
Trading con algoritmos: La IA y su camino hacia las alturas doradas
Introducción
La evolución en la comprensión de las capacidades de los métodos de aprendizaje automático en el trading ha llevado a la creación de diferentes algoritmos que son igual de buenos en la misma tarea, pero fundamentalmente diferentes. En este artículo volveremos a analizar un sistema comercial de tendencia unidireccional utilizando el oro como ejemplo, pero empleando un algoritmo de clusterización.
- En el artículo de la semana pasada describimos dos algoritmos de inferencia causal para crear una estrategia de tendencia similar para el oro.
- En el artículo sobre clusterización de series temporales, analizamos diferentes formas de clusterización en tareas comerciales.
- Con anterioridad ya presentamos la creación de una estrategia de reversión a la media utilizando un algoritmo de clusterización.
- El desarrollo de un sistema comercial de tendencias basado en la clusterización también ha puesto de relieve el potencial de este enfoque.
Al examinar este importante enfoque del análisis y la previsión de series temporales desde distintos ángulos, es posible identificar sus ventajas e inconvenientes en comparación con otras formas de creación de sistemas comerciales basados únicamente en el análisis y la previsión de series temporales financieras. En algunos casos, estos algoritmos resultan bastante eficaces y superan a los enfoques clásicos tanto en velocidad de creación como en la calidad de los sistemas comerciales a la salida.
En este artículo, nos centraremos en el trading unidireccional, en el que el algoritmo solo abrirá operaciones de compra o venta. Utilizaremos los algoritmos CatBoost y K-Means como algoritmos de base. CatBoost es un modelo básico que actúa como clasificador binario para clasificar las transacciones. K-Means, por su parte, se usa para identificar los modos de mercado durante la fase de preprocesamiento.
Preparación del trabajo e importación de módulos
import math import pandas as pd from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester_one_direction from bots.botlibs.export_lib import export_model_to_ONNX import time
El código usa únicamente paquetes fiables a disposición del público, como:
- Pandas — responsable de trabajar con tablas de datos (dataframes)
- Scikit-learn — contiene diversas funciones de preprocesamiento y aprendizaje automático, incluidos algoritmos de clusterización.
- CatBoost — un potente algoritmo de refuerzo por gradiente de la empresa Yandex
Hemos importado los módulos individuales creados por el autor:
- labelling_lib — contiene funciones de muestreo para operaciones de etiquetado
- tester_lib — contiene simuladores de estrategias basadas en aprendizaje automático
- export_lib — módulo para exportar los modelos entrenados al terminal Meta Trader 5 en formato ONNX
Obtención de datos y creación de características
def get_prices() -> pd.DataFrame:
p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+')
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed')
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
return pFixed.dropna() El código implementa la carga de cotizaciones desde un archivo para facilitar la obtención de datos de distintas fuentes. Solo se utilizan los precios de cierre. Las características se crean a partir de estos datos.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1
Las características se dividen en dos grupos:
- Las características clave para entrenar un modelo básico que prediga la dirección de una operación.
- Las meta-características adicionales para la clusterización. Estas se utilizan para dividir los datos de origen en grupos (modos de mercado).
En este ejemplo, la volatilidad (desviaciones estándar de los precios en ventanas deslizantes de un periodo determinado) se usará como características. Pero probaremos otras señales, como las medias móviles y las inclinaciones de las distribuciones.
Clusterización de los modos de mercado
def clustering(dataset, n_clusters: int) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] data['clusters'] = KMeans(n_clusters=n_clusters).fit(meta_X).labels_ return data
La función recibe un marco de datos con precios y características y utiliza meta-características adicionales para la clusterización en un número determinado de clústeres (normalmente 10). Para la clusterización se utiliza el algoritmo K-Means. Después, a cada fila del marco de datos se le asignará una etiqueta de clúster que se corresponderá con esa observación. Y se devolverá un marco de datos con una columna adicional "clusters".
Función de entrenamiento de clasificadores
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=500, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=300, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model_one_direction([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
Para el entrenamiento se usan dos modelos. El primero se entrena con características y etiquetas básicas, mientras que el segundo se entrena con meta-características y meta-etiquetas. En el primer modelo las etiquetas son direcciones de transacción, y en el segundo las etiquetas son números de clúster. 1 — si los datos coinciden con el clúster requerido, y 0 — si los datos coinciden con todos los demás clústeres.
