
Algorithmische Handelsstrategien: KI und ihr Weg zu den goldenen Zinnen
Einführung
Die Entwicklung des Verständnisses der Fähigkeiten von Methoden des maschinellen Lernens im Handel hat zur Entwicklung verschiedener Algorithmen geführt. Sie sind gleich gut in der gleichen Aufgabe, aber grundlegend verschieden. In diesem Artikel wird erneut ein unidirektionales Handelssystem für Gold betrachtet, allerdings unter Verwendung eines Clustering-Algorithmus.
- Im vorangegangenen Artikel wurden zwei Algorithmen zur kausalen Schlussfolgerung beschrieben, mit denen eine ähnliche Trendstrategie für Gold entwickelt werden kann.
- In dem Artikel über das Clustering von Zeitreihen wurden verschiedene Möglichkeiten des Clustering bei Handelsaufgaben erörtert.
- Die Entwicklung einer Strategie zur Umkehrung des Mittelwerts mit Hilfe eines Clustering-Algorithmus wurde der Öffentlichkeit bereits vorgestellt.
- Die Entwicklung eines auf Clustering basierenden Trendhandelssystems hat ebenfalls die Möglichkeiten dieses Ansatzes aufgezeigt.
Wenn man diesen wichtigen Ansatz zur Analyse und Prognose von Zeitreihen aus verschiedenen Blickwinkeln betrachtet, kann man seine Vor- und Nachteile im Vergleich zu anderen Methoden zur Erstellung von Handelssystemen, die ausschließlich auf der Analyse und Prognose von Finanzzeitreihen beruhen, bestimmen. In einigen Fällen sind diese Algorithmen sehr effektiv und übertreffen die klassischen Ansätze sowohl in Bezug auf die Geschwindigkeit der Erstellung als auch auf die Qualität der resultierenden Handelssysteme.
In diesem Artikel konzentrieren wir uns auf den unidirektionalen Handel, bei dem der Algorithmus nur kauft oder verkauft. Als Basisalgorithmen werden CatBoost- und K-Means-Algorithmen verwendet. CatBoost ist ein Basismodell, das die Funktionen eines binären Klassifizierers für die Klassifizierung von Handelsgeschäften übernimmt. K-Means wird hingegen in der Vorverarbeitungsphase zur Bestimmung der Marktarten verwendet.
Vorbereitung der Arbeit und Import von Modulen
import math import pandas as pd from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester_one_direction from bots.botlibs.export_lib import export_model_to_ONNX import time
Der Code verwendet nur zuverlässige und überprüfte öffentlich verfügbare Pakete wie z. B.:
- Pandas – zuständig für die Arbeit mit Datentabellen (dataframes)
- Scikit-learn – enthält verschiedene Funktionen für die Vorverarbeitung und das maschinelle Lernen, einschließlich Clustering-Algorithmen.
- CatBoost – ein leistungsstarker Gradient-Boosting-Algorithmus von Yandex
Die einzelnen von mir erstellten Module sind importiert worden:
- labeling_lib – enthält Sampler-Funktionen zur Kennzeichnung von Handelsgeschäften
- tester_lib – enthält Tester für auf maschinellem Lernen basierende Strategien.
- export_lib – ein Modul zum Exportieren trainierter Modelle in Meta Trader 5 im ONNX-Format
Daten abrufen und Merkmale erstellen
def get_prices() -> pd.DataFrame:
p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+')
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed')
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
return pFixed.dropna() Der Code implementiert das Herunterladen von Kurse aus einer Datei, um die Beschaffung von Daten aus verschiedenen Quellen zu erleichtern. Es werden nur Schlusskurse verwendet. Auf der Grundlage dieser Daten werden die Merkmale erstellt.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1
Die Merkmale werden in zwei Gruppen unterteilt:
- Die wichtigsten Merkmale für das Training eines grundlegenden Modells, das die Richtung des Handels vorhersagt.
- Zusätzliche Metamerkmale für das Clustering. Sie werden verwendet, um die Quelldaten in Cluster (Marktmodi) zu unterteilen.
In diesem Beispiel wird die Volatilität (Standardabweichungen der Preise in gleitenden Fenstern eines bestimmten Zeitraums) als Merkmal verwendet. Wir werden aber auch andere Merkmale wie gleitende Durchschnitte und die Schiefe von Verteilungen testen.
