regras de código limpo e DRY (não repita os princípios que a OOP está tentando nos ajudar a alcançar).
Ao contrário do python com funções flexíveis que podem receber muitos argumentos funcionais com a ajuda de *args e **kwargs, em MQL5 isso poderia ser alcançado usando string até onde eu posso pensar, acredito que este é o nosso ponto de partida.
void CMultipleLogisticRegression::MLRInit(string x_columns="3,4,5,6,7,8")
A entrada x_columns representa todas as colunas de variáveis independentes que nós usaremos em nossa biblioteca, essas colunas exigirão que tenhamos várias matrizes independentes para cada uma das colunas, mas não há como criar matrizes dinamicamente, então o uso de matriz "cai por terra" aqui.
Nós podemos criar vários arquivos CSV dinamicamente e usá-los como matrizes, com certeza, mas isso tornará nossos programas mais caros quando se trata do uso de recursos do computador em comparação com o uso de matrizes, principalmente ao lidar com vários dados sem falar no loop while que usaremos frequentemente para abrir os arquivos cujo processo será retardado, não tenho 100% de certeza, então me corrija se estiver errado.
Embora nós ainda possamos usar a maneira mencionada.
Eu descobri o caminho a seguir para usar matrizes, vamos armazenar todos os dados de todas as colunas em uma matriz e usar os dados separadamente de uma única matriz.
int start = 0; if (m_debug) //if we are on debug mode print Each Array vs its row for (int i=0; i<x_columns_total; i++) { ArrayCopy(EachXDataArray,m_AllDataArray,0,start,rows_total); start += rows_total; Print("Array Number =",i," From column number ",m_XColsArray[i]); ArrayPrint(EachXDataArray); }
Dentro do loop for, nós podemos manipular os dados nas matrizes e realizar todos os cálculos para o modelo do jeito que eu quiser para todas as colunas, eu já tentei esse método mas ainda estou na tentativa sem sucesso, o motivo pelo qual expliquei essa hipótese é permitir que todos que estão lendo este artigo entendam este desafio e eu congratulo-me com todas as suas opiniões nas seções de comentários sobre como podemos codificar esta função de regressão logística dinâmica múltipla minha tentativa completa de criar esta biblioteca é encontrada neste link https://www.mql5.com/en/code/38894.
Esta tentativa não foi bem sucedida, mas eu tenho esperanças e creio que vale a pena compartilhar.
Vantagens da Regressão Logística
- Não assume sobre a distribuição de classe no espaço de características
- Facilmente estendido para várias classes (regressão multinomial)
- Visão probabilística natural das previsões de classe
- Rápido para treinar
- Muito rápido na classificação de registros desconhecidos
- Boa precisão para muitos conjuntos de dados simples
- Resistente ao overfitting
- Pode interpretar os coeficientes do modelo como um indicador de importância do recurso
Desvantagens
- Constrói limites lineares
Pensamentos finais
Isso é tudo para este artigo, na vida real a regressão logística é usada em vários campos, como classificar e-mails como spam e não spam, detectar caligrafia e coisas muito mais interessantes.
Eu sei que nós não vamos usar algoritmos de regressão logística para classificar os dados do Titanic ou qualquer um dos campos mencionados, especialmente na plataforma MetaTrader 5, como dito anteriormente, o conjunto de dados foi usado apenas para construir a biblioteca em comparação com o saída que foi alcançada em python vinculado aqui > https://github.com/MegaJoctan/LogisticRegression-MQL5-and-python. No próximo artigo, nós veremos como nós podemos usar os modelos logísticos para prever a queda da bolsa.
Como este artigo se tornou muito longo, eu deixo a tarefa de regressão múltipla como lição de casa para todos os leitores.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/10626
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.


 Como desenvolver um sistema de negociação baseado no indicador MACD
Como desenvolver um sistema de negociação baseado no indicador MACD
 Desenvolvendo um EA de negociação do zero (Parte 23): Um novo sistema de ordens (VI)
Desenvolvendo um EA de negociação do zero (Parte 23): Um novo sistema de ordens (VI)
 Desenvolvendo um EA de negociação do zero (Parte 24): Dado robustez ao sistema (I)
Desenvolvendo um EA de negociação do zero (Parte 24): Dado robustez ao sistema (I)
 Como desenvolver um sistema de negociação baseado no indicador CCI
Como desenvolver um sistema de negociação baseado no indicador CCI
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso