
アルゴリズム取引戦略:AIで金市場の頂点を目指す
はじめに
機械学習手法が取引分野で有効であることが広く認識されるようになり、さまざまなアルゴリズムが生まれました。これらのアルゴリズムは、同じタスクに対して同様の性能を発揮しますが、基本的な仕組みは異なります。本記事でも金市場における一方向型のトレンドフォロー戦略を構築しますが、今回はクラスタリングアルゴリズムを使用します。
- 前回の記事では、同様の金のトレンド戦略を作成するための2種類の因果推論アルゴリズムが紹介されました。
- 時系列クラスタリングに関する記事では、取引タスクにおけるクラスタリングのさまざまな方法について解説しています。
- さらに、クラスタリングアルゴリズムを用いた平均回帰戦略の作成事例も公開されました。
- 今回のクラスタリングに基づくトレンドフォロー型取引システムの開発は、このアプローチの有用性をさらに明らかにしています。
このように、時系列データを多角的に分析・予測する重要なアプローチを考慮することで、従来の金融時系列の分析と予測のみを基にした取引システム作成法と比較し、利点や欠点を評価することが可能です。場合によっては、これらのアルゴリズムは非常に高い効果を発揮し、作成速度や生成される取引システムの品質の両面で、従来手法を上回ることもあります。
本記事では、一方向性取引戦略に焦点を当てます。この場合、アルゴリズムは買いまたは売りのいずれか一方向のポジションのみを保有します。基本アルゴリズムとしてCatBoostとK-Meansを使用します。CatBoostは、取引方向を判定する二値分類モデルとして機能します。一方、K-Meansは、前処理フェーズで市場のモードを判定するために使用されます。
作業準備とモジュールのインポート
import math import pandas as pd from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester_one_direction from bots.botlibs.export_lib import export_model_to_ONNX import time
このコードでは、信頼性があり、公開されている検証済みのパッケージのみを使用しています。
- Pandas:データテーブル(DataFrame)の操作を担当
- Scikit-learn:前処理や機械学習の各種機能を提供しており、クラスタリングアルゴリズムも含む
- CatBoost:Yandexが提供する強力な勾配ブースティングアルゴリズム
さらに、作成した個別モジュールもインポートしています。
- labeling_lib:取引にラベルを付与するためのサンプラー関数を含む
- tester_lib:機械学習ベースの戦略をテストするためのモジュール
- export_lib:学習済みモデルをONNX形式でMetaTrader 5にエクスポートするためのモジュール
データの取得と特徴量の作成
def get_prices() -> pd.DataFrame:
p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+')
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed')
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
return pFixed.dropna() このコードでは、ファイルから価格データ(クオート)を読み込む処理を実装しており、複数のデータソースからの取得を容易にしています。この際、終値のみを使用します。取得したデータに基づいて特徴量を生成します。
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1
特徴量は2つのグループに分けられます。
