
機械学習ベースの取引システムにおける隠れマルコフモデル
内容
- はじめに
- hmmlearnライブラリのアルゴリズム
- hmm.GaussianHMMクラス
- hmm.GMMHMMクラス
- vhmm.VariationalGaussianHMMクラス
- モデル性能の比較
- 事前行列の決定方法
- HMMを用いた市場レジームの識別
- 事前行列の作成
- MetaTrader 5へのモデルのエクスポート
- 結論
はじめに
隠れマルコフモデル(HMM, Hidden Markov Models)は、観測された事象が、マルコフ過程を形成する未観測(隠れ)状態のある系列に依存する逐次データを分析するために設計された強力な確率モデルのクラスです。HMMは二重確率モデルであり、有限個の隠れ状態と、現在の隠れ状態に依存する確率を持つ観測値の系列によって特徴づけられます。HMMの主な仮定には、隠れ状態に対するマルコフ性が含まれ、これは次の状態への遷移確率が現在の状態のみに依存することを意味し、また現在の隠れ状態が既知である場合の観測の独立性も含まれます。
HMMは、音声認識や画像認識、自然言語処理(たとえば品詞タグ付け)、バイオインフォマティクス(DNAおよびタンパク質配列解析)、および時系列解析(予測、異常検出)など、さまざまな分野で広く応用されています。この種のモデルでは、内部状態は直接観測することはできませんが、観測可能な出力に影響を与えます。このためHMMは時間依存関係のある複雑な関係を解析するための有用なツールとなります。このようなモデルでは、観測値は隠れ過程を間接的に反映したものにすぎず、それらを理解することはシステムのダイナミクスに関する重要な情報を提供することができます。
hmmlearnライブラリは、教師なし学習(隠れマルコフモデル)のためのPythonアルゴリズムのセットです。 このライブラリはHMMを扱うためのシンプルで効率的なツールを提供するよう設計されており、scikit-learnライブラリのAPIに従うことで、既存の機械学習プロジェクトへの統合を容易にし、scikit-learnに慣れたユーザーのために学習プロセスを簡略化します。hmmlearnはNumPy、SciPy、Matplotlibなどの基礎的な科学Pythonライブラリ上に構築されています。
hmmlearnの主な機能には、異なる出力分布タイプを持つさまざまなHMMモデルの実装、観測データからのモデルパラメータの学習、最も確からしい隠れ状態系列の推定、学習済みモデルからのサンプル生成、および学習済みモデルの保存と読み込み機能が含まれます。実装されているモデルの多様性により、データの性質に応じて最も適切な出力分布タイプを選択することが可能です。データの種類(連続、離散、カウント)は、各隠れ状態における観測生成過程を最も適切に記述する確率分布を決定します。
hmmlearnライブラリのアルゴリズム
hmmlearnライブラリは、以下の主要なHMMモデルを実装しています。
- hmm.CategoricalHMM:カテゴリカル(離散)観測系列をモデル化するためのものです。
- hmm.GaussianHMM:各隠れ状態においてガウス分布を仮定した連続観測系列をモデル化するためのものです。
- hmm.GMMHMM:各隠れ状態からの発生がガウス分布の混合として記述される連続観測系列をモデル化するためのものです。
- hmm.MultinomialHMM:固定された銘柄集合に対する確率分布を各状態が持つ、離散観測系列をモデル化するためのものです。
- hmm.PoissonHMM:各隠れ状態からの発生がポアソン分布に従う、イベント数を表す時系列をモデル化するためのものです。
- vhmm.VariationalCategoricalHMM:CategoricalHMMの変分版であり、学習に変分推論手法を用いるものです。
- vhmm.VariationalGaussianHMM:GaussianHMMの変分版であり、多変量正規分布に従う連続観測用に設計され、変分推論で学習されるものです。
連続データを扱うアルゴリズムに関心があるため、それらのみを扱います。
hmm.GaussianHMMクラス
hmmlearnライブラリにおけるhmm.GaussianHMMクラスは、ガウス分布による出力を持つ隠れマルコフモデルを実装しています。このモデルは、観測変数が連続値であり、各隠れ状態において多変量正規分布(ガウス分布)に従うと仮定される場合に使用されます。
GaussianHMMは、金融データ(例:株価)、各種センサーの計測値、および各隠れ状態において観測値がガウス分布で記述できるその他の連続過程など、さまざまな時系列のモデリングに広く使用されています。
hmm.GaussianHMMクラスのコンストラクタは以下のパラメータを受け取ります。
- n_components(int、デフォルト1):モデル内の隠れ状態の数を定義します。各状態は固有のガウス分布に対応します。
- covariance_type({"spherical", "diag", "full", "tied"}、デフォルト"diag"):各状態で使用される共分散行列の種類を設定します。共分散タイプの選択はモデルの複雑さおよび推定パラメータ数に直接影響します。
- spherical:各状態はすべての特徴に対して同一の分散を使用します。共分散行列は単位行列のスカラー倍になります。
- diag:各状態は対角共分散行列を使用し、各状態における特徴量は統計的に独立であると仮定されますが、分散は異なる場合があります。
- full:各状態は制約なしの全共分散行列(フル共分散行列)を使用し、各状態における特徴量の相関をモデル化できます。最も柔軟ですが、多くのデータを必要とし過学習の可能性があります。
- tied:すべての隠れ状態が同一の全共分散行列を共有します。特徴間の相関は考慮されますが、その構造はすべての状態で同一であると仮定されます。
- min_covar(float、デフォルト1e-3):学習中に共分散行列の対角要素がゼロ分散などの退化を起こさないようにするための最小値を設定します。
- startprob_prior(array、形状(n_components,), optional):startprob_初期確率に対するディリクレ事前分布のパラメータであり、観測系列の開始状態の確率を定義します。
- transmat_prior(array、形状(n_components,n_components), optional):遷移行列transmat_の各行に対するディリクレ事前分布のパラメータであり、状態間遷移確率を定義します。
- means_prior(array、形状(n_components,), optional):各隠れ状態の平均値means_に対する正規事前分布の平均値です。
- means_weight(array、形状(n_components,), optional):means_に対する正規事前分布の重み(精度)です。
- covars_prior(array、形状(n_components,), optional):共分散行列covars_の事前分布パラメータです。分布の種類はcovariance_typeに依存します。sphericalとdiagでは逆ガンマ分布のパラメータ、fullとtiedでは逆ウィシャート分布のパラメータになります。
