
初級から中級まで:構造体(VI)

はじめに
前回の「初級から中級まで:構造体(V)」では、シンプルな構造体テンプレートの作成方法を実演しながら解説しました。目的は、構造体全体を再実装することなく、他のデータ型に対して構造体をオーバーロードできるようにすることでした。やや理解が難しい内容もあったかもしれませんが、できる限りシンプルかつ実践的に説明するよう努めました。私たちは、読者の皆さんが各記事で扱うトピックを理解し、学び、実際に応用できることを目標としています。
しかし、前回扱った内容は、実は一連の概念の中では比較的やさしい部分にすぎません。熟練したプログラマであれば実装できる多種多様な処理を、ひとつの枠組みの下に整理・統合することこそが本質です。
本日から扱い始める内容(段階的に解説していきます)は、前回の記事で議論した内容を文字通り発展させるものです。そのため、このテーマは多くのプログラミングやデータ分析の講座でも取り上げられています。すべてを1つの記事で網羅できるとは思わないでください。適切に扱うには、相当数の記事が必要になります。しかも、これはオブジェクト指向プログラミング(OOP)を考慮しない場合の話です。
なぜこの点を強調するのでしょうか。それは、多くの方がクラスなどの使い方を学びたいと考えている一方で、OOPを理解するための基礎知識が十分でないケースをよく目にするからです。これらの概念は、構造化プログラミングを正しく理解することから生まれます。そして、それを身につけるには相応の時間が必要です。これは、経験を通じて初めて理解できるものでもあります。
しかし、本連載の目的は、その学習段階を加速させることにあります。本来であれば数年かかる内容を、努力と背景次第では数か月、あるいは数週間で身につけることも可能です。正直に言えば、プログラミングの基礎があることは、内容を素早く吸収するうえで非常に有利です。背景知識がなくてもさまざまなものを作ることは可能ですが、いずれ壁にぶつかる瞬間が訪れるでしょう。この連載記事の目標はまさにそこにあります。落ち着きと忍耐、そして決意があれば、背景の有無にかかわらず、誰でも優れたプログラマになれるということを示すことです。
それでは、新しいテーマに入りましょう。まずは前回の記事でおこなった内容を振り返り、見落とされがちな細部にも目を向けます。これらは、まもなく分析するいくつかの重要なポイントを理解するうえで非常に重要です。
日常のタスクについて考えてみましょう
最もシンプルな例のひとつは、アドレス帳で連絡先を検索することです。これはもちろん、辞書で類義語や単語の定義を探すのと同じくらい、非常に基本的で単純な作業です。子供でも学ぶことができます。しかし、もしアドレス帳で連絡先を見つける方法を知らなかったらどうでしょうか。あるいは電話帳で電話番号を探す方法を知らなかったらどうでしょうか。さらに、ウェブブラウザがどのようにして要求したウェブページを高速に見つけ出しているのかを考えたことはありますか。これらすべての背後には、同じ基本原理があります。それが「構造」です。
概念自体は同じですが、格納される情報の種類は大きく異なる場合があります。たとえば、アドレス帳には名前、住所、電話番号などが含まれます。一方、辞書には単語とその定義が並びます。これらはすべて、非常にシンプルかつ実用的な方法で整理できます。これらはすべて、非常にシンプルかつ実用的な方法で整理できます。本当に注目すべきなのは、こうした異なる種類の構造体を、大規模な修正を加えることなく扱えるコードを実装することです。そのための方法はいくつかありますが、そこまで踏み込む必要はありません。今回の私たちの目標は、あくまでシンプルなものをどのように実装するかを示すことです。
前回の記事では、構造体の内部に離散的なデータを保持する非常にシンプルな構造体ベースのコードの扱い方について説明しました。しかし、この方法では、より広範なタスクを解決するには適していません。理解を深めていただくために、以下に非常にシンプルで明確なコードを作成します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. }; 26. //+------------------------------------------------------------------+ 27. #define PrintX(X) Print(#X, " => ", X) 28. //+------------------------------------------------------------------+ 29. void OnStart(void) 30. { 31. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 32. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 33. 34. st_Data <double> Info_1; 35. st_Data <uint> Info_2; 36. 37. Info_1.Set(H); 38. Info_2.Set(K); 39. 40. PrintX(Info_1.Get(Info_2.Get(3))); 41. } 42. //+------------------------------------------------------------------+
コード01