Clustering der Marktteilnehmer
def clustering(dataset, n_clusters: int) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] data['clusters'] = KMeans(n_clusters=n_clusters).fit(meta_X).labels_ return data
Die Funktion erhält einen Datenrahmen mit Preisen und Merkmalen und verwendet zusätzliche Meta-Merkmale, um eine bestimmte Anzahl von Clustern zu bilden (normalerweise 10). Der K-Means-Algorithmus wird für das Clustering verwendet. Danach wird jeder Zeile des Datenrahmens eine Kennzeichnung (labels) des Clusters zugewiesen, das dieser Beobachtung entspricht. Und der Datenrahmen wird mit einer zusätzlichen Spalte „clusters“ zurückgegeben.
Eine Funktion zum Trainieren von Klassifikatoren
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=500, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=300, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model_one_direction([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
Für das Training werden zwei Modelle verwendet. Die erste wird auf Basis von Basismerkmalen und Labels trainiert, die zweite auf Basis von Meta-Merkmalen und Meta-Kennzeichen. Wenn für das erste Modell die Handelsrichtungen die Bezeichnungen sind, sind für das zweite Modell die Clusternummern die Bezeichnungen. 1 – wenn die Daten dem gewünschten Cluster entsprechen, und 0 – wenn die Daten allen anderen Clustern entsprechen.
Vor dem Training werden die Daten in einem Verhältnis von 70/30 in Trainings- und Validierungsdaten aufgeteilt, sodass der CatBoost-Algorithmus weniger übererfüllt wird. Es verwendet Validierungsdaten, um frühzeitig zu stoppen, wenn der Fehler während des Lernprozesses nicht mehr auf sie zurückfällt. Dann wird das beste Modell ausgewählt, das bei den Validierungsdaten den geringsten Vorhersagefehler aufweist.
Nach dem Training der Modelle werden diese an die Testfunktion weitergeleitet, um die Gleichgewichtskurve anhand von R^2 zu schätzen. Dies ist für die anschließende Sortierung der Modelle und die Auswahl des besten Modells erforderlich.
Modellprüfungsfunktion
def test_model_one_direction( result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): pr_tst = get_features(get_prices()) X = pr_tst[pr_tst.columns[1:]] X_meta = X.copy() X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X_meta)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(pr_tst, stop, take, forward, backward, markup, direction, plt)
Die Funktion akzeptiert zwei trainierte Modelle (das Haupt- und das Metamodell) sowie die übrigen Parameter, die zum Testen in einem nutzerdefinierten Strategietester erforderlich sind. Anschließend wird wieder ein Datenrahmen mit Preisen und Merkmalen erstellt, die an diese Modelle zur Vorhersage übermittelt werden. Die erhaltenen Vorhersagen werden in den Spalten „labels“ und „meta_labels“ dieses Datenrahmens gespeichert.
Ganz am Ende wird die nutzerdefinierte Testerfunktion aufgerufen, die sich im Plug-in-Modul tester_lib.py befindet. Es führt Modelltests für die Historie durch und liefert eine Schätzung von R^2.
Funktion zur Kennzeichnung des Handels
Das Modul labeling_lib.py enthält einen Probenehmer, der die Handelsgeschäfte nur in der ausgewählten Richtung markiert:
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Die wichtigste Lernschleife
# LEARNING LOOP dataset = get_features(get_prices()) // getting prices and features models = [] // making empty list of models for i in range(1): // the loop sets how many training attempts need to be completed start_time = time.time() data = clustering(dataset, n_clusters=hyper_params['n_clusters']) // adding cluster numbers to data sorted_clusters = data['clusters'].unique() // defining unique clusters sorted_clusters.sort() // sorting clusters in ascending order for clust in sorted_clusters: // loop over all clusters clustered_data = data[data['clusters'] == clust].copy() // selecting data for single cluster if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) // checking for sufficiency of training samples continue clustered_data = get_labels_one_direction(clustered_data, // marking up trades for selected cluster markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1)// deleting closing prices and cluster numbers meta_data = data.copy() // creating data for meta-model meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) // marking up current cluster as "1" models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) // training models and adding them to list end_time = time.time() print("Execution time: ", end_time - start_time)
In der Trainingsdurchlauf werden alle zuvor beschriebenen Funktionen nacheinander verwendet:
- Zitate werden aus der Datei in den Datenrahmen hochgeladen und Merkmale werden implementiert
- Es wird eine leere Liste erstellt, in der die trainierten Modelle gespeichert werden.