Antes del entrenamiento, los datos se dividen en datos de entrenamiento y datos de validación en una proporción de 70/30 para garantizar que el algoritmo CatBoost tenga menos probabilidades de sobreentrenarse. Este utiliza los datos de validación para detenerse anticipadamente cuando el error en ellos deje de disminuir durante el entrenamiento. A continuación, se selecciona el mejor modelo con el menor error de predicción en los datos de validación.
Una vez entrenados los modelos, se transmiten a la función de prueba para estimar la curva de balance mediante R^2. Esto es necesario para seguir clasificando los modelos y elegir el mejor.
Función de prueba de modelos
def test_model_one_direction( result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): pr_tst = get_features(get_prices()) X = pr_tst[pr_tst.columns[1:]] X_meta = X.copy() X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X_meta)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(pr_tst, stop, take, forward, backward, markup, direction, plt)
La función acepta dos modelos entrenados (un modelo principal y un metamodelo), así como los demás parámetros necesarios para realizar pruebas en el simulador de estrategias personalizado. A continuación, se crea un marco de datos con precios y características que son introducidos en estos modelos para realizar predicciones. Las predicciones resultantes se registran en las columnas "labels" y "meta_labels" del presente marco de datos.
Al final, se llama a una función de prueba personalizada, que se encuentra en el complemento tester_lib.py, y que prueba los modelos en la historia y devuelve la puntuación R^2.
Función de marcado de transacciones
El módulo labelling_lib.py contiene un muestreador diseñado para etiquetar transacciones solo en la dirección seleccionada:
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Ciclo de entrenamiento básico
# LEARNING LOOP dataset = get_features(get_prices()) // получение цен и признаков models = [] // создание пустого списка моделей for i in range(1): // цикл задает сколько попыток обучения нужно выполнить start_time = time.time() data = clustering(dataset, n_clusters=hyper_params['n_clusters']) // добавление номеров кластеров к данным sorted_clusters = data['clusters'].unique() // определение уникальных кластеров sorted_clusters.sort() // сортировка кластеров по возрастанию for clust in sorted_clusters: // цикл по всем кластерам clustered_data = data[data['clusters'] == clust].copy() // выбор данных для одного гластера if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) // проверка на достаточность обучающих примеров continue clustered_data = get_labels_one_direction(clustered_data, // разметка сделок для выбранного кластера markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1)// удаление цен закрытия и номеров кластеров meta_data = data.copy() // создание данных для мета-модели meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) // размтка текущего кластера как "1" models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) // обучение моделей и добавление их в список end_time = time.time() print("Время выполнения: ", end_time - start_time)
En el ciclo de entrenamiento, todas las funciones descritas anteriormente se utilizan de forma secuencial:
- Las cotizaciones se cargan desde el archivo al marco de datos y luego se crean las características
- Después se crea una lista vacía que almacenará los modelos entrenados
- Para eliminar las fluctuaciones aleatorias de los modelos, se fija el número de iteraciones (intentos) de entrenamiento sobre los mismos
- Asimismo, se agrupan los meta-características y se añade una columna "clusters" a los datos.
- En el ciclo, para cada clúster se seleccionan los datos que solo pertenecen a él
- Luego se etiquetan los datos de cada clúster, es decir, se crean etiquetas de clase para el modelo básico.
- Después se crea un conjunto de datos adicional para el metamodelo, que aprende a identificar un clúster determinado a partir de todos los demás
- Ambos conjuntos de datos se transmiten a la función de entrenamiento, que realiza el entrenamiento de los dos clasificadores
- Los modelos entrenados se añaden a la lista
El proceso de entrenamiento y prueba de modelos
Los hiperparámetros (ajustes generales) del algoritmo se colocan en el diccionario:
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 10,
} El entrenamiento tendrá lugar entre 2020 y 2024, con un periodo de prueba desde principios de 2024 hasta la actualidad.
Es muy importante configurar correctamente los siguientes parámetros:
- markup — 0.2 es el spread medio del símbolo XAUUSD. Si ajustamos un margen demasiado pequeño o demasiado grande, los resultados de la prueba podrían no ser realistas. Además, también se incluyen las pérdidas adicionales asociadas a los desvíos y las comisiones, si las hubiera.
- stop loss — tamaño del stop en puntos del símbolo.