この2項関係を扱うコードは、私が何を説明しようとしているのかを理解する前であっても、どのように分析するかによっては非常に興味深いものになります。この中では、2つのエンティティ間に「切り離し可能な関係」を作成しています。しかし、ここで焦る必要はありません。いま理解すべき概念は、日常的な問題をどのようにモデル化すれば、非常にシンプルで比較的完成度の高い構造化プログラミングを活用できるのかという点を明らかにする助けとなるものです。
コード01では、構造化プログラミングを用いて、配列KとHの要素間に関係性を構築しようとしています。もちろん、従来の方法でも同じことは可能です。しかし、構造的にコーディングすることで、それを他の問題解決に応用する際に、どれほど容易になるかがすぐに分かるでしょう。すでに作成したコードを変更する必要はありません。
これまでの記事内容を学習している方であれば、このコードがどのような結果を生成するのかは正確に理解できるはずです。そして、コード01を見ただけで、なぜその結果になるのかも分かるでしょう。まだそこまで到達していない方のために、以下にMetaTrader 5ターミナルへ出力された結果を示します。下の画像をご覧ください。

図01
質問:なぜ40行目は、図01のような値を示しているのでしょうか。回答:配列Kの要素を使って配列Hの要素をインデックス指定しているためです。しかし、これは本来意図していた動作ではありません。実際の目的は、配列Kのある値を配列Hの対応する値と結び付けることでしたが、その関連付けは期待どおりにはおこなわれませんでした。
ここで考え方を明確にするために、次の点を理解する必要があります。配列Kはキーとして機能することを想定していました。つまり、その各値が、配列H内の値にアクセスまたは識別のためのインデックスになるという設計です。しかし、配列Kは順序付けされていません。これは意図的にそうしています。なぜなら、この問題の解決策が必ずしも直感的に見えるわけではないことを理解していただくためです。
この関係がどのように発展していくのかを理解していただくために、コード01をコード02に変更します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. uint NumberOfElements(void) 26. { 27. return Values.Size(); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. void OnStart(void) 33. { 34. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 35. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 36. 37. st_Data <double> Info_1; 38. st_Data <uint> Info_2; 39. 40. Info_1.Set(H); 41. Info_2.Set(K); 42. 43. for (uint c = 0; c < Info_2.NumberOfElements(); c++) 44. PrintFormat("Index [%d] => [%.2f]", Info_2.Get(c), Info_1.Get(c)); 45. } 46. //+------------------------------------------------------------------+
コード02
おそらく、コード02を使えば、すべてがより明確になるでしょう。43行目では、ループを使ってすべての要素を順に処理し、ある配列がもう一方の配列とどのように関係しているかを示しています。コード02を実行すると、次のような結果が得られます。
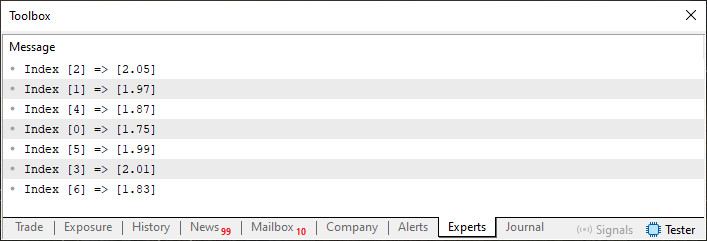
図02
さて、これでコード01の質問に戻ることができます。図02を見れば、配列Kで宣言されたすべてのインデックスに対して、配列Hに対応する値が存在することが分かるからです。したがって、コード01でインデックス03の値を求めた場合、実際には図01に示された値を指しているわけではありません。これは、配列が順序付けされていないことを無視すると、配列Kのインデックス03は0に相当するためです。しかし、対応する値を表示しようとすると、配列Hの正しいインデックスを指していません。少し複雑に感じるかもしれませんが、後ほど私の意図がはっきり理解できるようになります。
ここでの最初の問題は、配列が順序付けされていないことです。本当に効率的に検索するには、配列をソートする必要があります。図02に示された関係は保持されなければなりません。なぜなら、一方の配列が検索元として機能し、もう一方の配列が回答元として機能するからです。
