
算法交易策略:人工智能(AI)铸就的“点金”之路
概述
随着对机器学习方法在交易领域应用能力认知的不断深入,各种不同的算法应运而生。这些算法在执行相同任务时表现相似,但内在逻辑却截然不同。本文仍以黄金为例,探讨一种单向趋势交易系统,此次将重点应用聚类算法。
- 前一篇文章介绍了两种因果推断算法,构建了相似的黄金趋势策略。
- 关于时间序列聚类的文章探讨了交易任务中不同的聚类方法。
- 此前已向大家展示了使用聚类算法创建的均值回归策略。
- 基于聚类的趋势交易系统的开发,也凸显了该方法的优势所在。
从不同角度对这种重要的时间序列分析与预测方法进行考量,我们能够确定,与仅基于金融时间序列分析与预测来创建交易系统的其他方法相比,该方法具有哪些优势和劣势。在某些情况下,相当有效,在交易系统的创建速度和最终质量方面均超越了传统方法。
在本文中,我们将聚焦于单向交易,即算法仅进行买入或卖出交易操作。我们将采用CatBoost和K-Means算法作为基础算法。CatBoost作为基础模型执行二元分类,用于判定交易方向。而K-Means则用于预处理阶段的市场模式识别。
准备工作与模块导入
import math import pandas as pd from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester_one_direction from bots.botlibs.export_lib import export_model_to_ONNX import time
该代码仅使用可靠且经过验证的公开可用软件包,例如:
- Pandas —— 用于处理数据表(数据帧)
- Scikit-learn —— 包含各种用于数据预处理和机器学习的函数,包括聚类算法
- CatBoost —— 来自Yandex的强大梯度提升算法
导入自行创建的各个模块:
- labeling_lib —— 包含用于标记交易的采样器函数
- tester_lib —— 包含基于机器学习的策略测试器
- export_lib —— 一个用于将训练好的模型以ONNX格式导出到Meta Trader 5的模块
获取数据并创建特征
def get_prices() -> pd.DataFrame:
p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+')
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed')
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
return pFixed.dropna() 此段代码实现了从文件中下载行情报价的功能,以便于从不同来源获取数据。代码仅使用收盘价数据。基于这些数据进一步生成特征。
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1
将特征分为两组:
- 训练基础模型的主要特征,用于预测交易方向。
- 聚类附加的元特征。用于将源数据划分为不同的簇(即市场模式)。
本例中,我们将波动率(即给定周期滑动窗口内的价格标准差)作为特征。此外,我们也将测试移动平均线和分布偏度等其他特征。
市场模式聚类
def clustering(dataset, n_clusters: int) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] data['clusters'] = KMeans(n_clusters=n_clusters).fit(meta_X).labels_ return data
