Ciência de Dados e Aprendizado de Máquina (Parte 13): Analisando o mercado financeiro usando a análise de componentes principais (PCA)

A análise de componentes principais é uma técnica essencial para a análise de dados e o aprendizado de máquina, que é amplamente utilizada em aplicações que vão desde o processamento de imagens e sinais até finanças e ciências sociais.
Introdução
A análise de componentes principais é uma técnica para reduzir a dimensionalidade, ela é usada com frequência para baixar a dimensionalidade de conjuntos de dados grandes, convertendo um grupo grande de variáveis em um grupo menor que ainda contém a maior parte das informações do conjunto principal.
A redução do número de variáveis em uma amostra geralmente tem como custo a redução da precisão, mas o truque da redução da dimensionalidade é sacrificar um pouco a precisão visando simplificar. Você e eu sabemos que um pequeno número de variáveis em um conjunto de dados é mais fácil de investigar e visualizar, e a própria análise de dados se torna muito mais fácil e rápida para os algoritmos de aprendizado de máquina. Pessoalmente, não acho que optar pela simplicidade em troca da precisão seja algo ruim quando se trata de negociação. A precisão não é necessariamente sinônimo de lucro.

A ideia básica por trás dessa ferramenta é simples: reduzir o número de variáveis no conjunto de dados, mantendo o máximo de informações possível. Vejamos as etapas que compõem o algoritmo para análise de componentes principais.
Etapas do algoritmo do PCA
- Padronização de dados
- Cálculo da matriz de covariância
- Cálculo de autovetores e autovalores
- Cálculo das pontuações do PCA e sua padronização
- Obtenção de componentes
Comecemos com a padronização dos dados.
1. Padronização de dados
O objetivo da padronização é adequar todas as variáveis a uma mesma escala para que possam ser comparadas e analisadas sobre uma base comum. Ao analisar dados, muitas vezes acabamos lidando com variáveis que têm unidades ou escalas de medida diferentes, o que pode levar a resultados e conclusões incorretos. Por exemplo, uma média móvel tem um intervalo de valores semelhante ao do preço de mercado e o indicador RSI geralmente tem valores entre 0 e 100. Essas duas variáveis não podem ser comparadas quando usadas juntas em qualquer modelo. Ou seja, elas não podem ser combinadas ou usadas para comparação em sua forma pura.
A padronização de dados é a transformação de cada variável para que ela tenha um valor médio igual a zero e um como seu desvio padrão. Isso assegura que cada variável tenha a mesma escala e distribuição, tornando-as comparáveis. A padronização de dados também pode ajudar a melhorar a precisão e a estabilidade dos modelos de aprendizado de máquina, especialmente quando as variáveis têm magnitudes ou variâncias diferentes.
Para ilustrar esse aspecto, usaremos dados de pressão arterial. Normalmente, uso diferentes dados que não vêm à tona, só para entender melhor os conceitos básicos. Por exemplo, como agora, dados relacionados a humanos, que são mais fáceis de entender e depurar.