多くの初心者はこの説明を聞くと、すぐに解決策を考えます。最もわかりやすいのは、ArraySort関数で配列をソートする方法や、ArrayBsearch関数で配列内を検索する方法です。しかし、私たちの目的を達成するには、コード01を修正する必要があります。これにより、コードは次のようになります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. T Search(const uint index) 26. { 27. return ArrayBsearch(Values, index); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. #define PrintX(X) Print(#X, " => ", X) 33. //+------------------------------------------------------------------+ 34. void OnStart(void) 35. { 36. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 37. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 38. 39. st_Data <double> Info_1; 40. st_Data <uint> Info_2; 41. 42. Info_1.Set(H); 43. Info_2.Set(K); 44. 45. PrintX(Info_1.Get(Info_2.Search(3))); 46. } 47. //+------------------------------------------------------------------+
コード03
コード03を実行すると、ついに正しく必要な接続が確立されます。これにより、以下のような結果が得られます。

図03
ここで注意すべきは、返される値は実際には私たちがリスト内で探していたインデックスに対応しているという点です。これは、図02における配列KとHの対応関係からも確認できます。しかし、同じタイプの関係を作る方法はもっと簡単に存在します。これにより、配列KとHの接続をより密に保ちながら、より効率的に作業することが可能です。
その方法のひとつが、多次元配列の使用です。しかし、多次元配列は異なる種類の情報を扱うにはあまり適していません。そのため、この種の接続を作成するには別の方法を使う必要があります。ここで思い出してほしいのは、目的は「構造体内にコードを内包させること」です。
したがって、まず一歩戻り、その後に二歩前進する必要があります。目標は、解決方法をより明確にすることです。個別に検討するのを避けるため、ここで話題を少し変えましょう。
構造体の構造体
多くの初心者が混乱しやすいポイントのひとつは、これまで別々に扱っていた概念を、ひとつの形式にまとめて使う段階です。この説明は少し奇妙に感じるかもしれません。なぜなら、概念自体は本質的に変わっていないからです。しかし、概念を組み合わせてより深く応用すると、最初はまったく見えなかった新しい可能性が生まれます。
これを説明するために、前回のトピックで扱ったコード03を修正し、理解しやすい形にします。同時に、説明を本来の目的に集中させることができます。言い換えると、ある値の集合と、まったく異なる値の集合との間に、ひとつの接続関係を作ることになります。
これを実現するために、以下のコードを使用します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. struct st_Reg 07. { 08. double h_value; 09. uint k_value; 10. }Values[]; 11. }; 12. //+------------------------------------------------------------------+ 13. bool Set(st_Data &dst, const uint &arg1[], const double &arg2[]) 14. { 15. if (arg1.Size() != arg2.Size()) 16. return false; 17. 18. ArrayResize(dst.Values, arg1.Size()); 19. for (uint c = 0; c < arg1.Size(); c++) 20. { 21. dst.Values[c].k_value = arg1[c]; 22. dst.Values[c].h_value = arg2[c]; 23. } 24. 25. return true; 26. } 27. //+------------------------------------------------------------------+ 28. string Get(const st_Data &src, const uint index) 29. { 30. for (uint c = 0; c < src.Values.Size(); c++) 31. if (src.Values[c].k_value == index) 32. return DoubleToString(src.Values[c].h_value, 2); 33. 34. return "-nan"; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 43. 44. st_Data info; 45. 46. Set(info, K, H); 47. PrintX(Get(info, 3)); 48. } 49. //+------------------------------------------------------------------+
コード04
コード04が何をしているのか詳しく説明する前に、まず次の点を理解しておいてください。ここで示しているのは、あくまで、あらかじめ定められた目的を実現する方法に過ぎません。
決して、以下で示す方法が唯一の方法だと考えないでください。もっとシンプルな方法や、あるいは多次元配列を使った複雑な方法も存在します。これまで説明し、実演してきた内容を基にした一例にすぎません。