- take profit — take profit en pips. Debemos considerar que las operaciones se cierran tanto con las señales del modelo como cuando se alcanza el stop-loss o el take-profit.
- periods — lista con los valores de los periodos para las características principales. En general, bastarán diez periodos, empezando por cinco y en incrementos de 30.
- periods meta — lista con valores de periodos para las meta-características. No será necesario un gran número de características para definir los modos de mercado. Suele ser una única característica, como la desviación típica de las últimas 5 barras.
- direction — usaremos solo "buy", porque el oro está en una tendencia alcista.
- n_clusters — número de modos (clústeres) para la clusterización. Solemos usar 10.
Entrenamiento sobre desviaciones típicas
Al principio solo usaremos desviaciones estándar como características, por lo que la función de creación de características tendrá este aspecto:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Realizaremos un ciclo de entrenamiento, durante el cual obtendremos la siguiente información:
Iteration: 0, Cluster: 0 R2: 0.989543793954197 Iteration: 0, Cluster: 1 R2: 0.9697821077241253 too few samples: 19 too few samples: 238 Iteration: 0, Cluster: 4 R2: 0.9852770333065658 Iteration: 0, Cluster: 5 R2: 0.7723040599270985 too few samples: 87 Iteration: 0, Cluster: 7 R2: 0.9970885055361235 Iteration: 0, Cluster: 8 R2: 0.9524980839809385 too few samples: 446 Время выполнения: 2.140070915222168
Hemos intentado entrenar diez modelos para diez modos de mercado. No todos los modos han sido útiles porque algunos de ellos contienen muy pocos ejemplos de entrenamiento (transacciones). No han superado el filtro para el número mínimo de operaciones, por lo que no se han utilizado para el entrenamiento.
El mejor modo de mercado (clúster) número 7 ha mostrado R^2 0,99. Este es un buen candidato para el mejor modelo de negociación. El tiempo de ejecución de todo el ciclo de entrenamiento ha sido de solo 2 segundos, lo que es muy rápido.
