
マルコフ連鎖に基づく行列予測モデル

過去10年間において、ニューラルネットワークおよびディープラーニングの発展は目覚ましい成果を上げてきました。しかし、もしそれよりもさらに深いレベルの市場分析が存在するとしたらどうでしょうか。そこでは、高度な数学的構造が古典的なマルコフ理論と交わり、古来のフィボナッチ的調和が自己学習型の遺伝的アルゴリズムに織り込まれています。
金融市場は、カオスと秩序が入り混じって舞う万華鏡のような存在です。従来の統計的手法は市場の予測不可能性という岩礁でしばしば行き詰まり、一方でニューラルネットワークは高度であるにもかかわらず、その内部構造が「ブラックボックス」として扱われがちです。これら二つの極端の間には、中間的なアプローチとしての確率モデルが存在します。それは、市場は現在の状態を通じて過去の情報をある程度反映しているという考えに基づいています。本研究で扱う「マルコフ連鎖に基づく行列反復予測モデル」は、まさにそのようなモデルの一つです。
本モデルは、数学的確率論の美しさと機械学習の実用性を融合させ、市場を離散的な状態間の遷移系として表現します。本研究は、市場が一見ランダムに見えるにもかかわらず、テクニカル指標、時間サイクル、出来高のさまざまな組み合わせとして隠れたパターンが現れるという基本的な観察に基づいています。
数学的基礎:マルコフからウォール街へ
アンドレイ・マルコフは20世紀初頭の著名な数学者であり、確率論の研究の中で、100年後に現代金融数学の基礎の一つとなる概念を確立しました。確率過程の理論を発展させる過程で彼は、将来がシステムの現在の状態のみに依存し、過去の履歴には依存しないような事象の列を研究しました。この基本的な性質、すなわち現在よりも過去に関する「記憶を持たない」という性質は「マルコフ性」と呼ばれ、広範なモデルの基礎となっています。
マルコフ連鎖とは、確率的な規則に従ってある状態から別の状態へ遷移する数学的システムです。システムの取り得る状態を空間上の点として考えると、マルコフ連鎖はそれらの間の遷移確率を記述するものとなります。この概念の驚くほど洗練されている点は、非常に単純な確率的メカニズムによって極めて複雑な過程をモデル化できる点にあります。
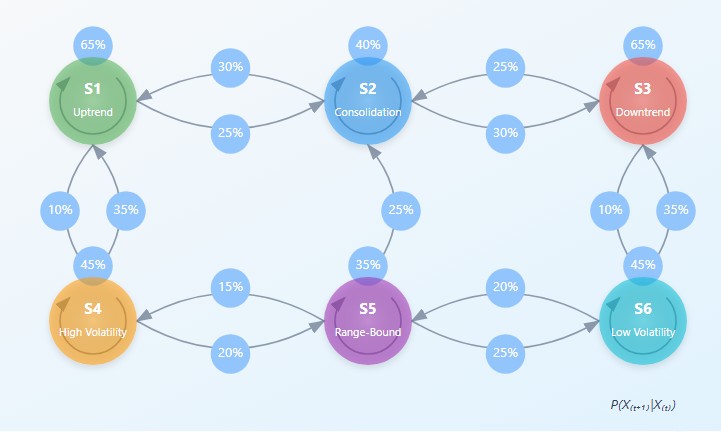
数学的には、マルコフ連鎖は遷移確率行列Pによって定義されます。ここで要素P(i,j)は、状態iから状態jへ遷移する確率を表します。マルコフ連鎖の基本方程式は以下のように表されます。
π(t+1) = π(t) · P ここで、π(t)は、時刻tにおける各状態にシステムが存在する確率を表す確率ベクトルです。
離散状態から連続プロセスへ
古典的なマルコフ連鎖は離散的な状態および離散時間を扱うため、価格水準、市場レジーム、あるいは取引セッションといったシステムのモデル化に適しています。しかし、マルコフ過程の理論は離散モデルに限定されるものではありません。連続マルコフ過程も存在し、その代表例がウィーナー過程です。これはブラウン運動の数学モデルであり、有名なブラック=ショールズのオプション価格評価モデルの基礎を成しています。
隠れマルコフモデルは、システムの真の状態が直接観測できず、間接的な観測のみが利用可能である場合における重要な拡張です。これは金融市場において特に重要であり、市場の真の「レジーム」(たとえば「強気トレンド」や「レンジ相場(保ち合い)」)は直接観測できず、価格変動や出来高といった観測データから推定する必要があります。
金融市場はマルコフモデルの適用にとって理想的な検証環境を提供します。弱形効率的市場仮説は、将来の価格は過去の価格から予測できないと主張しており、これは価格系列に対してマルコフ性が成立することを事実上仮定しています。市場が完全にマルコフ過程に従うかどうかは議論の余地がありますが、多くの実務的問題においてマルコフ近似が非常に高い精度を示すことが経験的に確認されています。
トレーディングの文脈において、マルコフモデルはさまざまな領域で応用されています。
- 価格変動予測:過去の市場遷移統計を用いて将来の価格変動の確率を推定します。
- 市場レジーム検出:現在の市場状態をトレンド相場、レンジ相場、遷移状態として自動分類します。
- トレーディングシステムの最適化:識別された市場状態に応じて戦略パラメータを調整します。
- リスク評価:現在の状態と既知の遷移統計に基づき、大きな価格変動の確率を算出します。
遷移行列:市場確率の代数
マルコフモデルの中心的要素は遷移行列です。これは、行が現在の状態、列が将来の状態に対応し、各要素が対応する遷移確率を表す表形式の行列です。市場をn個の状態に分割した場合、遷移行列Pはn×nのサイズを持ち、各行の総和は1となります(システムは必ずいずれかの状態へ遷移するためです)。