- 基本モデルの学習に用いる主要特徴量:取引の方向(売り/買い)を予測するモデルの学習に使用します。
- クラスタリング用のメタ特徴量(追加特徴量):元データを市場モード(クラスタ)に分類するために使用します。
この例では、ボラティリティ(一定期間の価格の標準偏差)を特徴量として使用しています。ただし、今後は移動平均や分布の歪度など、他の特徴量もテストする予定です。
市場モードのクラスタリング
def clustering(dataset, n_clusters: int) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] data['clusters'] = KMeans(n_clusters=n_clusters).fit(meta_X).labels_ return data
この関数は、価格データと特徴量を持つDataFrameを受け取り、追加のメタ特徴量を用いて指定された数のクラスタにクラスタリングします(通常は10程度のクラスタ数)。クラスタリングにはK-Meansアルゴリズムを使用します。その後、DataFrameの各行にクラスタラベルが付与されます。最終的に、clusters列を追加したDataFrameが返されます。
分類器を学習させる関数
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=500, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=300, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model_one_direction([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
学習には2つのモデルを使用します。1つ目は基本特徴量とラベルを用いて学習するモデル、2つ目はメタ特徴量とメタラベルを用いて学習するモデルです。1つ目のモデルでは、ラベルは取引の方向(Buy/Sell)です。2つ目のモデルでは、ラベルはクラスタ番号に基づき、データが対象クラスタに該当する場合は1、他のクラスタに該当する場合は0です。
学習前に、データは70/30の割合で学習用データと検証用データに分割されます。これは、CatBoostアルゴリズムの過学習を防ぐためです。学習中に検証データの誤差が改善されなくなった時点で、早期終了がおこなわれます。その後、検証データ上で最小の予測誤差を持つモデルが選択されます。
モデルを学習させた後は、テスト関数に渡して、決定係数を用いてバランスカーブを評価します。これは、モデルを後でソートし、最適なモデルを選択するために必要なステップです。
モデルテスト関数
def test_model_one_direction( result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): pr_tst = get_features(get_prices()) X = pr_tst[pr_tst.columns[1:]] X_meta = X.copy() X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X_meta)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(pr_tst, stop, take, forward, backward, markup, direction, plt)
この関数は、学習済みの2つのモデル(メインモデルとメタモデル)およびカスタム戦略テスターでのテストに必要な残りのパラメータを受け取ります。その後、再び価格と特徴量を含むDataFrameを作成し、これをモデルに渡して予測をおこないます。得られた予測結果は、DataFrameのlabels列およびmeta_labels列に格納されます。