- Die Anzahl der Iterationen (Versuche) des Trainings mit denselben Daten wird festgelegt, um zufällige Schwankungen der Modelle auszuschließen
- Die Meta-Merkmale werden geclustert und die Spalte „clusters“ wird den Daten hinzugefügt.
- In der Schleife werden für jedes Cluster die Daten ausgewählt, die nur zu diesem Cluster gehören.
- Die Daten für jeden Cluster werden markiert, d. h. es werden die Kennzeichnungen der Klassen für das Hauptmodell erstellt.
- Für das Metamodell wird ein zusätzlicher Datensatz erstellt, der lernt, einen bestimmten Cluster von allen anderen zu unterscheiden
- Beide Datensätze werden an eine Trainingsfunktion übergeben, die zwei Klassifikatoren trainiert
- Trainierte Modelle werden der Liste hinzugefügt
Der Prozess des Lernens und Testens von Modellen
Die Hyperparameter des Algorithmus (allgemeine Einstellungen) sind im Wörterbuch enthalten:
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 10,
} Das Training wird in einem Zeitraum von 2020 bis 2024 stattfinden, und der Testzeitraum wird von Anfang 2024 bis heute dauern.
Es ist sehr wichtig, die folgenden Parameter korrekt einzustellen:
- markup – 0,2, es ist der durchschnittliche Spread für das Symbol XAUUSD. Wenn Sie die Spanne zu klein oder zu groß einstellen, sind die Testergebnisse möglicherweise nicht realistisch. Außerdem werden hier zusätzliche Verluste in Verbindung mit Slippage und Gebühren berücksichtigt, falls vorhanden.
- Stop Loss – ist die Größe des Stopps in Symbolpunkten.
- Take Profit – ist die Größe des Take Profits in Punkten. Beachten Sie, dass Handelsgeschäfte sowohl gegen Modellsignale als auch bei Erreichen eines Stop Loss oder Take Profits geschlossen werden.
- periods – ist eine Liste mit den Werten der Periodenlängen für die Hauptmerkmale. Im Allgemeinen reichen zehn Periodenlängen aus, beginnend mit fünf und in Schritten von 30.
- periods meta – ist eine Liste mit Periodenwerten für Meta-Merkmale. Eine große Anzahl von Merkmalen ist nicht erforderlich, um Marktformen zu identifizieren. Dabei handelt es sich in der Regel um einen Indikator, z. B. die Standardabweichung für die letzten 5 Balken.
- direction – wir werden nur „buy“ verwenden, weil es einen Aufwärtstrend für Gold gibt.
- n_clusters – ist die Anzahl der Modi (Cluster) für die Clusterung. Ich verwende normalerweise 10.
Training mit den Standardabweichungen
Zunächst werden wir nur Standardabweichungen als Merkmale verwenden, sodass die Funktion zur Erstellung von Merkmalen wie folgt aussehen wird:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Wir starten eine Trainingsdurchlauf, in der wir die folgenden Informationen erhalten:
Iteration: 0, Cluster: 0 R2: 0.989543793954197 Iteration: 0, Cluster: 1 R2: 0.9697821077241253 too few samples: 19 too few samples: 238 Iteration: 0, Cluster: 4 R2: 0.9852770333065658 Iteration: 0, Cluster: 5 R2: 0.7723040599270985 too few samples: 87 Iteration: 0, Cluster: 7 R2: 0.9970885055361235 Iteration: 0, Cluster: 8 R2: 0.9524980839809385 too few samples: 446 Execution time: 2.140070915222168
Es wurde der Versuch unternommen, zehn Modelle für zehn Marktarten zu trainieren. Nicht alle Modi erwiesen sich als nützlich, da einige von ihnen zu wenige Übungsbeispiele (Handelsgeschäfte) enthielten. Sie haben den Filter für die Mindestanzahl von Handelsgeschäften nicht bestanden und wurden daher nicht für das Training verwendet.