- covars_weight(array、形状(n_components,), optional):共分散行列covars_の事前分布に対する重みです。分布の種類はcovariance_typeに依存します。sphericalとdiagでは逆ガンマ分布のパラメータであり、fullとtiedでは逆ウィシャート分布のパラメータであり、逆ガンマ分布または逆ウィシャート分布のスケーリングパラメータとなります。
- algorithm({"viterbi","map"}、optional):観測系列に対応する最尤の高い隠れ状態系列を求めるためのデコードアルゴリズムです。viterbiはビタビアルゴリズムを使用し、mapはFoward-backwardアルゴリズムによる平滑化をおこないます。
- random_state(RandomStateまたはint、optional):モデル初期化の乱数シードまたは乱数生成器です。再現性を確保します。
- n_iter(int、optional):学習時にEMアルゴリズムが実行する最大反復回数です。デフォルトは10です。
- tol (float, optional):EMアルゴリズムの収束判定閾値です。対数尤度の変化がこの値未満になった場合、学習を停止します。デフォルトは0.01です。
- verbose (bool, optional):Trueに設定された場合、収束データは各反復ごとに標準エラーへ出力されます。収束はmonitor_属性を通じても監視することができます。
- params(string、optional):学習中にどのモデルパラメータを更新するかを指定します。s(初期確率startprob_)、t(遷移確率transmat_)、m(平均means_)、c(共分散covars_)の組み合わせを含むことができます。デフォルトはstmc(すべてのパラメータが更新される)です。
- init_params(string、optional):学習開始前にどのモデルパラメータを初期化するかを指定します。記号の意味はparamsと同じです。デフォルトはstmc(すべてのパラメータが初期化される)です。
- implementation(string、optional):使用するFoward-backwardアルゴリズムの実装を定義します。対数形式(log)またはscalingを使用できます。デフォルトでは後方互換性のためlogが使用されますが、通常はscalingの方が高速です。
GaussianHMMのパラメータは、EMアルゴリズムを用いた学習の前に初期化されます。初期化パラメータはモデルの初期状態を定義します。init_paramsパラメータは、どのパラメータが初期化されるかを制御します。いずれかのパラメータがinit_paramsに含まれていない場合、その値はすでに手動で設定されているものと見なされます。
パラメータの初期値はランダムに設定することも、与えられたデータに基づいて計算することもできます。パラメータの正しい初期化は、EMアルゴリズムの収束速度および最終モデルの品質に大きな影響を与える可能性があります。なぜならEMアルゴリズムは局所解に収束する可能性があるためです。
GaussianHMMのパラメータ最適化は、反復的なExpectation-Maximization (EM)アルゴリズムによっておこなわれます。このアルゴリズムは、収束が達成されるまで反復的に実行される2つの主要なステップから構成されます。
- E-step(期待値):このステップでは、現在のモデルパラメータの推定値と観測時系列が与えられたもとで、各時点においてシステムが特定の隠れ状態にあった事後確率(posterior probabilities)が計算されます。これは通常、Foward-backwardアルゴリズムによっておこなわれます。
- M-step(最大化):このステップでは、モデルパラメータ(初期確率、状態間の遷移確率、各状態の平均および共分散)が更新され、E-stepで計算された事後確率のもとで観測データの期待対数尤度を最大化するように調整されます。
このプロセスは収束が達成されるまで繰り返されます。収束は、n_iterで指定された最大反復回数に到達するか、または連続する反復間の対数尤度の変化がtolで指定された閾値より小さくなることで判定されます。EMアルゴリズムは各反復において対数尤度を増加または維持することが保証されていますが、大域的最大値の発見は保証されておらず、結果は初期パラメータ設定に依存する可能性があります。
covariance_typeパラメータの選択は、各隠れ状態における発生をモデル化するために使用される共分散行列の構造に直接的な影響を与えます。
- sphericalを選択した場合、等方的な共分散が仮定されます。すなわち、ある状態におけるすべての特徴量の分散は同一であり、共分散行列は単位行列に比例します。
- diagは対角共分散行列の使用を意味し、各状態における特徴量は統計的に独立であると見なされますが、それぞれ異なる分散を持つ場合があります。
- fullは完全な共分散行列の使用を可能にし、各隠れ状態内の異なる特徴量間の相関を考慮します。
- tiedはすべての隠れ状態が同一の全共分散行列を共有することを意味します。共分散タイプの選択は、各隠れ状態におけるデータ構造に関する仮定に基づくべきです。fullのようなより複雑な共分散タイプは、特徴量間に複雑な依存関係を持つデータにはより適合する可能性がありますが、推定するパラメータ数が増えるため、データが不足している場合には過学習につながる可能性があります。
hmm.GaussianHMMの異なるパラメータが提供する柔軟性により、研究者はモデルを金融時系列の特性に合わせて調整することができます。特にcovariance_typeパラメータは、各隠れ状態における特徴量間の関係について異なる仮定を可能にします。
金融時系列に対してhmm.GaussianHMMパラメータを調整する際には、ボラティリティ、急激な価格変動、分布の正規性からの逸脱などの特性を考慮する必要があります。隠れ状態の数n_componentsは、想定される市場レジームの数に基づいて選択されるべきです。これは専門的知識またはAICやBICなどのモデル選択基準によって決定できます。
通常は少数の状態(例えば2または3)から開始し、必要に応じて増加させることが推奨されますが、その際には過学習のリスクを管理する必要があります。単変量の金融時系列(例えばリターン)の場合にはdiagまたはsphericalが十分である場合があります。多変量時系列(たとえば複数資産のリターンや価格と出来高などの特徴量)の場合には"full"が相関をモデル化できますが、モデルの複雑性が増加します。tiedはすべての状態で同一の相関構造を仮定します。
min_covarパラメータは、分散が過度に小さくなることを防ぎ、過学習を抑制するのに役立ちます。デフォルト値1e-3は一般的な出発点としてよく使用されます。startprob_priorやtransmat_priorを用いた事前分布の設定は、特にデータが限られている場合に有用です。例えば、市場レジームの安定性が期待される場合、それを遷移行列の事前分布に反映させることができます。
n_iterおよびtolパラメータは、EMアルゴリズムの最大反復回数と収束判定閾値を制御します。n_iterを大きくすると収束が改善する可能性がありますが、学習時間が増加します。tolを小さくするとより厳密な収束条件になります。