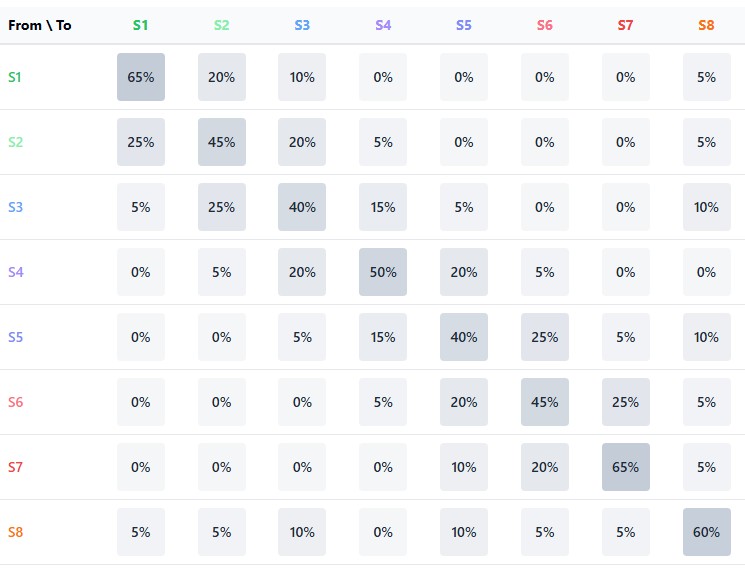
このマルコフ的アプローチの強みは、この行列を反復的に適用することで、多段階先の予測を得ることができる点にあります。状態iから状態jへのkステップ後の遷移確率は、行列P^k(Pのk乗)の対応要素として計算されます。これにより多段階先の予測が可能になりますが、予測ホライズンが延びるにつれて精度は通常低下します。
特に興味深いのは、k→∞におけるマルコフ連鎖の極限挙動であり、これは状態確率の長期的な平衡分布を記述します。エルゴード性マルコフ連鎖(任意の状態から他の任意の状態へ有限ステップで到達可能な連鎖)においては、以下を満たす一意な定常分布π*が存在します。
π* = π* · P
この定常分布は、初期状態に依存せず、システムが長期的に各状態に滞在する割合を示します。金融市場においては、これは外生的ショックが存在しない場合の市場レジームの本質的構造として解釈することができます。
理論から実践へ:マルコフモデルの学習
金融市場におけるマルコフモデルの実装には、主に2つの課題があります。それは、状態の決定と遷移確率の推定です。
状態の決定は、さまざまな方法でおこなうことができます。
- 専門家定義アプローチ:専門アナリストによって設定されたテクニカル指標や閾値に基づき状態を定義する方法です。
- クラスタリング:K平均法や階層クラスタリングなどのアルゴリズムを用いて、多次元の市場特徴空間における自然なグルーピングを自動的に抽出する方法です。
- 量子化:連続的な指標を離散的なレベルに分割し、それらの組み合わせとして状態を形成する方法です。
本研究では、価格、時間、出来高といった要因グループごとにK平均クラスタリングを個別に適用することで、状態の解釈可能性を維持しつつ、データから効率的に状態を抽出する手法を採用しています。
def create_state_clusters(feature_groups, n_clusters_per_group=3): for group_name, group_data in feature_groups.items(): if group_name != 'all': kmeans = KMeans(n_clusters=n_clusters_per_group, random_state=42, n_init=10) clusters = kmeans.fit_predict(group_data['data']) group_clusters[group_name] = clusters kmeans_models[group_name] = kmeans遷移確率は、過去データにおける対応する事象の出現頻度に基づいて推定されます。
for i in range(len(states) - 1): curr_state = states[i] next_state = states[i + 1] # Increase the transition counter transition_matrix[curr_state, next_state] += 1 # If the next candle is bullish, increase the rise counter if i + 1 < len(labels) and labels[i + 1] == 1: rise_matrix[curr_state, next_state] += 1 # Normalization of the transition matrix for i in range(9): row_sum = np.sum(transition_matrix[i, :]) if row_sum > 0: state_transitions[i, :] = transition_matrix[i, :] / row_sum
このプロセスは統計的に有意な推定を得るために十分な履歴データを必要とします。特に希少な遷移に関しては、データスパース性の問題が発生します。この問題は、単純な擬似カウントの追加から、モデルパラメータに事前分布を導入するベイズ的アプローチまで、さまざまな平滑化手法によって対処されます。
市場の三要因:価格、時間、出来高
従来の市場分析では、価格のダイナミクスのみに焦点を当てることが一般的でした。しかし、市場は本質的に多次元的な現象であり、価格はあくまで氷山の一角にすぎません。本手法では、市場データを相互に関連する3つの要素群に分解して捉えます。