Der beste Marktmodus (Cluster) auf Platz 7 zeigte einen R^2 von 0,99. Dies ist ein guter Kandidat für das beste Handelsmodell. Die Ausführungszeit des gesamten Trainingsdurchlaufs betrug nur 2 Sekunden, was sehr schnell ist.
Nachdem wir die Modelle sortiert haben, testen wir das beste Modell:
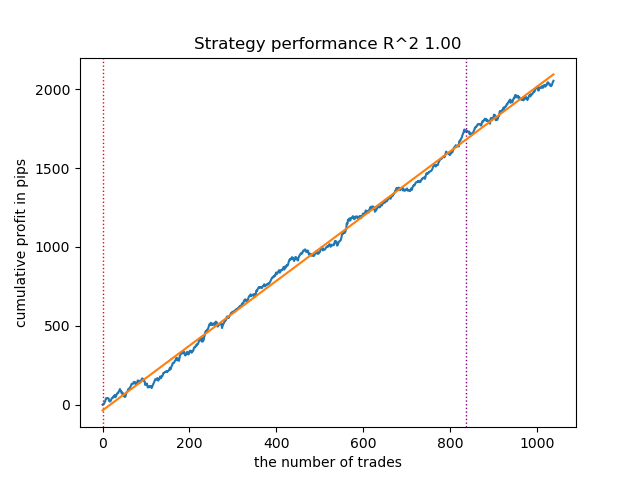
Abbildung 1. Testen des besten Modells nach der Sortierung
Das folgende Modell hat sich ebenfalls als recht gut erwiesen und weist eine große Anzahl von Handelsgeschäften auf:
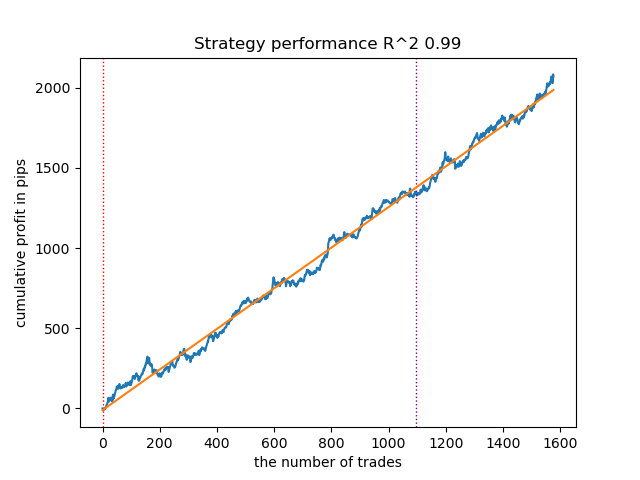
Abbildung 2. Testen des zweitplatzierten Modells
Da die Modelle sehr schnell trainiert und getestet werden, können wir die Schleife viele Male neu starten, um Modelle höchster Qualität zu erhalten. Nach dem nächsten Neustart und der Sortierung erhielten wir zum Beispiel diese Variante:
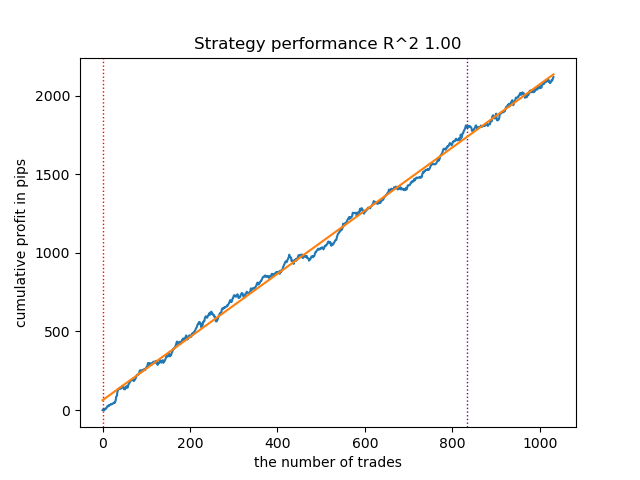
Abbildung 3. Testen des besten Modells nach wiederholtem Trainingsdurchlauf
Training mit gleitenden Durchschnitten und Standardabweichungen
Ändern wir unsere Merkmale und sehen wir, wie die Modelle abschneiden.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).mean() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Als Hauptmerkmale werden einfache gleitende Durchschnitte verwendet, als Metamerkmale werden Standardabweichungen eingesetzt.