最後に、プラグインモジュールtester_lib.py内にあるカスタムテスター関数が呼び出されます。学習済みモデルを履歴データに対してテストし、決定係数による性能評価を返します。
取引のラベル生成関数
labeling_lib.pyモジュールには、指定方向の取引のみをラベル付けするサンプラーが含まれています。
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
メイン学習ループ
# LEARNING LOOP dataset = get_features(get_prices()) // getting prices and features models = [] // making empty list of models for i in range(1): // the loop sets how many training attempts need to be completed start_time = time.time() data = clustering(dataset, n_clusters=hyper_params['n_clusters']) // adding cluster numbers to data sorted_clusters = data['clusters'].unique() // defining unique clusters sorted_clusters.sort() // sorting clusters in ascending order for clust in sorted_clusters: // loop over all clusters clustered_data = data[data['clusters'] == clust].copy() // selecting data for single cluster if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) // checking for sufficiency of training samples continue clustered_data = get_labels_one_direction(clustered_data, // marking up trades for selected cluster markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1)// deleting closing prices and cluster numbers meta_data = data.copy() // creating data for meta-model meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) // marking up current cluster as "1" models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) // training models and adding them to list end_time = time.time() print("Execution time: ", end_time - start_time)
学習ループでは、これまでに説明したすべての関数が順番に使用されます。
- 価格データ(クオート)をファイルからDataFrameに読み込み、特徴量を作成します。
- 学習済みモデルを格納する空のリストを作成します。
- 同じデータで複数回学習をおこない、モデルのランダムなばらつきの影響を抑えます。