该函数接收一个包含价格和特征的数据帧,并利用附加的元特征将其聚类为指定数量的簇(通常为10个)。聚类过程采用K-Means算法。随后,为数据帧的每一行分配对应的簇标签。最终返回的数据帧将新增一列"clusters“。
用于训练分类器的函数
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=500, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=300, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model_one_direction([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
训练过程中使用两个模型。第一个模型基于基础特征和标签进行训练,第二个模型则基于元特征和元标签进行训练。对于第一个模型,标签为交易方向;对于第二个模型,标签为簇编号。如果数据属于指定簇,则标签为1,否则,标签为0。
训练前,数据按70/30的比例划分为训练集和验证集,以降低CatBoost算法的过拟合程度。该算法利用验证集实现早停机制 —— 当验证集误差不再下降时,训练即刻终止。接下来,在验证数据集上,选择预测误差最小的最优模型。
模型训练完成后,将其传入测试函数,通过R²指标评估资金曲线。这一步对后续的模型排序及优选至关重要。
模型测试函数
def test_model_one_direction( result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): pr_tst = get_features(get_prices()) X = pr_tst[pr_tst.columns[1:]] X_meta = X.copy() X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X_meta)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(pr_tst, stop, take, forward, backward, markup, direction, plt)
该函数接收两个已训练好的模型(主模型和元模型),以及自定义策略测试器所需的其他测试参数。接下来,重新生成包含价格和特征的数据帧,并传入这两个模型进行预测。将预测结果分别记录在该数据帧的“labels”和“meta_labels”列中。
最终,调用位于插件模块tester_lib.py中的自定义测试函数。该函数在历史数据上执行模型测试,并返回R²的评估结果。
交易标记函数
labeling_lib.py模块包含一个采样器,专为仅标记选定方向的交易而设计:
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
学习主循环
# LEARNING LOOP dataset = get_features(get_prices()) // getting prices and features models = [] // making empty list of models for i in range(1): // the loop sets how many training attempts need to be completed start_time = time.time() data = clustering(dataset, n_clusters=hyper_params['n_clusters']) // adding cluster numbers to data sorted_clusters = data['clusters'].unique() // defining