金融データの前処理は非常に重要です。価格ではなくリターン(変化率)を使用することが推奨され、移動平均やボラティリティ指標(ATRなど)、出来高指標などのテクニカル指標を特徴量として含めることも考えられます。特徴量の正規化または標準化も推奨されます。金融時系列は非定常であることが多いため、差分化やスライディングウィンドウによるパラメータ推定などを用いて市場構造の変化に適応することが考慮されるべきです。
特定の金融データセットに対して最適なハイパーパラメータの組み合わせを見つけるためには、グリッドサーチやベイズ最適化(たとえばOptunaの使用)などの手法を用いるべきです。金融時系列の非定常性により、慎重な前処理と、場合によってはスライディングウィンドウ学習のような適応的手法の使用が必要となります。ハイパーパラメータ調整は、過去データへの過学習を避けつつGaussianHMMモデルが基礎的な市場動態を適切に捉えるために極めて重要です。
hmm.GMMHMMクラス
hmm.GMMHMMクラスは、連続的な発生を扱うために設計されており、それは複数のガウス分布の混合によって最もよく表現されます。これにより、単一のガウス分布を使用する場合よりも複雑な発生パターンのモデリングが可能となり、特に各隠れ状態内に明確なクラスタが存在するデータにおいて有用です。
hmm.GMMHMMは、金融データの分布が特定のレジーム内で多峰性を持つ場合、またはガウス分布から大きく逸脱する場合に有用です。たとえば、高ボラティリティレジームにおけるリターンは、価格変動の方向に応じて異なる特性を示す可能性があります。hmm.GMMHMMは、各隠れ状態に複数のガウス分布からなる混合モデルを割り当てることを可能にすることでhmm.GaussianHMMを拡張します。これは特に金融時系列において、異なる市場レジーム下でより複雑かつ正規分布に従わない動を示すデータに対して有効です。
- hmm.GMMHMMクラスのコンストラクタはhmm.GaussianHMMクラスのすべてのパラメータを含み、さらにn_mixパラメータ(整数、デフォルト1)を追加します。これは各状態における混合成分の数を指定します。また、混合重みに関連する事前分布も追加されます。
- GMMHMMにおけるcovariance_typeパラメータにはわずかな違いがあり、tiedオプションでは各状態のすべての混合成分が同一の全共分散行列を共有します。
- paramsおよびinit_paramsパラメータには、GMM混合重みを制御するためのwという記号も追加されます。
- パラメータにおける主要な違いはn_mixと、それに関連する混合重みの事前分布にあり、これにより各隠れ状態の発生確率をより柔軟にモデル化できます。GMMHMMにおけるより微妙なcovarianceのtiedオプションも、モデルを制約する追加の方法を提供します。
金融時系列に対してhmm.GMMHMMのパラメータを設定する際、混合成分の数n_mixの選択は重要なステップです。混合成分数は、各隠れ状態における金融データの分布を最も適切に表現するように設定されるべきであり、ある程度の試行が必要になる場合があります。通常は少数の成分(たとえば2または3)から開始し、モデルがアンダーフィットする場合に増加させますが、過学習は避ける必要があります。
AICやBICなどの情報量規準を使用してn_mixの最適値を決定することができます。他のパラメータはhmm.GaussianHMMと同様に設定できますが、金融データの特性を考慮する必要があります。たとえばcovariance_typeの選択は、各混合成分内の分散のモデル化方法に影響します。n_mixの最適な選択は、金融時系列におけるhmm.GMMHMMの効果的な利用において重要であり、モデルの複雑さと過学習リスクのバランスを取る必要があります。そのため、信頼性の高い推定を得るために交差検証や情報量規準などの手法を使用することが必要になる場合があります。
vhmm.VariationalGaussianHMMクラス
vhmm.VariationalGaussianHMMクラスは、多変量ガウス分布による出力を持つ隠れマルコフモデルであり、hmm.GaussianHMMで使用される期待値最大化(EM)アルゴリズムではなく、変分推論を用いて学習されます。
変分推論は、潜在変数およびモデルパラメータの真の事後分布を最もよく近似する分布のパラメータを見つけることを目的とします。EMとは異なり、EMがパラメータの点推定を提供するのに対し、変分推論はモデルパラメータの事後分布を提供するため、不確実性の推定に有用です。
vhmm.VariationalGaussianHMMの主な違いは、学習に変分推論を使用する点にあります。このベイズ的アプローチは、hmm.GaussianHMMにおける最尤推定よりも利点があり、特にモデルパラメータの事後分布を通じて不確実性の尺度を提供できる点にあります。
- vhmm.VariationalGaussianHMMクラスのコンストラクタは、n_components、covariance_type、algorithm、random_state、n_iter、tol、verbose、params、init_params、implementationといったパラメータを含み、hmm.GaussianHMMと類似しています。
- 追加の事前分布関連パラメータとして、startprob_prior、transmat_prior、means_prior、beta_prior、dof_prior、scale_priorが含まれます。これらのパラメータがNoneに設定されている場合、デフォルトの事前分布が使用されます。beta_priorパラメータは平均値に対する正規事前分布の精度に関連します。dof_priorおよびscale_priorパラメータは共分散行列の事前分布(covariance_typeに応じて逆ウィシャート分布または逆ガンマ分布)を定義します。
- vhmm.VariationalGaussianHMMの初期化には、すべてのモデルパラメータに対する事前分布の指定が必要です。これらの事前分布は学習において重要な役割を果たし、特にデータが限られている場合には、パラメータに関する事前知識や仮定を組み込むことを可能にします。
金融時系列データに対してvhmm.VariationalGaussianHMMのパラメータを調整する際には、事前分布の選択が重要です。事前分布は正則化の一種 として機能し、モデルが訓練データに過剰適合するのを防ぎます。また、モデルパラメータに関する既存の知識や仮定を組み込むことも可能にします。
たとえば、状態の初期分布startprob_が比較的均一であると考えられる場合、1に近い対称パラメータを持つディリクレ事前分布を使用することができます。同様に、遷移確率transmat_、平均means_prior、共分散scale_priorやdof_priorに関する仮定も適切な事前分布の選択によって符号化できます。
事前分布の選択は、学習後のモデルパラメータの事後分布に影響を与えます。情報的事前分布(たとえば特定の値の周囲で分散が小さいもの)はより強い影響を持ち、事後分布を事前分布に引き寄せます。一方で、非情報的または弱い事前分布(たとえば分散が大きいものや一様分布)は影響が小さくなり、データが事後分布を支配するようになります。
金融時系列データに対するモデル性能の比較
hmm.GaussianHMMモデルは基本的なモデルであり、各隠れ状態における観測された金融データがガウス分布に従うと仮定します。その長所は単純性と計算効率の高さにあり、大規模データセットや、分布が正規分布から大きく逸脱していないと考えられる場合に適しています。