- メタ特徴量に基づいてクラスタリングをおこない、DataFrameにclusters列を追加します。
- ループ内で、各クラスタごとにそのクラスタに属するデータのみを選択します。
- 各クラスタのデータに対してラベル付けをおこない、メインモデル用のクラスラベルを作成します。
- メタモデル用の追加データセットを作成し、対象クラスタを他のクラスタと区別するための学習に使用します。
- これら2つのデータセットを学習関数に渡し、2つの分類器(メインモデルとメタモデル)を学習させます。
- 学習済みモデルは、作成したリストに追加されます。
モデルの学習およびテストプロセス
アルゴリズムのハイパーパラメータ(全体設定)は、以下の辞書にまとめられています。
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 10,
} 学習期間は2020年から2024年までとし、テスト期間は2024年初頭から現在までとします。
特に重要なのは、以下のパラメータを正しく設定することです。
- markup - 0.2:XAUUSDにおける平均スプレッドを表します。スプレッドを小さくしすぎたり大きくしすぎたりすると、テスト結果が現実的でなくなる可能性があります。また、スリッページや手数料などの追加コストがある場合も、ここに含めます。
- stop_loss:ポイント単位での銘柄のストップロス幅です。
- take_profit:ポイント単位でのテイクプロフィット幅です。なお、ポジションはモデルのシグナルに反した場合だけでなく、ストップロスまたはテイクプロフィットに到達した場合にも決済されます。
- periods:主要特徴量用の期間リストです。一般的には、5から開始し、30刻みで約10個の期間を設定すれば十分です。
- periods_meta:メタ特徴量用の期間リストです。市場モードを識別するために多数の特徴量は必要ありません。通常は、直近5本のバーに対する標準偏差など、1つの指標で十分です。
- direction:今回は金市場に上昇トレンドが見られるため、「buy」のみを使用します。
- n_clusters:クラスタリングにおけるモード(クラスタ)の数です。通常は10を使用します。
標準偏差を使用した学習
まずは、特徴量として標準偏差のみを使用します。そのため、特徴量作成関数は次のようになります。
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
1回の学習ループを実行すると、以下のような情報が得られます。
Iteration: 0, Cluster: 0 R2: 0.989543793954197 Iteration: 0, Cluster: 1 R2: 0.9697821077241253 too few samples: 19 too few samples: 238 Iteration: 0, Cluster: 4 R2: 0.9852770333065658 Iteration: 0, Cluster: 5 R2: 0.7723040599270985 too few samples: 87 Iteration: 0, Cluster: 7 R2: 0.9970885055361235 Iteration: 0, Cluster: 8 R2: 0.9524980839809385 too few samples: 446 Execution time: 2.140070915222168
10個の市場モード(クラスタ)に対して、10個のモデルを学習する試みがおこなわれました。しかし、すべてのモードが有効だったわけではありません。いくつかのクラスタでは、学習サンプル(取引数)が少なすぎました。そのため、最小取引数のフィルタを通過できず、学習には使用されませんでした。