unique clusters sorted_clusters.sort() // sorting clusters in ascending order for clust in sorted_clusters: // loop over all clusters clustered_data = data[data['clusters'] == clust].copy() // selecting data for single cluster if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) // checking for sufficiency of training samples continue clustered_data = get_labels_one_direction(clustered_data, // marking up trades for selected cluster markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1)// deleting closing prices and cluster numbers meta_data = data.copy() // creating data for meta-model meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) // marking up current cluster as "1" models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) // training models and adding them to list end_time = time.time() print("Execution time: ", end_time - start_time)
在训练循环中,将按顺序依次使用上述函数:
- 从文件中加载报价数据至数据帧,并生成特征。
- 创建一个空列表,用于存储训练好的模型。
- 设置同一数据上的训练迭代次数(尝试次数),以排除模型因随机性产生的波动。
- 对元特征进行聚类,并在数据中添加“clusters”列。
- 在循环中,针对每个簇单独选择属于该簇的数据。
- 对每个簇的数据进行标记(即为主模型创建类别标签)。
- 为元模型创建附加的数据集,使其学习从所有簇中识别特定簇。
- 将两个数据集传入训练函数,训练两个分类器。
- 将训练好的模型添加至列表中。
模型的学习与测试过程。
字典中包含算法超参数(通用设置):
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 10,
} 训练在2020年至2024年期间进行,测试期则从2024年初延续至今。
正确设置以下参数至关重要:
- markup:0.2 —— 黄金兑美元(XAUUSD)交易品种的平均点差。如果点差设置过小或过大,测试结果可能缺乏真实性。此外,还包含与滑点及手续费(如有)相关的额外损失。
- stop_loss —— 以品种点数表示的止损幅度。
- take_profit —— 以点数表示的止盈幅度。需要注意的是,交易既会根据模型信号平仓,也会在触及止损或止盈时平仓。
- periods —— 用于生成主特征的时间周期列表。通常设置10个周期即可,起始值为5,以30为步长递增。
- periods_meta —— 用于生成元特征的时间周期列表。识别市场模式无需大量特征。通常仅需一个指标,例如最近5根K线的标准差。
- direction —— 仅使用"买入"方向,因黄金呈现上升趋势。