- 価格指標は、トレンド、移動平均、オシレーター、ローソク足パターンなど、従来のテクニカル分析ツールを含みます。これは「市場で何が起きているのか」という問いに答えるものです。
- 時間サイクルは、市場の季節性を異なるスケールで捉えるもので、イントラデイセッションから月次サイクルまでを含みます。これは「重要な値動きがいつ発生しやすいのか」という問いに答えます。
- 出来高指標は、市場参加者の活動の強度と性質を反映し、ティックボリュームの動態や、蓄積・分配を示す特殊な指標などを含みます。これにより、価格変動が「どのように、そしてなぜ起きているのか」を明らかにします。
この3要素を統合的に扱うことで、異なる市場ダイナミクスの側面同士の微妙な相互作用を把握することが可能になります。コードはこの情報を以下のように抽出します。
def add_indicators(df): # --- PRICE INDICATORS --- df['ema_9'] = df['close'].ewm(span=9, adjust=False).mean() df['ema_21'] = df['close'].ewm(span=21, adjust=False).mean() df['ema_50'] = df['close'].ewm(span=50, adjust=False).mean() df['ema_cross_9_21'] = (df['ema_9'] > df['ema_21']).astype(int) df['ema_cross_21_50'] = (df['ema_21'] > df['ema_50']).astype(int) # --- TIME INDICATORS --- df['hour'] = df['time'].dt.hour df['day_of_week'] = df['time'].dt.dayofweek df['hour_sin'] = np.sin(2 * np.pi * df['hour'] / 24) df['hour_cos'] = np.cos(2 * np.pi * df['hour'] / 24) # --- VOLUME INDICATORS --- df['tick_volume'] = df['tick_volume'].astype(float) df['volume_change'] = df['tick_volume'].pct_change(1) df['volume_ma_14'] = df['tick_volume'].rolling(14).mean() df['rel_volume'] = df['tick_volume'] / df['volume_ma_14']
このモデルでは、特に時間データの周期的表現を正弦・余弦変換によっておこなう点を重視しています。たとえば、1日の時刻はsin/cosの2次元座標へと変換されます。これにより、23:59と00:00の間に不連続性が生じることなく、日次サイクルをモデルが自然に捉えられるようになります。
カオスから秩序へ:市場状態の量子化
このモデルの中核的なアイデアは、連続的なデータから離散的な市場状態への遷移です。これは一種の「レジーム」であり、それぞれが固有の特徴と確率的な挙動を持ちます。そのために、各ファクターグループごとにK平均法を用いたクラスタリングを適用します:
def create_state_clusters(feature_groups, n_clusters_per_group=3): group_clusters = {} kmeans_models = {} for group_name, group_data in feature_groups.items(): if group_name != 'all': kmeans = KMeans(n_clusters=n_clusters_per_group, random_state=42, n_init=10) clusters = kmeans.fit_predict(group_data['data']) group_clusters[group_name] = clusters kmeans_models[group_name] = kmeans return group_clusters, kmeans_models
各特徴グループ(価格・時間・出来高)はそれぞれ3つのクラスタに分割されるため、理論的には27通りの市場状態が得られます。しかし、現行の実装では、モデルの複雑性と統計的推定の安定性のバランスを取るため、より重要な組み合わせのみを抽出した9つの状態のみを使用しています。このアプローチにより、モデルの詳細度と統計的ロバスト性の間で適切なトレードオフが実現されます。