最も良い結果を示したのはクラスタ番号7で、R² = 0.99という非常に高い値を記録しました。これは、最良の取引モデル候補として非常に有望です。また、学習ループ全体の実行時間はわずか2秒でした。非常に高速であることが分かります。
モデルをソートした後、最良モデルをテストします。
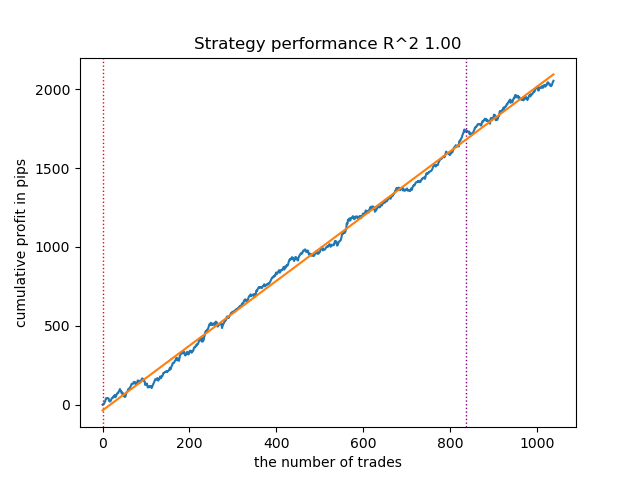
図1:ソート後の最良モデルのテスト結果
次点のモデルも、取引回数が多く、非常に良好な結果を示しました。
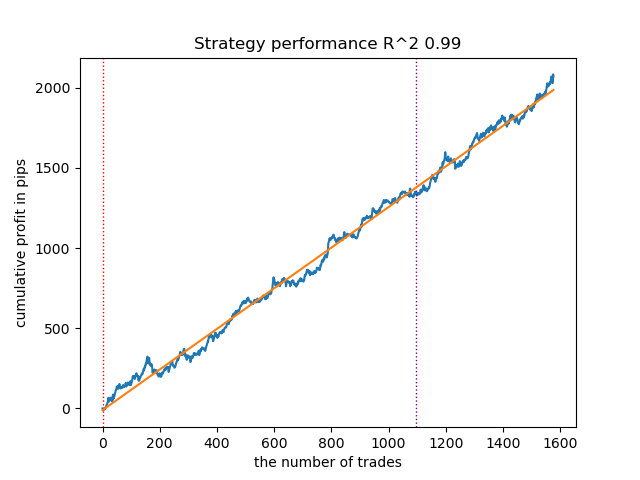
図2:2位モデルのテスト結果
モデルの学習とテストが非常に高速であるため、ループを何度も再実行して、より高品質なモデルを探すことが可能です。たとえば、再度ループを実行してソートした結果、次のようなバリエーションが得られました。
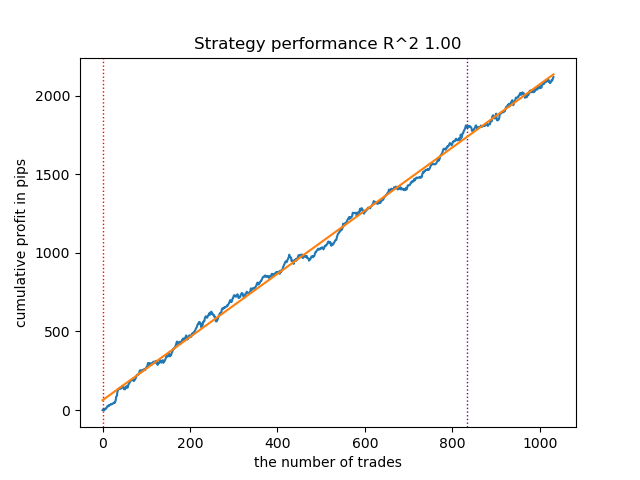
図3:再学習後の最良モデルのテスト結果
移動平均と標準偏差を用いた学習
それでは特徴量を変更し、モデルのパフォーマンスがどのように変化するかを確認してみます。
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).mean() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
単純移動平均をメインの特徴量として使用し、標準偏差をメタ特徴量として使用します。
学習ループを開始し、最良のモデルを検討します。
Iteration: 0, Cluster: 0 R2: 0.9312180471969619 Iteration: 0, Cluster: 1 R2: 0.9839766532391275 too few samples: 101 Iteration: 0, Cluster: 3 R2: 0.9643925934007344 too few samples: 299 Iteration: 0, Cluster: 5 R2: 0.9960009821184868 too few samples: 19 Iteration: 0, Cluster: 7 R2: 0.9557947960449501 Iteration: 0, Cluster: 8 R2: 0.9747160963596306 Iteration: 0, Cluster: 9 R2: 0.5526910449937035 Execution time: 2.8627688884735107
テスターで最適なモデルは次のようになります。
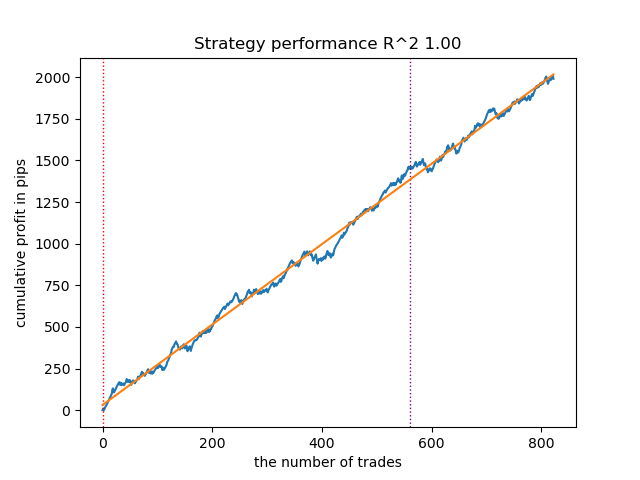
図4:移動平均を用いた最良モデルのテスト結果
第2位のモデルも良好なパフォーマンスを示しています。
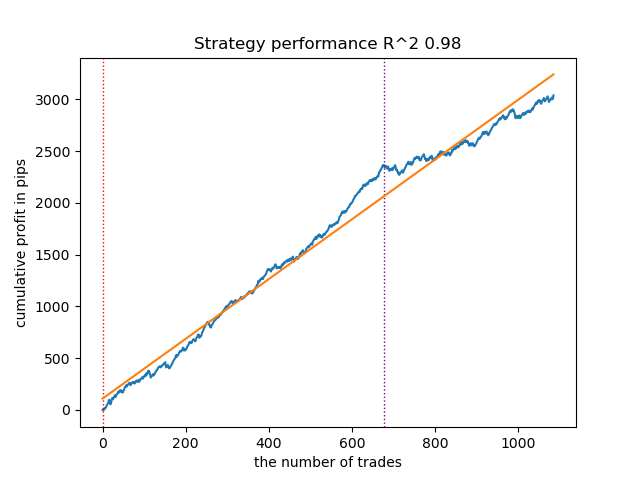
図5:移動平均を用いた第2位モデルのテスト結果
学習ループをさらに数回再実行した結果、より滑らかなバランス曲線を持つモデルが得られました。
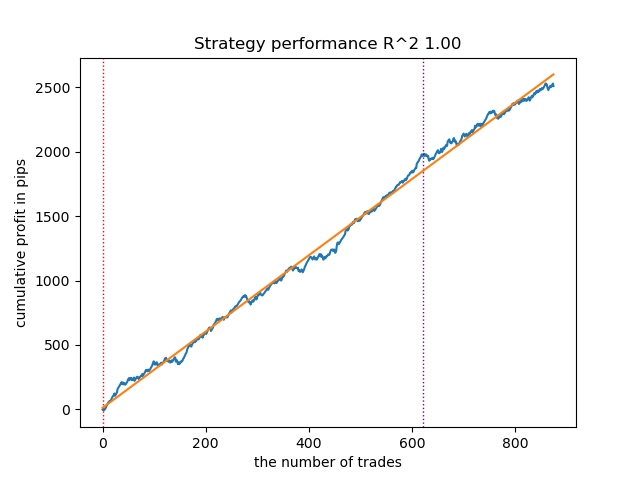
図6:再学習後の最良モデルのテスト結果
今回は特徴量の数(期間リスト)は特に最適化していません。そのため、期間の組み合わせを変更することで、さらに多様なモデルを生成することが可能です。提示したスクリーンショットは、あくまでその一部のバリエーションを示したものです。
過学習との戦い
モデルが過度に複雑になると、汎化性能が低下することがあります。これは、バリデーションフェーズやアーリーストッピングをおこなっている場合でも起こり得ます。このような場合は、特徴量の数を減らす、モデルを単純化するといった対策を試すことができます。CatBoostアルゴリズムにおける「モデルの複雑さ」とは、主に反復回数、つまり逐次的に構築される決定木の本数を指します。fit_final_models()関数内で、以下の値を変更してみてください。