- n_clusters —— 用于聚类分析的市场模式(簇)数量。通常设置为10。
基于标准差的训练方法
首先,我们仅使用标准差作为特征,因此特征生成函数将如下所示:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
启动一个训练循环,在此期间我们将获取以下信息:
Iteration: 0, Cluster: 0 R2: 0.989543793954197 Iteration: 0, Cluster: 1 R2: 0.9697821077241253 too few samples: 19 too few samples: 238 Iteration: 0, Cluster: 4 R2: 0.9852770333065658 Iteration: 0, Cluster: 5 R2: 0.7723040599270985 too few samples: 87 Iteration: 0, Cluster: 7 R2: 0.9970885055361235 Iteration: 0, Cluster: 8 R2: 0.9524980839809385 too few samples: 446 Execution time: 2.140070915222168
我们尝试针对十种市场模式训练了十个模型。但并非所有模式都具有实用价值,因为部分模式的训练样本(交易次数)过少。由于未能通过最低样本量筛选,因此未被用于训练。
编号为7的最优市场模式(簇)的R²值达到0.99。是优质交易模型的有力候选。整个训练循环的执行时间仅2秒,速度极快。
模型排序完成后,对最优模型进行测试:
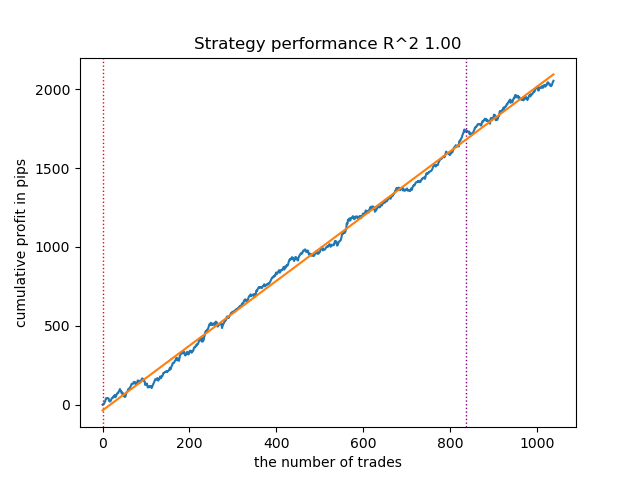
图例1. 测试排序后的最优模型
以下模型同样表现优异,且包含大量交易样本:
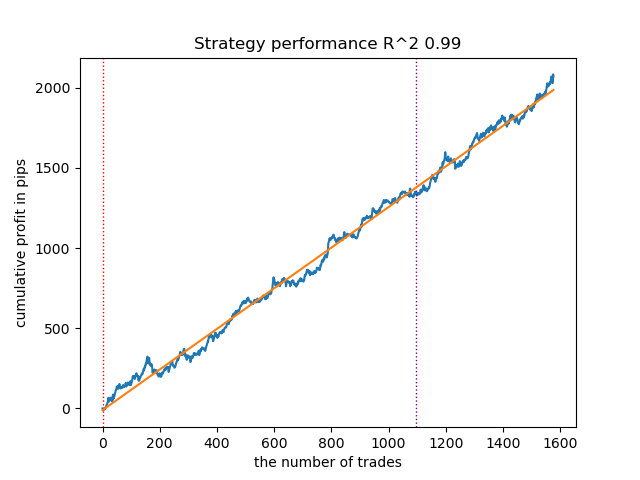
图例2. 测试排名第二的模型
由于模型训练和测试速度极快,您可以多次重启训练循环以获取更高质量的模型。例如,在下次重启并排序后,我们得到以下结果:
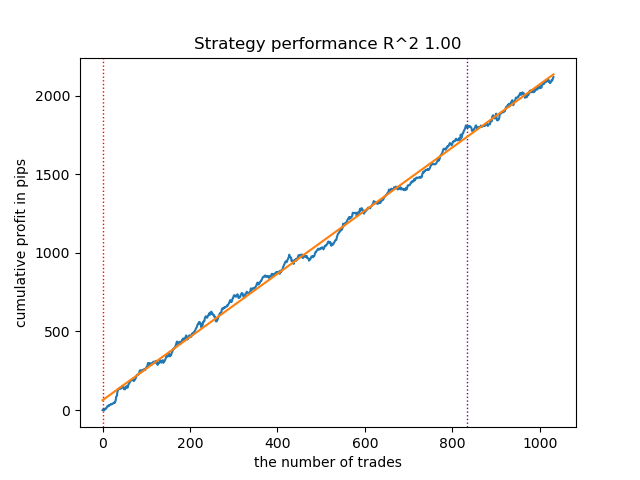
图例3. 测试多次训练循环后的最优模型
基于移动平均线和标准差的训练。
让我们更换特征组合,观察模型的表现如何。
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).mean() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
使用简单移动平均线作为主特征,标准差作为元特征。
启动训练循环并评估最优模型:
Iteration: 0, Cluster: 0 R2: 0.9312180471969619 Iteration: 0, Cluster: 1 R2: 0.9839766532391275 too few samples: 101 Iteration: 0, Cluster: 3 R2: 0.9643925934007344 too few samples: 299 Iteration: 0, Cluster: 5 R2: 0.9960009821184868 too few samples: 19 Iteration: 0, Cluster: 7 R2: 0.9557947960449501 Iteration: 0, Cluster: 8 R2: 0.9747160963596306 Iteration: 0, Cluster: 9 R2: 0.5526910449937035 Execution time: 2.8627688884735107
以下是该最优模型在测试器中的表现:
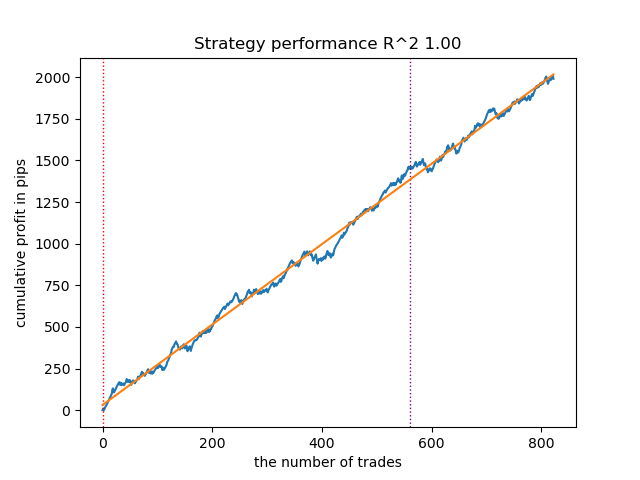
图例 4. 测试基于移动平均线的最优模型
次优模型同样表现出色:
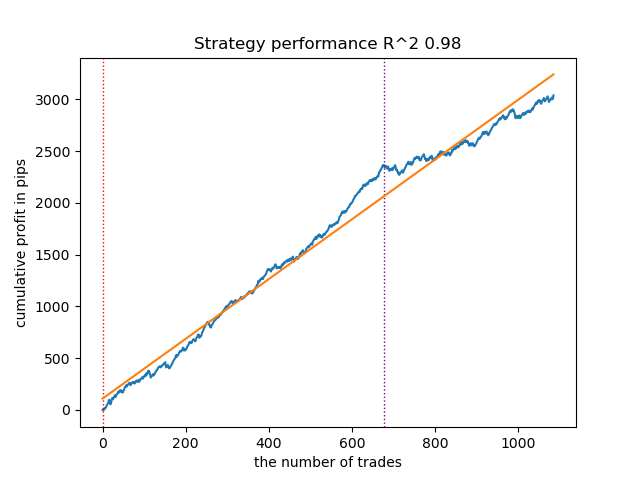
图例 5. 测试基于移动平均线的次优模型
通过重启几次训练循环,获得更精确的资金曲线图:
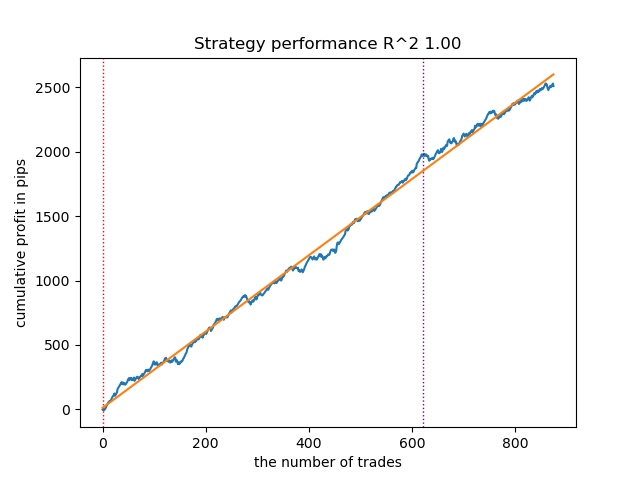
图例 6. 测试多次训练循环后的最优模型
在此阶段,我并未对特征数量(及其周期参数列表)进行系统性实验,因此实际上可生成多种不同模型。提供的截图仅展示了部分变体示例。
对抗过拟合
模型过度复杂往往会削弱其泛化能力。即使已通过验证阶段和早停机制控制。在此情况下,您可以尝试减少特征数量或简化模型结构。在CatBoost算法中,模型复杂度由迭代次数或顺序构建决策树的数量决定。在fit_final_models()函数中,可以尝试调整以下参数:
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.8, test_size=0.2, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.8, test_size=0.2, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False)
将迭代次数降至100,早停阈值设置为15。这将有助于构建复杂度更低的模型。
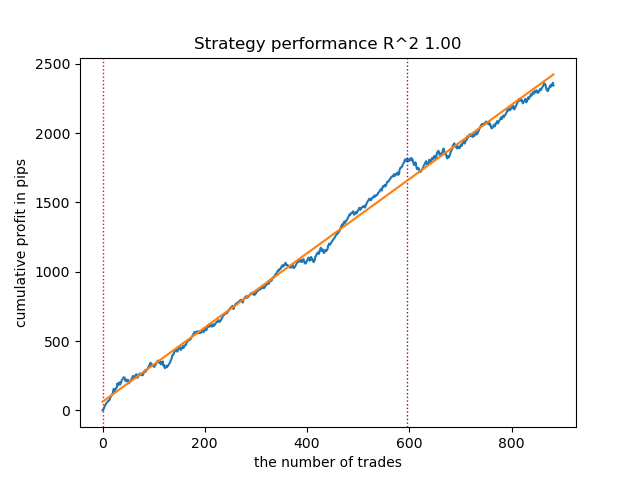
图例 7. 测试低“复杂度”模型
将模型导出至MetaTrader 5交易终端。
来自export_lib模块的export_model_to_ONNX()函数包含以下代码段:
# get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathMean(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathSkewness(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n'
在MQL5代码中,高亮显示的代码段负责计算特征值。如果您按照上述说明修改了Python脚本中 get_features()函数内的特征定义,则必须同步更新此MQL5代码中的计算逻辑,或直接在已导出的.mqh文件中进行修改。
例如,在导出的XAUUSD_H1 ONNX include 0.mqh文件中,修正以下代码段:
#include <Math\Stat\Math.mqh> #resource "catmodel XAUUSD_H1 0.onnx" as uchar ExtModel_XAUUSD_H1_0[] #resource "catmodel_m XAUUSD_H1 0.onnx" as uchar ExtModel2_XAUUSD_H1_0[] int PeriodsXAUUSD_H1_0[10] = {5,35,65,95,125,155,185,215,245,275}; int Periods_mXAUUSD_H1_0[1] = {5}; void fill_araysXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(PeriodsXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,PeriodsXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); // ret[0] = MathMean(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); } void