
初級から中級まで:構造体(V)

はじめに
前回の「初級から中級まで:構造体(IV)」では、構造化されたコードを作成するためのプログラミングについて、より詳細かつ実践的な議論を始めました。多くの人にとって、こうした話題は取るに足らないもの、実用性に欠けるものに思えるかもしれません。というのも、現在の主流はほとんどがオブジェクト指向プログラミング(OOP)だからです。そして多くの人は、OOPが一夜にして誕生したわけではないということを理解していません。それは、プログラミングコミュニティ全体における長年の研究と議論の成果であり、構造化プログラミングの限界が明らかになったときに初めて生まれたものなのです。
しかし、特定の課題を解決するために変数や関数、手続きを宣言する従来のプログラミングとは異なり、構造化プログラミングは、単一の問題だけでなく、相互に関連する一連の問題を解決できるアプローチを構築することを目指します。
おそらく多くの方(特に初心者の方)は、「こんなことは学びたくない。エキスパートアドバイザー(EA)やインジケーターの作り方を学びたい。自分が使う予定もない解決策を実装する方法を学ぶのは嫌だ」と思われているでしょう。もちろん、そのように考える権利はあります。しかし、インジケーターやEAのコードとは直接関係のない解決策を実装する方法を理解していなければ、思っているより早く行き詰まってしまいます。なぜなら、明白でも単純でもない問題をどのように実装すればよいかを理解していないからです。
発生するあらゆる問題を解決できるようになるためには、プログラマとしての思考法を身につける必要があります。そして、その中のひとつの課題が、これまで説明されてこなかった点、すなわち「構造化プログラミングをどのように拡張して、より広範な課題を解決するか」ということです。言い換えれば、整数型のデータを扱うコードを作成した場合、すべてを一から作り直すことなく、浮動小数点データに対してどのように対応できるのでしょうか。これは非常に興味深い問いですが、同時に混乱を招きやすいテーマでもあります。なぜなら、同じことを実現する方法がいくつも存在するからです。
少なくとも2つの異なる方法を説明してみたいと思います。2つ目の方法はメモリ操作を伴うもので、まだ準備ができていない方もいるかもしれません。まずは最もシンプルな方法から始めましょう。それによって、この問題にどのようにアプローチすればよいのか、全体像をつかむことができるはずです。さあ、この記事の本題に集中しましょう。ここからが面白くなります。
構造体でテンプレートを使用する方法
ここでは、データ構造においてテンプレートを使用する方法のひとつを分析します。これは、構造体がどのようにオーバーロードされるのかを理解するうえで最もシンプルな方法です。ここで示すすべての内容は、あくまで教育目的のものです。いかなる場合でも、本資料をそのまま最終コードとして使用できるものと考えてはいけません。十分に理解せずにそのまま利用すべきではありません。
まず最初に、前回の記事のコードを取り上げます。というのも、これからおこなう内容に関連して、非常に実用的で理解しやすいものが含まれているからです。使用するコードは以下のとおりです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. double Average(void) 20. { 21. double sum = 0; 22. 23. for (uint c = 0; c < Values.Size(); c++) 24. sum += Values[c]; 25. 26. return sum / Values.Size(); 27. } 28. //+----------------+ 29. double Median(void) 30. { 31. double Tmp[]; 32. 33. ArrayCopy(Tmp, Values); 34. ArraySort(Tmp); 35. if (!(Tmp.Size() & 1)) 36. { 37. int i = (int)MathFloor(Tmp.Size() / 2); 38. 39. return (Tmp[i] + Tmp[i - 1]) / 2.0; 40. } 41. return Tmp[Tmp.Size() / 2]; 42. } 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
コード01
コード01をMetaTrader 5プラットフォームで実行すると、次の結果が得られます。

図01
今のところ、特別なことは何もありません。しかし、次の状況を考えてみてください。コード01は、値の配列に対して「平均値」と「中央値」という2つの情報を返すように実装されています。しかし、これは浮動小数点値、具体的にはdouble型に対してしか機能しません。整数型は愚か、float型のような他の浮動小数点型には対応していません。
このような場合、一見実用的に見えるコード01も、実際にはほとんど役に立ちません。なぜなら、double以外の数値型を扱うには、すべての数値型を網羅するまで構造体を何度も実装し直さなければならないからです。
この状況は、オーバーロードの問題と関係しています。しかし、構造体のオーバーロードは、関数や手続きのオーバーロードとは同じようには機能しません。この場合、オーバーロードをおこなうには構造体の名前、つまりコード01の04行目で定義されている情報を変更する必要があります。