Después de clasificar los modelos, probaremos el mejor:
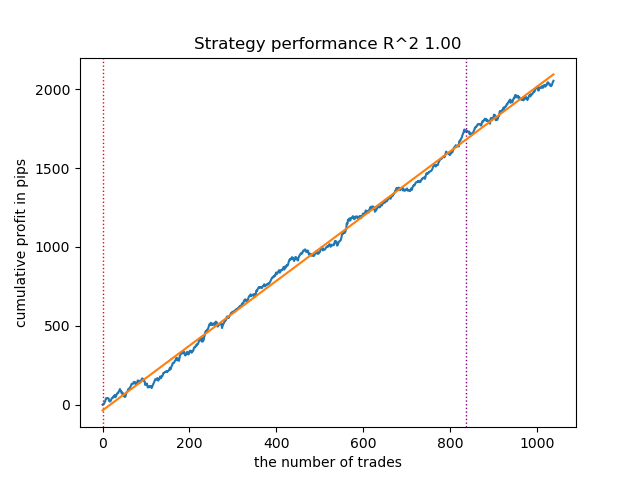
Fig. 1. Comprobación del mejor modelo tras la clasificación
El patrón que sigue también ha demostrado ser bastante bueno y tiene un gran número de transacciones:
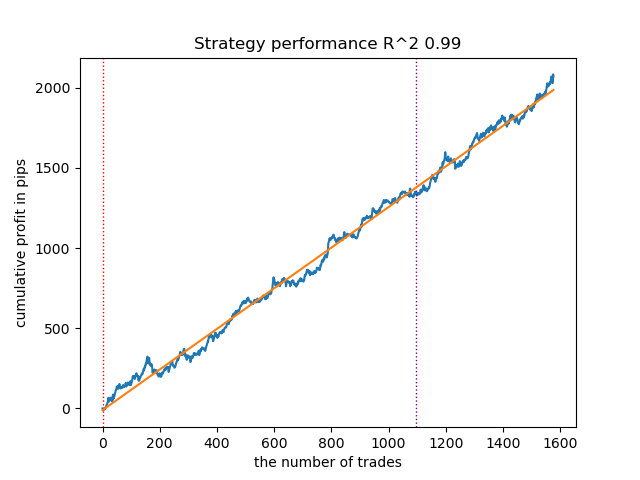
Fig. 2. Comprobación del segundo modelo de la clasificación
Como el entrenamiento y las pruebas de los modelos son muy rápidos, podemos reiniciar el ciclo muchas veces, obteniendo modelos de la mayor calidad posible. Por ejemplo, tras el siguiente reinicio y clasificación, ha quedado así:
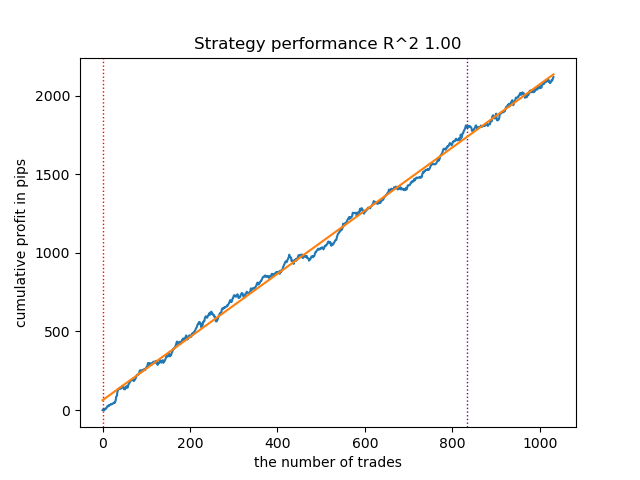
Fig. 3. Prueba del mejor modelo tras un ciclo de entrenamiento repetido
Entrenamiento sobre medias móviles y desviaciones típicas
Vamos a cambiar de signo y veamos cómo se comportan los modelos.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).mean() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Usaremos medias móviles simples como características principales, y desviaciones estándar como meta-características.
Luego iniciaremos un ciclo de aprendizaje y veremos los mejores modelos:
Iteration: 0, Cluster: 0 R2: 0.9312180471969619 Iteration: 0, Cluster: 1 R2: 0.9839766532391275 too few samples: 101 Iteration: 0, Cluster: 3 R2: 0.9643925934007344 too few samples: 299 Iteration: 0, Cluster: 5 R2: 0.9960009821184868 too few samples: 19 Iteration: 0, Cluster: 7 R2: 0.9557947960449501 Iteration: 0, Cluster: 8 R2: 0.9747160963596306 Iteration: 0, Cluster: 9 R2: 0.5526910449937035 Время выполнения: 2.8627688884735107
Este es el aspecto del mejor modelo en el simulador:
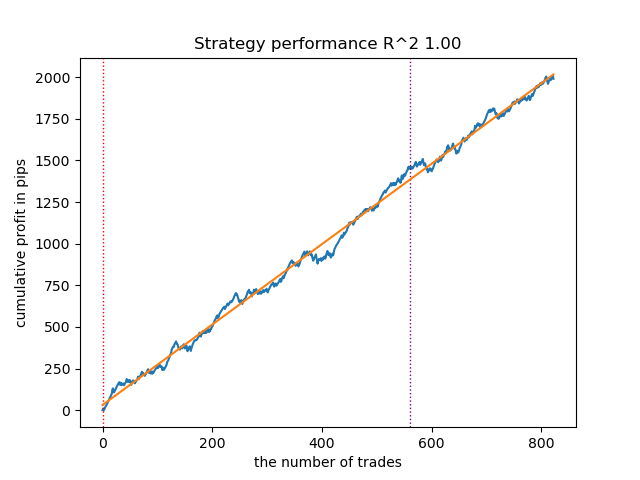
Figura 4. Prueba del mejor modelo de medias móviles
El segundo modelo de mayor calidad también obtiene buenos resultados:
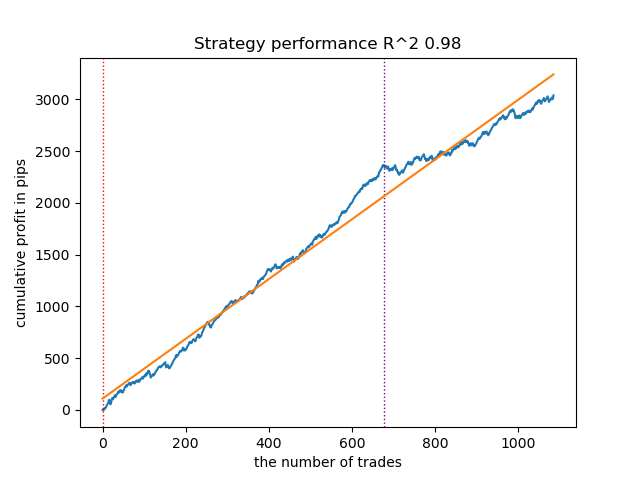
Figura 5. Prueba del segundo modelo con medias móviles