しかしその弱点は正規分布を仮定している点であり、多くの金融時系列に見られる歪度、尖度、厚い裾といった特徴には適合しない可能性があります。各レジーム内の金融データが比較的よく正規分布で近似できる場合にはhmm.GaussianHMMは良好に機能する可能性があります。たとえば日次または週次データにおける主要な市場レジームのモデリングでは有効です。一方で高頻度データや急激なスパイク、非正規分布を含むデータのモデリングでは性能が低下する可能性があります。
hmm.GMMHMMモデルは、各隠れ状態の発生を複数のガウス分布の混合によってモデル化することでhmm.GaussianHMMの能力を拡張します。その強みはより複雑で多峰性の分布をモデル化できる点にあり、単一の市場レジーム内に複数のサブパターンが存在しうる金融データに対してより適しています。たとえば高ボラティリティ期間では、リターンは市場の方向性によって異なる挙動を示す可能性があります。
hmm.GMMHMMの弱点はパラメータ数の増加であり、特にデータが限られている場合には過学習につながる可能性があります。さらにhmm.GaussianHMMと比較して学習計算コストが高くなる可能性があります。
hmm.GMMHMMは、イントラデイデータやボラティリティデータのように、分布が正規分布から逸脱していたり多峰性を持ったりする金融時系列のモデリングにおいて、より高い性能を示す可能性があります。一方で、分布が概ね正規的な単純なレジームや、データ量が非常に少なく過学習リスクが高い場合には性能が低下する可能性があります。
vhmm.VariationalGaussianHMMモデルはベイズ的アプローチである変分推論を用いて学習をおこないます。その強みはパラメータの事後分布を提供できる点であり、モデルの不確実性を評価できることです。ベイズ的手法は事前分布を利用することでモデルを正則化し、事前知識を組み込めるため、データが少ない場合にも有用です。
vhmm.VariationalGaussianHMMの弱点は事前分布の調整の難しさであり、それが結果に大きな影響を与える可能性があります。さらに変分推論は近似手法であるため、得られる事後分布は真の事後分布とは異なる場合があります。
vhmm.VariationalGaussianHMMは、パラメータの不確実性が重要な場合や、データが少なく事前知識を利用する必要がある場合の金融時系列モデリングにおいてより良い性能を示す可能性があります。一方で事前分布が不適切に設定されている場合や、十分なデータがあり最大尤度法による高精度な推定が求められる場合には性能が低下する可能性があります。
モデル選択は利用可能なデータ量、市場動態の複雑さ、モデルの解釈可能性要件などの要因に影響されます。大規模データセットで市場動態が比較的単純な場合には、hmm.GaussianHMMはその単純さと計算効率のために十分かつ好ましい選択となります。より複雑なダイナミクスや非正規分布の場合にはhmm.GMMHMMが必要となる可能性があります。不確実性の評価が重要である場合やデータが少ない場合にはvhmm.VariationalGaussianHMMを検討すべきです。
結論と提言
金融時系列において、最適または最悪のモデルは問題設定とデータの特性に依存します。
一般に、市場レジーム下の金融データがガウス分布で近似可能な場合には、hmm.GaussianHMMは単純で効率的な選択です。分布がより複雑または多峰性を持つ場合には、hmm.GMMHMMがより良い適合を提供する可能性がありますが、より慎重な調整が必要であり過学習しやすくなります。vhmm.VariationalGaussianHMMは不確実性推定が可能なベイズ的アプローチを提供し、特定のシナリオでは有用ですが、事前分布の理解と適切な設定が必要です。
モデル選択は理論的な根拠のみで決定できない点を強調する必要があります。実データに対する実証的検証およびバックテストは、特定の問題に最も適したモデルを決定するために不可欠です。対数尤度、予測精度、および金融分野特有の指標(例:MAPE、R^2)などのさまざまな性能指標を用いてモデルの性能を比較し、特定の金融時系列分析問題を解くために最も適したモデルを選択すべきです。
hmmlearnライブラリにおける時系列の事前共分散行列の決定方法
hmmlearnライブラリにおける一般的なHMMの一種としてガウス発生モデルがあり、各隠れ状態における観測データは多変量正規分布に従うと仮定されます。この分布のパラメータは平均ベクトルと共分散行列であり、後者は観測データの各成分間の形状、方向、および依存関係の程度を決定します。
ガウスHMMを学習する際、特に変分推論のようなベイズ的手法を用いる場合、事前共分散行列の定義は重要な役割を果たします。時系列の共分散構造に関する事前知識は、特にデータ量が限られている状況においてモデル学習を大きく支援します。不適切に指定された事前分布は、最適でない結果、学習アルゴリズムの収束問題、またはモデルの過学習につながる可能性があります。
Pythonのhmmlearnライブラリは、ガウス発生を持つHMMを扱うためのhmm.GaussianHMM(およびhmm.GMMHMM)クラスとvhmm.VariationalGaussianHMMクラスを提供します。hmm.GaussianHMMクラスは従来のExpectation-Maximization (EM)アルゴリズムによる学習を実装しているのに対し、vhmm.VariationalGaussianHMMは変分推論に基づくベイズ的アプローチを提供します。
両クラスは学習および初期化に影響を与えるパラメータを提供しており、共分散行列に対する事前分布の指定も可能です。具体的には、covariance_typeパラメータは共分散行列の種類(spherical、diag、full、tied)を選択でき、さらにhmm.GaussianHMMではcovars_priorおよびcovars_weight、vhmm.VariationalGaussianHMMではscale_priorおよびdof_priorによって共分散に対する事前分布を指定できます。これらのパラメータを正しく使用するには、時系列における事前共分散行列の決定方法に関する様々なアプローチの理解が必要となります。
時系列の事前共分散行列の決定方法
時系列の事前共分散行列を決定するためには、データに対する異なる仮定および利用可能な事前情報に基づくいくつかのアプローチが存在します。
経験的推定 最も直接的な方法は、過去に収集された時系列データから共分散行列を直接推定することです。標本共分散行列は時系列の異なる成分間の共分散を反映しており、行列の各要素(i, j)はi番目とj番目の成分間の標本共分散を表し、対角要素は標本分散を表します。
長さT、次元pの時系列Xに対して、標本共分散行列Σ̂は標準的な式により計算できます。しかし、時系列に対する経験的推定には制限があります。
第一に、時系列は定常であると仮定されます。すなわち、統計的特性(平均や共分散など)が時間に依存しないことが前提となります。
第二に、信頼できる推定を得るためには、次元と比較して十分なデータ量が必要です。
第三に、標本サイズが次元に比べて小さい場合、共分散行列の特異性の問題が生じる可能性があり、一部のアルゴリズムで使用できなくなることがあります。
これらの制限はあるものの、十分な定常データが利用可能であれば、経験的推定は合理的な出発点となり得ます。