その結果、同じ目的、同じ文脈、同じカプセル化されたデータを持ちながら、まったく異なる名前を持つ新しい構造体を大量に作ることになります。言い換えれば、完全な混乱を引き起こし、作業量は膨大です。
自分の経験から言っても、プログラマは余分な作業を好みません。同じコードを何度も繰り返す必要があると、飽きて、興味を失ってしまいます。問題を解決することを考えるのは好きですが、たった1つの詳細を変えるためにコードを複製するのは好みではありません。私自身は本当に嫌いです。同じように考えた他のプログラマたちが、この問題を解決する方法を見つけ、「本来オーバーロードできないものをオーバーロードする仕組み」を作り出しました。これが構造体テンプレートというアイデアの誕生です。
テンプレートの基本形については、「初級から中級まで:テンプレートとtypename (I)」から始まる、5回にわたる短い連載で既に説明しました。これからおこなう内容を理解するためには、そこで説明された知識と概念をしっかり把握しておくことが非常に重要です。以前説明した内容が理解できていなければ、これからおこなうことはまったく意味をなさないからです。
ここで示す方法は、構造体オーバーロードを扱う最も簡単で理解しやすい方法です。ただし、他にもより複雑で特定の目的に特化した方法があります。それについて記事を書く価値があるかどうかは検討します。いずれにせよ、最もシンプルな方法はテンプレートを使用することです。
まず一歩引いて考えましょう。構造体テンプレートを構造化された実装に適用する前に、より一般的な実装でどのように適用されるかを見る必要があります。つまり、通常のコードで構造体テンプレートがどのように使われるかを確認します。そのために、コード01を構造的な形式から通常の形式へ変更します。最終結果は次のとおりです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. double Values[]; 07. }; 08. //+------------------------------------------------------------------+ 09. double Average(const st_Data &arg) 10. { 11. double sum = 0; 12. 13. for (uint c = 0; c < arg.Values.Size(); c++) 14. sum += arg.Values[c]; 15. 16. return sum / arg.Values.Size(); 17. } 18. //+------------------------------------------------------------------+ 19. double Median(const st_Data &arg) 20. { 21. double Tmp[]; 22. 23. ArrayCopy(Tmp, arg.Values); 24. ArraySort(Tmp); 25. if (!(Tmp.Size() & 1)) 26. { 27. int i = (int)MathFloor(Tmp.Size() / 2); 28. 29. return (Tmp[i] + Tmp[i - 1]) / 2.0; 30. } 31. return Tmp[Tmp.Size() / 2]; 32. } 33. //+------------------------------------------------------------------+ 34. #define PrintX(X) Print(#X, " => ", X) 35. //+------------------------------------------------------------------+ 36. void OnStart(void) 37. { 38. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 39. const double K[] = {12, 4, 7, 23, 38}; 40. 41. st_Data Info_1, 42. Info_2; 43. 44. ArrayCopy(Info_1.Values, H); 45. PrintX(Average(Info_1)); 46. 47. ArrayCopy(Info_2.Values, K); 48. PrintX(Median(Info_2)); 49. } 50. //+------------------------------------------------------------------+
コード02
さて、コード02は通常の形式になりました。MetaTrader 5で実行すると、次の結果が得られます。

図02