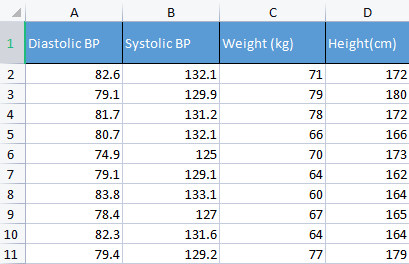
matrix Matrix = matrix_utiils.ReadCsv("bp data.csv"); pre_processing = new CPreprocessing(Matrix, NORM_STANDARDIZATION);
Antes e depois:
CS 0 10:17:31.956 PCA Test (NAS100,H1) Non-Standardized data CS 0 10:17:31.956 PCA Test (NAS100,H1) [[82.59999999999999,132.1,71,172] CS 0 10:17:31.956 PCA Test (NAS100,H1) [79.09999999999999,129.9,79,180] CS 0 10:17:31.956 PCA Test (NAS100,H1) [81.7,131.2,78,172] CS 0 10:17:31.956 PCA Test (NAS100,H1) [80.7,132.1,66,166] CS 0 10:17:31.956 PCA Test (NAS100,H1) [74.90000000000001,125,70,173] CS 0 10:17:31.956 PCA Test (NAS100,H1) [79.09999999999999,129.1,64,162] CS 0 10:17:31.956 PCA Test (NAS100,H1) [83.8,133.1,60,164] CS 0 10:17:31.956 PCA Test (NAS100,H1) [78.40000000000001,127,67,165] CS 0 10:17:31.956 PCA Test (NAS100,H1) [82.3,131.6,64,164] CS 0 10:17:31.956 PCA Test (NAS100,H1) [79.40000000000001,129.2,77,179]] CS 0 10:17:31.956 PCA Test (NAS100,H1) Standardized data CS 0 10:17:31.956 PCA Test (NAS100,H1) [[0.979632638610581,0.8604038253411385,0.2240645398825688,0.3760399462363875] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4489982926965129,-0.0540350228475094,1.504433339211528,1.684004976623816] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.6122703991316175,0.4863152056275964,1.344387239295408,0.3760399462363875] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.2040901330438764,0.8604038253411385,-0.5761659596980309,-0.6049338265541837] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-2.163355410265021,-2.090739730176784,0.06401843996644889,0.539535575034816] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4489982926965129,-0.3865582403706605,-0.8962581595302708,-1.258916341747898] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.469448957915872,1.276057847245071,-1.536442559194751,-0.9319250841510407] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.7347244789579271,-1.259431686368917,-0.416119859781911,-0.7684294553526122] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.8571785587842599,0.6525768143891719,-0.8962581595302708,-0.9319250841510407] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.326544212870186,-0.3449928381802696,1.184341139379288,1.520509347825387]]
A padronização dos dados é uma etapa importante na análise dos componentes principais, porque o método se baseia em uma matriz de covariância, que é sensível às diferenças de escala e variações entre as variáveis. A padronização dos dados antes da aplicação dessa análise garante que os componentes principais resultantes não dominem as variáveis com maior magnitude ou variância, o que poderia adulterar a avaliação e levar a conclusões errôneas.
2. Cálculo da matriz de covariância
A matriz de covariância representa a estimativa de quanto uma variável aleatória afeta a mudança em conjunto. Ela é usada para calcular a covariância entre cada coluna da matriz de dados. A covariância entre duas variáveis aleatórias reais X e Y distribuídas conjuntamente com segundos momentos finitos é definida como:
![]()
Não há problema se você não entender essa fórmula. Já existe uma função pronta na biblioteca padrão da linguagem MQL5.
matrix Cova = Matrix.Cov(false); Print("Covariances\n", Cova);
Resultado
CS 0 10:17:31.957 PCA Test (NAS100,H1) Covariances CS 0 10:17:31.957 PCA Test (NAS100,H1) [[1.111111111111111,1.05661579634328,-0.2881675653452953,-0.3314539233600543] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.05661579634328,1.111111111111111,-0.2164241126576326,-0.2333966556085017] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.2881675653452953,-0.2164241126576326,1.111111111111111,1.002480628180182] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.3314539233600543,-0.2333966556085017,1.002480628180182,1.111111111111111]]
Lembre-se de que a covariância é uma matriz quadrada cujos valores na diagonal são iguais a 1. Ao manusear o método de matriz de covariância, devemos definir a entrada rowval como false.
matrix matrix::Cov( const bool rowvar=true // rows or cols vectors of observations );
Por isso, precisamos que nossa matriz quadrada seja uma matriz unitária com base nas colunas que definimos com essa função, e temos 4 colunas. O resultado será uma matriz 4x4, caso contrário, seria uma matriz 8x8.
3. Cálculo de autovetores e autovalores
Os autovetores são vetores especiais associados a uma matriz quadrada. Um autovetor de uma matriz é um vetor diferente de zero que, quando multiplicado pela matriz, produz um número escalar múltiplo de si mesmo, chamado de autovalor.
Formalmente, se A for uma matriz quadrada, então um vetor diferente de zero v é um vetor próprio de A se existir um escalar λ chamado autovalor de modo que Av = λv. Você pode ler mais aqui.