Starten wir die Lernschleife und prüfen wir die besten Modelle:
Iteration: 0, Cluster: 0 R2: 0.9312180471969619 Iteration: 0, Cluster: 1 R2: 0.9839766532391275 too few samples: 101 Iteration: 0, Cluster: 3 R2: 0.9643925934007344 too few samples: 299 Iteration: 0, Cluster: 5 R2: 0.9960009821184868 too few samples: 19 Iteration: 0, Cluster: 7 R2: 0.9557947960449501 Iteration: 0, Cluster: 8 R2: 0.9747160963596306 Iteration: 0, Cluster: 9 R2: 0.5526910449937035 Execution time: 2.8627688884735107
So sieht das beste Modell im Tester aus:
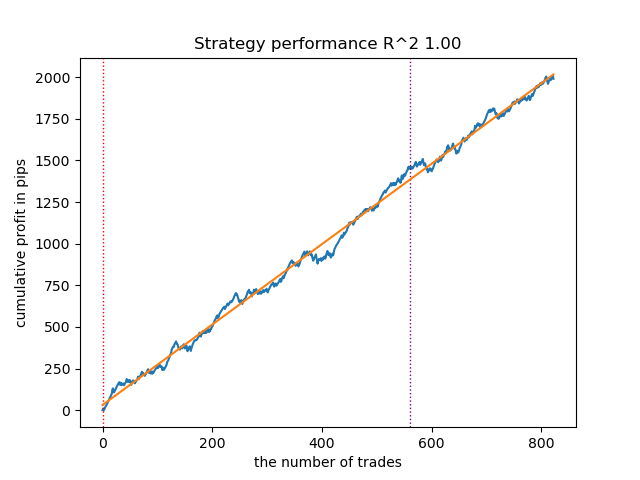
Abbildung 4. Testen des besten Modells mit gleitenden Durchschnitten
Auch das zweitbeste Modell zeigt ein gutes Ergebnis:
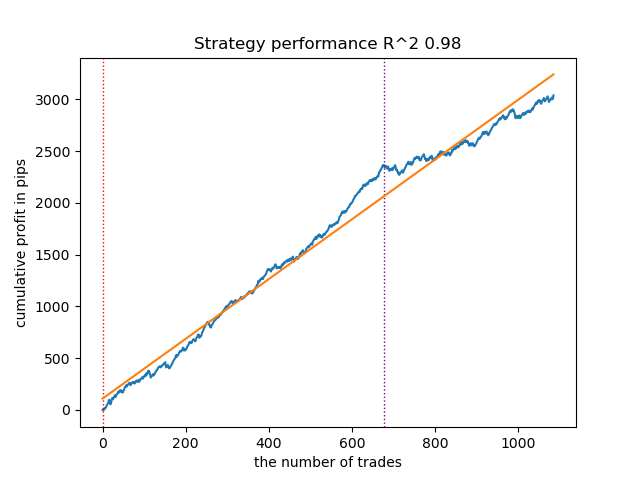
Abbildung 5. Testen des zweiten Modells mit gleitenden Durchschnitten
Indem ich die Trainingsdurchläufe noch ein paar Mal neu startete, erhielt ich eine genauere Saldenkurve:
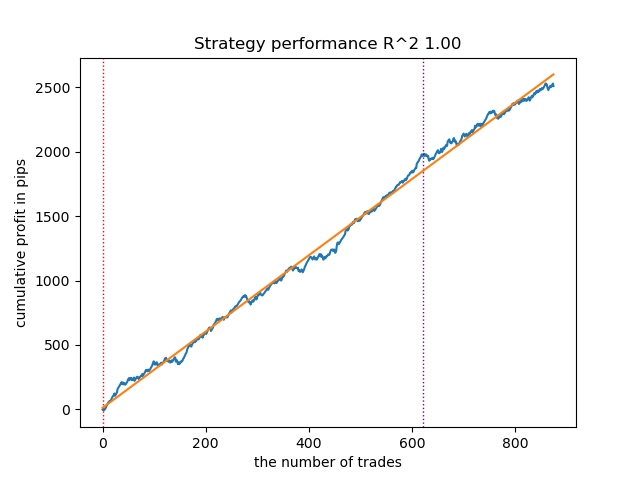
Abbildung 6. Testen des besten Modells nach wiederholtem Trainingsdurchlauf
Hier habe ich nicht mit der Anzahl der Merkmale experimentiert (eine Liste ihrer Zeiträume), sodass es in der Tat möglich ist, eine Vielzahl von solchen Modellen zu erhalten. Die Screenshots zeigen lediglich einige der Varianten.