収縮法: データ量が限られている場合や高次元の場合には、経験的共分散推定が不安定になる可能性があります。そのような場合、収縮法を用いることができます。これらの方法は標本共分散行列とターゲット行列を組み合わせ、収縮係数によってそれぞれの重みを決定します。
ターゲット行列は例えば単位行列(成分間独立を仮定)、対角行列(成分間の無相関を仮定)、または一定分散の行列などを用いることができます。線形収縮は Rα = (1 − α)S + αT により表され、Sは標本共分散行列、Tはターゲット行列、αは収縮係数です。
収縮法はデータ量が限られている場合に特に有効であり、共分散推定誤差を減少させ、頑健性を向上させ、過学習を防ぐことができます。ただしターゲット構造の選択にはデータの依存構造に関する事前情報が必要です。
情報的事前分布の利用: 対象領域や時系列の共分散構造に関する事前知識がある場合、それを情報的事前分布としてモデルに組み込むことができます。
共分散行列に対しては逆ウィシャート分布がよく用いられます。これは多変量正規分布における共分散行列の共役事前分布です。逆ウィシャート分布のパラメータはスケール行列と自由度です。
事前分布のパラメータの選択は、共分散構造に関する既存の事前信念を反映する必要があります。情報的事前分布は過去研究、専門知識、または類似時系列の分析に基づいて構築できます。このような事前分布は、特に十分なデータがない場合にモデル学習を大きく改善する可能性があります。
非情報的事前分布: 共分散構造に関する強い事前仮定が存在しない場合には、非情報的事前分布を使用することができます。この場合の目的は事前の影響を最小化し、データが主に学習結果を決定するようにすることです。
共分散行列に対する非情報的事前分布の例としてJeffreys分布があります。相関行列に対してはLKJ事前分布がよく用いられ、相関ゼロ周辺への集中度を調整することができます。ただし、完全に非情報的な事前分布の定義は難しく、特にデータが少ない場合には弱い事前分布であっても結果に影響を与える可能性があります。
時系列の構造的仮定:時系列が既知の自己相関特性を持つ場合、その情報を用いて事前共分散行列を構築することができます。たとえば自己相関関数(ACF)および偏自己相関関数(PACF)の分析により、時系列を説明する自己回帰(AR)または移動平均(MA)過程の次数を特定できます。
これらのモデルのパラメータに基づき、時間依存性を反映した事前共分散行列を構築できます。たとえばAR(1)過程では、共分散構造は自己相関パラメータに依存します。このアプローチは、時系列がある時系列モデルで適切に記述でき、そのモデルのパラメータが事前データに基づいて推定可能であることを前提としています。
hmmlearnにおける事前共分散行列決定方法の適用
hmmlearnライブラリは、hmm.GaussianHMMおよびvhmm.VariationalGaussianHMMクラスを用いて、事前共分散行列を定義するための様々なオプションを提供します。
事前データから得られた経験的共分散行列の推定値は、両クラスにおいてcovars_属性を直接初期化するために使用できます。同様に、収縮法を適用して得られた共分散行列もcovars_の初期化に使用できます。
情報的事前分布を指定するために、hmm.GaussianHMMクラスはcovars_priorおよびcovars_weightパラメータを提供します。これらのパラメータはcovars_共分散行列の事前分布のパラメータを制御します。事前分布の種類はcovariance_typeの値によって決定されます。covariance_typeがsphericalまたはdiagの場合は逆ガンマ分布が使用され、fullまたはtiedの場合は逆ウィシャート分布が使用されます。
covars_priorパラメータは逆ガンマ分布の形状パラメータとして解釈され、逆ウィシャート分布における自由度と関連します。covars_weightパラメータは逆ガンマ分布のスケールパラメータであり、逆ウィシャート分布におけるスケール行列と関連します。
vhmm.VariationalGaussianHMMクラスもscale_priorおよびdof_priorパラメータを用いて共分散行列に対する情報的事前分布を指定できます。dof_priorパラメータはWishart分布(fullおよびtied)または逆ガンマ分布(sphericalおよびdiag)の自由度を指定します。scale_priorパラメータはWishart分布(fullおよびtied)のスケール行列、または逆ガンマ分布(sphericalおよびdiag)のスケールパラメータを指定します。これらのパラメータは、変分推論を用いて実装されたベイズモデルにおける共分散構造に関する事前信念を決定します。
非情報的事前分布を指定する場合には、covars_prior、covars_weight、scale_prior、dof_priorを適切に設定し、事前分布の影響を弱くすることができます。たとえば精度や逆スケールに関するパラメータを非常に小さくする、あるいはスケールに関するパラメータを非常に大きくするなどの方法があります。
最後に、時系列の構造的仮定は自己相関分析に基づいて共分散行列を構築することで考慮でき、その行列をhmmlearnの両クラスにおいてcovars_属性の初期化に使用することができます。
HMMを用いた市場レジームの識別:実践編
このセクションを読む前に、以下の2つの前回記事を読むことを推奨します。
これらの記事では、取引システム構築の基本的な原理を説明しています。しかし、因果推論や市場レジームのクラスタリングの代わりに、ここでは隠れマルコフモデルを用いて市場レジームを識別します。この方法により、これらのアプローチを相互にテストおよび比較し、その有効性について独自の見解を形成できます。
開始する前に、必要なパッケージがインストールされていることを確認してください。
import math import pandas as pd from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from hmmlearn import hmm, vhmm from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester_one_direction from bots.botlibs.export_lib import export_model_to_ONNX
アルゴリズムは、市場レジームのクラスタリングに関する記事で説明されているのと同じ原理を用いて隠れマルコフモデルを学習することで市場レジームを識別します。したがって、コードの変更は市場レジームの識別のみに影響します。
以下に市場レジームを定義する関数を示します。