Como antes, não é necessário conhecer e entender a fórmula de cálculo - você pode usar uma função da biblioteca padrão.
if (!Cova.Eig(component_matrix, eigen_vectors)) Print("Failed to get the Component matrix matrix & Eigen vectors");
Observando mais de perto o método Eig
bool matrix::Eig( matrix& eigen_vectors, // matrix of eigenvectors vector& eigen_values // vector of eigenvalues );
É possível notar que a primeira matriz de entrada eigen_vectors retorna autovetores. Mas esse autovetor também pode ser associado a uma matriz de componentes. É por isso que armazeno esses autovetores na matriz de componentes, pois chamá-los de autovetores pode ser confuso, já que, pelos padrões da linguagem MQL5, eles são, na verdade, uma matriz.
Print("\nComponent matrix\n",component_matrix,"\nEigen Vectors\n",eigen_vectors);
Resultado
CS 0 10:17:31.957 PCA Test (NAS100,H1) Component matrix CS 0 10:17:31.957 PCA Test (NAS100,H1) [[-0.5276049902734494,0.459884739531444,0.6993704635263588,-0.1449826035480651] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4959779194731578,0.5155907011803843,-0.679399121133044,0.1630612352922813] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.4815459137666799,0.520677926282417,-0.1230090303369406,-0.6941734714553853] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.4937128827246101,0.5015643052337933,0.184842006606018,0.6859404272536788]] CS 0 10:17:31.957 PCA Test (NAS100,H1) Eigen Vectors CS 0 10:17:31.957 PCA Test (NAS100,H1) [2.677561590453738,1.607960239905343,0.04775016337426833,0.1111724507110918]
5. Cálculo das pontuações do PCA
Encontrar os resultados da análise de componentes principais é muito fácil e requer apenas uma linha de código.
pca_scores = Matrix.MatMul(component_matrix);
Para encontrar os valores, é necessário multiplicar a matriz normalizada pela matriz de componentes.
Resultado
CS 0 10:17:31.957 PCA Test (NAS100,H1) PCA SCORES CS 0 10:17:31.957 PCA Test (NAS100,H1) [[-0.6500472384886967,1.199407986803537,0.1425145462368588,0.1006701620494091] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.819562596624738,1.393614599196321,-0.1510888243020112,0.1670753033981925] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.2688014256048517,1.420914385142756,0.001937917070391801,-0.6847663538666366] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.110534258768705,-0.06593596223641518,-0.4827665581567511,0.09571954869438426] CS 0 10:17:31.957 PCA Test (NAS100,H1) [2.475561333978323,-1.768915328424386,-0.0006861487484489809,0.2983796568520111] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.6245145789301378,-1.503882637300733,-0.1738415909335406,-0.2393186981373224] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-2.608156175249579,0.0662886285379769,0.1774740257067155,0.4223436077935874] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.4325302694103054,-1.589321053467977,0.2509606394263523,-0.337079680008286] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.667608250048573,-0.2034163217366656,0.09411419638842802,-0.03495245015036286] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.664404875867474,1.051245703485609,0.1413817973120564,0.2119289033750197]]
Após a obtenção dos valore finais, eles precisam ser padronizados.
pre_processing = new CPreprocessing(pca_scores_standardized, NORM_STANDARDIZATION); Resultado
CS 0 10:17:31.957 PCA Test (NAS100,H1) PCA SCORES | STANDARDIZED CS 0 10:17:31.957 PCA Test (NAS100,H1) [[-0.4187491401035159,0.9970295470975233,0.68746486754918,0.3182591681100855] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.172130620033975,1.15846730049564,-0.7288256625700642,0.528192723531639] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.1731572094549987,1.181160740523977,0.009348167869829477,-2.164823873278453] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.715386880184365,-0.05481045923432144,-2.328780161211247,0.3026082735855334] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.594713612332284,-1.470442808583469,-0.003309859736641006,0.9432989819176616] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4023014443028848,-1.250129598312728,-0.8385809690405054,-0.7565833632510734] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.68012890598631,0.05510361946569121,0.8561031894464458,1.335199254045385] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.2786284867625921,-1.321151824538665,1.210589566461227,-1.06564543418136] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.074244269325531,-0.1690934905926844,0.4539901733759543,-0.1104988556867913] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.072180711318756,0.8738669736790375,0.6820006878558206,0.6699931252073736]]
6. Obtenção de componentes
Por último, mas não menos importante, precisamos obter os componentes principais, que é, na verdade, o objetivo principal de todas as etapas que realizamos até agora.