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.8, test_size=0.2, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.8, test_size=0.2, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False)
ここでは、iterationsを100に削減し、early_stopping_roundsを15に設定しています。これにより、より単純なモデルを構築できるようになります。
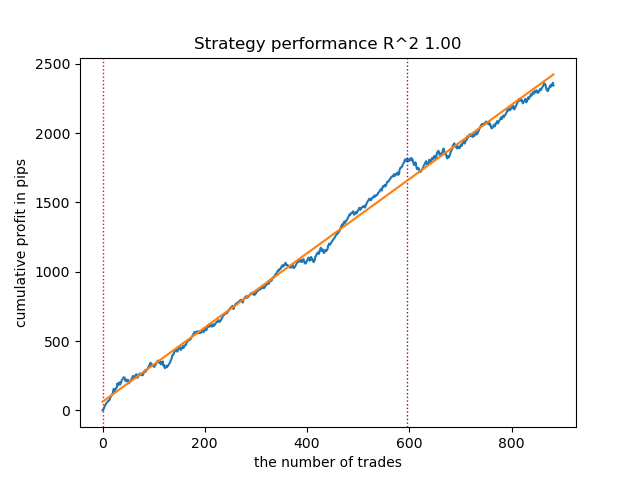
図7:複雑さを抑えたモデルのテスト結果
MetaTrader 5ターミナルへのモデルのエクスポート
export_lib()モジュールのexport_model_to_ONNX()関数には、次の文字列が含まれています。
# get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathMean(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathSkewness(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n'
ハイライトされている行は、MQL5コード内で特徴量を計算する部分に対応しています。Pythonスクリプトのget_features()関数で前述のように特徴量を変更した場合は、このMQL5コード内の計算も必ず変更する必要があります。あるいは、すでにエクスポート済みの.mqhファイル内で修正しても構いません。
たとえば、エクスポートされたXAUUSD_H1 ONNX include 0.mqhファイルでは、次の部分を修正します。
#include <Math\Stat\Math.mqh> #resource "catmodel XAUUSD_H1 0.onnx" as uchar ExtModel_XAUUSD_H1_0[] #resource "catmodel_m XAUUSD_H1 0.onnx" as uchar ExtModel2_XAUUSD_H1_0[] int PeriodsXAUUSD_H1_0[10] = {5,35,65,95,125,155,185,215,245,275}; int Periods_mXAUUSD_H1_0[1] = {5}; void fill_araysXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(PeriodsXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,PeriodsXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); // ret[0] = MathMean(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); } void fill_arays_mXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods_mXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods_mXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
現在のコードでは、get_features()関数で標準偏差のみを使用していた場合に対応するようになっています。移動平均を使用している場合は、MathStandardDeviation()をMathMean()に置き換えてください。