Reiniciando el ciclo de entrenamiento unas cuantas veces más, hemos logrado un gráfico de balance más ordenado:
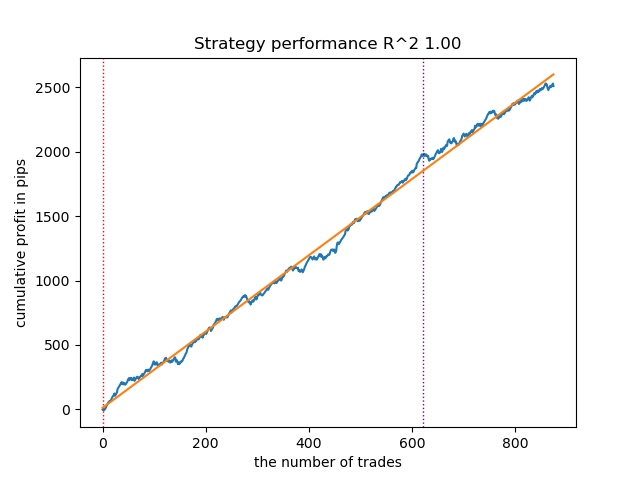
Figura 6. Prueba del mejor modelo tras un ciclo de entrenamiento repetido
Aquí no hemos experimentado con el número de características (su lista de periodos), por lo que en realidad es posible obtener una gran variedad de modelos de este tipo. Las capturas de pantalla ofrecidas simplemente demuestran algunas de las opciones.
Combatiendo el sobreentrenamiento
Suele ocurrir que la excesiva complejidad de un modelo repercute negativamente en su generalizabilidad. Incluso con el segmento de validación y la parada anticipada. En este caso, podemos intentar reducir el número de características y/o reducir la complejidad del modelo. La complejidad del modelo en el algoritmo CatBoost implica un número de iteraciones o árboles de decisión construidos secuencialmente. En fit_final_models() , probaremos a cambiar los siguientes valores:
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.8, test_size=0.2, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.8, test_size=0.2, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False)
Reduciremos el número de iteraciones a 100 y el valor de parada anticipada a 15. Esto permitirá construir un modelo menos complejo.
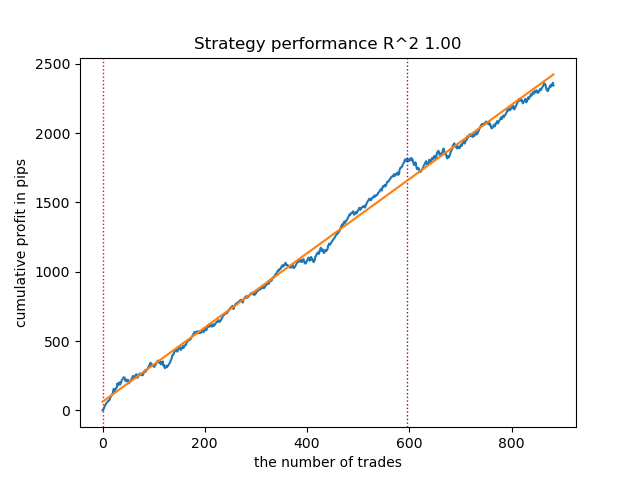
Figura 7. Prueba de un modelo menos "complejo"
Exportación de modelos al terminal Meta Trader 5
La función export_model_to_ONNX() del módulo export_lib() contiene las siguientes líneas:
# get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathMean(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathSkewness(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n'
Las líneas resaltadas son responsables del cálculo de características en código MQL5. Si cambiamos las características en el script de Python en get_features() como hemos descrito anteriormente, deberemos cambiar su cálculo en ese código, o podemos hacerlo en un archivo .mqh ya exportado.