Para obter os componentes, primeiro precisamos calcular os coeficientes das estimativas da análise não padronizada. Porque agora temos duas estimativas: padronizada e não padronizada.
Os coeficientes de cada estimativa são simplesmente a variância de cada coluna na coluna de estimativas.
pca_scores_coefficients.Resize(cols); vector v_row; for (ulong i=0; i<cols; i++) { v_row = pca_scores.Col(i); pca_scores_coefficients[i] = v_row.Var(); //variance of the pca scores }
Resultado
2023.02.25 10:17:31.957 PCA Test (NAS100,H1) SCORES COEFF [2.409805431408367,1.447164215914809,0.04297514703684173,0.1000552056399828]
Para extrair os componentes, é necessário considerar alguns critérios:
- Critério do autovalor: esse critério envolve a seleção dos componentes principais com os maiores autovalores. A ideia é que os maiores autovalores correspondam aos componentes principais que abrangem a maior variância dos dados.
- Critério de proporção da variância: esse critério envolve a seleção de componentes principais que explicam uma determinada proporção da variância total dos dados. Nesta biblioteca, definirei o valor acima de 90%.
- O critério de declive: esse critério envolve o exame de um gráfico que mostra os autovalores de cada componente principal em ordem decrescente. O ponto em que a curva começa a se achatar é usado como um limite para selecionar os componentes principais a serem mantidos.
- Critério de Kaiser: esse critério pressupõe que somente os componentes principais com autovalores maiores que a média dos coeficientes sejam mantidos. Em outras palavras, é o componente principal com coeficientes maiores que um.
- Critério de validação cruzada: esse critério envolve a avaliação do desempenho do modelo na amostra de validação e a seleção dos componentes principais que fornecem a melhor precisão de previsão.
Essa biblioteca implementa o que considero ser os três critérios melhores e mais eficientes do ponto de vista computacional. Eles são a proporção de variância, o gráfico de Kaiser e o gráfico de declive. Você pode selecionar o critério apropriado na lista:
enum criterion
{
CRITERION_VARIANCE,
CRITERION_KAISER,
CRITERION_SCREE_PLOT
};
Abaixo está a função completa para extrair os componentes principais:
matrix Cpca::ExtractComponents(criterion CRITERION_) { vector vars = pca_scores_coefficients; vector vars_percents = (vars/(double)vars.Sum())*100.0; //--- for Kaiser double vars_mean = pca_scores_coefficients.Mean(); //--- for scree double x[], y[]; //--- matrix PCAS = {}; double sum=0; ulong max; vector v_cols = {}; switch(CRITERION_) { case CRITERION_VARIANCE: #ifdef DEBUG_MODE Print("vars percentages ",vars_percents); #endif for (int i=0, count=0; i<(int)cols; i++) { count++; max = vars_percents.ArgMax(); sum += vars_percents[max]; vars_percents[max] = 0; v_cols.Resize(count); v_cols[count-1] = (int)max; if (sum >= 90.0) break; } PCAS.Resize(rows, v_cols.Size()); for (ulong i=0; i<v_cols.Size(); i++) PCAS.Col(pca_scores.Col((ulong)v_cols[i]), i); break; case CRITERION_KAISER: #ifdef DEBUG_MODE Print("var ",vars," scores mean ",vars_mean); #endif vars = pca_scores_coefficients; for (ulong i=0, count=0; i<cols; i++) if (vars[i] > vars_mean) { count++; PCAS.Resize(rows, count); PCAS.Col(pca_scores.Col(i), count-1); } break; case CRITERION_SCREE_PLOT: v_cols.Resize(cols); for (ulong i=0; i<v_cols.Size(); i++) v_cols[i] = (int)i+1; vars = pca_scores_coefficients; SortAscending(vars); //Make sure they are in ascending first order ReverseOrder(vars); //Set them to descending order VectorToArray(v_cols, x); VectorToArray(vars, y); plt.ScatterCurvePlots("Scree plot",x,y,"variance","PCA","Variance"); //--- vars = pca_scores_coefficients; for (ulong i=0, count=0; i<cols; i++) if (vars[i] > vars_mean) { count++; PCAS.Resize(rows, count); PCAS.Col(pca_scores.Col(i), count-1); } break; } return (PCAS); }
O critério de Kaiser é configurado para selecionar componentes principais com coeficientes que expliquem mais de 90% de todas as variâncias. Por isso, foi necessário converter as variâncias em porcentagens:
vector vars = pca_scores_coefficients; vector vars_percents = (vars/(double)vars.Sum())*100.0;
Abaixo estão os resultados do uso de cada critério.