しかし、さらに良い方法もあります。それは後ほど説明します。とりあえず、コード04が何をしているのか見ていきましょう。まず、実行結果を確認します。

図04
なんとも興味深い結果です。47行目が実行されると、コード01で見たものと非常に似たことをしていると考えるかもしれません。しかし、コード04の28行目にあるGet関数を見ると、インデックス値は配列Kの要素集合の中で検索されていることがわかります。
しかし、本当に重要なのはここです。31行目が正常に実行されると、返されるのは配列Kの要素のインデックスではなく、同じインデックスの配列Hの値です。これによって、KとHの間にリンクが作られるのです。ここで注目すべき点があります。要素数が少ない場合、コードの実行時間は気にする必要はありません。
ただし、通常かつ実際の状況では、4行目で作成された構造は何らかの方法で順序付けされているべきです。そのため、28行目で検索をおこなう際には、実行時間が最小になるようにできます。
ここで新たな考えが生まれます。現実に近いコードをどのように作るかということです。そのためには、この構造体に独自のコンテキストを与える必要があります。まさにここから、コンピュータサイエンスでいうデータ分析が始まります。
コードにデータ分析を適用する場合、ある程度の構造化は必要ですが、すべてのケースに完璧な構造があるわけではありません。状況によっては、コードを特定の方法で実装する必要がありますし、別の状況ではまったく異なる方法が必要です。そのため、各問題に応じて適切な知識が求められ、最短で最良の結果を得ることが可能になります。
今あなたは「データ分析の学習を始めるのか?」と思っているかもしれません。まだです、読者の皆さん。まず考えるべきことがいくつかあります。すぐに始めることもできますが、現時点ではおこないません。ポイントは、配列Kの要素集合と配列Hの要素集合の間にリンクがあることを理解することです。これにより、4行目の構造体を、必要な機構を内包して要素間のリンクを正しく維持および管理できる「コンテキスト構造体」に変換する方法を考え始めることができます。
このために、まずコード04を使ってこのシミュレーションを構築します。言い換えると、現時点では仕組みを一般化するわけではありません。これにより、コンパイラが型のオーバーロードを作成できるようになります。修正された新しいコードは以下の通りです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. struct st_Reg 10. { 11. double h_value; 12. uint k_value; 13. }Values[]; 14. //+----------------+ 15. public: 16. //+----------------+ 17. bool Set(const uint &arg1[], const double &arg2[]) 18. { 19. if (arg1.Size() != arg2.Size()) 20. return false; 21. 22. ArrayResize(Values, arg1.Size()); 23. for (uint c = 0; c < arg1.Size(); c++) 24. { 25. Values[c].k_value = arg1[c]; 26. Values[c].h_value = arg2[c]; 27. } 28. 29. return true; 30. } 31. //+----------------+ 32. string Get(const uint index) 33. { 34. for (uint c = 0; c < Values.Size(); c++) 35. if (Values[c].k_value == index) 36. return DoubleToString(Values[c].h_value, 2); 37. 38. return "-nan"; 39. } 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. #define PrintX(X) Print(#X, " => ", X) 44. //+------------------------------------------------------------------+ 45. void OnStart(void) 46. { 47. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 48. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 49. 50. st_Data info; 51. 52. info.Set(K, H); 53. PrintX(info.Get(3)); 54. } 55. //+------------------------------------------------------------------+
コード05
ここで、説明の流れを見失わないように注意してください。コード05を実行すると、MetaTrader 5ターミナルには図04と同じ基本情報が表示されますが、わずかな違いがあります。下の画像をご覧ください。

図05