Por ejemplo, en el archivo exportado XAUUSD_H1 ONNX include 0.mqh deberemos corregir las siguientes líneas:
#include <Math\Stat\Math.mqh> #resource "catmodel XAUUSD_H1 0.onnx" as uchar ExtModel_XAUUSD_H1_0[] #resource "catmodel_m XAUUSD_H1 0.onnx" as uchar ExtModel2_XAUUSD_H1_0[] int PeriodsXAUUSD_H1_0[10] = {5,35,65,95,125,155,185,215,245,275}; int Periods_mXAUUSD_H1_0[1] = {5}; void fill_araysXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(PeriodsXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,PeriodsXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); // ret[0] = MathMean(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); } void fill_arays_mXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods_mXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods_mXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
El cálculo de las características se corresponde ahora con el de get_features(), que utilizaba solo desviaciones estándar. Si hemos utilizado medias móviles, lo sustituiremos por MathMean().
Después de la compilación, podemos probar el bot en el terminal Meta Trader 5.
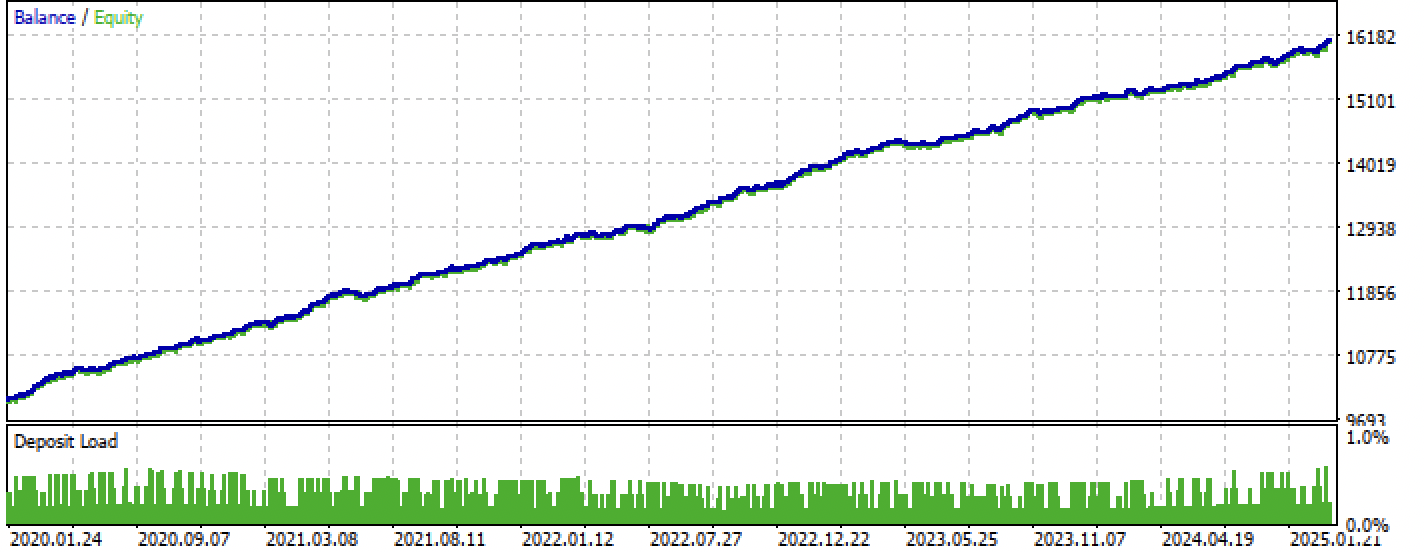
Figura 8. Pruebas en el intervalo entrenamiento + forward
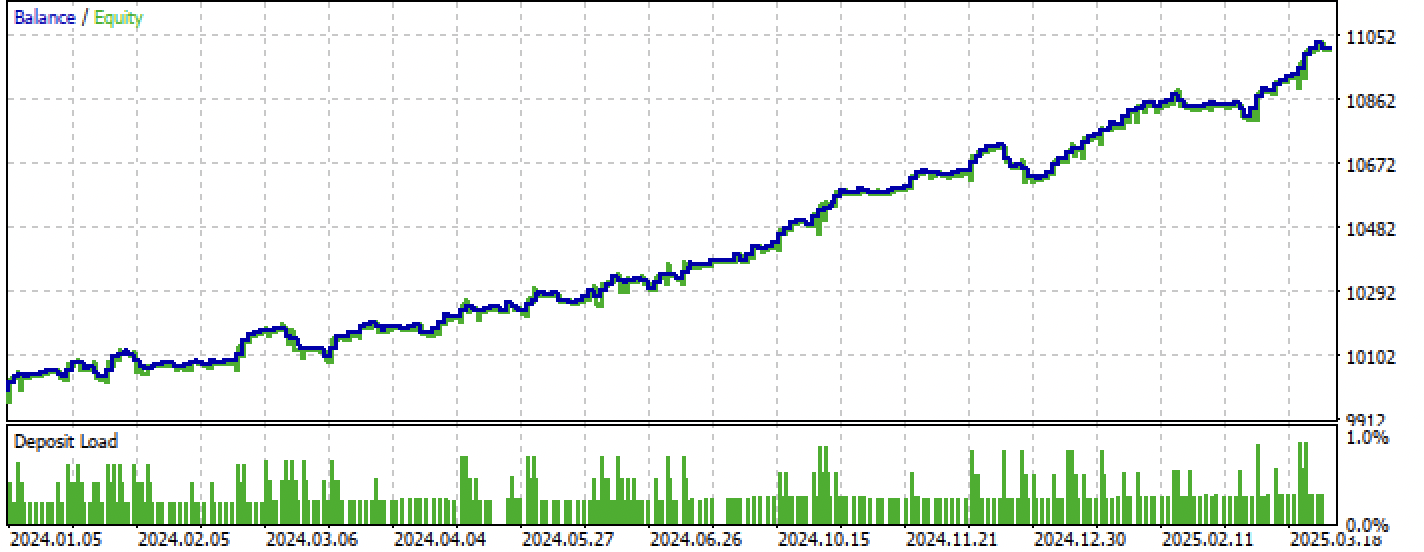
Figura 9. Pruebas solo en el periodo forward
Conclusión
En este artículo hemos visto otra forma de crear estrategias de tendencia unidireccionales, pero basadas en la clusterización. La principal diferencia de este enfoque reside en su intuitividad y su alta velocidad de aprendizaje. La calidad de los modelos resultantes es comparable a la del artículo anterior.
El archivo Python files.zip contiene los siguientes archivos para desarrollar en el entorno Python:
| Nombre del archivo | Descripción |
|---|---|
| one direction clusters.py | Script básico para el entrenamiento de modelos |
| labeling_lib.py | Módulo actualizado con marcadores de transacciones |
| tester_lib.py | Simulador personalizado actualizado para estrategias basadas en aprendizaje automático |
| export_lib.py | Módulo de exportación de modelos al terminal |