クラスタリングの本質的な価値は、事前の仮定を一切置かずにデータの中に存在する自然なグルーピングを自動的に発見できる点にあります。たとえば、過去の価格データの構造だけを手がかりとして、高ボラティリティ局面、レンジ相場、トレンド相場といった期間をモデルが自律的に識別することが可能になります。
確率行列:予測の核心
このモデルの中心的な要素は2つの行列です。すなわち、状態間の遷移行列と、各遷移における上昇確率行列です。これらは合わせてマルコフ連鎖を形成しており、将来の状態は現在の状態のみに依存し、過去の履歴には依存しないという構造になっています。
def combine_state_clusters(group_clusters, labels): # Fill the transition matrix and rise matrix for i in range(len(states) - 1): curr_state = states[i] next_state = states[i + 1] # Increase the transition counter transition_matrix[curr_state, next_state] += 1 # If the next candle is bullish, increase the rise counter if i + 1 < len(labels) and labels[i + 1] == 1: rise_matrix[curr_state, next_state] += 1 # Normalization of the transition matrix state_transitions = np.zeros((9, 9)) for i in range(9): row_sum = np.sum(transition_matrix[i, :]) if row_sum > 0: state_transitions[i, :] = transition_matrix[i, :] / row_sum
遷移行列は、ある状態から別の状態へ移行する確率を含んでおり、市場のダイナミックな構造を反映します。たとえば、レンジ相場の後、市場は一定の確率でトレンド局面へ移行する場合もあれば、そのまま横ばい状態を継続する場合もあります。
一方、上昇確率行列はさらに一歩踏み込み、各状態遷移ごとに「次のローソク足が陽線となる確率(終値が始値より高い確率)」を示します。これにより、単に次の市場状態を予測するだけでなく、価格変動の方向性までも推定できるようになります。
これらの行列を可視化すると、興味深い市場パターンが明らかになります。たとえば、ある状態は高い確率で同じ状態に留まり続けることで安定したレジームを形成する一方で、別の状態は遷移性が高く、短期間で別のレジームへと移り変わる傾向を持ちます。このような遷移構造の非対称性こそが、市場ダイナミクスを理解する上での重要な鍵となります。
反復予測:多段階予測
マルコフモデルの真価は反復的な予測において発揮されます。ここでは、予測は単一の遷移に依存するのではなく、起こり得るすべての経路(トラジェクトリ)にわたる確率を重み付きで合算することで構築されます。
def predict_with_matrix(state_transitions, rise_probability_matrix, current_state): # Probabilities of transition to the next state next_state_probs = state_transitions[current_state, :] # Calculation of the weighted rise probability taking into account all possible transitions weighted_prob = 0 total_prob = 0 for next_state, prob in enumerate(next_state_probs): weighted_prob += prob * rise_probability_matrix[current_state, next_state] total_prob += prob # Normalization (if necessary) if total_prob > 0: weighted_prob = weighted_prob / total_prob # Forecast prediction = 1 if weighted_prob > 0.5 else 0 confidence = max(weighted_prob, 1 - weighted_prob)