コード04とは異なり、コード05は構造化プログラミングによる実装です。しかし、11行目と12行目でおこなわれた型宣言により、ここで使用できるデータは特定の型に限定されています。仮に、数値ではなく文字列(テキスト値)をリンクさせる別のシステムを作りたい場合、つまりコード05で使用した値ではなく文字列を使いたい場合、コード05をなるべく変更せずにどう対応できるでしょうか。
前回の記事を読んでいない場合は少し残念です。そこではここで繰り返さない細かい説明がされています。しかし、今回は4行目で宣言された構造を一般化し、コンパイラが必要な型のオーバーロードを作成できるようにする方法を見ていきます。これにより、従来では明らかに対応できなかったケースもカバーできるようになります。
簡単にするために、まず11行目で定義されたひとつの基本型だけを一般化していきます。新しいコードは以下の通りです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. struct st_Reg 11. { 12. T h_value; 13. uint k_value; 14. }Values[]; 15. //+----------------+ 16. string ConvertToString(T arg) 17. { 18. if ((typename(T) == "double") || (typename(T) == "float")) return DoubleToString(arg, 2); 19. if (typename(T) == "string") return arg; 20. 21. return IntegerToString(arg); 22. } 23. //+----------------+ 24. public: 25. //+----------------+ 26. bool Set(const uint &arg1[], const T &arg2[]) 27. { 28. if (arg1.Size() != arg2.Size()) 29. return false; 30. 31. ArrayResize(Values, arg1.Size()); 32. for (uint c = 0; c < arg1.Size(); c++) 33. { 34. Values[c].k_value = arg1[c]; 35. Values[c].h_value = arg2[c]; 36. } 37. 38. return true; 39. } 40. //+----------------+ 41. string Get(const uint index) 42. { 43. for (uint c = 0; c < Values.Size(); c++) 44. if (Values[c].k_value == index) 45. return ConvertToString(Values[c].h_value); 46. 47. return "-nan"; 48. } 49. //+----------------+ 50. }; 51. //+------------------------------------------------------------------+ 52. #define PrintX(X) Print(#X, " => ", X) 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 57. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 58. 59. st_Data <double> info; 60. 61. info.Set(K, H); 62. PrintX(info.Get(3)); 63. } 64. //+------------------------------------------------------------------+
コード06
コード06の構築によって、いよいよ本当に面白くなってきました。これは、コード06では構造体を一般化できるようになり、必要に応じてコンパイラがオーバーロードをおこなえるためです。これにより、異なる種類のデータを扱い、検索メカニズムを作成することが可能になります。しかし、このコードをコンパイルしようとすると、これまでのコードとは異なるメッセージが表示されることがわかります。
下の画像をご覧ください。

図06
以前、コンパイラのメッセージは無視できる場合とできない場合があるとお話ししましたが、これは無視できる典型的な例です。なぜなら、19行目と21行目でおこなっている処理は、非常に特定のケースでのみ実行され、18行目も同様だからです。これらのメッセージの表示を防ぐ方法もありますが、それは別の機会、おそらく次回の記事で説明します。
ここでのポイントは、値のひとつを一般化する場合、コンパイラにどの情報が使われるかを知らせる必要があるということです。そのうえで、そのデータ型に適したコードを作成できます。具体的には、59行目で構造体にアクセスする変数を宣言しています。なお、56行目で宣言された基本型がdoubleであるため、59行目の宣言でも互換性のある型、もしくは同一の型を使用しなければなりません。そうしないと、構造体の参照時に問題が発生します。
「どういうことですか?その部分が理解できません。もちろん、59行目の宣言は構造体内の宣言のおかげで理解できます。しかし、なぜ56行目の型と一致させる必要があるのか分かりません。汎用的なものを作っているのだから、あまり意味がないように思えます」と思うかもしれません。