ここまで説明してきたことを踏まえれば、コード02が何をおこない、どのように動作しているかは容易に理解できるはずです。浮動小数点型でおこなえることと同様に、ここでも関数および手続きのテンプレートを実装することができます。そうすると、コード02は次のようになります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. double Values[]; 08. }; 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. double Average(const st_Data <T> &arg) 12. { 13. T sum = 0; 14. 15. for (uint c = 0; c < arg.Values.Size(); c++) 16. sum += arg.Values[c]; 17. 18. return sum / arg.Values.Size(); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. double Median(const st_Data <T> &arg) 23. { 24. T Tmp[]; 25. 26. ArrayCopy(Tmp, arg.Values); 27. ArraySort(Tmp); 28. if (!(Tmp.Size() & 1)) 29. { 30. int i = (int)MathFloor(Tmp.Size() / 2); 31. 32. return (Tmp[i] + Tmp[i - 1]) / 2.0; 33. } 34. return Tmp[Tmp.Size() / 2]; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uchar K[] = {12, 4, 7, 23, 38}; 43. 44. st_Data <double> Info_1; 45. st_Data <uchar> Info_2; 46. 47. ArrayCopy(Info_1.Values, H); 48. PrintX(Average(Info_1)); 49. 50. ArrayCopy(Info_2.Values, K); 51. PrintX(Median(Info_2)); 52. } 53. //+------------------------------------------------------------------+
コード03
「めちゃややこしい。このコード、正気の沙汰とは思えない。飛ばしちゃだめですか?」落ち着いてください。これはメモリ操作を使うコードほど狂気じみたものではありません。その方法を紹介する価値があるかどうかは検討します。しかし、コード03の大部分はすでに見慣れたものであり、理解できるはずです。おそらく、44行目と45行目だけが少し意外に感じられるかもしれません。
ちなみに、これに似たコードは「初級から中級まで:テンプレートとtypename (IV)」で扱いました。そこでは構造体ではなく共用体の使用についてでしたが、動作原理は同じです。そしてすでに2本の記事にわたって説明しているため、ここで同じ概念を繰り返し説明する必要はないでしょう。
コード03の内容が理解できない場合は、以前の記事に戻ることをお勧めします。これまでも述べてきた通り、知識は時間とともに積み重なっていくものです。基礎概念を理解せずに、より複雑な内容を理解しようとしても、良い結果にはなりません。
さて、ここで1つ、小さいながらも見落とされがちな点があります。それはMedian関数の戻り値の型です。問題は次の点にあります。配列の要素数が偶数の場合、28行目の判定により32行目が実行されます。しかし、要素数が奇数の場合は34行目が実行されます。そして多くの場合、このとき返される値の型は、期待される型とは異なります。
なぜなら、整数要素を持つ配列であれば、中央値も整数型で返すことを期待する場合があるからです。そのため、42行目で宣言された整数配列に対して、ターミナルに表示される結果は完全には一致していません。配列は整数型なのに、戻り値は浮動小数点型なのです。ただし、このコードは純粋に教育目的のものなので、完全に誤った結果を示すよりは、この小さな不一致を残すことにします。
さて、コード03を見て、これをコード01のような「構造化された実装」に変換する方法を考えてみると、正しい道筋はすぐに見えてきます。コード01を修正し、コード03に示したテンプレート宣言を適用すればよいのです。
しかし、ここで1つ気になるかもしれません。コード03では関数もテンプレートとして実装しました。「ではコード01でも同じことをする必要があるのか?構造体の実装を正しく機能させ、コンパイラに構造体のオーバーロードを認識させるためには必要なのか?」この場合、それは必要ありません。なぜなら、文脈が非常に単純で、特別に追加するものがほとんどないからです。