コンパイル後、すでにボットをMetaTrader 5上でテストできます。
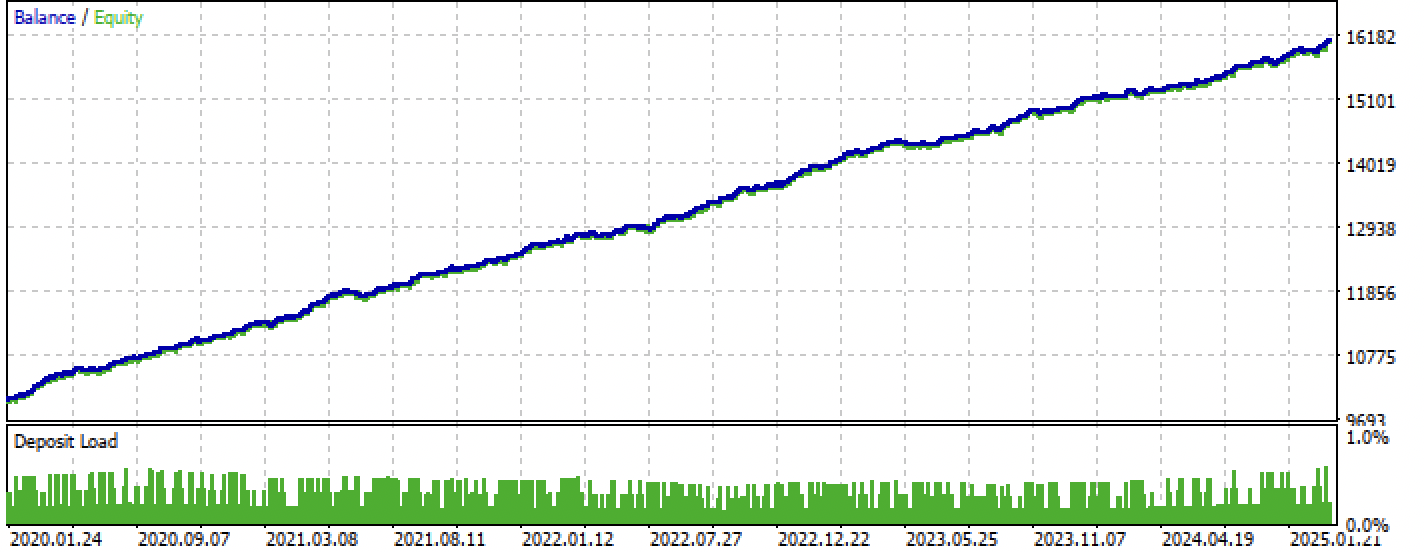
図8:学習+フォワード期間でのテスト結果
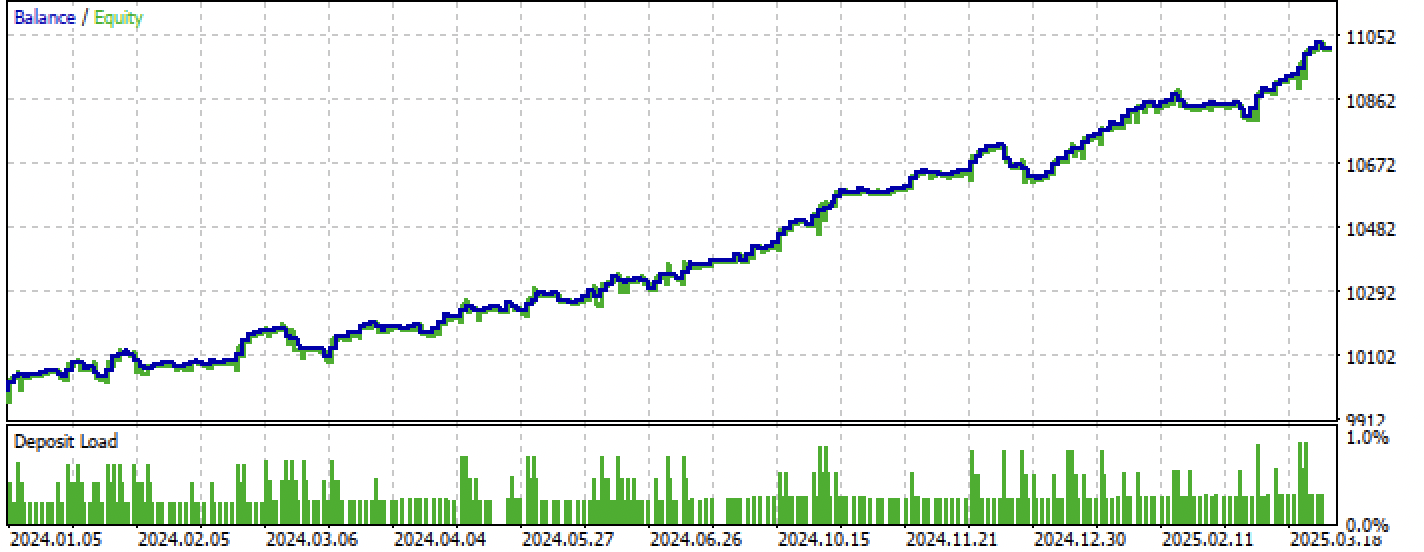
図9:フォワード期間のみでのテスト結果
結論
本記事では、クラスタリングに基づく一方向トレンド戦略の別の構築方法を示しました。このアプローチの主な特徴は、直感的であることと学習速度が非常に速いことです。得られるモデルの品質は、前回の記事で紹介した手法と同等レベルです。
Python files.zipアーカイブには、以下のPythonでの開発用のファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| one direction clusters.py | 学習モデルのメインスクリプト |
| labeling_lib.py | ラベル付けロジックを更新したモジュール |
| tester_lib.py | 機械学習ベース戦略用に更新されたカスタムテスター |
| export_lib.py | モデルをターミナルにエクスポートするモジュール |
| XAUUSD_H1.csv | MetaTrader 5ターミナルからエクスポートした価格データファイル |
MQL5 files.zipアーカイブには、MetaTrader 5用のファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| one direction clusters.ex5 | 記事で作成したボットのコンパイル済みファイル |
| one direction clusters.mq5 | 記事のボットのソースコード |
| Include//Trend following(フォルダ) | ONNXモデルおよびボット接続用ヘッダファイルの配置フォルダ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17755
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
つまり、R2は修正指数であり、その効率はpipsの利益に基づいています。ドローダウンやその他のパフォーマンス指標はどうでしょうか?トレーニングで90%以上、テストで85%以上の結果を出すモデルがあれば、その指標は印象的な数字になるでしょう。MT5で何度テスターを実行しても、履歴で利益を得たことがありません。入金は途絶えています。Pythonのテスターでは0.97-0.98の利益を出しているにもかかわらずです。
これがCVと何の関係があるのか理解できません。
これらの戦略はすべて、非定常相場の履歴のみに基づいているため、証明力が低い。しかし、トレンドを捉えることはできる。では、AIはどこにいるのか?キャットバストはこのレベルまでアップグレードしたのか?それとも、観客をおびき寄せるためのよくあるマーケティングのトリックなのだろうか?
私はこの奇妙な機能に、異なる著者による最近のいくつかの出版物で気づいている。
キャットバスト以外にまともなモデルはいないのだろうか?
では、AIはどこにいるのか?キャットバストはこのレベルまでアップグレードしたのか?それとも、これは観客をおびき寄せるためのよくあるマーケティング・ギミックなのか?
私はこの奇妙な機能に、異なる著者による最近のいくつかの出版物で気づいた。
catbust以外にまともなモデルはないのだろうか?
クリックベイト(一般的な略語)。私はこの言葉の支持者ではまったくない。
人々はMOを "AI "と呼ぶことに慣れている。それにTCは、クラスタリングや分類など、さまざまなMOアルゴリズムの複合体だ。