Kampf gegen Überanpassung
Es kommt häufig vor, dass sich die übermäßige Komplexität eines Modells negativ auf seine Verallgemeinerungsfähigkeit auswirkt. Auch vorbehaltlich der Validierungsphase und des vorzeitigen Abbruchs. In diesem Fall können Sie versuchen, die Anzahl der Merkmale zu reduzieren und/oder das Modell zu vereinfachen. Die Komplexität des Modells im CatBoost-Algorithmus bezieht sich auf die Anzahl der Iterationen oder sequentiell konstruierten Entscheidungsbäume. Versuchen wir, in der Funktion fit_final_models() die folgenden Werte zu ändern:
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.8, test_size=0.2, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.8, test_size=0.2, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False)
Wir verringern die Anzahl der Iterationen auf 100 und den Wert für den frühen Stopp auf 15. So können Sie ein weniger komplexes Modell erstellen.
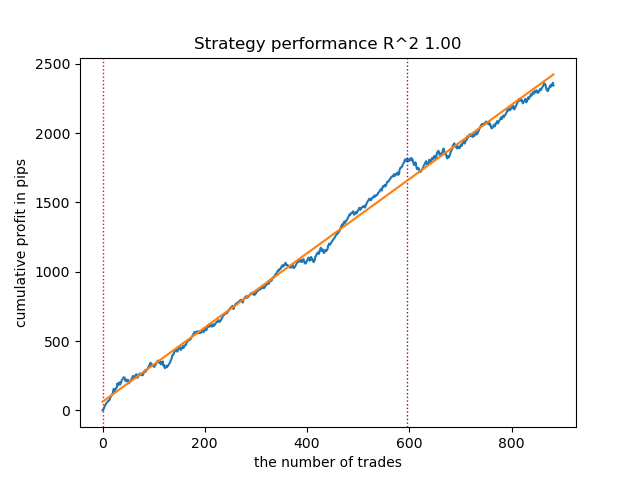
Abbildung 7. Prüfung eines weniger „komplexen“ Modells
Exportieren von Modellen in das Meta Trader 5-Terminal
Die Funktion export_model_to_ONNX() aus dem Modul export_lib() enthält die folgenden Zeichenketten:
# get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathMean(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathSkewness(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n'
Die hervorgehobenen Zeichenfolgen sind für die Berechnung der Merkmale im MQL5-Code verantwortlich. Falls wir die Merkmale im Python-Skript in der Funktion get_features() ändern, wie oben beschrieben, müssen wir ihre Berechnung in diesem Code ändern, oder wir können dies in einer bereits exportierten .mqh-Datei tun.
Korrigieren wir zum Beispiel in der exportierten Datei XAUUSD_H1 ONNX include 0.mqh die folgenden Zeichenfolgen:
#include <Math\Stat\Math.mqh> #resource "catmodel XAUUSD_H1 0.onnx" as uchar ExtModel_XAUUSD_H1_0[] #resource "catmodel_m XAUUSD_H1 0.onnx" as uchar ExtModel2_XAUUSD_H1_0[] int PeriodsXAUUSD_H1_0[10] = {5,35,65,95,125,155,185,215,245,275}; int Periods_mXAUUSD_H1_0[1] = {5}; void fill_araysXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(PeriodsXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,PeriodsXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); // ret[0] = MathMean(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); } void fill_arays_mXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods_mXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods_mXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Die Berechnung der Merkmale entspricht nun der Berechnung der Funktion get_features(), die nur Standardabweichungen verwendete. Wenn gleitende Durchschnitte verwendet wurden, ersetzen Sie sie durch MathMean().
Nach der Kompilierung können wir den Bot bereits in Meta Trader 5 testen.