バイナリな「上昇/下降」予測とは異なり、我々のモデルは予測に対する信頼度を含む、完全な確率的全体像を提供します。これは、適切なリスク管理を伴う意思決定をおこなう上で極めて重要です。
また、このモデルの反復的な性質は、直近の次のローソク足だけでなく、数ステップ先までのシナリオに対する確率ツリーを構築できる点にも表れています。このアプローチにより、単一ステップ予測では捉えられない長期的なトレンドを可視化できます。
意味の抽出:解釈可能性と透明性
マルコフモデルがニューラルネットワークの「ブラックボックス」と比較して持つ大きな利点の一つは、その完全な透明性と解釈可能性です。各状態および遷移には明確な統計的意味があり、単に予測結果を得るだけでなく、市場のロジックそのものを理解することが可能です。
各要因が状態分類に与える影響を分析することで、各種インジケーターの相対的重要度を明らかにできます。
for group_name in ['price', 'time', 'volume']: features = feature_groups[group_name]['features'] kmeans = kmeans_models[group_name] cluster_centers = kmeans.cluster_centers_ for cluster_idx in range(3): center = cluster_centers[cluster_idx] # We obtain the importance of each feature as its deviation from zero at the center of the cluster importances = np.abs(center) sorted_idx = np.argsort(-importances) top_features = [(features[i], importances[i]) for i in sorted_idx[:3]]
この情報により、トレーダーは現在の市場レジームにおいて最も重要なインジケーターに集中し、有意性の低い要因によるノイズを無視できるようになります。さらに、各状態の特性は、トレンド、レンジ相場、反転といった古典的な市場パターンと一致することが多く、統計モデリングと従来のテクニカル分析を橋渡しする役割を果たします。
二項分類を超えて:信頼度の段階的評価
金融分野における予測精度という概念には議論の余地があります。ランダムなモデルであっても、価格方向について50%程度の正答率を示すことがあります。本モデルの真価は、予測信頼度の段階的な分布を分析した際に明らかになります。
bins = [0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.0] confidence_groups = np.digitize(confidences, bins) accuracy_by_confidence = {} for bin_idx in range(1, len(bins)): bin_mask = (confidence_groups == bin_idx) if np.sum(bin_mask) > 0: bin_accuracy = np.mean([1 if predictions[i] == test_labels[i+1] else 0 for i in range(len(predictions)) if bin_mask[i] and i+1 < len(test_labels)]) accuracy_by_confidence[f"{bins[bin_idx-1]:.2f}-{bins[bin_idx]:.2f}"] = (bin_accuracy, np.sum(bin_mask))
この分析は、高い信頼度(>70%)を持つ予測が、68〜70%に達する精度を実現していることを示しています。これはランダム予測を大きく上回る結果であり、実運用のトレーディングにおいて極めて重要な優位性となります。これにより、最も期待値の高いシグナルに集中し、不確実な局面を回避することが可能になります。
特に重要なのは、高い予測信頼度が特定の市場状態と相関している点です。これにより、有利なトレーディング機会を、その形成初期段階で特定できるようになります。
実証結果:EUR/USDのテスト