CRITERION KAISER:
CS 0 12:03:49.579 PCA Test (NAS100,H1) PCA'S CS 0 12:03:49.579 PCA Test (NAS100,H1) [[-0.6500472384886967,1.199407986803537] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.819562596624738,1.393614599196321] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.2688014256048517,1.420914385142756] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.110534258768705,-0.06593596223641518] CS 0 12:03:49.579 PCA Test (NAS100,H1) [2.475561333978323,-1.768915328424386] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-0.6245145789301378,-1.503882637300733] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-2.608156175249579,0.0662886285379769] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.4325302694103054,-1.589321053467977] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.667608250048573,-0.2034163217366656] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.664404875867474,1.051245703485609]]
CRITERION VARIANCE:
CS 0 12:03:49.579 PCA Test (NAS100,H1) PCA'S CS 0 12:03:49.579 PCA Test (NAS100,H1) [[-0.6500472384886967,1.199407986803537] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.819562596624738,1.393614599196321] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.2688014256048517,1.420914385142756] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.110534258768705,-0.06593596223641518] CS 0 12:03:49.579 PCA Test (NAS100,H1) [2.475561333978323,-1.768915328424386] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-0.6245145789301378,-1.503882637300733] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-2.608156175249579,0.0662886285379769] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.4325302694103054,-1.589321053467977] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.667608250048573,-0.2034163217366656] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.664404875867474,1.051245703485609]]
CRITERION SCREE PLOT:

Ótimo, agora temos dois componentes principais. Em termos simples, o conjunto de dados é reduzido de 4 para 2 variáveis. Essas variáveis podem então ser usadas em qualquer projeto em que você esteja trabalhando.
Aplicação da análise de componentes principais no MetaTrader
Agora é hora de usar o método de componentes principais para aquilo que nos interessa aqui - o trading.
Para isso, peguei 10 osciladores. Como todos eles são osciladores, decidi testá-los para provar que, se tivermos 10 indicadores do mesmo tipo, podemos aplicar a análise de componentes principais para reduzi-los e obter diversas variáveis fáceis de trabalhar.
Executei 10 indicadores em um gráfico: ATR, Bears Power, MACD, Chaikin Oscillator, Commodity Channel Index, De marker, índice de força, Momentum, RSI, faixa percentual de Williams.
handles[0] = iATR(Symbol(),PERIOD_CURRENT, period); handles[1] = iBearsPower(Symbol(), PERIOD_CURRENT, period); handles[2] = iMACD(Symbol(),PERIOD_CURRENT,12, 26,9,PRICE_CLOSE); handles[3] = iChaikin(Symbol(), PERIOD_CURRENT,12,26,MODE_SMMA,VOLUME_TICK); handles[4] = iCCI(Symbol(),PERIOD_CURRENT,period, PRICE_CLOSE); handles[5] = iDeMarker(Symbol(),PERIOD_CURRENT,period); handles[6] = iForce(Symbol(),PERIOD_CURRENT,period,MODE_EMA,VOLUME_TICK); handles[7] = iMomentum(Symbol(),PERIOD_CURRENT,period, PRICE_CLOSE); handles[8] = iRSI(Symbol(),PERIOD_CURRENT,period,PRICE_CLOSE); handles[9] = iWPR(Symbol(),PERIOD_CURRENT,period); for (int i=0; i<10; i++) { matrix_utiils.CopyBufferVector(handles[i],0,0,bars,buff_v); ind_Matrix.Col(buff_v, i); //store each indicator in ind_matrix columns }
Utilizei todos esses indicadores em um único gráfico. Aqui estão eles:

Por que todos parecem quase iguais? Vejamos sua matriz de correlação:
Print("Oscillators Correlation Matrix\n",ind_Matrix.CorrCoef(false));
Resultado