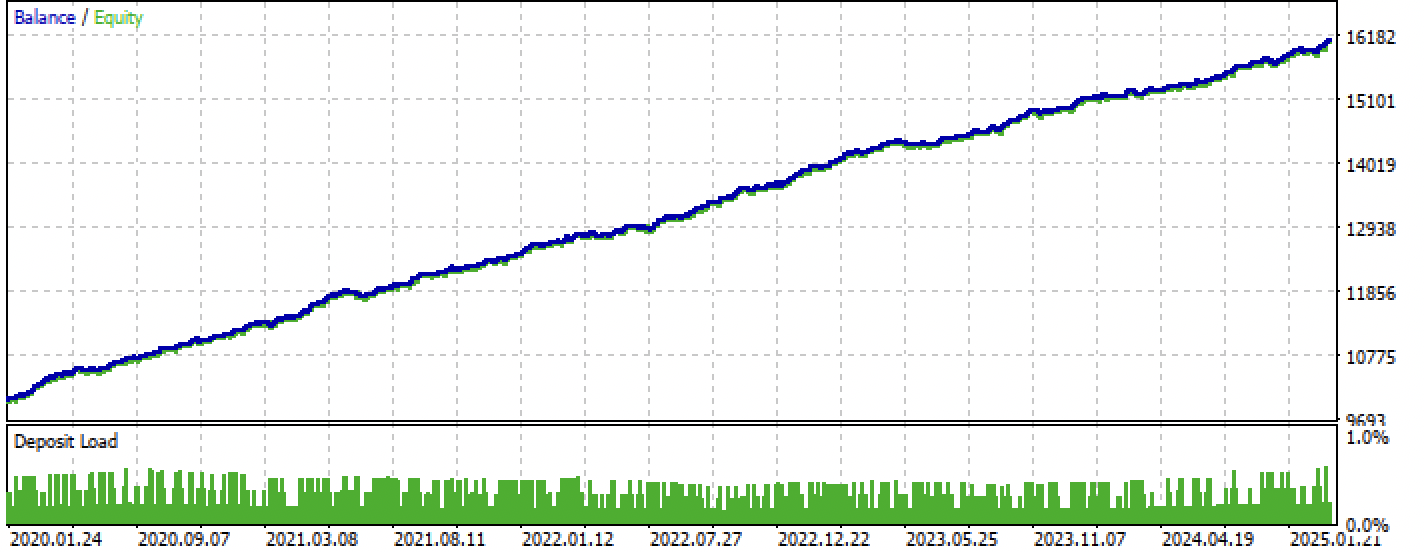
Abbildung 8. Testen im Training + Vorwärtsintervall
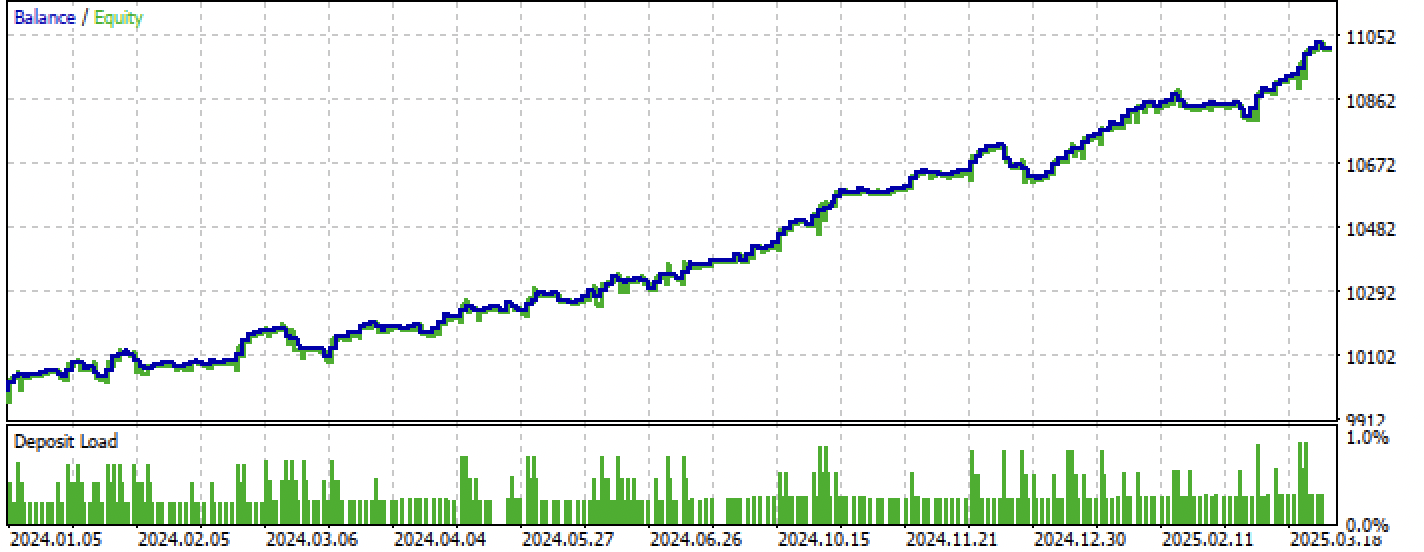
Abbildung 9. Prüfung nur im Zeitraum des Vorwärtstests
Schlussfolgerung
In diesem Artikel wird eine weitere Möglichkeit zur Erstellung unidirektionaler Trendstrategien aufgezeigt, die jedoch auf Clustering basiert. Der Hauptunterschied dieses Ansatzes ist seine Intuitivität und seine hohe Lernrate. Die Qualität der resultierenden Modelle ist vergleichbar mit der des vorherigen Artikels.