本モデルは、最も流動性が高く、かつテクニカル分析上も複雑な金融商品であるEURUSD通貨ペアのヒストリカル1時間足データを用いて検証されました。学習には履歴データの80%を使用し、残り20%の時系列データをホールドアウト検証用として利用しました。
テストサンプルにおけるモデル全体の精度は約55%となり、同一ポジションサイズで取引した場合の理論上の損益分岐点を有意に上回る結果となりました。さらに、高信頼度予測(分布の上位四分位)に限定すると、精度は65〜70%に達しました。
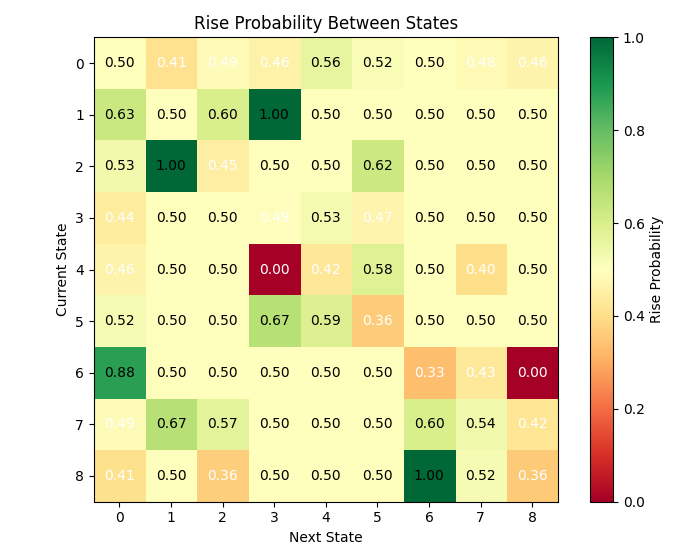
ご覧の通り、多くの状態が比較的高い遷移確率を示しています。これは、行列ベースの予測モデルにとって課題と見なせるのでしょうか。
状態分析の結果、興味深いパターンが明らかになりました。一部の状態は、価格が特定方向へ動く強い傾向を持っています。たとえば、状態3(高い相対ボラティリティ、欧州取引セッション、そして出来高減少を特徴とする状態)は、60%以上の確率で価格上昇を示しました。
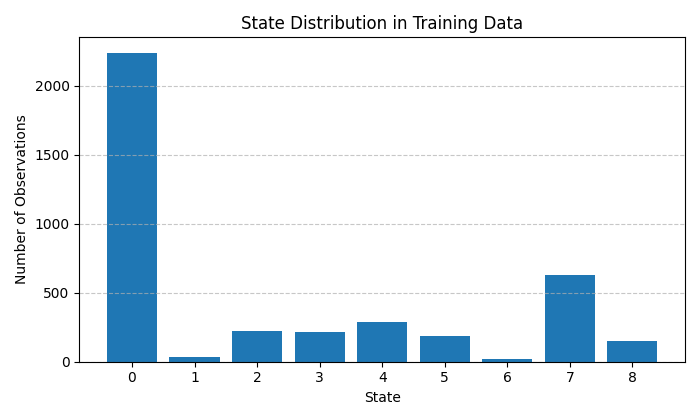
以下のチャートは、RSIおよびモメンタムのクラスタリング結果を示しています。
バイナリな予測を超えて:実用的な応用例
本記事では、価格方向に対するバイナリ予測に焦点を当てていますが、マルコフモデルはそれを遥かに超える応用可能性を備えています。以下は、その代表的な活用例です。
- マルチクラス分類:単なる方向予測ではなく、値動きの規模まで予測します(大幅上昇、中程度上昇、横ばい、中程度下落、大幅下落など)。
- 市場レジーム検出:現在の市場状態を自動分類し、それに応じてトレーディング戦略を適応させます。
- シグナルフィルタリング:従来のテクニカルシグナルに対する追加フィルターとしてモデルを活用し、シグナルの精度と特異性を向上させます。
- ボラティリティ評価:方向だけでなく期待ボラティリティも予測することで、適切なポジションサイズ設定やストップロス設計を可能にします。
現在のモデル実装は、まだ出発点に過ぎません。今後の有望な発展領域として、以下が挙げられます。
- 適応型クラスタリング:クラスタ品質指標に基づき、各特徴量グループに対する最適クラスタ数を動的に決定します。
- ファンダメンタルデータとの統合:マクロ経済指標やニュースセンチメントを追加要因群として取り込みます。
- 階層型マルコフモデル:異なる時間軸間における状態依存性を考慮し、マルチスケール予測を実現します。
- 適応学習:最新市場データに基づいて遷移行列を継続的に更新し、市場レジーム変化へ適応します。
結論:確率によってカオスを制御する
金融市場は、決定論的カオスと確率的秩序の狭間で揺れ動いています。マルコフ連鎖行列反復モデルは、統計的アプローチの厳密性とテクニカル分析の実践的ニュアンスを融合する、極めて洗練された妥協点を提供します。
機械学習の「ブラックボックス」とは異なり、このモデルは市場ダイナミクスを完全に透明かつ解釈可能な形で提示します。市場を、離散状態間を遷移する確率システムとして表現することで、数学的厳密性と実務的直感の双方を満たしています。この考え方は、市場レジームやその遷移という観点で相場を捉える経験豊富なトレーダーにとって、特に直感的に理解しやすいものです。
EUR/USD通貨ペアに対する実証結果は、特に高信頼度予測において、本モデルが実運用レベルのポテンシャルを持つことを示しています。今後さらに発展を重ねることで、より高い精度と汎用性が期待されます。
最終的に、マルコフモデルは、市場の見かけ上の混沌の中にも構造とパターンが存在することを私たちに思い出させます。そして未来が決して完全には確定しないからこそ、確率論的思考こそが、市場の不確実性という海を航行するための最良の道具となるのです。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/18097
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
よくやった!特に、価格、時間、出来高に分けた 方法が気に入りました。EUR/USDでのテストは有望に見えます。
しかし、 Covid時のような 急激な相場変動時にモデルはどのように振る舞うのでしょうか?トランジション・マトリックスが過去のデータに基づいて構築されている場合、そのような極端な状況にどのように適応できるのでしょうか?
このモデルがEUR/USD以外のペアで テストされた のかどうかも知りたい。ボラティリティの急激な変化に対する適応メカニズムは組み込まれているのか?マクロニュースのようなファンダメンタルズ要因を考慮する予定はありますか?