ただし、コード03と異なり、そこでは構造体の値を参照渡ししていましたが、コード01ではそれはできません。その理由は前回の記事で説明しました。これは文脈およびデータカプセル化の問題に関連しています。新しい値を導入する唯一の方法は、コード01にあるSet手続きを通すことです。したがって、ここが元のコード01から変更しなければならない数少ない点のひとつになります。以下に、構造体オーバーロードを考慮した新しいコード01を示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. double Average(void) 21. { 22. double sum = 0; 23. 24. for (uint c = 0; c < Values.Size(); c++) 25. sum += Values[c]; 26. 27. return sum / Values.Size(); 28. } 29. //+----------------+ 30. double Median(void) 31. { 32. T Tmp[]; 33. 34. ArrayCopy(Tmp, Values); 35. ArraySort(Tmp); 36. if (!(Tmp.Size() & 1)) 37. { 38. int i = (int)MathFloor(Tmp.Size() / 2); 39. 40. return (Tmp[i] + Tmp[i - 1]) / 2.0; 41. } 42. return (double) Tmp[Tmp.Size() / 2]; 43. } 44. //+----------------+ 45. }; 46. //+------------------------------------------------------------------+ 47. #define PrintX(X) Print(#X, " => ", X) 48. //+------------------------------------------------------------------+ 49. void OnStart(void) 50. { 51. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 52. const char K[] = {12, 4, 7, 23, 38}; 53. 54. st_Data <double> Info_1; 55. st_Data <char> Info_2; 56. 57. Info_1.Set(H); 58. PrintX(Info_1.Average()); 59. PrintX(Info_1.Median()); 60. 61. Info_2.Set(K); 62. PrintX(Info_2.Average()); 63. PrintX(Info_2.Median()); 64. } 65. //+------------------------------------------------------------------+
コード04
ご覧のとおり、コード01を構造体オーバーロード可能なコードへ変換するのは非常に簡単です。最終的には完全に構造体ベースのコードになります。関数および手続きは構造体の文脈内で宣言されているため、構造体自身の宣言を継承します。これは、コンパイラが構造体をオーバーロードするときに自然に発生します。
先ほど述べたように、戻り値の問題は、整数値を浮動小数点値(具体的にはdouble型)へ変換していることに起因します。これはコード04の20行目および30行目で確認できます。「しかし、なぜそれが問題になるのか?もし問題になるとしたら、回避する方法はあるのか?」
これを理解するためには、まずコード04の実行結果を見てみましょう。以下をご覧ください。
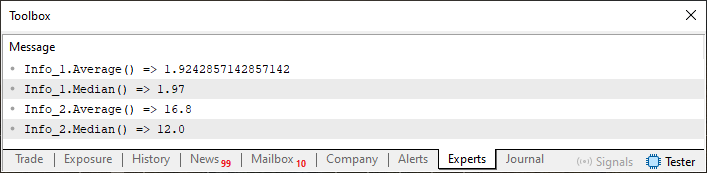
図03
図03に示された結果に注目してください。Info_2.Medianの戻り値は浮動小数点値です。しかし55行目を見ると、Info_2はcharとして宣言されています。問題は、構造体に対して、そのデータ構造内部に存在する中央値を返すように要求したとき、この状況をうまく処理できないという点にあります。その結果、実装上、意図した型とは異なる型(double)で返されてしまいます。より正確に言えば、本来であれば整数値を返すべきなのに、浮動小数点値を返しているのです。
このような問題は、一見すると簡単に解決できそうに思えますが、実際のコードや実務の場面でははるかに複雑になることが少なくありません。しかし一般的に、多くのプログラマ(あくまで一般論として述べています)は、構造体内部の問題を解決するために、さらに多くの関数や手続きを追加するという方法を取ります。ほとんどの場合、それで問題は解決しますが、その実装は他のプログラマにとってはあまり意味をなさないものになることもあります。理由は単純です。問題を解決する最良の方法は、それを直接「解決する」ことではなく、それをより小さな部分として考えられる仕組みを提供することだからです。
「どういうことですか。矛盾に聞こえるようですが。」これを理解するために、コード04を教材として使いましょう。第一のポイントです。なぜ平均値を関数を通じて直接返す必要があるのでしょうか。構造体自体を使うことでコードがより簡潔になるからだと答える人もいるでしょう。それは確かに妥当な主張です。
しかし、55行目の宣言にある整数のケースに戻ってみましょう。61行目で設定した要素の平均値は実際には浮動小数点値であり、この場合は16.8になります。しかし、整数としての平均値が必要な状況を考えてみてください。その場合は丸め処理が必要になります。丸めの規則は存在しますが、ここで重要なのはそれではありません。
重要なのは、この構造体を使用するプログラマ自身が、いつ、どのように、そしてなぜ値を丸めるのかを理解し、判断できるようにすることです。目的は整数値を得ることです。