CS 0 18:03:44.405 PCA Test (NAS100,H1) Oscillators Correlation Matrix CS 0 18:03:44.405 PCA Test (NAS100,H1) [[1,0.01772984879133655,-0.01650305145071043,0.03046861668248528,0.2933315924162302,0.09724971519249033,-0.054459564042778,-0.0441397473782667,0.2171969726706487,0.3071254662907512] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.01772984879133655,1,0.6291675928958272,0.2432064602541826,0.7433991440764224,0.7857575973967624,0.8482060554701495,0.8438879842180333,0.8287766948950483,0.7510097635884428] CS 0 18:03:44.405 PCA Test (NAS100,H1) [-0.01650305145071043,0.6291675928958272,1,0.80889919514547,0.3583185473647767,0.79950773673123,0.4295059398014639,0.7482107564439531,0.8205910850439753,0.5941794310595322] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.03046861668248528,0.2432064602541826,0.80889919514547,1,0.03576792595345671,0.436675349452699,0.08175026884450357,0.3082792264724234,0.5314362133025707,0.2271361556104472] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.2933315924162302,0.7433991440764224,0.3583185473647767,0.03576792595345671,1,0.6368513319457978,0.701918992559641,0.6677393692960837,0.7952832674277922,0.8844891719743937] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.09724971519249033,0.7857575973967624,0.79950773673123,0.436675349452699,0.6368513319457978,1,0.6425071357003039,0.9239712092224102,0.8809179254503203,0.7999862160768584] CS 0 18:03:44.405 PCA Test (NAS100,H1) [-0.054459564042778,0.8482060554701495,0.4295059398014639,0.08175026884450357,0.701918992559641,0.6425071357003039,1,0.7573281438252102,0.7142333470379938,0.6534102287503526] CS 0 18:03:44.405 PCA Test (NAS100,H1) [-0.0441397473782667,0.8438879842180333,0.7482107564439531,0.3082792264724234,0.6677393692960837,0.9239712092224102,0.7573281438252102,1,0.8565660350098397,0.8221821793990941] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.2171969726706487,0.8287766948950483,0.8205910850439753,0.5314362133025707,0.7952832674277922,0.8809179254503203,0.7142333470379938,0.8565660350098397,1,0.8866871375902136] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.3071254662907512,0.7510097635884428,0.5941794310595322,0.2271361556104472,0.8844891719743937,0.7999862160768584,0.6534102287503526,0.8221821793990941,0.8866871375902136,1]]
Pela análise da matriz de correlação, podemos ver que apenas alguns indicadores estão correlacionados com outros, mas esses são poucos, portanto, não são idênticos. Vamos aplicar a análise de componentes principais a essa matriz e ver o que ela nos revela.
pca = new Cpca(ind_Matrix); matrix pca_matrix = pca.ExtractComponents(ENUM_CRITERION);Selecionei o critério do gráfico de declive:

O gráfico deixa claro que apenas três componentes principais foram selecionados, e o gráfico a seguir os mostra:
CS 0 15:03:30.992 PCA Test (NAS100,H1) PCA'S CS 0 15:03:30.992 PCA Test (NAS100,H1) [[-2.297373513063062,0.8489493134565058,0.02832445955171548] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-2.370488225540198,0.9122356709081817,-0.1170316144060158] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-2.728297784013197,1.066014896296926,-0.2859442064697605] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-1.818906988827231,1.177846546204641,-0.748128826146959] ... ... CS 0 15:03:30.992 PCA Test (NAS100,H1) [-3.26602969252589,0.4816995789189212,-0.7408982990360158] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-3.810781495417407,0.4426824869307094,-0.5737277071364888…]
Há somente 3 das 10 variáveis que havia!
É por isso que é muito importante ser não apenas um trader, mas também um analista. Tenho visto com frequência traders com muitos indicadores no gráfico e, às vezes, até mesmo em EAs. Acho que é importante usar essa forma de reduzir as variáveis como recurso para economizar custos de computação. A propósito, não entenda isso como um conselho de negociação. Se o que você está fazendo funciona e você está satisfeito, então não há nada com que se preocupar.