Das Archiv Python files.zip enthält die folgenden Dateien für die Entwicklung in Python:
| Dateiname | Beschreibung |
|---|---|
| one direction clusters.py | Das wichtigste Skript zum Lernen von Modellen |
| labeling_lib.py | Aktualisiertes Modul mit Handelskennzeichnungen |
| tester_lib.py | Aktualisierter nutzerdefinierter Tester für auf maschinellem Lernen basierende Strategien |
| export_lib.py | Ein Modul zum Exportieren von Modellen in das Terminal |
| XAUUSD_H1.csv | Die vom MetaTrader 5-Terminal exportierte Kursdatei |
Das Archiv MQL5 files.zip enthält Dateien für MetaTrader 5:
| Dateiname | Beschreibung |
|---|---|
| one direction clusters.ex5 | Kompilierter Bot aus diesem Artikel |
| one direction clusters.mq5 | Der Source-Code des Bot aus dem Artikel |
| Verzeichnis Include//Trend following | Speicherort der ONNX-Modelle und der Header-Datei für die Verbindung mit dem Bot. |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17755
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
So haben Sie R2 ist ein modifizierter Index, dessen Effizienz auf dem Gewinn in Pips basiert. Was ist mit dem Drawdown und anderen Leistungsindikatoren? Wenn wir ein Modell erhalten, das mehr als 90 % beim Training und mindestens 85 % beim Test erzielt, dann wird Ihr Index beeindruckende Zahlen liefern. Egal, wie oft ich den Tester auf MT5 laufen lasse, ich habe noch nie einen Gewinn in der Historie erhalten. Das Depot ist aufgebraucht. Dies ist trotz der Tatsache, dass Ihr Tester auf Python gibt 0,97-0,98
Ich verstehe nicht, was das mit CV zu tun hat.
Alle diese Strategien haben eine geringe Beweiskraft, weil sie nur auf der Geschichte der nicht-stationären Kurse basieren. Aber man kann Trends aufspüren.Und wo bleibt die KI dabei? Haben Sie catbust auf dieses Niveau gebracht? Oder ist das nur ein üblicher Marketingtrick, um das Publikum zu ködern?
Ich habe dieses seltsame Merkmal in mehreren neueren Veröffentlichungen von verschiedenen Autoren bemerkt.
Gibt es außer dem Catbust keine anständigen Modelle?
Und wo bleibt die KI dabei? Haben Sie catbust auf dieses Niveau gebracht? Oder ist das nur ein üblicher Marketing-Gag, um das Publikum zu ködern?
Mir ist dieses seltsame Merkmal in mehreren neueren Veröffentlichungen verschiedener Autoren aufgefallen.
Gibt es außer catbust keine anständigen Modelle?
Clickbait (populäre Abkürzung). Ich bin überhaupt kein Befürworter dieses Begriffs.
Die Leute sind es gewohnt, MO als "AI" zu bezeichnen. Außerdem ist TC ein Komplex aus verschiedenen MO-Algorithmen, z. B. Clustering und Klassifizierung.