def markov_regime_switching(dataset, n_regimes: int, model_type="GMMHMM") -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract meta features meta_X = data.loc[:, data.columns.str.contains('meta_feature')] if meta_X.shape[1] > 0: # Format data for HMM (requires 2D array) X = meta_X.values # Features normalization before training from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Create and train the HMM model if model_type == "HMM": model = hmm.GaussianHMM( n_components=n_regimes, covariance_type="spherical", n_iter=10, ) elif model_type == "GMMHMM": model = hmm.GMMHMM( n_components=n_regimes, covariance_type="spherical", n_iter=10, n_mix=3, ) elif model_type == "VARHMM": model = vhmm.VariationalGaussianHMM( n_components=n_regimes, covariance_type="spherical", n_iter=10, ) # Fit the model model.fit(X_scaled) # Predict the hidden states (regimes) hidden_states = model.predict(X_scaled) # Assign states to clusters data['clusters'] = hidden_states return data
コードは、理論部分で説明した3つのモデルを示しており、これらはデフォルトパラメータを持っています。まず、それらが正常に動作することを確認し、その後でパラメータの設定に進みます。関数呼び出し時にいずれかのモデルを選択し、そのままクラスタリングの品質をテストすることができます。
学習のサイクルは、市場レジームを識別する関数を除いて同じままです:
for i in range(1): data = markov_regime_switching(dataset, n_regimes=hyper_params['n_clusters'], model_type="HMM") sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_one_direction(clustered_data, markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1)))
学習のハイパーパラメータは以下のように設定されます。
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 5,
}
- 特徴量の期間は5とし、この期間に基づいて隠れマルコフモデルの学習をおこないます。
- ゴールドの買い戦略を対象とします。
- 推定されるレジーム数は5です。
すべてのモデルは、特徴量として移動ウィンドウにおける標準偏差(ボラティリティ)を用いてテストされます。
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
デフォルトパラメータによる学習結果
- GaussianHMMアルゴリズムは、デフォルトパラメータにおいて隠れ状態(レジーム)を効果的に見つける能力を示し、その結果、テストデータ上で許容可能なバランスカーブが得られました。
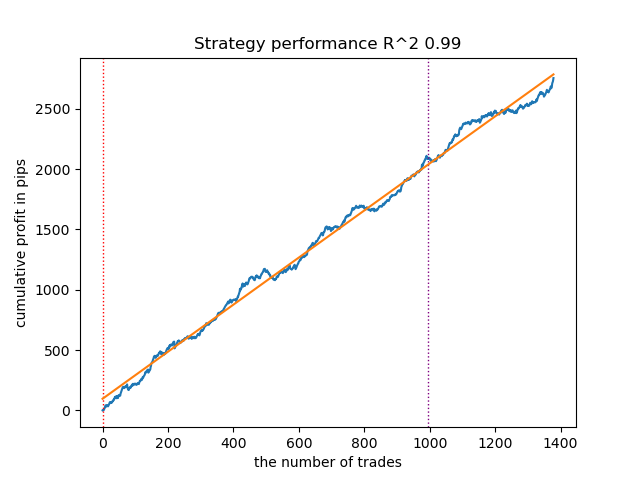
図1:デフォルト設定によるGaussianHMMのテスト
- GMMHMMアルゴリズムも良好な性能を示し、モデルの品質に目立った変化は観察されませんでした。
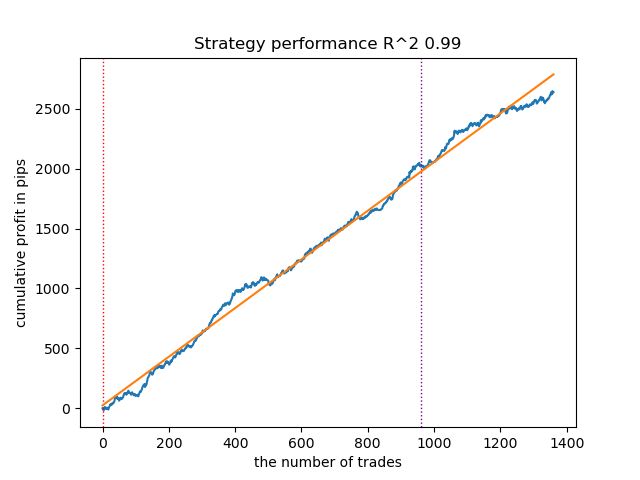
図2:デフォルト設定によるGMMHMMのテスト
- VariationalGaussianHMMアルゴリズムは一見すると外れ値のように見える可能性がありますが、数回再学習を行うことでより良いカーブを生成する場合があります。
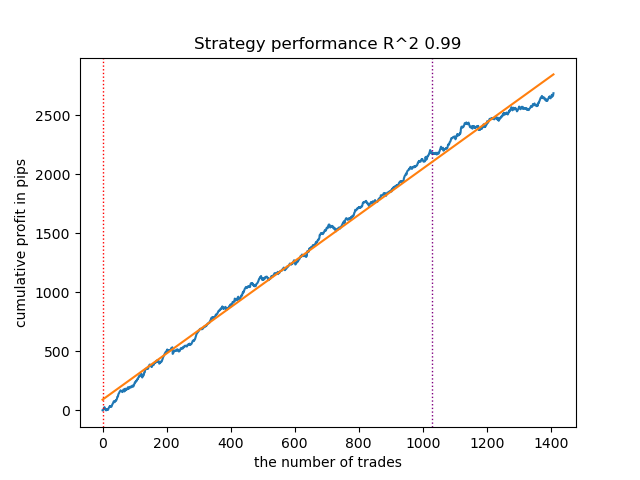
図3:デフォルト設定によるVariationalGaussianHMMのテスト
全体として、すべてのアルゴリズムは動作可能であることが確認され、次にパラメータ調整へ進むことができます。
学習反復回数の増加(n_iter = 100)
マルコフモデルの学習反復回数を増加させることで、すべてのアルゴリズム変種において新しいデータ上の結果がわずかに改善されました。これは、アルゴリズムがより良い局所最適解を見つけたためと考えられます。全体として、この段階では異なるアルゴリズム間で生成されたモデルの品質に大きな差は観察されませんでした。しかしGaussianHMMは、その単純性によりやや高速に学習しました。
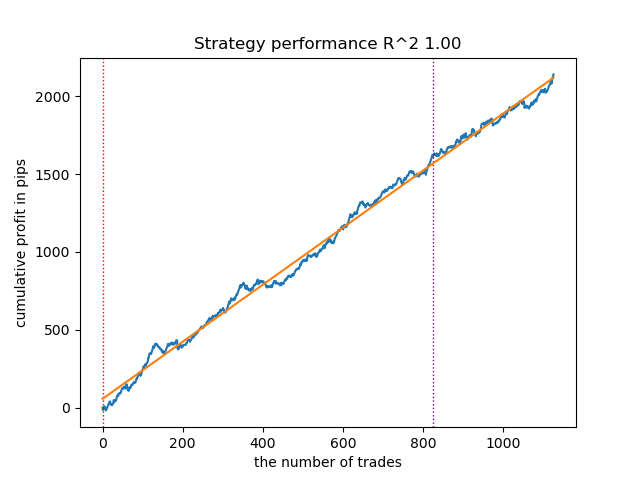
図4:n_iter = 100でのGaussianHMMのテスト
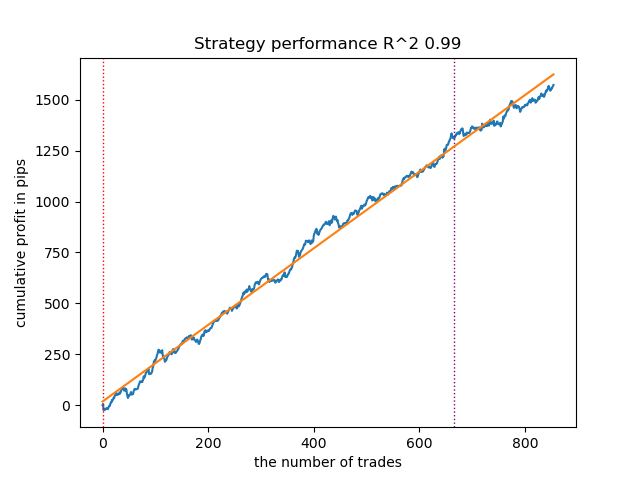
図5:n_iter = 100でのGMMHMMのテスト
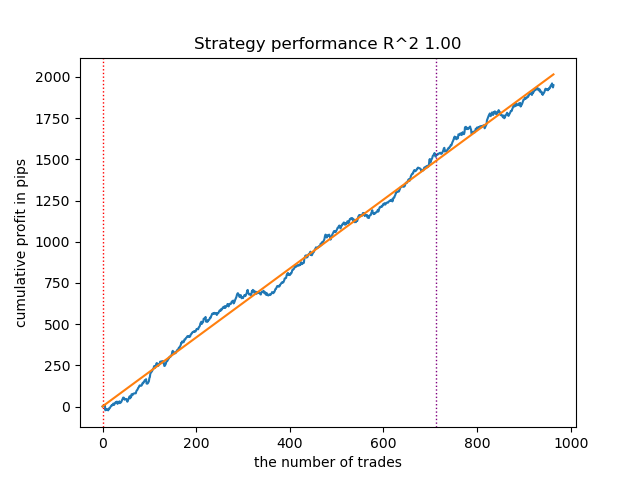
図6:n_iter = 100 でのVariationalGaussianHMMのテスト
市場レジーム数の削減(3レジーム)
反復回数はモデル品質に影響を与えるため、このパラメータは100回に固定します。次に、市場レジーム(モデルの隠れ状態)の数を3に減らし、その結果を確認します。
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 3,
} GaussianHMM、GMMHMM、およびVariationalGaussianHMMはいずれも3つの市場レジームの識別において良好な性能を示しましたが、最後のモデルは複数回の再学習を必要としました。
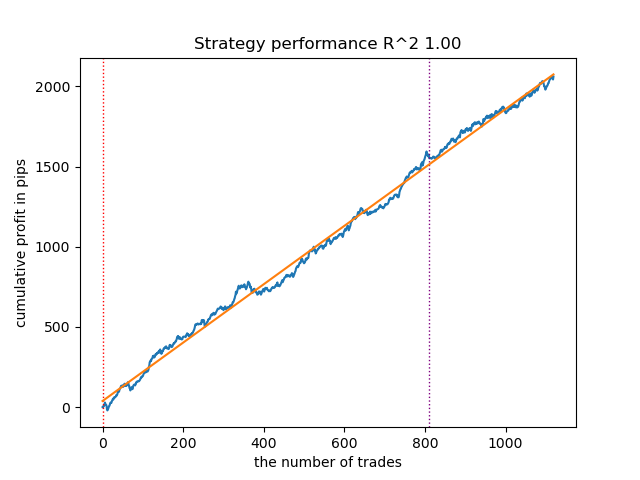
図7:n_iter = 100および3レジームでのVariationalHMMのテスト
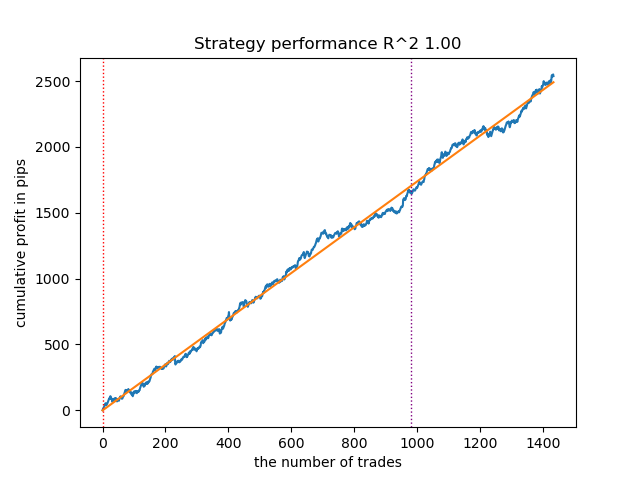
図8:n_iter = 100および3レジームでのGMMHMMのテスト
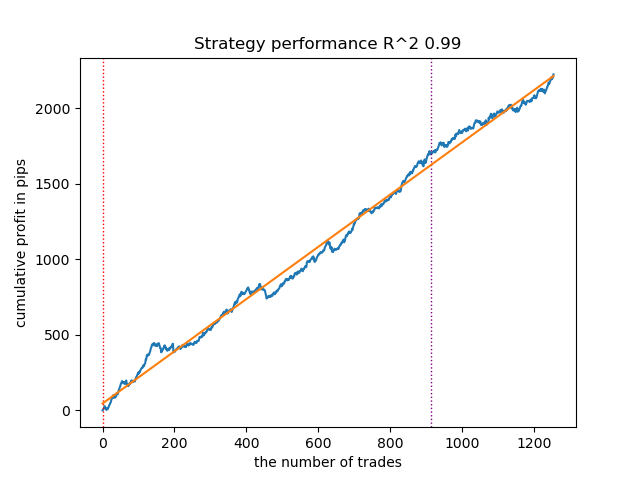
図9:n_iter = 100および3レジームでのVariationalGaussianHMMのテスト
隠れマルコフモデルにおける事前共分散行列の作成
理論部分では、時系列に対する事前共分散行列の決定方法として5つの手法を検討しました。そのうち、最初の手法と最後の手法が私たちにとって最も適しています。これらを改めて確認します。
- 経験的推定: 最も直接的な方法は、過去に収集された時系列データから共分散行列を直接推定することです。標本共分散行列は時系列の異なる成分間の共分散を反映しており、行列の各要素(i, j)はi番目とj番目の成分間の標本共分散を表し、対角要素は標本分散を表します。 長さT、次元pの時系列Xに対して、標本共分散行列Σ̂は標準的な式によって計算できます。しかし、時系列に対する経験的推定には制限があります。 第一に、時系列は定常であると仮定されます。すなわち、統計的特性(平均や共分散など)が時間に依存しないことが前提となります。 第二に、信頼できる推定を得るためには、次元と比較して十分なデータ量が必要です。 第三に、標本サイズが次元に比べて小さい場合、共分散行列の特異性の問題が生じる可能性があり、一部のアルゴリズムで使用できなくなることがあります。これらの制限はあるものの、十分な定常データが利用可能であれば、経験的推定は合理的な出発点となり得ます。