そのためには、構造体内に実装されている内容の文脈を変更する必要があります。多くの場合、コードの一部を削除するのではなく、新しい部分を追加し、それによってより小さく、より明確なブロックを作成します。これをよりよく理解するために、具体的なコード例を見てみましょう。コード04の20行目には、構造体自身の値の平均を計算する関数があります。ここまでは特に変わったことはありません。
しかし、その平均値を得るためには、実際には2つのことをおこなう必要があります。第一に、要素の合計を求めること。第二に、要素がいくつあるかを知ることです。ここで皆さんはこう思うかもしれません。「まだ何かあるんですよね?」これをAverage関数の内部で直接おこなうのではなく、2つの別々の関数として実装すれば、構造体の利用者は、平均値をどのように、どこで、そしてなぜ丸めるのかを選択できるようになります。
要点が見えてきたでしょうか。では、実際にどのように実装するのかを見てみましょう。このために、次のコードを使用します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Sum(void) 21. { 22. T sum = 0; 23. 24. for (uint c = 0; c < NumberOfElements(); c++) 25. sum += Values[c]; 26. 27. return sum; 28. } 29. //+----------------+ 30. uint NumberOfElements(void) 31. { 32. return Values.Size(); 33. } 34. //+----------------+ 35. double Average(void) 36. { 37. return ((double)Sum() / NumberOfElements()); 38. } 39. //+----------------+ 40. double Median(void) 41. { 42. T Tmp[]; 43. 44. ArrayCopy(Tmp, Values); 45. ArraySort(Tmp); 46. if (!(Tmp.Size() & 1)) 47. { 48. int i = (int)MathFloor(Tmp.Size() / 2); 49. 50. return (Tmp[i] + Tmp[i - 1]) / 2.0; 51. } 52. return (double) Tmp[Tmp.Size() / 2]; 53. } 54. //+----------------+ 55. }; 56. //+------------------------------------------------------------------+ 57. #define PrintX(X) Print(#X, " => ", X) 58. //+------------------------------------------------------------------+ 59. void OnStart(void) 60. { 61. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 62. const char K[] = {12, 4, 7, 23, 38}; 63. 64. st_Data <double> Info_1; 65. st_Data <char> Info_2; 66. 67. Info_1.Set(H); 68. PrintX(Info_1.Average()); 69. PrintX(Info_1.Median()); 70. 71. Info_2.Set(K); 72. PrintX(Info_2.Average()); 73. PrintX(Info_2.Sum()); 74. PrintX(Info_2.NumberOfElements()); 75. PrintX(Info_2.Sum() / Info_2.NumberOfElements()); 76. PrintX(Info_2.Median()); 77. } 78. //+------------------------------------------------------------------+
コード05
コード05がモデル化しているのは、コードを小さなブロックに分解するということです。これは、多くの人がオブジェクト指向プログラミング(OOP)でのみおこなわれると考えていますが、実際には構造化プログラミングに起源を持ちます。このコードの20行に注目してください。そこには、構造体内にあるすべての要素の合計を返すことを目的とした関数があります。戻り値の型は、構造体自体の中に含まれているデータの型に依存します。この点に注意してください。これは重要です。さらに、30行目には、構造体内の要素数を返すことを目的とした別の関数があります。
さて、ここからが最も興味深い部分です。平均値は、先に述べたこれら2つの関数で計算された値を割ることで求められます。そのため37行目では、構造体の文脈内で平均値の計算がおこなわれています。しかし、ここが重要なポイントです。Sum関数の結果をdouble型に変換するよう、コンパイラに指示している点に注目してください。なぜこのようなことをするのでしょうか。その答えは、コード05の実行結果の画像を見れば分かります。以下をご覧ください。