fill_arays_mXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods_mXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods_mXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
当前特征计算逻辑与仅使用标准差的get_features()函数保持一致。如果原代码中使用了移动平均线,请将其替换为MathMean()。
编译完成后,即可在MetaTrader 5中测试交易EA。
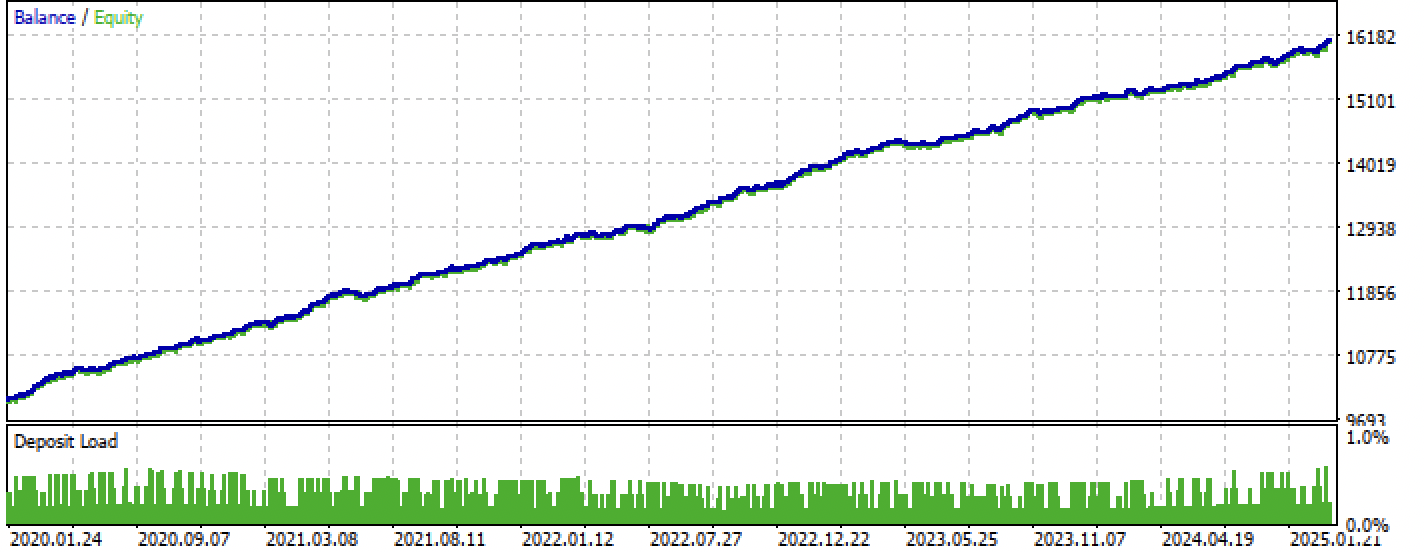
图例 8. 在训练集+前瞻区间上测试
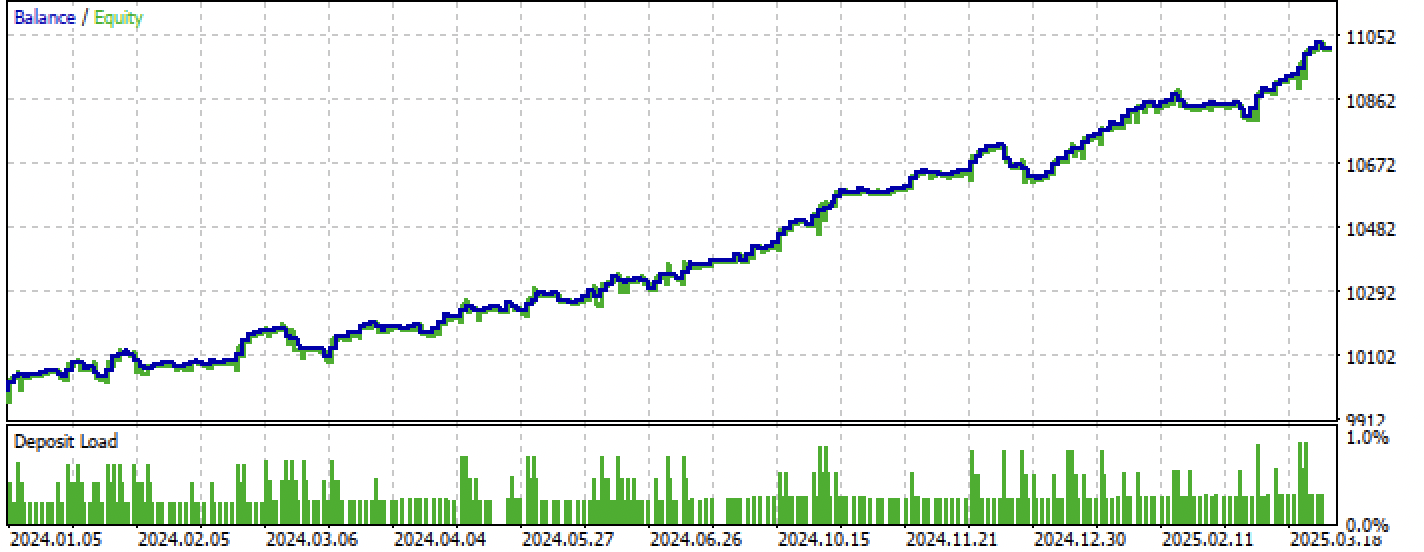
图例 9. 仅在前瞻区间上测试
结论
本文展示了另一种基于聚类分析构建单向趋势交易策略的方法。该方法的核心优势在于直观性强且学习效率高。最终生成的模型质量与前文所述方法相当。
Python开发文件压缩包Python files.zip包含以下文件:
| 文件名 | 描述 |
|---|---|
| one direction clusters.py | 学习模型的主脚本 |
| labeling_lib.py | 带交易标记的模块(更新版) |
| tester_lib.py | 基于机器学习策略的定制化回测模块(更新版) |
| export_lib.py | 用于将模型导出至交易终端的模块 |
| XAUUSD_H1.csv | 从MetaTrader 5终端导出的行情数据文件 |
MQL5 files.zip压缩包包含以下MetaTrader 5专用文件:
| 文件名 | 描述 |
|---|---|
| one direction clusters.ex5 | 本文中编译后的EA |
| one direction clusters.mq5 | 本文中EA的源代码 |
| folder Include//Trend following | ONNX模型文件及连接EA头文件的存放位置 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/17755
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
因此,R2 是一个修正指数,其效率基于点数利润。那么缩水和其他性能指标呢?如果我们的模型在训练中的收益率超过 90%,在测试中的收益率至少达到 85%,那么您的指数就会给出令人印象深刻的数据。无论我在 MT5 上运行测试器多少次,我从未在历史记录上获得过利润。保证金被消耗殆尽。尽管您在 Python 上的测试器给出了 0.97-0.98 的收益,但还是出现了这种情况。
我不明白这与 CV 有什么关系。
所有这些策略的证明力都很低,因为它们只是基于非平稳报价的历史。但你可以捕捉趋势。人工智能在哪里?你们的猫步升级到这个水平了吗?还是这只是吸引读者的一种常见营销手段?
我在最近几本不同作者的出版物中都注意到了这个奇怪的功能。
难道除了 catbust 就没有像样的模型了吗?
人工智能在哪里?你们的猫步升级到这个水平了吗?还是这只是吸引观众的一个普通营销噱头?
我在最近几本不同作者的出版物中都注意到了这个奇怪的功能。
难道除了 catbust 就没有其他像样的模式了吗?
Clickbait(流行缩写)。我根本不赞成这个词。
人们习惯于将 MO 称为 "人工智能"。另外,TC 是不同 MO 算法的综合体,例如聚类和分类。