- 時系列に関する構造的仮定:時系列が既知の自己相関特性を持つ場合、その情報を用いて事前共分散行列を構築することができます。たとえば自己相関関数(ACF)および偏自己相関関数(PACF)の分析により、時系列を説明する自己回帰(AR)または移動平均(MA)過程の次数を特定できます。 これらのモデルのパラメータに基づき、時間依存性を反映した事前共分散行列を構築できます。たとえばAR(1)過程では、共分散構造は自己相関パラメータに依存します。このアプローチは、時系列がある時系列モデルで適切に記述でき、そのモデルのパラメータが事前データに基づいて推定可能であることを前提としています。
しかし、金融時系列がこのような単純なモデルで十分に記述できるかどうかは確実ではありません。実験の結果、このような事前分布は必ずしも隠れマルコフ状態の推定結果を改善しないことが分かりました。さらに、k平均法による事前クラスタリングを用いて、得られた値で遷移行列を初期化する実験も行いました。その結果、隠れマルコフモデルは前回の論文と同様に市場レジームのクラスタリング結果を示しましたが、新しいデータにおける収益曲線の改善はほとんど、あるいは全く見られませんでした。
クラスタリングに基づく事前分布の作成
学習スクリプトは、クラスタリングを用いて事前分布を事前計算し、その後に隠れマルコフモデルを学習するための実験的な関数を示しています。
def markov_regime_switching_prior(dataset, n_regimes: int, model_type="HMM", n_iter=100) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract meta features meta_X = data.loc[:, data.columns.str.contains('meta_feature')] if meta_X.shape[1] > 0: # Format data for HMM (requires 2D array) X = meta_X.values # Features normalization before training scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Calculate priors from meta_features using k-means clustering from sklearn.cluster import KMeans # Use k-means to cluster the data into n_regimes groups kmeans = KMeans(n_clusters=n_regimes, n_init=10) cluster_labels = kmeans.fit_predict(X_scaled) # Calculate cluster-specific means and covariances to use as priors prior_means = kmeans.cluster_centers_ # Shape: (n_regimes, n_features) # Calculate empirical covariance for each cluster from sklearn.covariance import empirical_covariance prior_covs = [] for i in range(n_regimes): cluster_data = X_scaled[cluster_labels == i] if len(cluster_data) > 1: # Need at least 2 points for covariance cluster_cov = empirical_covariance(cluster_data) prior_covs.append(cluster_cov) else: # Fallback to overall covariance if cluster is too small prior_covs.append(empirical_covariance(X_scaled)) prior_covs = np.array(prior_covs) # Shape: (n_regimes, n_features, n_features) # Calculate initial state distribution from cluster proportions initial_probs = np.bincount(cluster_labels, minlength=n_regimes) / len(cluster_labels) # Calculate transition matrix based on cluster sequences trans_mat = np.zeros((n_regimes, n_regimes)) for t in range(1, len(cluster_labels)): trans_mat[cluster_labels[t-1], cluster_labels[t]] += 1 # Normalize rows to get probabilities row_sums = trans_mat.sum(axis=1, keepdims=True) # Avoid division by zero row_sums[row_sums == 0] = 1 trans_mat = trans_mat / row_sums # Initialize model parameters based on model type if model_type == "HMM": model_params = { 'n_components': n_regimes, 'covariance_type': "full", 'n_iter': n_iter, 'init_params': '' # Don't use default initialization } from hmmlearn import hmm model = hmm.GaussianHMM(**model_params) # Set the model parameters directly with our k-means derived priors model.startprob_ = initial_probs model.transmat_ = trans_mat model.means_ = prior_means model.covars_ = prior_covs # Fit the model model.fit(X_scaled) # Predict the hidden states (regimes) hidden_states = model.predict(X_scaled) # Assign states to clusters data['clusters'] = hidden_states return data return data