これは説明がやや難しいので、この記事の残りはこのトピックに割き、詳細な部分は次回の記事で扱うことにします。
ここで注目してほしいのは、この記事の冒頭でコード06に非常に似たコードを使ったことです。そのときは、結果はある意味で事前にわかっていました。なぜなら、正しいデータ型に変換して返すことを考慮していなかったからです。
今考えてみてください。コード01では、返されるデータの型は格納されているデータの型によって変わります。しかし、これが重要な点です。コード06では、格納されているデータの型に関わらず、常にデータ型が返されます。この場合、格納されるのはdouble型ですが、返される答えは常にstring型です。
この変換がおこなわれるという事実自体が、システムを混乱させる原因になります。なぜなら、この変換は構造体を使用するプログラマが想定していないからです。「まさか」と思われるかもしれません。もちろん、プログラマは理解しているでしょう。しかし、必ずしもそうとは限りません。なぜなら、コードライブラリを作成して異なるタイミングで使用することも可能だからです。そして、コードライブラリというのは、単に大量のソースコードを蓄積することではありません。
これらのライブラリは通常、良く知られているDLLのような実行可能コードで構成されます。その内部の処理が正確にどうなっているかはわかりません。わかるのは、値を渡すと結果が返ってくるという点だけです。構造体に渡すデータ型を把握しておくことが重要です。なぜなら、返される結果は常に文字列型になるため、必要に応じて元の型に戻す必要があるからです。
「でも、汎用のままにしておけばいいのでは?つまり、データをstring型に変換せず、元の型のまま保持すれば、先ほどの問題は起こらないのでは?」と思うかもしれません。確かにその通りです。しかし、ここでの目的は学習であり、実際に使うためのコードを作ることではないことを覚えておいてください。
とはいえ、少し立ち止まって考える機会を提供するために、コード06を修正します。この修正では、上に示したコードのうち、下記のフラグメントだけが変更されます。この変更自体が、ここで扱っている状況が完全に新しいものであることを示しています。以下が修正されたフラグメントです。
. . . 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const string T = "possible loss of data due to type conversion"; 57. const uint K[] = {2, 1, 4, 0, 7, 5, 3, 6}; 58. 59. st_Data <string> info; 60. string H[]; 61. 62. StringSplit(T, ' ', H); 63. info.Set(K, H); 64. PrintX(info.Get(3)); 65. } 66. //+------------------------------------------------------------------+
コード07
心配はいりません。付録にはすべてのコードが掲載されているので、ここで示した内容をすべて実際に試し、練習することができます。それよりも、ここで何をしているのかを少し立ち止まって考えてほしいと思います。コード06をコード07のフラグメントに置き換えることで、構造体内に格納される情報の型を変更するという単純な操作だけで、多くの人にとって実装が困難または不可能に思えるようなものを構築できるようになるのです。
ここでひとつヒントを挙げると、コード07の60行目で使用している変数に情報をどのように作り、並べるかによって、適切に実装すれば、どの言語でも動作するコードを作成できる可能性があります。もちろん、そのためには60行目の変数に格納する情報を適切に実装し、並べる必要があります。
これがどのように可能か、そしてそれが作成できるコード全体にどのような影響を与えるかを考えてみてください。
まとめ
本記事では、プログラミングの基本原則のいくつかをより深く掘り下げ、共通のコードベースを実装し始める方法を探りました。目的は、プログラミングの作業負担を軽減し、使用しているプログラミング言語(ここではMQL5)そのものが持つ潜在能力を最大限に活用することです。ここで示したり説明した内容は、私自身が理解するまでに非常に長い時間がかかりました。
しかし、それは当時、これらの概念がまだ生まれたばかりであったからです。現在では、ほとんどの人がOOP(オブジェクト指向プログラミング)が最良だと言います。そして確かに、OOPは非常に優れた有用な手法です。しかし、なぜそうなのかを理解せずに、クラスのコードを見たり、使ったり、改変したりしても意味はありません。本当に理解し、学ぶためには、まずプログラミング言語がどのようにこのレベルに到達したのか、なぜOOPが生まれたのか、そしてなぜ広く使われているのかを理解する必要があります。
この理解は、実践と試行を通じてしか得られません。OOPでのみ語られる原則を用いたコードを使って学ぶこともできますが、実際にはそれらの原則は構造化プログラミングの中で生まれたものであり、今日ほとんど語られることのないテーマです。私たちはここで、その構造化プログラミングの学習を始めています。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15889
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索