| XAUUSD_H1.csv | Archivo con las cotizaciones exportadas desde el terminal MetaTrader 5 |
El archivo MQL5 files.zip contiene archivos para el terminal MetaTrader 5:
| Nombre del archivo | Descripción |
|---|---|
| one direction clusters.ex5 | Bot recopilado de este artículo |
| one direction clusters.mq5 | Bot fuente del artículo |
| carpeta Include//Trend following | Asimismo, encontrará los modelos ONNX y el archivo de encabezado para conectarse al bot |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17755
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Así que tienes R2 es un índice modificado, cuya eficiencia se basa en el beneficio en pips. ¿Qué pasa con la reducción y otros indicadores de rendimiento? Si obtenemos un modelo que da más del 90% en el entrenamiento y al menos el 85% en la prueba, entonces su índice dará cifras impresionantes. No importa cuántas veces he ejecutado el probador en MT5, nunca he recibido un beneficio en el historial. El depósito se agota. Esto es a pesar del hecho de que su probador en Python da 0.97-0.98
No entiendo que tiene que ver esto con CV.
Todas estas estrategias tienen bajo poder de prueba, porque se basan sólo en la historia de las cotizaciones no estacionarias. Pero pueden detectar tendencias.¿Dónde está la IA en esto? ¿Se ha actualizado a este nivel? ¿O es sólo un truco de marketing habitual para atraer al público?
He observado esta extraña característica en varias publicaciones recientes de distintos autores.
¿No hay modelos decentes aparte del catbust?
¿Dónde está la IA en esto? ¿Se ha actualizado Catbust a este nivel? ¿O es sólo un truco de marketing común para atraer al público?
He observado esta extraña característica en varias publicaciones recientes de diferentes autores.
¿No hay modelos decentes aparte de catbust?
Clickbait (abreviatura popular). No soy partidario del término en absoluto.
La gente está acostumbrada a referirse a la MO como "IA". Además, TC es un complejo de diferentes algoritmos de MO, por ejemplo, agrupación y clasificación.