Vamos visualizar esses componentes principais para ver como eles ficam no mesmo eixo.
plt.ScatterCurvePlotsMatrix("pca's ",pca_matrix,"var","PCA");
Resultado

Vantagens da análise de componentes principais
- Redução da dimensionalidade: esse método pode reduzir efetivamente o número de variáveis em um conjunto de dados e, ao mesmo tempo, reter as informações mais importantes. Isso pode simplificar a análise e a visualização dos dados, economizar recursos computacionais e melhorar o desempenho do modelo.
- Compactação de dados: esse método pode ser usado para compactar com eficiência grandes conjuntos de dados até menos componentes principais, o que pode economizar espaço de armazenamento e reduzir o tempo de transferência de dados.
- Eliminação de ruídos: esse método pode remover ruídos ou variâncias aleatórias nos dados para se concentrar nos padrões ou tendências mais significativos. Como você acabou de ver, os 10 osciladores tinham muito ruído.
- Resultados interpretáveis: os componentes principais resultantes podem ser facilmente interpretados e visualizados, o que é útil para entender a estrutura dos dados.
- Normalização de dados: o método padroniza os dados reduzindo-os à variância unitária para eliminar os efeitos das diferenças na escala das variáveis e melhorar a precisão dos modelos.
Desvantagens da análise de componentes principais.
- Perda de dados: esse método pode descartar muitos componentes principais ou deixar aqueles que não abrangem a diversidade dos dados.
- A interpretação dos resultados pode ser difícil porque é difícil entender o que são as variáveis, especialmente quando as variáveis iniciais são altamente correlacionadas ou quando são obtidos muitos componentes principais.
- Sensibilidade a valor atípicos: como muitos métodos de ML, os valores atípicos podem distorcer o algoritmo e levar a resultados tendenciosos.
- Demanda grandes recursos computacionais. Quanto a um grande conjunto de dados, o método de componentes principais pode criar o mesmo problema que está tentando resolver.
- O método pressupõe que os dados estão linearmente relacionados e que os componentes principais não estão correlacionados, o que, de fato, nem sempre é verdade. E se esse não for o caso, os resultados não serão confiáveis.
Considerações finais
Por fim, a análise de componentes principais (PCA) é um método poderoso que pode ser usado para reduzir a dimensionalidade dos dados e, ao mesmo tempo, reter as informações mais importantes. Ao identificar os componentes principais de um conjunto de dados, podemos ter uma visão das estruturas básicas do mercado. Essa análise é amplamente utilizada fora do mercado, por exemplo, em engenharia e biologia. Embora seja um método matematicamente intensivo, suas vantagens fazem com que valha a pena. Com a abordagem correta e os dados corretos, o método pode ajudar a encontrar novas informações e tomar decisões de negociação informadas com base nos dados.
Acompanhe o desenvolvimento do assunto no meu repositório do GitHub em https://github.com/MegaJoctan/MALE5
| Arquivo | Descrição |
|---|---|
| matrix_utils.mqh | Contém funções de matriz adicionais |
| pca.mqh | Biblioteca principal de componentes principais |
| plots.mqh | Contém uma classe para ajudar a desenhar vetores |
| preprocessing.mqh | Biblioteca para preparar e dimensionar dados para algoritmos ML |
| PCA Test.mqh | Expert Advisor para testar o algoritmo e tudo discutido neste artigo |
Artigos relacionados:
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/12229
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Dúvidas: Quais são os indicadores que deram correlação inversa? Esse indicador pode variar de acordo com o ativo e de acordo com os parâmetros? Neste programa, você pode inserir outros indicadores no handler para avaliarmos juntos? Seus artigos são ótimos! Muito obrigado!
Dúvidas: 1 - Quais são os 3 indicadores? Eles são inversamente correlacionados entre si. Está correto? 2 - Tem como alterar o programa para inserir mais indicadores? Indicadores de tendência como média móvel e indicador de volume no programa? 3 - Esse resultado dos 3 indicadores muda para cada ativo, período de tempo e respectivos parâmetros?
Obrigado por ler meu artigo, há muitas ideias e indicadores para usar nesse programa. Não tenho como explorar todos eles, mas sugiro que você baixe o programa e brinque com ele, pois acredito que o artigo seja muito claro. Ninguém pode fazer o trabalho para você, especialmente para você, especialmente de graça.