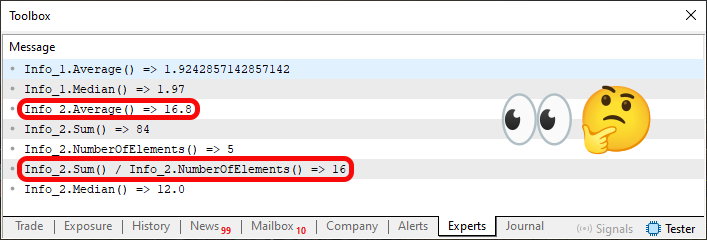
図04
この画像では、2つの情報が赤枠で強調表示されています。1つは72行目の実行結果に対応するもの、もう1つは75行目の実行結果に対応するものです。ただし、ここで示されている2つのデータ型は異なっており、一方は浮動小数点型、もう一方は整数型です。ここで、なぜ37行目でSum関数の結果をdoubleに変換しているのかを説明します。37行目でおこなわれている計算は、75行目でも同じ形で繰り返されています。しかし、一方では、62行目の要素を合計した結果である84がdoubleに変換されていますが、もう一方では変換されていません。したがって、文脈上は37行目のように構造体の内部で直接平均値を計算することもできますし、構造体の外部で同じ計算をおこなうこともできます。まさにそのために、使用するデータ型という観点から、結果がどのように表現されるかを制御できるのです。
これは一見すると奇妙に思えるかもしれません。しかし、本質を変えることなく、プログラマに結果の表現方法を制御し、調整し、さらには選択する能力を与えている点に注目してください。本来であれば、はるかに困難で時間のかかる作業になるはずのことを可能にしています。これらすべては、以前は1つの関数の中でおこなっていた計算を、構造体本体の外部から利用可能な複数の関数に分割しただけで実現されています。それにもかかわらず、構造体自体の文脈は保持されています。なぜなら、75行目を見れば、どのような情報が必要なのかが明確に分かるからです。
このようなことを学んでいけば、多くの場合、これこそがクラスやオブジェクト指向プログラミングで語られる内容なのだと理解できるでしょう。しかし、この単純なコードによって、その概念がOOPとは独立して存在していることを示しました。したがって、将来このプログラミングモデルについて説明を受けたとき、すでに確かな基礎を持っていることになります。なぜなら、OOPはまさに構造化プログラミングでは対応できない部分を補うことを目的としているのだと理解できるからです。
「なるほど、それは興味深いです。でも、あまり複雑にせずに他のことはできませんか?」はい、読者の皆さん。ここまで見てきた多くのことを簡略化するために、さまざまなプログラマがコード内で用いている技法があります。しかし、ここで議論した内容を理解していなければ、構造体のオーバーロードをどのように作成できるのかを理解するのは難しいでしょう。ここで扱っているオーバーロードは、より一般的な構造体を作成することを目的としていますが、その文脈は非常に特定されたものです。
まだ少し時間があるので、先ほど触れた手法がどのようなものかを簡単に概説しておきます。そのためには、立ち止まっていくつかの点を考える必要があります。まず、コード05の64行と65行に注目してください。そこでは、整数値や浮動小数点値といった離散的なデータを格納するための宣言がおこなわれています。しかし、よく考えてみれば、共用体や構造体もまたデータの一形態です。したがって、それらもデータ型として宣言し、特定のデータ型に適したモデルを構築するために、そのコードをオーバーロードする構造体の中で使用することができます。
この点はすでに理解しており、テンプレートやオーバーロードの使い方を扱った記事で実践しているはずです。しかし、離散的なデータ型とは異なり、共用体や構造体のような型はより複雑です。さまざまな要素を含むことができるからです。たとえばMqlRates構造体には、始値、終値、スプレッド、出来高などの要素が定義されています。したがって、原理的には、複雑な値であれ離散的な値であれ、あらゆる型の情報を受け入れることができる構造体テンプレートを宣言することは可能です。しかし、離散型が想定されている箇所に複雑型を定義することを困難にする要因が存在します。とはいえ、それによって特定の課題をより低コストで解決するための仕組みを作ることが妨げられるわけではありません。
そこで皆さんに考えてほしいのです。コード05のようなコードの中で、共用体や構造体といったデータをどのように利用すれば、さまざまな方法で構造体のオーバーロードを一般化し、完全に構造体ベースのコードを構築できるでしょうか。簡単な課題ではありません。しかし、次回の記事では、まさにこの点に関連する内容を扱いますので、ぜひ考えてみてください。
まとめ
本記事では、構造体コードのオーバーロードを、最も簡単で教育的かつ実践的な方法で説明することを試みました。特に初めて目にする方にとっては、最初は理解するのがかなり難しいかもしれません。より複雑で高度なトピックに踏み込む前に、これらの概念をしっかりと理解しておくことが非常に重要です。
付録には、学習と実践のためのコードを掲載しています。次回の記事では、さらに一歩進めて、この構造体オーバーロード自体に任意のデータ型を使用できるケースへと実装を拡張していきます。これは多くの人がOOPでのみ可能だと考えていることですが、特定の種類の解決策を実装するためには、必ずしもOOPを必要としないことがわかるでしょう。それでは、皆さんの学習の成功を祈っています。また次回お会いしましょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15869
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索