GaussianHMMモデルを例にとると、事前分布の準備は次のようになります。
- データの正規化:メタ特徴量はStandardScalerを用いてスケーリングされ、クラスタリング結果にスケールの影響が及ばないようにします。
- k平均法クラスタリング:これは隠れ状態(レジーム)の初期パラメータを定義するために用いられます。データはn_regimes個のクラスタに分割されます。得られたクラスタラベルcluster_labelsは、事前平均prior_means(クラスタ中心)および共分散行列prior_covs(クラスタ内の経験的共分散、またはクラスタが小さい場合は全体共分散)の計算に使用されます。
- 初期確率の計算:初期分布initial_probsは各クラスタに属するデータ点の割合として計算されます。たとえばデータの30%がクラスタ0に属する場合、initial_probs[0] = 0.3となります。
- 遷移行列:時間的にあるクラスタの後に別のクラスタがどの程度出現するかを計算します。
- その後、隠れマルコフモデルはこれらの事前情報を用いて初期化され、学習がおこなわれます。
その他の手法は依存関係に対する仮定がさらに弱いため、今回は考慮されていません。これは事前分布の決定方法として完全なリストではない可能性があり、他の手法も存在し得ますが、それらは専門家の判断に基づく必要があります。
事前分布を用いた隠れマルコフモデルのテスト
結果のばらつきが減少したことが確認されました。モデルが局所最適解に陥る可能性は低下しましたが、その一方で多様性は減少しました。また、隠れマルコフモデルによる市場レジームの識別では、通常k平均法よりも少ないレジーム数(クラスタ数)が必要となる傾向があります。
設定された事前分布を用いて3つのモデルをテストした結果は以下の通りです。
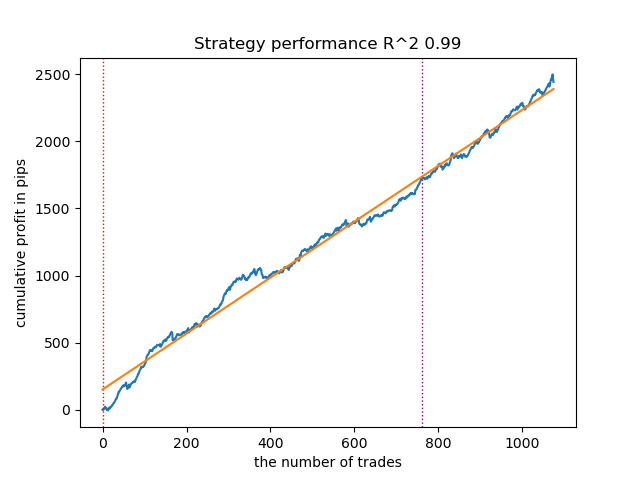
図10:事前分布を用いたGaussianHMMのテスト
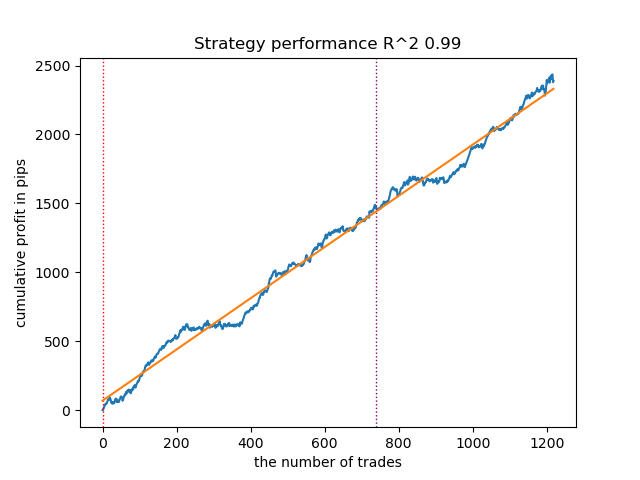
図11:事前分布を用いたGMMHMMのテスト
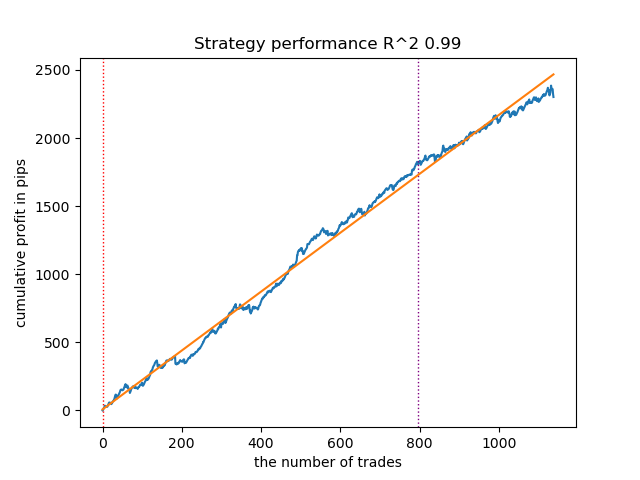
図12:事前分布を用いたVariationalGaussianHMMのテスト
MetaTrader 5用のモデルのエクスポートとボットのコンパイル
モデルのエクスポートは、以前の記事で提示した方法とまったく同様におこなわれます。エクスポート用のモジュールは添付アーカイブに含まれています。
ここでは、カスタムストラテジーテスターを用いてモデルを選択したと仮定します。
# TESTING & EXPORT models.sort(key=lambda x: x[0]) test_model_one_direction(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=True)
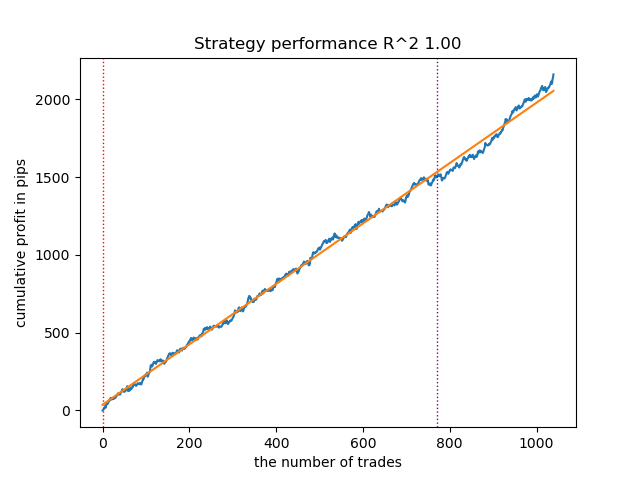
図13:カスタムストラテジーテスターを用いた最良モデルのテスト
その後、エクスポート関数を呼び出し、モデルをターミナルフォルダへ保存します。
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods_meta'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
その後、記事の末尾に添付されているボットをコンパイルし、MetaTrader 5のテスターで動作確認をおこなう必要があります。
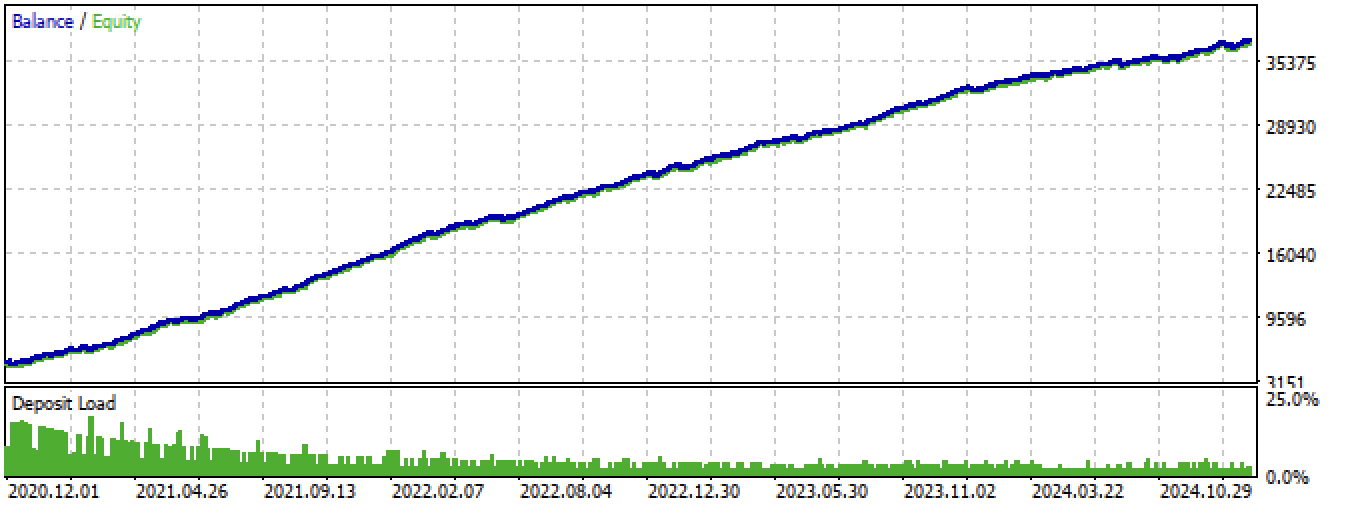
図14:全期間におけるMetaTrader 5ターミナルでの最良モデルのテスト
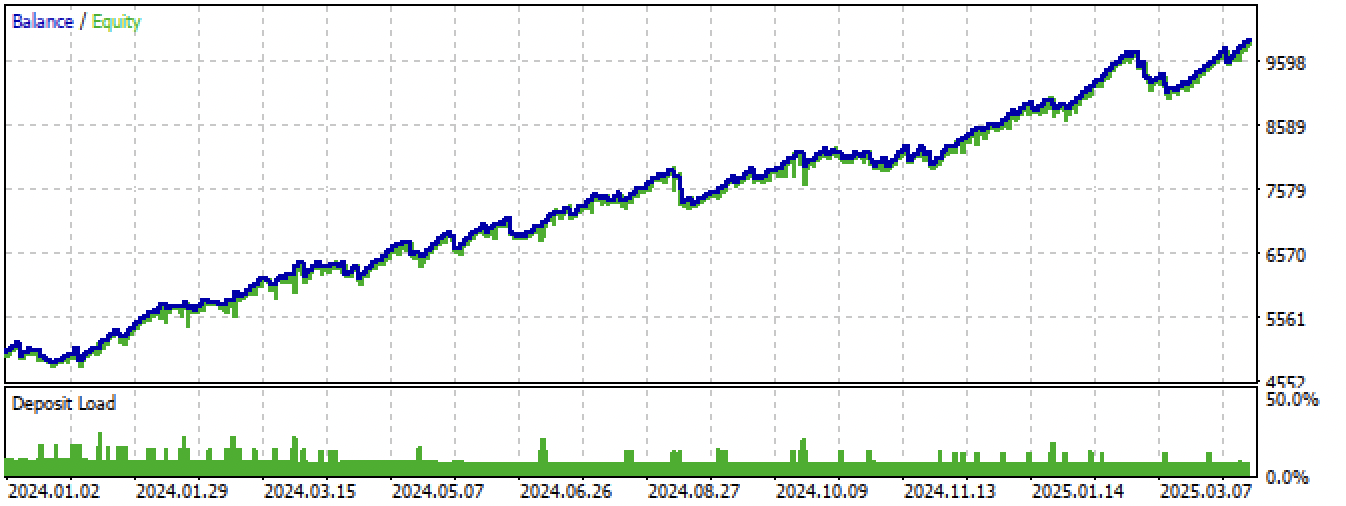
図15:新規データにおけるMetaTrader 5ターミナルでの最良モデルのテスト
結論
隠れマルコフモデルは市場レジームを識別するための興味深い手法です。しかし、他の機械学習モデルと同様に、非定常時系列に対しては過学習を起こしやすいという問題があります。
事前行列の適切な設定により、新しいデータ上でも有効性を維持するより安定した市場レジームを見つけることができます。一般的に、クラスタリングの場合よりも少ない市場レジーム数で十分となる傾向があります。たとえば最初のケースで10個のクラスタが必要だったとしても、2つ目のケースでは3〜5個の隠れ状態で足りる場合があります。
3つのアルゴリズムの性能差は大きくは確認されず、いずれも概ね同様の結果を示しました。そのため最も単純で高速なGaussianHMMを使用できます。GMMHMMは理論上、各市場レジーム内のサブパターンを捉えることによりより滑らかな資金曲線を生成できますが、その分過学習のリスクが高くなる可能性があります。VariationalGaussianHMMはより慎重な事前分布の設定が必要であり、パラメータの定義や解釈もより困難です。
もう1つの有用なアプローチとして、各foldにおける分布パラメータを推定しながらモデルの交差検証をおこなう方法が考えられますが、本記事ではこのアプローチは扱いませんでした。
Python files.zipアーカイブには、Python環境向けの開発ファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| one direction HMM.py | モデル学習用のメインスクリプト |
| labeling_lib.py | 取引ラベル付けロジックモジュールの更新 |
| tester_lib.py | 機械学習ベースのカスタムストラテジーテスターの更新 |
| export_lib.py | モデルをターミナルにエクスポートするモジュール |
| XAUUSD_H1.csv | MetaTrader 5ターミナルからエクスポートしたレートデータ |
MQL5 files.zipアーカイブには、MetaTrader 5ターミナル用のファイルが含まれています。
| ファイル名 | 説明 |
|---|---|
| one direction HMM.ex5 | 記事で作成したボットのコンパイル済みファイル |
| one direction HMM.mq5 | 記事で使用したボットのソースコード |
| Include//Trend following folder | ONNXモデルおよびボット接続用ヘッダファイル |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17917
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
Затем, следует скомпилировать приложенного в конце статьи бота и протестировать его в тестере MetaTrader 5.
図 14. MetaTrader 5 ターミナルにおける全期間の最良モデルのテスト
MQL5 files.zipアーカイブにはMetaTrader 5ターミナル用のファイルが含まれています。
記事に掲載されたバックテスト結果の対応するtstファイルを公開することを標準にしてください。ありがとうございました。
記事に掲載されたバックテスト結果の対応するtstファイルも公開することを標準にしてください。ありがとうございます。